基于神經網絡模型壓縮技術的目標檢測算法研究
2021-12-28 10:47:26魏志飛宋泉宏楊擎宇王愛華
空天防御 2021年4期
魏志飛,宋泉宏,李 芳,楊擎宇,王愛華
(上海機電工程研究所,上海 201109)
0 引 言
近年來,計算機視覺領域的專家學者在目標檢測領域[1]所做的工作逐漸增多,使得卷積神經網絡(convolutional neural network,CNN)應用在該領域獲得了非凡的成果;隨著網絡模型層數、結構、體積不斷提升,模型的計算量也隨之增加,所依賴的計算資源也在不斷提高。卷積神經網絡的實際應用場景變得越來越廣泛,但在許多實際應用中,部署深度卷積神經網絡很大程度上受計算資源限制,深度學習模型因無法達到實時性效果難以在嵌入式設備中部署。針對深度學習模型在嵌入式系統中計算資源相比較于服務器資源有限的難題[2],本文開展了基于神經網絡模型壓縮算法的目標檢測算法研究。
網絡模型在嵌入式設備中部署主要受限于3個因素;①模型體積,CNN 模型中包含著數以百萬計的訓練參數,這些參數以及模型結構等運行過程中的相關信息都需要儲存在磁盤當中,這些參數對存儲資源有限的嵌入式設備來講是非常大的挑戰;②運行時所需內存,模型在前向傳播過程中,即便設置批量大小為1,運行過程當中可能會產生非常龐大的中間參數,或許會比存儲模型的參數還要多,這對于許多內存有限的設備而言是無法承受的運算載荷;③運行時的計算量,在圖像上進行卷積操作,該過程計算量是非常龐大的,這可能導致高性能的深度學習算法模型處理單張圖片就需要幾十秒甚至幾分鐘的運算時間,那么將該算法應用于嵌入式設備是不切實際的。
模型壓縮算法有很多,如低秩分解、參數量化等,需要為其編制特定的軟件和設計相關的硬件方案來實現加速。而通過模型剪枝對網絡進行模型壓縮,無需特定的軟件及硬件設計,就可對模型進行優化,是一種非常有效、便捷的方案。本文采用的是一種基于通道因子對網絡模型進行結構剪枝的方法,這是一種簡單而有效的壓縮策略,它可以解決在資源有限的條件下應用網絡模型所面臨的問題,可以在保證算法精度損失較小的情況下提高網絡模型的運行效率。
1 YOLO算法
YOLO 算法一共有五種系列,分別為YOLOv1~YOLOv5。YOLO 算法是基于單階段的目標檢測算法,將特征提取、錨框回歸和分類融合在一個模型當中,與兩階段目標檢測算法相比,有著運行速度快的優點。
YOLOv1(you only look once)算法,只需一次神經網絡的前向傳播運算就可以進行目標檢測任務。YOLOv1 算法的主要思想是先把輸入圖像分成S×S個網格單元,每個單元承擔對落入該區域內目標進行檢測的任務;每個單元分別預測B個包圍框(bounding boxes)、包圍框的置信度及C種類別的概率。
YOLOv2 算法引入了R-CNN 算法中錨框(anchor boxes)的策略,采用錨框來提高目標定位的準確度,同時,采用ImageNet 分類數據集和COCO 檢測數據聯合訓練的方式,來提高算法的分類和檢測性能。
YOLOv3 算法為了讓檢測性能得到進一步提高,在YOLOv2 的基礎上,借鑒了ResNet 中的殘差結構的思路,使得網絡的深度進一步得到加深,將原來的Darknet19 網絡結構優化成Darknet53 網絡結構,這樣可使網絡模型能更好地提取高層結構中的語義特征,同時,該算法采用了特征金字塔網絡(feature pyramind network,FPN)算法的策略,生成3 個不同維度的特征張量,進行多尺度預測,從而使得該算法適應于不同尺度大小的目標檢測任務。
YOLOv4 算法在YOLOv3 的基礎上采用了CSPDarknet53 和空間金字塔池化(spatial pyramid pooling,SPP)結構,提高了檢測器的檢測精度能力。
YOLOv5 算法采用了Focus、PANet 等模型結構,同時采用了自適應特征池化的方法,用于聚合多特征層上的信息路徑,從而提高了模型預測的準確性。
就算法主體的網絡構建而言,YOLOv3 算法與YOLOv4/YOLOv5 算法基本相同,算法的核心思想沒有太大變化;就參數量而言,YOLOv3 算法參數量相對較少,具有運算速度更快的優勢,故本文選擇對YOLOv3算法進行相應的改進和優化。
2 神經網絡的模型優化
本文主要是在YOLOv3 算法網絡基礎上進行兩方面的優化和改進,如圖1 所示。第一,采用Kmeans++聚類算法對訓練集的先驗框進行聚類,使得深度學習算法訓練速度更快,便于網絡模型收斂;第二,對YOLOv3 算法網絡結構,采用模型壓縮算法中的模型剪枝技術進行裁剪,使得網絡能夠在不損失較大算法精度條件下,提高算法的運行速率。
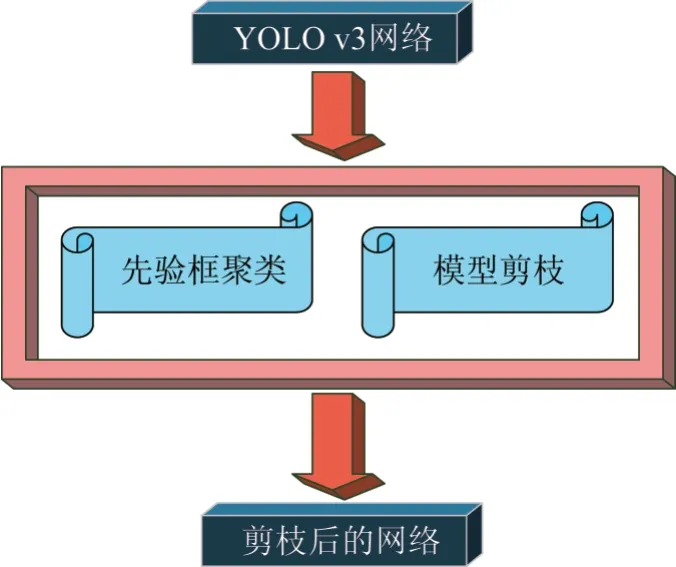
圖1 YOLOv3的模型優化Fig.1 Optimization of YOLOv3
2.1 先驗框的聚類算法
在Faster R-CNN 算法[3]當中,錨框的初始值是人為設定的,而初始值會影響算法訓練的收斂效果,所以根據應用場景中的目標尺寸來設定網絡模型中錨框的初始值是非常必要的。因此,針對錨框的初始值設定,使用聚類算法對數據集當中的目標相關信息進行錨框聚類,以便獲取比較好的初始值設定。
聚類算法[4],是一種無監督的策略,一般而言,數據的聚類中心選擇得越好,算法訓練效果就越佳。本文使用K-means++算法進行數據集的聚類。聚類數據為目標的檢測數據,數據格式為(xj,yj,wj,hj),j=1,2,…,N,其 中(xj,yj)是錨框的左下角坐標值,(wj,hj)是錨框的寬度和高度,N是錨框的數量。
首先,隨機選取k個樣本點數據,由于錨框的坐標值是確定的,因此本文采用錨框的寬度和高度作為樣本數據,接著計算其他數據從而獲取其他聚類中心。
在初始化樣本點以后,計算其他點到聚類中心的距離,選取距離最近點成為自身的聚類中心,所有點分配完成以后,對樣本點形成的簇重新更新聚類中心,更新的計算形式為Wi=∑wi Ni和Hi=∑hi Ni,其中Ni為第i簇的樣本點個數;不斷迭代上述計算過程,直到值的改變量幾乎不變的時候,便獲取到最終的聚類中心,進而確定錨框的初始大小。
聚類算法中,樣本點間的距離一般使用歐氏距離來評估,數據集中目標尺度的大小可以分為:大尺度、中尺度和小尺度。采用歐氏距離計算時,會使得大的錨框比小的錨框誤差更大。因而采用錨框和真實框有更大的重疊度(intersection over union,IOU)來評估樣本點之間的間距,從而避免受到錨框大小的影響,所以算法改進時采用Jake 距離,可適應不同目標的尺度,如式(1)所示。
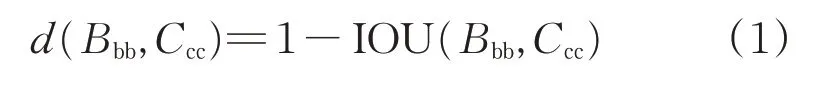
式中:Bbb為樣本的錨框;Ccc為聚類中心;IOU(Bbb,Ccc)為錨框與聚類值的重疊度。IOU 如式(2)所示,表示預測的準確度。
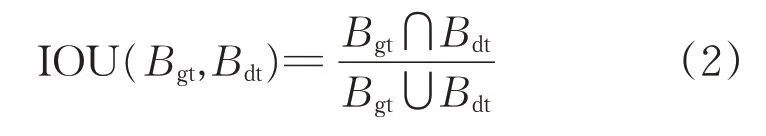
式中:Bgt表示真實框;Bdt表示預測框。
結合式(1)和(2),最終距離可由式(3)計算。
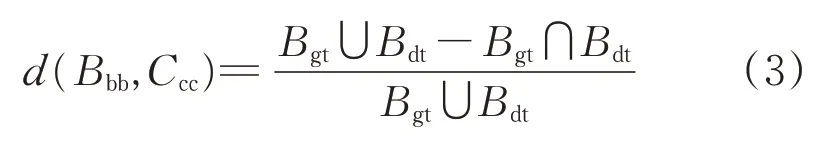
采用聚類算法以后,算法訓練過程收斂變得更快。根據實際應用領域對所設計的網絡進行重新聚類。
2.2 模型壓縮算法優化
本文中,模型壓縮算法主要采用模型通道剪枝[5]的方法,該方法分5 個步驟執行,如圖2 所示。第一步,初始化網絡,可選擇高斯初始化或全零初始化等方案,本文采用隨機初始化方案;第二步,基于通道稀疏正則化的方法進行訓練,在網絡中加入通道因子用于識別作用較小的通道(或神經元),這有利于在下面的流程中對網絡進行通道級別的裁剪;第三步,裁剪網絡,采用通道因子加入到網絡層當中對網絡結構進行剪枝,從而稀疏稠密的網絡結構[6];第四步,微調網絡,重新訓練被裁剪后的網絡結構中剩余神經元連接的權值,不斷迭代訓練,直到滿足網絡模型準確度等指標要求后,便得到最終壓縮后的網絡模型;最后,將壓縮后的網絡模型輸出。

圖2 模型剪枝流程Fig.2 Process of model pruning
這種方法的主要實現途徑是對網絡模型中的批量歸一化(batch normalization,BN)層中的通道因子γ加入正則化約束[7]。
每個通道因子γ對應特定的網絡層通道,通過L1正則化能夠辯知作用較小的通道(或神經元)。這有助于開展后續模型裁剪。當作用較小的通道被裁剪的時候,可能會暫時使網絡性能變弱,但后續可對裁剪后的網絡進行微調用于彌補裁剪的影響。相比較于起始的網絡結構,裁剪后的網絡結構在模型大小、運行時內存和計算量等方面更加輕量化[8]。
圖3 為通道裁剪示意圖,當通道因子γ的值幾乎等于0時,就斷開網絡層之間相應輸入和輸出的連接,反之,保留網絡層之間的連接。如圖3所示,當通達因子γ為橙色顯示的極小值時,相關連接就被刪除,而藍色表示的網絡連接就會被保留[9]。由于通道因子與網絡權重是共同訓練的,這就使得該策略能夠在保留原模型性能的同時對通道進行裁剪。
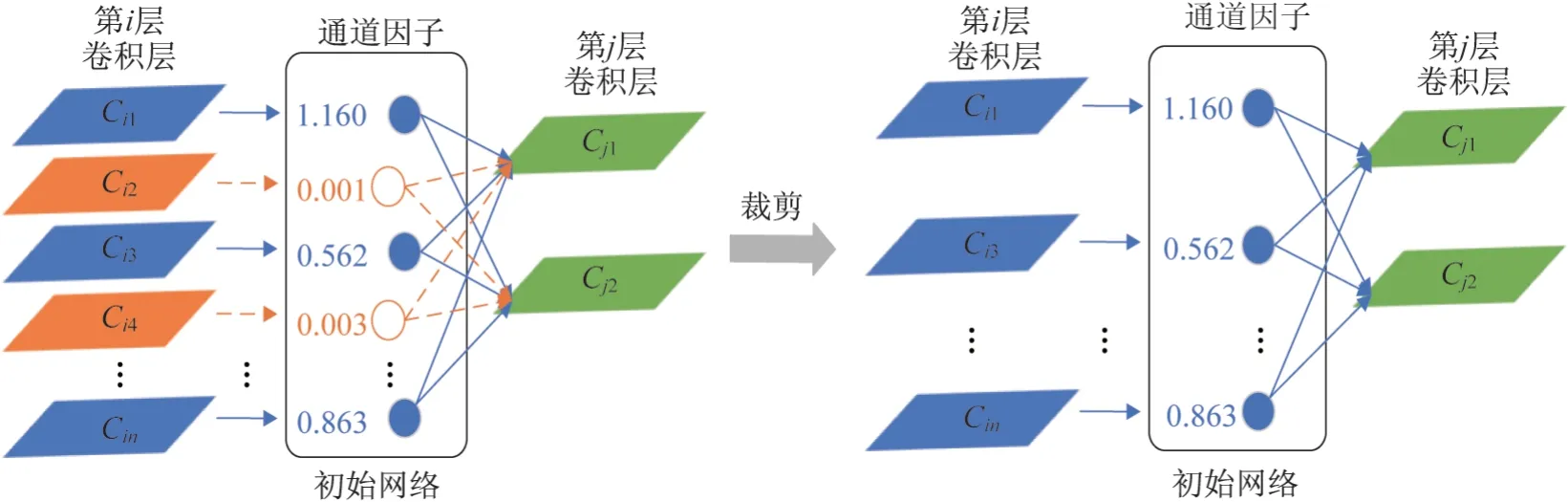
圖3 通道裁剪示意圖Fig.3 Diagram of channel pruning
對模型中的通道進行裁剪,會降低網絡模型的準確度,因此,需對訓練后的模型進行微調[10]。采用整個數據集對裁剪后的模型再一次進行網絡訓練,恢復起始模型的準確度;最后,便產生了一個裁剪后性能基本不變的網絡模型。
3 試驗結果及分析
本文的試驗環境為:①處理器型號,AMD Ryzen5 2600X@3.6GHz;②存儲配置,16GRAM,512G SSD;③顯卡配置,NVIDIA GTX1080Ti;④操作系統,Windows 10(64 位);⑤軟件平臺,Python3.5、Pytorch1.3.0(GPU版)。
本文采用KITTI 公開數據集,因此,需將該數據集標注的txt 數據格式轉化為VOC 數據集XML 格式[11];然后,采用K-means++聚類算法對6 500 張訓練集數據進行錨框聚類。聚類后的這九個錨框大小的結果從小到大為:(22,19),(46,29),(39,54),(86,52),(71,108),(139,86),(106,161),(231,130)和(289,188);接著,對錨框中的位置數據進行歸一化處理,進而提升模型的訓練效果。
在神經網絡壓縮的試驗階段中主要包括了模型的基礎訓練、稀疏訓練、模型剪枝和模型微調4 個步驟[12]。
第一步是基礎訓練,主要是為獲取一個高精度的初始化模型,它的精度和參數選擇對后續階段的訓練有著至關重要的作用。第二步是稀疏訓練,使用通道因子對網絡模型的權重分布進行重新調整。第三步是通道剪枝,裁剪作用較小的通道或神經單元。第四步是模型微調,剪枝后的網絡或許會導致網絡模型的精度降低,因而對網絡模型進行微調,從而復原起始的網絡模型準確度。
圖4 所示為訓練效果,綠色線部分展現的是基礎訓練,紅色線展現的是稀疏訓練。在基礎訓練過程中,訓練的圖像批次數量(batch_size)設置為32 張,基礎訓練總次數(epochs)設置為100 次。稀疏化訓練過程中,訓練的圖像批次數量設置為32 張,總訓練次數設置為280 次。由圖4 可以看出YOLOv3 模型稀疏化訓練后模型mAP的變化趨勢,模型的準確度在不斷地上升,平均準確度mAP在0.8之后變化趨于平穩。
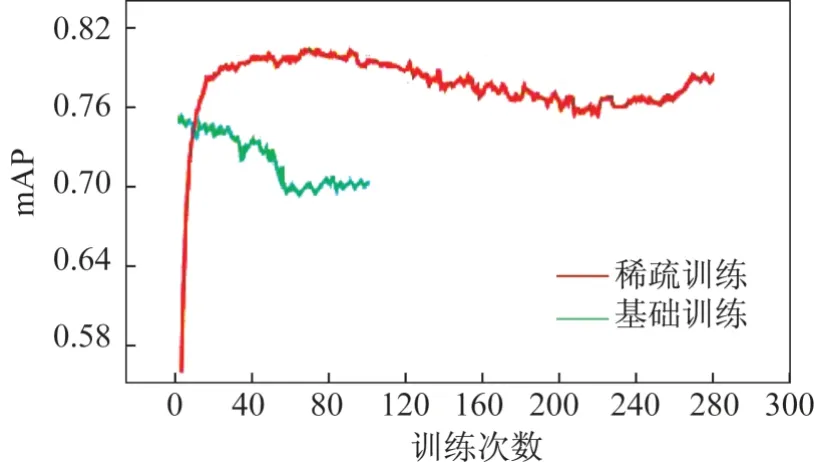
圖4 基礎訓練和稀疏訓練效果Fig.4 Results of basic training and sparse training
本文的裁剪率參數設定為80%,模型微調的訓練參數中,訓練的圖像批次大小設為32 張,總訓練次數設為100 次。表1 所示為模型裁剪前后的試驗結果對比,可以看出模型的參數量、計算量都有著非常大的下降,而剪枝后算法模型的運行速率是未剪枝算法模型的2 倍左右,而網絡模型的平均準確度mAP 沒有太大的損失。試驗結果顯示,對網絡模型進行網絡剪枝,能保證原算法模型準確度不損失的同時,明顯加快網絡模型的運行速率。

表1 YOLOv3模型剪枝前后對比Tab.1 Comparison of YOLOv3 model pruning and unpruning
為了更直觀驗證,使用通道剪枝后的YOLOv3 算法對KITTI測試集上的圖片進行場景內的物體測試,如圖5所示。

圖5 測試效果Fig.5 Test result
由圖5 測試結果可以看出,采用通道剪枝后的YOLOv3網絡模型依然擁有著較好的檢測性能。
4 結束語
本文提出了一種基于神經網絡模型壓縮技術的目標檢測算法。先采用K-means++算法對數據集的先驗框進行聚類;接著采用基于模型通道剪枝的模型壓縮算法對神經網絡進行模型壓縮;最后通過試驗驗證了使用模型通道剪枝裁剪YOLOv3 模型有良好效果。可以看出,本文在保持著高準確度的情況下,能減小模型的參數數量和模型體積,也能有效提高模型的運行速度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
