基于改進多嵌入空間的實時語義數據流推理
2022-02-24 05:06:18姚光濤顧進廣
計算機工程 2022年2期
高 峰,姚光濤,顧進廣
(1.武漢科技大學 計算機科學與技術學院,武漢 430065;2.武漢科技大學 大數據科學與工程研究院,武漢 430065;3.智能信息處理與實時工業系統湖北省重點實驗室,武漢 430065;4.富媒體數字出版內容組織與知識服務重點實驗室,武漢 430065)
0 概述
近年來,物聯網和移動互聯網取得快速發展,其中產生了海量的傳感器數據以及其他類型的數據,這些數據具有高速、實時、動態的特征,對它們進行分析并推理出其中隱含的知識具有重要的理論和現實意義。將實時數據與知識圖譜技術相結合,并以RDF(Resource Description Framework)三元組加時間標注的方式進行表示,可以形成實時語義數據流數據,基于實時語義數據流的RDF 流推理逐漸引起研究人員的關注。
目前的語義數據流推理引擎包括集中式和分布式兩大類:集中式流推理以CSPARQL(Continuous SPARQL)[1]引擎為代 表,使 用Esper[2]、Jena[3]和Sesame[4]進行窗口運算以及處理查詢;分布式流推理屬于新興領域,目前尚處于研究階段,主要包括CQELS[5]的分布式版本、基于Storm 集群的Katts[6]、基于Spark 框架的Strider[7]等。現有的語義數據流引擎雖然能夠在一定程度上完成語義推理,但仍存在一些問題,如缺乏對海量數據的適應性、推理性能不佳、推理時延較大等,難以適應當前海量數據場景下人們對推理查詢實時性的需求。
隨著知識圖譜嵌入表示學習的興起,可以對知識圖譜中的實體和關系進行向量表示,將實體相互之間復雜的語義關系轉換為向量計算,這種簡單的向量計算的方式對提升知識圖譜推理效率具有重要意義。然而,現有的知識表示學習模型存在一定不足,如只關注靜態圖譜嵌入而忽略知識圖譜的動態更新,或缺乏推理能力等,導致其無法直接應用于實時動態語義數據流推理任務。
為了使得知識表示學習模型能夠適應知識圖譜的在線更新,本文建立一種PUKALE(Parallel Universe KALE)模型。針對傳遞閉包等復雜推理場景,在聯合嵌入模型KALE 的基礎上引入多嵌入空間,提出能夠適應復雜推理的嵌入空間生成算法。為了在進行增量更新訓練時更合理地選擇嵌入空間,提出基于實體關系映射的嵌入空間選擇算法。將PUKALE 模型嵌入至語義數據流推理引擎CSPARQL-engine 中,以實現對實時語義數據流的推理查詢。
1 相關工作
目前,語義數據流處理平臺大多基于SPARQL[8],首先讀取所有的RDF 數據并構建所讀取數據的完整索引,然后評估SPARQL 的推理查詢性能。Streaming SPARQL[9]流處理平臺基于SPARQL,設計一個擴展用于處理數據流上的窗口查詢,允許在數據流上定義基于時間和計數的窗口,但其沒有考慮關于數據結構選擇和連續執行計算狀態共享的性能問題。CSPARQL 是SPARQL 的一個擴展,其特點是支持連續查詢,即在RDF 數據流上注冊然后連續執行的查詢。CQELS 支持流式數據以及靜態RDF 數據,此外,CQELS 是一個本地自適應的查詢處理器,在本地實現所需的查詢運算符,能夠提供一個靈活的查詢執行框架,在查詢執行的過程中,其根據一些啟發式規則不斷地對操作符進行重新排序,提高了查詢執行的延遲和復雜性。EP-SPARQL[10]是一種描述事件處理和流推理的語言,可以翻譯成基于Prolog的復雜事件處理框架ETALIS[11],它可以將基于RDF的數據轉化為邏輯事實,然后將EP-SPARQL 查詢轉化為Prolog 邏輯規則,但是其轉化過程耗時,性能不高。StreamRule[12]結 合RSP 引擎和Clingo[13]用于流的過濾以及聚合,提升了知識密集場景下的復雜推理能力。結合了Spark 和Flink 分布式平臺的實時語義數據流推理平臺BigSR[14]能利用分布式處理來有效降低推理延時,但其對硬件資源要求較高。
BORDES 等[15]提出一種 知識表示 學習模型TransE,其將三元組中實體之間的關系嵌入到低維向量空間中進行計算,由于參數少、易于訓練、可擴展性強,使得知識表示在知識圖譜領域受到廣泛關注。隨后,針對TransE 出現了一些擴展性模型,如TransH[16]、TransR[17]等,盡管這些模型在TransE 模型的基礎上做了進一步擴展,但是它們都沒有利用邏輯規則。KALE[18]模型在TransE 模型的基礎上引入邏輯規則,建立三元組與邏輯規則的統一框架,使得模型具備一定的推理能力,可以推理出三元組之間隱藏的知識。然而,KALE 模型缺乏對流式增量數據的更新能力,當流式數據中出現新的實體或關系時,KALE 模型需要在整個數據集上重新訓練,在數據規模較大、更新較頻繁的場景下,時間消耗難以被人們接受。TAY 等[19]在TransE 的基礎上進行改進,提出puTransE 模型,其通過劃分子嵌入空間的方式使得模型具備處理動態知識圖譜的能力,然而,該模型不具備推理能力,不能直接應用于數據流推理任務。還有一些動態圖嵌入方法[20-22]支持在線學習圖節點嵌入,然而這些方法不能被用于動態知識圖譜嵌入,因為它們學習的是結構相近的節點的嵌入,而沒有考慮邊的語義信息。
2 PUKALE 模型
2.1 PUKALE 框架
圖1 所示為PUKALE 模型框架。模型在初始訓練時,會根據訓練集三元組的個數和嵌入空間三元組的限定值生成n個嵌入空間,模型在n個嵌入空間中分別訓練;當增量更新的三元組到達時,如果增量更新的三元組的實體和關系在已有的嵌入空間中,則對相應的嵌入空間重新訓練;若最后一個嵌入空間三元組個數沒有達到限定值,則將增量更新的三元組加入當前嵌入空間中重新訓練,否則,重新創建一個嵌入空間進行訓練。

圖1 PUKALE 模型框架Fig.1 PUKALE model framework
算法1 是PUKALE 模型算法的偽代碼表示:第1 行根據訓練集數據生成初始嵌入空間;第2 行讀取推理規則到模型中;第3 行~第19 行表示對每個嵌入空間分別進行訓練,包括隨機生成超參數、隨機初始化向量空間等。在訓練完成后,會保存每個嵌入空間的實體和關系矩陣。
算法1PUKALE 模型算法

2.2 嵌入空間生成策略
對于PUKALE 模型中嵌入空間的生成,本文實現并測試3 種嵌入空間的生成策略:第1 種策略是語義相關的生成方法;第2 種策略是結構上相關的方法;第3 種策略是上述兩者的結合。
1)第1 種語義相關策略在對一個嵌入空間劃分三元組時,具有相同關系的三元組更傾向于劃分到同一個嵌入空間,而具有不同關系的三元組更傾向于劃分到不同的嵌入空間。如圖2(a)虛線部分所示,假設(e3,r1,e4)是初始三元組,則(e1,r1,e2)和(e3,r1,e4)更傾向于劃分到同一嵌入空間中。
2)第2 種結構相關策略的思路是在創建一個嵌入空間時,首先隨機選擇一個三元組加入當前嵌入空間,然后以當前三元組的頭實體和尾實體為起點,選擇出度和入度方向的三元組加入當前嵌入空間,隨后繼續以新加入的三元組的頭實體和尾實體為起點,添加出度和入度方向的三元組,以此類推,直到添加的三元組個數達到嵌入空間的限定值。從新加入三元組的頂點出發繼續選擇出度和入度方向的三元組,一方面是為了適應復雜環境(如軍事態勢感知)中的傳遞閉包推理場景;另一方面,隨著時間的推進,圖譜中會頻繁進行三元組的添加、刪除等圖譜更新操作,為了適應這些更新,模型不僅要快速學習所更新實體以及關系的嵌入,還要考慮其對現有實體以及關系嵌入的影響。以圖2(b)為例,假設在實體e1和實體e2之間添加一個關系r1,構成新的三元組(e1,r1,e2),則需要對和e1、e2有關的5 個三元組重新訓 練,它們分別 為(e1,r7,e5)、(e4,r8,e1)、(e1,r3,e3)、(e2,r2,e3)、(e1,r1,e2),而不需要在整個圖譜上重新進行訓練。對于超參數嵌入空間三元組限定值的設置,本文在[500,3 000]范圍內以步長500 遞增進行調優,嵌入空間限定值設置在1 500 個時模型效果較好,繼續增大該限定值,模型準確度并沒有明顯提升,而嵌入空間計算延遲會略有增加。結構相關策略選擇三元組的方式如圖2(b)所示,假設(e3,r1,e4)是初始三元組,則虛線部分是所選擇的三元組。
3)第3 種嵌入空間生成策略是第1 種策略和第2 種策略的結合,其生成嵌入空間的主要思路是:首先隨機選擇一個三元組,將其加入當前嵌入空間并記錄當前三元組的謂語關系;之后以當前三元組的頭尾實體為起點選擇出度和入度方向的三元組加入嵌入空間,與第2 種策略不同的是,其不是繼續以新的實體為起點添加三元組,而是重新隨機選擇一個語義相似的三元組加入嵌入空間,繼續重復前面的流程,直到三元組的個數達到嵌入空間三元組的限定值。在結構相關策略的基礎上引入語義相關策略的原因是,三元組的更新操作影響的不僅是以對應頂點出發的結構上相近的三元組,還有結構上雖然不相近但是關系相同的三元組,同樣以添加(e1,r1,e2)為例,關系嵌入r1的變化會影響圖譜上包含r1的其他三元組,如(e3,r1,e4)。第3 種策略可以兼顧2 種類型的三元組,與結構相關策略相比,該策略選擇的三元組更具多樣性,在嵌入空間訓練時可以學習到更多的信息。第3 種策略的三元組選擇方式如圖2(c)所示,假設(e3,r1,e4)是初始三元組,則虛線部分是所選擇的三元組。
第3 種嵌入空間生成算法描述如算法2 所示。此外,本文也嘗試puTransE 中的語義雙向隨機游走嵌入空間生成方式,該策略與策略3 的主要區別在于,隨機游走從頂點出發選擇三元組的路徑是隨機的,而策略3 會選擇出度和入度方向的所有三元組。puTransE 生成嵌入空間的方式如圖2(d)虛線部分所示,如果初始時三元組是(e3,r1,e4),則下一輪選擇的三元組是以實體e3、e4為起點或終點的一個隨機三元組。
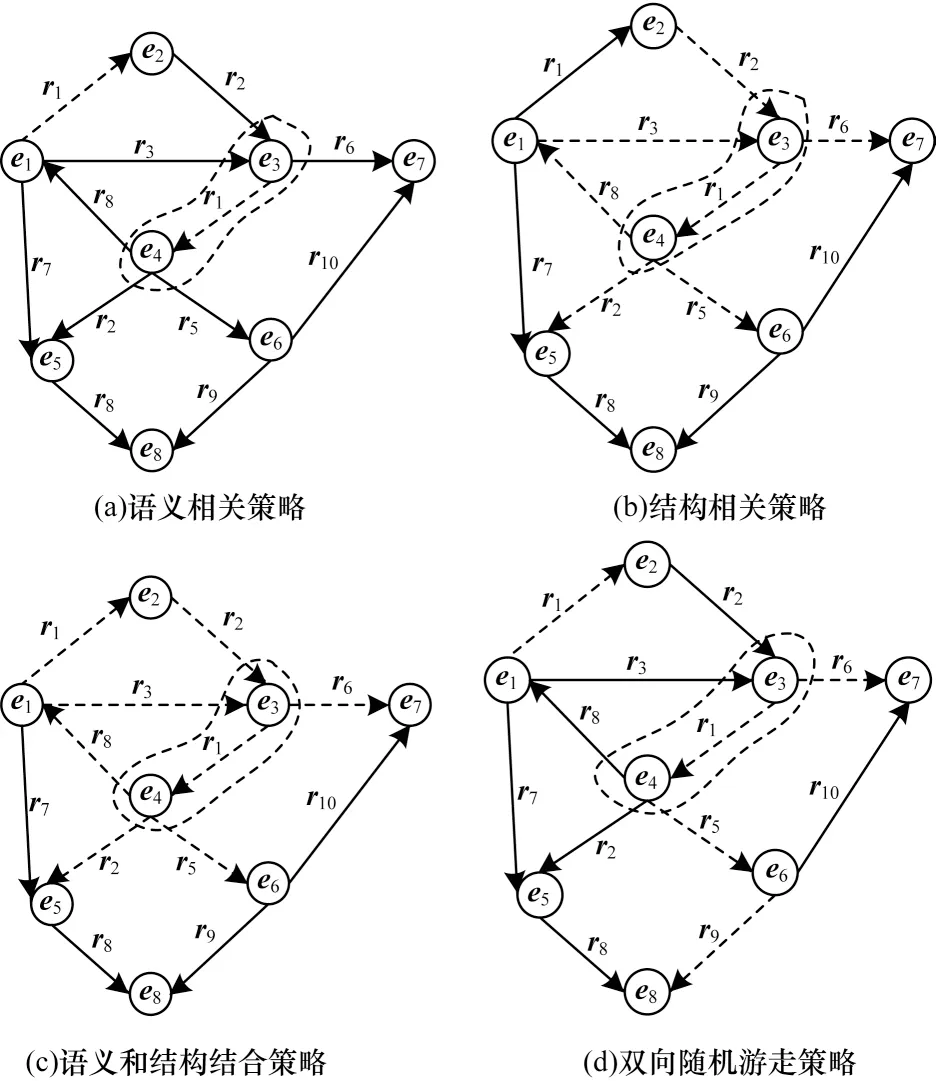
圖2 嵌入空間三元組選擇策略示意圖Fig.2 Schematic diagram of embedding space triplet selection strategies
算法2結合語義和結構的嵌入空間生成算法


2.3 嵌入空間選擇策略
在PUKALE 模型的訓練過程中,每個嵌入空間都會生成獨立的實體向量矩陣和關系向量矩陣。對于嵌入空間的選擇問題,本文分析如下2 種策略:
1)第1 種策略是線性遍歷每個嵌入空間,如果輸入的三元組對應的實體和關系存在于當前嵌入空間,則計算當前三元組在當前嵌入空間的能量分數并進行記錄,最終該三元組的全局能量分數就是所有符合條件的嵌入空間中能量分數的最大值。這種方式的時間復雜度是O(n),其中,n是嵌入空間的個數。在嵌入空間數量比較大的情況下,順序遍歷會有很多無效的遍歷,從而浪費大量時間。
2)本文對第1 種策略進行優化,提出第2 種嵌入空間選擇策略,建立實體和關系到各個嵌入空間的索引映射,如圖3 所示。在訓練時,如果一個三元組到達,則根據三元組的實體和關系查找對應的索引列表,索引列表中重疊的嵌入空間就是符合要求的嵌入空間。如圖4 所示,這種建立在索引機制上的嵌入空間選擇方式可以有效避免多余的遍歷,在不影響模型準確度的前提下能夠提高嵌入空間的選擇速度,其時間復雜度可以達到O(k),其中,k是查找的索引列表最大長度。該策略對應的算法描述如算法3 所示。
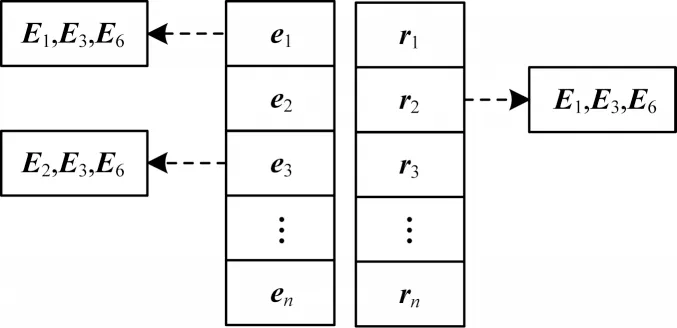
圖3 實體和關系到嵌入空間的索引映射Fig.3 Index mapping of entities and relationships to embedding space
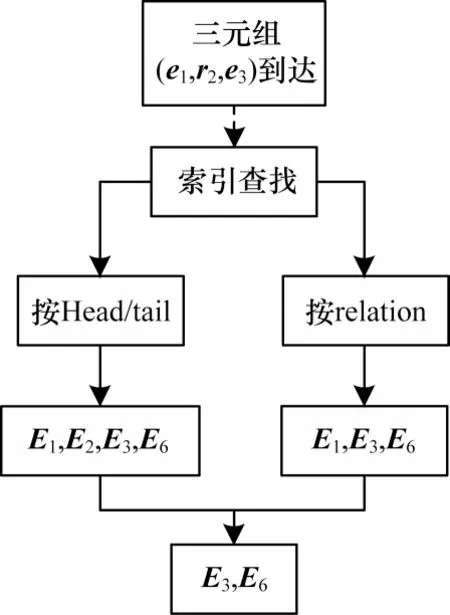
圖4 基于索引映射的嵌入空間選擇流程Fig.4 Procedure of embedding space selection based on index mapping
算法3基于索引映射的嵌入空間選擇算法

2.4 算法復雜度分析
為了分析PUKALE 模型的空間復雜度和時間復雜度,將PUKALE 和TransE 及其相關改進模型進行空間和時間復雜度對比,結果如表1 所示。

表1 知識表示學習模型的空間和時間復雜度對比Table 1 Comparison of space complexity and time complexity of knowledge representation learning models
在表1 中:d表示嵌入學習的向量空間維度;ne表示實體個數;nr表示關系個數;nt表示三元組個數;ng表示邏輯規則個數;ns表示生成的語義空間個數。從表1 可以看出,PUKALE 的空間及時間復雜度與性能最好的TransE 相差不大,與KALE 相比,PUKALE 的空間復雜度相同而時間復雜度降低,原因是對于流式增量數據,KALE 是在完整數據集上重新訓練,而PUKALE 中引入了子嵌入空間,其在子嵌入空間中進行局部訓練,在圖譜規模較大、嵌入空間個數較多的場景下,可以大幅縮短模型的訓練時間。
2.5 PUKALE 訓練方案
為了對PUKALE 模型進行有效訓練,本文使用KALE 中基于間距的Hinge 表達式優化損失函數,其常用形式如下:

間距模型常用于二分類或者樣本相似性分析任務,本文基于間距模型并結合聯合嵌入模型中所提的損失函數,提出一種PUKALE 模型的損失函數,如下:
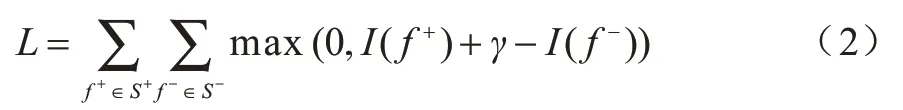
其中:L表示正確三元組和否定三元組之間的margin距離;S+為數據集中正確三元組組成的集合;S-為否定三元組組成的集合;I為模型計算出的真值;γ是距離超參數。
PUKALE 模型的訓練過程為:首先隨機初始化三元組(h,r,t)中實體和關系的向量表示;然后對訓練樣本生成否定三元組,生成方式是隨機替換樣本的頭實 體或尾實體,構 造出負例三元組(h′,r,t)或(h,r,t′);最后針對每個三元組計算統一得分函數,對于正確的三元組,其期望得分更低,而對于否定三元組,其期望得分更高,這樣即可通過訓練樣本的分數來區分正負樣本。
2.6 基于PUKALE 的實時語義數據流推理
現有的數據流推理引擎CSPARQL-engine 主要包括ESPER 流處理引擎、Sparql 推理引擎和Jena 查詢引擎。ESPER 是一個復雜事件處理以及事件流處理引擎,Jena 是Apache 的開源并基于Java 的RDF 流處理工具,CSPARQL 支持流式數據的持續查詢功能。本文將基于多嵌入空間的PUKALE 模型嵌入到CSPARQL-engine 中,使得復雜的規則推理可以映射至低維向量空間進行簡單的向量計算,從而降低圖譜規模不斷增大后的推理延遲,使其滿足大規模流式數據場景下的實時推理需求。實時語義數據流推理架構如圖5 所示,推理過程如下:
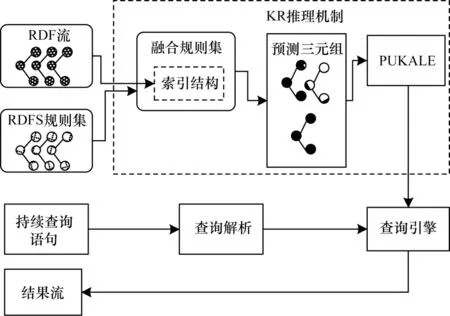
圖5 基于PUKALE 的實時語義數據流推理過程Fig.5 Procedure of real-time semantic data flow reasoning based on PUKALE
1)輸入到CSPARQL-engine 中的RDF 數據先通過Jena 進行格式化,轉換成系統可以識別的數據格式。
2)系統讀取Jena 格式化后的數據,在RDF 三元組的基礎上加上時間戳形成四元組,將該四元組放到RDF 數據流中。
3)系統讀取并解析CSPARQL 查詢,獲得查詢的時間步長和RDF 流窗口大小。
4)系統從ESPER 流引擎中取出指定窗口內的數據,將其輸入到查詢引擎中,同時作為輸入數據輸入到PUKALE 模型中。
5)PUKALE 模型獲取數據后,根據預設的邏輯規則進行計算,推理出隱藏的三元組知識,然后生成推理三元組集合并輸入查詢引擎。
6)系統根據查詢語句在查詢引擎中進行持續查詢,并返回查詢結果。
3 實驗與結果分析
本節首先通過實驗分析嵌入空間生成算法和選擇算法的性能,然后評估PUKALE 模型的動態更新效果以及模型性能,最后將其嵌入到CSPARQL-engine,并完成2 個語義數據流的推理查詢測試。實驗所使用的軟件環境均為Windows10 操作系統,Java8 編程環境,Maven 版本3.6;硬件環境為CPU i5-8265U@1.6 GHz,內存大小8 GB。
3.1 PUKALE 模型實驗
為了測試嵌入空間生成算法和選擇算法以及PUKALE 模型的性能,本節進行4 個實驗:前2 個實驗是對嵌入空間生成算法和選擇算法的性能測試;第3 個是測試新增數據集時PUKALE 模型和KALE模型在同等規模數據集下更新相同個數三元組時的時間消耗;第4 個是測試對比PUKALE 模型與其他知識表示學習模型的性能。
為了評價PUKALE 模型在軍情態勢預測數據集上的效果,對于樣本中的每一個三元組(s,p,o),模型會生成多個否定三元組實例,生成方式是主語s或賓語o替換為實體集合中的其他實體,形成(s′,p,o)或(s,p,o′),之后計算所有生成的三元組的得分,最后模型對三元組的得分進行排序,根據排序結果統計正實例三元組在列表中的位置排名。本文使用與KALE 相同的評估指標:
1)MRR(Mean Reciprocal Rank),其為一個國際通用的搜索算法性能評估指標。
2)HITS@K,指前K個位置中正實例三元組所占的比例。
3.1.1 嵌入空間生成策略性能分析
本文通過實驗分析2.2 節所提3 種嵌入空間生成策略以及puTransE 隨機游走策略對PUKALE 模型準確性的影響。實驗使用的數據集是海軍軍情態勢預測數據集,其包含100 000 個三元組。為了使模型有更好的適應性,本文減少超參數對模型性能的影響,在各個嵌入空間的訓練過程中,模型的初始參數不是固定的,而是采用隨機設置的方式,以避免參數耦合影響模型的訓練效果。訓練參數設定如下:嵌入空間三元組限定值為1 500;向量空間維度為30;margin 參數范圍 為{0.1,0.2,0.3};學習率learning_rate 參數范圍為{0.1,0.01}。
實驗結果如表2 所示。從表2 可以看出:第1 種語義相關策略在數據集關系個數較少的情況下不適用,原因在于這種劃分方式雖然可以讓一個嵌入空間中的三元組盡可能滿足語義的相關性,但是劃分到每個嵌入空間的關系個數比較少,三元組關系不具備多樣性,訓練效果比較差;在第2 種結構相關的三元組選擇策略下模型的準確率有明顯提高,一方面是因為劃分至嵌入空間的關系個數增加,解決了第1 種策略嵌入空間關系個數太少的缺陷,另一方面,結構相關的三元組劃分到同一個嵌入空間,避免了相互影響的三元組分散在多個嵌入空間,減少了圖譜更新時需要重新訓練的嵌入空間個數,提升了模型的訓練效率和準確率,此外,這種方式下相鄰嵌入空間的三元組存在一定程度的重疊,經過測試,所有嵌入空間三元組的總重復率為4.6%;第3 種語義結構結合策略相比第2 種結構相關策略,模型的準確率進一步提升,因為圖譜中三元組的更新影響的不僅是頂點入度出度方向的三元組,還有關系相同的三元組,策略2 只選擇了受頂點變化影響的三元組,而忽略了受關系變化影響的三元組,策略3 在策略2 的基礎上加入了關系相同的三元組,使得嵌入空間重訓練時可以學習到更多的信息;與puTransE中的隨機游走策略相比,策略3 下的模型準確率更高,原因是其模型可以推理出更多隱含的三元組。
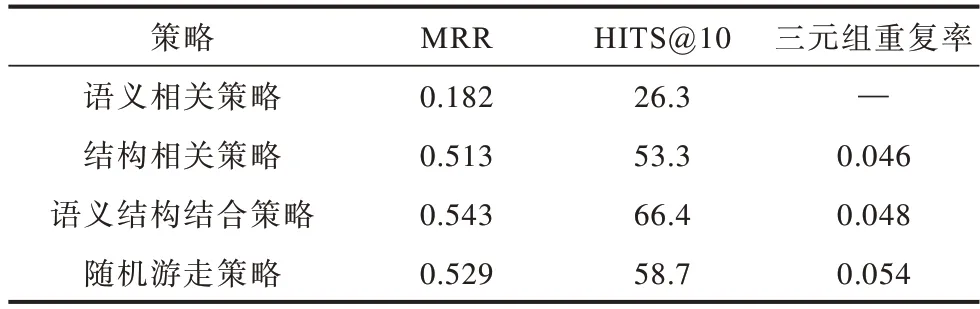
表2 嵌入空間生成策略性能對比Table 2 Performance comparison of embedding space generation strategies
如圖6、表3 所示,本文以數據流傳遞閉包規則為例進行推理查詢。以t1為初始三元組,假設使用隨機游走策略劃分三元組,由于隨機游走的隨機性,三元組t1、t2可能劃分在嵌入空間E1,t3、t4可能劃分在嵌入空間E2,則E1中可以推理出t5,E2中可以推斷出t6。假設使用結構語義結合策略,則三元組t1、t2、t3、t4會劃分到同一個嵌入空間E3,在E3中除了可以推理出t5、t6外,還 可以推理出t7、t8。而在傳遞 閉包規則中,推理的結果可以作為推理條件繼續使用,將其加入嵌入空間進行訓練,模型可以學習更多的信息,即準確率會提升。
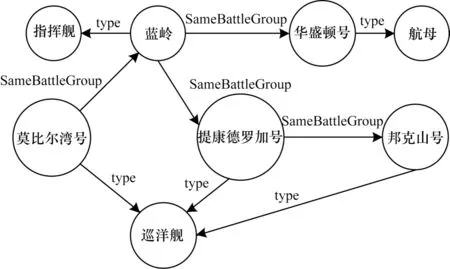
圖6 傳遞閉包圖譜示例Fig.6 Sample of transitive closure graph

表3 傳遞閉包圖譜三元組編號Table 3 Transitive closure graph triples numbers
3.1.2 嵌入空間選擇策略性能分析
本節通過在10 萬、30 萬、50 萬規模的數據集上分別進行實驗,記錄不同規模數據集下嵌入空間的平均選擇時間,以分析2.2 節所提2 種嵌入空間選擇策略的性能。在3 個不同規模數據集上的參數設定均一致,嵌入空間三元組限定值為1 500,向量空間維度為30,margin 參數范圍為{0.1,0.2,0.3},學習率learning_rate參數范圍為{0.1,0.01},實驗結果如表4 所示。從表4可以看出,隨著訓練集三元組規模的增大,子嵌入空間個數增多,索引映射的時間消耗明顯低于線性遍歷,原因在于索引映射使用索引算法避免了對多余子嵌入空間的遍歷,從而節省了時間。
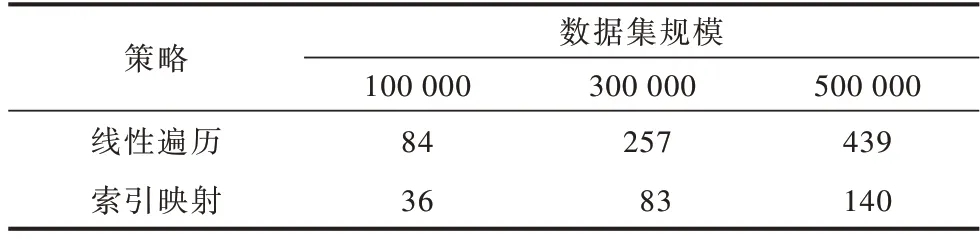
表4 不同規模數據集下嵌入空間選擇時間對比Table 4 Comparison of embedding space selection time under different scale datasets ms
3.1.3 PUKALE 模型動態更新分析
PUKALE 模型中引入了多嵌入空間,避免了數據集三元組增量更新時模型在整個數據集上重新訓練。為了驗證PUKALE 模型引入多嵌入空間的有效性,本文對比PUKALE 模型和KALE 模型在不同規模數據集下增量更新時的訓練時間消耗,數據集詳細信息如表5 所示,KALE 和PUKALE 在表5 的3 個不同規模數據集上動態更新所消耗時間如表6 所示。實驗參數設置:嵌入空間三元組個數限定值為1 500,margin 參數范圍 為{0.1,0.2,0.3},學習率learning_rate 參數范圍為{0.1,0.01}。
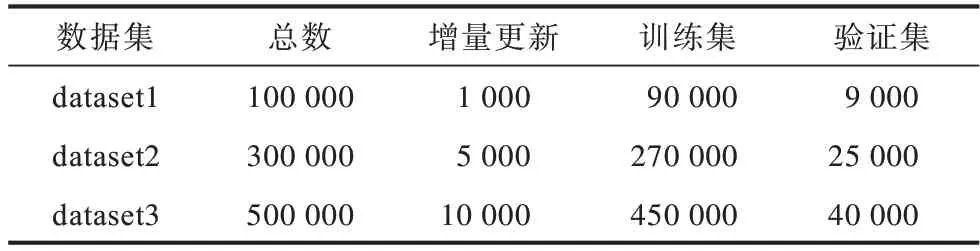
表5 用于增量更新測試的數據集信息Table 5 Datasets information for incremental update test

表6 不同規模數據集下增量更新時間對比Table 6 Comparison of incremental update time under different scale datasets min
在訓練集三元組增量更新時,KALE 模型在整個圖譜上重新訓練,是一種全量更新的方式,隨著三元組數目的不斷增大,KALE 模型重新訓練所消耗的時間會顯著增加。而PUKALE 模型的增量更新方式是在選定的嵌入空間進行更新,是一種局部更新的方式,相比于全量更新,其訓練時間明顯降低,適用于大規模數據流更新場景。
在動態更新實驗過程中,不同規模數據集上PUKALE 模型和KALE 模型的準確率對比如表7 所示。從表7 可以看出,對于不同規模的三元組,隨著三元組數量的增多,PUKALE 模型的準確率會逐漸提高,同等規模三元組在進行增量更新時,PUKALE模型在各個子嵌入空間的平均準確率也略有提高,這表明PUKALE 模型的增量更新具有有效性。
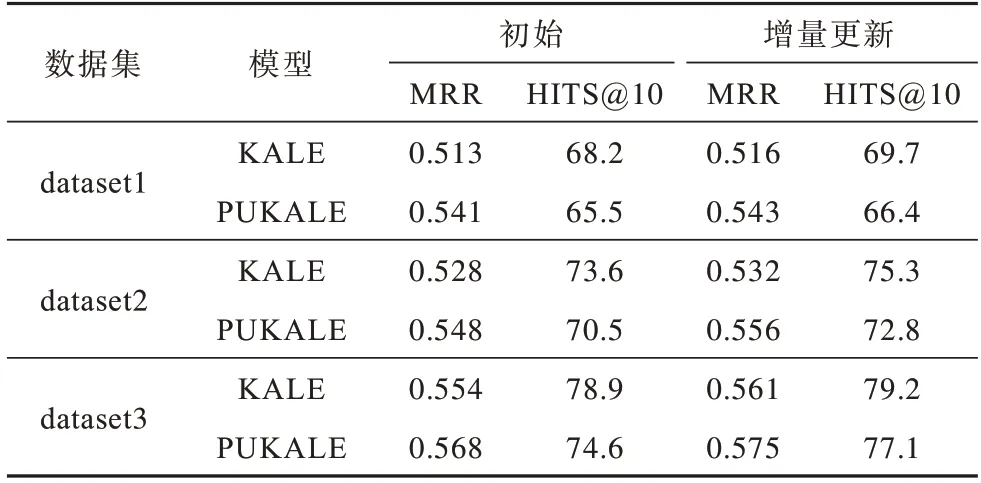
表7 不同規模數據集下模型準確率對比Table 7 Comparison of models accuracy under different scale datasets
3.1.4 PUKALE 模型性能分析
為了比較PUKALE 模型和其他知識表示學習模型的訓練效果,本文進行對比實驗,設置如下:向量空間維度d分別設置為{30,40,50};訓練集三元組個數為90 000;驗證集三元組個數為10 000;嵌入空間三元組個數分別設置為{1 000,1 500,2 000,3 000};margin 參數范圍為{0.1,0.2,0.3};學習率learning_rate 參數范圍為{0.1,0.01}。實驗結果如表8 所示。
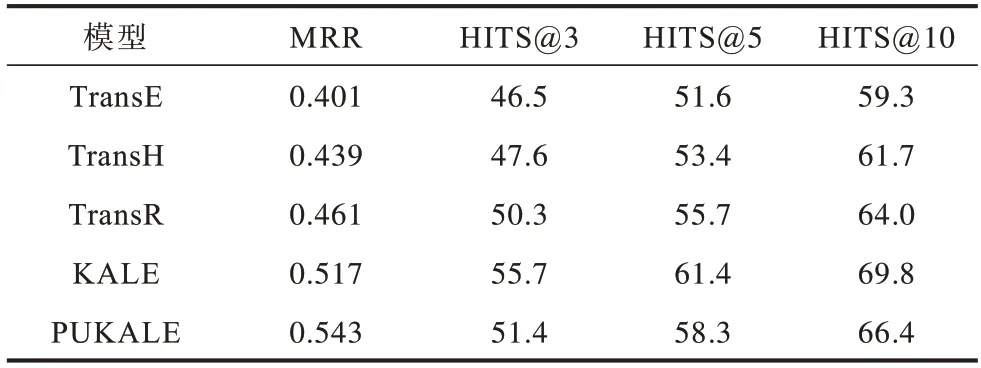
表8 PUKALE 與其他知識表示學習模型準確率對比Table 8 Comparison of accuracy between PUKALE and other knowledge representation learning models
從表8 可以看出,KALE 模型和PUKALE 模型的準確率均優于TranE、TransH、TransR 模型,PUKALE 在各個嵌入空間的平均準確率比KALE低,但是MRR 相比KALE 有所提高,PUKALE 準確率比KALE 低的原因在于KALE 訓練時只有一個全局嵌入空間,其可以完整學習所有三元組的信息,而PUKALE 是將三元組按語義相關和結構相關劃分到各個子嵌入空間中,由于嵌入空間生成算法具有差異性,因此相關的三元組不一定能全部劃分到同一個嵌入空間,導致在各個嵌入空間學習的信息不一定完整,平均準確率降低。PUKALE 的MRR 有所提高的原因在于嵌入空間的選擇機制會忽略掉一些不相關的嵌入空間和三元組,精簡了三元組的搜索范圍,使得測試三元組的排名更靠前。雖然PUKALE的準確性低于KALE,但是PUKALE 支持增量更新,進行增量更新時是在局部嵌入空間重新訓練,而不是在整個數據集上進行重新訓練。在大規模三元組場景下,PUKALE 的更新時間消耗遠低于KALE,這在后續的實時語義數據流處理中具有重要意義。
3.2 PUKALE 在語義數據流推理中的性能分析
本節將PUKAEL 模型添加推理嵌入到CSPARQLengine 中進行2 種場景實驗,測試其在2 種場景下的推理查詢時延,并與傳統的CSPARQL 推理查詢和KALE推理查詢進行對比。場景1 是具有傳遞閉包規則的艦船戰斗群隸屬關系推理,場景2 是較為復雜的動態威脅感知推理。場景1 的規則如表9 所示。

表9 場景1 閉包規則Table 9 Scenario 1 closure rule
表9 規則表示,如果艦船目標x 和艦船目標y 處于同一個戰斗組,艦船目標y 和艦船目標z 處于同一個戰斗組,則艦船目標x 和艦船目標z 處于同一個戰斗組。對于艦船目標x,如果獲取了與其同組的y 和z,則可以通過分析其同組艦船目標的歷史活動進行意圖分析。因此,在數據流平臺快速推理出x 同組的其他艦船目標比較關鍵。另外,該規則存在傳遞閉包特征,推理結果可以作為推理條件繼續使用。
針對表9 構造的Rule1,本文在CSPARQL-engine中使用如下查詢語句Query1,表示查詢出所有與艦船x 同組的艦船。
Query1傳遞閉包查詢

場景2 的規則如表10 所示。該規則表示,如果艦船目標a 裝載了武器b,武器b 的目標是c,而艦船目標d 的類型是c,則艦船目標a 對艦船目標d 存在潛在威脅。

表10 場景2 復雜推理規則Table 10 Scenario 2 complex reasoning rule
針對規則2,本文使用的推理查詢語句如Query2所示。Query2 是一個較為復雜的推理查詢,表示如果在時間點time1 和位置1 發現了2 艘艦船x 和y,并且x對y 有威脅,而在時間點time2(time2>time1)和位置2又發現了x 和y,并且2 個區域在一定范圍內,則查詢出2 艘艦船的信息。
Query2復雜推理規則查詢
針對以上2 個查詢,本文實驗所設置的參數如下:數據流窗口大小分別為{10,20,30,40},單位為秒;每秒窗口三元組的數量為{2 000,4 000,8 000,16 000,32 000,64 000};窗口的步長為1 s。根據以上輸入參數可以得到實驗結果如圖7、圖8 所示。
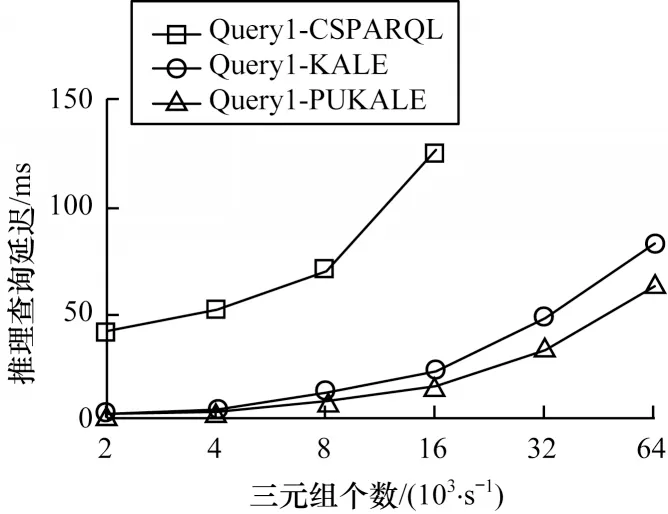
圖7 規則1 推理查詢時間延遲Fig.7 Rule1 reasoning and query time delay
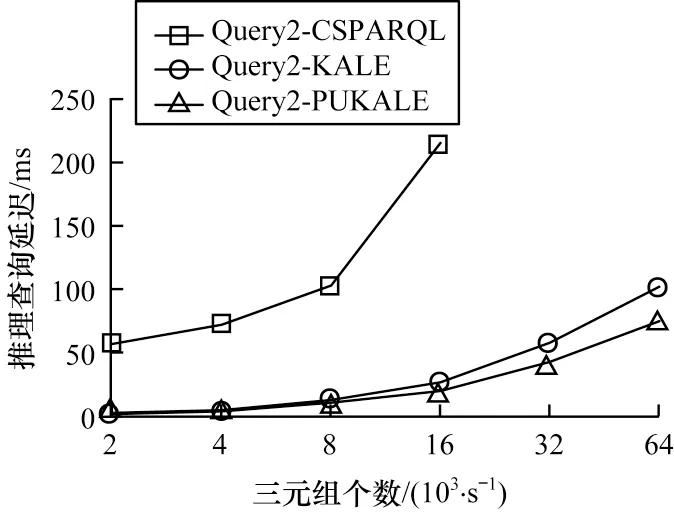
圖8 規則2 推理查詢時間延遲Fig.8 Rule2 reasoning and query time delay
實驗結果表明:在相同的條件限制下,CSPARQL-engine 在PUKALE 作為推理引擎時的推理查詢延遲明顯低于傳統的CSPARQL 規則推理引擎,而且傳統的CSPARQL 規則推理引擎在三元組輸入速率達到32 000 個/s 時失去響應,而在使用PUKALE 和KALE 作為推理引擎時,CSPARQLengine 還能正常工作;CSPARQL-engine 在使用PUKALE 作為推理引擎時的推理查詢時延在三元組速率低于16 000 個/s 時與KALE 作為推理引擎時延遲差別不大,但在三元組速率達到32 000 個/s 或64 000 個/s 時,PUKALE 推理的性能略好于KALE,原因在于KALE 推理只有一個全局配置空間,在計算時對所有三元組都會計算一次,在三元組個數較多的情況下會有較多的無效計算,比較耗時,而PUKALE 采用多嵌入空間的方式,能過濾掉一些無效嵌入空間和三元組,因此,在三元組個數較多的情況下,其計算量較少,性能較高。
4 結束語
本文在知識表示學習模型KALE 的基礎上引入多嵌入空間,提出一種PUKALE 模型,并設計3 種嵌入空間生成策略以及2 種嵌入空間選擇策略。為了提升數據流推理引擎的推理效率,本文將PUKALE 模型嵌入實時數據流推理平臺CSPARQL-engine,并與傳統的CSPARQL 推理和KALE 推理進行對比。實驗結果表明,相較KALE 的全量更新方式,PUKALE 中的增量更新方式在三元組數量較大、更新較頻繁的場景下具有顯著優勢,在50 萬圖譜規模數據集中時間消耗約下降93%。此外,相較傳統的CSPARQL 推理,PUKALE 推理的查詢時間約縮短85%,且其更適用于大規模實時語義數據流推理查詢任務。
PUKALE 模型在知識圖譜在線更新時使用局部子嵌入空間訓練,雖然避免了在整個圖譜上重新訓練,縮短了訓練時間,然而,局部子空間并不能保存圖譜全局結構信息,從而導致信息學習不全的問題。此外,PUKALE 利用TransE 的打分函數計算每個三元組的能量分數,其并不能很好地建模1~N、N~1、N~N的關系。因此,后續將為PUKALE 設計新的三元組學習及打分機制,弱化TransE 中三元組h+r≈t的嚴格限制,進一步提升PUKALE 模型對1~N、N~1、N~N關系的建模及適應能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
開放教育研究(2020年2期)2020-03-31 01:54:14
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數學大世界(2018年1期)2018-04-12 05:39:14
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
