多尺度通道注意力機制的小樣本圖像分類算法
2022-02-28 06:49:24靳華中李文萱李晴晴
湖北工業大學學報 2022年1期
王 奇,靳華中,李文萱,李晴晴
(湖北工業大學計算機學院,湖北 武漢 430068)
隨著大數據時代的到來,基于數據驅動的深度學習模型在圖像分類任務中取得了巨大成功[1]。一般來說,深度學習的成功可歸因于三個關鍵因素:充足的計算資源、復雜的神經網絡和大規模數據集。然而,許多現實的應用場景中,例如在醫學、軍事和金融領域,由于涉及隱私安全問題和較高的人力成本等因素,無法得到足夠多的訓練樣本。訓練模型時沒有足夠多的有監督樣本,容易產生過擬合現象,即模型在訓練樣本上表現良好,在測試集上的泛化效果不佳[2]。小樣本學習[3]使用遠小于深度學習所需要的數據樣本量,達到接近甚至超越大數據深度學習的效果。為了讓小樣本學習進一步提高模型泛化性能,國內外學者對其進行大量的研究。阿里巴巴智能服務事業部團隊[4]根據內部實現機制將小樣本學習方法分為基于模型、基于度量和基于優化三類。李新葉等人[5]和趙凱琳等人[6]從跨任務學習知識的角度將基于元學習和基于遷移學習的方法也歸為小樣本學習。祝鈞桃等人[7]根據小樣本分類中所采用的技術將小樣本學習的解決方案分為數據增強、度量學習、外部記憶、參數優化四個策略。由于真實世界中樣本采集困難或成本昂貴,小樣本學習已成為當前機器學習的研究熱點。
從宏觀角度來看,研究小樣本學習的理論和實踐意義主要來自三個方面[8]。1)小樣本學習方法不依賴大規模的訓練樣本,從而避免了某些特定場景中數據準備的高昂成本;2)小樣本學習可以縮小人工智能和人類智能之間的差距,是開發通用人工智能的必要研究;3)小樣本學習可以為一個新出現的任務實現低成本和快速的模型部署,為新任務闡明早期的規律。
在圖像分類中,依據不同的建模方式,小樣本圖像分類算法分為卷積神經網絡模型和圖神經網絡模型兩大類[9]。其中基于卷積神經網絡模型的算法包括四種學習范式:遷移學習[10]、元學習[11]、對偶學習[12]和貝葉斯學習[13]。元學習包括基于度量的元學習[14]、基于模型的元學習、基于優化的元學習。基于度量的元學習方法依據不同的度量方式對成對的樣本進行相似度度量,根據不同的度量方式,可被分為暹羅網絡[15]、匹配網絡[16]、原型網絡[17]以及關系網絡[18]。在基于度量的元學習方法中,暹羅網絡、匹配網絡和原型網絡的分類器采用手動設計的方法,使用歐氏距離或者余弦距離,關系網絡改進了距離的度量方式,使用神經網絡作為分類器來學習特征之間度量方式。
基于度量的元學習首先專注學習一個可嵌入的模塊,并預先定義固定的度量方式,在此基礎上關系網絡用來學習一個可轉移的深度度量模塊以提高圖像的分類精度。2018年,sung等人[18]首次提出關系網絡。從深度學習出發,關系網絡延續基于度量的元學習的基本原理,通過設計模型學習“如何度量”樣本間的距離。相比于固定距離的度量方式,關系網絡通過學習一種非線性的度量方式取得了更好的分類效果。但是關系網絡中的特征提取模塊忽略了很多重要的樣本信息,對樣本的關鍵信息提取不充分,導致仍然存在識別準確率低的問題。通過將圖像裁剪與關系網絡相結合,龐振全等人[19]構造的網絡取得了較好的圖像分類精度,但裁剪操作會造成樣本有效信息的損失。金璐等人[20]在關系網絡中引入inception模塊,融合多尺度特征后對紅外空中目標分類取得了良好效果。王年等人[21]通過引入自注意力機制與感受野模塊提升了網絡的特征表達能力和度量能力。
注意力機制[22]能夠使網絡模型更加關注重要信息而減少與目標任務無關的信息。2018年,胡杰等人提出SE-Net[23],將它引入CNN中取得良好的圖像分類效果。此后,研究者提出ECA-Net[24]、SK-Net[25]、ResNeSt[26]、CBAM[27]等注意力機制,分別從通道域與空間域兩個方面增強了注意力機制的性能。注意力機制大幅度提升模型訓練的速度與任務效果,同時其即插即用的特性極大方便了模型的設計。小樣本學習的訓練樣本較少,能提取到的信息相對有限,而使用注意力機制可以在有限的訓練樣本下提取到更多的有效信息。
基于上述分析,在關系網絡的基礎中本文引入多尺度空間與通道的注意力機制,使關系網絡的嵌入模塊能夠學習更豐富的多尺度特征,同時自適應地對多維度的通道注意力權重進行特征重標定,提升了模型對小樣本的分類能力。在MiniImageNet[15]與Omniglot[28]數據集上進行實驗,實驗表明本文方法的分類精度比原方法明顯提高。
1 相關技術原理
1.1 小樣本問題描述
受人類智能的啟發,研究小樣本學習的目的是希望模型(算法)能夠像人腦一樣,在學習大量的基類后,僅需要少量樣本就能快速得到新類,獲取新的知識,做到舉一反三。
小樣本圖像分類流程(圖1)包括數據集處理,特征提取網絡和分類器三個部分。

圖 1 小樣本圖像分類流程
小樣本學習的基本模型定義為r=g(f(x|θ)|ω),它由特征提取網絡f(·|θ)和分類器g(·|ω)組成,θ和ω分別表示f和g的參數,x表示待識別的圖像,f(x|θ)表示對圖像x提取的特征,r表示對圖像x識別的結果。
為了提取圖像的有效特征,分類時需要建立特征提取模型。對于模型,提取的圖像特征應該盡可能有效地描述圖像,使分類器能夠更好地利用它們。可見,提高圖像特征描述和提取能力,將能夠獲得更好的分類結果。注意力機制、記憶力機制等是常見的圖像特征有效提取的技術手段。
分類器通過對特征進行相似度度量,來獲取對象的不同類別。小樣本圖像分類中所使用的分類器大多數是在卷積神經網絡的最后一層構建帶有Softmax的全連接層,或者對提取的圖像特征應用K近鄰算法等。本文分類器采用的是前者。
1.2 關系網絡
關系網絡是一個靈活、通用、端到端的小樣本學習框架,通過計算支持集和查詢集樣本圖像的關系得分,對新類別的樣本圖像進行分類。關系網絡結構見圖2,它主要由嵌入模塊fφ和關系模塊gφ組成。
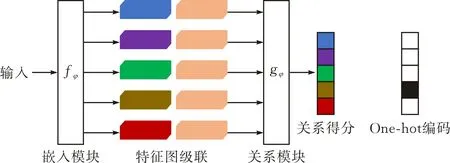
圖 2 關系網絡結構
嵌入模塊用于提取圖像樣本的抽象特征,生成支持集和查詢集圖像的特征表示,如圖3中fφ所示,由4個卷積塊和2個最大池化層組成,每個卷積塊包含一個卷積核大小為3×3,通道數為64的卷積層,一個BatchNorm層,一個ReLU層。嵌入模塊能提取出樣本的抽象特征,為模型提供可以用于對比的特征信息。支持集與查詢集圖片分別輸入嵌入模塊,首先提取圖像特征,接著將特征圖級聯后送入關系模塊。

圖 3 嵌入模塊與關系模塊
如圖3中gφ所示,關系模塊由2個卷積塊,2個最大池化層,2個全連接層組成。該模塊最終產生0-1范圍內的標量,該標量表示支持集樣本和測試集樣本之間的相似性,為關系得分。計算該得分的公式如下:
ri,j=gφ(C(fφ(xi),fφ(xj))),i=1,2,…,S
(1)
其中,ri,j為相似度得分即關系得分,C(·)為特征級聯。
訓練中的損失函數使用均方誤差MSE,如:
(2)
2 基于多尺度通道注意力機制的小樣本圖像分類模型
2.1 金字塔切分注意力模塊
金字塔切分注意力模塊(PSA)是一種多尺度空間與通道注意力機制[29]。金字塔切分注意力機制框架的結構見圖4。

圖 4 金字塔切分注意力機制框架
PSA模塊包括以下四個部分:
1)使用分割和連接模塊(SPC module)將輸入轉換為通道方向上的多尺度特征圖。其中,分割和連接模塊的實現步驟如下,將輸入的特征圖X分割成S個部分,每個部分用[X0,X1,…,XS-1]和通道維度C′表示,C′=C/S。引入群卷積的方法對這些部分分別用多尺度并行處理。
SPC設計了新的準則來處理多尺度內核與組大小的關系:
(3)
其中,G是組大小,K是內核大小。此外,當內核大小K=3時,G=1。經過SPC模塊的多尺度特征圖的生成函數如下:
Fi=conv(ki×ki,Gi)(Xi),i=1,2,…,S-1
(4)
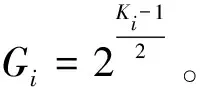
F=cat([F0,F1,…,FS-1])
(5)
2)使用SE權重模塊提取不同比例的特征圖的注意力權重,獲得通道方向的注意力向量。
Zi=SEWeight(Fi),i=1,2,…,S-1
(6)
Z=Z0⊕Z1⊕…⊕ZS-1
(7)
其中,⊕是級聯運算符,Zi是Fi的注意力權重,Z是多尺度注意力權重向量。
SE模塊是通道注意力機制中的經典模型,包括Squeeze操作與Excitation操作。SE模塊結構見圖5。
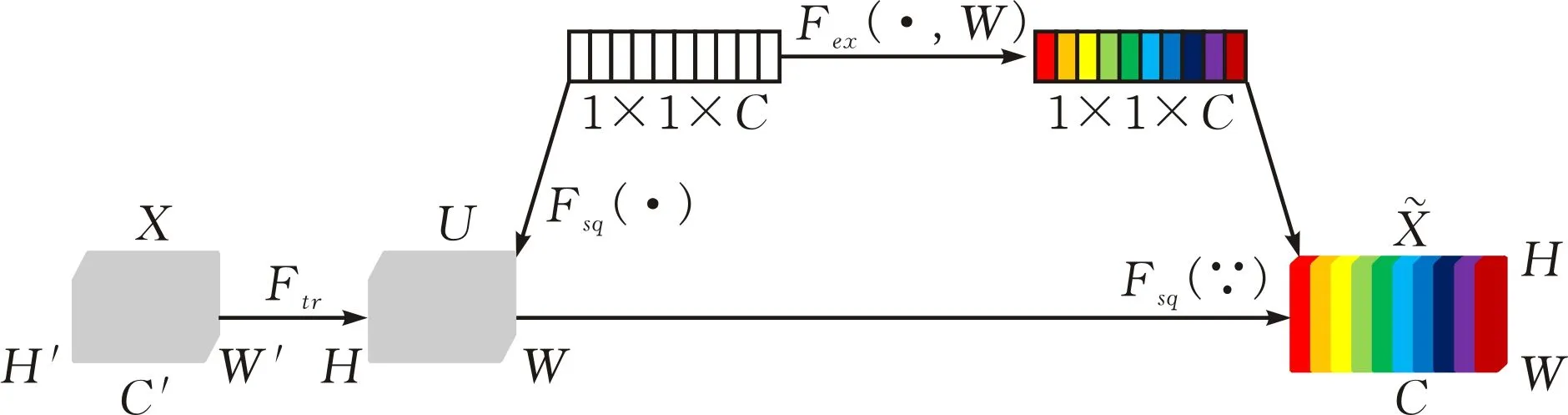
圖 5 SE模塊結構
對于任何給定的變換,將輸入X映射到特征映射U,其中U∈RH×W×C。特征U首先通過Squeeze操作在空間維度上被壓縮為1×1×C向量,即全局平均池化。Squeeze操作的公式如下:
(8)
Squeeze操作之后是Excitation操作,該操作通過兩個全連接層組成一個Bottleneck結構去建模通道間的相關性,為每個通道生成一個權重值,得到各個通道權重的集合。Excitation操作的公式如下:
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
(9)
式中,δ為ReLU激活函數,W1、W2分別為兩個全連接層的參數。
最后通過Scale操作將得到的歸一化權重加權到每個通道的特征上,以生成SE模塊的輸出。Scale操作的公式如下:
(10)
3)使用Softmax重新校準通道方向的注意力向量,得到多尺度通道重新校準的注意力權重。
(11)
其中,Softmax用于獲得多尺度通道的重新校準的權重,其包含空間上的所有位置信息和通道中的注意力權重。
att=att0⊕att1⊕…⊕attS-1
(12)
其中,att表示注意力級聯后的多尺度通道權重。
4)將得到的多尺度通道的權重加權到對應的特征圖Fi中:
Yi=Fi⊙atti,i=1,2,…,S-1
(13)
其中,⊙表示通道乘法。
最后得到一個多尺度特征信息更豐富的細化特征圖作為輸出。
out=cat([Y0,Y1,…,Ys-1])
(14)
2.2 基于多尺度通道注意力機制的小樣本圖像分類算法
本文提出的基于多尺度通道注意力機制的小樣本圖像分類網絡模型見圖6。
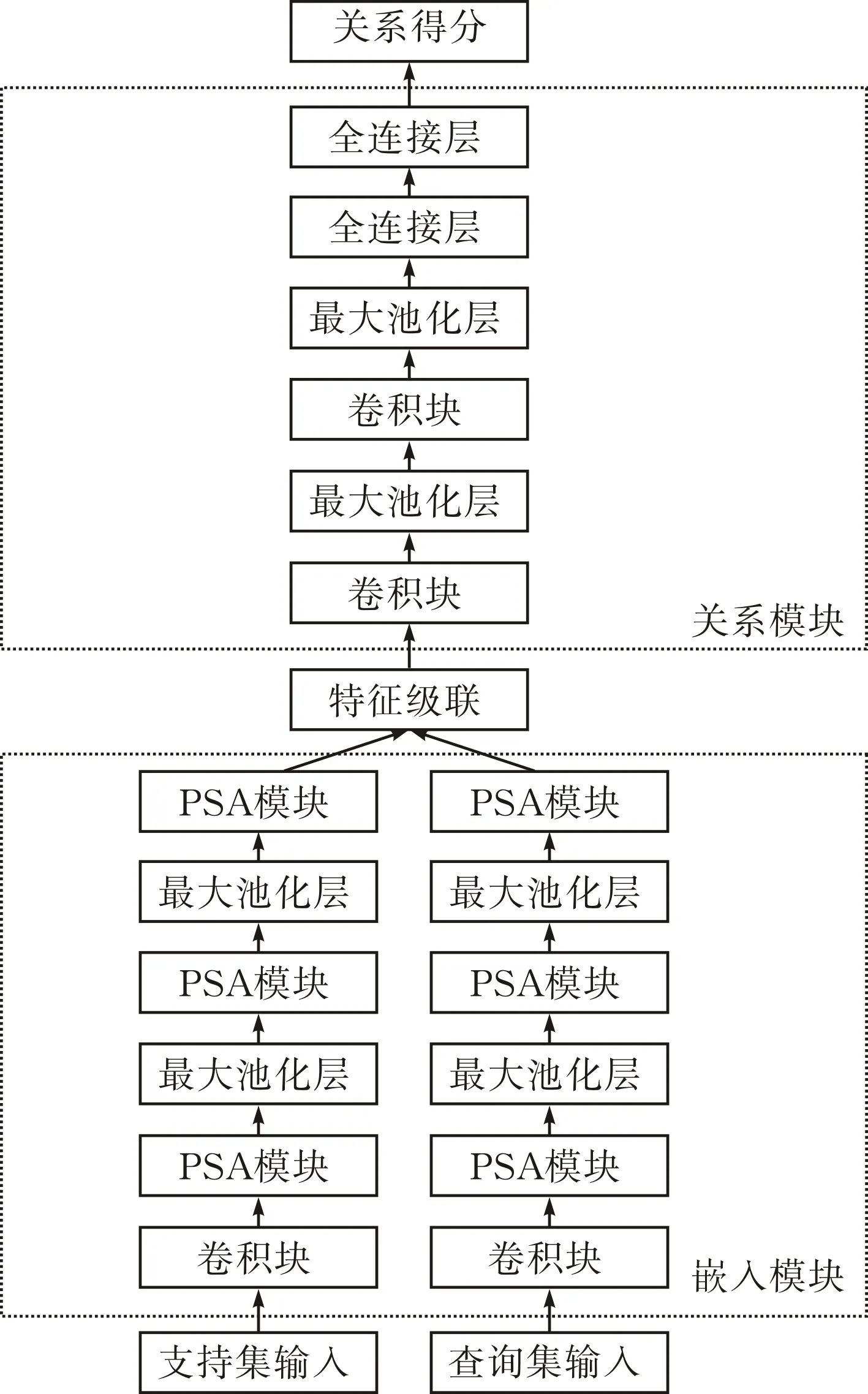
圖 6 小樣本圖像分類網絡模型
嵌入模塊由一層卷積塊、三層PSA模塊以及兩層最大池化層組成;關系模塊由兩層卷積塊、兩層最大池化層,兩層全連接層組成。將得到的支持集圖像特征與查詢集圖像特征級聯并輸入關系模型。
PSA模塊網絡結構是一個金字塔切分注意力模塊[29],其網絡結構如圖7所示。它將輸入的特征圖分為四個尺度,用大小不同的卷積核并行處理,其中,K0=3,K1=5,K2=7,K3=9。圖中,SE權重模塊得到通道注意力先計算不同通道特征圖的權重,再通過Softmax層對權重校準,最后得到通道權值不同的特征圖。
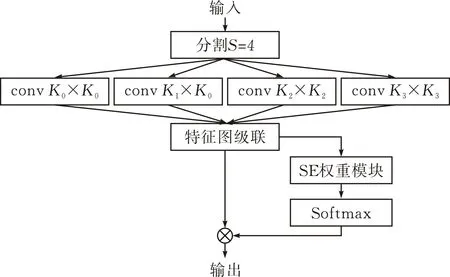
圖 7 PSA模塊網絡結構
本文使用PSA模塊替換嵌入模塊中后三層卷積塊,從而得到改進后的嵌入模塊(圖7)。
3 實驗
3.1 數據集
MiniImageNet數據集是元學習和小樣本領域的基準數據集,由google DeepMind團隊Oriol Vinyals等人在ImageNet的基礎上提取并提出,數據集復雜,包含100類共60 000張彩色圖片,其中每類有600個樣本,每張圖片的規格為84×84,適合進行原型設計和實驗研究(圖8)。

圖 8 MiniImageNet數據集圖像示例
Omniglot數據集包含來自50個不同字母的1623個不同手寫字符。每個字符由20個不同的人通過亞馬遜的Mechanical Turk在線繪制的。對現有數據旋轉90°,180°和270°來擴充數據集,1200個原始類加上來進行訓練,剩余的423個類來進行測試。輸入圖像都調整到28×28(圖9)。

圖 9 Omniglot數據集圖像示例
3.2 實驗設置
遵循大多數現有的小樣本學習工作采用的標準設置,對于MiniImagenet數據集,使用5-way 1-shot和5-way 5-shot兩種模式進行訓練,在訓練階段隨機采樣并構建500 000個episode,在每個訓練的episode中,5-way 1-shot每類包含15個查詢圖像,5-way 5-shot每類包含10個查詢圖像。即,在一個episode中5-way 1-shot有15×5+1×5=80個圖像,5-way 5-shot有10×5+5×5=75個圖像,實驗設置見表1。對于Omniglot數據集,20-way 1-shot和20-way 5-shot兩種模式進行訓練,在訓練階段隨機采樣并構建1 000 000個episode,在每個訓練的episode中,20-way 1-shot每類包含10個查詢圖像,20-way 5-shot每類包含5個查詢圖像。即,在一個episode中20-way 1-shot有10×20+1×20=220個圖像,20-way 5-shot有5×20+5×20=200個圖像,實驗設置見表2。
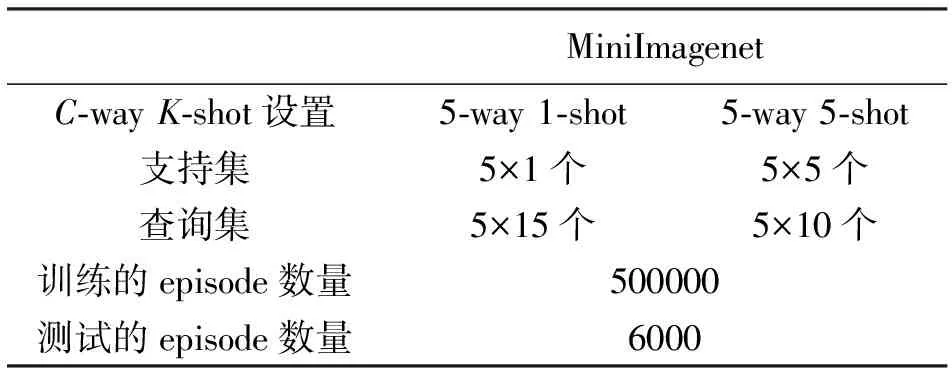
表1 MiniImagenet實驗設置

表2 Omniglot實驗設置
3.3 實驗結果
在MiniImagenet和Omniglot數據集上的實驗結果見表3和表4。

表3 MiniImagenet數據集上識別率
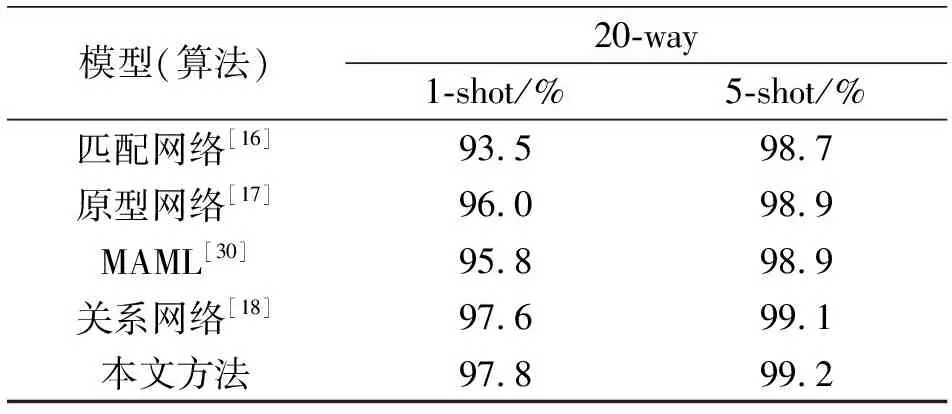
表4 Omniglot數據集上識別率
從實驗數據可以看出,本文改進后的網絡在MiniImageNet數據集上5-way 1-shot與5-way 5-shot的分類精度分別提升到了51.22%與65.86%,比原網絡分別提高了0.78%和0.54%;在Omniglot數據集上20-way 1-shot與20-way 5-shot的分類精度,比原網絡提高了0.2%和0.1%。
4 結論
本文在關系網絡的嵌入模塊中引入多尺度空間與通道注意力機制PSA模塊,提出了一種基于多尺度通道注意力機制的小樣本圖像分類方法,用不同尺度的卷積核對圖像進行特征提取,豐富了特征空間。實驗表明,在標準的MiniImageNet與Omniglot數據集中,本文提出的方法提升了關系網絡中嵌入模塊的特征提取效率,提高了小樣本圖像的分類精度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
