基于深度神經網絡融合稀疏分組lasso的預測模型研究*
2022-01-19 08:38:12哈爾濱醫科大學衛生統計教研室150081盧宇紅宋佳麗
中國衛生統計 2021年6期
哈爾濱醫科大學衛生統計教研室(150081) 盧宇紅 宋佳麗 王 萌 侯 艷
【提 要】 目的 探索深度神經網絡(DNN)聯合不同正則化方法后模型預測準確性的差異;探索模型預測準確性較高時的樣本特征規律。方法 R軟件產生不同分組、不同樣本量的模擬數據集,在不同數據特征下比較DNN模型及融合正則化后模型的預測能力。通過真實數據分析進一步評價兩種模型的預測能力。結果 DNN融合不同正則化方法的結果均優于單純DNN模型,其中DNN融合稀疏分組lasso(SDP)效果最好。稀疏組別組內變量個數的大小及樣本量會影響預測準確性,組內變量個數≥8,樣本量≥700時,SDP模型預測準確性較高。結論 與單純DNN模型相比,SDP模型預測準確性得到顯著改善;考慮不同樣本量和分組方式的情況,SDP模型的預測能力均有明顯提高,并且其對預測相關重要特征的提取較為準確。在實際案例分析中發現在小樣本的高維組學數據中,SDP模型預測準確性和防止過擬合的能力均有明顯提升。
隨著高通量檢測技術的快速發展,產生了大量的組學數據,其越來越普遍地用于疾病與健康的相關研究,但組學數據具有維度高、樣本量小、結構復雜的特點,分析起來較為復雜,而深度神經網絡(deep neural networks,DNN)模型可擬合任意函數,適用于分析此類數據,但在進行模型訓練時,組學數據中存在大量與預測不相關的冗余特征,訓練過程中使用全部特征可能會導致模型出現過擬合問題,影響模型預測的準確性,而在DNN模型中,可以通過刪除冗余參數達到壓縮模型的目的[1-2]。在DNN壓縮方法中基于梯度正則化方法具有更高的優勢,具體表現為該方法可在訓練網絡調節網絡參數的同時,進行特定結構的稀疏[3],并且對變量數目沒有限制、計算速度較快,可用于處理高維、低樣本量的數據[4]。目前基于梯度正則化方法主要用于對DNN結構的調整,通過修剪或合并網絡結構以簡化模型,降低模型的復雜度和過擬合程度,而未用于輸入層特征的稀疏[5-7]。
本文提出基于深度神經網絡融合稀疏分組lasso的預測模型(prediction model based on deep neural network together with sparse group lasso,SDP),該方法基于梯度正則化方法壓縮DNN結構的思想,在每次迭代調整模型參數的過程中,修剪掉輸入層中不重要的特征,使模型充分學習重要特征,以提高預測準確性、避免過擬合。本研究將通過模擬不同樣本特征的數據評估SDP模型的預測能力是否優于傳統的DNN模型,并探索SDP模型預測能力較高時樣本特征規律。采用腫瘤基因組圖譜計劃(the cancer genome atlas,TCGA)數據庫中乳腺癌數據,按通路分組進行實例分析,進一步評價SDP模型與DNN模型的預測能力。
原 理
1.深度神經網絡融合稀疏分組lasso模型(SDP)
該方法的基本原理是把額外的懲罰項加到已有模型的損失函數上,稀疏模型中的特定結構,以防止過擬合現象發生。在傳統的DNN基礎上,將正則化方法應用于深度神經網絡的輸入層與第一隱藏層間,用以對輸入層特征進行稀疏,將Cox模型連接于深度神經網絡的輸出層,即圖1所示。
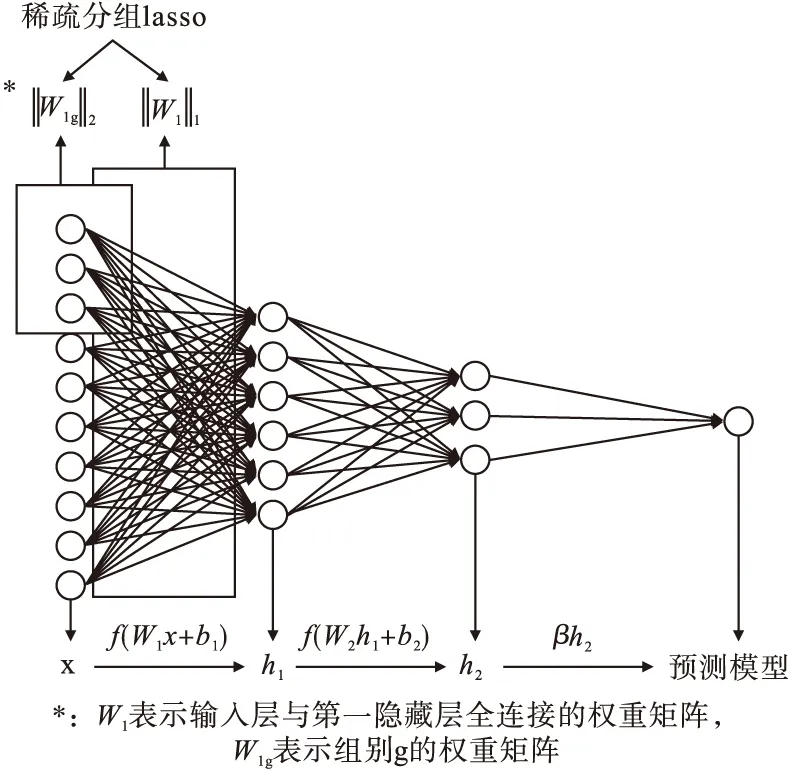
圖1 基于深度神經網絡融合稀疏分組lasso模型(SDP)基本結構
在深度神經網絡中,第一隱藏層h1表示為:
h1=f(W1x+b1)
(1)
第二隱藏層h2表示為:
h2=f(W2h1+b2)
(2)
其中,f(z)為激活函數,本研究中采用常用的ReLU函數,表達式為:
f(x)=max(0,x)
(3)
將深度神經網絡第二隱藏層的輸出作為Cox模型的輸入,則有
h(t|x)=h0(t)exp(βh2)
(4)
其中h2表示第二隱藏層節點,β表示第二隱藏層節點與輸出層之間的權重向量。βh2為預后指數(prognostic index,PI),PI越大則風險函數h(t|x)越大、預后越差,該指標不隨時間的變化而變化。由于未對基礎風險函數h0作任何假設,因此常規的最大似然估計無法估計回歸系數向量β,對此可以構造對數偏似然函數對模型參數進行估計。
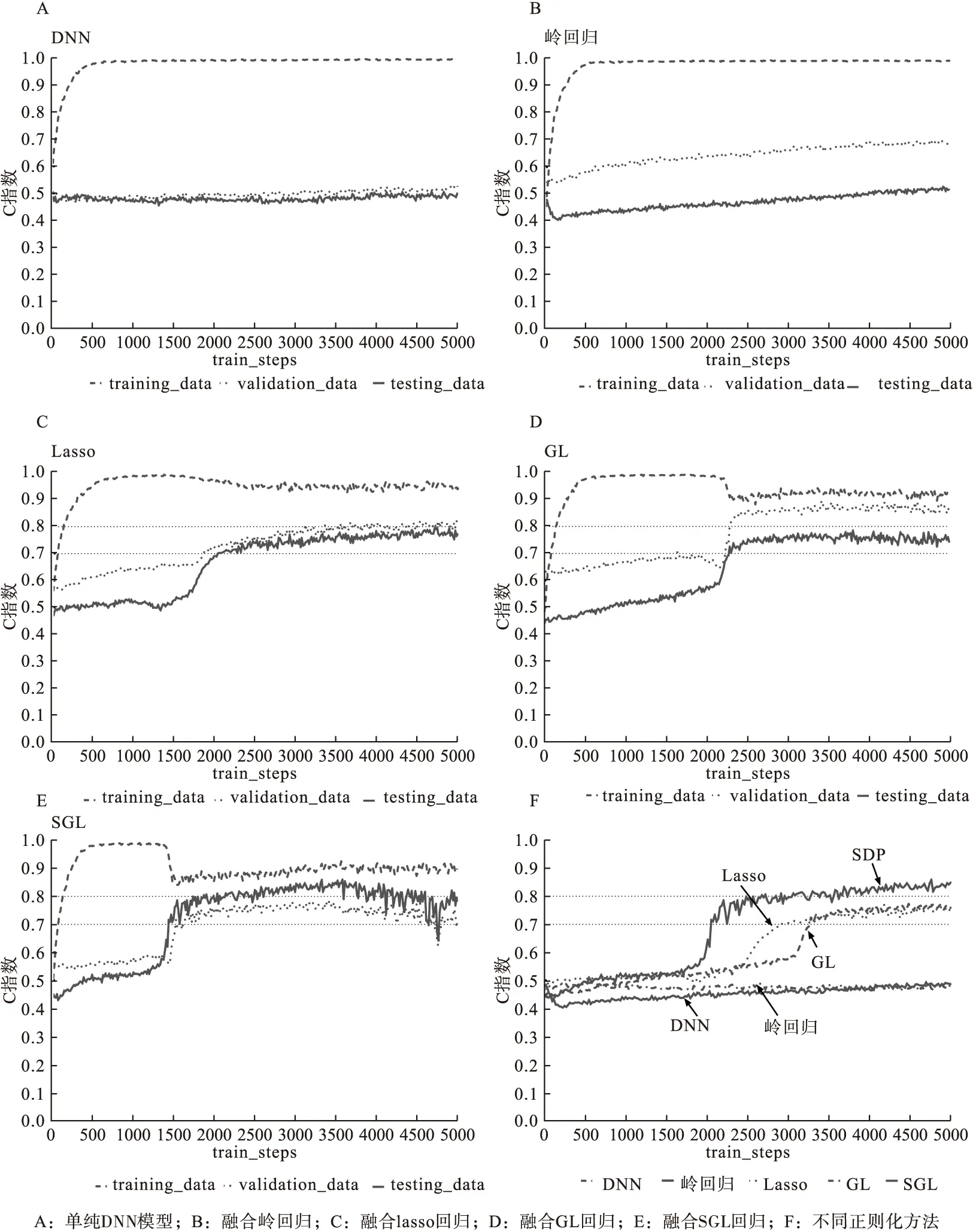
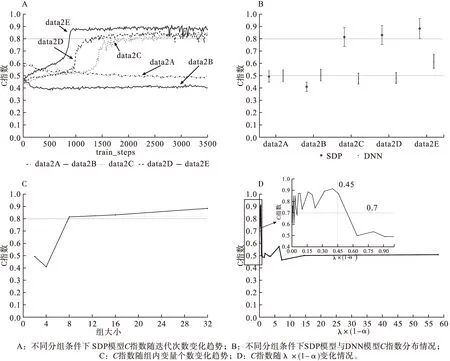
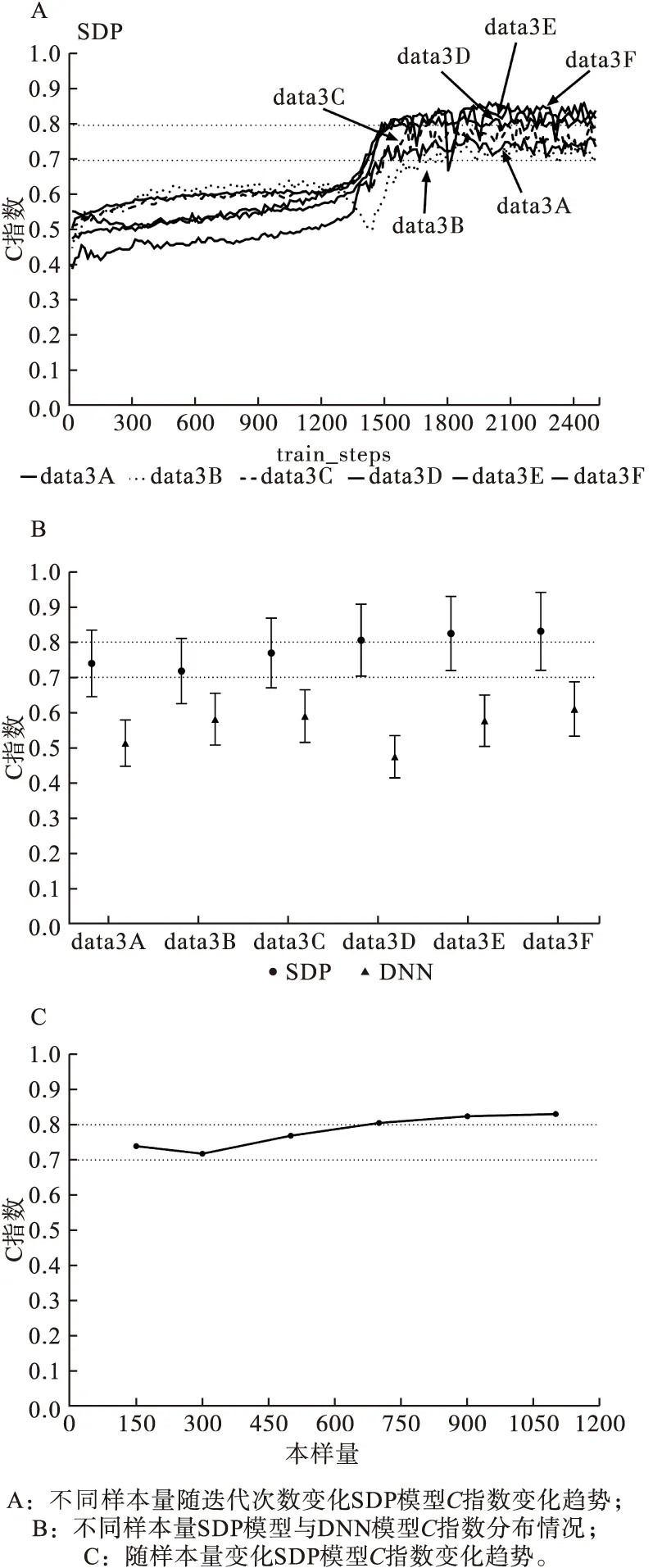
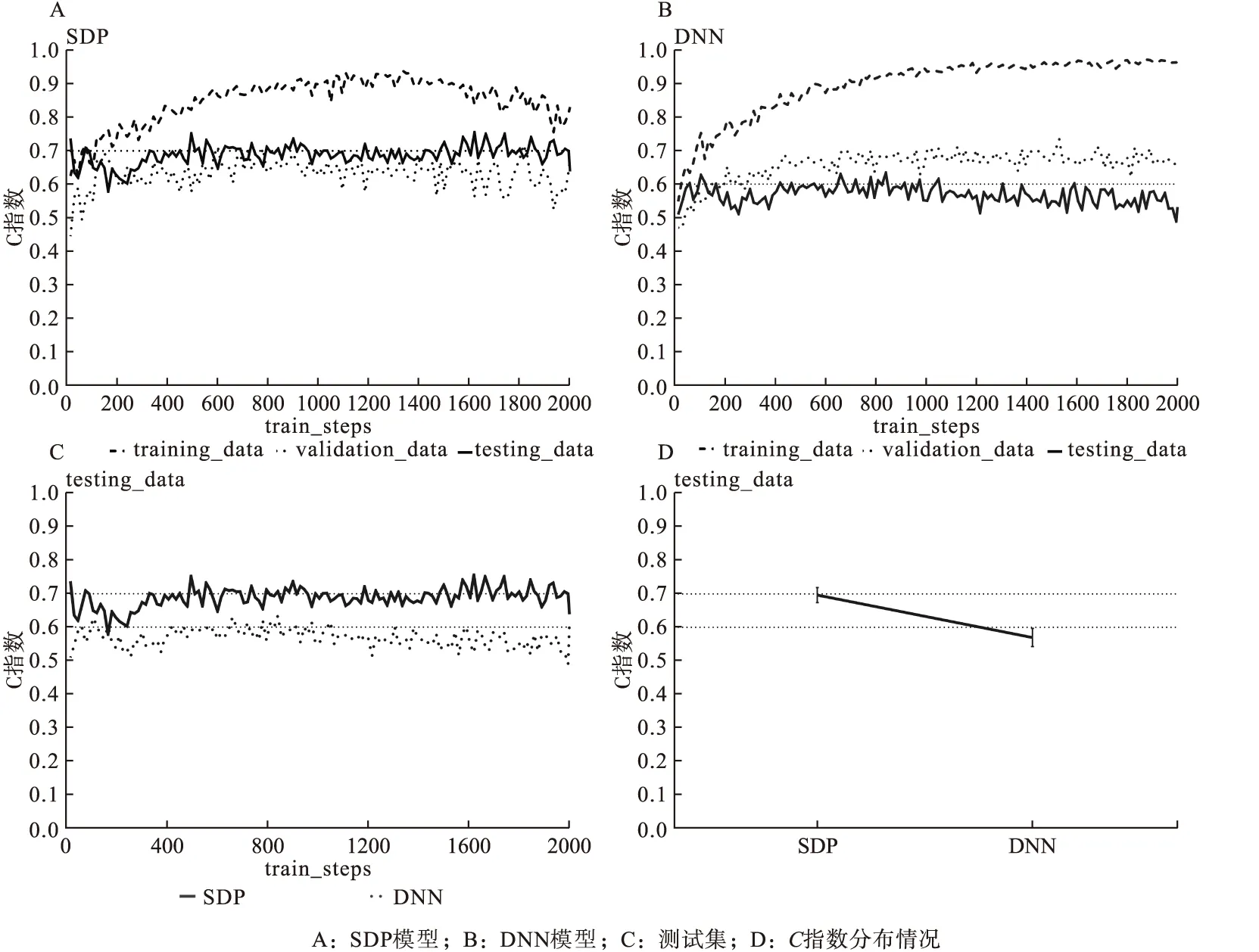
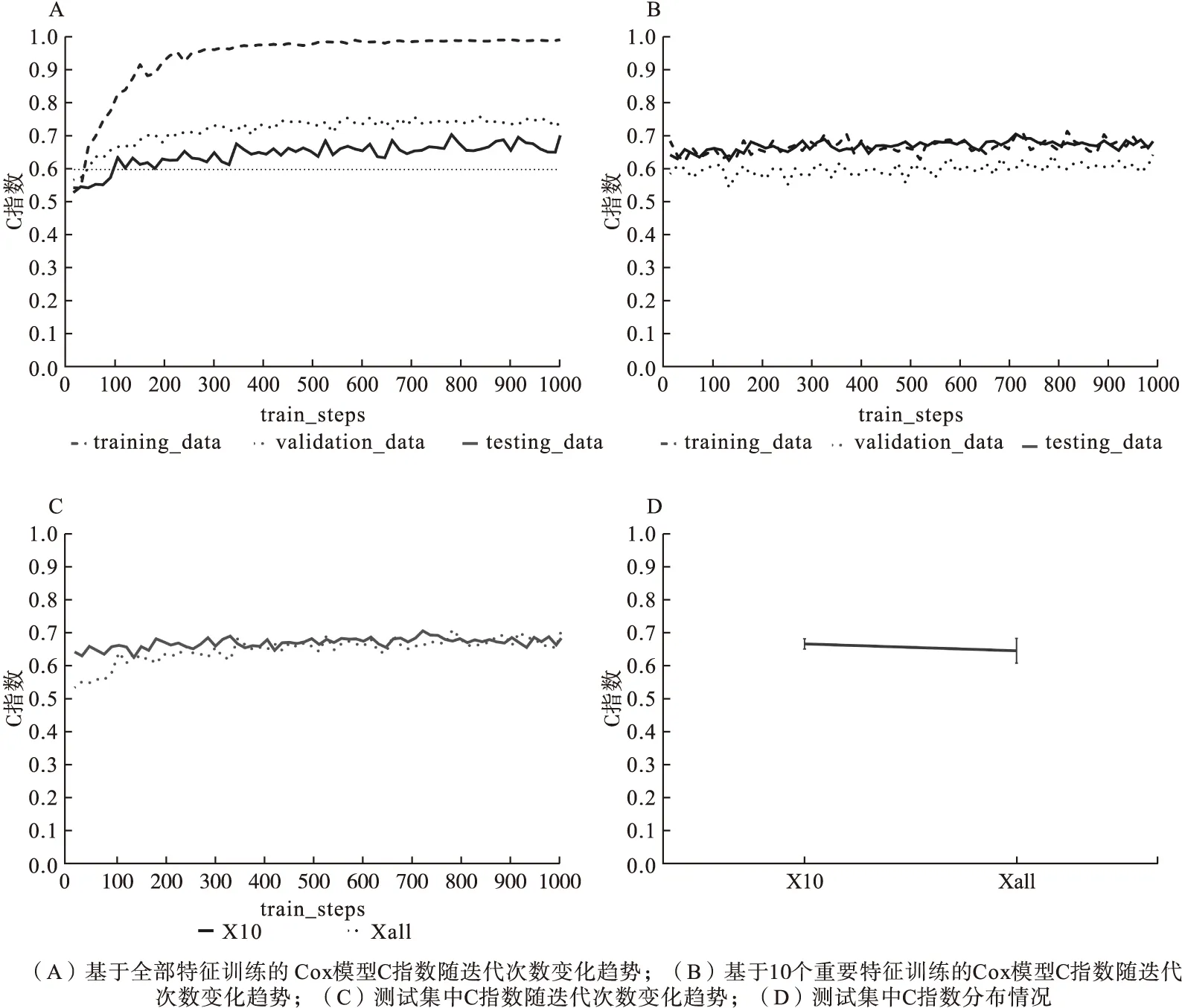
首先,將k個樣本生存時間從小到大排序t1 (5) 則各死亡時間點累積死亡概率為: (6) 式中censor表示刪失狀態。對公式(6)取對數得到以下公式: (7) 此為SDP模型不考慮正則化懲罰時的損失函數。當考慮稀疏輸入層成組特征和單個特征時,將SGL懲罰項加入式(7)中,則SDP模型的損失函數表達式為: (8) 2.模型訓練及評價指標 根據樣本量大小選取適當批尺寸的樣本進行模型迭代訓練,用60%的樣本作為訓練數據集(training dataset)進行模型訓練,用20%的驗證數據集(validation dataset)評估并選擇出模型預測能力較高時的正則化參數α、λ,最終的模型預測能力通過另外20%測試數據集(testing dataset)進行比較。本文以生存分析為例評價SDP模型的預測準確性,評價指標選用常規生存分析預測準確性評價指標C指數,C指數越高說明模型預測準確性越高。 1.模擬數據產生原理及特征 通常分三步產生包含隨機刪失的生存數據:首先采用Bender等提出的模擬方法[8],產生完整生存時間T。第二步產生刪失時間Tc,觀察時間T0=min(Tc,T)。第三步判斷樣本狀態,如果T≤TC,則觀察時間為T,該樣本狀態為死亡;如果T>TC,則觀察時間為Tc,此時樣本為刪失狀態。 本研究模擬在固定總特征不變的前提下,考慮不同分組信息以及每組包含不同的變量個數情況下,評價模型的預測能力。模擬數據共分為三個場景,主要探討深度神經網絡融合不同正則化方法模型的預測能力及過擬合改善情況,以及模型預測能力較好時樣本特征規律。具體特征如表1。 表1 模擬數據特征* 2.模擬數據結果 (1)融合不同正則化方法模型預測效果比較 本次模擬改變輸入層與第一隱藏層權重稀疏方法,比較DNN及其融合不同正則化方法時模型預測準確性。由圖2A可知DNN模型預測C指數約為0.5,準確性較差,驗證集、測試集與訓練集間距離依然很大存在過擬合現象。由圖2B~F可知,當融合lasso回歸、嶺回歸、分組lasso回歸及稀疏分組lasso(SGL)時,測試集C指數均值分別為0.5、0.72、0.77、0.8,除嶺回歸外模型預測能力均有顯著改善;訓練集與驗證集和測試集的間距明顯縮小,有效改善DNN模型的過擬合問題。其中融合SGL時預測準確性及過擬合問題改善最為明顯。DNN模型測試集C指數約為0.5,與DNN融合稀疏分組lasso(SDP)模型的差異有統計學意義(t=-31.95,P<0.0001),SDP模型預測能力優于傳統的DNN模型。 圖2 DNN融合不同正則化方法后模型C指數隨迭代次數的變化情況 從上述結果中可以看出,基于模擬數據data1應用SDP模型對生存風險的預測結果與實際情況一致性較好(0.8),為進一步探索模型對重要特征的提取能力,將基于data1數據集訓練的SDP模型輸入層與第一隱藏層的權重輸出,對每個特征各節點權重加和后得到各個特征的權重,按絕對值大小進行排序,選取權重值前32的特征與模擬生存數據的特征做對比,32個特征中與相關特征(16個)一致的特征有15個,特征提取靈敏度為93.75%,可證明模型對重要特征提取的準確性較高。 (2)不同分組情況SDP模型預測效果比較 本次模擬固定樣本量不變,假定先驗分組方式不同,則組內變量個數不同,即模擬產生組內變量個數不同的data2A~data2E數據集,比較先驗分組信息不同條件下SDP模型與DNN模型的預測準確性。當組內變量個數為2、4、8、16、32時,正則化參數的最佳組合分別為0.5/0.99、0.25/0.99、16/0.99、64/0.999、32/0.99。在圖3A~B中,除組大小為2、4的C指數低于0.5,其余分組方式SDP模型C指數均高于0.8。說明應用SDP模型時,要選擇合適的先驗分組信息,注意控制組內變量個數不宜過低;圖3C中,隨著組大小的增大,C指數有逐漸增高的趨勢,當組大小≥8時SDP模型C指數大于0.8,預測能力較好。為了進一步總結分組方式不同時,正則化參數設置的規律,以2E數據集為例,設λ×(1-α)為橫軸,迭代次數2000~3500的C指數均值為縱軸(此時模型訓練趨于穩定),觀察隨正則化參數變化C指數均值變化情況,如圖3D,當λ×(1-α)大于1時,C指數均值低至0.5,模型預測能力不佳,將圖3D的0~1部分放大,當λ×(1-α)小于0.45時,SDP模型的預測C指數高于0.7,預測能力較好。 圖3 不同分組情況SDP模型的預測情況 (3)不同樣本量SDP模型預測效果比較 本次模擬固定分組方式不變,改變樣本量以比較不同樣本量條件下,SDP模型與DNN模型的預測準確性。在不同研究、不同平臺及不同疾病等中,可獲得的模型訓練數據樣本量不同,而樣本量大小可能影響模型的學習能力,進而影響其預測性能。如圖4A所示,在各樣本量條件下,SDP模型C指數均大于0.7,SDP模型預測能力較好;圖4B中,Y軸為訓練穩定后,各模擬數據集測試集C指數均值,SDP模型C指數均大于DNN模型,預測能力優于DNN模型;如圖4C所示,隨著樣本量增大,SDP模型C指數有逐步上升的趨勢,當樣本量≥700時,C指數在0.8以上,模型預測能力較好。 圖4 不同樣本量SDP模型和DNN模型的預測情況 TCGA數據庫中乳腺癌患者的mRNA數據(1217例)、臨床表型數據(1284例)和生存數據(1260例)進行分析,考慮到樣本刪失率不能超過80%,否則測試時可能會導致無可比對子數進而無法計算C指數,因此排除部分刪失數據,最終選擇700例樣本作為模型訓練樣本。考慮到京都基因與基因組百科全書(Kyoto encyclopedia of genes and genomes,KEGG)通路是一組包含生物系統信息的網絡通路,其可整合生物分子及化學分子間的相互作用[9],因此將KEGG通路作為乳腺癌mRNA特征的分組信息。采用R軟件中的“org.Hs.eg.db”軟件包識別60483個KEGG-ID號,共有25880個mRNA成功獲得KEGG-ID號;利用KEGG的API獲取基因對應的通路信息,共有32605個mRNA(一個mRNA可能存在于多個通路中,共7921個mRNA)富集于337個通路,每個通路中包含的mRNA的范圍是1到1487個;考慮到臨床表型特征的實際意義以及缺失率,納入8個臨床表型特征進行分析,包括初始診斷年齡、TNM分期、樣本來源、種族、初始診斷類型以及stage分期,將每個特征單獨分為一組。 基于此數據訓練模型,當正則化參數λ、α分別設為16、0.999時,SDP模型預測結果如圖5所示,與DNN模型相比,SDP模型過擬合問題及預測能力有明顯改善。隨著迭代次數的增加SDP模型訓練集C指數與驗證集、測試集的C指數間距小于DNN模型訓練集與測試集間距,說明SDP模型一定程度上改善了單純DNN模型存在的過擬合現象(見圖5A和圖5B)。SDP模型測試集C指數均值為0.70,相較于DNN模型的0.58有明顯提高,預測能力改善明顯(見圖5C和圖5D)。 圖5 SDP模型及DNN模型在乳腺癌數據中的預測情況 為了進一步說明SDP模型特征提取的準確性,在訓練好的SDP預測模型中,根據輸入層與第一隱藏層的權重求得各特征的平均權重,排序得到權重前10的重要特征,基于這10個特征建立Cox模型,與利用全部特征擬合的Cox模型進行預測能力、過擬合改善情況的對比。如圖6A,基于全部特征訓練Cox模型,其訓練集C指數與驗證集、測試集C指數間差距較大,模型存在過擬合問題。如圖6B,基于提取特征訓練的Cox模型,其訓練集C指數與驗證集、測試集C指數間差距明顯縮小,有效改善了過擬合問題。由圖6C和圖6D可知,基于SDP模型中提取的重要特征訓練的Cox模型C指數為0.67,與基于全部特征訓練的模型的0.65相比,其預測能力差異不大。綜上所述,基于SDP模型提取的特征訓練Cox模型,可在不降低預測準確性的同時,有效改善由于變量過多導致的過擬合現象,提示提取的特征與預后相關較好,證明SDP模型在重要特征提取方面具有一定的優越性。 圖6 基于乳腺癌數據不同特征擬合Cox模型的預測情況 基于小樣本高維組學數據應用深度神經網絡(DNN)模型時,存在的一個顯著缺點是模型的“過擬合”問題,該問題可以通過減少過度參數化、簡化、壓縮DNN解決。壓縮DNN模型一般有構建法和修剪法兩種方法,修剪法學習速度較快,對初始條件的敏感度較低,并且泛化能力較強,因此修剪法更為常用。神經網絡修剪方法,一般包括以下四種類型,即基于閾值的方法、基于結構靈敏度的方法、基于結構間相關性的方法以及基于梯度正則化的方法[10]。相對于其他三種方法,基于梯度正則化方法因以下優勢而使用更加廣泛:第一,正則化方法不需要預訓練模型,模型參數調整與結構修剪可同時進行;第二,不需要計算靈敏度、特異度;第三,僅通過添加一個或多個正則化項稀疏網絡結構;第四,可以考慮學習錯誤使模型獲得更好的性能。目前基于梯度正則化的方法未用于輸入層數據[7,11-12],然而應用DNN進行癌癥預測問題時,輸入數據中存在大量的對預測不重要的冗余數據,以及一些相對很重要的數據,若不加選擇地全部應用于模型訓練,勢必會導致模型的過擬合問題,影響其預測準確性。 在本研究中,基于梯度正則化修剪網絡的思想,在DNN模型損失函數中加上稀疏輸入層特征的正則化項,在最小化誤差調節參數的同時懲罰輸入層特征的權重,不斷加強對重要特征的學習,有效改善了模型過擬合問題、提高了其預測能力。目前常見的正則化方法中,嶺回歸是將每個變量系數變小;lasso可以使部分變量稀疏為0;分組lasso回歸根據先驗分組信息考慮組間特征的相關性,對分組變量進行篩選;SGL回歸結合lasso和GL回歸二者優勢,可同時實現成組變量和單個變量的篩選,對特征的稀疏程度更加充分。由模擬實驗結果可知,相對于其他正則化方法,融合SGL的SDP模型的C指數最高、預測能力最好,測試集和驗證集C指數與訓練集差距最小,過擬合改善情況最為明顯。可能的原因是與其他的正則化方法相比,SGL將先驗分組信息加入模型損失函數的正則化項,充分考慮了輸入特征間的相關性,同時稀疏分組特征和單個特征,模型對重要特征提取能力可能更高。當組內變量個數≥8時,SDP模型預測能力優于單純DNN模型;應用于不同樣本量數據時,SDP模型的預測能力優于DNN模型,當樣本量≥700時模型預測能力更佳,樣本量越大SDP模型的學習越充分。 在實例分析中,通過聯合TCGA乳腺癌的mRNA數據和臨床表型數據,應用SDP模型和DNN模型進行死亡風險預測,顯示SDP模型預測準確性和過擬合改善情況優于DNN模型。值得注意的是,有研究表明隨著數據刪失率的增大,Cox模型的偏倚性、準確性以及模型的擬合程度均會有所下降,且刪失率較大時模型偏倚性有加速下降的趨勢[13-15]。而在乳腺癌訓練數據中刪失率高達76%,但應用SDP模型其預測準確性較高,提示SDP模型對于刪失率較高的數據可能具有一定的適用性。另外,在基于乳腺癌數據訓練的SDP模型中,通過特征權重排序獲得的重要特征訓練Cox模型,與基于全部特征訓練的Cox模型相比,過擬合現象有顯著的改善,說明SDP模型在特征提取方面具有一定的優越性。 SDP模型也存在一定的缺陷,例如損失函數加入正則化項后降低了模型的運算速度,當數據變量較多時較為耗時;另一個問題是網絡結構的設置,如網絡層數、各層節點數,均可能影響模型的預測結果,如何設置網絡結構有待進一步探討。根據目的不同,可以將SDP模型的輸出層部分的Cox模型替換,如當感興趣結局為事件的分類時,像患病與否,疾病分型等,可連接logistic模型或者SVM模型等,但此時DNN融合正則化模型的預測能力是否依然優于DNN模型有待未來的研究具體驗證。
模擬數據
實例分析
討 論
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
發明與創新(2022年30期)2022-10-03 08:40:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
人大建設(2018年6期)2018-08-16 07:23:10
文理導航·科普童話(2017年5期)2018-02-10 19:42:14
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
