基于BERT-CRF的中文分詞模型設計
2022-02-17 07:39:26陳月月,李燕,帥亞琦,徐麗娜,鐘昕妤
電腦知識與技術 2022年35期
陳月月,李燕,帥亞琦,徐麗娜,鐘昕妤



摘要:分詞作為中文自然語言處理中的基礎和關鍵任務,其分詞效果的好壞會直接影響后續各項自然語言處理任務的結果。本文基于BERT-CRF的分詞模型利用通用領域數據集與醫學領域數據集對模型進行訓練,分別取得F1值0.898和0.738的實驗結果。
關鍵詞:BERT;CRF;中文分詞;自然語言處理
中圖分類號:TP311? ? ? ? 文獻標識碼:A
文章編號:1009-3044(2022)35-0004-03
自然語言處理(Natural Language Processing, NLP)是研究計算機理解和自然語言生成的信息處理[1]。隨著深度學習的發展,神經網絡算法被廣泛應用于各項自然語言處理任務中。分詞作為自然語言處理中的基礎和關鍵任務,其結果會直接影響后續命名實體識別、關系抽取等自然語言處理相關工作的準確性[2]。由于神經網絡具有很強的自學習性和自適應性,有助于提高中文分詞模型的性能,因此,現有的中文分詞模型大都結合了神經網絡算法對分詞模型進行構建。
分詞的目的是將一個完整的句子分割為詞語級別[3]。不同于英文中以空格為分詞符號的分詞,在中文文本中,詞與詞之間沒有明確的分詞標記,其以連續字符串的形式呈現,且存在一詞多義和語境不同意義不同的現象。因此,做好中文分詞工作對處理所有的中文自然語言處理任務有著至關重要的作用。
1 相關工作
分詞模型是自然語言處理中最基本的語言處理模型之一。中文的語言結構復雜,難以準確地進行詞語識別[4]。因此,中文分詞成為分詞任務中的熱點話題。中文分詞方法可以分為傳統的分詞方法和基于神經網絡的分詞方法。
傳統的分詞方法包括基于詞典規則的方法和基于統計的方法。基于詞典規則的方法就是按照中文文本的順序將其切分成連續詞序,然后根據規則以及連續詞序是否在給定的詞典中來決定連續詞序?是否為最終的分詞結果[5]。基于詞典規則方法構建的分詞模型分詞速度快、容易實現,且其在特定領域分詞的準確率較高,但其高度依賴詞典規則,針對詞典規則中未登錄詞的識別效果差。基于統計方法構建的分詞模型,其主要思想是把字符序列中的每個詞都看作由字組成,計算字符序列中任意相鄰字符出現的概率,概率值越大則說明相鄰字符成詞的可能性越大[6]。基于統計方法構建的分詞模型可以很好地識別未登錄詞,但模型復雜度高,存在人工特征提取工作量大、容易過擬合等問題。
鑒于傳統分詞方法的各種不足,近年來,隨著計算機技術的不斷發展,基于神經網絡的分詞方法逐漸成為分詞任務處理中的研究熱點。基于神經網絡的分詞方法構建的分詞模型,其主要思想是將輸入序列中詞向量的元素值作為模型參數,并使用神經網絡和訓練數據的學習來獲取模型的參數值。神經網絡充分利用了文本自身所具有的有序性和詞共現信息的優勢,具有很強的自學習性和自適應性,可以自動從原始數據中提取特征,而無須人工構造特征,避免了人工設置特征的局限性[7]。因此,神經網絡算法在自然語言處理任務中得到了廣泛的應用。張文靜等[8]提出了一種基于Lattice-LSTM的中文分詞模型,該模型集成了多粒度的分詞信息,在多粒度的中文分詞任務中取得了優異的性能表現;胡曉輝等[3]利用雙向LSTM可以提取輸入序列前后信息和卷積神經網絡能夠提取文本局部特征信息的特點,提出了基于BiLSTM-CNN-CRF的中文分詞模型,在中文分詞任務中取得了較好的效果。
2 基本原理
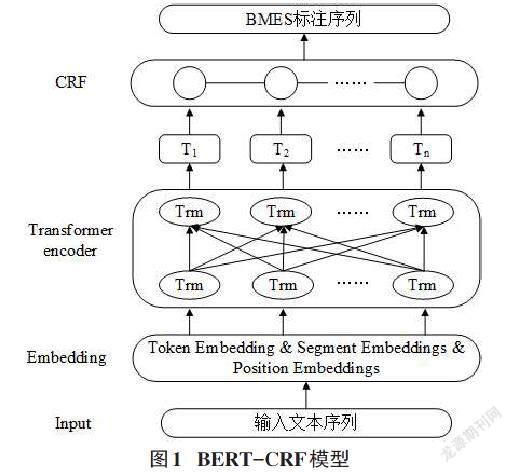
本文采用基于BERT-CRF的中文分詞模型對文本進行分詞處理。模型結構如圖1所示。主要包含基于BERT的詞嵌入層和CRF條件隨機場模型層。其中,BERT的詞嵌入層用于提取輸入文本序列的上下文信息;CRF用于進行最后的序列標注,將輸入的數據標注成B、M、E、S的向量形式。
2.1 BERT詞嵌入層
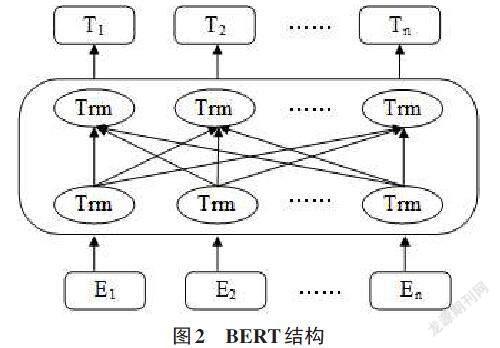
BERT是從Transformer中衍生出來的預訓練模型,2018年由Google團隊提出。BERT模型采用深層雙向的Transformer組件來進行模型構建,打破了單向融合上下文的限制,生成了融合上下文信息的深層雙向語言表征[9]。BERT的結構如圖2所示,其中,E1、E2…En為輸入向量; T1、T2…Tn為經過多層Transformer編碼器后的輸出向量。
BERT預訓練模型憑借龐大的語料庫和強大的計算能力,在獲得通用語言模型和表示的基礎上,結合任務語料對模型進行微調[10],可以很好地完成各類文本處理任務,成為當前各類自然語言處理任務中的研究熱點和核心技術。
2.2 CRF條件隨機場模型層
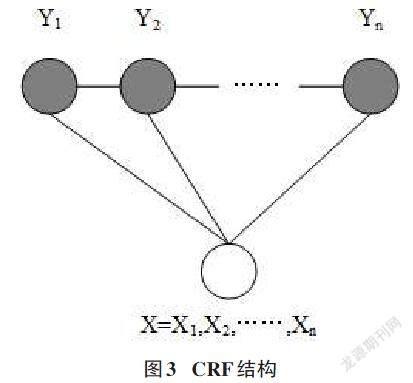
CRF條件隨機場模型是由Lafferty等[6]提出的一種序列標記模型,它結合了最大熵模型(Maximum Entropy)和隱馬爾可夫模型(Hidden Markov Model,HMM)的特點,能夠充分考慮標簽之間的依存關系,避免了標記偏執和最大熵模型局部優化的問題,克服了HMM輸出獨立性假設的缺點,可以很好地完成分詞等其他序列標注任務。因此,現有的分詞模型大都結合了CRF模型,模型結構如圖3所示。
根據CRF的定義,CRF條件隨機場模型是輸入隨機變量X和輸出隨機變量Y的條件概率分布模型。其中,X為輸入變量,表示要標記的字符序列;Y是表示標注序列(也稱為狀態序列)的輸出變量。
3 實驗及分析
3.1 數據集
本實驗中的通用數據集來自SIGHAN 2005第二屆中文分詞任務中的Peking University數據集(簡稱PKU數據集);中文醫學領域數據(Chinese Medical Corpus,CMC)來自《國醫大師治療中風經典醫案》療病叢書中所記錄的醫案數據。
按照9:1的比例將通用領域和中文醫學領域訓練數據分割為訓練集和驗證集。
3.2 實驗設置
本實驗的環境參數和模型訓練參數設置如表1和表2所示。其中,模型訓練的迭代次數(epoch_num)為20次。實驗中涉及通用領域訓練語料和醫學領域訓練語料,針對兩個不同領域的數據集均使用BERT-CRF分詞模型對數據集進行訓練。所有數據采用BMES四詞位標注法進行標注,各標注的具體含義如表3所示。
3.3 評價指標
試驗結果評估指標采用查準率(Precision,P)、召回率(Recall,R)和F1值,各項指標的計算公式為:
[F1=2PRR+P]? ? ? ? ? ? ? ? ? ? ? ? ? (1)
[P=TPTP+FP]? ? ? ? ? ? ? ? ? ? ? ? ? ? (2)
[R=TPTP+FN]? ? ? ? ? ? ? ? ? ? ? ? ? ?(3)
式中:TP表示分詞正確的詞數;TP+FP表示分詞的總詞數;TP+FN表示標準分詞集中的詞數。
3.4 結果分析
本次實驗分別利用PKU數據集和CMC數據集對BERT-CRF分詞模型進行訓練,其訓練結果如圖4和圖5所示,兩個數據集實驗結果的對比如表4所示。
由表4可以看出,基于BERT-CRF的中文分詞模型的分詞效果在通用領域數據集上的分詞結果更好。這是因為不論是基于哪種分詞方法來構建分詞模型,其分詞的效果都依賴于大規模的訓練數據,但由于目前醫學領域開放的數據集較少,且數據專業性強,很難獲得大量標注的訓練數據,導致模型訓練不夠完全,無法達到模型所期望的最佳分詞效果。因此,若想在醫學領域數據集上獲得更好的分詞效果,需要增加醫學領域的訓練數據,并對模型進行進一步的優化和訓練,使得模型能夠更好地理解醫學領域的中文文本,從而發揮模型的最佳分詞性能。
4 結束語
針對自然語言處理中的中文分詞任務,本文利用BERT-CRF的模型探究同一模型在不同領域數據集上的分詞效果,分別在PKU數據集和CMC數據集上進行模型訓練,得到F1值分別為0.898和0.738的實驗結果,證明了該模型在通用領域數據集上的分詞效果更好。
參考文獻:
[1] ISO/IEC.Information technology—artificial intelligence—artificial intelligence concepts and terminology:ISO/IEC TR 24372:2021(E)[S].2021
[2] WANG K,ZONG C,SU K Y.A character-based joint model for Chinese word segmentation[C]//23rd International Conference on Computational Linguistics,2010:1173-1181.
[3] 胡曉輝,朱志祥.基于深度學習的中文分詞方法研究[J].計算機與數字工程,2020,48(3):627-632.
[4] 王若佳,趙常煜,王繼民.中文電子病歷的分詞及實體識別研究[J].圖書情報工作,2019,63(2):34-42.
[5] WU A.Word segmentation in sentence analysis[C]//Proceedings of 1998 International Conference on Chinese Information Processing.Beijing:Chinese Webster F.What information society?[J].The Information Society,1994,10(1):1-23.
[6] LAFFERTY J D,MCCALLUM A,PEREIRA F C N.Conditional random fields:probabilistic models for segmenting and labeling sequence data [C]//Proceedings of the Eighteenth International Conference on Machine Learning.San Francisco.Morgan Kaufmann Publishers Inc,2001:282-289.
[7] 姚茂建,李晗靜,呂會華,等.基于BI_LSTM_CRF神經網絡的序列標注中文分詞方法[J].現代電子技術,2019,42(1):95-99.
[8] 張文靜,張惠蒙,楊麟兒,等.基于Lattice-LSTM的多粒度中文分詞[J].中文信息學報,2019,33(1):18-24.
[9] 何濤,陳劍,聞英友.基于BERT-CRF模型的電子病歷實體識別研究[J].計算機與數字工程,2022,50(3):639-643.
[10] 王海寧.自然語言處理技術發展[J].中興通訊技術,2022,28(2):59-64.
【通聯編輯:唐一東】
