基于圖卷積網絡的視覺問答研究*
2022-02-16 08:32:40姚鑫杰
計算機與數字工程 2022年1期
龔 安 丁 磊 姚鑫杰
(中國石油大學(華東) 青島 266580)
1 引言
視覺問答任務是人工智能領域的新興課題[1]。給定圖像和相關的文本問題,視覺問答的任務是結合輸入的圖像和文本,生成一條人類可讀的自然語言作為輸出答案。該任務融合了計算機視覺、自然語言處理等計算機領域的知識,可視為對通用人工智能技術的探索。視覺與語言是人類最重要的交流方式,讓計算機能同時理解視覺和語言并正確做出反饋,能極大地改善人類與計算機間的交互方式。由于視覺問答任務的多技術交叉性質以及潛在的實用價值,因此對于視覺問答任務的研究很有價值。
視覺問答任務的難點在于需要計算機同時理解圖像和文本。近年來,視覺問答技術得到了迅猛的發展。主流方法為將圖像和文本聯合嵌入到相同的特征空間的聯合嵌入模型。Malinowski[2]等提出了Neural Image QA 模型,該模型以CNN 和LSTM為基礎,使模型可處理可變大小的問題輸入和答案輸出。Yu[3]等提出了一種多層次注意力網絡模型,通過圖像語義層級的注意力來減少與問題語義間的差異。Peter[4]等提出了Bottom-up 模型,以基于殘差神經網絡的Faster R-cnn 提取圖像目標等級的特征,使模型脫離使用圖像的全域特征而關注于特定的目標區域。但這些方法并不能很好地關聯圖像中的目標和文本的聯系。
近年來,由于圖形的強大表現力,用機器學習分析圖形的研究越來越受到關注,圖神經網絡[5](GNN)是基于深度學習的方法,在圖域上運行卷積神經網絡。由于其令人信服的性能和高可解釋性,GNN 最近已成為一種廣泛應用的圖形分析方法,其側重于分類、鏈路預測和聚類。在視覺問答中,圖像中的目標可視為圖的節點,節點間基于問題的聯系可視為邊。綜上,本文在聯合嵌入模型的基礎上結合圖卷積神經網絡(GCN),加強圖像目標和問題間的聯系,通過圖網絡強大的分類能力,以提高視覺問答的準確率。
2 相關工作
2.1 圖卷積網絡
卷積神經網絡的發展促進了圖卷積網絡的研究。應用卷積神經網絡的歐幾里德域數據例如圖像和文本可以看成圖的實例。近年來,卷積運算被推廣到圖域。圖卷積通常被分類為譜圖域卷積[6]和空間域卷積[7]。譜圖域GCN 利用圖的信號處理過程,通過計算圖的拉普拉斯算子的特征值矩陣,在傅里葉變換中定義卷積運算。空間域GCN 直接在圖上定義卷積,學習鄰近空間的信息。Kipf[8]提出了將CNN 擴展為GCN 以連接任意的無向圖。GCN學習圖中每個節點的局部特征,該特征編碼了圖中節點與其鄰接節點關系。在圖卷積層,通過聚合節點本身和其鄰域節點的特征以產生新的輸出特征。通過堆疊多個層,GCN能從更遠的節點接受信息。
2.2 視覺問答
Antol[8]等率先提出了視覺問答任務,用于視覺問答研究的大型數據集VQA[9]、GQA[10]的推出也大大促進了該領域的研究。視覺問答是根據輸入圖像回答給定問題的任務,問題通常處理為詞向量,再用LSTM或GRU編碼,而圖像常由ResNet提取的固定大小網格的特征表示,圖像和問題的融合常用concatenated 和hadaman product。Damien[11]中提出了基于圖形的方法,將問題和圖像抽象為圖形表示,提升了抽象圖像理解的能力。有時,僅靠圖像不足以推斷出正確答案,Narasimhan[12]通過檢索外部知識庫建立了圖像和事實的關系子圖,用視覺概念和屬性作為圖的節點。
3 方法
對于給定的問題和圖像對,為了預測準確的答案,本文提出了一種基于圖卷積網絡的方法。算法流程圖可見于圖2,先提取圖像的目標特征和計算問題的詞向量,再將圖像和問題特征處理為圖結構,模擬圖的鄰接矩陣,其受限與圖像基于問題的關系。鄰接矩陣可用于圖卷積層的運算,卷積后的特征不僅關注圖像目標,也表示了圖像目標和問題的相關性。
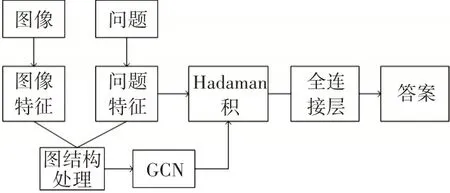
圖1 算法流程
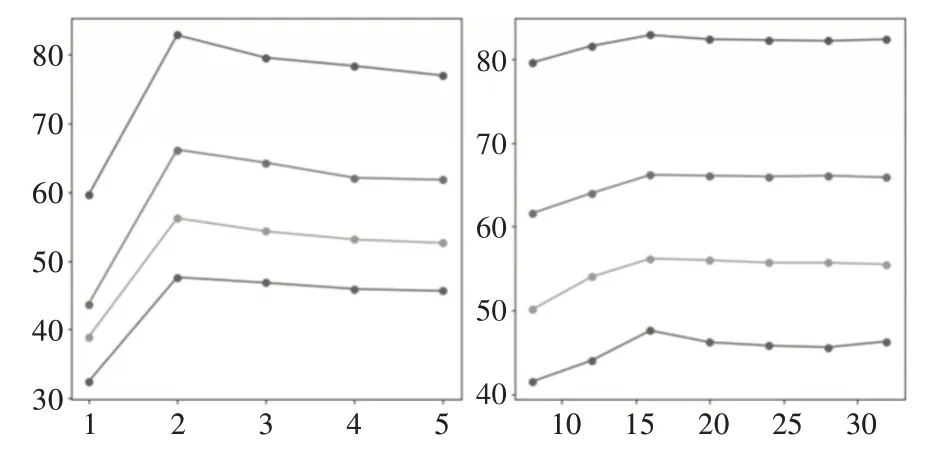
圖2 topMax和Gcn層數的對比實驗
3.1 數據預處理
模型的輸入質量直接影響模型的訓練質量,本模型需要分別處理圖像和問題。
圖像特征提取采用bottom-up的圖像特征提取方法,該方法在視覺問答領域取得了廣泛的應用,其用了基于殘差神經網絡的Faster R-CNN 的目標檢測方法,專注于識別圖像中的特定元素,輸出為圖像中Top-K 個目標區域的resnet 特征。圖像轉化為目標特征V=(v1,…,vn),vi∈RD,n 為檢測到的目標數,D 為特征向量的維度。大多數問題只涉及圖像中的部分區域,在本實驗中,參考demain[13]等的實驗,K設置為36。
輸入問題首先用分詞工具去除標點符號和空格。因為數據集中僅有0.25%的問題超過14 個單詞,為了提高計算效率,所有問題都被裁切為最大14 個單詞,多余的單詞將被丟棄。每一個問題都編 碼 為Glove[14]詞 向 量(Global Vectors for Word Representation),Glove 使用基于維基百科語料庫預訓練的公開版本。問題長度小于14 的用零向量擴充。詞嵌入后的序列用GRU[15](Recurrent Gated Unit)編碼,在處理過14 個單詞嵌入后生成問題嵌入Q。
3.2 基于圖像和問題的圖形表示
模型需要融合圖像和文本的特征,本文使用concatenated 連接圖像和問題的向量表示,對于圖像中的目標區域i=1…K,圖像特征vi用concatenated連接問題嵌入Q,記為[vi,Q],再計算聯合嵌入ji=F[vi,Q],F 為非線性函數。由kipf 歸納的圖卷積網絡的公式可知,使用圖卷積網絡,需要輸入特征的圖形表示。在圖像處理為K 個目標特征后,每個目標區域可構成圖的節點。本文定義一無向圖G={V,E,A},V 為節點,即為圖像的K 個目標檢測區域的特征向量的集合,每一個特征向量vi∈V,A為鄰接矩陣,邊的關系可用鄰接矩陣表示,其代表圖像和問題的聯系。將每張圖像和問題聯合嵌入的K 個ji組成矩陣M,該矩陣融合了圖像和問題特征。由于鄰接矩陣為方陣,令a=MMT。鄰接矩陣定義節點間的相關性,所以再用歐式距離處理,得到鄰接矩陣A,Aij越大,節點i和節點j間的相關性越強。
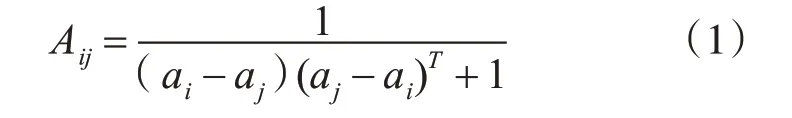
以上定義未對圖的稀疏度施加約束,因此可能產生完全連接的鄰接矩陣。如輸入參數中很多參數對輸出無影響一樣,視覺問答任務中的大多數問題亦只需關注圖像中的小部分區域。融合后的圖結構是接下來圖卷積網絡的核心,其作用是得到圖像目標和問題聯系的最相關區域。為得到圖的稀疏系統,本文采用Ai=topMax(Ai)的過濾策略,Ai為鄰接矩陣A 的第i 行,topMax 為向量Ai的最大top-Max 個參數,其余參數置0。這將得到節點最強連接的領域系統。
3.3 基于GCN的預測模型
給定特定問題的圖結構,本節使用圖卷積網絡(Graph Convolution Net)來學習新的對象的表示形式。圖像和問題聯合嵌入ji視為圖的節點,將多個ji組成的矩陣M 作為GCN 的輸入。GCN 的層間傳播公式為
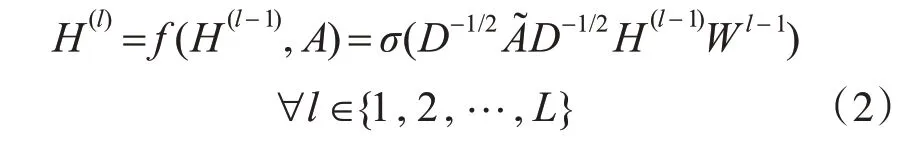
GCN 的輸入為H(0),=A+I(I 為單位矩陣),D為A~ 的節點度矩陣,W(l)為GCN 第L 層的可訓練權重矩陣,σ(·)為非線性激活函數。最終輸出的H 和問題Q 通過Hadamard 乘積融合生成h,h 將被輸入后續模塊進行答案預測。
圖像問答任務可視為多標簽分類任務,其中每個類對應于訓練集中最常見的答案之一。首先將訓練集中所對應的正確答案中所有出現大于等于8 次的答案構建為答案候選集,這將形成總數T=3129 的詞表。在VQA2.0 數據集中每一個訓練問題都對應10 個答案。當問題語義不明確或有多個語義相近的答案時,因注釋者間的分歧,答案并不相同。使用軟精度可以減少注釋者答案間的分歧,軟精度比二進制目標提供了更豐富的訓練信號,可以捕獲ground truth 注釋中偶爾出現的不確定性。Antol[9]給出的VQA 數據集的每個答案準確率計算為
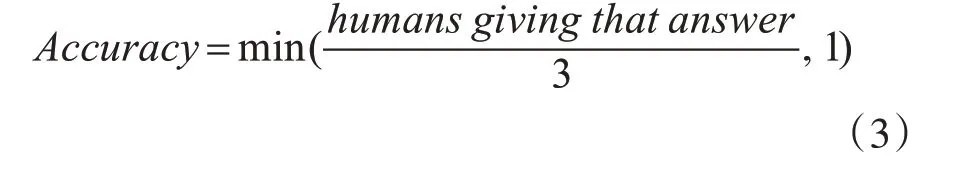
為預測答案,將聯合嵌入h 先用非線性函數處理,然后通過線性映射計算每個候選答案的分數S~ ,sigmoid可將分數映射為(0,1),以此作為候選答案的概率。
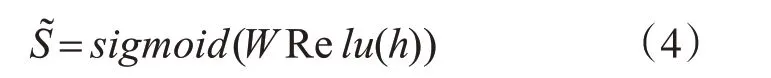
Sigmoid 函數的輸出允許針對每個問題優化多個正確答案,損失函數和二元交叉熵損失類似,此步驟可視為預測每個正確候選答案的回歸層:
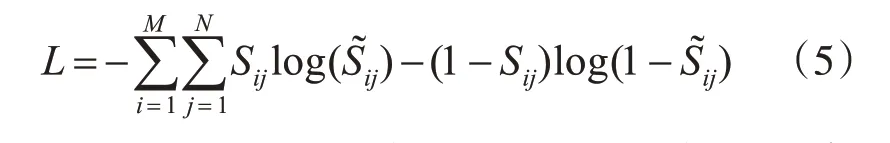
式(5)中的i 屬于訓練問題M,j 屬于候選答案N,Sij為式(3)計算的值。
4 實驗
4.1 實驗數據集
模型的評估在VQA2.0數據集上進行。該數據集包含約20 萬張圖片和110 萬個由人類標注的問題和每個問題對應的答案。數據集中的訓練集、驗證集、測試集的比例分別為0.4、0.2、0.4。VQA2.0數據集的評價指標即為式(3)。
4.2 實驗設置
本實驗的問題處理使用了預訓練的300 維度的glove詞嵌入向量,再用GRU編碼詞向量,輸出維度為1024。圖像的特征提取使用BottomUp,維度為2048,目標提取數量為36。接下來用兩層的圖卷積層學習,所有的全連接層和卷積層使用ReLU激活函數。初始學習率為0.001,圖像特征和全連接 層 的dropout 為0.5,優化器使用Adamax,Batch-size設為128,epoch為60。
4.3 實驗結果
對于影響實驗的主要參數,本實驗主要探究GCN 的層數N 和構建鄰接矩陣中的topMax 的數量,在實驗中,N 的數量分別設為{1,2,3,4,5},top-Max 的取值為{8,12,16,20,24,28,32}。在數據集中是/否、全部、其它和數字類型問題的準確率如下圖所示。左圖topMax 數量保持16,右圖GCN 層數為2。
GCN 層數為2 和topMax 為16 是最優選擇。在圖網絡中,堆疊多層的深度網絡依然是個挑戰,圖網絡深度一邊在2、3 層時表現出最佳性能。為了驗證詞嵌入對實驗的影響,本節用Glove 做了多組對比實驗。
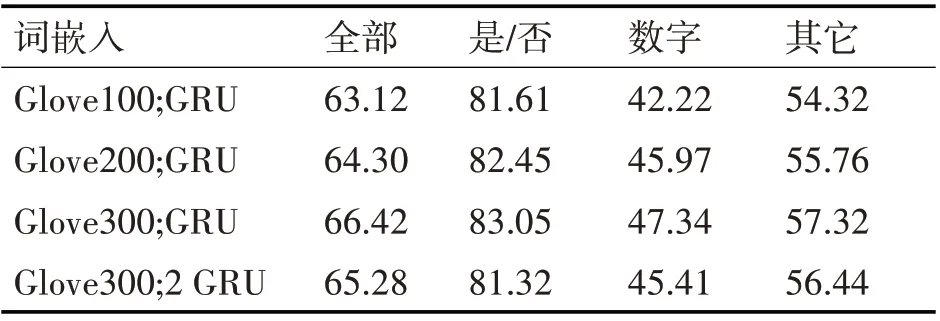
表1 不同文本處理方式間的比較
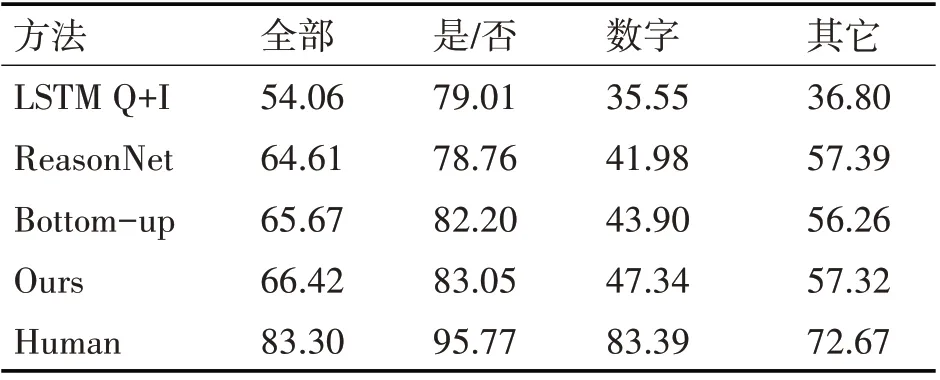
表2 在VQA2.0標準測試集上的結果和經典方法對比
實驗證明低維度的glove向量(100或200)性能明顯低于glove300,單層GRU 性能優于雙層的GRU。所以問題的詞嵌入使用glove300 和單層GRU。
基于圖卷積網絡的圖像問題方法可以提升預測準確率,與同樣使用Bottom-up attention 提取圖像特征的bottom-up 方法相比平均提升約0.7%,在計數的問題上獲得了約3.5%的提升。相比LSTM Q+I 和ReasonNet,GCN 僅以兩層網絡便優于其復雜的深層網絡模型。
5 結語
本文提出了一種基于圖卷積神經網絡的視覺問答方法,將視覺問答任務視為多標簽分類問題,用GCN 強大的分類能力提升答案預測的準確性。該方法考慮了圖像和問題的相關性,通過圖形結構處理將圖像和問題特征轉化為易于處理的可學習的圖結構表示,再使用圖卷積網絡學習節點的鄰接節點信息。基于當前的工作,后續可從以下方面繼續研究:尋找更有效的圖像和文本特征提取和融合方式,更復雜的圖形結構和圖網絡。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
