超像素相似性傳遞的弱監督語義分割算法設計
2021-12-31 01:20:06國網信通億力科技有限責任公司興業銀行股份有限公司李良御
電力設備管理 2021年13期
國網信通億力科技有限責任公司 席 勒 興業銀行股份有限公司 李良御
近年來,注意力機制已經成為神經網絡領域中一個重要的概念,被廣泛地應用于自然語言處理、語音識別以及圖像解釋等任務中。注意力機制類似于人類視覺的觀察機制,關注于從大量的數據中尋找當前任務的關鍵信息,改善神經網絡中有效特征的提取。
目前,大量的基于圖像級標簽的弱監督語義分割方法中,使用神經網絡的圖像注意力機制定位目標的種子區域,并結合擴充算法尋找完整的目標掩膜(mask)。例如,在SEC 算法中提出種子定位、種子擴張以及邊界限制三種損失函數,旨在從注意力定位區域逐漸尋找完整的分割掩膜[1]。在DSRG 算法中提出運用經典種子生長分割算法,產生從初始定位區域逐漸覆蓋于全圖像的分割掩膜[2]。然而,現有的圖像級監督的語義分割方法,由于缺少精確的空間定位信息,通常會在邊緣處存在粗糙的分割結果。
受到種子定位思路的啟發,本文提出超像素相似性傳遞的弱監督語義分割算法設計。如圖1所示,以圖像注意力機制為基礎定位目標種子區域,并引入隨機游走算法以超像素塊的形式傳遞種子區域的相似性。本文通過邊緣檢測器尋找不同物體之間的邊緣線索,生成具有相同語義集合的超像素塊區域,并使用超像素塊代替像素點作為圖像基本單位擴張種子區域,保證了局部區域的相同語義特征。同時,在傳遞相似性特征過程中,將隨機游走結果以超像素的方式融合,提升了算法的準確性和魯棒性。在PASCAL VOC2012數據集上進行驗證,結果表明本章提出的弱監督語義分割方法相比于其它算法在mIoU 評價標準下精確度提升了2.1%,同時解決了語義分割標簽邊緣粗糙以及容易產生錯誤分割區域的問題。
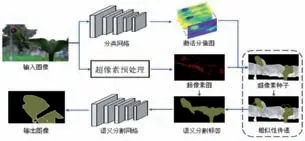
圖1 類別掩膜生成流程圖
1 超像素相似性傳遞的弱監督語義分割算法
本文算法總共分為兩個階段,第一階段通過優化算法產生像素級語義標簽;第二階段使用文中生成的語義標簽訓練語義分割模型,以該模型的輸出結果與其它弱監督算法做出比較,以此判斷本文算法的有效性。在第一階段中,為了生成高質量的語義分割標簽,以圖像注意力機制為基礎,在圖像預處理、種子標定、產生像素標簽三個方面進行設計。
1.1 圖像預處理
在傳統的圖像分割領域中,大部分算法以像素點作為分割的基礎單元,但隨著彩色圖像分辨率的增大,待處理的計算量也急劇增加。本文受靈感于UCM 算法[3]通過在多尺度上結合全局與局部特征,計算每個像素點屬于邊緣的概率值,并通過設定閾值生成圖像的超像素圖。可以表示為。
最終,gpb 的值經過Sigmoid 函數變換,輸出值每一個像素點作為邊緣的概率值。為了產生圖像真邊界,在此基礎上使用分水嶺算法尋找真邊緣,邊緣強度由邊界在走勢方向上各像素點概率平均值確定。在本文中使用0.15作為閾值產生所有超像素圖,通過預處理的圖像,將圖像的最小單位擴大為了超像素塊,不僅減小了后處理的計算量,并且通過聚合相似性像素點,減少了圖像噪聲。
1.2 種子標定
圖像級類別標簽作為監督信息時,缺少有效的目標的定位線索,成為了弱監督語義分割的難點。為了解決這個問題,Zhou 等人[4]提出分類網絡中卷積層保留了語義位置信息,然而這種定位效果由于全連接層的使用失效了。為了保留卷積層的定位效果,使用全局平均池化層代替全連接層,產生的類激活映射(class activation mapping,CAM)有效定位于目標物體最具有辨別性區域。對于類別c 在卷積層空間位置(x,y)的激活值可以表示為。
原算法類激活映射方式缺少關于背景區域的分值圖,則需要對各個類別的激活分值圖進行標準化操作,假設某類別的最大激活值為Mc-max。則修正后的關于圖像背景區域的類激活映射分值圖可表示為,其中α 為調整背景激活分值的超參數。通過這種方式有效的生成關于背景類別的激活映射分值圖。根據設定閾值t,將處于空間位置(x,y)處且低于閾值t(本章中t 取0.3)的激活值置為零,并選取相應位置處的最大激活值類別作為該像素點語義。
直觀來說,類激活映射就是將不同空間單元的激活值線性加權后的處理結果。然而,種子區域在邊緣處存在粗糙的分割結果,定位區域中不僅包含目標物體,并且含有部分其它類別物體。因此需要利用超像素圖對定位結果進行修正,使得產生更加準確的超像素塊定位區域。在超像素塊內的各像素點之間具有較強的相似性特征。本文設計填充率選擇方案,根據粗糙定位區域對超像素塊的填充程度篩選超像素種子。假設當前超像素塊中大部分區域屬于種子點,則認為該像素塊與種子所含語義高度相關,賦予當前超像素塊相應的語義信息,反之則認為超像素塊與種子無關。則超像素塊的填充率可表示為:
其中,Bi表示圖像中索引號為i 的超像素塊,Sc表示類別C 的粗糙種子區域,通過計數區域內像素點的方式,判別各超像素塊填充率數值。當超像素塊內填充率大于指定范圍時,判定為指定語義的超像素塊。同時,為了避免種子區域過小,填充率篩選后沒有產生相應語義的超像素塊,取種子區域所在超像素塊直接賦予種子語義,保證了圖像內存在的語義信息都有各自的定位區域。填充后的超像素種子,相比原始的粗糙種子包含更少的噪聲。
1.3 相似性傳遞模塊
超像素相似性傳遞模塊在建模過程中,以隨機游走算法[5]為靈感,首先將待分割圖像構建成無向圖模型G=(V,E),其中V 為圖節點集合,E 為圖像的邊集合,連接兩個節點vi和vj的邊可以表示為eij。同時,為了保證兩個坐標之間相似度有效傳遞,并且滿足圖像平滑性需求。不同于原始算法在4鄰域或8鄰域空間中計算節點對的相似性,本文設置搜索半徑為γ,并在HSV 顏色空間中,計算各節點對之間的相似性權值Wij,可以表示為。
在上式中共包含兩項,第一項被稱作色域相似性,第二項被稱作空域相似性。在第一項中,n 表示HSV 顏色空間通道索引值,g 表示指定圖像位置在通道n 的強度。λ 為通道權重系數,為了減輕光亮度對相似性傳播的影響,亮度通道的權重設為0.2,其余均為0.4。由此可知,在滿足搜索半徑-γ≤ij≤γ 的范圍內,當兩個像素值越接近,則色域相似度越強。除此之外,當兩節點對在空間距離越近時,則空域相似性越強。
通常情況下,由于噪聲對于相似性傳遞的影響,利用概率最大值判別各像素點真實類別會產生不準確的分割結果。因此延用超像素塊的思路,減少噪聲對于整體分割區域的影響。為了計算各超像素塊屬于某一類別的概率值Bc,該過程可以表示為,其中,S 表示指定超像素塊內像素點的集合,N 為超像素塊內像素點的數目。通過計算超像素塊內各像素點的平均概率作為超像素塊的概率值,選擇最大概率值的類別作為相應的語義標簽。最終,利用相似性傳遞模塊的輸出結果作為語義標簽,訓練語義分割網絡。
2 實驗結果與分析
本章提出的算法在PASCAL VOC 2012數據集下進行驗證。PASCAL VOC 2012分割數據集中有包含背景在內共21類的像素級標簽,原始數據集中有1464張訓練集圖像,引入SBD 數據集[6]將訓練圖像擴充至10582張,同時包含1449張驗證集圖像。在本文中,僅利用訓練集的圖像類別標簽作為弱監督信息,測試實驗效果時使用原數據集中的真實標簽。為了驗證本文所提方法的有效性,本文采用平均交并比(mIoU)作為評價標準對分割結果進行測試。
本文提出算法的兩個階段,均在VGG16網絡架構上進行修改,并使用公開數據集ImageNet 的預訓練參數對網絡進行初始化操作。在制作像素級標簽的過程中,為了保留分類網絡對于目標定位的效果,使用卷積層替換了全連接層fc6和fc7,并且緊接一個全局平均池化層,將整合后的全局特征輸入Softmax 預測層。在分類網絡的訓練階段,輸入圖片的大小被調整為448×448,設置初始學習率為0.01,權重衰減為0.0001,動量0.9,圖像批量大小設置為16,共訓練20輪。在推斷階段,共生成20個類別的激活映射分值圖。
在語義分割模塊中,使用DeepLab-CRFLargeFOV 作為分割模型。其中,刪除了VGG16架構最后的全連接層,使用卷積層代替。并且引入空洞卷積,將conv5中的三層卷積層設置空洞卷積參數為2,同時fc6設置空洞卷積參數為12,且pool4和pool5的采樣步長調整為1,使模型輸出尺度更大的語義分割結果。在語義分割網絡的訓練階段,使用隨機梯度下降算法優化網絡,其中動量值為0.9,權重衰減為0.0005。對于網絡中進行結構修改的部分,使用0均值且方差為0.05進行隨機初始化。設置初始學習率為0.001,并隨訓練過程逐漸降低,衰減率為0.9,圖像批量大小設置為4,共訓練15 輪。在推斷階段中,語義分割結果使用全連接條件隨機場進行后處理。
2.1 語義標簽效果分析
為了探索本文算法里各個階段產生語義標簽質量的變化情況,在測試階段進行了實驗結果定量分析。在表1展示了語義標簽對比效果,可以發現SPBCAM 相比SPN在精確度上提升了4.7%,原因在于本文所提方法通過結合全局相似性與局部相似性,更好的判別各個像素點屬于邊緣的情況,有效的過濾掉假邊緣噪聲,使得產生的超像素塊中聚合了相似性強的像素點。除此之外,額外的CAM 優化步驟大量的減少了錯誤定位區域,因此產生的種子區域效果更好。
另外,在使用了SPBCAM 作為種子標記區域,本文提出的種子擴張策略相比隨機游走算法在語義標簽平均交并比精確度上提升了5.5%,原因在于使用相似性搜索半徑的方式代替傳統圖論算法中四鄰域或八鄰域的連接方式,使算法可以在更大的感受野范圍內判別圖節點的相似性程度,減少了由于假邊緣產生的相似性傳遞隔斷。并且利用超像素塊作為圖像語義判別的基礎單位,增強了算法在擴張種子區域時的魯棒性。
總體來看,本文提出的算法在多階段優化策略下逐步改善語義標簽效果,不僅提高了圖像種子區域的精確性,而且以種子區域為線索,有效的將相似性特征傳遞到圖像的未標記區域。算法各階段語義標簽質量對比(%):CAM34.6、SPBCAM48.5、SPBCAM+RW56.7、SPBCAM+SPBRW62.2。
2.2 弱監督語義分割效果分析
為進一步證明超像素相似性傳遞算法的有效性,使用本文產生的像素級語義標簽訓練語義分割網絡。另外,在驗證集中使用mIoU 評價標準對語義分割結果測試,并與目前主流的弱監督語義分割方法進行效果對比,在表2中展示WSSL、STC、SEC、CBTS、AdvErasing、DSNA、MCOF 工作以及本章所提出的弱監督語義分割方法的準確率對比。為了便于觀察,在表內對各個類別的最高分值進行加粗處理。
在表2中可以看出,本章所提方法在21個類別(包括背景)的mIoU 分值上獲得了59.7%的分數,相比于其它弱監督語義分割方法在分割精度上提升2.1%,獲得了更精確的語義分割結果。尤其在例如“背景”、“鳥”、“牛”等多個類別中均獲得了最高的分值。分析原因在于本章方法產生的語義分割標簽在邊緣處有著更精確的細節效果,同時超像素的方式可以聚合具有強相似性的像素點,在語義標簽形成的過程中利用該特性可以有效的濾除噪聲區域,產生更加準確的語義標簽。除此之外,回顧表1可以發現,超像素種子定位的效果很大程度上決定著同種類別下語義分割結果的質量,例如類別“牛”在超像素種子定位階段獲得了62.2%的分值,種子區域經過相似性傳遞后獲得了更精確的語義標簽,因此類別“牛”的語義分割效果相比于其它弱監督語義分割方法中最好的結果仍然高出了4.7%。圖2中展示了部分圖像的語義分割效果。

圖2 語義分割效果展示
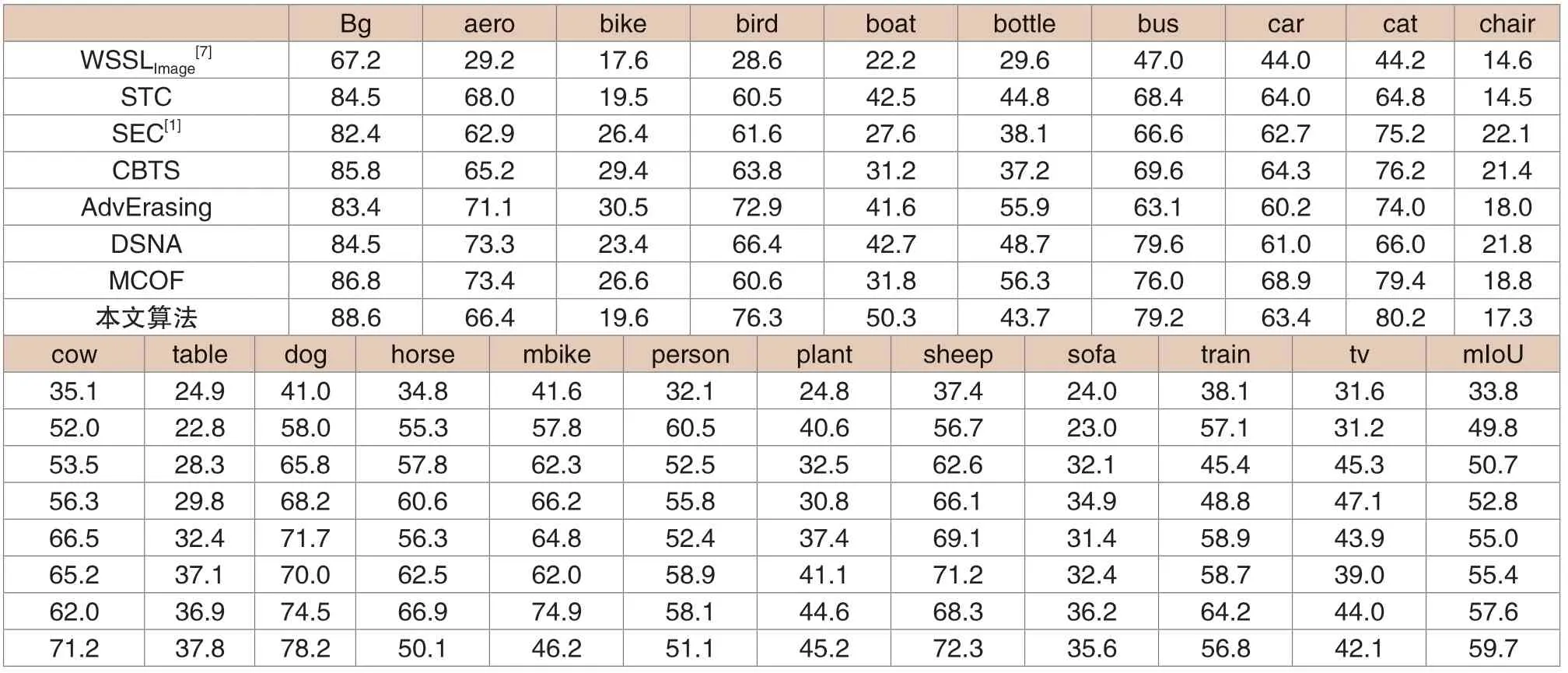
表2 監督語義分割效果比對(單位:%)
3 結論
本文以圖像注意力機制為基礎定位目標種子區域,同時以超像素作為圖像的基本分割單位,兩者相互結合產生高精確度的超像素種子代替隨機游走算法的人工交互標記。除此之外,在相似性傳遞階段設計了搜索半徑以及超像素語義判別等優化策略,解決了隨機游走算法容易受假邊緣影響的問題,產生了高質量的語義標簽。最后,利用語義標簽訓練語義分割網絡,并在PASCAL VOC2012數據集以及SBD 補充數據集中,對語義標簽和弱監督語義分割性能以mIoU 指標作為評價標準測試,并與其它主流圖像級弱監督語義分割方法進行比較。實驗結果表明,本文所提出的弱監督語義分割方法相比于其它主流方法在mIoU 分值上提高了2.1%,并且該算法具有更強的魯棒性,同時語義標簽有著高精確度的邊緣分割效果。
猜你喜歡
今日農業(2021年9期)2021-11-26 07:41:24
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
開放教育研究(2020年2期)2020-03-31 01:54:14
現代語文(2016年21期)2016-05-25 13:13:44
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
大連民族大學學報(2015年2期)2015-02-27 08:28:11
民生周刊(2012年10期)2012-10-14 09:06:46
當代修辭學(2011年6期)2011-01-29 02:49:50
