基于知識圖譜的變電站安全隱患動態分析方法
2022-01-13 10:11:20郭素芹鄭建寧林瑞安張勃波
電力系統及其自動化學報 2021年12期
郭素芹,鄭建寧,陳 坤,林瑞安,張勃波,宗 鑫
(福建億力電力科技有限責任公司,福州 350003)
近年來,電力企業各項安全生產工作穩步推進,安全文化建設持續深入,安全管理水平不斷提升[1-2]。但在安全管控的高壓態勢下,變電站設備隱患、隱患指數仍居高不下。由于變電站生產過程中的安全隱患無處不在,涉及到人員隱患、設備設施隱患、消防隱患、電力安全隱患等各個方面,需要運維管理人員及時發現并規范防護,降低安全事故發生的概率[3-5]。實際工作中通過人工錄入隱患排查治理表文檔的方式記錄變電站隱患信息,由于變電站安全隱患記錄的非結構化特點給隱患分析造成了很大困難。雖然有相關的電力規范以表格形式對可能發生隱患的部件和對應現象等進行了總結,但隱患情況復雜多樣,規范中表格難以進行全面歸納[6]。此外,隱患記錄是以自然語言的非結構化文本形式進行描述,進一步增加了計算機對變電站隱患記錄的理解難度,文本的檢索效果依賴于文本的語義分析和表示方法的有效性。
在電力系統領域文本處理方面已經開展了大量研究。文獻[7-8]基于人工經驗建立了語義框架,并通過語義框架填充來表示文本,但是語義框架形式為二維表形式,靈活性和可擴展性不足,難以表征電力設備等安全隱患情況,同時語義框架的定義十分依賴專家經驗,難以挖掘隱患記錄內在的復雜性、關聯性和規律性。文獻[9]通過文本挖掘分析變電站變壓器故障,評估了各種因素如何引起跳閘問題。為了解決傳統專家經驗的局限性,部分研究利用機器學習算法進行數據挖掘,通過人工智能方法自動挖掘文本記錄中關鍵詞的規律,并且利用統計特征對文本進行向量化表示。文獻[10]集成了詞的全局矢量表示方法和基于注意力的雙向長期短期記憶方法。文獻[11]根據電力設備中缺陷文本的特征,建立了基于卷積神經網絡的缺陷文本分類模型,該模型的準確性明顯高于傳統的機器學習方法。文獻[12]基于智能變電站二次設備的歷史缺陷數據,提出了一種基于Apriori算法的二次設備缺陷數據挖掘與分析方法,為設備的運行和控制提供參考。然而,上述模型在文本表示和語義信息提取方面存在一些不足,容易造成文本語義信息的丟失。因此,在特征提取與分類過程中,如何獲得更好的文本表示并保持文本的語義信息是提高電力安全隱患智能分析能力的關鍵。
鑒于以上分析,隱患文本信息之間存在明顯的邏輯和作用關系,本文利用知識圖譜的關聯圖結構對文本信息及其之間的關系進行表示,突破語義框架二維表結構的局限,在充分考慮變電站隱患文本信息內在邏輯的基礎上,設計彈性搜索引擎實現隱患數據高效存儲和索引;提出隱馬爾可夫模型-維比特算法HMM-VA(hidden Markov model-Viterbi algorithm)的隱患分詞處理模型,從隱患語料中自動提取構建知識圖譜所需的信息;基于Neo4j圖數據庫和Echart渲染技術實現知識圖譜的動態生成和隱患記錄的關聯分析。以某地區變電站電力隱患數據為例,結果表明所提方法能有效地對隱患文本進行管理,并防范潛在的電力安全隱患。
1 變電站安全隱患非結構化數據抽取與存儲
電力系統變電站安全隱患一般通過人工錄入隱患排查治理表來記錄,包括隱患排查時間、隱患設備信息、運維管理違規信息、防控措施等多維度、大體量文本數據,為了利用這些非結構化數據動態分析隱患關聯,首先對安全隱患信息進行信息抽取,將非結構化數據轉化為JavaScript對象簡譜JSON(JavaScript object notation)格式,進而設計彈性搜索引擎實現數據的高效存儲。
1.1 變電站設備隱患信息抽取
變電站的運行涉及多個部門、單位,也涉及多種設施、設備和線路,是電力系統內部的專業化工作,隱患內容繁雜[13]。雖然有相關的電力規范以表格形式對可能發生隱患的部件和對應現象等進行了總結,但隱患情況復雜多樣,規范中的表格難以進行全面歸納。
變電站一般隱患排查治理表是一種特殊的非結構化文檔,形式上具有半結構化文檔的特征,但數據流實際上是非結構化的。除了文檔中的信息以外,原來的表格線全部被空格和換行符所替換,真實數據與這些空格和換行符混為一體,增加了計算機處理難度。從數據類別看,非結構化表格文檔中的數據可分為標題區和數據區,標題區表示數據的性質和類別,數據區表示數據實際取值,例如“隱患詳細分類”為標題區,“開關刀閘設備”為數據區。隱患數據抽取是提取表格中所有標題區和數據區,數據組織是要建立標題區和數據區的語義聯系,以及相關標題區之間的語義關系,并以JSON的格式進行儲存。
數據抽取流程如圖1所示。首先進行數據抽取步驟,通過標準化的JSON生成器將非結構化數據抽取與之關聯的特征數據并形成JSON文件,提取對應的數據實體,例如隱患排查時間、排查地點、設備名稱、事故隱患內容、違反規定信息、評估等級、防控措施等;然后使用導入工具將抽取出的JSON文件進行讀取并解析,依據解析出來的特征劃分分類與屬性,并將各個實體歸納為相應分類并賦予屬性。
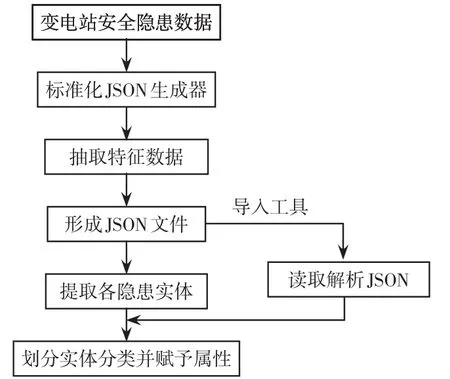
圖1 數據抽取流程Fig.1 Data extraction process
1.2 基于ElasticSearch搜索引擎的隱患數據存儲
由于變電站設備密集,隱患數據隨著設備的增多呈現指數型增長,知識圖譜的自動生成與關聯需要高效的數據存儲與檢索操作,因此本文設計了基于ElasticSearch的實時彈性分布式搜索引擎。圖2為安全隱患數據存儲流程。
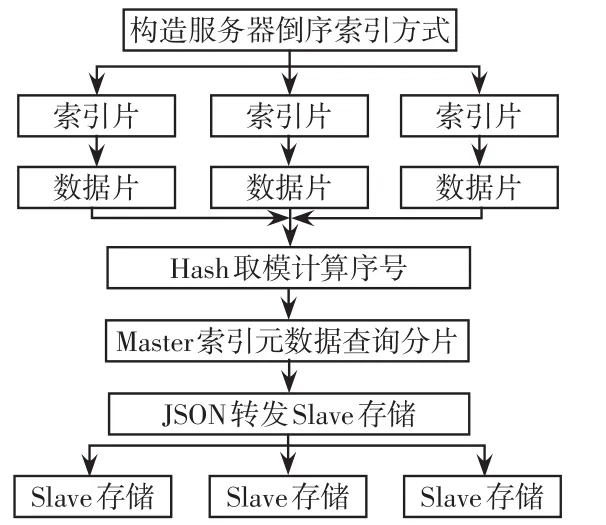
圖2 數據存儲流程Fig.2 Data storage process
由于搜索過程需要大量迭代計算,為了提高性能,在服務主機器上構造倒序索引方式,由JSON中所有不重復的詞語組成,建立詞語與包含其文檔列表的映射,文檔列表的每條記錄包括文檔鑒別號碼ID(identity card)、出現頻率、該詞在文檔中出現的位置等。
構建多個索引分片,每個分片都進行獨立的隱患數據存儲,且每個分片只有一份數據[14-15]。通過路由公式,采用hash取模方式進行分片序號的計算,然后通過master主節點的索引元數據可以查詢該分片所屬的分片信息,并且可以繼續獲取其網絡協議IP(internet protocol)信息,再將JSON轉發到各slave節點的信息進行存儲。
知識圖譜的倒排全文索引示例如圖3所示。現有相似數據包括主變壓器異常、主變壓器滲油、主變壓器容量、主變壓器停運等信息。倒排索引是將數據中的詞進行拆分,構建出一張表,進而將關鍵詞拆解出來,例如“鍵值”中用“值”去索引“鍵”。當輸入“主變壓器”時,會被拆分為“主”、“變壓器”2個關鍵字,利用這2個關鍵字去倒排索引表中檢索數據,并將結果返回。
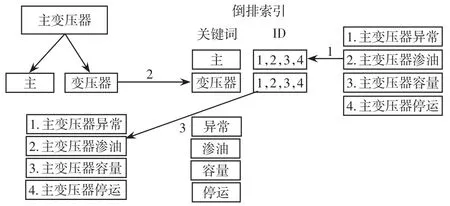
圖3 隱患知識倒排全文索引示例Fig.3 Example of inverted full-text index of hidden danger knowledge
利用高性能Lucene信息搜索庫處理片級索引查詢,維護相關索引文件,ElasticSearch在Lucene之上寫入功能元數據,例如各隱患字段映射、索引配置及其他集群元數據。若干個段和提交點組成Lucene索引,每段都是1個倒序索引,提交點用來記錄可用段,通過提交點就可以獲取全部可用段并做段上查詢。
2 基于HMM-VA的安全隱患文本分詞處理模型
電力設備信息中每個漢字都有屬于自己的構詞詞位。構詞詞位可用4種標簽表示,即B表示詞首位、M表示詞中位、E表示詞尾位,S表示單獨成詞。設備信息中每條信息構成觀測序列,每個字的構詞詞位標注構成狀態序列。設備信息分詞可轉換為構詞詞位標注問題,基于已加工好的語料庫,得到隱馬爾科夫模型HMM(hidden Markov model)的參數信息λ=(π,X,Y),再通過維特比算法VA(Viterbi algorithm)得到待分詞文本的構詞詞位標注序列。
隱馬爾科夫模型參數包括觀測序列O={o1,o2,…,ot};狀態序列Q={q1,q2,…,qt};初始狀態概率集合π表示模型在初始時刻各狀態出現的概率;狀態轉移概率矩陣X表示模型在各個狀態間轉換的概率;觀測概率矩陣Y表示模型根據當前狀態獲得各個觀測值的概率。
初始狀態概率集合π可表示為
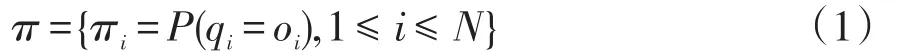
式中:i為第i種觀測狀態;N為觀測狀態的最大數目。
狀態轉移概率矩陣X可表示為

式中,z為字的詞位序列,z=(B,M,E,S)。
觀測概率矩陣Y可表示為
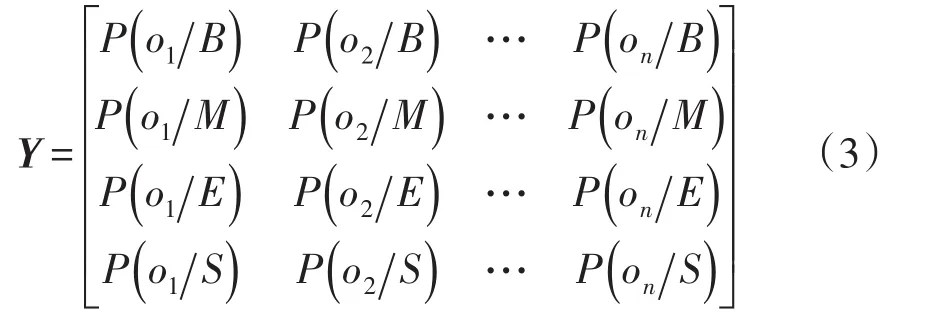
式中:P(on/z)為觀測值的概率;oj為觀測值。
隱馬爾科夫分詞模型訓練完成后可通過VA來預測設備信息中漢字的構詞詞位從而達到分詞的目的。VA采用動態規劃的思路,求解給定觀察序列的最大概率的隱藏狀態序列。算法基本流程如下。
步驟1初始化,即

式中:S1(i)為觀測序列初始時刻在狀態i下最大概率,1≤i≤N;φ1(i)為初始時刻在狀態i下概率最大的單路徑;πi為初始狀態i的概率;bi(o)為觀測值o1的概率。
步驟2狀態轉移,即

式中:St(i)為觀測序列t時刻在狀態i下最大概率,1≤i≤N;φt(i)為t時刻在狀態i下概率最大的單路徑;Ot為t時刻觀測序列,2≤t≤T,T為最大時刻。
步驟3輸出最大概率的狀態序列,即

3 基于圖譜搜索的安全隱患動態分析
3.1 變電站安全隱患知識圖譜構建
變電站安全隱患知識圖譜中實體及關系復雜多樣,隨著設備設施的更新換代,知識圖譜也應進行不斷補充以保證設備信息檢索的準確性和實效性。圖數據庫的可視化功能使變電站設備信息具有更強的可讀性,方便運維管理人員快速獲取變電站設備相關參數和運行數據。變電站安全隱患知識圖譜構建過程如下。
步驟1分詞與實體屬性抽取。通過前文方法將安全隱患信息提取和分詞處理,然后將分詞結果進行詞性標注,進而通過命名識別出各部分實體及屬性。由于電力領域詞匯的專業性與特殊性,故將電力行業專業詞典作為輔助分詞工具導入數據庫,若抽取出的實體和屬性與詞典詞匯相匹配,則確定該實體與屬性。在電力特定領域內,變電站安全隱患知識圖譜屬于封閉性圖譜,故不需要進行實體消歧步驟。
步驟2關系抽取。對于電力設備隱患的固有隱患危害程度等屬性,除了需要抽取實體-實體、實體-屬性之間的關系之外,還需抽取屬性-屬性的關系。通過依存句法分析隱患實體和屬性各成分間的“主謂賓”、“定狀補”等依存關系;通過人工篩選標注安全隱患關系種類,依次針對電力安規相關術語進行細致劃分,形成安全隱患關系語料。在對關系抽取完成后,為避免冗余現象,通過語義相似度計算篩選冗余關系[7],提高處理性能。以“66 kV變電站2號主變壓器差動保護裝置”為例,說明實體-實體、實體-屬性和屬性-屬性的關系,如圖4所示。
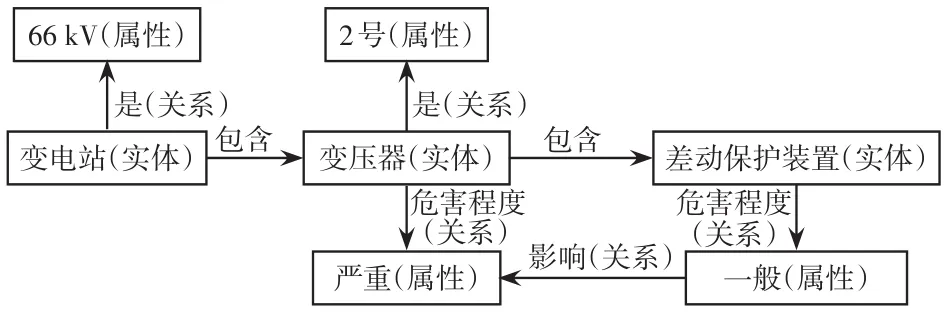
圖4 實體-實體、實體-屬性、屬性-屬性的關系Fig.4 Relationships of entity-entity,entity-attribute,and attribute-attribute
步驟3圖譜生成。利用Neo4j圖數據庫[16-17]將上述處理的數據進行整合,導入安全隱患的實體-屬性-關系三元組并加載語料,創建實體之間的關系和屬性匹配,形成變電站安全隱患知識圖譜,實現全局索引。變電站安全隱患知識圖譜生成示例如圖5所示。
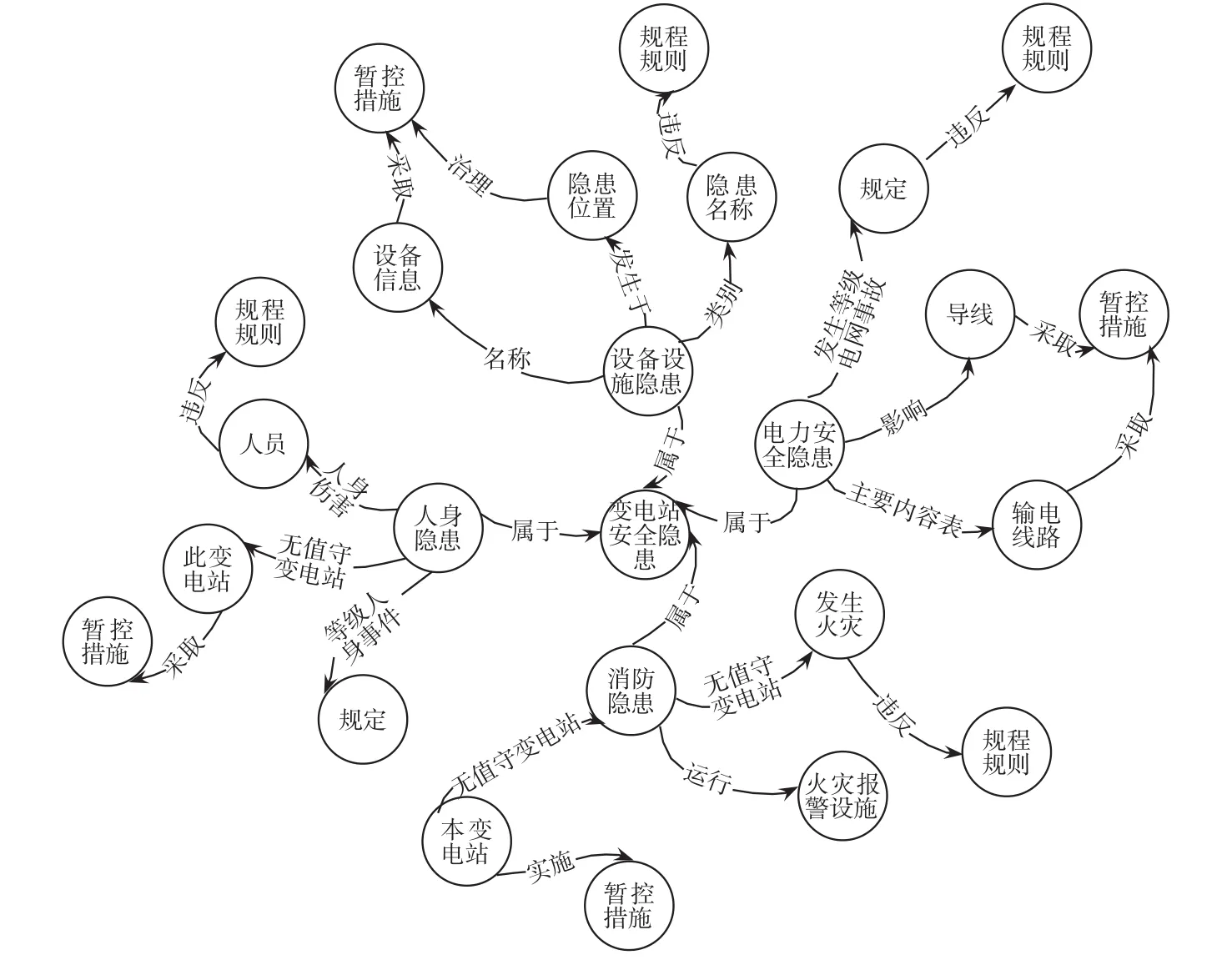
圖5 變電站安全隱患知識圖譜生成示例Fig.5 Example of generating a knowledge map of hidden dangers in substation
3.2 基于知識圖譜的安全隱患動態分析
通過把Vue.js圖庫集成到應用程序中,將存儲至Neo4j圖形數據庫的隱患數據推送到Web端展示,并采用Echarts實現數據的圖表可視化,形象化呈現給運維管理人員具體隱患的原因、類別和危害等,以指導采取暫控措施和防控措施等。
變電站安全隱患知識圖譜搜索引擎架構設計如圖6所示,主要由數據倉庫、服務模塊和應用模塊組成。數據倉庫包括elastic-block隱患元數據分布式管理、中文分詞管理、索引管理和logstash批量文件導入。經過處理后的隱患數據呈遞至服務模塊,包括ElasticSearch service用以提供所以排序和存取讀入、data-offer service用以提供新數據的錄入、security service用以提供權限控制和安全管理。最后呈遞至應用模塊,包括隱患信息錄入、檢索展示和安全隱患知識圖譜展示。
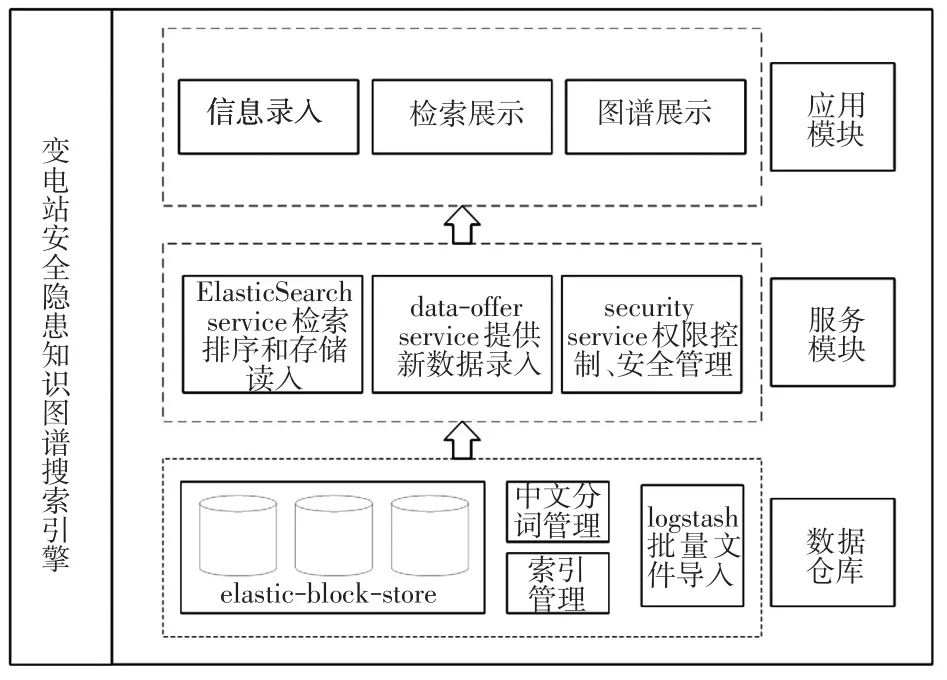
圖6 變電站安全隱患知識圖譜搜索引擎架構Fig.6 Search engine architecture of the hidden danger knowledge map of substation
基于知識圖譜搜索引擎的變電站安全隱患動態分析流程如圖7所示。變電站安全隱患知識圖譜引擎設計步驟如下。
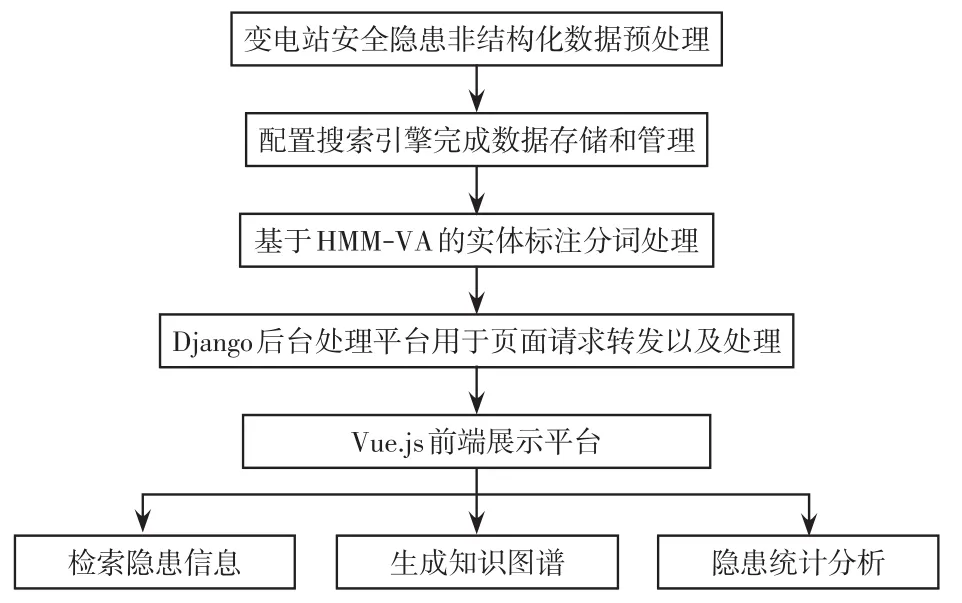
圖7 變電站安全隱患動態分析流程Fig.7 Dynamic analysis process of hidden dangers in substation
步驟1構建Django后臺處理框架,主要用于頁面請求轉發以及處理,其中包括創建Elastic-Search彈性搜索引擎服務模塊和HMM-VA分詞服務模塊。
步驟2構建基于Vue.js的前端展示平臺,主要用于對后臺處理內容的前端展示,主要包括變電站安全隱患檢索信息展示、安全隱患知識圖譜生成和統計分析功能。
步驟3環境模塊阿里云部署,在Centos系統上,使用Docker部署Django后臺、HMM-VA分詞服務模塊、ElasticSearch、Vue前端等請求并配置相關參數,聯調使用。
根據以上步驟,通過錄入安全隱患信息,添加具體的關鍵信息字段,例如“66 kV”、“變電站”、“雨天”等關鍵詞,就可以個性化動態生成該地區66 kV變電站安全隱患知識圖譜,利用圖譜的關聯性搜索可以分析當前各類設備面臨的隱患類別、隱患原因、未處理結果后的危害、可能治理方式、違反規程規則、防控措施等。
4 實驗算例分析
本文以某省電力公司變電站近3年的安全隱患歷史數據作為數據集,驗證所提方法的有效性和實用性。數據集包含隱患1 655個,包括電力安全隱患、人身安全隱患、設備安全隱患、其他事故隱患等。通過人工錄入和批量導入的方式將隱患信息存儲于構建的知識圖譜搜索引擎中。
運用所提HMM-VA分詞模型對安全隱患文本進行分詞處理,通過以下4個算例進行所提方法的有效性驗證,包括變電站安全隱患實體分詞方法對比、搜索引擎信息檢索性能對比、變電站安全隱患原因知識圖譜分析、隱患風險統計分析與預測。
4.1 變電站安全隱患實體分詞方法對比
本文提出的HMM-VA模型分詞步驟包括語料庫訓練、測試集預測和得出分詞結果。預訓練使用國網公司電力詞典和變電站安全隱患規范語料庫,共15萬詞,初始參數信息λ=(π,X,Y)采用有監督方式通過訓練語料庫后得到,而不采用固定的數值參數,統計每個安全隱患詞性出現的次數,每個隱患詞性和后面隱患詞性出現的次數及隱患詞性對應的詞可計算概率π,進而計算狀態轉移概率矩陣X和觀測概率矩陣Y。
采用實體分詞問題中常用到的評價指標體系準確率P、召回率R及F值作為評價指標,通過評價指標體系對變電站安全隱患分詞效果進行評價。
(1)精確率P可以表示為

式中:TP為測試樣本中的預測類別為正例且真實類別為正例的實體數;FP為預測類別為正例且真實類別為負例的實體數。
(2)召回率R可以表示為

式中,FN為預測類別為負例且真實類別為正例的實體數。
(3)F值可以表示為

考慮在不同命名實體分詞模型上進行算例對比,進而驗證本文所提模型的分詞效果。實驗中涉及到模型包括博耶-摩爾BM(Boyer-Moore)匹配模型[18]、N-gram分詞模型[19]、jieba模型[20]及本文提出的HMM-VA模型。以上模型均在同一訓練集和測試集上進行。表1為測試集在不同命名實體識別模型效果對比結果。
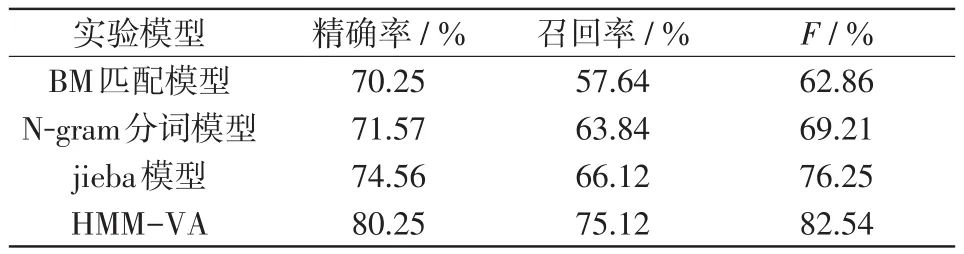
表1 命名實體識別模型效果對比Tab.1 Comparison of effects among named entity recognition models
從表1實驗結果可以看出,本文所提出的基于HMM-VA的電力安全隱患分詞模型在精確率、召回率和F值指標表現的效果均優于其他3種實體分詞模型。
4.2 搜索引擎信息檢索性能對比
通過測試單機索引[21]和分布式索引的索引速度來衡量系統的索引性能,前者是使用Elasticsearch默認配置的單機搜索引擎,后者為本系統設計和配置的12個節點的分布式搜索引擎。索引性能的測試結果如表2所示。搜索時間測試結果如表3所示。
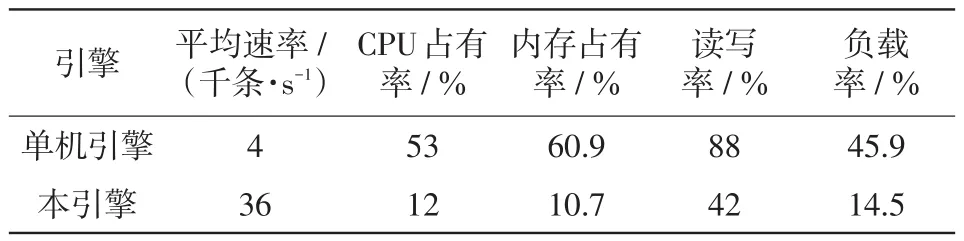
表2 索引測試結果Tab.2 Index test results
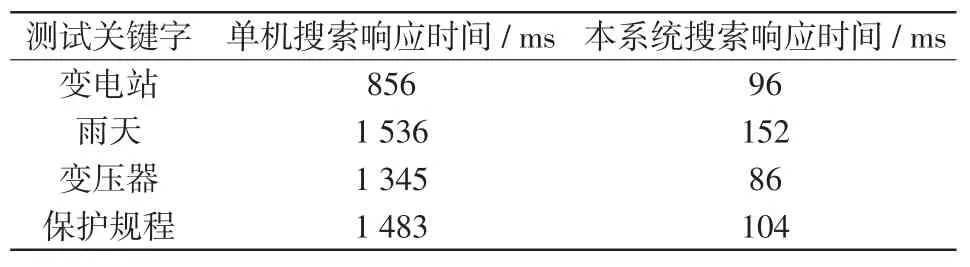
表3 搜索時間測試結果Tab.3 Search time test results
如表2所示,本文設計和配置的彈性分布式搜索引擎對于數據的平均速率、CPU占有率、內存占有率、讀寫率、負載率等索引效率指標明顯優于單機搜索引擎,說明提出的方法有效提高了隱患數據索引的實時性,也滿足對于實際變電站隱患排查工作中的快速處置效率要求。
如表3所示,對于4種測試關鍵字的搜索,單機平均響應時間為1 305 ms,本文提出的搜索平均響應時間為109.5 ms,說明本引擎響應時間明顯低于原有單機響應時間,充分證明了文中搜索引擎的優勢,而且隨著數據體量的增加,本搜索引擎對于安全隱患數據的處理優勢十分顯著。
4.3 變電站安全隱患原因知識圖譜分析
根據220 kV變電站檢索內容自動生成的變電站安全隱患原因知識圖譜如圖8所示。從圖8可以看出,220 kV變電站中隱患原因包含人身安全隱患、設備設施隱患和電力安全隱患3個方面。
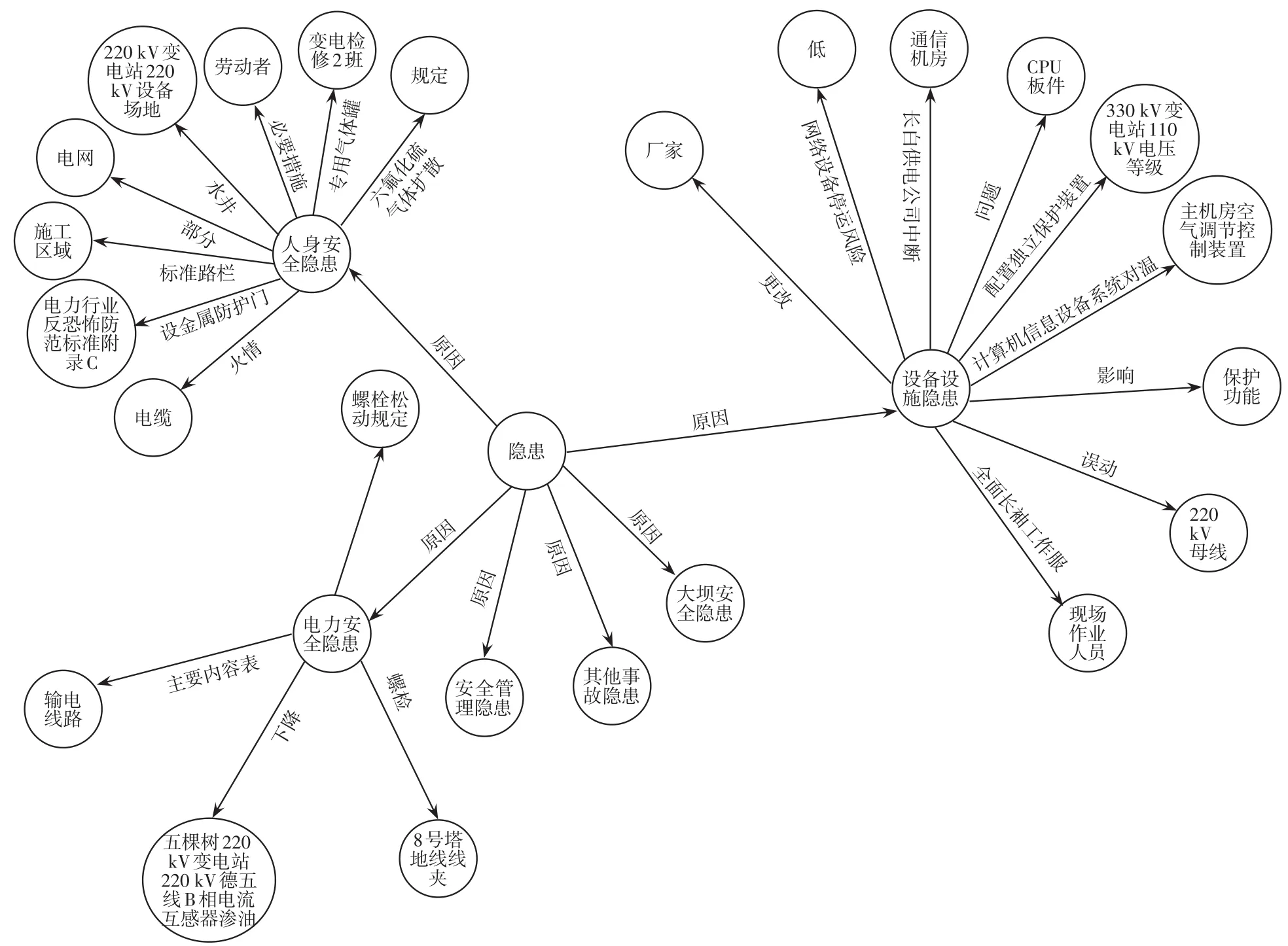
圖8 變電站安全隱患原因知識圖譜Fig.8 Knowledge graph of the causes of hidden dangers in substation
(1)人身安全隱患方面。例如:變電站六氟化硫氣體罐未存放專用庫房存在人身安全隱患,需要加大變電站巡視力度,未存放至專用庫房之前,不準人員進入倉庫,并對現場環境進行檢測,是否出現泄漏情況;220 kV變電站中由于施工中車輛行駛壓壞,設備場地排水井蓋上有裂紋,且裂紋嚴重,不符合《國家電網公司變電運行規程》,需及時更換新的排水井蓋;施工區域未設置標準路欄,存在安全隱患等。
(2)設備設施隱患方面。例如:需要聯系廠家更換破舊設備設施;網絡設備停運造成的運行風險較低,330 kV變電站110 kV電壓等級的設備設施需配置獨立保護裝備;現場工作人員需穿戴全棉長袖工作服;CPU板件出現問題;設備設施隱患影響系統保護功能等。
(3)電力安全隱患方面。例如:四鐵220 kV牽引站電源線違反了螺栓松動規定,可能發生變壓器接地,不能迅速造成開關動作跳閘,極易造成人身傷害事件;8號塔地線線夾螺栓缺失,違反《架空輸電線路運行規程》主要內容表“線路本體:螺栓松動”之規定;五棵樹220 kV變電站220 kV德五線B相電流互感器滲油,油位指示下降,若不及時處理,將導致電流互感器絕緣擊穿、220 kV母差保護動作、220 kV德五線線路保護動作、瞬間造成220 kV德五線及2號主變與220 kV北母線非計劃停運,減供負荷。
4.4 隱患風險統計分析與預測
通過調取各單位3月—7月的變電站隱患知識圖譜統計,如圖9所示,共有繞組變形E1、故障停運E2、保護誤動E3、引流線脫落E4、污閃和雨閃事故E5、機構泄壓E6等6類變電站隱患。根據變電站知識圖譜統計這6類隱患發生次數可以得出不同月份不同隱患的發生規律,對變電站的隱患預防可以有針對性地進行,采取不同的措施和對策,以保障變電站的安全穩定運行。
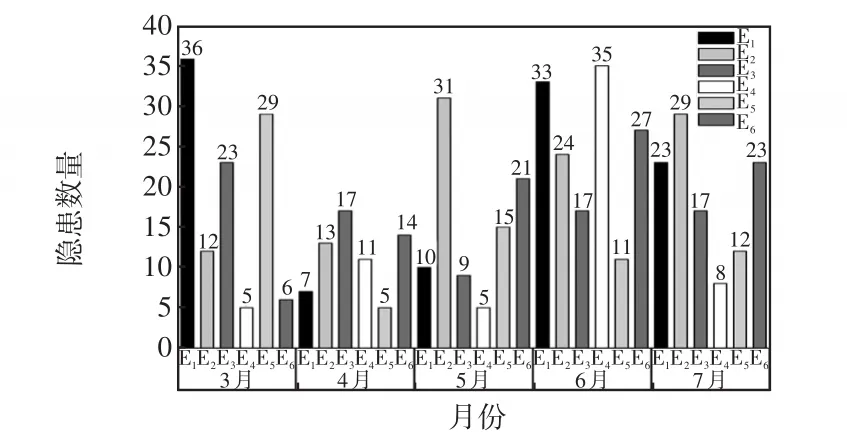
圖9 3月—7月變電站隱患次數統計分析Fig.9 Statistical analysis of the number of hidden dangers in substation from March to July
由圖9可知,通過隱患圖譜將隱患的關鍵表現特征進行了描述,根據季節性及周期性規律可以預測未來某種類型的設備或作業,在特定的時間周期內容易產生的隱患類型,例如“繞組變形”在3月和6月隱患較為明顯,應該額外注意防范,其余5種隱患類型分析亦然。通過變電站隱患統計分析,防范措施主要根據變電站專家經驗、《國家電網公司變電運行規程》與《國網公司隱患風險管理白皮書》的指導建議,可以預測易發隱患位置。例如:①遭受10 kV線路出口短路、近區多次短路沖擊的變壓器,無法有效掌控沖擊程度,易產生繞組變形;②運行15 a及以上的互感器設備及電磁型電壓互感器易發生異常引起故障停運;③變壓器瓦斯繼電器、壓力釋放閥防雨措施不完善等反措未落實,易造成保護誤動;④部分設備引流線線夾、壓接管松動問題逐步顯現,易造成引流線脫落而引發事故;⑤部分變電設備外絕緣爬距不滿足標準要求,處于污穢嚴重地區,雨雪、霧霾天容易發生污閃、雨閃事故;⑥220 kV開關液壓機構需按周期進行大修,超檢修期或施工工藝不到位易引發機構泄壓,被迫停運風險。
實驗結果表明,本方法能夠對變電站安全隱患進行有效分析和預測,提供給運維檢修人員輔助決策,為變電站安全穩定運行提供有力保障。
5 結語
本文引入知識圖譜技術和彈性分布式搜索引擎技術,提出了變電站安全隱患動態分析方法,詳細分析了安全隱患數據與分布式存儲,給出了基于HMM-VA的分詞處理、知識圖譜構建等完整的隱患動態分析過程,通過實驗算例證明了知識圖譜搜索引擎在隱患可視化展示、高效檢索和關聯分析上的優勢,為現有的安全隱患管控處置提供借鑒和指導,具有良好的實際應用和推廣價值。在后續研究中,將在關系抽取步驟中提取更多語料特征,提高知識圖譜構建的精確性,從而提升變電站安全隱患的分析效果。
猜你喜歡
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
電子制作(2018年8期)2018-06-26 06:43:34
電子制作(2017年8期)2017-06-05 09:36:15
現代工業經濟和信息化(2016年5期)2016-05-17 05:35:57
小學教學參考(2015年20期)2016-01-15 08:44:38
中國衛生(2015年12期)2015-11-10 05:13:38
河南電力(2015年5期)2015-06-08 06:01:45
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
技術經濟與管理研究(2014年11期)2014-03-11 17:02:44
