利用人工智能技術提升機器翻譯質量的方法應用
2022-02-17 07:23:24陳銀娣王秀珍
中華醫學圖書情報雜志 2022年7期
陳銀娣,王秀珍
近年來,隨著大數據與人工智能技術的飛速發展,機器翻譯技術也呈現蓬勃發展的勢頭,許多在線翻譯軟件的翻譯水平大幅提升,在多個場景下已經能夠提供翻譯質量可接受的翻譯結果。但在具體的應用過程中(如研究報告翻譯、學術論文翻譯、領域專著翻譯等),現有翻譯軟件在特定領域詞匯翻譯、多重嵌套長句式理解、根據上下文語境確定詞義等方面還存在較大問題,嚴重影響了機器翻譯的多場景應用。
提高機器翻譯的質量,首先要解決的是語言問題而不是程序問題[1]。從目前人工智能機器翻譯的原理來看,僅憑改進算法、擴大語料庫、采用多種翻譯引擎等技術很難解決語言表達多樣化方面的問題。為此,筆者進行了長期的思索與研究,提出一種利用降噪簡化、領域矯正等手段提升機器翻譯質量的方案。經檢驗,利用該方法可有效解決在機器翻譯過程中存在的特定領域詞匯句式翻譯不準確、結構復雜長句式理解偏差、不能依托上下文靈活用詞等問題,可提升研究報告、學術論文、領域專著等長篇報告的翻譯質量,為情報研究工作提供更大助益。
1 機器翻譯的現狀
機器翻譯,又稱為自動翻譯,是利用計算機將一種自然語言(源語言)轉換為另一種自然語言(目標語言)的過程。機器翻譯技術隨著計算機技術的進步而發展,自從1946 年第一臺現代電子計算機面世,科學家們就開始研究機器翻譯的可行性。經過70 多年的不斷探索,人們先后開發了基于規則機器翻譯、基于語料庫的機器翻譯(包括基于統計、基于實例的機器翻譯)及基于神經網絡的機器翻譯方法。
1.1 基于規則的機器翻譯方法
20 世紀90 年代前,機器翻譯的主流一直是基于規則的方法[2]。由人類語言學家將相應的翻譯規則提前編好,包括某一句子中的單詞應翻譯成什么,應在目標句子中何處出現等,均用規則表示(圖1)。這種方法的優點是直接使用語言學家的專家知識,準確率高[3]。但缺點也非常明顯:一是成本高,需要大量精通各種語言的語言學家;二是不夠靈活,規則不能覆蓋的句子無法進行翻譯;三是經常面臨規則沖突,由于語言靈活性強需要撰寫大量規則,但規則之間經常互相制約和影響,造成混亂[4]。
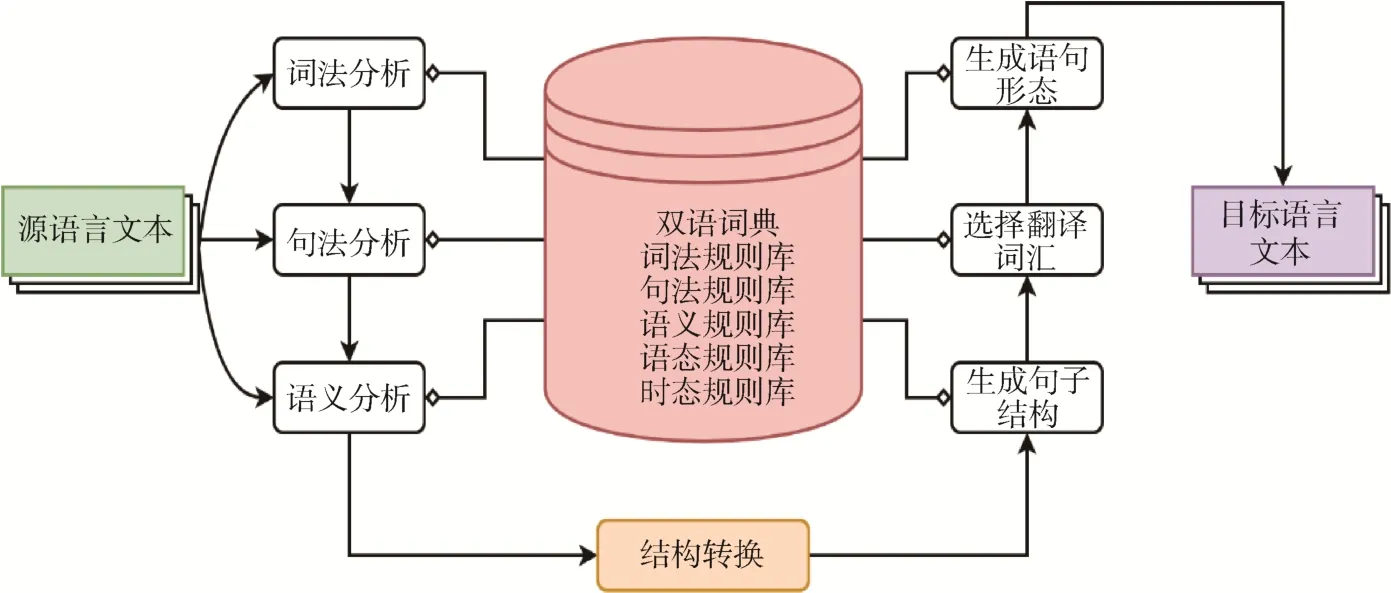
圖1 基于規則的翻譯方法
1.2 基于語料庫的統計機器翻譯方法
20 世紀90 年代中期,為破解規則庫建設的難題,科學家們提出了基于語料庫(主要為雙語平行語料庫)的統計機器翻譯技術,通過模仿實例庫中已有的翻譯句式,或者通過建立和訓練統計翻譯模型進行翻譯[5-6](圖2)。這種方法具有三大優點:一是不需要詞典也無需規則,可避免深層語言學分析問題;二是基于實例進行翻譯,譯文質量高,可讀性強;三是系統很容易擴展,只需豐富語料庫即可[7]。但由于該方法需要龐大的語料庫作為支撐,在翻譯中經常因語料庫覆蓋不全而出現數據稀疏等問題。
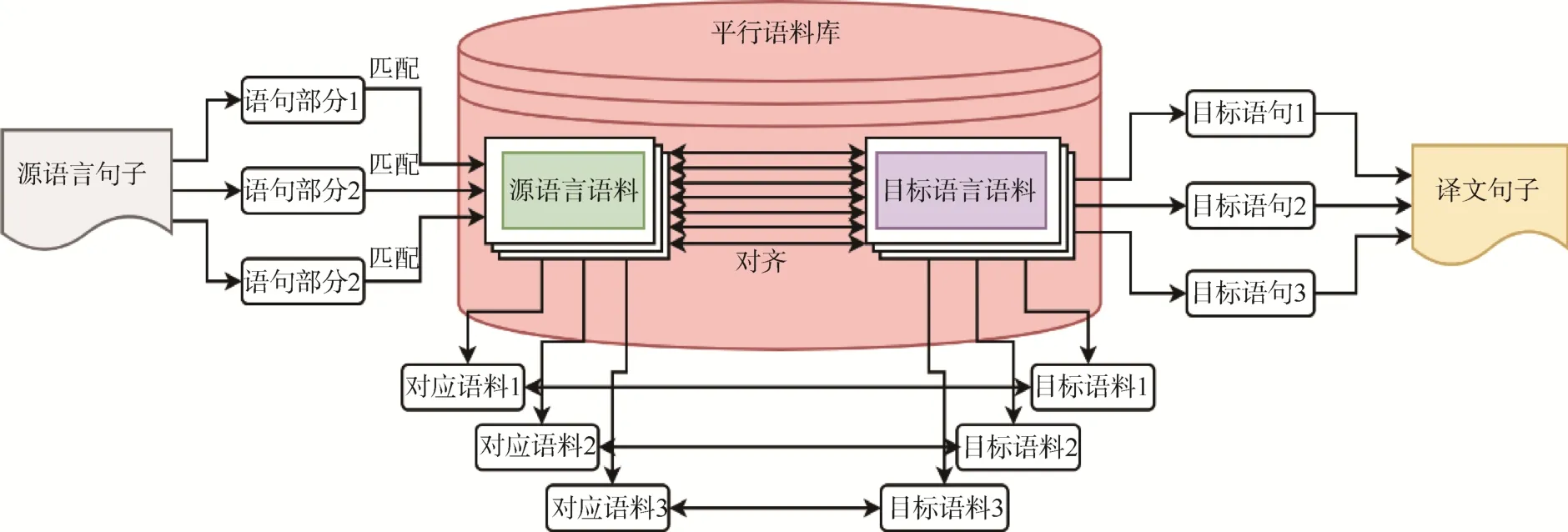
圖2 基于語料庫的統計機器翻譯方法
1.3 端到端的神經網絡機器翻譯方法
2014 年以來,端到端的神經網絡機器翻譯(簡稱“神經機器翻譯”)迅速發展[8-9],可通過神經網絡直接實現自然語言之間的自動翻譯[10](圖3)。相較于統計機器翻譯,神經機器翻譯模型較為簡單,主要包含一個編碼器及一個解碼器。編碼器是將源語言經過一系列神經網絡變換后,表示成一個高維的向量;而解碼器負責把這個高維向量再重新解碼(翻譯)成目標語言[11-12]。由于神經機器翻譯模擬了人腦的翻譯過程,翻譯質量顯著提升,目前采用神經網絡機器翻譯的有谷歌、微軟、百度、搜狗等翻譯系統。
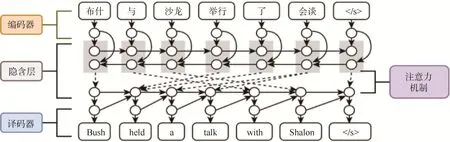
圖3 端到端的神經網絡機器翻譯方法
2 機器翻譯在情報研究實踐中存在的問題
情報研究過程中,需要對大量外文文獻進行跟蹤處理,而在當前大數據時代,開源情報信息海量化趨勢愈演愈烈,如何快速有效地進行信息的篩選和處理成為亟須解決的問題。利用機器輔助翻譯,能夠極大提高對大量文獻進行初期篩選和處理的速度,加快情報研究響應能力,提升情報研究工作效率。在情報研究與翻譯實踐(尤其是研究報告、學術論文、專著翻譯)中,機器翻譯暴露出的語言問題(如英譯漢)非常復雜,相同內容在不同語境下表述的意義不同,不同的作者表達方式也多種多樣,經常出現大量歧義現象;而且機器翻譯過程涉及多個環節,每個環節都無法做到完全準確,導致有時錯誤積累非常嚴重。因此,在實際應用中,無論統計機器翻譯還是神經機器翻譯,都可能出現翻譯謬誤問題[13-14]。
在情報研究與翻譯實踐(尤其是研究報告、學術論文、專著翻譯)中,無論機器翻譯系統采用何種技術,在面對專業性長文檔時也很難保證翻譯質量。它們存在以下3 個共性問題。
2.1 多重嵌套長句式理解困難
在專業性英文報告,尤其是政府發布的文件或科研機構發布的報告中,經常使用多重從句嵌套的長語句模式。翻譯此類句子時,需要弄清源語言句式的語法結構、句式構成,并理解源語言的相關內容,然后按照目標語言的表達習慣進行重新搭配、翻譯。但目前使用的機器翻譯系統,不管是建立在語法規則基礎上的翻譯引擎,還是建立在語料庫基礎之上的統計翻譯引擎,以及建立在神經網絡基礎之上的翻譯引擎,其基礎都是簡單結構的短句式,對復雜的長句式則多采用類比法在雙語語料庫中尋找相似結構的源語言,然后進行類比翻譯,因此在翻譯多重從句嵌套語句結構時,經常出現翻譯語序混亂、從句修飾錯誤等問題,導致翻譯結果與原文意思相差甚遠。如圖4 所示的長句式,其中嵌套了2 個定語從句、1 個狀語從句、2 個分詞。正確的翻譯應為“習近平進一步擴大了軍隊的實力,對解放軍進行了建軍以來最具雄心的改組,具體目標是使中國軍隊能夠在武力統一臺灣地區所需的兩棲登陸、戰場封鎖、導彈打擊行動中開展聯合作戰,空軍、海軍、陸軍和戰略火箭軍都能無縫融合”。但機器翻譯將長句式分解成多個短句之后,源語句的結構徹底被打破,其間的修飾關系出現了混亂,導致翻譯出的文本與源語句的意思出現了較大偏差。
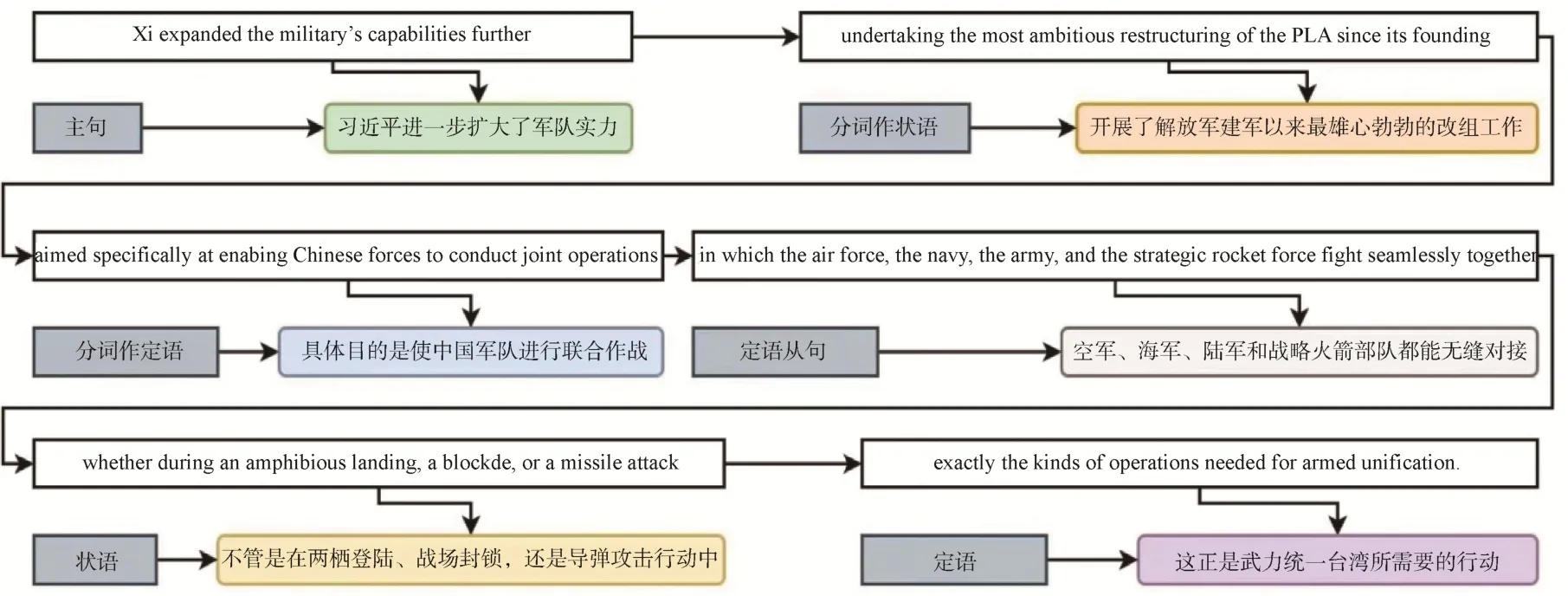
圖4 多重從句嵌套的長語句模式句式結構分析
2.2 特定領域內容翻譯不準確
同一個詞、短語甚至句式在不同領域代表不同的意義,即使在同一個領域中,在不同的應用環境中也會有不同的釋義,翻譯時需要根據領域、語境進行靈活的翻譯。當前市面上的機器翻譯系統在該方面還存在較大問題:一是語料庫、詞庫都是不區分領域的通用庫,在對特定領域專業內容進行翻譯時經常用詞錯誤,導致翻譯的語句無法理解;二是無法理解上下文的意思,很難根據上下文語境進行釋義。如圖5 所示的句子,來自國防工業、軍事領域,其中幾個專業詞匯,如“Budget Control Act”“the services”及“by services”在軍事領域都有專門的釋義,如果不能理解這些專業知識或相關背景,翻譯效果也很難令人滿意。而當前的機器翻譯采用通用詞匯和通用語料庫,無法正確理解文中的專業詞匯,導致翻譯的語句無法理解。如果翻譯系統具備相關領域專業知識,翻譯效果會好一些。
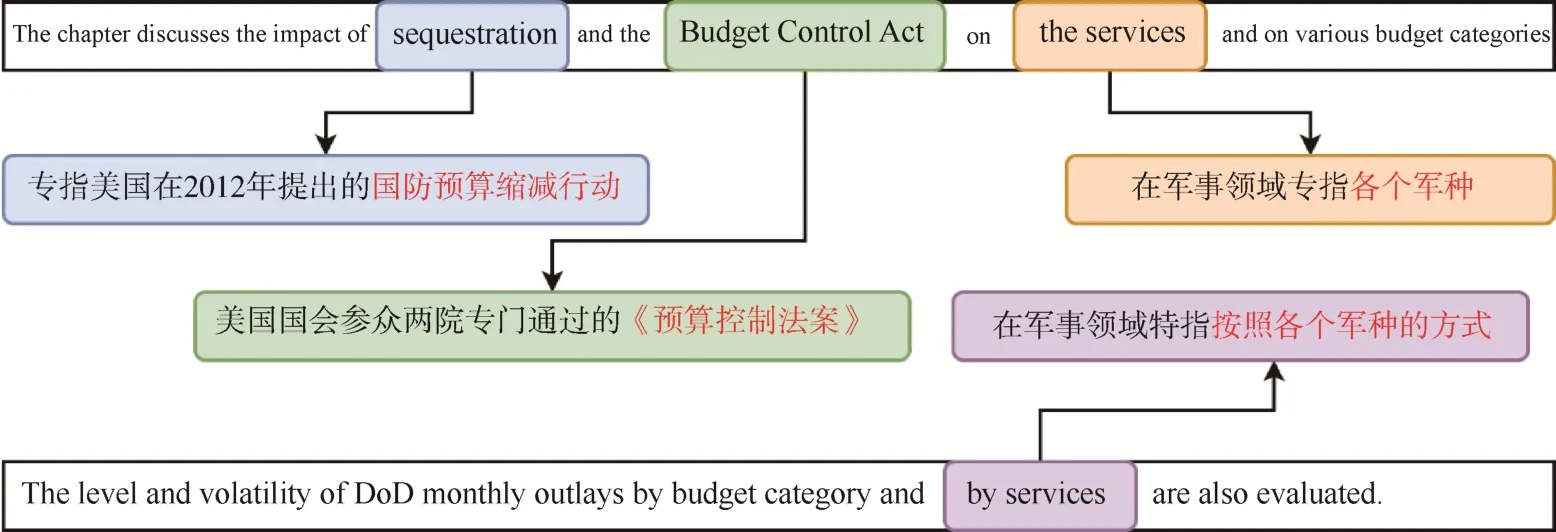
圖5 特定領域內容翻譯句式分析
2.3 難以根據上下文語境確定詞義
任何一種語言中絕大多數詞匯都具有多種語義。在不同的語境和上下文中,詞語會呈現不同的語義,因此在翻譯過程中要結合專業知識及上下文語境,充分考慮詞匯的具體使用場合。當前的機器翻譯系統已經在著力解決上下文語境的問題,如谷歌、百度的翻譯系統通過增加長短期記憶網絡(LSTM)、注意力機制等技術手段來提升對上下文的理解,但這些手段主要考慮的仍是在單一句式中的應用,還未擴展到一段話中上下語句之間的語境關聯,而段與段之間的語境關聯更是無從涉及。由于缺乏足夠的上下文語境理解工具,導致很多翻譯簡單機械甚至錯漏百出。如圖6 所示,通過上下文的理解可以判斷原文介紹的是石油鉆探的知識,由此可以確定其中的“well”指的是油井,而“geological picture”是海底巖層的地質狀況,但當前的機器翻譯系統很難聯系上下文確定不同語境下的準確語義,“picture”一詞很容易被機械地理解為圖片、圖像。如何處理詞語在不同語境下的含義,是機器翻譯面臨的一大難題。

圖6 根據上下文語境的詞義分析
3 利用人工智能技術提升情報翻譯質量的方案
機器翻譯存在的上述問題僅憑改進算法、擴大語料庫、采用多種翻譯引擎等手段很難解決,因此我們提出一種利用降噪簡化、領域矯正等人工智能技術提升情報領域機器翻譯質量的方案,如圖7所示。
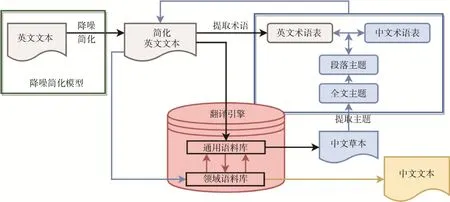
圖7 利用降噪簡化、領域矯正技術的機器翻譯方法
3.1 主要步驟
對一篇專業研究報告進行翻譯時,由于報告中存在大量作者個人語言習慣方面的表述及領域知識,導致翻譯引擎難以獲得較好效果,因此采取以下步驟:第一步,運行英文降噪簡化模塊對英文報告中過于繁雜的表述進行適度簡化(圖7),簡化后的文本更容易被機器翻譯引擎理解;第二步,提取英文術語表,通過利用詞語的多元模型對報告中的高頻專業詞匯(去除通用詞匯)和縮略語詞匯進行抽取,形成情報專用術語表;第三步,將簡化后的英文文本輸入翻譯引擎,由于無法確認報告的主題和領域,因此調用通用語料庫進行翻譯,形成臨時的中文譯文(簡稱中文草本);第四步,利用N-gram 模型對中文草本全文及每個章節、段落進行統計分析,提取全文主題詞、章節主題詞、段落主題詞;第五步,利用全文主題詞確定報告所屬領域,對英文術語表進行翻譯;第六步,以中英文術語對照表、全文主題詞、各個章節段落主題詞作為參照指標,將簡化后的英文文本再次輸入翻譯引擎,涉及專業的章節、段落需調用領域語料庫,通用術語調用中英文術語對照表,最后生成中文文本;第七步,對中文文本再次執行降噪簡化,將許多影響文本理解、不利于表達主題的句式結構進行簡化處理,形成簡明扼要的翻譯文本。
3.2 關鍵過程
整個方案包含以下兩個關鍵過程。
一是英文文本降噪簡化。文本簡化任務的目標是在不顯著改變句子原始語義的前提下,將復雜句子轉換為更容易理解的簡單句子。文本簡化可降低分析和理解難度,大幅提升機器翻譯對復雜句式的翻譯質量[15]。目前,英文文本降噪簡化領域有許多現成可用的系統,包括基于短語表的統計文本簡化系統(PBMT-R)[16]、基于深度強化學習的文本簡化系統(DRESS)[17],以及帶有注意力機制的序列到序列神經網絡模型(NTS)[18]等,本文采用的是開發時間較長且相對成熟的統計文本簡化模型(圖8)。經過降噪簡化,得到簡化的英文文本。其中,絕大多數難以理解的多重從句嵌套的長語句都經過了簡化,許多影響報告主題表達的內容經過降噪處理,形成了易于翻譯系統處理的英文文本。
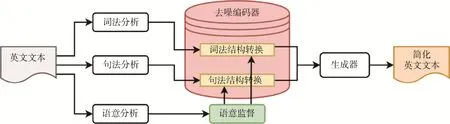
圖8 統計文本簡化模型
二是對特定領域的專業詞匯和用法進行領域矯正。領域矯正是利用機器翻譯系統對簡化英文文本進行初次翻譯,主要包含兩部分。第一部分是對報告中的專用術語進行統一定義。英文研究報告中含有大量縮略語,縮略語可指代的意思較多,機器翻譯在進行通用翻譯時很難識別因此應建立縮略語詞匯表;此外,還需對報告中大量多次重復出現的高頻詞匯(去除通用詞匯)進行統一翻譯。第二部分是對專業領域詞匯或語句進行翻譯。專業領域詞匯或語句存在一些特定的表達方式,利用通用的翻譯手段容易出現偏差,因此需要對這些詞匯或語句進行辨識,并使用專用的領域翻譯模塊進行翻譯。領域矯正的主要過程如圖9 所示。
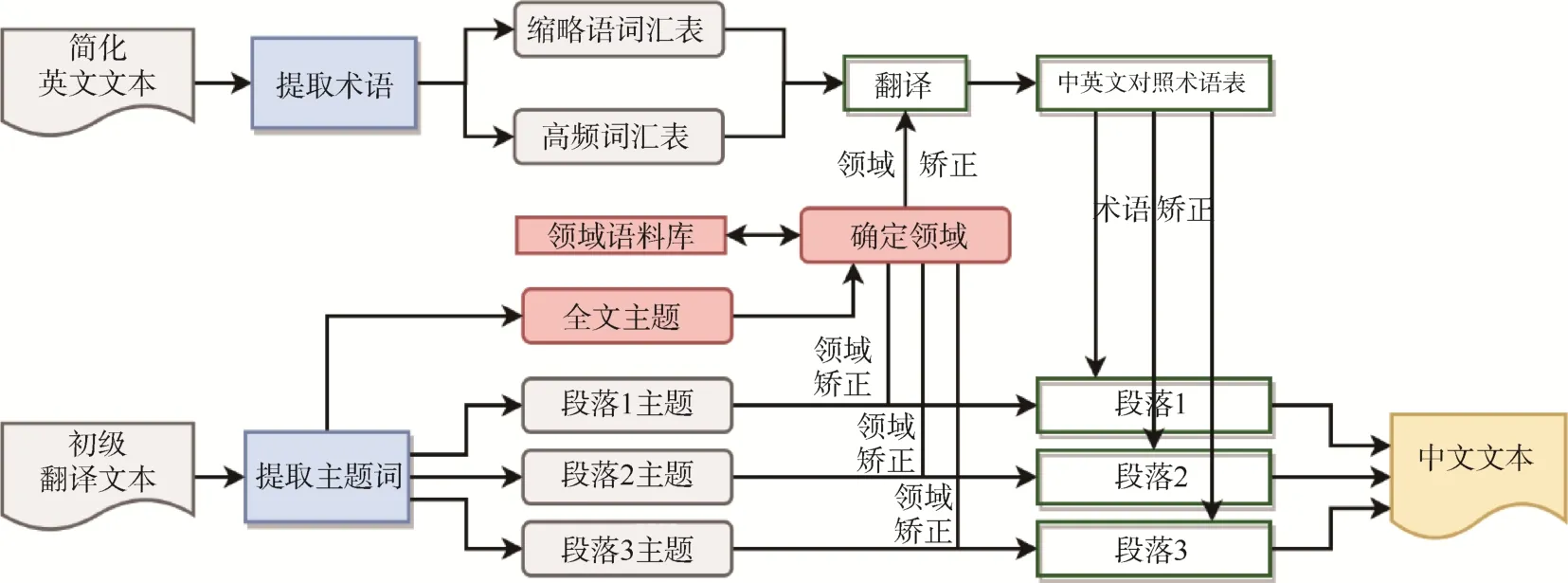
圖9 領域矯正過程
領域矯正有兩個關鍵。一是利用主題詞提取工具提取全文主題詞和段落主題詞。目前無論中文還是英文,可用的工具都比較多[19-20]。二是確定領域后調用領域語料庫對術語表及各個段落的翻譯文本進行矯正,這個過程可以通過在翻譯引擎中增加插件的形式來完成,在此不再贅述。
3.3 翻譯效果評判
為評判本文所提方法的效果,下面從《美國聯邦數據戰略2020 年行動計劃》中選取一句多重從句嵌套的長語句(縮略語)(圖10),其中有幾個專業詞匯,如CAP、FDS 等,也涉及到上下文語句環境。圖10 展示了當前機器翻譯系統翻譯的結果。

圖10 當前機器翻譯系統翻譯結果
從圖10 可以看出,現有的機器翻譯系統不能很好地破解長句式,無法理解上下文環境,不能明確專業詞匯的意義,因此很難將語義正確地翻譯出來,該翻譯結果在句式分析、專業詞匯理解、縮略語解構等方面均不理想。
為此,對上述文本進行降噪簡化和領域校正處理,過程如圖11 所示。首先進行文本的降噪簡化,將難以理解的從句嵌套長句式轉化為4 個簡單句式,然后進行術語提取,將專業領域詞匯提取出來;其次,調用翻譯引擎,對4 個簡單句式進行翻譯,通過比對提取主題,確定相關領域并調用領域詞匯表對前期提取的相應術語進行翻譯,最后利用中英文術語對照表對翻譯初稿進行校對,得到最終文本。

圖11 降噪簡化及領域矯正樣例
經驗證,算法匹配能夠有效解決情報翻譯過程中存在的特定領域詞匯句式翻譯不準確、結構復雜長句式理解偏差、無法根據上下文靈活用詞等問題,可提升研究報告、學術論文、專著等長篇報告的翻譯質量,為情報研究工作中的文獻處理提供更大助益。
4 結語
本文屬于人工智能技術在機器翻譯領域的簡單應用。2017 年,國務院發布了《新一代人工智能發展規劃》,將發展人工智能技術作為未來重要的國家戰略。未來10-20 年,大數據、人工智能技術將高速發展,并將在多個新領域大放異彩,機器翻譯將是一個很有可能取得突破性發展的領域。當前的人工智能技術已解決許多過去傳統機器翻譯面臨的技術障礙,在簡單文本翻譯方面取得較大進展,在復雜文本翻譯方面也為翻譯人員減輕了大量的工作量,大大提升了翻譯效率。
猜你喜歡
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
電子制作(2018年18期)2018-11-14 01:48:06
鄱陽湖學刊(2016年6期)2017-01-16 13:05:41
中國遠程教育(2016年6期)2016-12-07 10:07:02
財經(2016年19期)2016-08-11 08:17:03
中國遠程教育(2016年5期)2016-06-29 10:13:42
小學教學參考(2015年20期)2016-01-15 08:44:38
