基于集成學習的乳腺癌生存預測研究
2022-01-01 11:39:10張繼婕覃慶洪劉雪萍王康權魏薇
廣西科技大學學報 2022年1期
關鍵詞:乳腺癌
張繼婕 覃慶洪 劉雪萍 王康權 魏薇

摘? 要:為對乳腺癌5年生存狀態進行預測并分析其影響因素,首先,選取SEER數據庫中2004—2010年乳腺癌相關數據,對選取的特征進行數據預處理;其次,在數據層面上,對數據進行SMOTE上采樣以解決數據類別不平衡問題;在算法層面上,比較LightGBM、CatBoost和GBDT這3個模型在預測乳腺癌5年生存狀態上的優劣;最后,根據重要性對乳腺癌5年生存狀態的影響因素進行排序,并通過SHAP值對影響因素進行解釋分析。本文構建的乳腺癌5年生存狀態預測模型比單一模型具有更好的性能,其準確率、AUC、召回率、精確度和F1值分別為0.906 0、0.844 3、0.983 7、0.916 0和0.948 7;發現乳腺癌5年生存狀態與腫瘤大小、檢出的淋巴結總數、淋巴結轉移數、雌激素受體、孕激素受體、年齡等因素有較大關系。本預測模型選擇出的重要性特征與目前的臨床結果保持一致,能為臨床預后預測提供一定的技術支持。
關鍵詞:SEER數據庫;乳腺癌;集成學習;預后預測
中圖分類號:TP181;R737.9? ? ? ? ? ? ?DOI:10.16375/j.cnki.cn45-1395/t.2022.01.015
0? ? 引言
乳腺癌是女性中最常見的腫瘤之一,也是人類第二大致死癌癥[1]。據2018年國際癌癥研究機構調查的數據顯示,全球女性乳腺癌的發病率為24.2%,位居女性惡性腫瘤首位,嚴重威脅著女性的身心健康[2]。
對癌癥患者生存數據的分析一直備受國內外學者的廣泛關注。目前多數研究都是通過單因素和多因素分析篩選出癌癥的預后因素,再將預后因素放到Cox比例風險模型中進行預后分析。然而,Cox比例風險模型通常假設預測因子與生存結果呈線性相關,基于這樣的假設,乳腺癌的預后模型有可能將復雜關系過度簡化[3],且Cox比例風險模型多用于評價群體,不適合評價個體,在預后判斷上起到的作用有限[4]。
近年來,機器學習算法廣泛應用于人臉識別[5]、工業預測[6]等方面,越來越多的學者也開始將機器學習應用于醫學領域。繼Delen等[7]首次采用數據挖掘的方法建立乳腺癌患者5年生存預測模型后,其他學者[8-11]也相繼采用不同的機器學習模型來研究乳腺癌患者的生存情況,但都存在一些弊端。與單一機器學習相比,集成學習有更好的性能和泛化能力[12]。有研究表明[4,13],相較于單一機器學習算法,采用集成模型預測不同癌癥患者的存活率時,集成模型都展示出更好的效果。
Boosting方法是訓練一系列弱分類器集成來得到一個強分類器的一種集成學習方法[14],既有集成學習的優勢,又能靈活處理連續型和離散型數據[15]。鑒于集成學習在其他癌癥預后上的優良表現,本文利用SEER數據庫中乳腺癌患者相關數據,通過Boosting集成學習方法來預測乳腺癌患者5年生存狀況并分析其影響因素,為臨床預后預測提供支持。
1? ? 方法
1.1? ? SMOTE算法
類別不平衡問題是指目標變量的類別分布不均,數據集中于某一類的樣本量遠高于其他類的現象[16]。本文采用SMOTE算法[17]來進行上采樣,其基本思想是:對少數類樣本進行分析后,人工合成新的少數類樣本。具體算法流程為:
Step 1? ? 計算少數類中每一個樣本[a]到其他少數類樣本的歐式距離,得到其[k]近鄰;
Step 2? ? 從少數類樣本[a]的[k]近鄰中隨機選擇若干個樣本,假設選擇的近鄰為[b];
Step 3? ? 對于每一個隨機選出的近鄰[b],分別與原樣本按照式(1)構建新的樣本[c]。
[c=a+rand(0, 1)×|a-b|].? ? ? ? ?(1)
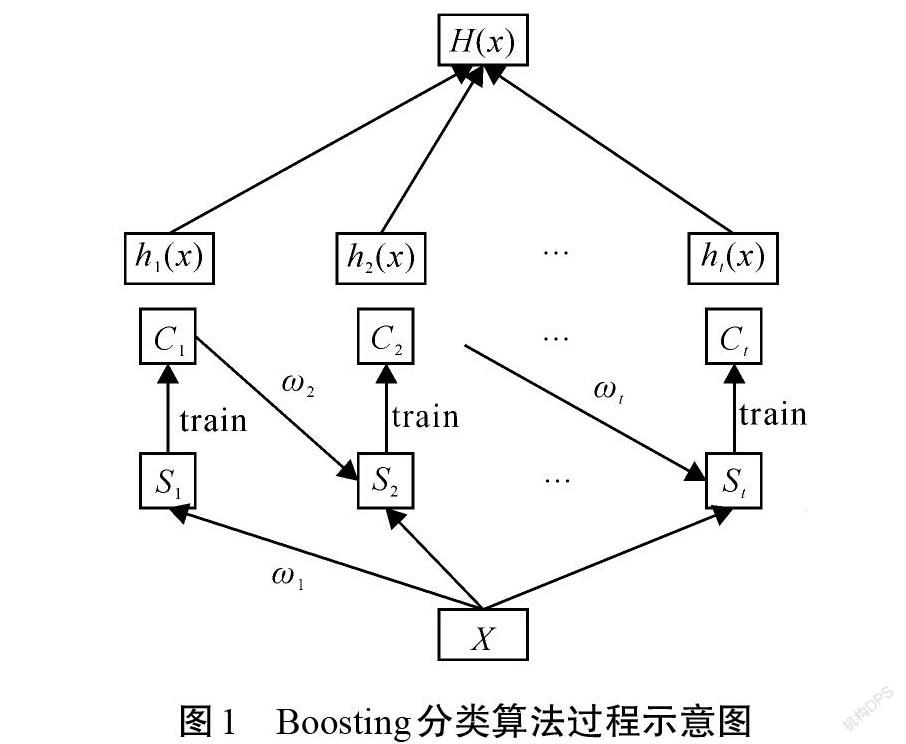
1.2? ?Boosting算法
Boosting算法是一種通過訓練產生多個簡單分類器集成從而提升弱分類器為強分類器的過程[18],如圖1所示。其具體實現步驟是[19]:
Step 1? ?給定一組訓練樣本[S],[S={(x1, y1)],[(x2, y2)][, …][, (xn, yn)}],初始化每一個樣本的權重系數[ω(1)i=1/n, i=1,2,…,n];
Step 2? ? 在每一次循環[t=1, 2, …, r],重復以下步驟:
1)使用弱分類器訓練有權重的樣本[{S,ω(t)}],得到分類器[ht]和權重訓練誤差[εt],依靠權重訓練誤差檢查得到一個終止準則;
2)選擇弱分類器權重[αt],更新權重系數[ωt];
Step 3? ? 輸出強分類器[H(x)=argmaxy∈{-1,1}t,ht(x)=yαt]。
圖1中:[X]對應訓練樣本[S];[St(t=1, 2, …, r)]為[r]次迭代的樣本分配;[Ct(t=1, 2, …, r)]為在一定權重條件下訓練數據得到的分類法,可以根據[Ct]的錯誤率調整權重,每一個[Ct]對應每一個弱分類器[ht(x)];[ω(t)]為第[t]次循環初始化樣本權重[ω(t)i(i=1, 2, …, n)]的集合;[ωt(t=1, 2, …, r)]為樣本更新權重;[αt(t=1, 2, …, r)]為每一個基分類器權重。
為了預測乳腺癌患者5年生存狀態,本文選取的單一模型為邏輯回歸(Logistic Regression)、決策樹(Decision Tree)和K近鄰(Knn);集成模型則選擇Boosting集成模型的代表性算法:Light Gradient Boosting Machine(LightBGM)、Categorical Boosting(CatBoost)和Gradient Boosting Decision Tree(GBDT)。
1.3? ?SHAP方法
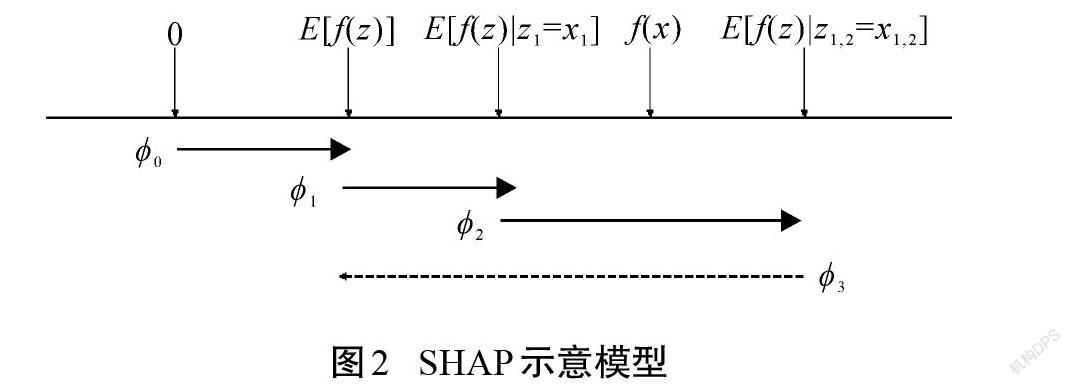
SHAP[20]是shapley additive explanation的縮寫,是一種可以對復雜機器學習模型進行解釋的方法。SHAP方法的核心是shapley值,即貢獻值。如圖2所示,假設集合中有3個特征[z1]、[z2]、[z3],[f(x)]表示某一樣本的最終預測值。對于整個數據,可以用原始模型[f]預測后的預測值來計算平均值[E[f(z)]],記作[?0]。[?1]、[?2]、[?3]分別表示考慮特征[z1]、[z2]、[z3]的貢獻值。貢獻值可正可負,如圖2中實線[?1]、[?2]表示正影響,虛線[?3]表示負影響。
1.4? ?模型評價指標
通過5個二元分類性能指標來評價各模型的性能:準確率(Accuracy)、AUC、召回率(Recall)、精確度(Precision)以及F1值。5個指標的區間都是[[0, 1]],值越接近1表示分類效果越好。
2? ? 數據來源和處理
2.1? ?數據來源
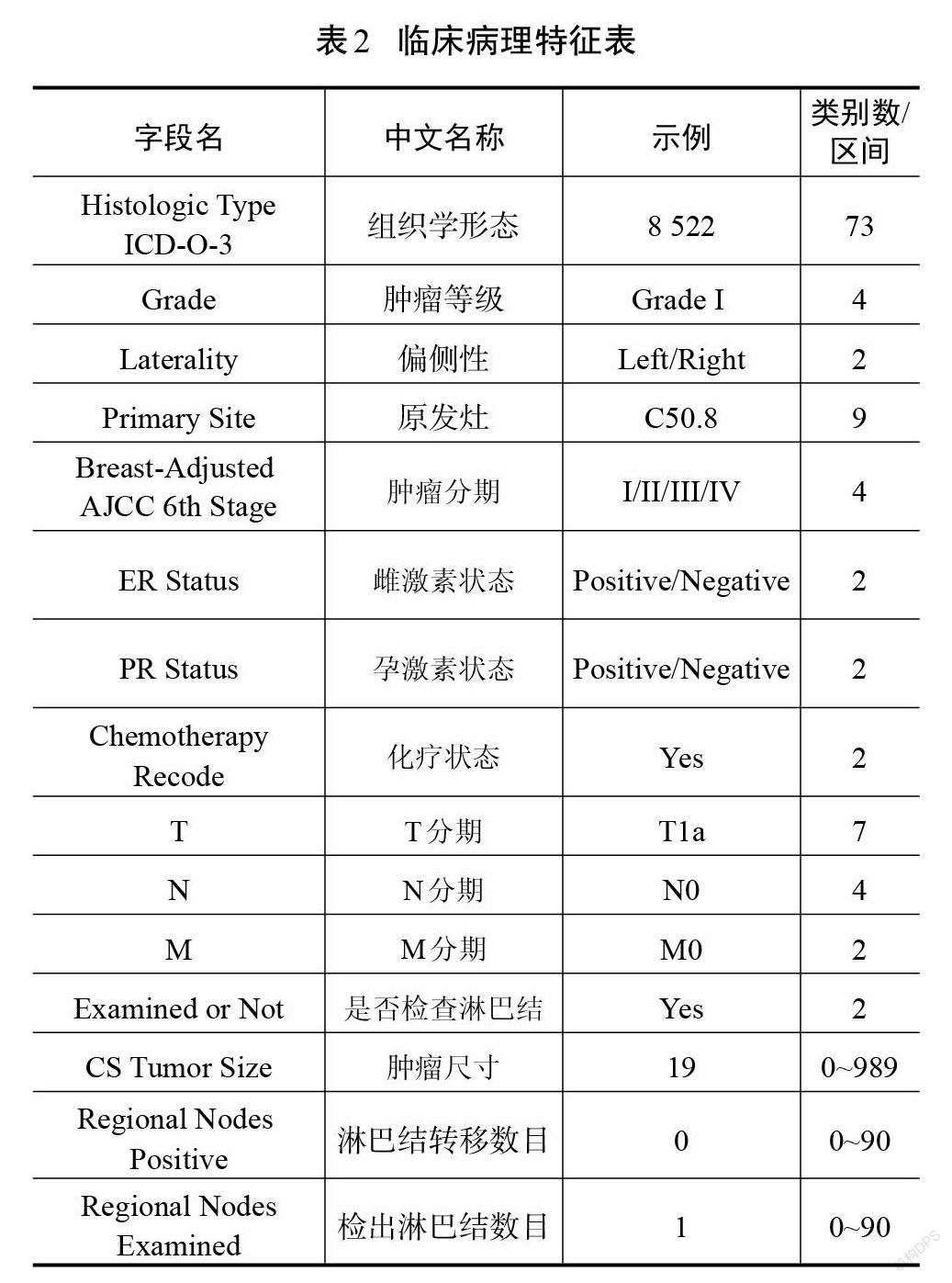
本研究數據來源于監測、流行病學及預后數據庫(surveillance, epidemiology and end results, SEER)[21],通過SEER*Stat 8.3.9軟件提取更新于2021年4月15日的數據。依據第7版AJCC臨床指南、NCCN臨床指南以及臨床醫師的指導,從原始數據中,篩選出性別、診斷年份、種族、年齡段、原發灶、組織學形態、偏側性、腫瘤等級、腫瘤分期、雌激素狀態、孕激素狀態、腫瘤大小、化療與否、腫瘤患者發病部位、婚姻狀態、檢出淋巴結數目、淋巴結轉移數目、死亡原因、存活月數、T分期、N分期、M分期和生存狀態一共23個字段作為原始數據。
2.2? ?隊列選擇
2.2.1? ? ?5年特異性生存
本研究以乳腺癌患者5年生存情況為預測目標,用存活月數構建分類變量。存活月數>60,記為1,認為該患者在首次確診為乳腺癌后的5年后仍存活;存活月數≤60,記為0,認為該患者在首次確診為乳腺癌后的5年內因為乳腺癌而死亡。
2.2.2? ? ?隊列篩選
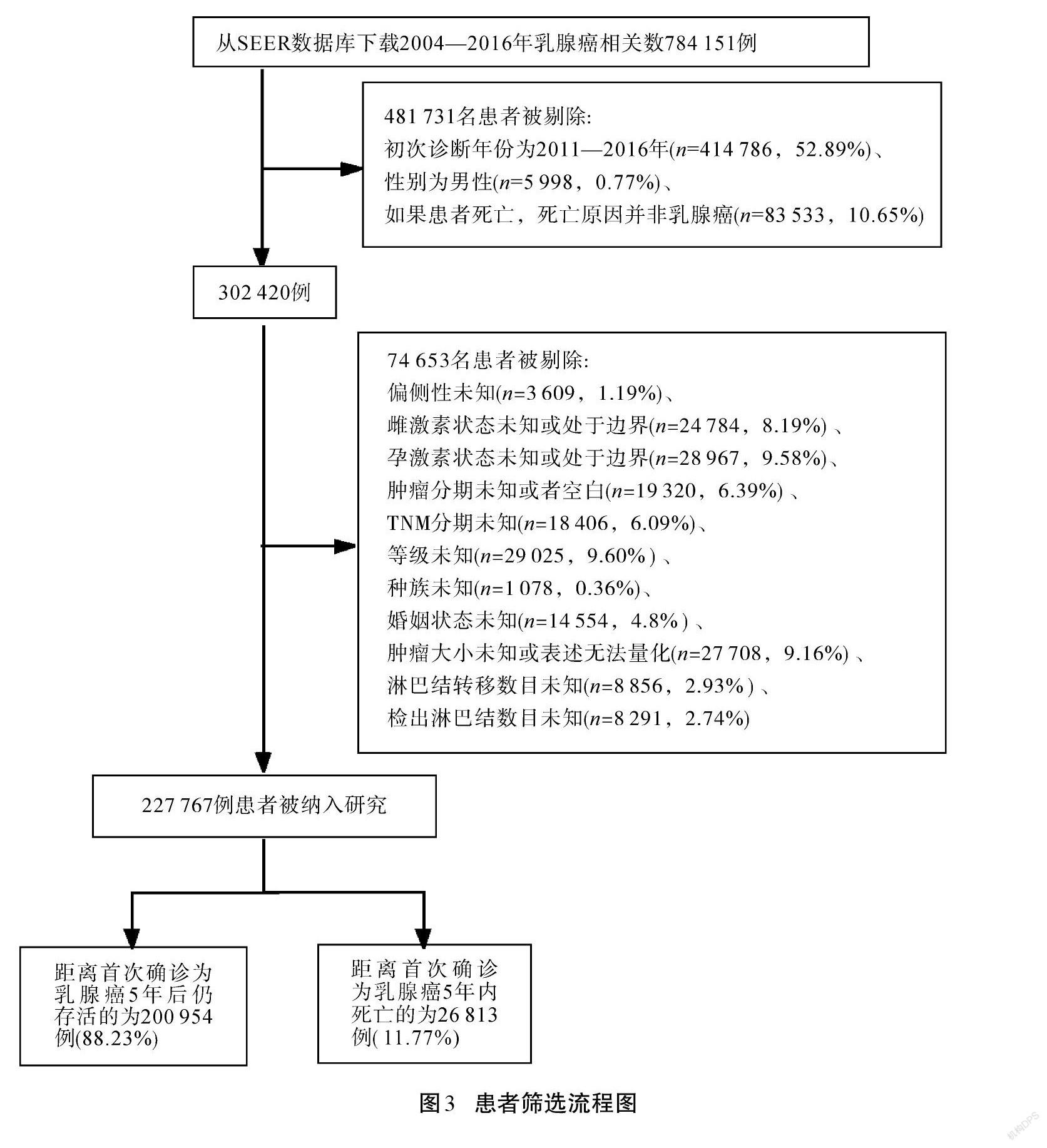
從2004—2016年共784 151條數據中按要求篩選,最終得到數據227 767條。具體要求如下:
1)初次診斷年份為2004—2010年。入選病例隨訪截止時間為2016年12月31日,為保證患者隨訪時間在5年以上,僅選擇初次診斷年份為2004—2010年的患者。
2)性別為女性。
3)腫瘤患者發病部位為乳腺。
4)若患者死亡,則死亡原因為乳腺癌。
5)患者信息須準確。SEER數據庫中存在缺失值,被記錄為不知道(unknown)和空白(black())。除此之外,還存在信息表述不清的情況,例如腫瘤大小這一變量除被記錄為不知道(unknown)和空白(black())數據之外,還存在兩類數值:第一類是當數值在0~989 時,其值對應具體腫瘤大小,該數值以mm為單位;第二類是991~995之間的具有特殊意義的數值,該類與第一類中采用精確數值來表示腫瘤大小不同,采用區間來表示腫瘤大小,如995表示腫瘤大小[<]5 cm。考慮到無法為其進行精確量化,同時原始樣本量大,該類信息表述不清的樣本占比較小,故直接將這些記錄刪除。篩選過程如圖3所示。
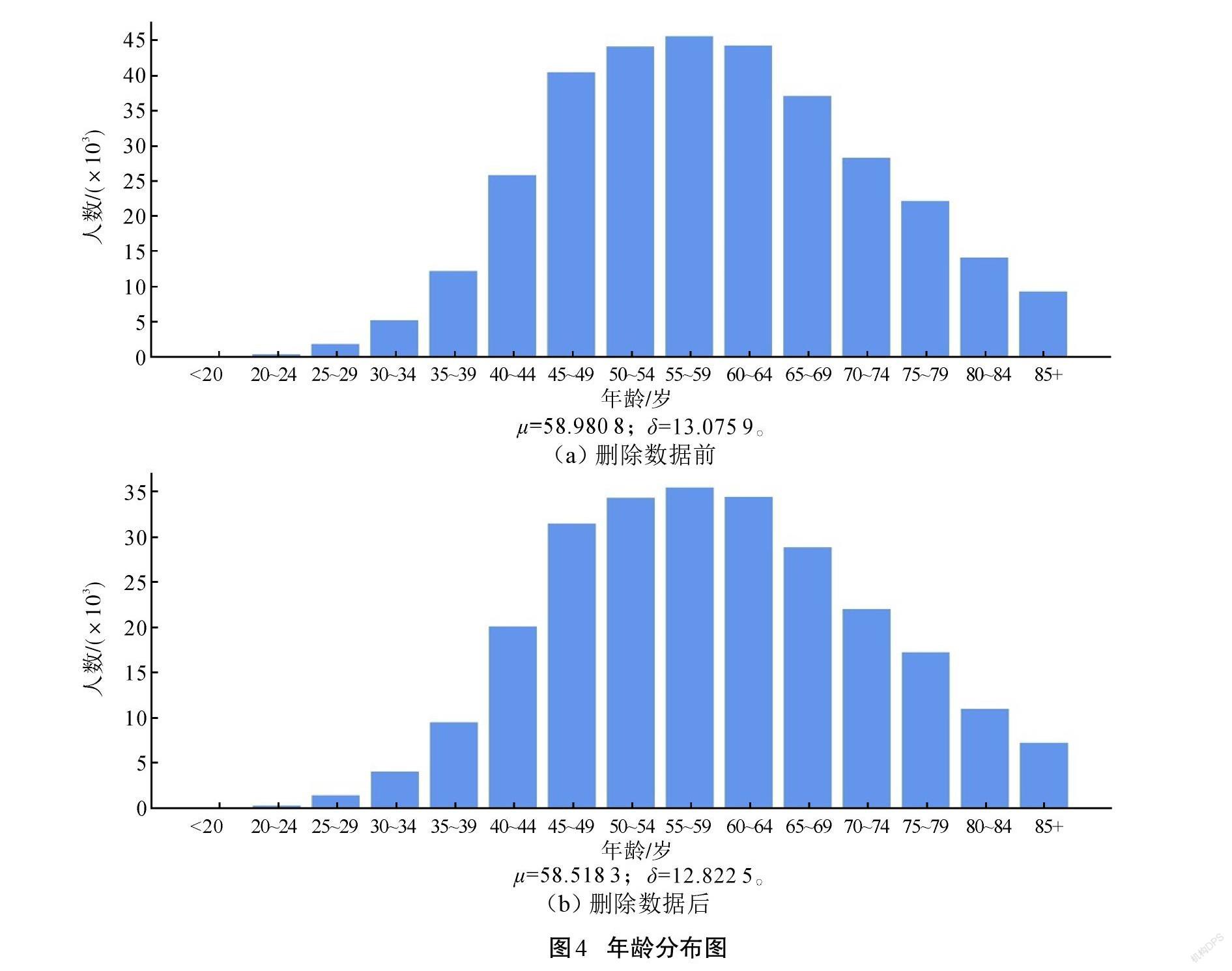
進一步分析,檢查刪除這些記錄對于其他變量的影響。結果表明,刪除這些記錄對其他變量分布的影響不顯著,認為刪除這部分數據合理。如圖4所示,刪除數據前后,年齡這一變量的分布變化不顯著。同時,將年齡段組值計算加權平均數代替平均值,計算標準差進行比較,發現差異較小。
2.2.3? ? ?特征選擇
除直接從SEER數據庫中獲得變量外,淋巴結轉移數目這一變量的值,大部分為0~90之間的整數,除此之外,還存在一個特殊的數值為98,表示該患者未檢查淋巴結。考慮到在臨床中不對淋巴結進行檢查,可能的原因是該患者的臨床癥狀不明顯或病情較輕而無需對淋巴結進行檢查,所以將該特殊數值98修改為0,并創建一個新的類別變量——examined or not,用來表示患者是否對淋巴結進行了檢查。若淋巴結轉移數目為0~90,表示檢查了淋巴結,用Yes表示;淋巴結轉移數目為98,則用No表示。
最終納入模型的18個特征分為人口學特征(表1)和臨床病理特征(表2)。
2.3? ?數據預處理
將數據按照7∶3的比例劃分訓練和測試數據,并進行以下預處理:
1)標準化
對數據進行zscore標準化來避免數據變量量綱不同、自身變異或者數值相差較大等問題造成的預測誤差。
2)yeo-johnson變換
日常生活中的數據普遍滿足高斯分布,因此,對原始數據做轉型操作,轉換方法設置為“yeo-johnson”變換[22]。
3? ? 模型建立與結果
3.1? ?模型的建立
227 767條數據中,患者在被確診為乳腺癌5年后仍存活的數據200 954條,死亡數據26 813條,其比例約7.45∶1,認為存在類別不平衡問題。因此,用SMOTE算法對訓練數據進行處理。
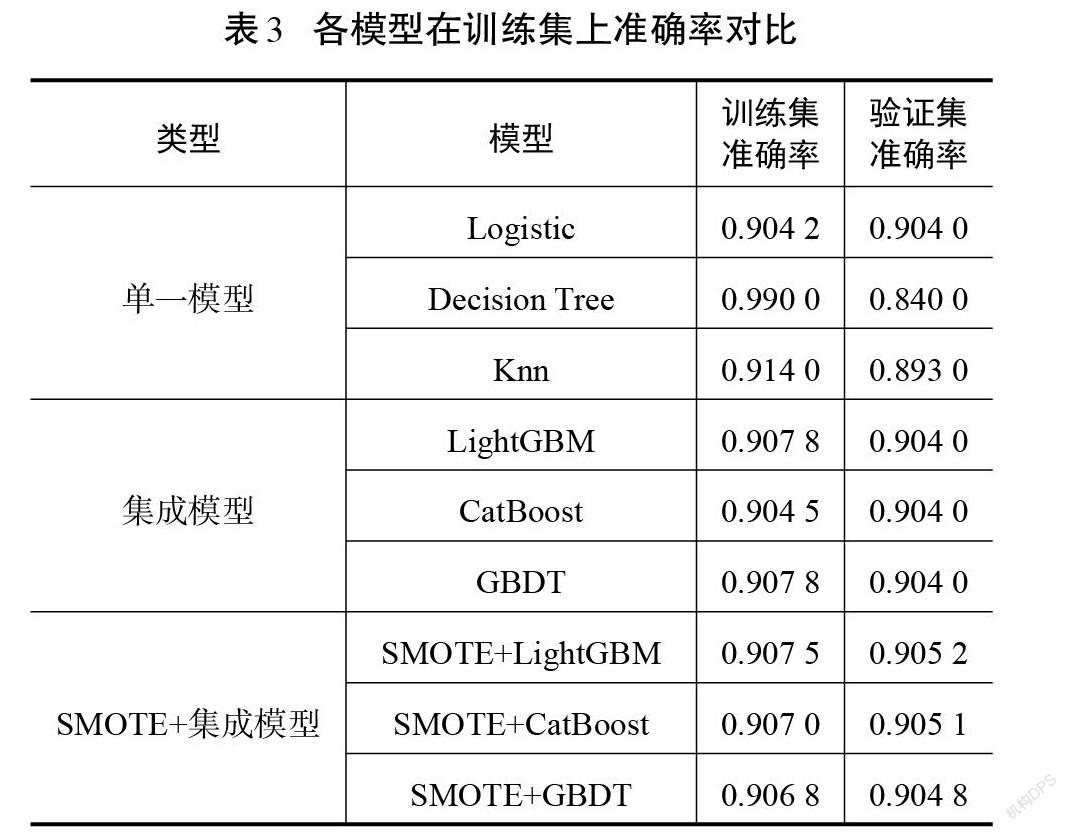
各模型在進行十折交叉驗證訓練后的準確率如表3所示。單一模型中決策樹模型的訓練準確率最高,達到0.990 0,但是驗證集的準確率僅為0.840 0,相差較大,說明模型在訓練集上出現了過擬合現象;集成模型中LightGBM和GBDT的訓練精確度和驗證精確度相同,數值分別為0.907 8和0.904 0;SMOTE方法與集成模型的組合中,LightGBM的準確率在測試集和驗證集上均最高,分別為0.907 5和0.905 2。
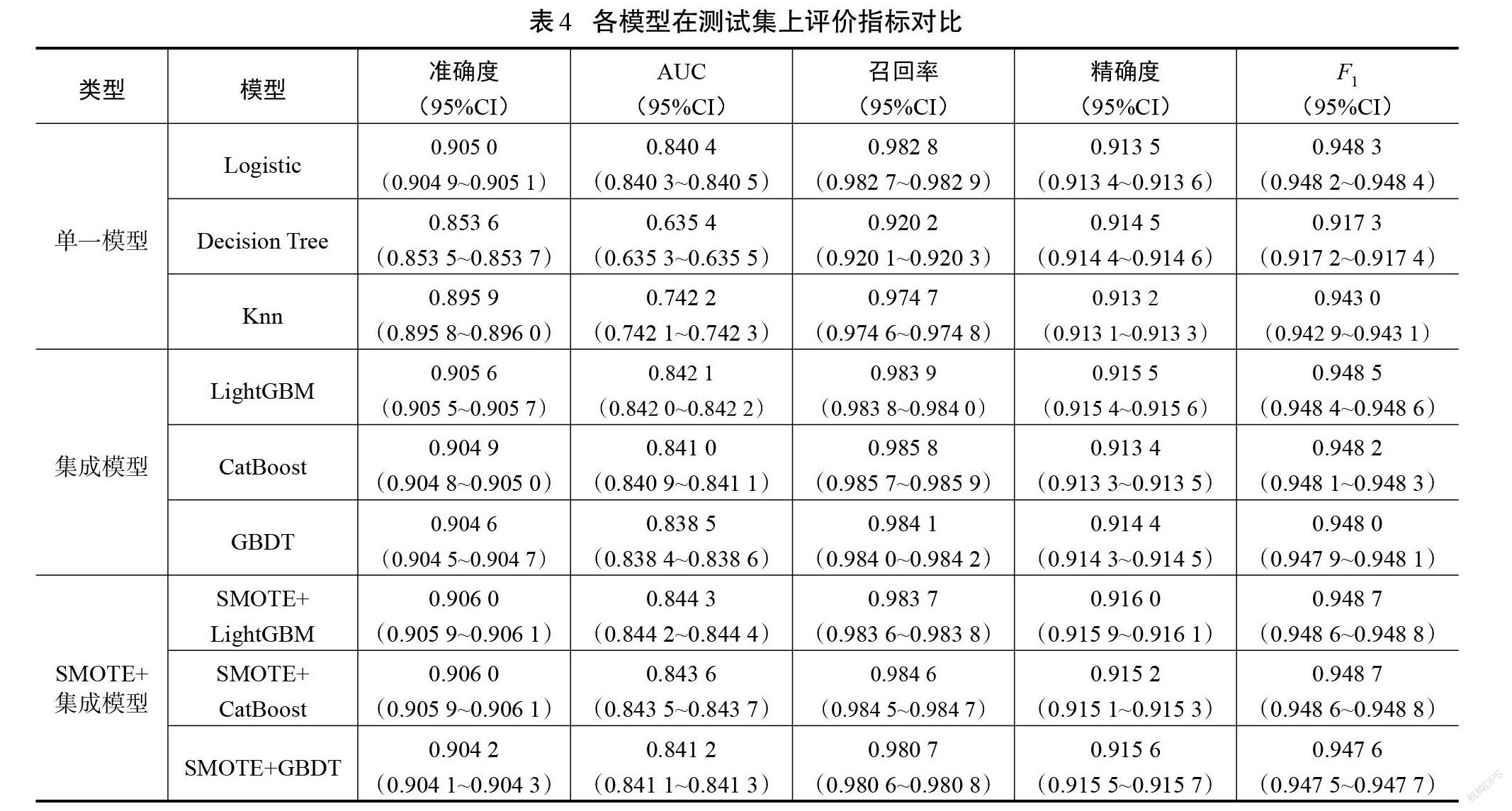
各模型在測試集上的表現如表4所示。SMOTE方法與LightGBM結合得到了最高的準確度、AUC、精確度和F1值,召回率僅比CatBoost模型低0.002 1,是所有模型中最優的。
從整體上來看,單一模型的效果沒有集成模型好,SMOTE方法與集成學習的組合比僅使用集成模型在測試集上效果好。可見,SMOTE算法解決了數據類別不平衡的問題,使各個集成模型的分類能力得到了一定程度的提升。
3.2? ?特征重要性排序及解釋
3.2.1? ? ?特征重要性排序
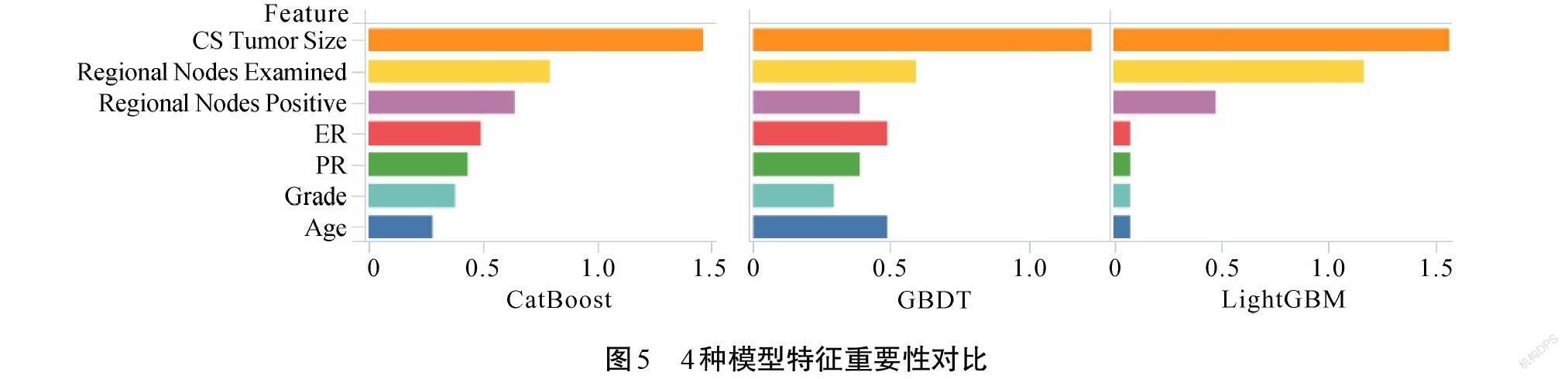
如表4所示,SMOTE與集成模型組合的預測效果較優,分別將LightGBM、CatBoost和GBDT共3個模型在做乳腺癌5年生存狀態預測時的特征按重要性進行排序,發現最重要的10個特征中有7個特征是3個模型所共有的。如圖5所示,共同特征為腫瘤大小、檢出淋巴結數目、淋巴結轉移數、孕激素受體、雌激素受體、組織學等級、年齡。同時發現,這些特征在3個模型上的重要性排序基本保持一致,最重要的特征是腫瘤大小,其次是檢出淋巴結數目和淋巴結轉移數。
3.2.2? ? ?SHAP特征解釋
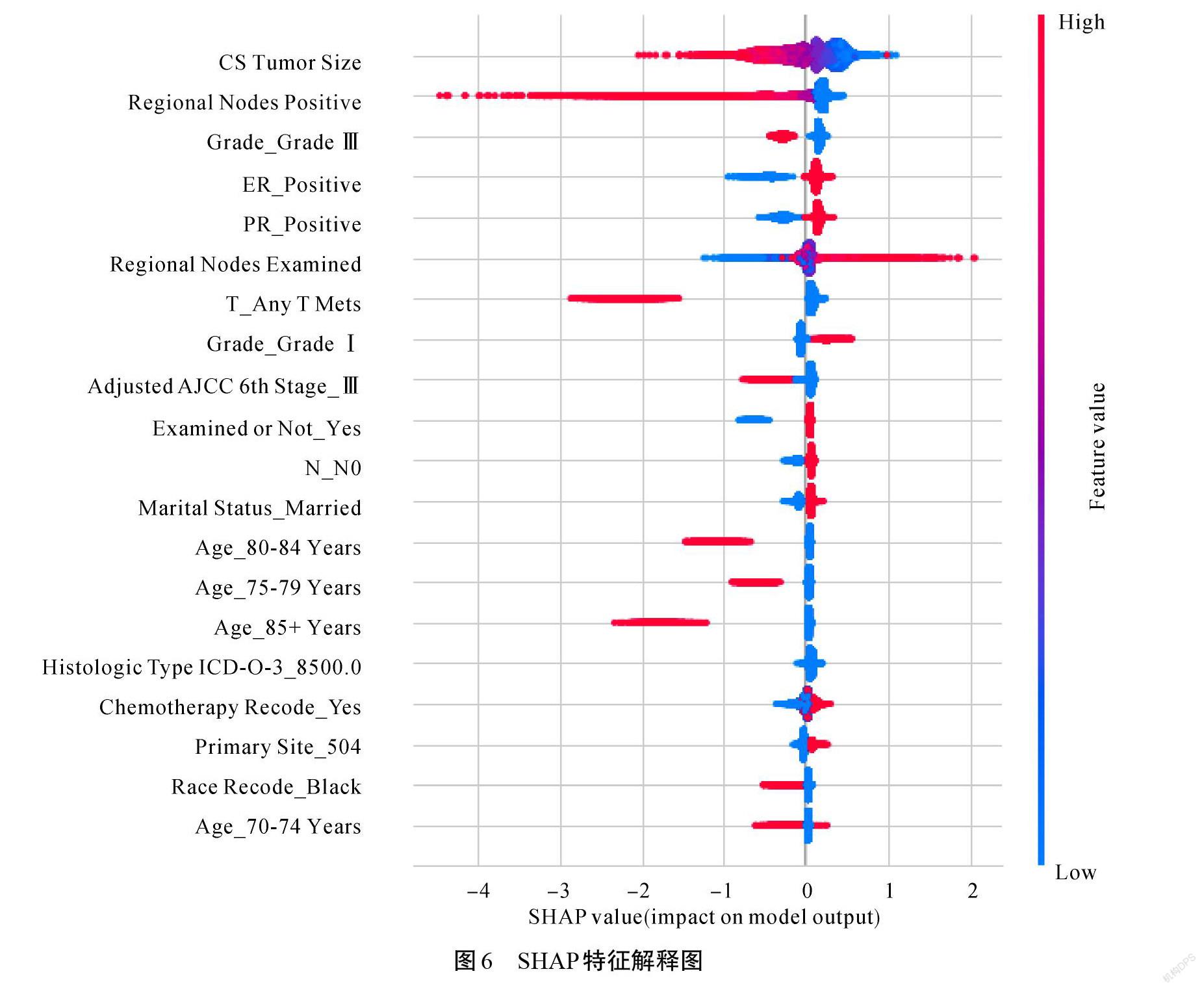
如圖6所示,腫瘤大小增加,患者5年內死亡的風險也會升高。淋巴結轉移數越多,患者5年內死亡的風險越高。隨著檢出淋巴結數目的增加,患者五年內死亡的風險降低。由此可見腫瘤大小和淋巴結轉移對乳腺癌5年生存狀態影響很大,轉移淋巴結的切除能夠降低死亡風險。同時發現組織學分級越高,患者在5年內死亡的風險也會越高。孕激素和雌激素受體成陰性時,患者5年內死亡的風險升高。年齡越大,患者5年內死亡的風險也越大。
4? ? 討論
在“數字醫學”背景下,利用大數據輔助醫生進行醫學決策越來越受到重視。基于大量歷史數據,依據數據特征采用合適的算法來預測特定人群、疾病的未來趨勢是醫療大數據的特點之一。本研究利用SEER數據庫中2004—2010年乳腺癌相關數據,通過Boosting集成學習算法的3種經典模型來預測乳腺癌5年生存狀態并分析其影響因素,可為個性化醫療制定合理的治療計劃提供參考。
本研究的數據是連續變量和分類變量的混合體,其中大部分是多分類變量,這一類型的變量在建立模型時易出現維度災難等問題。Boosting集成模型是一種基于樹的模型,可基于類別變量的劃分規則去創建樹,能夠有效解決維度災難問題[19]。此外,該類模型可根據變量在樹結構中的位置深度對變量的重要性進行排序,使模型具有較好的可解釋性[13]。本文通過特征重要性排序發現,腫瘤大小、檢出的淋巴結總數、淋巴結轉移數、雌激素受體、孕激素受體、組織學等級等均是乳腺癌患者5年生存情況的重要影響因素。同時發現淋巴結轉移數越多、腫瘤越大,患者5年內死亡的風險越高;隨著檢出的淋巴結總數的增加,預后越好;組織學等級越高,雌激素受體和孕激素受體為陰性時預后越差。這些結果均與已有研究[23-27]結論相吻合。
為了解決乳腺癌數據因較高特異性生存率而產生的類別不平衡問題,本研究采用SMOTE上采樣方法來處理訓練集,結果發現平衡后的數據建模效果更優。與此同時,冉霞[28]采用下采樣的方法平衡數據后進行乳腺癌預后預測也取得較好結果。可見,面對類別不平衡問題,通過重采樣技術能夠在一定程度上提升模型的性能。但是,本研究中Boosting集成模型在采用SMOTE處理后,各個模型在測試集上的表現提升較小,可能的原因有:Boosting集成模型在處理數據時,主要通過擬合殘差的方式逐步減小誤差來找出樹的最佳節點和分枝方法[3],該過程與數據類別是否平衡無關,因此,受類別不平衡因素的影響較小。未進行SMOTE上采樣時,Boosting集成模型的AUC已較優,在平衡數據后僅有較小提升。
利用單一機器學習模型進行乳腺癌生存情況預測存在一定不足,雖然最優模型可獲得較高AUC,但準確度較低[9-11]。相比之下,集成學習模型具有更好的性能。一方面,集成學習模型中最優模型的AUC與單一機器學習模型相當,但準確度和召回率等指標均達到0.9以上;另一方面,集成學習模型能更加靈活地處理乳腺癌生存率等復雜性數據。SEER數據庫中的變量主要來自于先前的臨床知識,大多與生存結果線性相關[3]。Logistic模型作為一種廣義上的線性模型,能夠較好地處理變量之間的線性關系,這也進一步說明本研究采用Logistic模型測試數據集時,其性能較好,僅略低于集成模型。然而,實際情況是:影響乳腺癌生存率的特征不僅存在線性相關關系,還可能存在非線性關系[29]。相較于Logistic模型,集成模型沒有線性關系的限定,可能不會受到變量間非線性關系的影響,因而在本研究中展現出更好的性能,這也側面反映了本研究結果存在一定的科學性與準確性。
5? ? 結論
本文從SEER數據庫提取乳腺癌相關數據,使用集成學習模型構建乳腺癌5年生存狀態的預測模型。研究結果表明,腫瘤大小、檢出淋巴結數目、淋巴結轉移數、孕激素受體、雌激素受體等特征是乳腺癌5年生存狀態最重要的特征;同時,從各模型的表現來看,LightGBM模型各項指標均較優,可作為一個工具輔助臨床醫生為乳腺癌患者做出更好的治療決策。但本研究也存在未進行外部驗證,缺少自身心理狀況數據[30]等不足,因此,需進一步尋找外部數據進行更深入的研究。
參考文獻
[1]? ? ?徐盼玲.基于SEER數據庫的三陰型乳腺癌腦轉移預后及影響因素研究[D].合肥:安徽醫科大學,2019.
[2]? ? ?陳茂山,李芳芳,楊宏偉,等.基于SEER數據庫分析142007例乳腺癌診斷時婚姻狀態與預后的關系[J].重慶醫科大學學報,2020,45(11):1567-1572.
[3]? ? ?DU M,HAAG D G,LYNCH J W,et al.Comparison of the tree-based machine learning algorithms to Cox regression in predicting the survival of Oral and Pharyngeal cancers:analyses based on SEER database[J].Cancers,2020,12(10):1-17.
[4]? ? ?徐良辰,郭崇慧.基于集成學習的胃癌生存預測模型研究[J].數據分析與知識發現,2021,5(8):86-99.
[5]? ? ?安曉寧,王智文,張燦龍,等.基于隱馬爾可夫模型的人臉特征標注和識別[J].廣西科技大學學報,2020,31(2):118-125.
[6]? ? ?孫金芳,王智文,王康權,等.基于主成分降維及多層感知神經網絡的辛烷值預測分析[J].廣西科技大學學報,2021,32(3):67-73.
[7]? ? ?DELEN D, WALKER G, KADAM A. Predicting breast cancer survivability:a comparison of three data mining methods[J]. Artificial Intelligence in Medicine,2005,34(2):113-127.
[8]? ? ?BELLAACHIA A,GUVEN E.Predicting breast cancer survivability using data mining techniques[C]//Proceedings of the 6th SIAM International Conference on Data Mining,Bethesda,MD,USA,2006.
[9]? ? ?劉雅琴,王成,章魯.基于神經網絡的乳腺癌生存預測模型[J].中國生物醫學工程學報,2009,28(2):221-225.
[10]? ?章鳴嬛,張璇,郭欣,等.基于SEER數據庫利用機器學習方法分析乳腺癌的預后因素[J].北京生物醫學工程,2019,38(5):486-491,497.
[11]? ?章鳴嬛,陳瑛,郭欣,等.利用Logistic回歸和神經網絡分析乳腺癌的預后因素[J].計算機與數字工程,2020,48(3):617-622.
[12]? ?周波.基于集成學習的不平衡數據分類的研究及應用[D].大連:大連理工大學,2014.
[13]? ?JIANG J Z,PAN H,LI M B,et al.Predictive model for the 5-year survival status of osteosarcoma patients based on the SEER database and XGBoost algorithm[J].Scientific Reports,2021,11(1):1-9.
[14]? ?WOLPERT D H. Stacked generalization[J].Neural Networks,1992,5(2):241-259.
[15]? ?陳雨桐.集成學習算法之隨機森林與梯度提升決策樹的分析比較[J].電腦知識與技術,2021,17(15):32-34.
[16]? ?SUH S,LEE H,LUKOWICZ P,et al.CEGAN:classification enhancement generative adversarial networks for unraveling data imbalance problems[J]. Neural Networks,2021,133:69-86.
[17]? ?秦靜,左長青,汪祖民,等.基于堆疊分類器的心電異常監測模型設計[J].計算機應用,2021,41(3):887-890.
[18]? ?VALIANT L G.A theory of the learnable[J].Communications of the ACM,1984,27(11):1134-1142.
[19]? ?李想.Boosting分類算法的應用與研究[D].蘭州:蘭州交通大學,2012.
[20]? ?LUNDBERG S M,LEE S I.A unified approach to interpreting model predictions[C]//Conference on Neural
Information Processing Systems,Long Beach,CA,USA,2017:4765-4774.
[21]? ?章鳴嬛,陳瑛,汪城,等.美國國立癌癥研究所SEER數據庫概述及應用[J].微型電腦應用,2015,31(12):26-28,32.
[22]? ?YEO I K,JOHNSON R A. A new family of power transformations to improve normality or symmetry[J].Biometrika,2000,87(4):954-959.
[23]? ?宋效清,謝裕賽,邱雪杉.乳腺癌患者預后評估模型的構建[J].大連醫科大學學報,2021,43(1):29-37.
[24]? ?王哲.陽性淋巴結比例預測乳腺癌患者預后的價值研究[D].天津:天津醫科大學,2020.
[25]? ?TAUSCH C,TAUCHER S,DUBSKY P,et al.Prognostic value of number of removed lymph nodes,number of involved lymph nodes,and lymph node ratio in 7502 breast cancer patients enrolled onto trials of the Austrian breast and colorectal cancer study group(ABCSG)[J].Annals of Surgical Oncology,2012,19(6):1808-1817.
[26]? ?VINH-HUNG V,BURZYKOWSKI T,CSERNI G,et al.Functional form of the effect of the numbers of axillary nodes on survival in early breast cancer[J].International Journal of Oncology,2003,22(3):697-704.
[27]? ?張振偉,孫家和,張立功,等.乳腺癌骨轉移患者危險因素及預后因素分析[J].臨床外科雜志,2021,29(3):243-247.
[28]? ?冉霞.基于機器學習組合模型的乳腺癌生存預測[D].濟南:山東大學,2020.
[29]? ?尹玢璨,辛世超,張晗,等.基于SEER數據庫應用貝葉斯網絡構建亞洲腫瘤患者預后模型——以非小細胞肺癌為例[J].數據分析與知識發現,2017(2):41-46.
[30]? ?唐鈴豐,嚴萍,舒秀潔,等.基于SEER數據庫構建轉移性乳腺癌患者的生存預測模型[J].中國普外基礎與臨床雜志,2021,28(3):309-315.
Breast cancer survival prediction based
on ensemble learning
ZHANG Jijie1, QIN Qinghong2, LIU Xueping*3, WANG Kangquan1, WEI Wei1
(1.College of Science, Guangxi University of Science and Technology, Liuzhou 545006, China;
2.Affiliated Cancer Hospital, Guangxi Medical University, Nanning 530021, China;
3.Medical School, Guangxi University of Science and Technology, Liuzhou 545005, China)
Abstract: The research is conducted to predict the 5-year survival status of breast cancer and analyze the influence factors. Firstly, the breast cancer related data from 2004—2010 were selected from the SEER database, and the selected featured data were preprocessed. Secondly, in terms of data, SMOTE algorithm was used to oversample the data to solve the imbalance of data categories; in terms of? ? ? ? ? algorithm, the advantagess and disadvantages of lightgbm, catboost and gbc in predicting the 5-year? survival status of breast cancer were compared. Finally, the influencing factors of breast cancer 5-year survival status were analyzed by SHAP value after ranking. The 5-year survival prediction model of breast cancer constructed in this paper has better performance than a single model. The accuracy rate, AUC, recall rate, precision rate and F1-score are 0.906 0, 0.844 3, 0.983 7, 0.916 0 and 0.948 7? ? ? ? ? ? respectively; and it shows that the 5-year survival status of breast cancer is closely related to tumor size, examined lymph nodes, positive lymph nodes, ER status, PR status, and age. The model can provide prognosis prediction for the clinic with its excellent performance and the selected important features consistent with the current clinical results.
Key words: SEER database; breast cancer; ensemble learning; prognosis prediction
(責任編輯:黎? 婭)
猜你喜歡
中老年保健(2022年6期)2022-08-19 01:41:48
現代臨床醫學(2022年1期)2022-02-12 02:04:58
甘肅科技(2020年20期)2020-04-13 00:30:42
中國生殖健康(2019年2期)2019-08-23 08:11:42
中國生殖健康(2019年6期)2019-01-06 09:20:12
中國生殖健康(2019年5期)2019-01-06 09:16:40
幸福家庭(2019年14期)2019-01-06 09:15:38
祝您健康(2018年5期)2018-05-16 17:10:16
癌癥進展(2016年9期)2016-08-22 11:33:20
中國組織化學與細胞化學雜志(2016年4期)2016-02-27 11:16:08
