多通道區域建議的多尺度X光安檢圖像檢測
2022-01-22 07:46:48康佳楠
計算機工程與應用 2022年1期
康佳楠,張 良
中國民航大學電子信息與自動化學院,天津 300300
交通運輸工具的飛速發展使人們出行越來越方便,每天都有大量的人選擇飛機、火車、地鐵、汽車等交通工具,在運輸過程中一些匕首、槍支、彈藥等違禁品可能藏匿于行李中,而維護公共場所的安全顯得尤為重要。目前,在火車站、飛機場、地鐵站等都設置了X光安檢機用來檢測違禁品。但是,檢測到的X光圖片需要安檢員用肉眼進行識別,在有限的時間內檢查緊湊、雜亂和高度變化的行李會給安檢員帶來巨大的壓力,出現誤檢、漏檢的情況,所以急需一種技術能夠快速、準確地自動檢測到旅客行李內的違禁品。而隨著大數據和人工智能時代的到來,目標檢測已然成為計算機視覺領域中的研究熱點,現廣泛應用于智能交通、行人檢測[1-2]、人臉識別[3-4]、視頻監控[5]、醫學診斷[6]、軍事國防[7]等領域。所以將目標檢測應用到智能安檢中已是大勢所趨,既可減輕安檢人員的任務,又可提高安檢的精確度和效率。
目標檢測的傳統算法一般分為三個階段:首先在圖像上選擇候選區域,然后利用HOG、SIFT等手工提取特征[8]的方法進行特征提取,最后用訓練的分類器進行分類。基于深度學習的目標檢測算法主要分為兩大類:一類是基于候選區域的兩階段算法,包括RCNN、SPP-Net、Fast RCNN 和Fster RCNN 等;另一類是一階段的目標檢測算法,包括YOLO 系列、SSD、RetinaNet、FCOS 等。2014年,Girshick等人[9]提出了RCNN算法,首先用選擇性搜索算法(selective search)生成候選區域,然后在每個候選區域上都運行卷積運算,再將輸出送入支持向量機(SVM)進行分類,送入線性回歸器進行回歸,最后再進行定位。接著,He 等人[10]提出SPP-Net,引入空間金字塔池化層,可以對任意大小的候選框進行處理,但是只對原圖進行一次卷積,節省了時間,提高了速度。2015 年,Girshick 等人[11]結合RCNN 和SPP-Net 的缺點,提出了Fast RCNN,該算法先進行特征提取,再對整個圖像進行一次卷積,把支持向量機換成softmax層,但是依然用選擇性搜索區域算法生成候選區域,因此還是比較耗時,運行速度慢,而且無法實現端到端的測試。所以,2015 年Ren 等人[12]在Fast RCNN 的基礎上提出了Faster RCNN,引入region proposal 網絡(RPN)生成候選區域。2016年,提出了YOLO系列算法,包括YOLO、YOLOV2、YOLOV3,YOLO 算法在檢測速度上得到了很大的提高,但是在精度上有所欠缺。所以,2016 年,Liu 等人[13]又提出了SSD 網絡,該網絡可以在多個分辨率的特征圖上進行檢測,在一定程度上解決了多尺度問題,同時也提高了速度,但是對于一些小目標對應于特征圖中很小的區域,還是無法得到充分訓練。2018年,Facebook AI團隊提出了RetinaNet;隨后,2019年,阿德萊德大學團隊又提出了全卷積網絡FCO,該網絡是逐像素預測,類似于語義分割,使得檢測精度進一步提高。
針對安檢中X光圖像的檢測,Cha等人[14]提出一種可以產生中間的過程序列的方法,即采用仿射變換和交叉溶解相結合,但是在一定程度上會使圖像失真。董浩等人[15]提出了多視角X射線圖像分析算法,但是對復雜多變的行李檢測效果不好。Riffo 等人[16]提出自適應隱式形狀模型(adapted implicit shape model,AISM),但是違禁品的姿態各異,難以分辨,Riffo 等人[17]又提出主動視覺方法,利用Q-learning 算法預測違禁品的下一最佳視角。
但是,把目標檢測用到智能安檢中也存在很多難點,比如X光圖片中違禁品有各種類別,多種形狀,尺度不一,所以在檢測中具有一定的難度。Faster RCNN本身是基于單層次特征提取的目標檢測算法,對小目標不敏感,可能會出現漏檢的情況,本文通過多層特征提取和多通道區域建議,對Faster RCNN 進行了改進,以改善其在多尺度目標檢測方面的性能。主要做出以下三點貢獻:
(1)對Faster RCNN 的網絡結構進行改進,由原來的只從最后一個卷積層提取特征變為從三層提取,利用高層的語義信息和低層的精確定位的細節信息提高小目標的精確度,從而完成多尺度檢測。
(2)提出一種基于多通道區域建議網絡,依據大小不同的違禁品實例構建多通道RPN,使各通道RPN 都有合適的錨框與多層提取的特征圖一一對應,也使每個RPN分支基于有效感受野生成候選區域,再通過非極大值抑制算法得到合適的候選區域,然后各通道的候選區域通過感興趣池化區域(ROI pooling)后進行通道融合,送入后續檢測網絡。
(3)通過在多通道上引入多分支膨脹卷積模塊[18],增大了各個尺度目標的感受野,更有利于多尺度目標的檢測。
1 Faster RCNN網絡模型
Faster RCNN 網絡主要由特征提取網絡[19]、候選區域生成網絡RPN和感興趣區域池化層(ROI pooling)三部分組成。其中采用經典的VGG16作為特征提取網絡的基本骨架。該網絡包括13個卷積層、13個激勵層和3個池化層,卷積層均采用較小的3×3 的卷積核,既可以減少參數,又可以增加網絡的實時性,同時還進行較多的非線性映射,增加網絡的擬合和表達能力[20]。
輸入的圖片經過特征提取網絡提取出特征并生成特征圖,送入RPN 網絡生成候選區域。RPN 是一個全卷積網絡,包含一個3×3的卷積層和兩個全連接層。該網絡與檢測網絡共享VGG16 提取的特征,特征圖先經過3×3 的滑動窗口得到512 維的特征向量[21],并送入兩個全連接層,其中一個全連接層有2k個1×1的卷積核,完成分類,判別是前景還是背景;另一個全連接層有4k個1×1的卷積核,對候選區域完成坐標位置的回歸。然后利用非極大值抑制算法抑制掉無用的框,生成正錨框和對應邊框偏移量,然后計算出建議。
下一步將提取的候選區域建議和特征圖送入到感興趣區域池化層,將不同大小的區域處理為統一大小7×7的感興趣區域特征池化圖。最后再將池化圖轉化為4 096維的向量并送入兩個全連接層,一個經過softmax完成最終的分類并算出分類得分,另一個利用邊框回歸獲得位置偏移量,輸出最終的目標檢測框[20]。具體的Faster RCNN網絡結構如圖1所示。
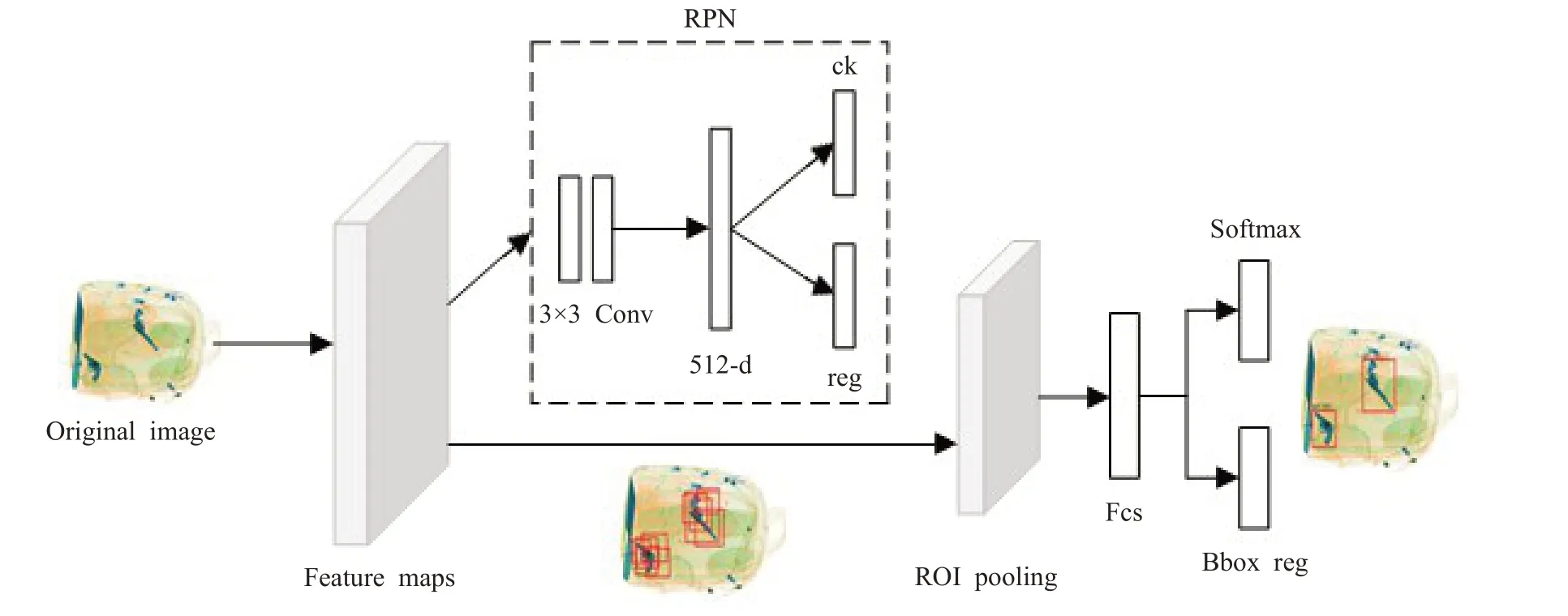
圖1 Faster RCNN網絡結構Fig.1 Faster RCNN network structure
2 改進的X光安檢圖像檢測模型
針對Faster RCNN 網絡對多尺度違禁品檢測存在缺陷的問題,本文聯合多層特征提取設計多通道區域建議網絡并增加膨脹卷積模塊分別提取出不同尺寸目標的特征圖,然后通過具有膨脹卷積模塊的多通道RPN增強各個尺度的特征,完成多尺度違禁品的檢測。改進后的具體結構如圖2所示。

圖2 Faster RCNN改進Fig.2 Improvement of Faster RCNN
2.1 多通道RPN網絡MCRPN
提取圖像特征的方法很多,比如傳統方法尺度不變特征變化SIFT,可提取物體的局部特征,包括邊緣細節信息等,對小目標也具有一定適應性,但是對于邊緣光滑的目標卻無法精確地提取到特征,而且實時性不高。又如方向梯度直方圖HOG,通過計算和統計圖像局部區域的梯度直方圖來構成特征,比較適合人體檢測。但是二者都是依靠先驗知識設計特征圖,而深度學習是一種自學習的特征表達方法,在深度卷積網絡中,一般低層卷積提取的淺層特征分辨率較高,紋理、邊緣等細節信息較豐富,適合小目標的檢測,例如X 光圖片中的小剪刀、小扳手等;而高層卷積提取的深層特征分辨率較低但是語義信息較豐富,感受野大,可以提取出物體的輪廓[21],適合大目標的檢測,例如X光圖片中的手槍、刀等。所以本文通過改進Faster RCNN網絡,提出多通道區域建議網絡。
采用VGG16 結構作為特征提取網絡,對于5 個卷積模塊,Conv5_3 后的特征分辨率低但語義信息豐富,對大目標檢測效果更好;Conv4_3 和Conv3_3 后的特征分辨率高,細節信息豐富,檢測小目標更加精確。所以分別提取Conv5_3、Conv4_3和Conv3_3后的特征,然后將不同大小的特征圖送入多通道RPN 網絡中。3 個路徑的RPN 分別根據不同的目標設置不同的錨點規格,從Conv5_3層提取的特征經過RPN1,設置步長為16,錨框參數為16、32、64;從Conv4_3 層提取的特征經過RPN2,設置步長為8,錨框參數為8、16、32;從Conv3_3層提取的特征經過RPN3,設置步長為4,錨框參數為4、8、16。由于每個RPN路徑面向不同尺度的違禁品進行訓練,所以不同的RPN的損失函數也是獨立的。
在深度學習中有眾多損失函數,如均方誤差(又稱MSE,L2損失),具體如式(1):

該損失函數比較適合訓練數據中含有比較多的異常值,因為它會給予異常值較大權重,但模型為了盡力減小這些異常值造成的誤差,會使模型整體效果下降,因此對于一般的訓練數據是不適用的。又如平均絕對誤差(又稱MAE,L1損失),計算方法如式(2):

L1 損失函數雖然對異常值有很好的魯棒性,但是在極值點處有很大的躍變,不利于收斂,所以也不適合RPN的訓練。
本文的訓練數據沒有很多異常值,而且數據集中幾乎每張圖像中都存在違禁品,因此,RPN使用平滑L1損失函數(smooth L1 loss),如式(3)。這個函數克服了L1 和L2 的缺點,采用了稍微緩和一點的絕對損失函數f(x)=|x|,它隨著誤差線性增長,既避免了像平方函數那樣成平方增長對誤差較大的損失懲罰過高的問題,又使得損失函數保持連續可導。因為該函數在0 處不存在導數,可能會影響收斂,所以設計成分段函數,在0處使用平方函數,讓曲線更加平滑。
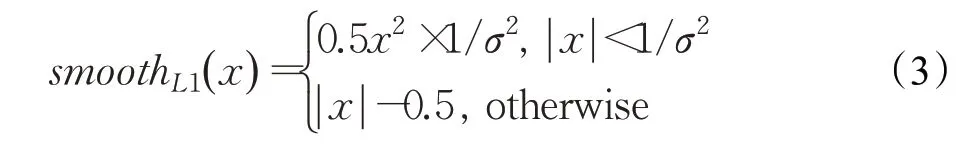
RPN 損失主要包括分類損失(cls loss)和回歸損失(Bbox regression loss)。分類損失的公式為式(4):


R是smooth L1函數。
2.2 膨脹卷積模塊DCM
感受野的值可以用來大致判斷每一層的抽象程度,神經元感受野的值越大表示其能接觸到的原始圖像范圍越大,則它可能蘊含著更為全面,語義層次更高的特征;反而感受野的值越小,表示其能接觸到的原始圖像范圍越小,則也可能意味著所包含的特征只是一些邊緣的,局部的信息。所以,為了增大圖像的感受野又不增加模型的計算量,引入膨脹卷積[22],設計了一種多分支的增大感受野的模塊。
膨脹卷積是一種下采樣方式,而傳統的神經網絡中一般采用池化層來減小圖片的大小,會造成圖片信息以及結構的丟失,甚至小物體信息無法重建。膨脹卷積則不做池化損失,并且是在普通卷積的基礎上保持相同的卷積核,并增加了一個擴張率(dilation rate),在卷積核元素中間填充0元素。它與普通卷積相比,卷積核大小是一樣的,在神經網絡中的參數也是保持不變的,但是卻比普通卷積的感受野大,使得每個卷積輸出都包含較大范圍的信息。普通卷積的感受野和層數呈線性關系增長,比如在步長為1 的情況下,4 層4×4 的卷積加起來,感受野才達到13,而膨脹卷積的感受野則是呈指數級增長的。又比如一個膨脹系數為2的3×3的卷積核與一個普通的5×5的卷積核感受野相同,但膨脹卷積的參數量只有9個,是5×5卷積核參數量的36%。由此可見,膨脹卷積可以增大感受野卻不增加參數量,更有利于計算。具體計算方式如下。
假設原來卷積核為k,擴張率為d,則新的卷積核的大小為式(8):

如圖3為普通卷積和膨脹卷積對應的感受野。

圖3 普通卷積和膨脹卷積對應的感受野Fig.3 Receptive fields corresponding to ordinary convolution and dilated convolution
在第二和第三條RPN通道上增加多分支結構的膨脹卷積模塊。首先,經過1×1的卷積在不改變輸出寬度和高度的同時,實現各個通道信息的融合以及通道數的降維。其次,感受野是由不同大小的卷積核所決定的,通過設置多種尺寸的卷積核和不同的膨脹系數來獲得不同目標的感受野,設置了膨脹系數分別為1、3、5的1×1、3×3和5×5的膨脹卷積來增大感受野。然后,加入旁路剪枝,以確保更多的原始特征信息。最后,利用Concat函數和1×1卷積核將各個分支充分融合到一起,并將網絡通道數降低到512維,即通過減少卷積核通道數和參數,降低計算量。三條支路融合到一起通道數增加為1 028 維,最后通過1×1 卷積降低到512 維,模型的收斂速度更快,性能更好。同時,多分支的結構可以增加網絡的寬度,各分支通過不同的感受野大小實現對不同尺度目標更好的適應性,利于多尺度檢測,使模型的性能更好,本文通過增大神經元的感受野,增強小尺度違禁品的檢測。具體模塊如圖4所示。
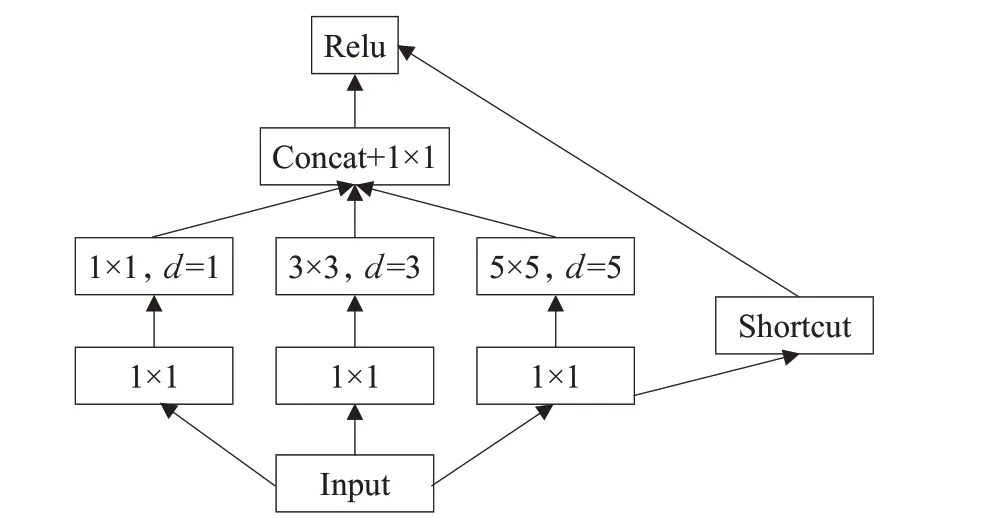
圖4 膨脹卷積模塊Fig.4 Dilated convolution module
3 實驗
3.1 實驗環境和數據集
所用工作站配置了NVIDIA GeForce GTX 1080TI GPU 顯卡,操作系統是Ubuntu16.04,使用Pytorch 深度學習框架和Python語言編寫程序。
實驗在自制的X 光違禁品SIXray_OD 數據集上進行,用于二分類的公開數據集SIXray 有1 059 231 幅X光圖像,在SIXray 數據集基礎上選出8 718 幅全部包含違禁品的圖像并通過Labeling 手動打上標簽,組成了SIXray_OD 數據集。標注的信息包括違禁品的類別和位置,用標注框左上角的坐標和右下角的坐標來表示違禁品的位置,用輸出的檢測框和標注框的交并比來判定匹配分數,從而確定精確度。SIXray_OD 數據集包含5類違禁品:Gun、Knife、Wrench、Pliers、Scissors,加上背景一共6 類,其中Gun 有2 936 幅,Knife 有156 幅,Wrench 有2 266 幅,Pliers 有3 951 幅,Scissors 有1 159幅。如圖5為數據集SIXray_OD中的部分樣本。

圖5 數據集SIXray_ODFig.5 Data set SIXray_OD
3.2 實驗分析和結果討論
3.2.1 不同模型對比實驗
為驗證Faster RCNN 在X 光違禁品檢測性能上的優越性,首先將Faster RCNN網絡與目前國際上較為流行的幾種目標檢測網絡在相同設備和工作環境下進行實驗對比。模型衡量指標用平均精度均值mAP(mean average precision)表示,表1 為SSD、YOLOV3、Faster RCNN這3種目標檢測網絡分別在SIXray_OD數據集上的檢測精度。
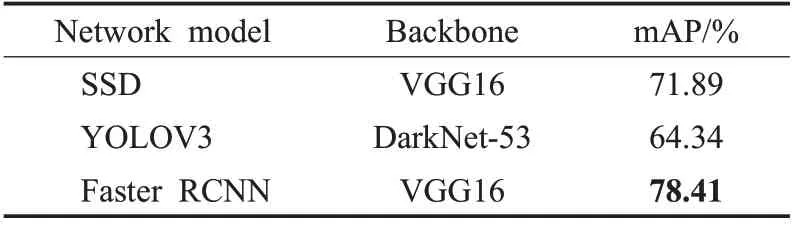
表1 不同模型的檢測精度Table 1 Detection accuracy of different models
從實驗結果可以看出,Faster RCNN的檢測精度較YOLOV3 高了14.07 個百分點,較SSD 高了6.52 個百分點,明顯Faster RCNN 的檢測性能更好,大大降低了安檢中的漏檢率。
3.2.2 單支路實驗
為驗證淺層特征更有利于小目標的檢測,分別進行提取不同層特征的單支路實驗。從SIXray_OD 數據集中找出全部包含小目標的圖像,如圖6所示,一共2 040張,組成新的小目標測試集。然后利用SIXray_OD中的原訓練集訓練,新的小目標測試集進行測試。同時將每層卷積層提取的特征圖進行可視化,如圖7 所示。表2是分別從Conv5_3、Conv4_3、Conv3_3 提取的基于單層次的單支路實驗。

圖6 包含小目標的測試集Fig.6 Test set with small targets

圖7 原圖和每層卷積提取的特征可視化Fig.7 Visualization of features extracted from original image and each layer of convolution

表2 單支路對小違禁品的檢測Table 2 Single branch detection of small targets
實驗結果中也可以看出,從Conv4_3和Conv3_3提取的特征對小違禁品的檢測精度高于從Conv5_3 提取的特征。這是因為對于小目標來說,只需要經過Conv4_3或Conv3_3 卷積后,提取的特征就很充分了,反而多加卷積層會使效果變差。從可視化的特征圖也可以看出對于小剪刀,經過幾層卷積,輪廓較明顯,越到后面,尤其是Conv5_3 之后,小剪刀的特征變得模糊不清,幾乎消失。也顯示出低層卷積提取的淺層特征更有利于小目標的檢測,而高層卷積提取的特征在一定程度上可能忽略了邊緣、細節等信息,使得檢測結果不如淺層特征。
3.2.3 多通道RPN融合實驗
如表3是多通道RPN融合實驗,分別提取各個層的特征,然后不同通道通過不同RPN網絡和ROI pooling,再將支路用Concat函數和1×1卷積進行通道融合,最后送入全連接層完成最終的分類和位置回歸。

表3 多通道RPN融合實驗Table 3 Multi-channel RPN fusion experiment
通過不同通道的融合實驗顯示,只有將Conv5_3、Conv4_3 和Conv3_3 三條支路融合后并在SIXray_OD數據集上進行實驗,檢測效果達到最好。這是因為對于大目標,前面幾層卷積提取的特征不夠充分,對于小目標,后面的卷積會使特征變模糊或消失。所以,多層提取的多通道RPN改進算法比原網絡單層特征提取的算法更有利于多尺度違禁品的檢測。
3.2.4 增加DCM實驗
如表4是增加了DCM后的檢測結果。為增大感受野,使小目標的邊緣、細節信息更清晰,分別在多通道上增加膨脹卷積模塊DCM。其中RPN1 對應錨框參數設置為16、32、64,RPN2 錨框參數為8、16、32,RPN3 錨框參數為4、8、16。

表4 增加膨脹卷積結果Table 4 Results of increasing expansion convolution
實驗結果顯示,根據不同支路引入DCM 后結果不同,也說明只有在適合的支路引入擴張率合適的DCM才能增大圖像的感受野,提高對小目標的檢測,從而提高多尺度違禁品的檢測性能;同時,在解決部分遮擋問題上也有一定的提高。如圖8為檢測結果。
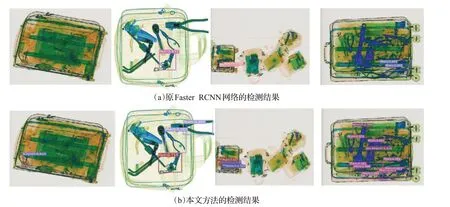
圖8 檢測結果對比Fig.8 Comparison of test results
3.2.5 參數設置實驗
在實驗中,參數的設置也很重要。初始學習率lr設置為0.001,學習率衰減因子lr_decay設置為0.1,權重衰減因子weight_decay設置為0.000 5,迭代次數為14。表5實驗結果也顯示,學習率設置過大、過小對算法性能的影響都不好,只有設置最利于模型的參數,實驗效果才能達到最佳。

表5 參數設置Table 5 Parameter settings
4 結論
為改善X光圖像中不同違禁品檢測的性能,本文在Faster RCNN基礎上引入多層提取和多通道區域建議,融合圖像高低層的不同信息,提取不同目標的特征,并且每個獨立的RPN 通道都設置不同規格的錨框參數,分別經過ROI pooling,三條支路再進行通道融合,后利用非極大值抑制算法剔除掉分數較小的檢測框。同時,在多通道上引入多分支的膨脹卷積模塊也增大了感受野,利于小目標的檢測。改進算法在SIXray_OD數據集上的實驗結果表明,分層提取的信息使圖像特征更加全面,多通道RPN 也使各個目標檢測更加準確。該算法有效改善了對小違禁品的檢測性能,提高了多尺度檢測。但同時速度也有所下降,并且隨著網絡的增大,GPU占用率也增加了,網絡參數變多,需要的數據量也增多,但不會影響模型在實際中的應用。現實生活中由于旅客的行李很雜,不同違禁品互相遮擋,同類違禁品自遮擋,模型在解決這個問題上還不是很成熟,所以在安檢的過程中,會出現漏檢的情況。下一步的工作是在改進網絡的基礎上解決違禁品被遮擋的問題,以進一步提高違禁品檢測的準確度。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
