基于局部敏感哈希的隱私保護實時服務推薦*
2022-02-16 08:32:40和鳳珍
計算機與數字工程 2022年1期
和鳳珍
(1.麗江文化旅游學院信息學院 麗江 674199)(2.麗江師范高等專科學校數學與信息技術學院 麗江 674199)
1 引言
信息技術和互聯網的快速發展改變了人們的生活消費方式,同時也產生了信息過載問題。如何快速從過載的信息中提取有價值的、能夠滿足用戶需求的信息仍具有挑戰性。服務推薦(如文獻推薦[1~2]、健康推薦[3]、新聞推薦[4~5]、電影音樂推薦[6~8]等)是解決信息過載問題的有效方式之一。
研究人員已經提出一些推薦算法和模型,其中協同過濾推薦方法是最有效的,也是應用最為廣泛的推薦算法[6,9]。協同過濾算法分析用戶的歷史行為數據并為其自動推薦一些與用戶興趣愛好相匹配的top-k物品,其側重于改善推薦結果的準確度,卻忽略了推薦效率。
例如,k 近似最近鄰(Approximate Nearest Neighbor,ANN)協同過濾算法通常需要窮舉搜索數據集中所有用戶或物品才能發現k個最近鄰居。其計算代價非常高,尤其是在大體量數據中。現有n個用戶和m個項目,利用余弦距離進行相似度計算時,基于用戶的協同過濾推薦算法時間復雜度為n2m;基于項目的協同過濾推薦算法時間復雜度為m2n,而且用戶、物品的數量及用戶行為數據更新頻繁。基于矩陣分解的協同過濾算法[10]在Netflix 大賽中表現突出,其需要經過模型訓練和推薦兩個步驟。盡管模型訓練可以離線完成,但是,用戶、物品的數量及用戶行為數據更新頻繁,模型也需要頻繁調整更新。這些都將降低協同過濾推薦算法的效率,影響服務推薦的體驗效果。
此外,用戶的歷史評級數據可能包含用戶的隱私信息,可能被非法使用,甚至轉售。然而,大多數現有的協同過濾推薦方法很少考慮隱私保護。這可能導致用戶隱私泄露的風險升高。
考慮到傳統協同過濾算法存在的上述問題,我們對傳統協同過濾算法進行擴展:結合高效率的局部敏感哈希技術挖掘相似項,在此基礎上提出基于局部敏感哈希(Locality Sensitive Hashing,LSH)的協同過濾(Collaborative Filtering,CF)算法(簡寫為LSHCF)。LSHCF算法利用了局部敏感哈希函數的性質和其在效率上的優勢以及協同過濾算法較高的準確度,從而使得我們的服務推薦算法在準確率和效率上取得較好折衷,同時還保護了用戶隱私。
文章主要的貢獻如下:
1)利用局部敏感哈希技術過濾了絕大多數不相似的項目,降低了相似度的計算時間;同時,利用哈希技術將用戶行為數據哈希為二進制哈希編碼,保護了用戶隱私。
2)提出一種新的基于局部敏感哈希技術的協同過濾算法LSHCF,算法還在評分預測時考慮了相似項的相似度。
3)在不同規模的數據集上實驗,實驗展示了我們算法在效率和準確率上具有較好的折衷。
2 相關工作
Resnick[11]等提出了推薦系統的概念,隨著信息技術和互聯網的快速發展,推薦系統吸引了學術界和工業界越來越多的關注,成為一個非常重要的研究領域。
文獻[12]最先使用協同過濾推薦算法開發Tapestry 推薦框架,解決電子郵件信息的過載問題。Herlocker[13]等提出基于用戶的協同過濾算法,主要思想是從評分信息中發現與當前用戶偏好相似的最近鄰居,通過整合這些鄰居的偏好進行評分預測,最后生成推薦結果列表回顯給當前用戶,其模擬的是一種“人以群分”的思想。但是,評分矩陣中,用戶的評分信息會經常頻繁更新,這將導致每次推薦后都需要重新進行相似度和最近鄰居的計算。尤其是在大數據中,用戶規模較大,基于用戶的協同過濾系統效率較低。
為解決文獻[13]中的效率問題,Sarwar[14]提出基于項目的協同過濾推薦算法,其模擬的是一種“物以類聚”的思想,與基于用戶的協同過率算法不同之處在于文獻[14]的相似度是在物品與物品之間進行計算的,使用該方法計算項目之間的相似度較穩定。相似度和最近鄰居的計算過程可以離線進行,在系統用戶數量遠小于物品數量的情況下,基于項目的協同過濾算法可提高系統效率[8],顯然,基于項目的協同過濾算法在大數據系統推薦時效率也較低。
上述基于鄰居的協同過濾算法是比較經典的推薦技術,能夠獲得較高的準確度。但是,基于鄰居的協同過濾算法是基于內存進行計算的,需將評分矩陣數據全部裝載到內存后進行計算,當用戶或物品的規模非常大時,無論是基于物品的協同過濾還是基于物品的協同過濾在相似度的計算過程中都會非常耗時,時間開銷代價大。評分矩陣中包含的評分數據越多,協同過濾推薦算法將獲得較高的推薦精度,而實際上,用戶不愿意主動對物品評分,系統引導用戶進行評價的激勵機制也并不多,導致評分矩陣的稀疏率較高[1~2],影響推薦結果的準確度。為解決基于鄰居的協同過濾算法存在的問題,提 出 了Singular Value Decomposition(SVD)[15]、Non-negative Matrix Factorization(NMF)[16]等基于矩陣分解的模型推薦算法和基于聚類[17~18]的模型推薦算法。基于模型的協同過濾推薦算法需進行訓練和推薦兩個步驟,先利用歷史數據離線訓練得到一個模型,再利用該模型快速進行評分預測和推薦。然而,用戶的行為數據經常被頻繁更新,模型也需要不斷的訓練更新,在大體量數據下不能及時產生推薦結果,無法滿足用戶實時響應的需求。
綜上,在大數據背景下,傳統協同過濾算法的效率受到用戶和物品的規模巨大,用戶行為數據頻繁更新等因素的影響;其很少考慮用戶隱私,可能存在用戶隱私泄露問題。因此,提出新的基于局部敏感哈希的協同過濾推薦算法實現高效率推薦和用戶隱私保護。
3 我們的方法
3.1 局部敏感哈希
Gionis[19]提出了LSH概念并證明是一種高效率的近似查詢方法。得益于LSH函數的特性,其查詢結果的準確度也較高,被廣泛應用到視頻、圖像檢索等領域。LSH 的核心思想是原來相似或相近的項目被局部敏感哈希函數哈希到同一個“桶”中的概率很大,而不相似或離的較遠的項目被哈希到同一個“桶”中的概率很小。其過濾掉大多數不相似的項目,降低了相似度計算的數量,提高了計算效率。
文獻[19]將LSH函數定義如下。

3.2 基于局部敏感哈希的隱私保護推薦方法


3.2.1 初始化
在初始化階段,輸入評分矩陣M中用戶數量n,LSH tables 數量h以及每個LSH table 包含LSH functions的數量r,根據算法1完成初始化工作。

3.2.2 離線生成索引
在離線生成索引階段,需對評分矩陣M中每個用戶或者項目進行哈希,每個哈希函數哈希后都會得到一個0 或1 的布爾值,經過LSH table 中的哈希函數哈希后生成一串由0和1組成的二進制哈希編碼,該二進制哈希編碼可當作索引,遍歷完所有LSH tables 后生成一個局部敏感哈希索引表,具體如算法2。

3.2.3 查找最近鄰居

3.2.4 評分預測
算法4 對未評分項目集合unrated_set 中每一個項目i利用式(5)進行評分預測,sim()i,m是i與m的相似度,使用Pearson Correation Coefficient距離計算相似度。


3.2.5 Top-k推薦
選擇鄰居集合中評分大于閾值threshold 的項目作為候選集,按照評分降序排列后取前k項作為推薦結果集,具體如算法5。

4 實例
為更加簡潔明了地理解我們提出的方法,本節通過一個實例進一步詳述所提算法。如表1 所示,現有6 個用戶對5 個物品的評分數據,其中0 表示用戶尚未對物品進行評分。矩陣中每一行代表一個用戶向量。
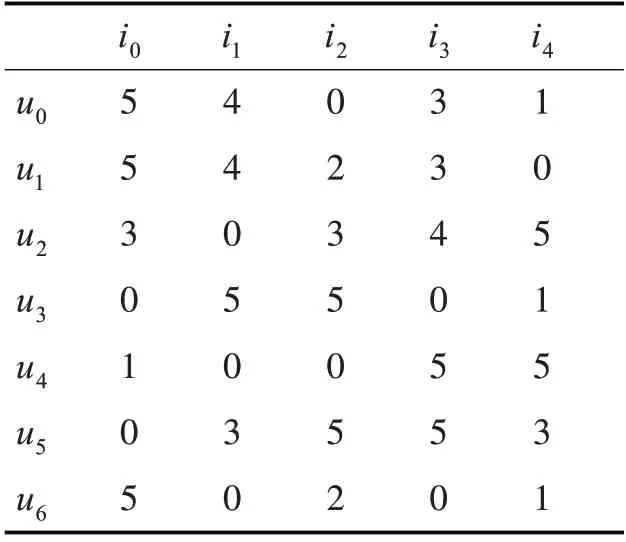
表1 用戶-項目評分矩陣
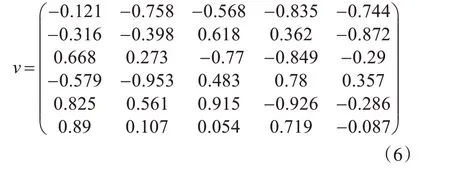
步驟1:初始化。我們從[-1,1]中隨機生成6個向量v,如等式(6),v中每一行為一個向量。為方便演示,我們僅使用1個LSH table。
步驟2:離線生成索引。將每個用戶向量與向量v中的每個向量按照式(3)、(4)的局部敏感哈希函數建立索引,將每次哈希后得到的0 或1 的二進制哈希編碼合并后便可以得到每個用戶的二進制哈希編碼索引。經過計算后,得到用戶u0,u1,u2,u2,u3,u4,u5,u6的二進制哈希編碼分別為001011,001011,000111,010011,000101,010111,001011。
步驟3:查找最近鄰居。設用戶u6為目標用戶,查找與用戶u6在同一個LSH table 中并且具有相同二進制哈希編碼的鄰居有u0,u1。
步驟4:評分預測。通過PPC 相似度計算得到用戶u6與用戶u0,u1的相似度分別為0.302325,0.413665。利用式(5)計算用戶u6尚未評分的物品i1,i3。
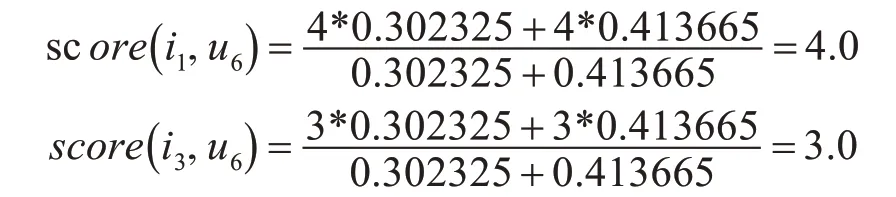
步驟5:top-1 推薦。按照評分降序排列,選擇評分大于閾值0.5的top-1物品i1推送給用戶u6。
5 實驗
實驗環境為Win 10 專業版64bit,Intel Core i7-3367U CPU,RAM 8GB,程序設計語言為Python3.8,實驗使用Anaconda3(64-bit)開發工具,采用k折交叉驗證法,實驗結果為重復執行實驗50次后的平均值。實驗在MovieLens(http://grouplens.org/datasets/movielens/)ml-latest-small(簡 寫為ml-small),ml-1m 兩個不同規模的數據集上對比所提方法的效率,同時與主流了協同過濾算法對比所提方法的準確度。兩個數據集的詳細信息如表2所示。
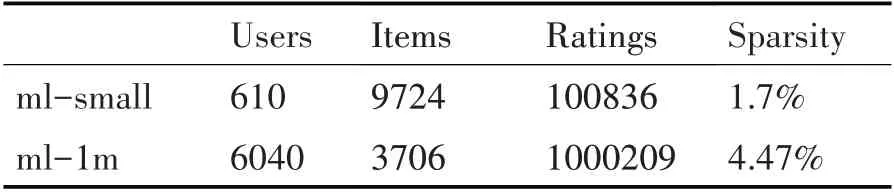
表2 數據集
5.1 評價指標
效率上使用時間開銷進行度量;準確率上,文獻[13]對協同過濾推薦系統提出了度量方法,本文也是一種基于協同過濾的top-k推薦,實驗結果的準確度采用文獻[13]中的F1 作為度量標準,F1 定義如下:

其中,R(u)為用戶u的推薦結果集,T(u)為測試集中用戶u喜歡的物品集合。
5.2 對比算法
我們從準確率和效率兩個方面與下面主流的協同過濾算法進行對比,這些主流算法能夠獲得較高的準確率、效率。
UBCF:文獻[13]提出的基于用戶的協同過濾推薦算法,能夠獲得較高的準確率,同時,當用戶數量遠小于項目數量時,UBCF還能獲得較高的效率。
IBCF:文獻[14]提出的基于項目的協同過濾推薦算法,能夠獲得較高的準確率。
LSHCF:我們提出的基于局部敏感哈希技術的協同過濾推薦算法。
5.3 實驗結果
5.3.1 選擇參數tables和functions
實驗設置LSH tables、LSH fuctions 的數量均為[2,4,6,8,10],當LSH tables 取2 的時候,觀察F1值在LSH fuctions 在[2,4,6,8,10]上的變化情況,改變LSH tables 的數量,進行25 組實驗,每組實驗重復進行50次。F1的變化情況如圖1所示,從圖1可以觀察到,隨著LSH tables 數量的持續增加,準確率先上升,再保持穩定,后下降。也就是說,LSH tables 的數量應適量。隨著LSH fuctions 數量的增加,準確率整體呈上升趨勢,LSH fuctions 數量增加,計算量也將增大。綜合圖1 中(a)、(b)兩圖可以觀察到:LSHCF在LSH tables取6,LSH fuctions取10時能夠獲得較高的準確率。
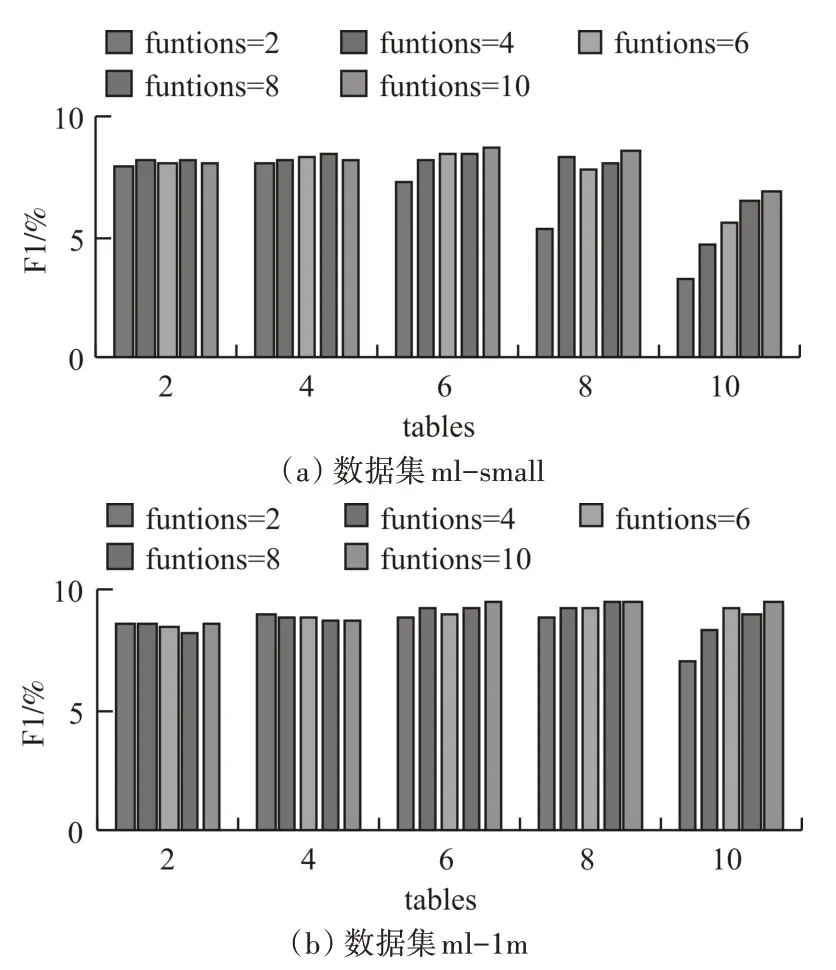
圖1 LSHCF在不同tables和functions的F1
5.3.2 LSHCF推薦結果準確率
在LSH tables=6,LSH fuctions=10 時,觀察topk與precision,recall 和F1 的變化情況。由圖2 可以看出,隨top-k 不斷增大,四種推薦算法的precision 呈下降趨勢,LSHCF 推薦算法表現最好。由圖3 可以看出,隨top-k不斷增大,四種推薦算法的recall 呈上升趨勢。由圖4 可以看出:在兩個不同規模尺寸的數據集上,UBCF 和IBCF 協同過濾推薦算法的F1相當;我們提出的LSHCF在top-k=5時能夠取得與UBCF 和IBCF 相當的準確度,隨著top-k的不斷增大,LSHCF 的F1 值在提高。與主流算法對比顯示,LSHCF能夠取得較好的準確率。
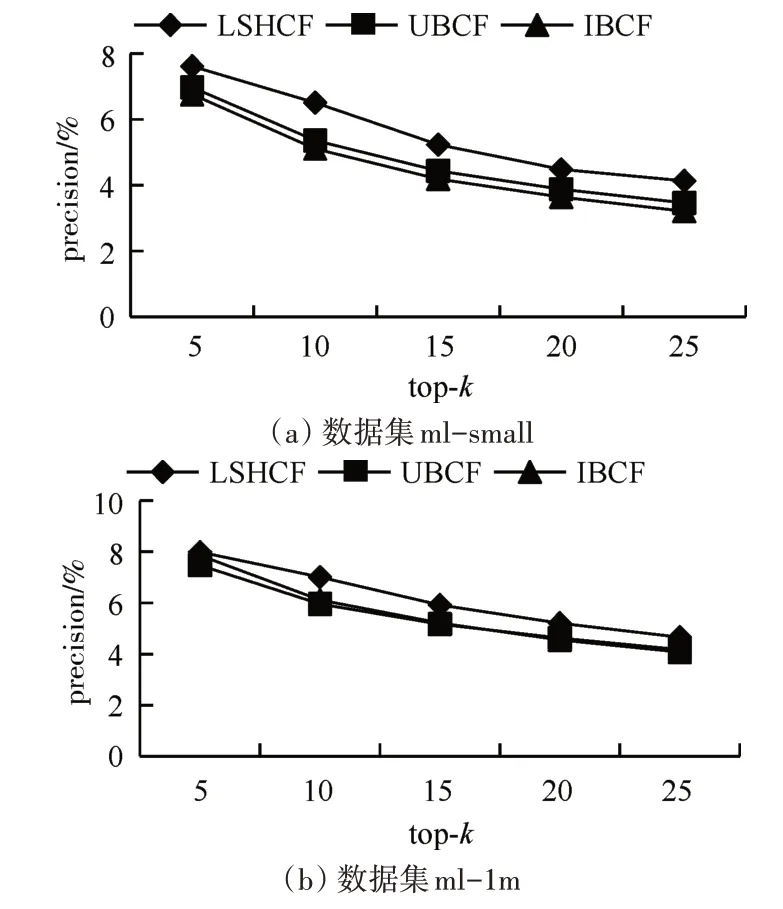
圖2 top-k下precision的變化
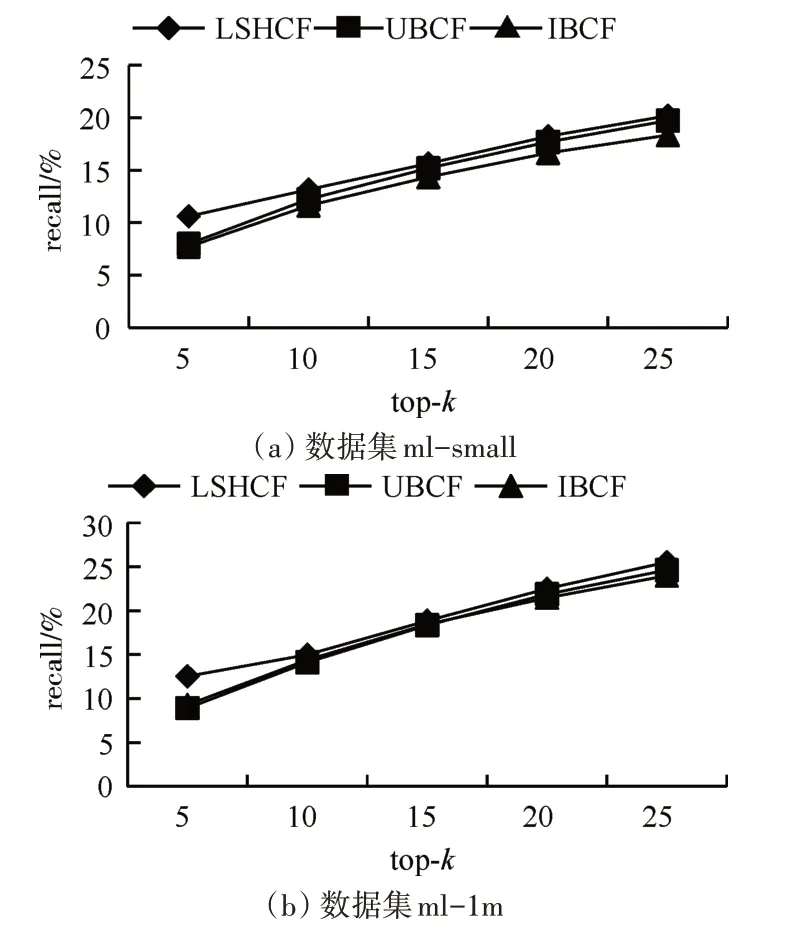
圖3 top-k下recall的變化
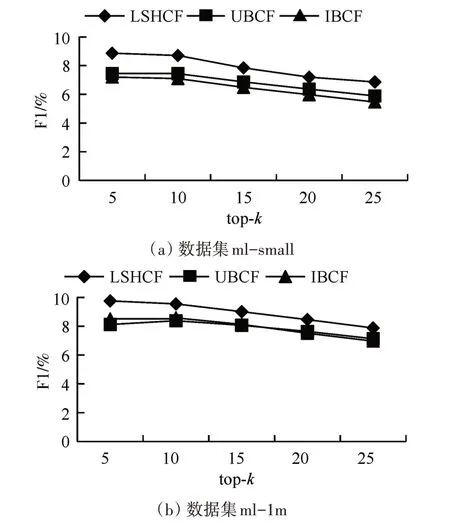
圖4 top-k下F1的變化
5.3.3 效率
在同樣的實驗設置下,我們進一步觀察LSHCF的效率。從圖5 中可以看到,LSHCF 隨數據規模的增加,LCHCF算法推薦效率仍較高。
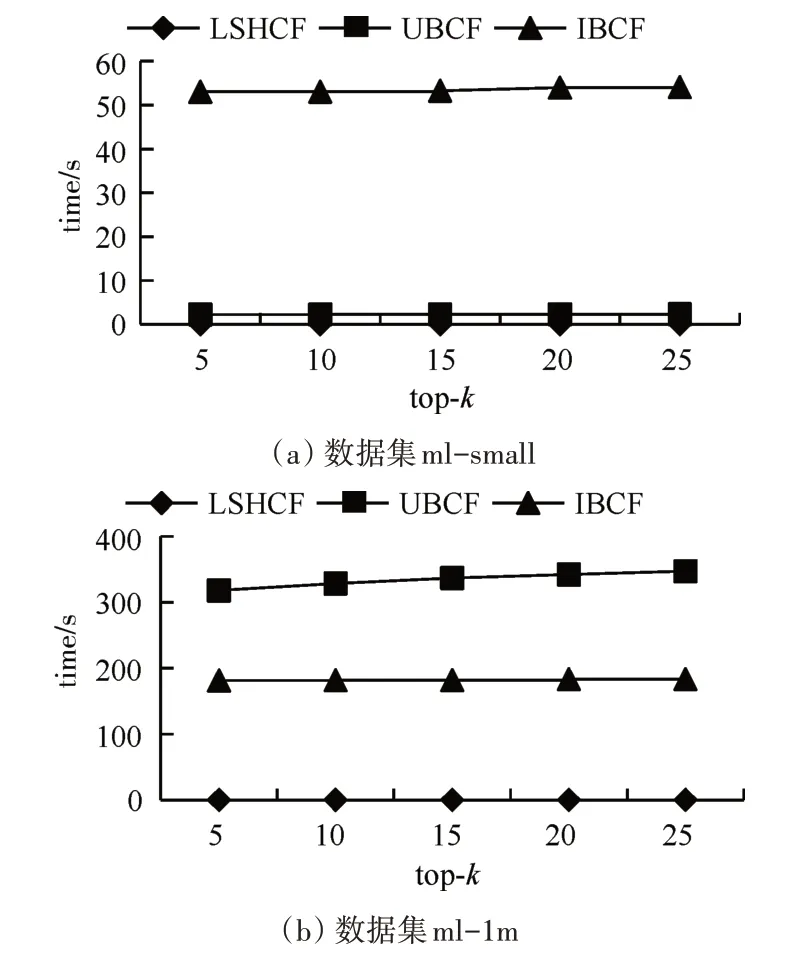
圖5 top-k下F1的變化
6 結語
我們提出的基于局部敏感哈希的隱私保護實時服務推薦方法LSHCF,能夠獲得較好的準確率和效率上的折衷,同時保護了用戶隱私。所提算法僅使用了用戶評分矩陣,后續將考慮利用更多的項目信息(如類別、時間等)進一步擴展算法,改善推薦質量。
猜你喜歡
甘肅教育(2020年14期)2020-09-11 07:57:42
中學生數理化(高中版.高考數學)(2020年5期)2020-06-02 09:19:08
商周刊(2017年9期)2017-08-22 02:57:49
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
時代英語·高二(2015年1期)2015-03-16 00:08:11
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
創業家(2015年5期)2015-02-27 07:53:25
