基于深度學習的中文文本分類算法*
2022-02-16 08:34:00薛興榮靳其兵
計算機與數字工程 2022年1期
薛興榮 靳其兵
(北京化工大學信息科學與技術學院 北京 100029)
1 引言
文本情感識別也稱為情感分析、意圖挖掘[3],它是根據文本所表達的含義和情感信息將文本分為積極、消極的兩種或多種類型,它是特殊的文本分類問題[4]。通過分析和研究這些數據,挖掘出潛在的信息,以此來分析網民對社會熱點話題的關注度和情感傾,從而為相關部門的政策制定提供支持以及正確引導網民的情緒傳播[5~11]。
2 方法
本文提出了一種混合深度神經網絡文本分類模型TBLC-rAttention,如圖1 所示。模型由七個部分組成:1)輸入層:獲取文本數據;2)預處理層:分詞并去除無關數據;3)詞嵌入層:把文本數據映射為詞向量;4)Bi-LSTM 層:提取文本數據的上下文語義特征;5)Attention 機制層:生成含有注意力概率分布的加權全局語義特征;6)CNN 層:在加權全局語義特征的基礎上進行局部語義特征提取;7)輸出層:實現文本分類。
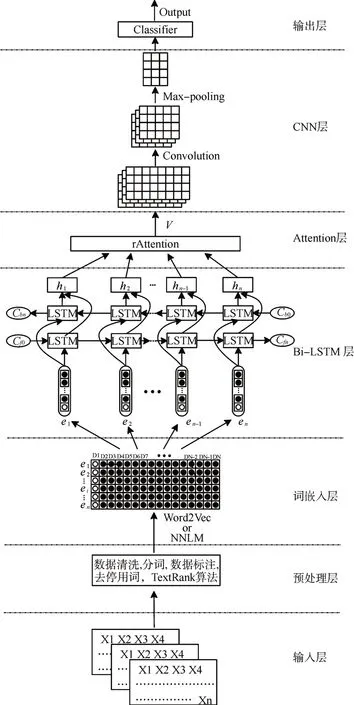
圖1 TBLC-rAttention文本分類模型
2.1 預處理層
對文本數據按照以下方式進行預處理操作。
1)數據清,刪除原始數據集中的無關數據、重復數據以及處理異常和缺失數據;
2)進行類別標簽標注;
3)使用jieba 進行分詞和去停用詞,在分詞的過程中可以使用一些領域專屬名詞以提高分詞的準確度;
4)將預處理完成的文本數據分為訓練集、測試集和驗證集。
2.2 詞嵌入層
詞嵌入是把文本數據轉化為計算機能夠識別和處理的過程[12],如圖2所示。
在這樣的故事情節之中,小說的創作還體現出如下的特點:首先,小說具有歐·亨利特有的結尾方式。即,故事的結局既在人的預料之中又出乎人的意料。因而,它體現出了故事獨有的幽默,體現出了小說主題特有的諷刺。其次,小說語言與眾不同。在小說各種語言描寫中,作者不僅通過巧妙的修辭增強了文學語言的意蘊性,還且通過對時弊的針砭產生了“含淚的微笑”。
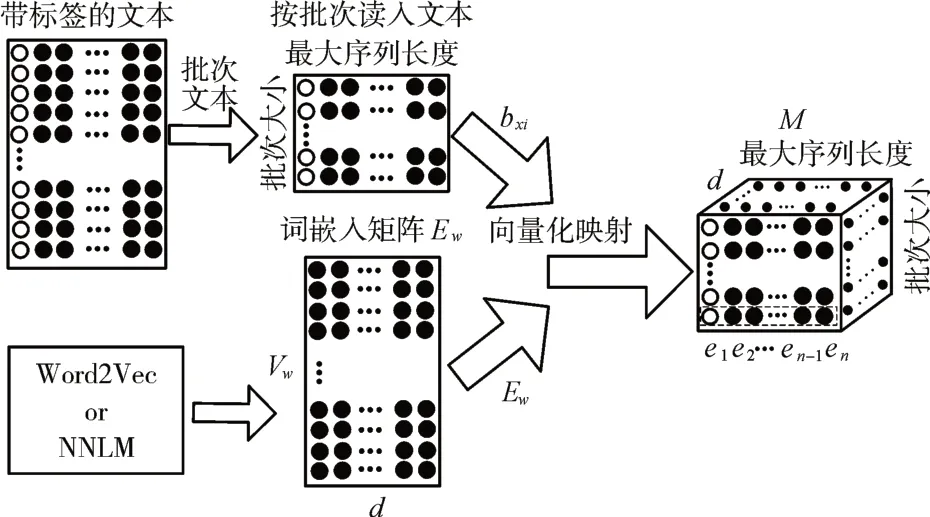
圖2 文本數據向量化表示
通過詞嵌入矩陣Ew的映射,把按批次讀入帶有標簽的文本數據映射為一個三維詞向量矩陣M,Ew可以通過Word2Vec 等方法得到。此時,一個包含n 個字的文本Dj=(x1,x2,…,xn)可以表示如下:
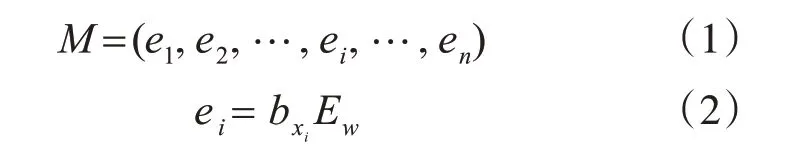
其中,M∈Rbatch×n×d,Ew∈Rvw×d,batch為每一批次讀入的文本數據條數,vw為字典大小,d 為詞向量維度,每個字在Ew中都有一個唯一的用于檢索其對應詞向量的索引bxi。
2.3 Bi-LSTM 層

2.4 Attention機制層
在Bi-LSTM 網絡之后引入注意力機制[14~16],對重要的信息給予較多的關注,模型如圖3所示。

圖3 多注意力機制


其中,V∈Rbatch×r*n×2d為加權全局語義特征,a∈Rbatch×r*n×2d為注意力概率分布,r 為每個文本的Attention 方案數,Wa1∈Rd×n是全局注意力權重矩陣,ba為全局注意力偏置矩陣,wa2∈Rr*n×d為每個文本不同的Attention 方案矩陣,m 值越大說明了該時刻的全局語義特征越重要。
得到每一時刻的ai后,將它們分別和該時刻對應的hi相乘,得到第i 時刻的加權全局語義特征Vi。
2.5 CNN層
把V作為CNN的[17~18]輸入進行局部特征提取,如圖4 所示。每一次卷積都通過一個固定大小的窗口來產生一個新的特征,經過卷積后得到第j個文本包含局部和全局語義特征的Cj,接著采用最大池化方法得到每個文本的最終特征表示C。

圖4 CNN模型
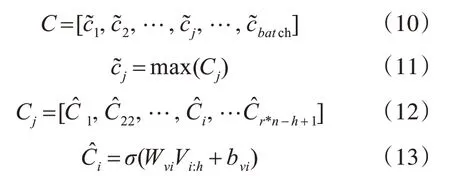
其中,C ∈Rbatch×2d,Cj∈R(r*n-h+1)×2d,Wvi∈R2d×h為卷積核向量,h 和2d 分別為卷積核窗口的高和寬,Vi:h表示第i行到第h 行的加權全局語義特征值,bvi表示偏置。
2.6 輸出層
把C 作為分類層的輸入,分類層采用dropout方式將最佳特征Cd連接到Softmax 分類器中,并計算輸出向量p(y):
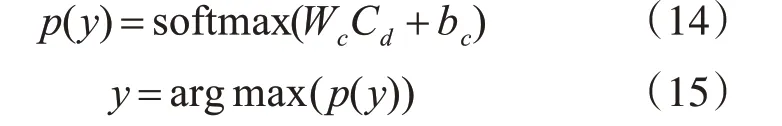
其中,p(y)∈Rbatch×classes,Wc和bc分別表示分類器的權重參數和偏置項,classes表示文本的類別數,Cd為C通過dropout產生的最佳特征。
分類器用于計算出每個文本屬于每一類別的概率向量p(y),然后選擇最大概率y對應的類型作為文本分類的預測輸出,通過分類器層之后,整個模型就實現對文本的分類任務。
3 實驗
3.1 實驗語料
語料數據是利用爬蟲技術爬取某電商平臺上一種感冒藥銷售的評論數據,語料的一些基本信息如表1、圖5和圖6所示。
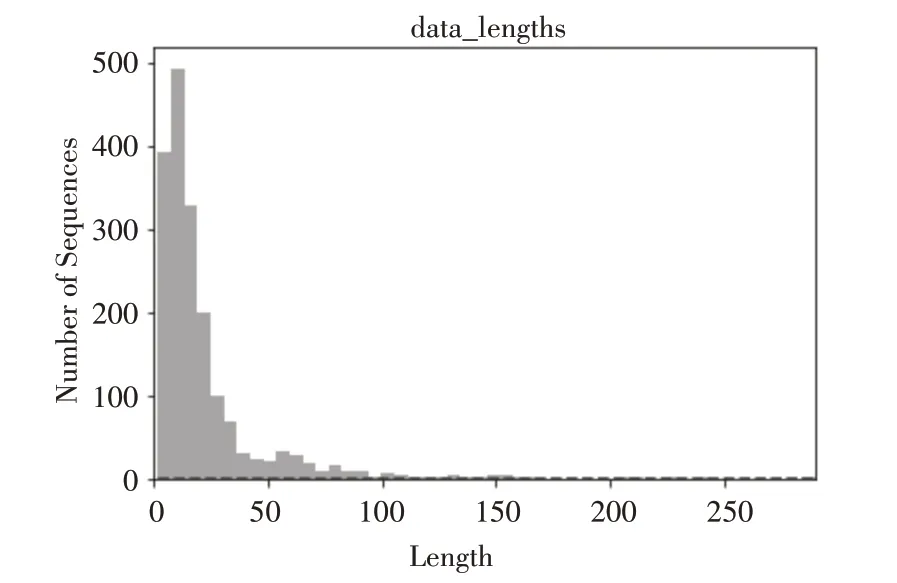
圖5 語料句子長度分布

圖6 語料詞云圖

表1 語料數據信息
3.2 實驗設置
具體實驗設置如表2和表3所示。
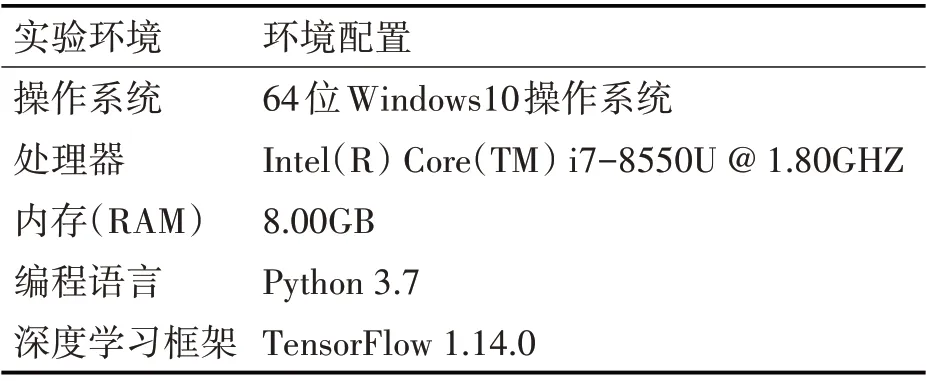
表2 實驗環境
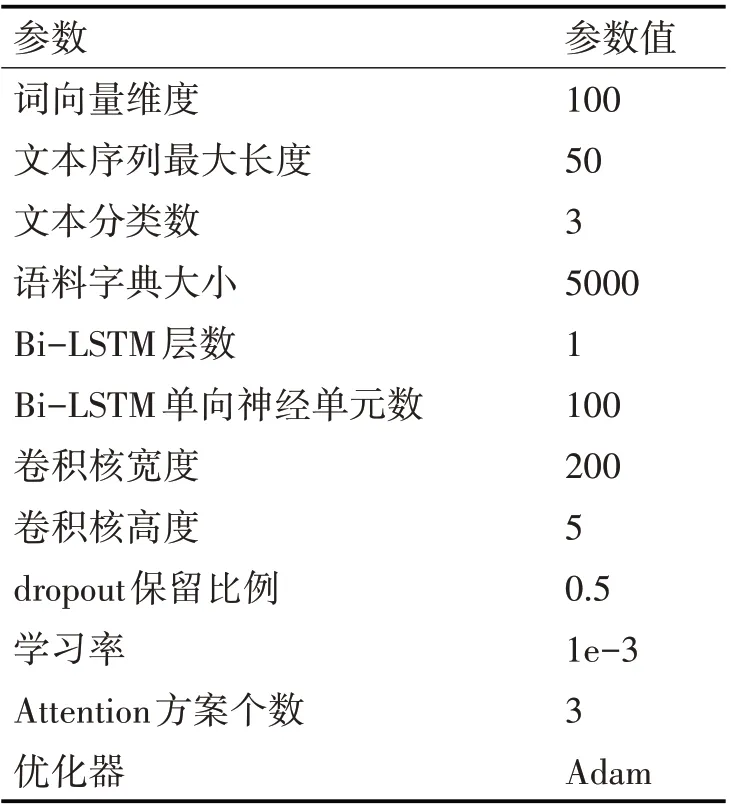
表3 實驗參數設置
3.3 模型訓練

其中,θ為模型當前參數,α為學習率,N 為訓練樣本大小,D 是訓練樣本,L是樣本D 對應的真實類別標簽,Li∈L,y 為分類器的預測分類結果,p(Lj)表示正確分類結果,λ是L2正則項系數。
3.4 評價指標
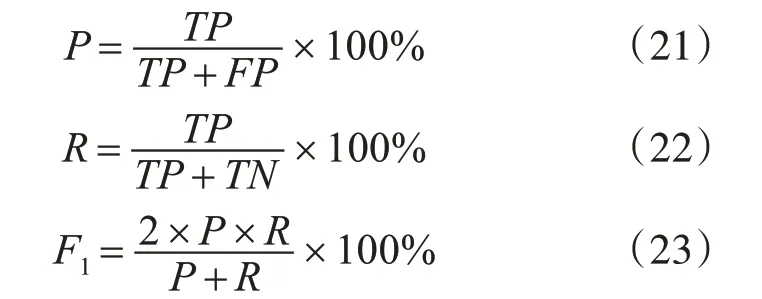
其中,TP 為真正率,TN 為真負率,FP 為假正率,FN為假負率。
4 結果與討論
模型訓練過程的準確度和損失值變化如圖7所示,為了比較本文提出的模型性能,選取了CNN、LSTM、Bi-LSTM、BiLSTM+Attention、RCNN 5 種模型作為比較基準,比較結果如表4 所示,所有結果都是在訓練的準確度和測試準確度都不再變化再循環1000次后得到的結果。
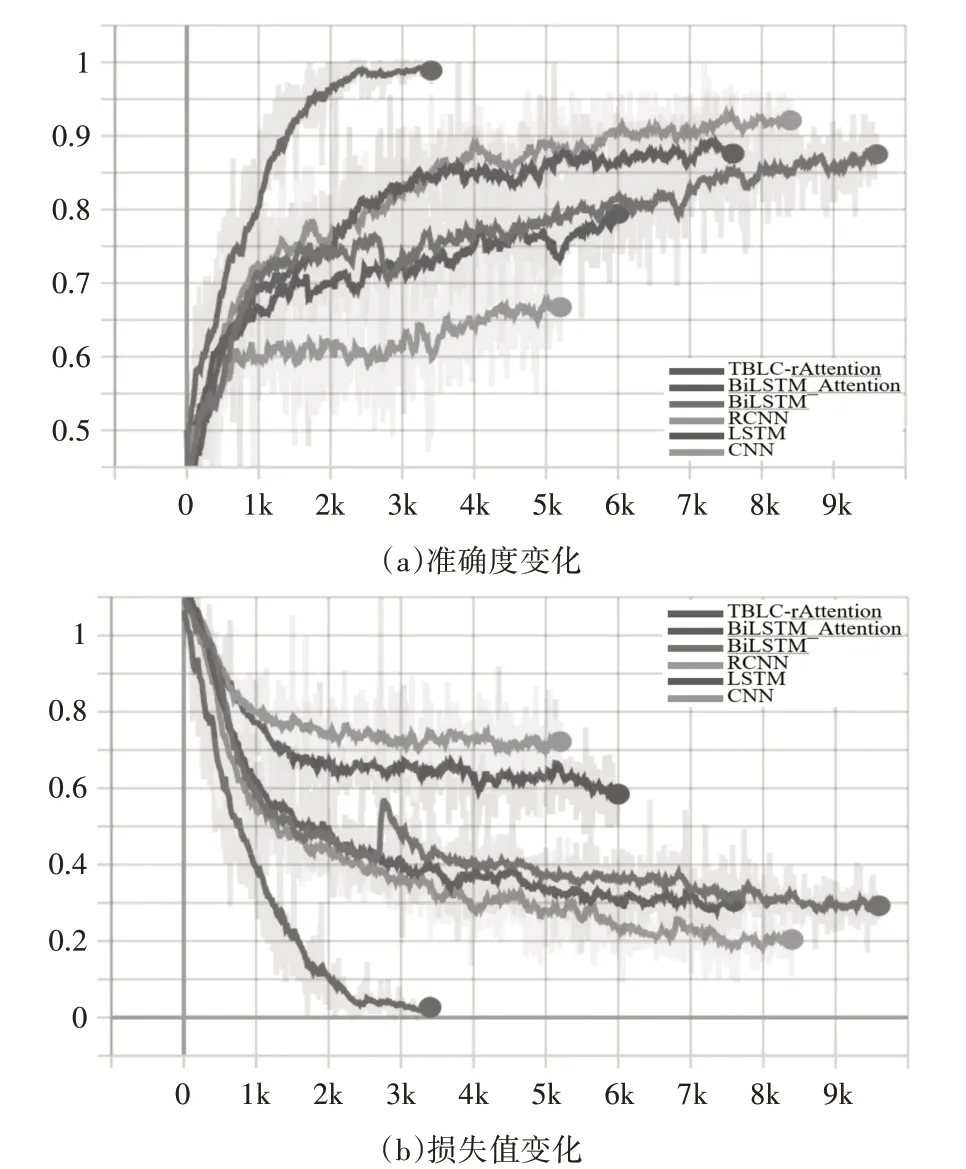
圖7 訓練過程中個模型的準確度和損失值變化
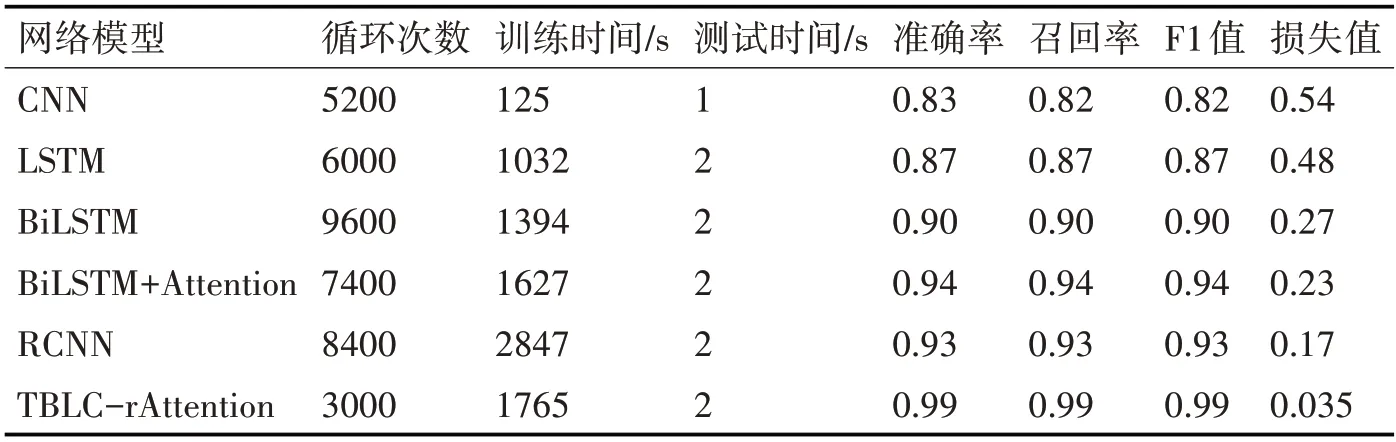
表4 各文本分類模型分類效果對比
在表4 中,通過LSTM 和Bi-LSTM 的實驗結果可以發現,雖然Bi-LSTM 花費的時間比LSTM 多,但是準確度提高了約3%,這是由于Bi-LSTM 網絡通過正向和反向兩層網絡結構來擴展單向的LSTM 網絡的結果,這樣的網絡結構可以充分提取文本的上下文信息,但是空間復雜度是LSTM 的2倍,所以花費的時間比LSTM 略長;在Bi-LSTM 模型中引入Attention 機制準確度提高了4%左右,說明Attention 機制的確可以有效識別出對分類影響較大的特征信息;只使用CNN 時,雖然準確率不是最好的但大大的節省了訓練時間;RCNN 汲取了RNN 和CNN 各自的優勢,分類效果比單獨使用RNN、CNN 都好,與BiLSTM+Attention 效果相近;本文提出的模型分類準確率達到了99%,在本次實驗的所有模型中分類準確度最高,模型在驗證時以100%的準確率實現了數據分類,值得注意的是當消費者沒有進行評論,電商系統會默認為好評,但模型將這類數據視為中評。
5 結語
本文提出了一種基于混合深度神經網絡的網絡輿情識別方法,該方法先提取文本數據的上下文語義特征,再提取局部語義特征得到最終的特征表示,并通過實驗驗證了本文提出模型的有效性。未來的工作是如何對語料數據進行更好的預處理操作,例如進一步減少噪聲數據、更好地進行精準分詞等;同時,研究其他算法和模型,并進行有效的融合和改進,進一步提高分類的準確度。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
