直鏈淀粉的傅里葉衰減全反射中紅外特征光譜篩選與定量分析
2022-01-06 05:01:32夏蘭欣
食品科學 2021年24期
關鍵詞:模型
王 廣,劉 宇,夏蘭欣,李 偉,程 超,
(1.生物資源與利用湖北省重點實驗室(湖北民族大學),湖北 恩施 445000;2.湖北民族大學生物科學與技術學院,湖北 恩施 445000)
淀粉由直鏈淀粉和支鏈淀粉兩大主要部分構成,這兩種淀粉在理化性質、分子結構和相對分子質量等方面存在一定差異,直鏈淀粉含量是影響淀粉產品加工品質的重要指標之一,如稻米中直鏈淀粉含量高則米質松散,而支鏈淀粉含量高的米質較黏稠[1],因此能及時快速掌握原料中直鏈淀粉的含量對其加工產品種類具有一定指導作用。近年來發展起來的測定支鏈淀粉和直鏈淀粉含量的方法有單標單波長法、單標雙波長法、雙標單波長法、雙標雙波長法、自動分析檢測法、伴刀豆球蛋白法及排阻色譜分析法,這些方法需要將產品進行復雜的前處理才能測得直鏈淀粉含量,且此過程易導致淀粉損失,這不僅使得研究數據不準確,還限制了某些領域的生產速度[2]。
近年來快速、無損紅外定量檢測技術發展迅速,如利用近紅外和中紅外光譜定量分析肉制品、乳制品等產品中摻假成分[3-8]、米酒和巧克力的抗氧化能力[9-10]、脂肪酸、淀粉結晶度等指標測定[11-14]等。有資料報道中紅外定量分析效果略優于近紅外,如向伶俐等[15]用近、中紅外光譜儀采集中國4 個不同葡萄主栽產地153 個葡萄酒樣品的近紅外透射光譜和中紅外衰減全反射光譜,建模后發現4 個產區葡萄酒判別模型建模集的平均準確率為78.21%(近紅外)和82.57%(中紅外),檢驗集平均準確率為82.50%(近紅外)和81.98%(中紅外),但二者融合后均優于單獨采用一種光譜技術。鄒小波等[16]發現中紅外光譜建立的玉米淀粉回生模型較近紅外光譜更佳。熊艷梅等[17]用近紅外和中紅外法測定氰戊菊酯、馬拉硫磷定量模型的相關系數分別為0.998 1、0.999 4和0.994 6、0.999 8,外部驗證集標準差分別為0.082、0.081和0.092、0.075,中紅外的定量方法略優于近紅外。Musingarabwi等[18]利用傅里葉變換近紅外和衰減全反射中紅外光譜技術對不同發育階段的白蘇維翁葡萄漿果進行了定性和定量分析,結果發現中紅外光譜分析結果更可靠。
多組分樣品紅外光譜數據相對較大,很難辨析目標成分的特征分析光譜,需要選擇合理的光譜區間進行分析,合適、準確的波段區間能減少計算量,同時提高精度[19],因此區間選擇法和變量篩選法等在優化紅外光譜模型方面得到了廣泛的應用,如肖朝耿等[20]利用區間偏最小二乘(partial least squares,PLS)法,向后PLS法、向前PLS法進行波譜區間選擇,結果發現向后PLS法模型效果最優。此外詹雪艷等[21]利用MATLAB軟件的移動窗口PLS、組合間隔PLS和競爭自適應抽樣方法進行建模的變量篩選,發現競爭自適應抽樣方法能實現目標成分紅外特征大部分化學特征的解析,有利于增強模型的解釋性。
鑒于此,本實驗以馬鈴薯直鏈淀粉與支鏈淀粉標準品為原材料,在iD7ATR Transmission衰減全反射附件上對樣品進行掃描,獲取其紅外圖譜,嘗試利用Simca軟件的主成分分析(principal component analysis,PCA)和正交偏最小二乘(orthogonal partial least squares,OPLS)回歸分析篩選影響直鏈淀粉含量的全反射中紅外光譜的特征波段,而后結合TQ analyst軟件對比分析以此波段建立的直鏈淀粉含量定量分析預測模型的可行性和準確性。
1 材料與方法
1.1 材料與試劑
馬鈴薯直鏈淀粉標準品、馬鈴薯支鏈淀粉標準品美國Sigma公司。
1.2 儀器與設備
PTY-224/323電子天平 福州華志科學儀器有限公司;iS5傅里葉紅外光譜儀、iD7 ART Transmission衰減全反射附件 美國Thermo公司。
1.3 方法
1.3.1 樣品制備
準確稱取馬鈴薯直鏈淀粉、馬鈴薯支鏈淀粉兩種標準品,使其直鏈淀粉質量分數分別為0%、2%、4%、6%、8%、10%、12%、14%、16%、18%、20%、22%、24%、26%、28%、30%、32%、34%、36%、38%、40%、42%、44%、46%、48%、50%、52%、54%、56%、58%、60%、62%、64%、66%、68%、70%、72%、74%、76%、78%、80%、82%、84%、86%、88%、90%、92%、94%、96%、98%、100%,將上述稱取的樣品裝入PE管中,擰緊管蓋,旋渦振蕩混合均勻,備用。
1.3.2 中紅外光譜數據的采集
用藥匙取少量1.3.1節制備的淀粉樣品,置于傅里葉紅外光譜儀的iD7 Transmission衰減全反射附件上,進行紅外掃描,波數范圍為400~4 000 cm-1,掃描次數共32 次,分辨率為8 cm-1,掃描間隔為2 cm-1[22]。每個直鏈淀粉含量的樣品做2 次平行實驗。
1.4 數據及圖形處理
利用Simca14.1軟件對不同直鏈淀粉含量的中紅外圖譜進行PCA和OPLS回歸分析[23],而后采用TQ analyst 8軟件對光譜數據進行處理,使用PLS建立定量模型并驗證。所有圖形均利用Origin2018作圖。
2 結果與分析
2.1 直鏈淀粉和支鏈淀粉的傅里葉中紅外全反射圖譜
一般認為紅外光譜中4 000~1 500 cm-1區域為官能團區;1 500~400 cm-1為指紋區[24],當分子結構略有變化時即可在指紋區的吸收峰上表現出細微差異。純直鏈淀粉和支鏈淀粉及二者混合樣品的衰減全反射中紅外圖譜見圖1。
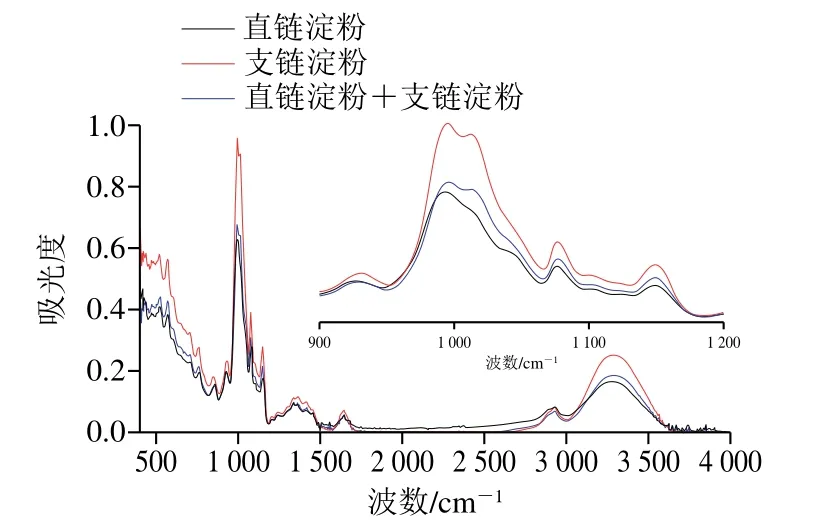
圖1 直鏈淀粉和支鏈淀粉及其混合樣品的傅里葉全反射中紅外圖譜Fig.1 FT-MIR spectra of amylose, amylopectin and their mixed samples
由圖1可看出,在指紋區含有兩種淀粉的特征結構,該區間含有淀粉基本結構α-D-吡喃葡萄糖環、淀粉晶體和無定形結構的特征振動,將圖譜進行解卷積處理后發現,1 047 cm-1和1 022 cm-1分別具有淀粉結晶區和非結晶區域的特征振動,這與文獻[16,25]的研究結果一致,同時測定發現同等濃度時由于不同樣品結晶度不同,這兩個波段的吸收峰也有差異。此外在900~1 000 cm-1為α-1,4-糖苷鍵的C—O—C伸縮振動等[26-28],因此可以利用這些振動信息與直鏈淀粉含量相關聯建立預測模型。
2.2 傅里葉中紅外光譜定量分析直鏈淀粉含量的特征波段的選擇
每種化合物都具有特征紅外吸收光譜,因此才得以進行定性和定量分析。由于樣品組分眾多,其獲取的紅外光譜分析數據集相對較大,因此要選擇合適的波段,減少計算量、提高計算精度。
2.2.1 直鏈淀粉含量與其中紅外圖譜相關性確定
利用Simca軟件對所有不同含量直鏈淀粉的中紅外光譜數據進行PCA,為降低噪音的影響,對中紅外光譜數據進行Ctr中心化處理后進行PCA,結果發現可以分為4 個PC,其中R2X為0.986,Q2為0.982,表明4 個PC包含了樣品的大部分信息,能代表樣品中直鏈淀粉含量的主要光譜特征,PCA的scoreplot見圖2。由圖2可看出,PCA結果可以客觀地分析中紅外光譜數據和直鏈淀粉含量的分布態勢,隨著PC1在-10~8、PC2在-2.5~1.5范圍的遷移,直鏈淀粉的含量逐漸增加,說明傅里葉中紅外圖譜數據與直鏈淀粉含量具有一定的相關性。
2.2.2 直鏈淀粉含量與中紅外圖譜回歸模型分析
為進一步探索傅里葉中紅外光譜數據是否能足夠預測直鏈淀粉含量,利用Simca軟件進行OPLS回歸模型分析。
OPLS是一種新型的多元統計數據分析方法,可研究Y變量和多元X變量之間的關系,最大特點是可去除自變量中與分類變量無關的數據變異,使分類信息主要集中在一個或幾個PC中,模型變得簡單和易于解釋,其判別效果及PC得分圖可視化效果更明顯[29],因此利用Simca軟件建立直鏈淀粉含量與中紅外圖譜的OPLS回歸模型,模型的R2X為0.979,R2Y為0.958,Q2為0.940,說明此回歸模型較好,為進一步考察此回歸模型的可靠性,對此OPLS模型進行擬合和置換檢驗,結果見圖3和圖4。
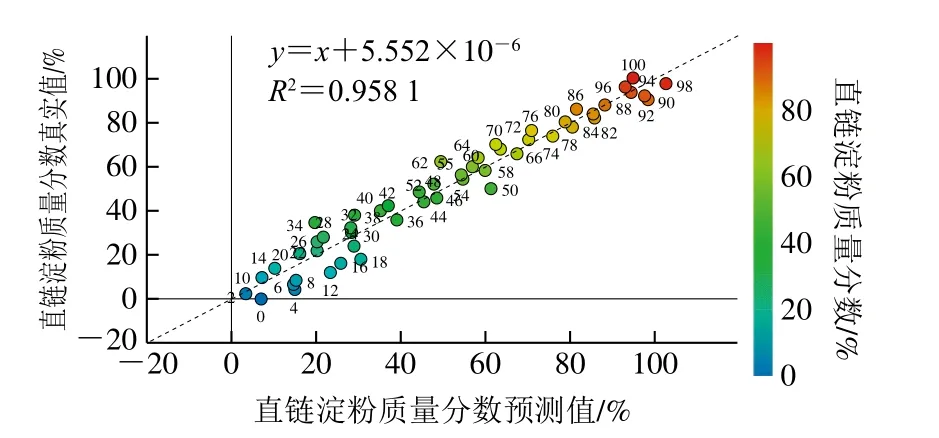
圖3 基于OPLS法回歸模型的直鏈淀粉含量擬合效果Fig.3 Fitting of actual amylose contents to predicted values from OPLS regression model
由圖3可以看出,R2為0.958 1,說明此回歸方程擬合程度較高。從圖4的R2和Q2可以看出,隨機數據產生的模型比現有模型差很多,說明現有OPLS模型可靠。為深入了解在400~4 000 cm-1中對直鏈淀粉含量影響最顯著的波段,對OPLS模型進行變量重要度投影[30](variable importance for the projection,VIP)分析,結果見圖5。
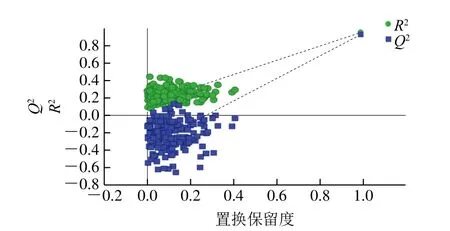
圖4 基于OPLS回歸模型的置換檢驗圖Fig.4 Permutation plot based on OPLS regression model
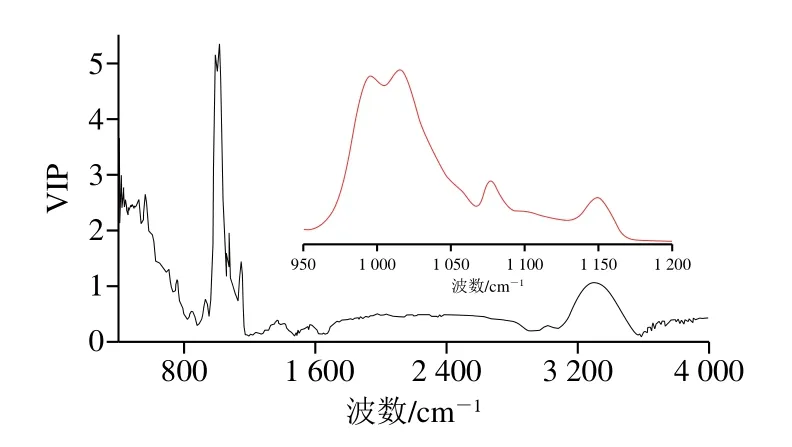
圖5 基于OPLS回歸模型VIP圖Fig.5 VIP plot based on OPLS regression model
由圖5可看出,直鏈淀粉含量模型擬合貢獻比較大波段主要有400~765、969~1 158、3 250~3 329 cm-1,這3 個波段區間的VIP大于1,因此可以認為此波段可作為影響直鏈淀粉含量預測的特征波段。
2.3 不同直鏈淀粉含量的中紅外圖譜模型建立及驗證
鑒于400~765 cm-1的噪音干擾過大,3 250~3 329 cm-1受羥基影響大,因此只選擇VIP大于1的969~1 158 cm-1作為不同直鏈淀粉含量的中紅外圖譜檢測的分析波段。利用TQ analyst軟件對傅里葉中紅外的全波段和此分析波段分別進行建模預測和驗證。使用TQ analyst8軟件進行數據分析,選擇原始光譜數據、一階導數、二階導數的處理方法,在PLS法的基礎上建模。
2.3.1 直鏈淀粉混合樣品定量模型的建立
分別用隨機數生成器,在淀粉紅外圖譜中隨機選擇2/3為建模集,1/3為驗證集,驗證集為隨機選擇包含高中低濃度的樣品圖譜,依次選用400~2 000 cm-1、主要指紋峰波段800~1 200 cm-1、OPLS分析的VIP大于1的969~1 158 cm-1三大波段為建模波段,在PLS方法基礎上,每個波段分別以原始圖譜數據、一階導數和二階導數處理的光譜數據建立兩個模型,模型內部采用交叉驗證的方法。表1為400~4 000、800~1 200、969~1 158 cm-1建模和交叉驗證的結果。
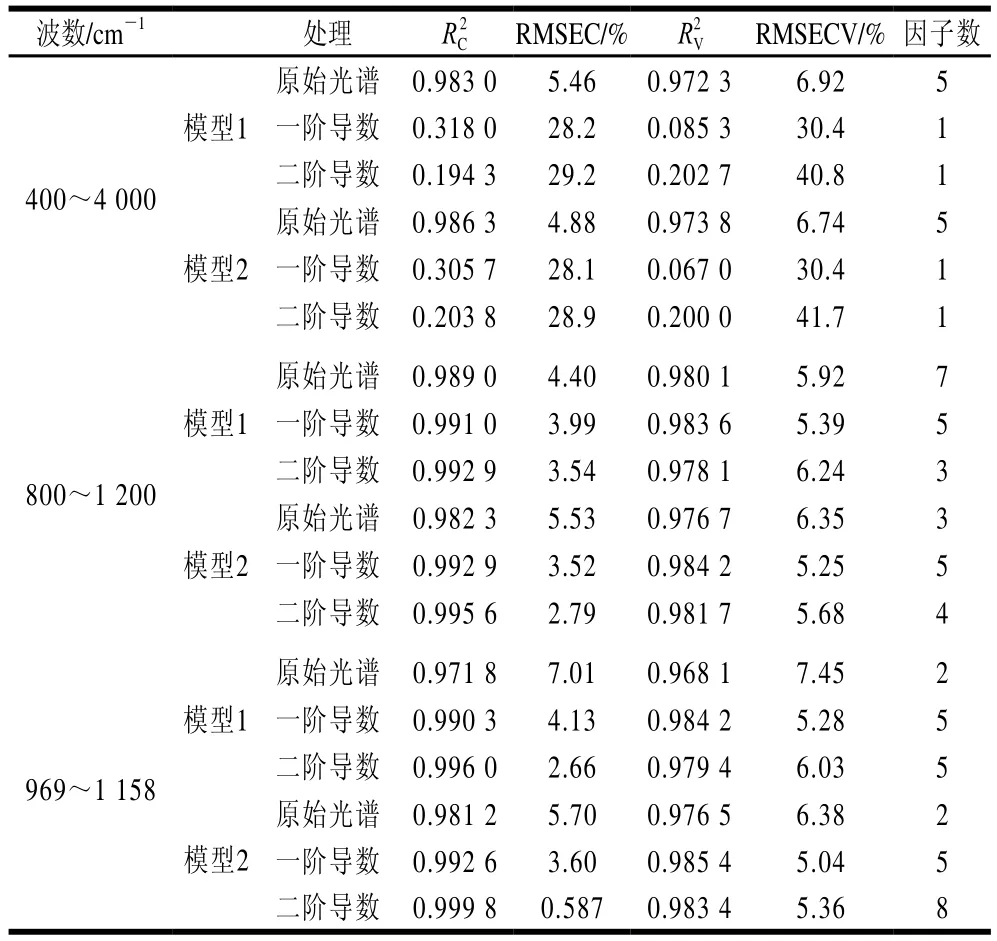
表1 不同分析波段PLS建模的模型參數Table 1 Parameters of PLS models within different bands
所構建的模型,其內部穩健性和擬合效果是根據決定系數(RC2)和校正集均方根誤差(root mean square error for calibration,RMSEC)為指標進行綜合評定。模型內部預測能力以決定系數(RV2)和交互驗證均方根誤差(root mean squares error of cross-validation,RMSECV)為評價指標。其中決定系數越大,其均方差越小,對應的模型擬合效果就越好。
比較表1的3 個波段的PLS建模參數可知,選用400~4 000 cm-1建模時,在兩個模型中,原始光譜的建模效果均顯著優于一階導數、二階導數處理后,這可能是由于全光譜建模會將很多噪聲信息納入,這些噪音信息和反映直鏈淀粉含量的光譜信息混合,而光譜導數處理同時也放大了噪聲信息,進而對模型造成嚴重干擾[31]。以800~1 200 cm-1和969~1 158 cm-1兩個波段的光譜數據的建模效果顯著優于400~4 000 cm-1,這兩個波段建模的RC2和RV2基本上均大于0.97,說明模型的擬合效果和內部預測能力均較好,通過比較可以看出這兩個波段建模效果的順序均為二階導數>一階導數>原始光譜,尤其是以Simca軟件篩選VIP大于1的969~1 158 cm-1RC2顯著優于800~1 200 cm-1,達到了0.999 8;這可能是由于Simca篩選的分析變量去除光譜中噪音變量和冗余變量,從而提高模型的穩定性,此外對原始光譜數據經一階導數和二階導數處理后,反映直鏈淀粉的信息量得到放大,使光譜之間的差異更加明顯,能將重疊的峰分開,提供了比原光譜更高的分辨率和更清晰的光譜輪廓變化,因此二階導數處理的建模效果最優。
2.3.2 模型驗證結果
進一步用驗證集對模型進行外部驗證,由于400~4 000 cm-1建模效果較差,同時800~1 200、969~1 168 cm-1的原始數據建模效果也較差,因而驗證時舍棄。驗證集數據預測結果如表2所示。為更直觀地比較預測效果,將模型中驗證效果良好的800~1 200 cm-1波段和969~1 158 cm-1的一階導數和二階導數建模的預測值與真實值進行擬合作圖,結果見圖6。
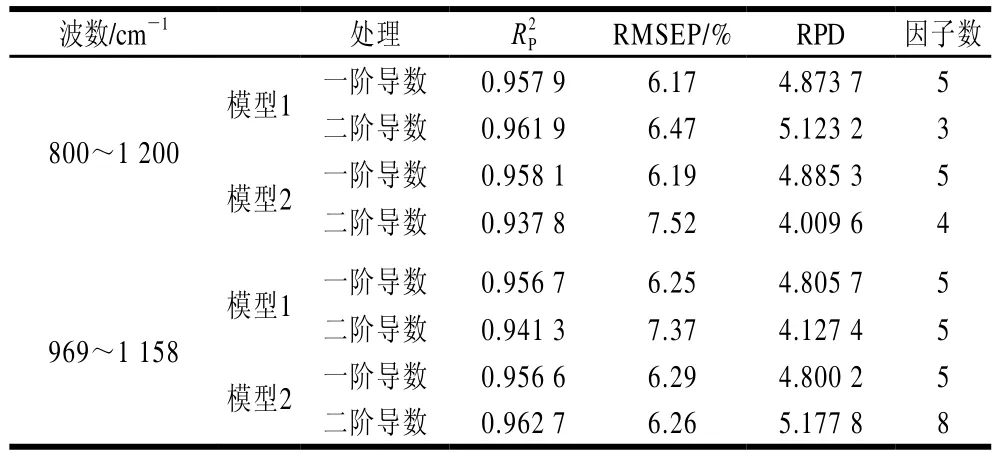
表2 全波長驗證數據預測效果Table 2 Validation of prediction models based on full-band spectra
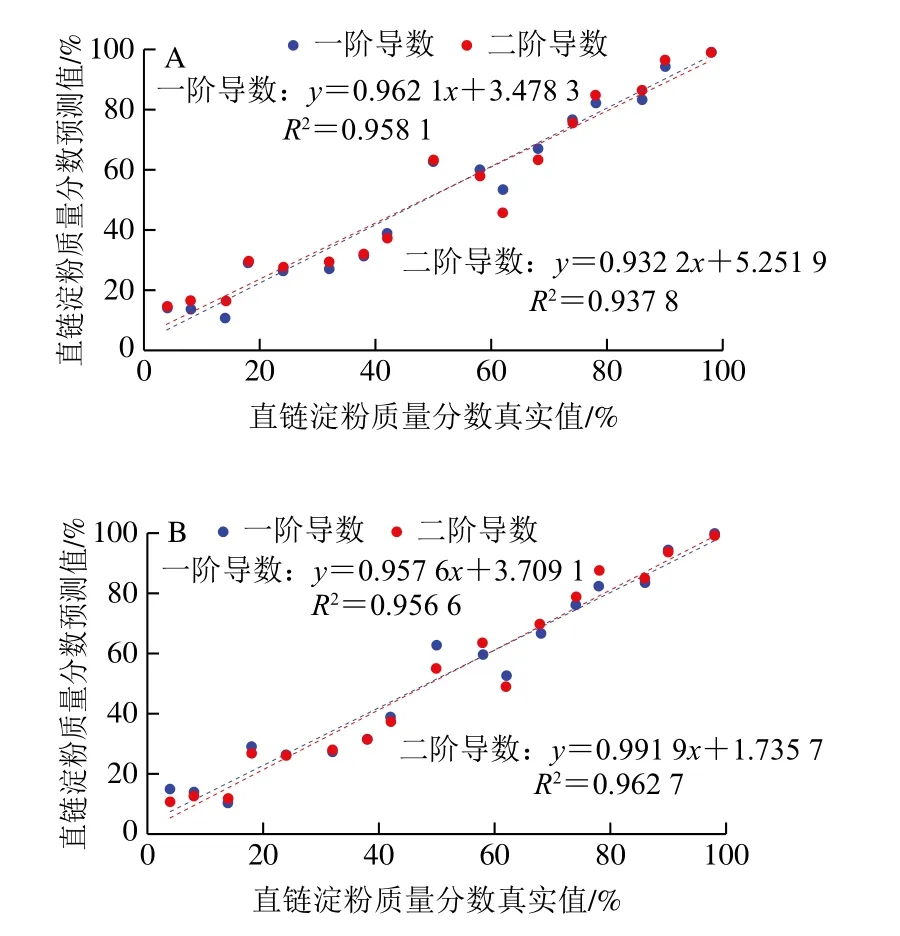
圖6 驗證集驗證效果Fig.6 Validation with validation set in the region of 800 -1 200 cm-1 and 969-1 158 cm-1
所構建好的模型,根據驗證樣品的預測能力,以線性相關系數(RP2)和預測集均方根誤差(root mean square error for prediction,RMSEP)作為評價指標觀測實驗結果,相關系數越接近1,RMSEP越小,則其所對應模型的預測效果就越好。此外,相對分析誤差(relative percent deviation,RPD)也是評價模型預測能力的關鍵指標之一,RPD可以對不同樣本集造成的影響進行有效消除,并能夠提高實驗預測的準確性,使其更加標準化。RPD越大,表征其相對應模型的預測能力越好。當RPD>3時,表明模型有很好的預測效果。
由表2可以看出,驗證集的RPD都大于3,線性相關系數在0.93以上,說明這兩個波段模型1、2具有很好的預測效果。但通過對比發現,以969~1 158 cm-1為分析波段經二階導數數據處理后建模驗證時,其預測相關系數最高可達到0.962 7,而預測均方差也相對較低,同時圖6B的驗證結果也說明中紅外光譜模型預測值與真實值接近,具有較好的線性關系。
3 結 論
本實驗利用傅里葉衰減全反射中紅外光譜建模定量分析直鏈淀粉含量,為提高預測模型的準確性,利用Simca軟件的PCA和OPLS分析篩選了中紅外定量分析的特征波段,結果發現969~1 158 cm-1特征波段,主要對應直鏈淀粉的結晶區和非結晶區,同時也是α-1,4-糖苷鍵C—O—C伸縮振動的特征波段,基于此特征波段、全波段等,利用TQ analyst軟件采用PLS法使用原始光譜、一階導數、二階導數的處理方法建模驗證時發現,969~1 158 cm-1光譜數據進行二階導數處理后建模的效果最優,模型的預測性能較全波段等得到了提高,模型相關系數為0.999 8,RMSEC和RMSEP分別為0.587%和6.26%,RPD為5.177 8,預測值和真實值相關系數為0.962 7。因此OPLS篩選的變量能實現直鏈淀粉中紅外區大部分化學特征的解析,可增強預測模型的解析性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
