基于輕量級卷積神經網絡人臉識別算法的研究與應用*
2022-01-21 00:32:04胡佳玲施一萍謝思雅
傳感器與微系統 2022年1期
胡佳玲, 施一萍, 謝思雅, 陳 藩, 劉 瑾
(上海工程技術大學 電子電氣工程學院,上海 201620)
0 引 言
近年來,人臉識別[1]一直是很多學者們研究的熱點問題。人臉識別算法目前主要分為兩種:一種是機器學習算法,本質主要是通過設定人臉特征再結合Adaboost等分類算法加以實現;第二種是近年來比較流行的結合深度學習[2]的人臉識別算法。基于深度學習的人臉識別算法一般采用卷積神經網絡(convolution neural network,CNN)來實現。發展至今,基于CNN[3]的人臉識別算法在準確率上已經趨于100 %,并且有越來越多效果很好的網絡相續出現。2014年,香港中文大學的團隊利用深度學習人臉識別算法取得了準確率為97.45 %的好成績;準確率的提升往往伴隨著CNN深度和復雜度的增加,在提高精度的同時,意味著網絡深度、參數和計算量的大幅增加,訓練時間也相對延長。例如Google Inception Net有22層,且ResNet達到了152層。其次,隨著小型設備的應用不斷廣泛,越來越多的研究不僅僅局限于靠強大的服務器去訓練網絡。
針對上述問題,本文選用了一種輕量級MobileNet[4]模型,將改進的MoblieNet網絡和區域生成網絡(region proposal network,RPN)[5]融合構成一個用于人臉識別的專用網絡,并對其進行了改進,有效地提高了網絡的運行速度,降低了網絡的參數量。最后用Jetson Nano嵌入式開發板作為訓練的載體,測試網絡的具體性能,并應用到實際場景中。
1 人臉識別系統
如圖1所示,為本文設計構建的人臉識別模型,系統的硬件采用嵌入式開發板Jetson Nano,將搭建好的改進型輕量級人臉識別網絡在開發板上訓練好,并投入使用。
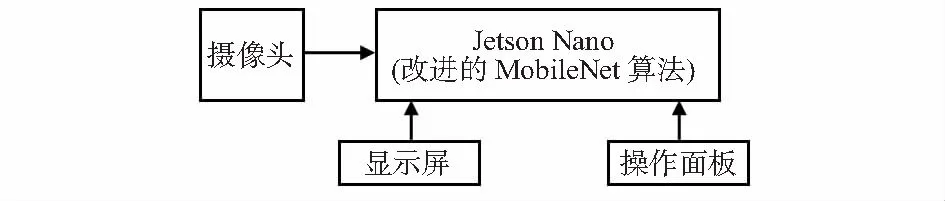
圖1 人臉識別系統模型
2 改進型MobileNet網絡
本文設計的模型具體從兩個方面進行改進:首先,將MobileNet網絡中SoftMax[6]層改用L-SoftMax[7]層替換;其次,網絡融合入RPN,提高網絡的識別效率。
2.1 MobileNet網絡
2017年,Google提出MobileNet深度學習網絡,與傳統卷積神經網絡不同在于,MobileNet網絡采用深度可分離卷積[8](depthwise separable convolution),即把傳統卷積分為深度卷積(depthwise convolution)和逐點卷積(pointwise convolution)。深度可分離卷積可以在保證網絡不損失大量精確度的情況下大大降低網絡參數和計算量。卷積的具體分解過程如圖2所示。
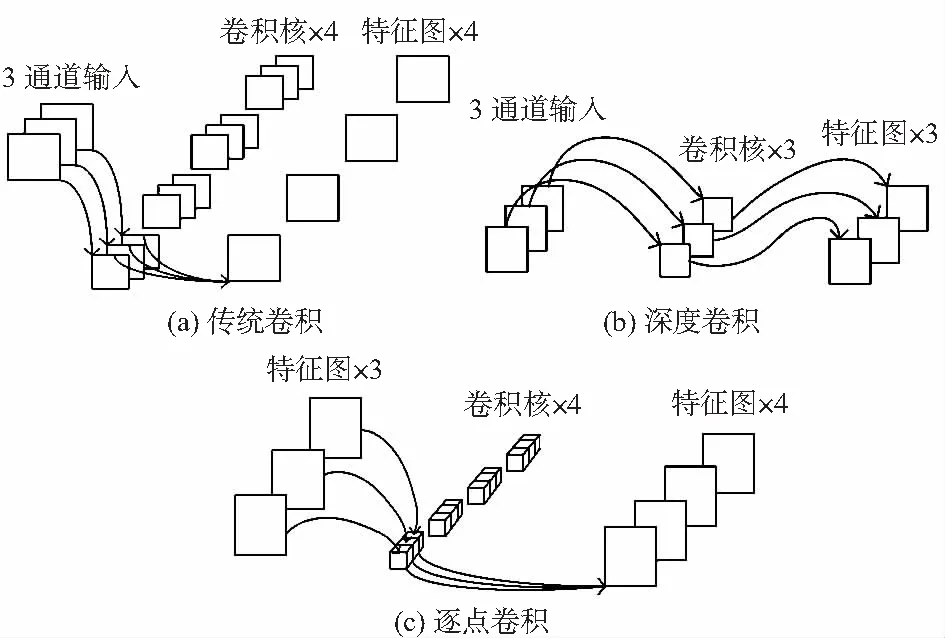
圖2 傳統卷積、深度卷積和逐點卷積
如圖2(a)傳統卷積所示:卷積核channel=輸入特征矩陣channel;輸出特征矩陣channel=卷積核個數。而圖2(b)中的深度卷積:卷積核channel=1;輸入特征矩陣channel=卷積核個數=輸出特征矩陣channel。
1×1的卷積核在深度可分離卷積中被稱為逐點卷積。特征映射F的大小為(DF,DF,M),K為(DK,DK,M,N),如圖2(a)傳統卷積所示。其輸出的特征映射G大小為(DG,DG,N)。傳統卷積的計算公式如下
(1)
傳統卷積的計算量為DK·DK·M·N·DF·DF。現將傳統卷積(DK,DK,M,N)進行拆分,拆分為深度卷積和逐點卷積:
1)濾波由深度卷積負責,尺寸為(DK,DK,1,M),如圖2(b)的深度卷積所示,輸出的特征為(DG,DG,M)。
2)轉換通道由逐點卷積負責,尺寸為(1,1,M,N),如圖2(c)的逐點卷積所示,得到最終的輸出為(DG,DG,M)。深度卷積的卷積公式為
(2)
DK·DK·M·DF·DF+M·N·DF·DF
(3)
因此,深度可分離卷積與傳統卷積比值為
(4)
一般情況下,N的取值較大。假設用的卷積核為3×3大小,則這里計算量大約會減少9倍左右,訓練網絡的時間也大大縮短。
2.2 網絡層優化
雖然,MobileNet的計算量比傳統卷積神經網絡高許多倍,但其檢測準確率低于層數較多的卷積神經網絡。MobileNet在訓練時使用SoftMax分類器。但研究發現采用L-SoftMax的分類效果比SoftMax更好。最初,人臉識別采用SoftMax Loss方法,但實驗發現,這種方式只能確保讓其組與組間具有區分性,而對組內的約束是很小的。所以,鑒于此,L-SoftMax增加了一個代表分類間隔的超參數m,它決定了接近地面真值類的強度,產生一個角邊距,使得學習特征變得更加緊湊和良好分離。
SoftMax Loss函數公式如式(5)所示
(5)
式中sj為SoftMax函數,代表屬于各個類別的概率。
而L-SoftMax Loss的公式如下
(6)
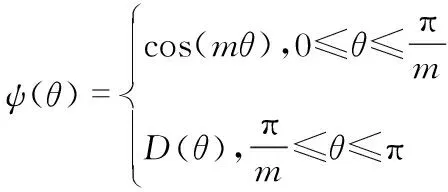
式中D(θ)要求是單調遞減函數,D(π/m)應等于cos(π/m)。m是一個與分類裕度密切相關的整數,隨著m的增大,分類裕度變大,學習目標也變難。而這種方式,會迫使模型學習到類間距離更大,而類內距離更小的特征。因此,會使得分類效果更清晰。這一點在迭代次數多的情況下效果會更明顯。表1為改進后的網絡結構。

表1 改進型MobileNet網絡結構
3 改進型MobileNet+RPN識別算法
3.1 RPN
為了縮小與深層卷積神經網絡在識別率上的差距,本文還加入了RPN,用來確定人臉檢測窗口。
RPN原理上是在卷積神經網絡的卷積層后生成的特征圖上產生建議選區。因其巧妙地采用了Anchor機制,所以,可以產生多尺度長寬比的建議選區。RPN網絡的具體實現過程如下:首先,用一個小網絡在特征圖上進行滑動,一般的滑動窗口設置為3×3大小。這個滑動窗口會做全卷積操作,并根據最后卷積層的通道數,生成一個對應數目的向量。其次,將向量連向分類層,分類層將判斷該區域是場景中的哪部分,并給出具體的分數。原Fast R-CNN[9]一共設置了9種Anchor。由于人臉的特殊性,一般人臉的比例是固定的。本文對LFW(labeled faces in the wild)中人臉比例情況做了粗略統計,結果表明,人臉的長寬比基本都是1︰1和2︰1,大部分在1.5左右。所以,本文的Anchor比例設置為1︰1和2︰1,尺寸和原RPN—樣,都采用3種尺寸,所以,一個3×3的區域只需要產生6個Anchor,達到了減少計算量的目的,同時,加入的RPN也提升了本文算法的識別率。
3.2 改進后的模型
如圖3,第一部分為MobileNet的卷積層,第二部分為加入的RPN,第三部分為全卷積層后對原SoftMax改進為L-SoftMax。改進后的算法為MobileNet-L+RPN算法。

圖3 整體網絡結構
4 實驗結果與分析
4.1 實驗數據集
本次實驗采用的人臉數據庫為LFW,其中的圖片均來自網絡,共包含13 233張人臉圖片,5 749位名人,每位名人有一張或多張人臉圖片且都被標注了姓名和編號。
4.1.1 數據集分類情況
針對LFW數據集,選取10 000張用于訓練集,3 000張用于驗證集。除此外,本文還準備了1 000張測試集,測試集來源于網絡人臉和現實拍照,包括身邊的同學、朋友等。
4.1.2 圖像預處理
1)灰度化[10]:為使后續的圖像計算量變少,本文預先對數據庫進行統一的灰度化處理,采用的是傳統的灰度化處理方法。
2)直方圖均衡化[11]:增強灰度圖像的對比度,減少不相關因素的影響。
4.2 實驗結果及數據分析
Jetson Nano支持的系統為Ubuntu系統,本次安裝的版本為較新的Ubuntu 18.04.2 LTS。軟件部分采用Python 3.6版本下的Anaconda,采用Pytorch框架。網絡訓練參數的設置如下:初始學習率為0.001,學習策略采用按需調整學習率,權重衰減為0.000 4。
本文比較了3種網絡模型:CNN,MobileNet,MobileNet-L+RPN。首先在帶有GPU服務器的電腦設備上進行模型的評價,實驗數據如圖4所示:三種模型迭代15 000次的準確率折線圖,從圖中可以看出:采用CNN在迭代4 000~5 000次時,準確率趨于收斂,準確率最終穩定在98 %左右。MobileNet在迭代10 000左右趨于收斂,準確率穩定在95 %左右。采用MobileNet(L-SoftMax)+RPN模型在迭代8 000次左右趨于收斂,準確率最終穩定在97 %左右。對比傳統的CNN,準確率還是有所下降。但比原MobileNet網絡,準確率提高了2個百分點。因此,本文提出的改進MobileNet網絡切實可行,且在準確率上較原MobileNet網絡有提升。雖然沒有達到和傳統CNN一樣或者更高的精確度,但這對于大大提升計算速度和大大降低網絡參數而言,在性能上有了很大的提升。
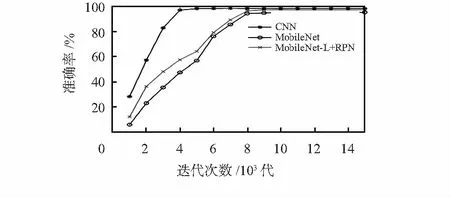
圖4 三種模型準確率比較折線圖
三個模型試驗結果對比如表2所示,由表2可以看出,本文提出的模型在降低網絡參數和訓練時間的同時,識別的準確率較原MobileNet網絡也有提升。
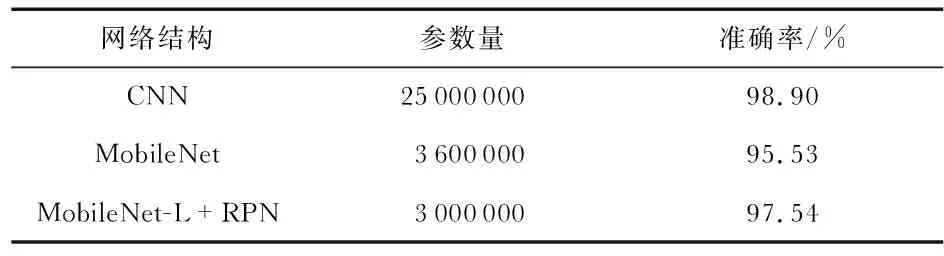
表2 三種模型參數量及識別準確率比較
其次,本文又將原MobileNet模型和改進后的輕量級模型分別在Jetson Nano嵌入式平臺上進行測試,最終得到的數據如表3所示。由表3可以看出,本文提出的模型在運行速度上比原MobileNet快了21.3 %左右。
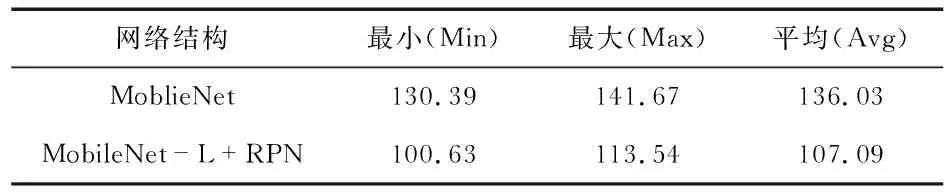
表3 模型在Jetson Nano上運行速度對比 ms
5 結束語
本文提出了一種輕量級人臉識別算法,對MobileNet網絡進行網絡層的改進,并融合RPN,在提升網絡識別速度的同時,網絡的準確率也得到提升,使得網絡能夠在小型計算平臺上得以應用(本文以Jetson Nano為例)。實驗結果表明:在LFW數據庫和自建的數據庫上訓練的人臉識別準確率達到了97.54 %。同時,本文將改進的MobileNet人臉識別運用到具體的Jetson Nano設備上,可構成完整的識別系統,運用于多個現實場景。如室外安防、打卡系統、查寢系統等。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
作文中學版(2022年1期)2022-04-14 08:00:34
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
學生天地(2020年31期)2020-06-01 02:32:06
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
光學精密工程(2016年6期)2016-11-07 09:07:19
