基于瞬時(shí)特征譜的聯(lián)合特征調(diào)制識(shí)別算法*
2022-03-01 08:27:20劉一兵
通信技術(shù) 2022年12期
羅 強(qiáng),劉一兵,趙 洋
(中國(guó)人民解放軍63892部隊(duì),河南 洛陽(yáng) 471003)
0 引言
在通信偵察對(duì)抗、無(wú)線頻譜監(jiān)測(cè)、信號(hào)認(rèn)知認(rèn)證等非協(xié)作通信[1]的應(yīng)用中,調(diào)制識(shí)別作為其中的關(guān)鍵環(huán)節(jié),通過(guò)對(duì)多維度的信號(hào)特征進(jìn)行聯(lián)合分析來(lái)判別信號(hào)的調(diào)制方式,為信號(hào)參數(shù)分析、信息監(jiān)控、對(duì)抗干擾等環(huán)節(jié)提供重要支撐。
針對(duì)信號(hào)的調(diào)制識(shí)別方法主要包括基于判決理論識(shí)別和基于統(tǒng)計(jì)模式識(shí)別兩種方法[2-4]。判決理論識(shí)別方法屬于非參數(shù)方法,從本質(zhì)上可看作在無(wú)窮維的信號(hào)空間上,基于不同信號(hào)在空間上的概率分布差異,通過(guò)廣義似然比等判決準(zhǔn)則[5-6]對(duì)信號(hào)進(jìn)行分類的過(guò)程。實(shí)際分析中,信號(hào)采樣后由無(wú)窮維變?yōu)橛邢蘧S,但高維的貝葉斯估計(jì)或者K近鄰等決策算法仍然需要巨量的樣本才能擬合出信號(hào)的空間分布,因而該方法應(yīng)用較少。統(tǒng)計(jì)模式識(shí)別主要通過(guò)提取與調(diào)制方式相關(guān)的識(shí)別特征,將信號(hào)空間映射到能代表信號(hào)模式的特征空間,并通過(guò)特征空間的差異來(lái)區(qū)分信號(hào)模式。統(tǒng)計(jì)模式識(shí)別方法降低了空間維度,便于工程實(shí)現(xiàn),但識(shí)別效果與特征的選取高度相關(guān)。目前,統(tǒng)計(jì)模式識(shí)別方法選取的特征通常包括瞬時(shí)特征、高階累積量特征、循環(huán)譜特征、小波特征、分形特征[7]、星座圖特征[8-10]等。這些特征在特定條件下均能對(duì)調(diào)制類型進(jìn)行有效識(shí)別,但識(shí)別效果受限于信號(hào)的信噪比、成型脈沖形狀、采樣率,同時(shí)部分特征的計(jì)算量制約了算法的工程應(yīng)用。
本文在信號(hào)瞬時(shí)特征的基礎(chǔ)上進(jìn)行特征變換,將高階調(diào)制映射為低階調(diào)制,基于變換后譜密度的功率變化和分布變化,同時(shí)結(jié)合瞬時(shí)特征統(tǒng)計(jì)量、譜相關(guān)特征、分形特征,對(duì)2ASK、4ASK、2FSK、4FSK、BPSK、QPSK這6種數(shù)字調(diào)制信號(hào)進(jìn)行識(shí)別分類,并通過(guò)集成學(xué)習(xí)模型進(jìn)行分類,有效提升了低信噪比環(huán)境下信號(hào)識(shí)別的正確率。
1 瞬時(shí)特征譜
典型的瞬時(shí)特征方法通過(guò)對(duì)信號(hào)的瞬時(shí)幅度、頻率、相位進(jìn)行歸一化,提取其標(biāo)準(zhǔn)差、峰度等信息來(lái)區(qū)分信號(hào)的調(diào)制類型。這些特征包括絕對(duì)幅度、相位和頻率標(biāo)準(zhǔn)偏差,均值歸一化包絡(luò)方差參量,信號(hào)包絡(luò)峰度,頻率峰度等,屬于二階統(tǒng)計(jì)量,對(duì)噪聲以及脈沖成型濾波非常敏感[11]。為了提升識(shí)別算法對(duì)成型濾波的適應(yīng)能力,可基于統(tǒng)計(jì)量的頻域來(lái)設(shè)計(jì)特征。
瞬時(shí)特征譜的基本思想是,信號(hào)瞬時(shí)特征以符號(hào)寬度為周期進(jìn)行規(guī)律變化,對(duì)瞬時(shí)特征求功率譜密度,譜密度會(huì)集中在符號(hào)帶寬內(nèi),通過(guò)對(duì)瞬時(shí)特征進(jìn)行不同的數(shù)值變換,其功率譜密度會(huì)發(fā)生不同變化,從而區(qū)分出不同階數(shù)的數(shù)字調(diào)制。
接收端信號(hào)r(t)滿足模型:
式中:A(t)為已調(diào)信號(hào)振幅;θ(t)為已調(diào)信號(hào)相位;n(t)為窄帶高斯噪聲;wc為信號(hào)載頻。信號(hào)的包絡(luò)、相位形式如下:
式中:z(t),φ(t)分別為接收信號(hào)的包絡(luò)和相位。
信號(hào)經(jīng)正交下變頻后的基帶形式為:
信號(hào)的瞬時(shí)幅度、瞬時(shí)相位、瞬時(shí)頻率分別為:
定義信號(hào)的N階瞬時(shí)特征如下:
式中:Inst為InstA(t)、InstP(t)、InstF(t)的縮寫形式。
信號(hào)的N階瞬時(shí)特征譜為:
式中:RN(τ)為InstN的自相關(guān)函數(shù)。
理想的2N階ASK/PSK/FSK調(diào)制信號(hào)所對(duì)應(yīng)的瞬時(shí)幅度/瞬時(shí)相位/瞬時(shí)頻率,其N-1階瞬時(shí)特征的均值為二值函數(shù),N階瞬時(shí)特征均值為0。N-1階瞬時(shí)特征的譜密度主要集中在符號(hào)速率Rb對(duì)應(yīng)的頻率范圍內(nèi),N階瞬時(shí)特征的譜密度則為白噪聲。以4階調(diào)制的瞬時(shí)特征譜為例,如圖1、圖2、圖3所示,一階瞬時(shí)特征譜相比0階瞬時(shí)特征譜,總功率明顯降低,并且低頻分量的功率比高頻分量的功率下降更快,高斯白噪聲二階瞬時(shí)特征譜已趨近于白噪聲。
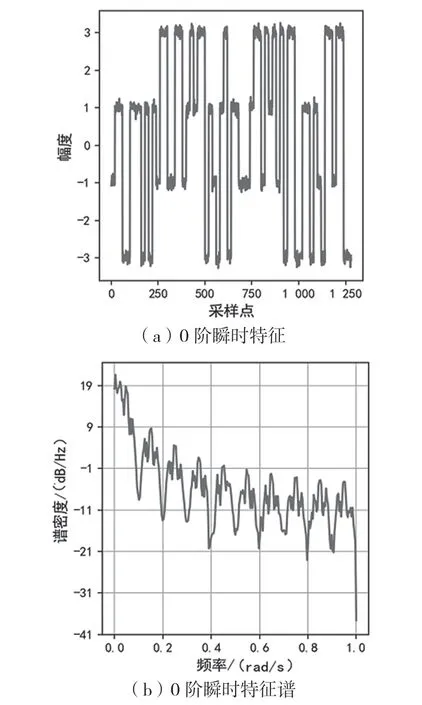
圖1 4階調(diào)制的0階瞬時(shí)特征譜
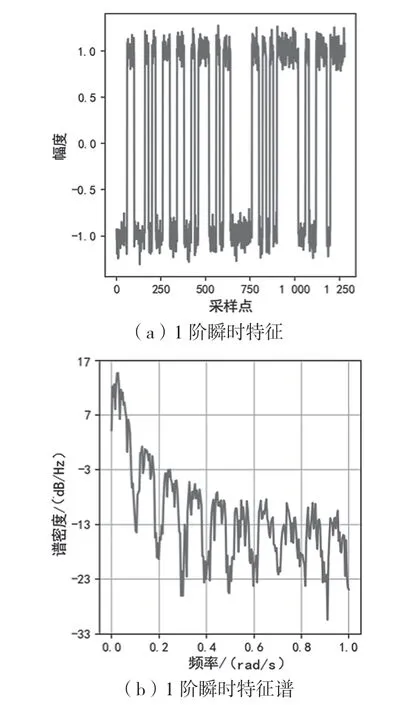
圖2 4階調(diào)制的1階瞬時(shí)特征譜
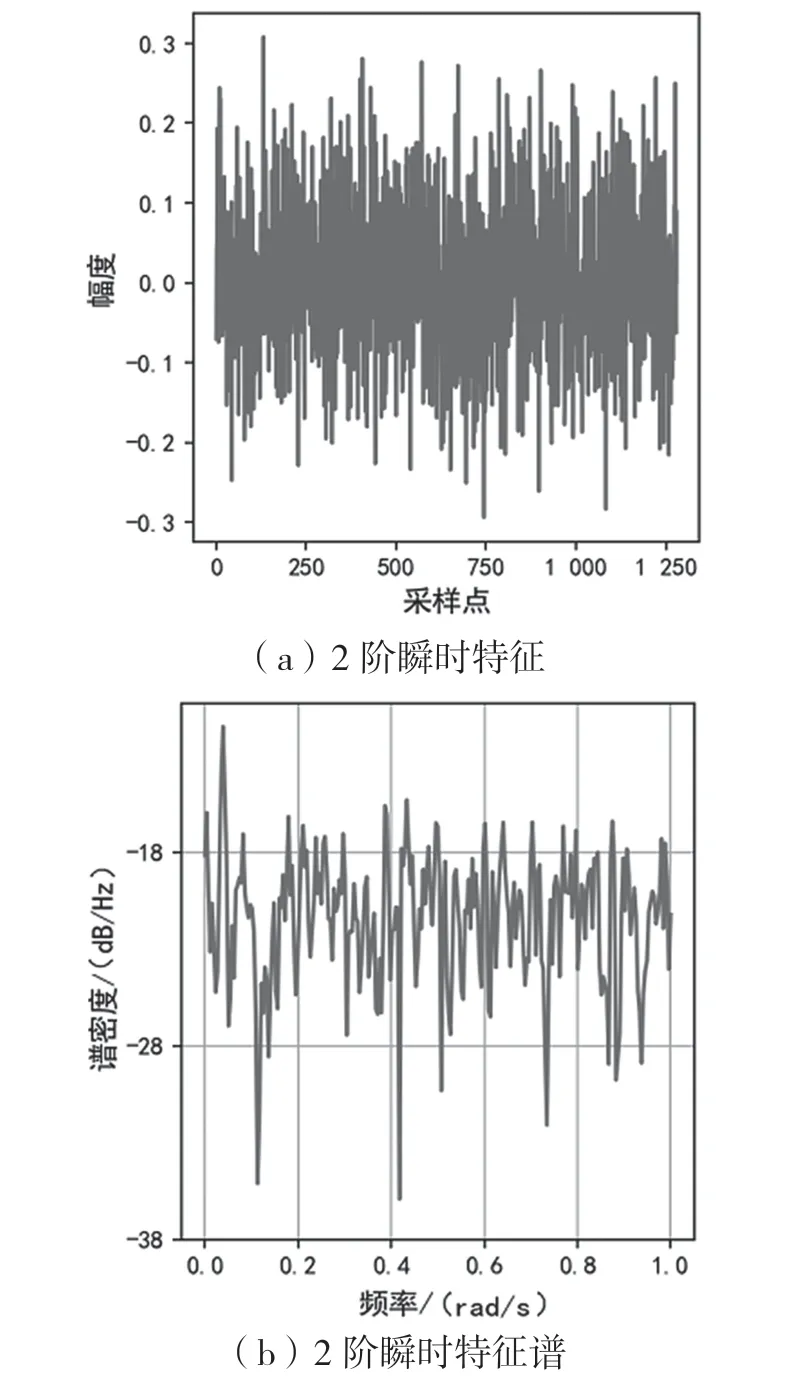
圖3 4階調(diào)制的2階瞬時(shí)特征譜
考慮基于Rb范圍內(nèi)瞬時(shí)特征的功率變化以及總體譜密度的分布變化來(lái)區(qū)分?jǐn)?shù)字調(diào)制階數(shù)。定義信號(hào)的N階瞬時(shí)特征譜增量ΔPN,以及N階瞬時(shí)特征譜熵增量ΔSN(q),則有:
式中:pN(q)為N階特征譜中,頻率q以下的功率占比;SN(q)為該分布在q頻率分位處的分布度量。
信號(hào)的瞬時(shí)特征譜增量、譜熵增量分別從功率變化、分布改變的角度對(duì)變換后瞬時(shí)特征的功率譜進(jìn)行度量。脈沖成型以及各類濾波會(huì)改變信號(hào)的瞬時(shí)特征譜,但不會(huì)改變瞬時(shí)特征譜隨著階數(shù)改變的變化趨勢(shì),這也體現(xiàn)為特征在一定信噪比范圍內(nèi)對(duì)信號(hào)失真不敏感。
2 瞬時(shí)特征譜的抗噪聲性能
以2ASK、4ASK、BPSK、QPSK、2FSK、4FSK為數(shù)據(jù)集,通過(guò)仿真實(shí)驗(yàn)研究瞬時(shí)特征譜增量、譜熵增量隨信噪比的變化情況,分析其識(shí)別性能。實(shí)驗(yàn)數(shù)據(jù)為零中頻IQ信號(hào),符號(hào)速率Rb=10 000 Baud,采樣頻率fs=100 kHz,ASK、PSK成型函數(shù)為升余弦滾降脈沖,滾降系數(shù)為0.5,F(xiàn)SK信號(hào)調(diào)制指數(shù)為1,仿真數(shù)據(jù)長(zhǎng)度為512個(gè)符號(hào),信噪比范圍為0~20 dB。
圖4、圖5、圖6依次為信號(hào)的瞬時(shí)幅度譜、相位譜、頻率譜的增量與信噪比的變化關(guān)系曲線。從圖4可以看出,一階幅度譜增量可以將2ASK與4ASK區(qū)分開(kāi)來(lái),二階幅度譜增量能在一定信噪比范圍內(nèi)將ASK與其他調(diào)制區(qū)分開(kāi)。從圖5可以看出,相位譜增量的標(biāo)準(zhǔn)差較大,區(qū)分能力有限。從圖6中可以看出,瞬時(shí)頻率譜增量能在較低信噪比水平下將2FSK與4FSK區(qū)分開(kāi)。
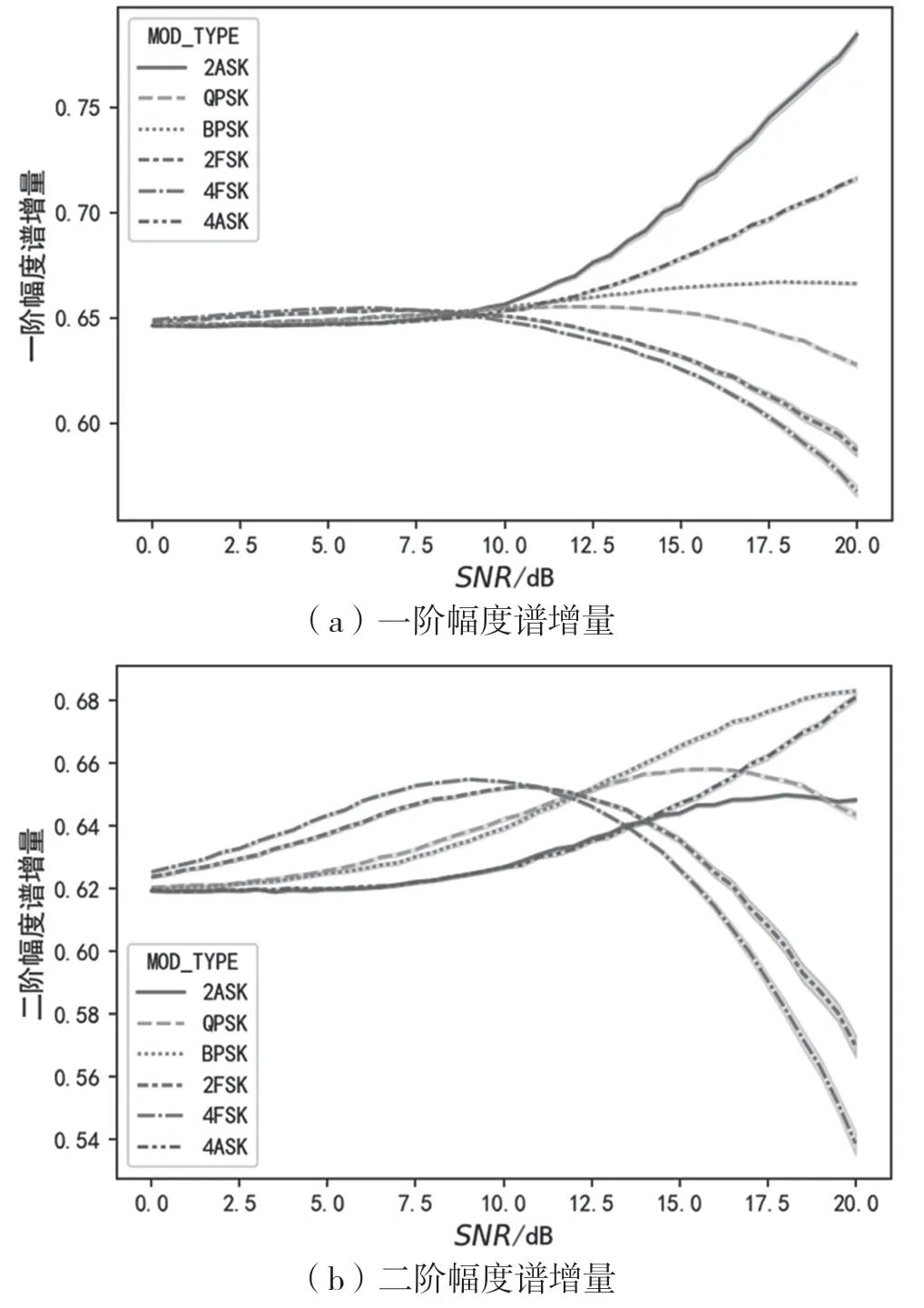
圖4 一階、二階幅度譜增量
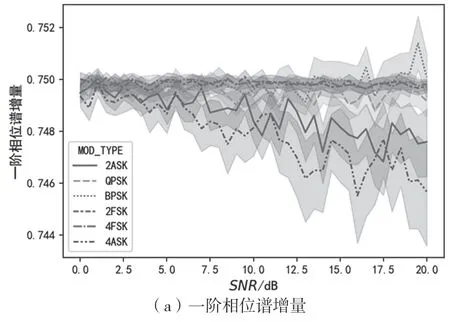
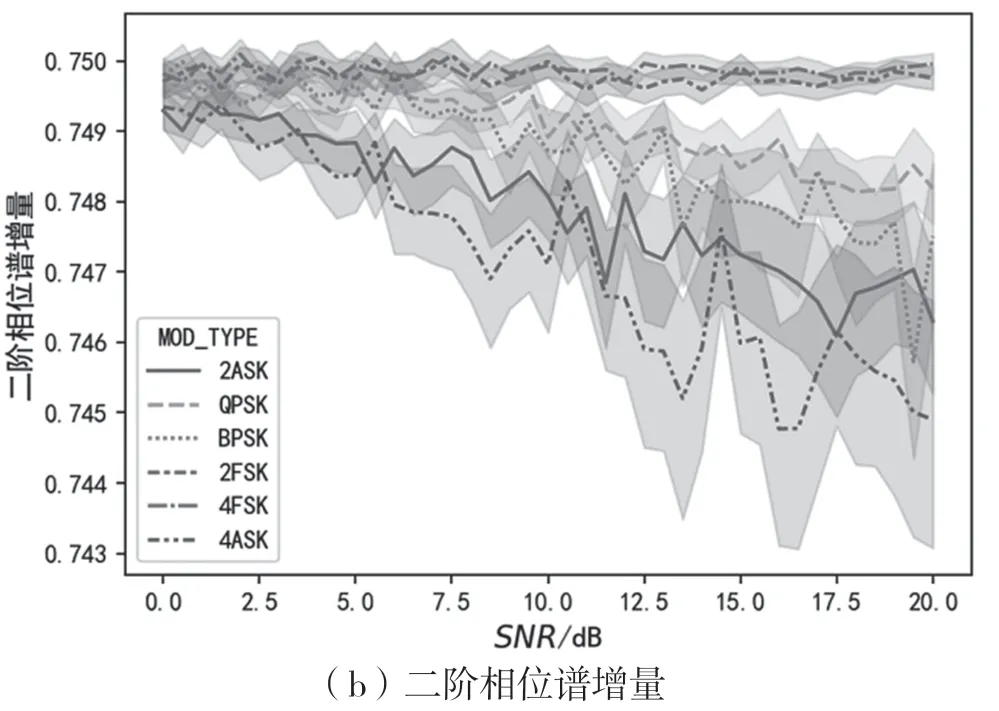
圖5 一階、二階相位譜增量
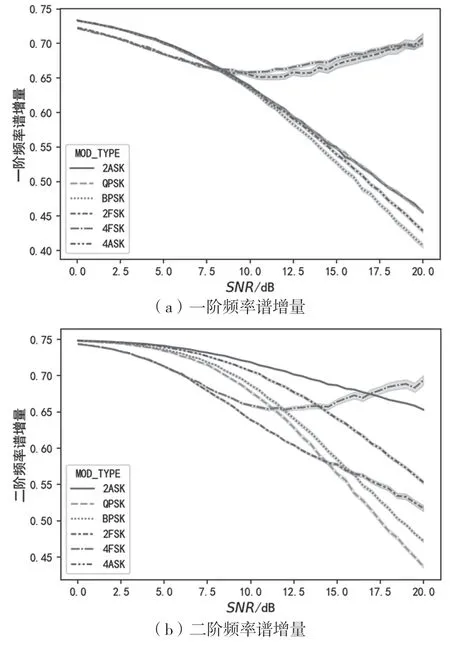
圖6 一階、二階頻率譜增量
圖7、圖8、圖9依次為一階、二階的瞬時(shí)幅度譜、相位譜、頻率譜的譜熵增量(q=0.5Rb)與信噪比的變化關(guān)系曲線。從圖7中可以看出,一階幅度譜熵增量可以在0~20 dB的信噪比范圍內(nèi),將ASK、PSK、FSK明顯區(qū)分開(kāi)來(lái),二階幅度譜熵增量能在固定的信噪比上將2ASK、4ASK、BPSK區(qū)分開(kāi),但在信噪比未知的情況下區(qū)分能力有限。從圖8中可以看出,相位譜熵增量能在較低信噪比水平下將BPSK與QPSK區(qū)分開(kāi),二階相位譜熵增量比一階相位譜熵增量的標(biāo)準(zhǔn)差更小。從圖9中可以看出,一階瞬時(shí)頻率譜熵增量能明顯將FSK與其他調(diào)制區(qū)分開(kāi),二階瞬時(shí)頻率譜熵增量能明顯將2FSK與4FSK區(qū)分開(kāi)。

圖7 一階、二階幅度譜熵增量
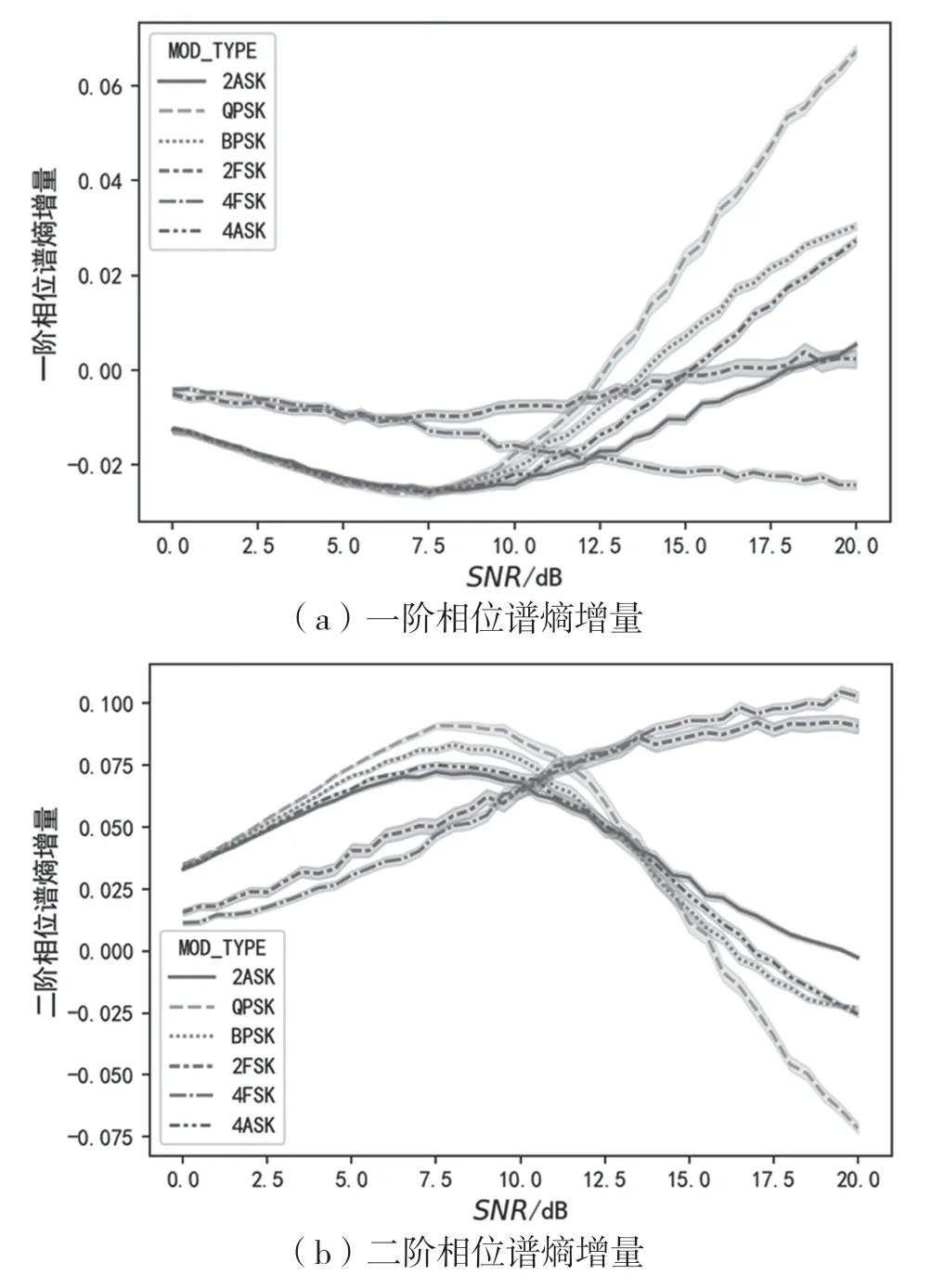
圖8 一階、二階相位譜熵增量
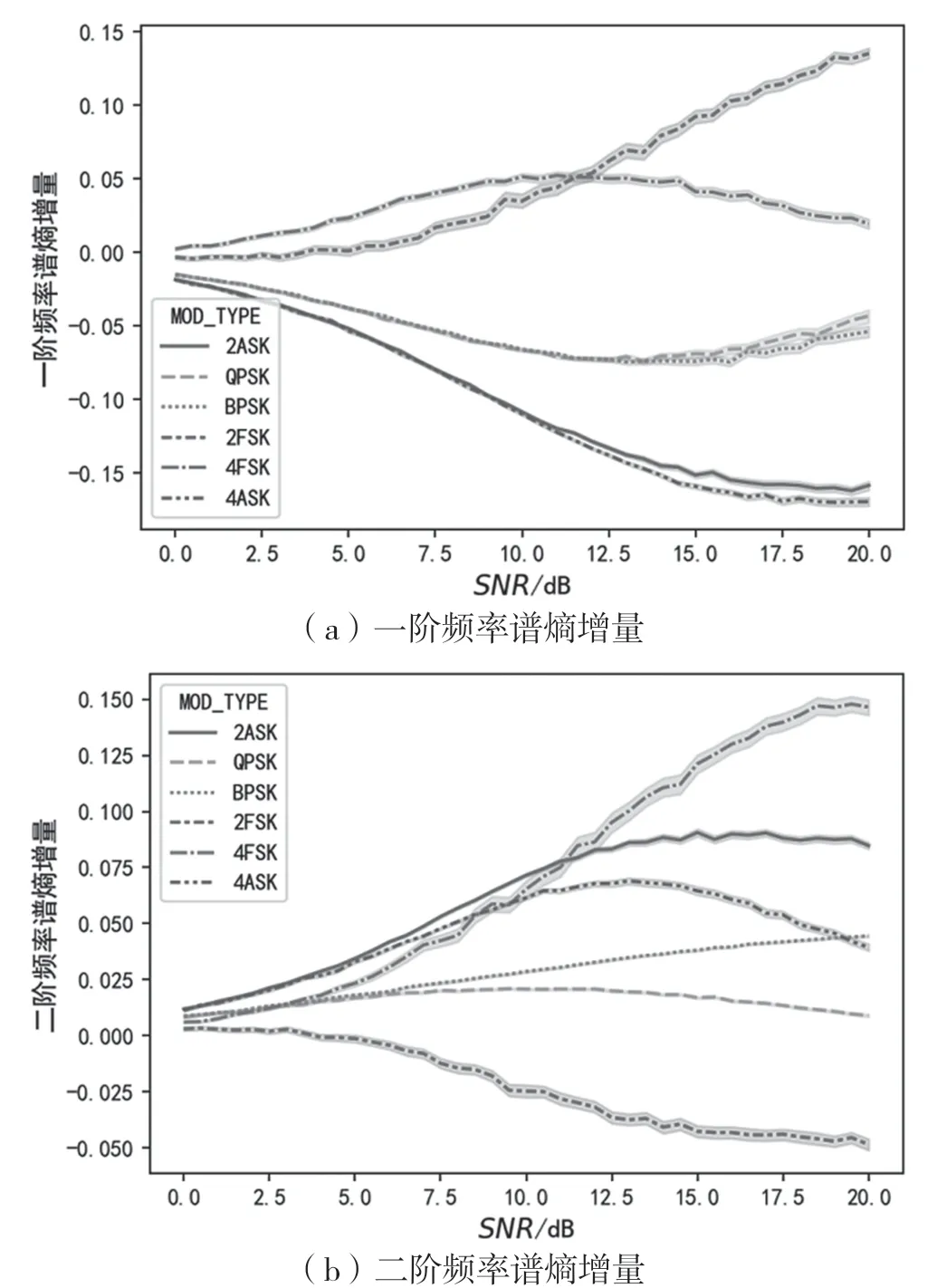
圖9 一階、二階頻率譜熵增量
總體而言,瞬時(shí)特征譜增量和瞬時(shí)特征譜熵增量對(duì)不同的信號(hào)均有一定的區(qū)分能力,但單獨(dú)一個(gè)特征無(wú)法對(duì)不同信噪比的不同信號(hào)進(jìn)行有效區(qū)分,因此需要將特征進(jìn)行組合,構(gòu)造特征空間下的類別分布,通過(guò)不同模型的分類器對(duì)信號(hào)進(jìn)行識(shí)別。
3 分類器的設(shè)計(jì)及仿真
構(gòu)造的特征空間通常是非線性的,使用線性分類器無(wú)法對(duì)空間進(jìn)行有效區(qū)分,因此本文使用樹形結(jié)構(gòu)分類器。當(dāng)樣本數(shù)量規(guī)模較大時(shí),樹形分類器通過(guò)空間搜索,能使特征參數(shù)在高維空間有效地收斂到不同的信號(hào)類別。在此,利用boosting算法中的殘差提升模型XGBoost,將多個(gè)弱學(xué)習(xí)器進(jìn)行集成,實(shí)現(xiàn)特征空間到類別空間端到端的學(xué)習(xí)分類。
XGBoost將損失函數(shù)展開(kāi)至泰勒二階函數(shù),并引入正則化項(xiàng),其損失函數(shù)為:
式中:L(t)為第t棵樹的損失函數(shù);為第t棵樹之前的樹的損失值;gi為關(guān)于第t棵樹之前預(yù)測(cè)值的一階導(dǎo)數(shù);hi為關(guān)于第t棵樹之前預(yù)測(cè)值的二階導(dǎo)數(shù);ft(xi)為需要求解的第t棵樹;Ω為對(duì)樹的數(shù)量的懲罰項(xiàng)。XGBoost算法最大的優(yōu)勢(shì)在于性能,無(wú)論是從準(zhǔn)確率還是計(jì)算速度,相比于SVM、神經(jīng)網(wǎng)絡(luò)等經(jīng)典算法,更具有實(shí)效性[12]。
選擇待識(shí)別的信號(hào)集為2ASK、4ASK、BPSK、QPSK、2FSK、4FSK共6種數(shù)字調(diào)制信號(hào)。符號(hào)速率Rb=10 kBd,采樣頻率fs的范圍為50~200 kHz,符號(hào)個(gè)數(shù)為128~1 024,ASK、PSK成型函數(shù)為升余弦滾降脈沖,滾降系數(shù)為0.3~0.7,成型濾波長(zhǎng)度為6~20倍的Rb[13],F(xiàn)SK信號(hào)調(diào)制指數(shù)為0.6~2,信噪比定義為信號(hào)帶寬內(nèi)的信號(hào)噪聲能量比,范圍為0~20 dB,信號(hào)相位為隨機(jī)相位。信號(hào)樣本集為100 000個(gè),訓(xùn)練集為80 000個(gè),測(cè)試集為20 000個(gè)。
信號(hào)集所需的瞬時(shí)特征譜階數(shù)為2階,提取信號(hào)的6個(gè)瞬時(shí)特征譜增量,選取q=[0.5Rb,Rb],提取信號(hào)的12個(gè)瞬時(shí)特征譜熵增量。采用XGBoost學(xué)習(xí)器,樹個(gè)數(shù)設(shè)置為100個(gè),深度設(shè)置為10層。提取8個(gè)傳統(tǒng)瞬時(shí)特征參量[14]、2個(gè)譜相關(guān)特征參量、2個(gè)分形特征[15]參量作為基本特征,然后單獨(dú)使用瞬時(shí)特征譜特征,最后將瞬時(shí)特征譜特征與基本特征進(jìn)行聯(lián)合,通過(guò)學(xué)習(xí)訓(xùn)練,對(duì)不同特征組合下的信號(hào)進(jìn)行調(diào)制識(shí)別,識(shí)別正確率的結(jié)果如圖10所示。
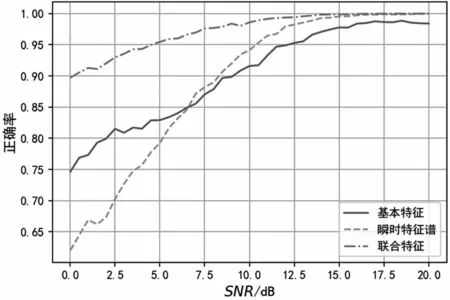
圖10 分類識(shí)別正確率
可以看出,當(dāng)SNR<6 dB時(shí),基本特征的識(shí)別效果要優(yōu)于瞬時(shí)特征譜,這是因?yàn)榛咎卣魃婕岸鄠€(gè)維度的設(shè)計(jì),單一維度下設(shè)計(jì)的特征很難在所有信噪比下優(yōu)于多個(gè)維度特征的識(shí)別效果;當(dāng)SNR>6 dB時(shí),瞬時(shí)特征譜的識(shí)別效果要優(yōu)于基本特征且提升明顯。特征聯(lián)合后,基本特征的識(shí)別正確率大幅提高,當(dāng)SNR>8 dB時(shí),聯(lián)合特征的識(shí)別正確率接近100%。
當(dāng)10 dB<SNR<20 dB時(shí),基本特征識(shí)別的平均正確率為98.3%,瞬時(shí)特征譜識(shí)別的平均正確率為99.5%,聯(lián)合特征的識(shí)別正確率為100%。不同特征識(shí)別的混淆矩陣如圖11、圖12和圖13所示。對(duì)比混淆圖可知,基于瞬時(shí)特征譜的識(shí)別效果在4ASK、QPSK的識(shí)別正確率比基本特征要高7%和3%,基本特征的4ASK、QPSK存在相互誤判的情況,這是因?yàn)榫€性調(diào)制中,為了控制信號(hào)帶寬,對(duì)基帶脈沖做了成型處理,導(dǎo)致基本特征中的統(tǒng)計(jì)特性對(duì)信號(hào)的區(qū)分能力變?nèi)酢?/p>

圖11 基本特征識(shí)別混淆矩陣(10 dB<SNR<20 dB)
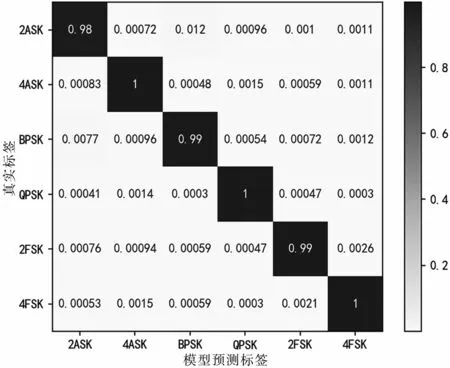
圖12 瞬時(shí)特征譜識(shí)別混淆矩陣(10 dB<SNR<20 dB)
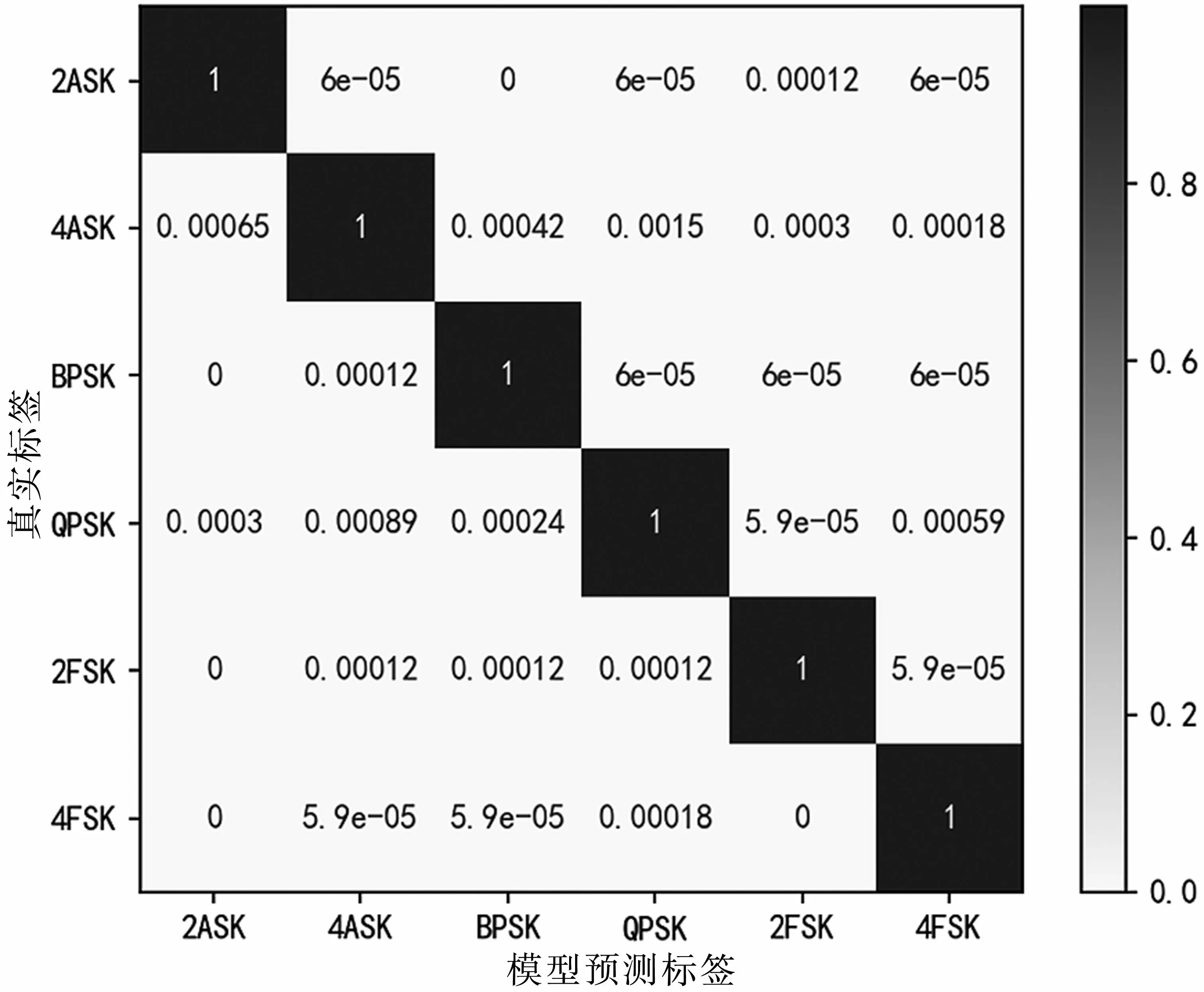
圖13 聯(lián)合特征識(shí)別混淆矩陣(10 dB<SNR<20 dB)
當(dāng)0 dB<SNR<10 dB時(shí),基本特征識(shí)別的平均正確率為92.8%,瞬時(shí)特征譜識(shí)別的平均正確率為91.7%,聯(lián)合特征的識(shí)別正確率為98.7%。不同特征識(shí)別的混淆矩陣如圖14、圖15和圖16所示。對(duì)比混淆圖可知,基于瞬時(shí)特征譜的識(shí)別效果在4ASK、QPSK的識(shí)別正確率比基本特征要高20%和7%,其他特征的正確率要低于基本特征,特征聯(lián)合后,正確率顯著提升。
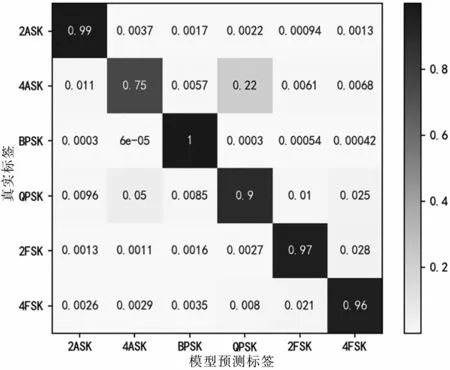
圖14 基本特征識(shí)別混淆矩陣(0 dB<SNR<10 dB)
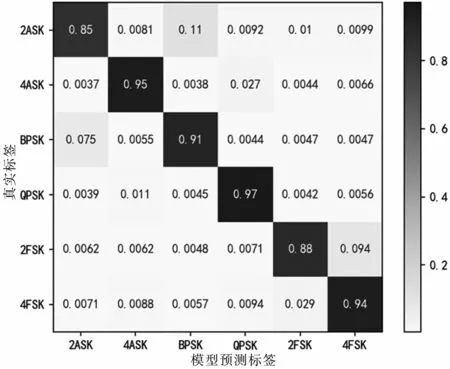
圖15 瞬時(shí)特征譜識(shí)別混淆矩陣(0 dB<SNR<10 dB)
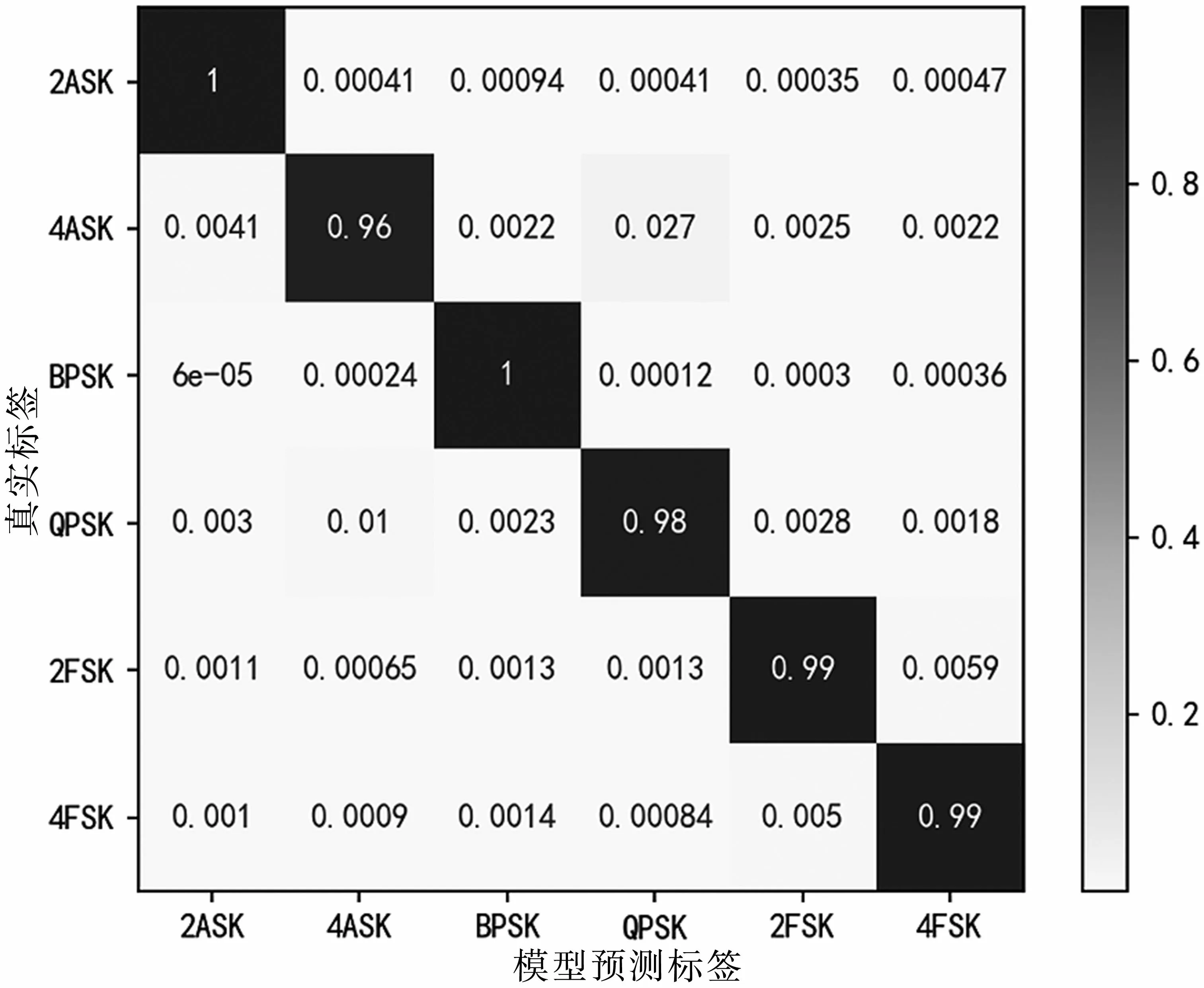
圖16 瞬時(shí)特征譜識(shí)別混淆矩陣(0 dB<SNR<10 dB)
實(shí)際信號(hào)分析中,對(duì)信號(hào)的載頻估計(jì)往往存在一定偏差,因此對(duì)信號(hào)集的基帶信號(hào)加入一定頻偏,頻偏范圍在±fs/100之間,信號(hào)識(shí)別的正確率如圖17所示。可以看出,當(dāng)SNR>3 dB時(shí),瞬時(shí)特征譜的性能要優(yōu)于基本特征,且正確率隨信噪比的增加快速提升,而特征聯(lián)合后,正確率要遠(yuǎn)高于基本特征,這也體現(xiàn)了瞬時(shí)特征譜算法對(duì)先驗(yàn)信息的不敏感。
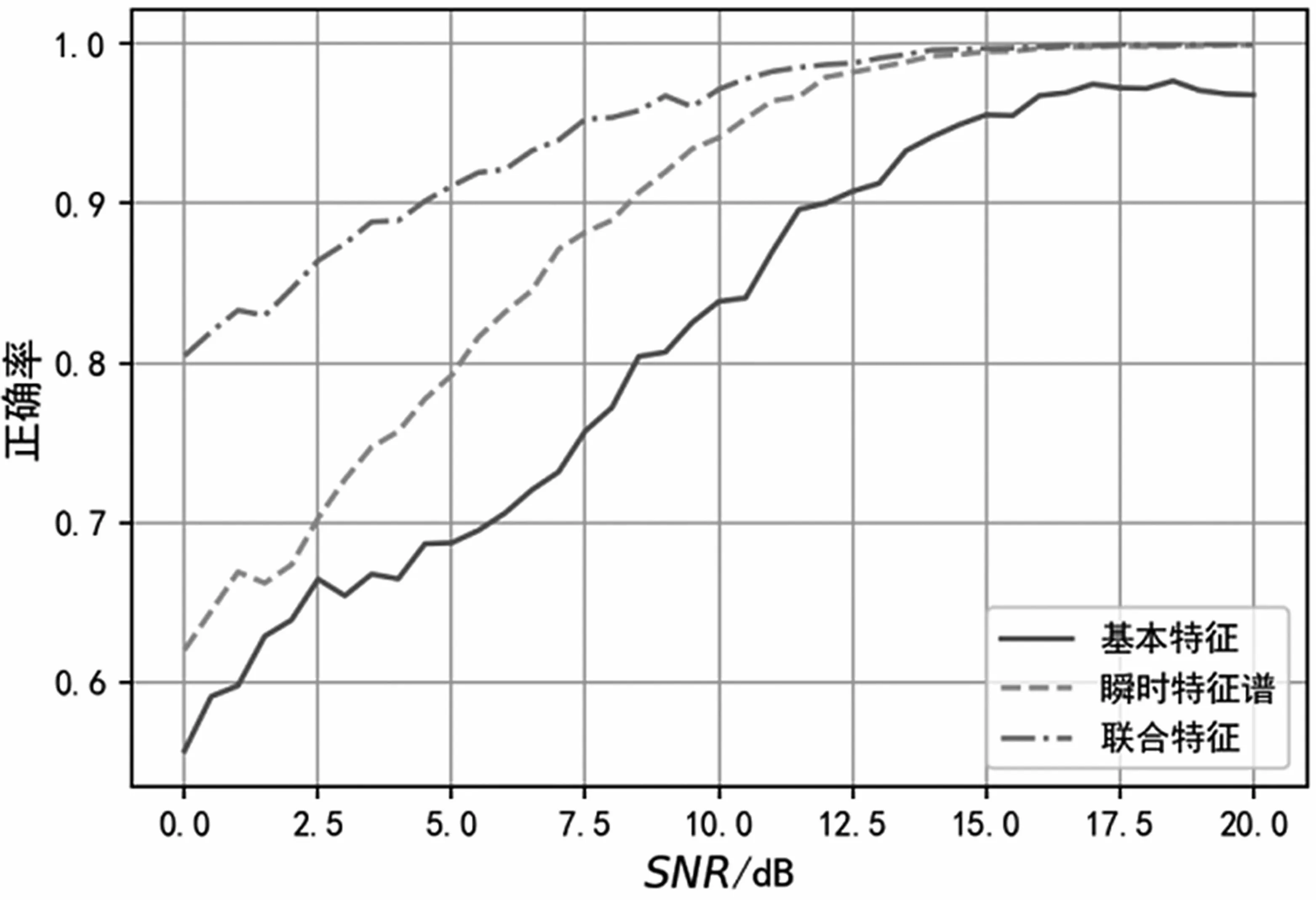
圖17 分類識(shí)別正確率(加入頻偏)
4 結(jié)語(yǔ)
本文提出了一種基于瞬時(shí)特征譜的特征構(gòu)建方法。該方法首先對(duì)信號(hào)的瞬時(shí)特征進(jìn)行多階變換,其次從譜功率和譜分布兩個(gè)維度進(jìn)行特征設(shè)計(jì),最后以XGBoost集成學(xué)習(xí)器分類器進(jìn)行調(diào)制識(shí)別。仿真結(jié)果顯示了基于瞬時(shí)特征譜信號(hào)識(shí)別方法的有效性,在低信噪比情況下能大幅提升傳統(tǒng)特征參數(shù)識(shí)別的正確率,因此具有一定的實(shí)用價(jià)值。
猜你喜歡
湘潮(上半月)(2023年5期)2023-06-14 05:42:52
社會(huì)科學(xué)戰(zhàn)線(2022年9期)2022-10-25 03:30:28
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評(píng)價(jià)·高一版(2020年6期)2020-11-02 02:45:24
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年11期)2018-08-04 03:25:42
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
湖湘論壇(2016年1期)2016-12-01 04:22:01
鑿巖機(jī)械氣動(dòng)工具(2016年3期)2016-03-01 04:00:25
