面向智能駕培系統的深度學習表情識別方法*
2022-02-28 13:52:18方淦杰嚴楷淳歐陽潔榆
傳感器與微系統 2022年2期
關鍵詞:模型
馮 桑, 方淦杰, 嚴楷淳, 歐陽潔榆
(廣東工業大學 機電工程學院,廣東 廣州 510006)
0 引 言
虛擬現實駕駛培訓系統己經被廣泛應用到駕駛技能培訓以及交通安全教育領域,這種駕駛培訓方式能夠以逼真的駕駛場景高度還原真實訓練場地,有效提升學員學習駕駛技能的效率與體驗。
但是,現有面向車輛駕駛培訓的虛擬現實系統存在較為明顯的缺點。首先,學員在訓練時得不到教練員隨車指導,系統主要是通過傳感器和學員的操作信息來判斷學員的駕駛表現,但是這種判斷僅限于是否符合駕駛考試規則,并不能準確反映學員的真實駕駛水平,缺乏有效的訓練指導功能。其次,系統的訓練內容是針對駕駛考試進行設置的,功能單一,不能根據學員的表現來制定個性化的訓練方案,訓練效果達不到預期。
表情識別是實現人機交互的有效手段,人與人之間交流,有55 %的信息是通過表情來傳遞。面對復雜多變的虛擬場景,情緒會嚴重影響學員的認知行為,通過實時檢測并準確識別出學員的表情變化,可以掌握學員在培訓過程中的情緒狀態,對提升訓練效率以及促進學員個性化培訓發展顯得尤為重要。因此,可以把表情識別算法嵌入虛擬現實駕駛培訓系統來解決這個問題。
傳統的表情識別方法,如局部二值模式、Gobar特征、定向梯度直方圖、非負矩陣分解和尺度不變特征變換等,在一定程度上可能會丟失原有的表情特征,難以提取到深層次的本質特征。隨著深度學習的發展,卷積神經網絡(convolutional neural network,CNN)被廣泛應用到表情識別領域[1,2],AlexNet,VGGNet,GoogleNet和ResNet等神經網絡模型的出現,極大促進了表情識別的進展。
神經網絡對數據量的要求高,訓練時需要大量數據。如果數據量不足,容易使網絡訓練過擬合,導致訓練的模型對新數據的表現較差。而圖像底層元素具有相似性,遷移學習可以將標注數據集的訓練結果,應用到一個全新的領域數據上,從而改善過擬合[3]。
此外,為獲得更好的識別精度,需要具有更寬、更深或更高的圖像分辨率,導致模型參數增多,訓練時間增長。在此背景下,研究者提出了各種緊湊型CNN,以平衡模型精度與計算成本。EfficientNet[4]網絡采用復合系數的縮放方法,來平衡網絡的深度、寬度和圖像分辨率,可大幅減少模型參數量,實現模型輕量化。
本文針對智能駕培系統的應用,提出一種改進型的EfficientNet(modified-EfficicentNet,M-EfficientNet)構建人臉表情圖像的自動識別模型,同時為避免圖像樣本過少帶來的模型過擬合問題,采用遷移學習及數據增強的方法來提高模型的準確率,以更好地滿足實際檢測的需要。
1 智能駕培系統的總體設計
系統(圖1)先通過圖像采集模塊標出人臉位置,將含有表情特征的圖片集提取出來。然后將經過預處理的圖像通過深度學習網絡模型進行表情分類,評估學員狀態,并以此為依據智能切換虛擬現實場景,有針對性地調整訓練方案。同時,對可能涉及負面情緒影響的駕駛狀況進行標記,方便教練員查看、及時介入。
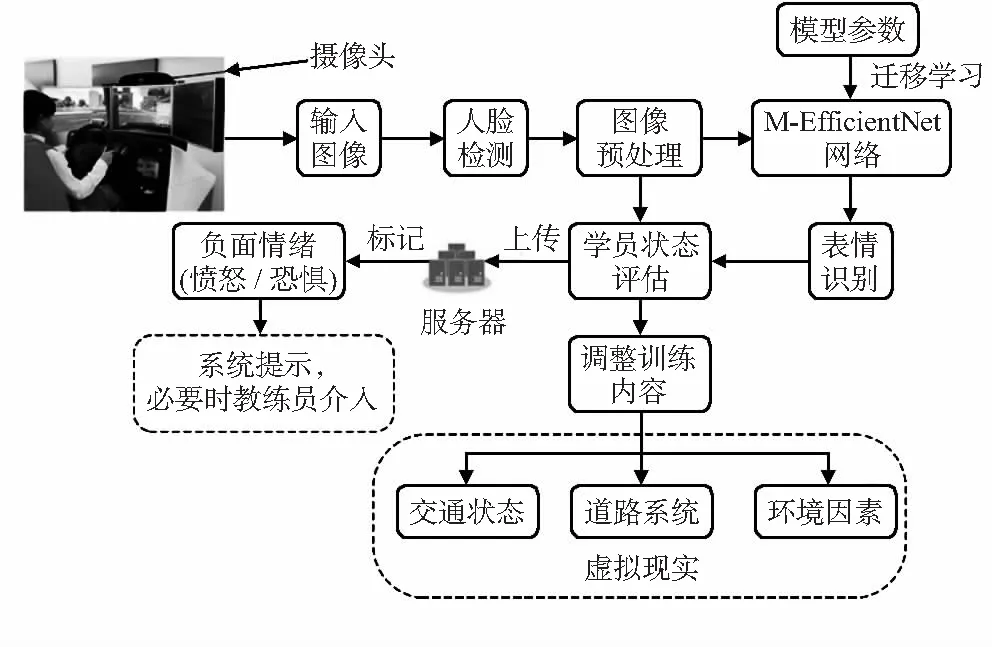
圖1 系統框架設計
2 網絡設計方法
2.1 網絡結構的設計
一個簡單卷積神經網絡,可以定義如式(1)
(1)
式中Fi為i層的卷積運算,Li為Fi在第i階段重復Li次,(Hi,Wi,Ci)為第i層輸入的維度。
本文的EfficientNet網絡結構以MnasNet[5]為基礎,使用AutoML[6]方法進行搜索,得出使所有卷積層可以按相同比例拓展的系數。相關數學表達式如式(2)
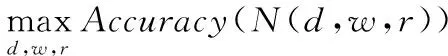
(2)
式中d,w和r分別為網絡深度、寬度和分辨率。Fi,Li,Hi,Wi,Ci分別為基線網絡預定義的參數。而搜索出來的相關系數調整如式(3)
d=αΦ,w=βΦ,r=γΦ
s.t.α·β2·γ2≈2
α≥1,β≥1,γ≥1
(3)
式中α,β,γ為使用網格搜索出來的常量,代表調整網格的深度、寬度和分辨率;Φ為控制模型擴增的自定義的相關系數。
EfficientNet使用了MobileNet V2[7]中的MBConv層作為模型的主干網絡,同時使用SENet[8]中的Squeeze和Excitation方法進行優化。本文對EfficientNet-B0網絡結構進行了改進,獲得的M-EfficientNet如表1所示。
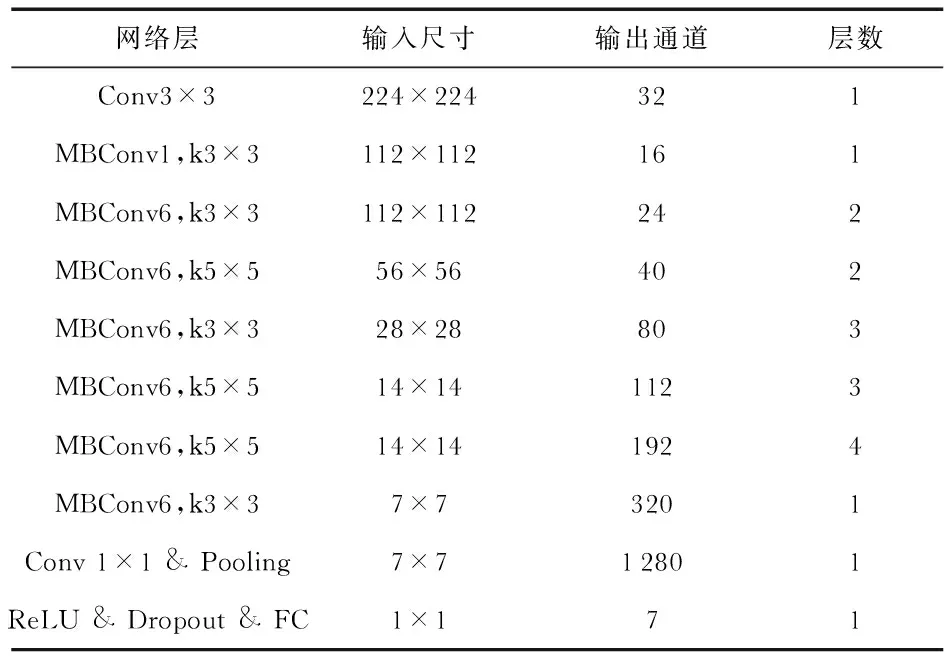
表1 M-EfficientNet網絡結構
ReLU的定義式如(4)
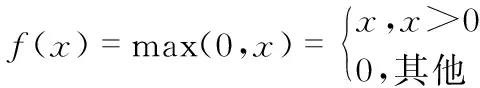
(4)
改進后的網絡結構由輸入層、1個3×3卷積層、7個卷積核為3×3的MBConv層、9個卷積核為5×5的MBConv層、1個1×1卷積層、1個池化層、1個ReLU激活層、1個Dropout層和1個全連接層組成。
本文沿用EfficientNet-B0網絡結構,保留了其原有優勢,同時為了增大網絡的稀疏性加入ReLU激活函數,使提取的特征更具代表性,再加入Dropout函數防止網絡陷入過擬合的狀態。
2.2 損失函數
本文使用交叉熵損失函數來計算網絡輸出的損失。交叉熵能夠衡量同一個隨機變量中的兩個不同概率分布的差異程度,在機器學習中表示為真實概率分布與預測概率分布之間的差異,如式(5)
(5)
式中p(xi)為樣本的真實分布概率,q(xi)為預測樣本的分布概率。
2.3 優化器
本文在模型訓練過程中使用Adam優化器動態調整學習率。Adam是一種對隨機目標函數執行一階梯度優化的算法,適合處理含有大量參數的問題,在訓練過程中可以自動調整參數。參數的更新公式如式(6)
(6)
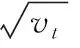
3 實驗與結果分析
實驗硬件環境為:Ubuntu 16.04系統,NVIDIA GeForce GTX1080Ti GPU,16 G運行內存;軟件環境為:Python 3.7.4,Pytorch 1.4.0深度學習框架。
使用的數據集有Fer2013和CK+數據集。針對兩個數據集中數據樣本不平衡、數據分類不明確等問題,首先對數據進行圖像歸一化處理,然后對樣本不平衡的類別進行隨機旋轉±5°、水平翻轉等操作擴充訓練數據集。
首先,在ImageNet數據集中預訓練M-EfficientNet,初始學習率為0.01,batchsize為256,得到預訓練模型。然后,凍結低層網絡結構,只訓練全連接層進行微調,學習率為0.000 5,batchsize為64,迭代次數100。
3.1 Fer2013實驗結果
Fer2013數據集是由35 887張含有憤怒、厭惡、恐懼、高興、悲傷、驚訝和中性7種表情圖片組成,如圖2所示。數據集一共分為了三個部分:訓練集28 709張、公共測試集3 589張和私有測試集3 589張。

圖2 Fer2013數據集7類表情樣本示例
本文實驗與主流網絡ResNet—18進行對比,實驗記錄了在使用不同網絡的訓練過程中模型準確率的變化情況。圖3為EfficientNet網絡與ResNet網絡識別準確率隨著迭代次數的變化情況。
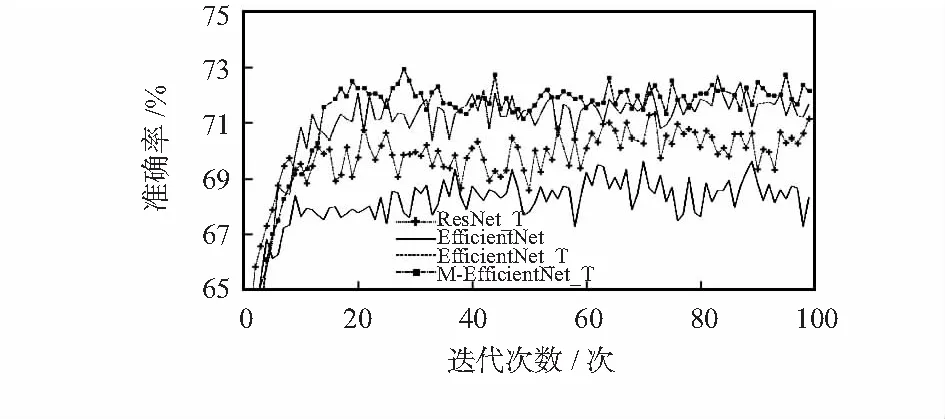
圖3 EfficientNet網絡模型準確率變化對比
ResNet_T,EfficientNet_T,M-EfficientNet_T曲線分別為經過遷移學習各網絡準確率變化情況,EfficientNet曲線為未經過遷移學習識別準確率變化情況。從圖3中可以得出,網絡模型的識別準確率隨著迭代次數的增多而趨于穩定狀態,未經過遷移學習的EfficientNet準確率達到穩定狀態時最低的,經過遷移學習的ResNet的識別準確率比EfficientNet略高,經過遷移學習的M-EfficientNet識別準確率最高。
實驗中,M-EfficientNet_T識別的最高準確率為72.6 %。另外,EfficientNet和M-EfficientNet的網絡參數大小均為15.5 MB,而ResNet為42.7 MB,減少了64 %。本文提出的M-EfficientNet算法不僅在識別準確率上高于ResNet,并且在參數量上也大大減少;比起EfficientNet雖然參數大小一樣,但識別的準確率提高了,在一定程度上說明了遷移學習在表情識別應用和EfficientNet網絡改進的有效性。
混淆矩陣[9]是機器學習中總結分類模型預測結果的情形分析表,為了比較本文所提出的M-EfficientNet方法與其他方法的不同點,編制了在Fer2013數據集上驗證的混淆矩陣,如表2所示。
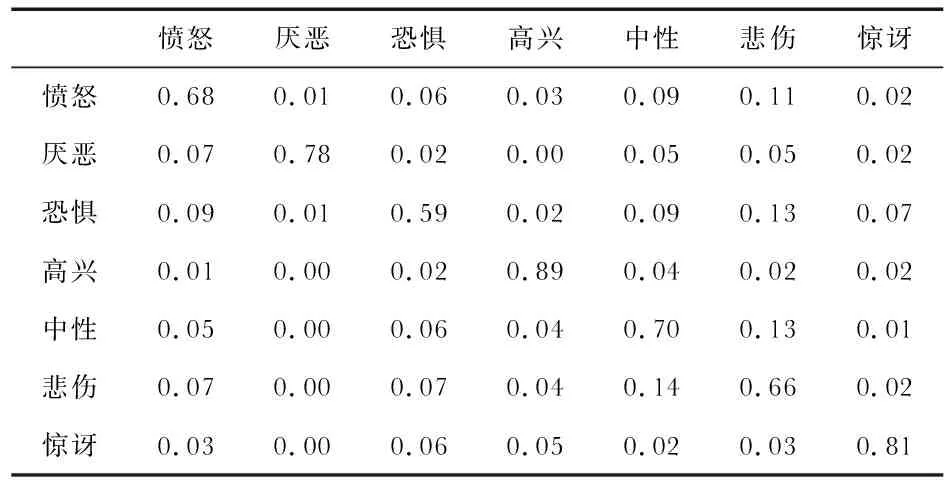
表2 M-EfficientNet在Fer2013數據集驗證的混淆矩陣
由混淆矩陣可以看出,本文的識別模型對于高興類表情識別的準確率是最高的,達到89 %,對于驚訝類表情和厭惡類的識別準確率分別為81 %和78 %,而憤怒類、恐懼類、悲傷類和中性類的表情識別準確率都在總體識別正確率72 %之下。
經分析,高興類的識別率相對較高的原因是由于訓練樣本中,類別的數量比較多,并且高興類的高層特征可能在網絡中得到好的反饋。而驚訝類和厭惡類中的訓練樣本雖然數量也足夠多,但是相對于高興類的高層特征沒那么容易提取,驚訝類易混淆的類別是恐懼類,厭惡類易混淆的類別是生氣類。其他低于總體識別率的四個類別,容易混淆的類都有多個,是因為訓練樣本中這幾個類別的數量相對其他類較少,類內之間特別分界不明顯。
模型總體的識別率在Fer2013數據集中各類表情都不算太高,主要原因是因為數據集的來源主要是通過網絡爬取的,數據集中且存在大量未經過清洗的圖片,有包括漫畫人臉、非人臉、側臉和類內分類不正確等情況。
為了驗證本文識別算法在Fer2013數據集上與其他算法的不同點,還與其他算法進行了準確率的對比,如表3所示。目前在Fer2013數據集上的人工識別準確率為65 %±5 %,本文算法的準確率為72.6 %,已達到人工識別的效果。與其他學者所研究的算法[10~13]相比,本文算法在準確率上也有一定的優勢。

表3 M-EfficientNet與其他方法在Fer2013準確率上的對比
3.2 CK+結果
CK+數據集是由123名不同人的面部表情圖像組成。實驗為了對比與其他方法的不同點,只取憤怒、厭惡、恐懼、高興、悲傷、驚訝和中性七類表情進行實驗,實驗步驟如Fer2013步驟一樣。CK+數據集七種表情如圖4所示。

圖4 CK+數據集7類表情樣本示例
本文算法在CK+數據集上驗證的混淆矩陣如表4所示。
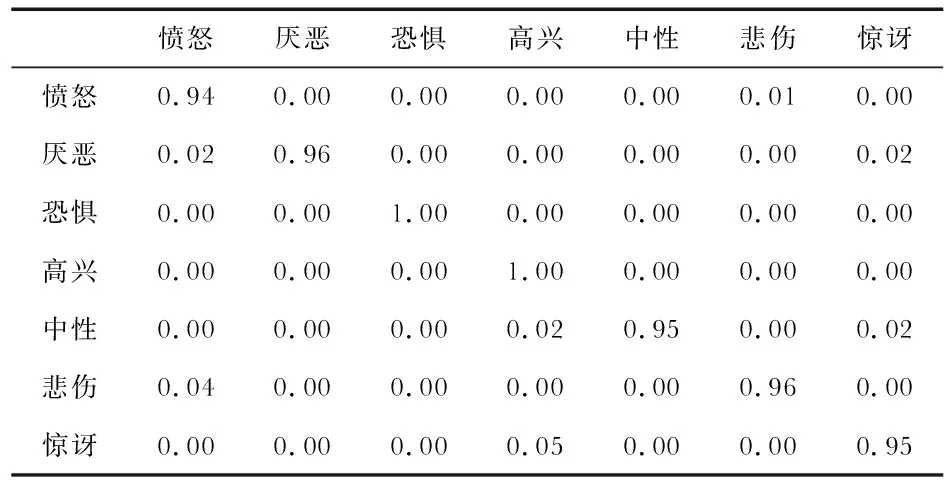
表4 M-EfficientNet在CK+數據集上驗證的混淆矩陣
在CK+表情識別的混淆矩陣中,恐懼類和高興類的識別準確率達到100 %,其他類別的識別率基本上都在95 %左右。與Fer2013數據集的識別效果對比,在CK+數據集的識別準確率高很多,主要原因是CK+數據集獲取的訓練樣本更嚴格,相對Fer2013數據集雜質偏多以及類內誤分較多的情況,在CK+數據集上獲得較高的識別準確率是有據可循的。
本文算法在CK+數據集的識別率與其他方法[14~16]的識別準確率對比情況如表5所示。在CK+的準確率與其他的算法的比較中,本文算法的準確率達到了96.7 %,實驗識別效果較目前算法有優勢。

表5 M-EfficientNet與其他方法在CK+準確率上的對比
4 結束語
本文提出了一種基于改進型的Efficienet表情識別方法,通過在網絡層加入ReLu激活函數,使網絡模型提取更具代表性的網絡特征,同時加入Dropout使網絡不容易陷入過擬合狀態。加入幾何歸一化和灰度歸一化和數據增強平衡分類中內類數據不平衡情況,使用M-EfficientNet通過遷移學習得到圖像底層相似特征,再對預訓練的網絡進行提取表情圖像的高級特征,從而提高表情識別準確率。在Fer2013和CK+兩個數據集上分別取得72.6 %和96.7 %的結果,并且識別模型的參數大小比主流的ResNet—18減小了64 %。
基于本文研究的表情識別算法可準確識別學員的面部表情,且參數量較小,易于實現輕量化,方便后續在智能駕培系統端部署,從而實現智能培訓。在未來工作中,將在保證模型準確率的同時繼續改進網絡結構,增大模型的泛化能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
