社交網絡用戶謠言轉發行為預測算法*
2022-02-16 08:33:58劉笑影
計算機與數字工程 2022年1期
方 冰 劉笑影
(上海大學管理學院 上海 200444)
1 引言
預測謠言傳播具有重大意義,這是因為謠言在社交網絡上更易傳播,社交網絡上的謠言具有極大的破壞性,并且往往傳播速度比普通信息更快[1]。由于社交網絡特有的傳播方式:社交網絡上的信息傳播參與者除了有信息發布方之外,信息的接收方同時也是信息傳播的參與者,而且是主要參與者。這種傳播方式使得社交網絡上的謠言傳播速度更加迅速傳播范圍更加廣泛,其造成的恐慌和后果也更加嚴重。鑒于此,對社交媒體謠言傳播的研究就變得愈加重要和緊迫。
現有的預測謠言傳播的研究主要分為兩類:第一類是基于經典的謠言傳播模型,如流行病傳播模型和SIR 模型。第二類是采取機器學習的方法,通過識別特征進行訓練模型。然而這些研究都針對謠言在大規模群體中的傳播規律,鮮少涉及到謠言在具體個體中的傳播規律。而這方面的研究對于精準定位謠言傳播者以及高效切斷謠言傳播途徑具有不可或缺的作用。
為了克服這一局限性,本文提出了一種新的基于信息傳播理論的謠言個體轉發預測算法。該算法基于社會網絡理論,認為用戶轉發謠言是受到謠言發布者以及謠言內容的共同影響。本文通過使用NLP相關技術和復雜網絡分析算法等技術,計算這兩大類影響力強度,最后利用這兩大類特征構建社交網絡用戶個體謠言轉發預測算法。
2 相關工作
現有的預測謠言傳播的研究主要分為兩類:第一類是基于經典的謠言傳播模型。第二類是基于機器學習方法來預測謠言轉發。
2.1 經典的謠言傳播模型
經典的謠言傳播模型主要建立在流行病傳播模型基礎上,最常見的兩種模型是雙態模型和三態模型。Daley 和Kendal[2]首次提出經典的謠言傳播的數學模型,他們將個體分為三類狀態,將未聽說過謠言的人稱為易染者S,聽過謠言并進行傳播的人稱為感染者I,聽過謠言但不進行傳播的人稱為免疫者R。Kermack 和Mckendrick 提出的SIR 模型[3]。Zanette 等[4]考慮了網絡結構對謠言傳播的影響。Moreno 等[5]則面向無標度網絡中的謠言傳播過程,提出了相應的謠言傳播模型。Li 和Gu[6]等在SIR模型基礎上提出遺忘記憶機制。
2.2 基于機器學習的謠言預測方法
基于機器學習的謠言轉發預測研究方法主要聚焦于兩點:改進特征指標、改進算法。
在改進特征指標方面,Morchid 等[7]的實驗選取的指標主要有信息的形式、信息的內容、信息的情感,用NLTK、SNOWNLP 等技術算出信息的情感指標和信息發布者的影響力,用粉絲數量衡量。其綜合以上指標對于信息轉發進行預測。Nesi,P.等[8]選取微博鏈接數、@用戶數目、標簽數、博文點贊數、tweet 發布時間、博文持續時間、博主在此博文后續發布其他博文數量、博主粉絲數等指標進行預測博文轉發。在改進算法方面,Zhao 等[9]依據用戶粉絲的興趣、用戶行為和博文內容來預測信息被轉發的次數。Huang 等[10]使用貝葉斯算法對用戶興趣進行分類,并根據微博內容預測用戶是否感興趣,在預測用戶轉發行為的同時也對用戶興趣建模。羅知林等[11]構建了隨機森林算法預測用戶會轉發哪些信息。
綜上所述,經典的謠言傳播模型的不足主要在于沒有考慮更加全面合理的影響因素,因此不能準確預測謠言的傳播。基于機器學習的謠言預測研究大都只是提出特征,而未提出一個完整的特征框架。針對兩類研究的不足,本文基于信息傳播理論與社會網絡理論,首先考慮到更加全面合理的影響因素,其次建立了社交網絡上用戶個體謠言轉發行為的影響因素框架,此框架為后來的研究者在研究社交網絡上謠言轉發行為的過程提供理論幫助。
3 研究框架
由信息傳播理論,人們在與他人的交流和互動中受到影響的過程的中心作用,這導致了社會影響的產生[12]。Wellman 提出人們通過交流和互動形成的社會關系,使他們能夠學習和反思他人的選擇或意見[13],由此產生的社會影響的強度反映了連接它們的社會關系的強度。此外,Morchid[14]等提出信息的傳播除了與發布者影響力密切相關外也與信息本身的影響力有很大關系。
綜上所述,根據信息傳播理論,本文認為用戶最終是否傳播特定謠言受到:發布者影響因素和謠言內容影響因素的共同作用。如圖1所示。
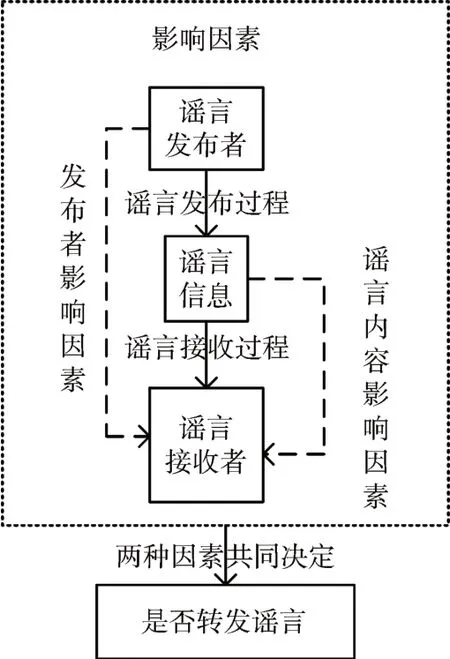
圖1 用戶轉發謠言影響因素
因此用戶是否轉發謠言受到兩種影響因素的共同作用:發布者影響因素和謠言內容影響因素。基于此,本文提出了新的預測謠言轉發算法。如圖2所示。
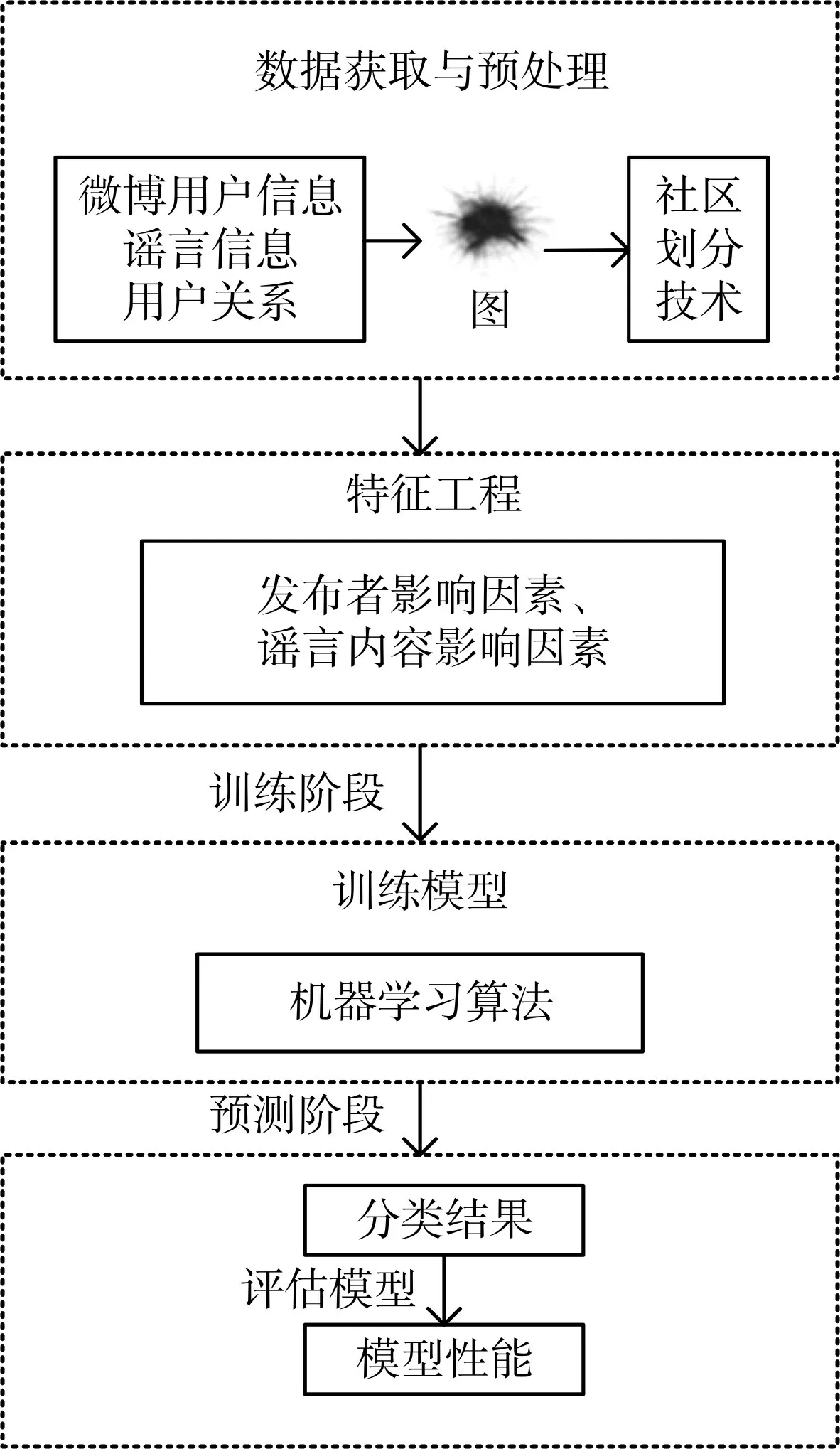
圖2 研究框架
3.1 社區劃分
為了更好地研究基于社交網絡拓撲結構影響的立場檢測,我們將大型的社會網絡劃分成多個獨立的社區[15]。本文采用最大化整個數據模塊度的社區發現算法——Louvain算法[16]。
3.2 特征提取
3.2.1 發布者對個體用戶的影響力強度
假設V={v1,v2,…vn} 是微博社交網絡上一組用戶。Wasserman 等[17]指出成對的微博用戶是通過社會關系將他們聯系在一起,且在微博社交媒體網絡中這種社會關系存在是定向的。Brown 等[18]提出社會關系的強度反映了通過關系采取行動的強度。因此我們可以使用用戶之間的關系強度來衡量用戶通過關系轉發謠言的概率。
我們使Xij代表:用戶vi對用戶vj的社會影響力,即社會關系強度。在有向的社會聯系中,Xij一般不同于Xji。Xij=0,代表用戶vi與vj沒有社會聯系。
社會聯系的強度Xij可以通過互動強度來測量[24]。在本研究中,Xij由vi與vj之間的互動強度來衡量,互動強度可以通過三個維度進行衡量,即可以由vi用戶與vj用戶之間的點贊、轉發、評論的互動頻率進行衡量,如果實體之間沒有互動,則Xij=0。Xij作為三維向量,其表示方式如下:
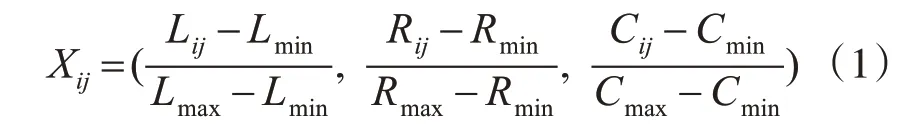
其中:Lij代表用戶vi的微博對用戶vj在于點贊方面的影響力,其衡量標準如下:
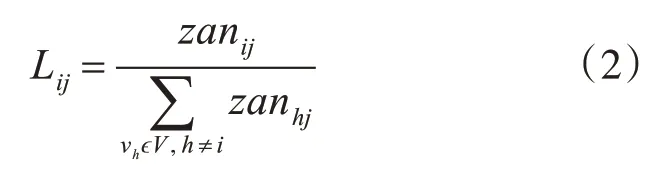
其中zanij表示用戶vi收到用戶vj的點贊數,zanhj表示用戶vh(h≠i)收到用戶vj的點贊數,Lmax和Lmin分別代表用戶之間在點贊方面的最大影響力和最小影響力。
Rij代表用戶vi對用戶vj在于轉發方面的影響力,其衡量標準如下:
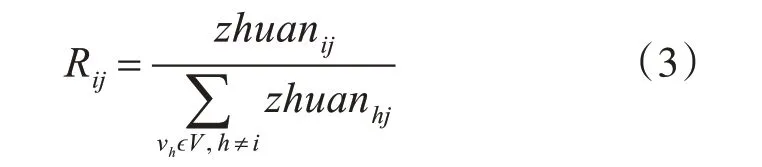
Cij代表用戶vi的微博對用戶vj在于評論方面的影響力,其衡量標準如下:

其中commentij表示vi的微博被vj評論數,commenthj表示用戶vh(h≠i)的微博被用戶vj評論的數量。
我們測量用戶vi對用戶vj的社會影響力(以下簡稱影響力influence power)Iij,通過使用用戶vi和用戶vj的社會聯系強度Xij。

其中Xmax和Xmin分別表示最大和最小的社會聯系強度,標準化有助于避免Iij依賴于Xij的測量單位。
3.2.2 謠言內容對個體用戶的影響力強度
由于用戶對于謠言攜帶特性的敏感度越高,其易感性越高,其轉發謠言的概率越高[19]。用戶對于謠言攜帶的特性的敏感性可以通過歷史數據進行衡量。謠言特性可以通過以下幾個維度進行衡量。根據Lazer 等[1],謠言的主要特性有以下幾點:謠言信息形式(#@url length圖片等)、謠言語義(分別使用謠言的句子向量、LDA、LSA、TFIDF來表示)、謠言迷惑性(模糊性、明確行為、謠言情感、趨利避害)等。
謠言計算:對于謠言在謠言信息形式方面的特征,計算如下:
我們用向量ti=(ti1,ti2,…tik)表示謠言Mi的原始數據字段,此時的特征沒有經過轉化數字、歸一化等處理。例如:謠言t11=(謠言內容-是否有標簽)。Mi1表示謠言Mi其第個特征,且Mip為經過處理的謠言特征向量。例如:M11=(0)。
如果此特征是離散型特征,如是否帶有標簽,是否@用戶,是否帶有網址,是否帶有圖片,是否模糊,是否帶有明確行為等,那么對于謠言Mi其第p個特征Mip的計算方式為

如果此特征是實值或者整數,如此謠言的長度,微博的轉發數、點贊數、評論數,謠言情感等特征,那么對于謠言Mi其第p個特征Mip的計算方式為
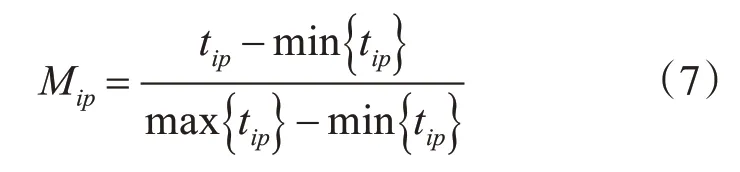
如果此特征是此謠言的語義特征,那么我們使用此謠言的句子向量來衡量,即用此謠言中的所有詞的詞向量Vecn的平均值來衡量此謠言的句子向量,即:
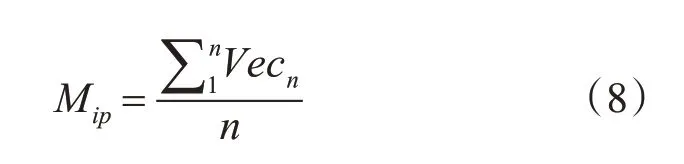
3.3 分類器選擇
本研究提出了預測謠言傳播影響因素的完整框架,把預測謠言傳播問題轉化成二分類問題,并在此基礎上進行了分類實驗。本研究采取預測轉發常見分類方法[20]:支持向量機(SVM),邏輯回歸(LR),樸素貝葉斯(NB),Adaboost(ADA)以及隨機森林(RF)五種機器學習方法進行謠言預測實驗。
4 實驗過程與結果討論
4.1 數據收集
本研究的數據來自新浪微博平臺。數據集包含2018年4月~2018年8月微博平臺上出現并廣泛傳播的9 條謠言微博,涉及38079 位用戶,395622條轉發關系。這些謠言涵蓋了常見謠言話題,如人身安全、健康養生、死亡焦慮、風水迷信等,謠言具體信息見表1。
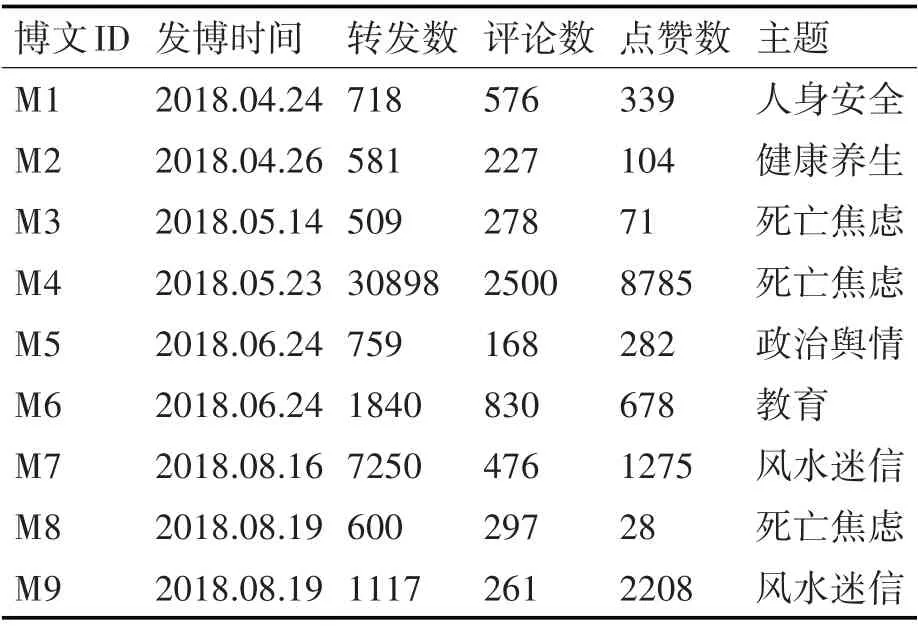
表1 謠言信息分布
4.2 謠言預測實驗
針對謠言預測研究,本文設計了兩個實驗,目的在于證明本研究提出的影響因素框架的合理性以及考慮發布者對于個體的影響而非僅僅考慮對于群體的影響是必要的。
實驗1:為了證明本研究提出的影響因素框架的合理性,即證明兩大影響因素都是有效的。所以實驗設計為評估各個影響因素下的算法預測能力和本研究提出的影響因素框架下的算法預測能力,即分別對謠言發布者對個體的影響因素和謠言內容對個體的影響因素和影響因素框架的預測能力進行評估。
實驗2:為了證明本研究提出的特征能夠更好地預測謠言轉發,因此該實驗為對比試驗。即將特征劃分為兩部分,其中對照組包括(發布者對于群體的社會影響因素、謠言內容影響因素),實驗組則在對比組的基礎上多考慮了發布者對于個體的社會影響因素。
4.3 分類器選擇
對于數據不均衡問題,本文采用欠采樣的方式進行處理。訓練集與測試集按4∶1 進行劃分。實驗1,實驗2采用樸素貝葉斯(NB),隨機森林(RF),支持向量機(SVM),Adaboost(ADA)和邏輯回歸(LR)共5 種機器學習方法進行分類實驗。所有實驗均采用10折交叉驗證。
4.4 評價指標
本文采用最常用的準確率、精確率、召回率和F1值作為評價標準。
4.5 結果分析
4.5.1 探究本研究各個影響因素和特征框架的有效性
我們設計實驗1,得到各個影響因素下算法的預測能力。根據圖3~圖6的結果表明,本研究提出的影響因素框架中2 個影響因素:發布者影響因素和謠言內容影響因素都是合理并且是必要的。
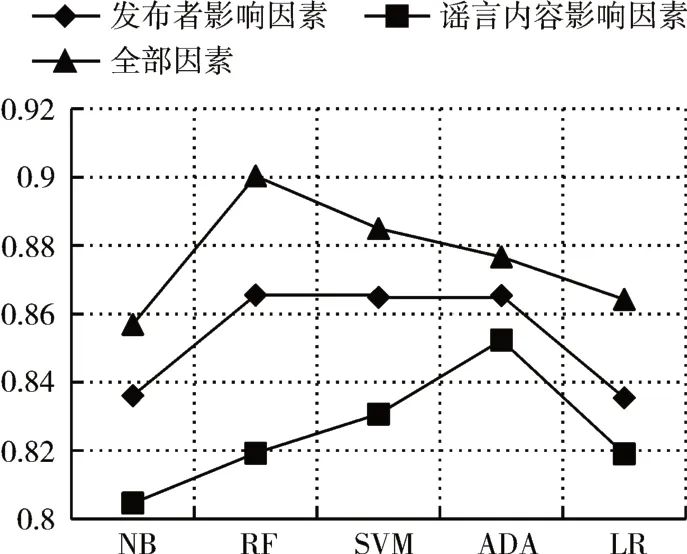
圖3 實驗1準確率

圖4 實驗1精確率

圖5 實驗1召回率

圖6 實驗1 F1指標
4.5.2 探究各特征體系下的算法預測能力
我們設計實驗2 進行對比各個影響因素框架下算法的預測能力。根據圖7~圖10的結果表明基于五個機器學習方法的實驗組結果均優于對照組。這表明本研究提出的特征能夠更好地預測謠言轉發。
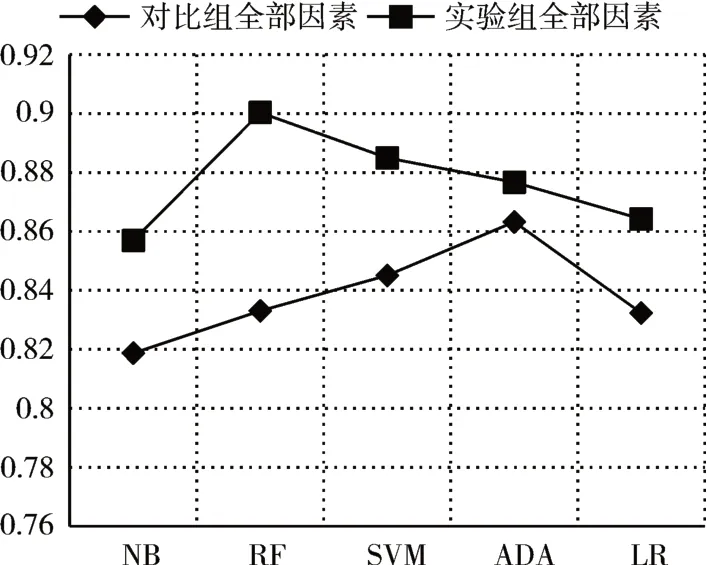
圖7 實驗2準確率
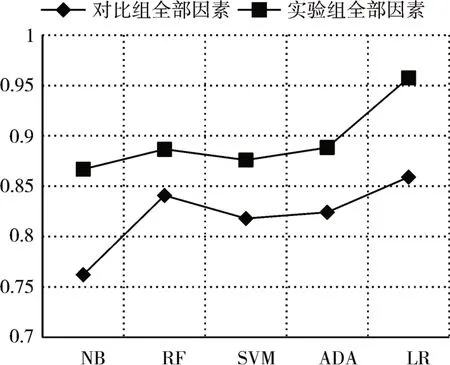
圖8 實驗2精確率
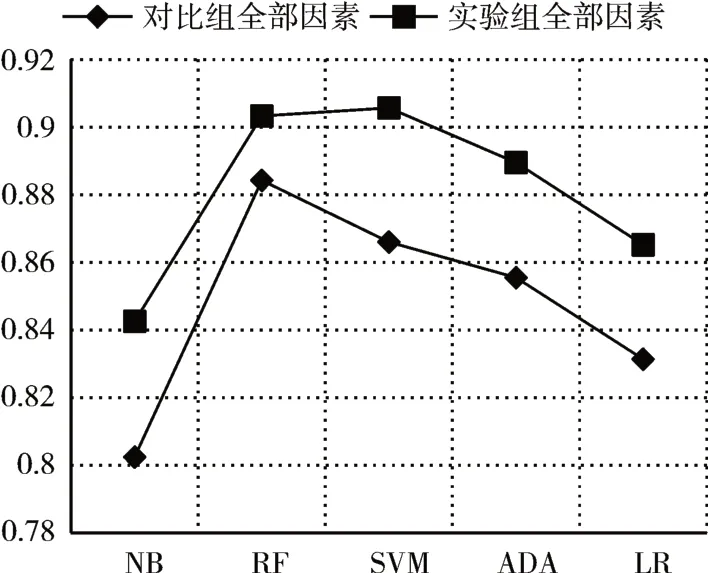
圖9 實驗2 F1指標
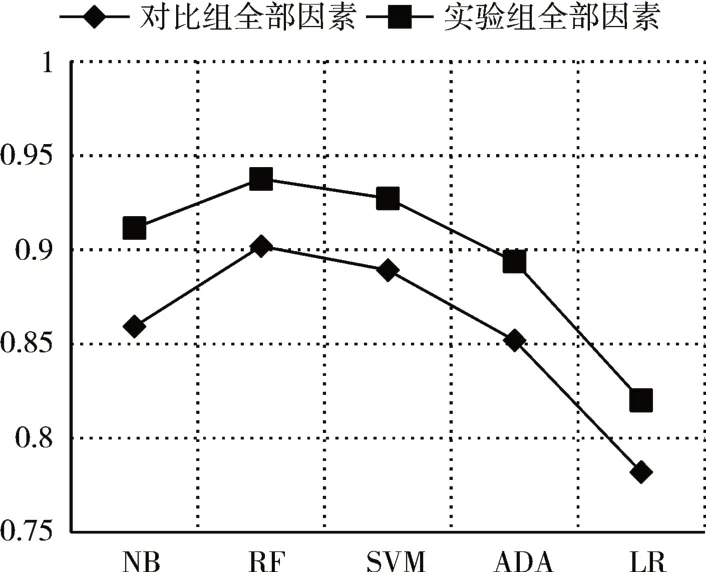
圖10 實驗2召回率
5 結語
本文基于社會網絡分析、語言模型Doc2Vec、信息傳播理論等方面的相關研究,對用戶在社交網絡上轉發謠言這一行為進行深入的研究。本文的創新點如下。
1)本研究首次提出了一個預測謠言個體轉發的預測算法。以前的研究多涉及到了謠言在大規模傳播中的規律,忽視了謠言對個體影響力的研究。由于大規模辟謠的成本較高,而本研究對個體轉發謠言的精準預測可以幫助精準定位受謠言影響道德個體,可以幫助大幅度減少辟謠成本。
2)基于信息傳播等理論,本文首次提出一個完整的社交網絡謠言個體轉發影響因素的框架,這是之前研究所欠缺的。具體而言,此影響因素框架由兩種影響因素組成:發布者對個體的影響力強度和謠言內容對個體的影響力強度。
猜你喜歡
中老年保健(2022年5期)2022-08-24 02:36:04
中學生數理化·八年級物理人教版(2022年3期)2022-03-16 05:55:08
當代陜西(2021年12期)2021-08-05 07:45:46
當代陜西(2021年2期)2021-03-29 07:41:24
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
中國塑料(2016年3期)2016-06-15 20:30:00
商用汽車(2016年4期)2016-05-09 01:23:12
冰雪運動(2016年4期)2016-04-16 05:54:56
劍南文學(2015年1期)2015-02-28 01:15:15
