基于N3D_DIOU 的圖像與點云融合目標(biāo)檢測算法
2021-12-14 02:07:10郭保青謝光非
光學(xué)精密工程 2021年11期
關(guān)鍵詞:檢測
郭保青 ,謝光非
(1. 北京交通大學(xué)機(jī)械與電子控制工程學(xué)院,北京100044;2. 北京交通大學(xué)智慧高鐵系統(tǒng)前沿科學(xué)中心,北京100044)
1 引 言
基于目標(biāo)檢測的環(huán)境感知是自動駕駛和機(jī)器人導(dǎo)航[1-2]的基礎(chǔ),常見的目標(biāo)檢測方法包括二維圖像目標(biāo)識別和三維點云目標(biāo)精確定位。基于 二 維 圖 像 的 SPPnet[3],R-CNN[4],F(xiàn)ast RCNN[5],F(xiàn)aster R-CNN[6]和 YOLO[7]系列算法被廣泛應(yīng)用于目標(biāo)識別,這類算法效率較高,但對目標(biāo)大小及位置的估計不夠準(zhǔn)確。
與二維目標(biāo)檢測[8-9]相比,基于三維點云的目標(biāo)識別與定位[10]可以精準(zhǔn)估計目標(biāo)的三維尺寸及位置,對車輛自主駕駛和機(jī)器人導(dǎo)航具有更重要的意義。然而,三維目標(biāo)檢測面臨著數(shù)據(jù)量大、點云分布不均勻和處理復(fù)雜等諸多挑戰(zhàn),許多相關(guān)研究致力于提高三維點云檢測的時效性和準(zhǔn)確性。Complex-YOLO[11]和 YOLO3D[12]算法對YOLO 的檢測框架進(jìn)行了三維擴(kuò)展,PIX?OR[13]將三維點云投影到BEV 視圖中進(jìn)行二維檢測,SqueezeSeg 算法[14]則將三維點云投影到了球形網(wǎng)格。上述這類算法均是利用成熟的二維探測框架將點云投影到平面上,然而投影過程中的空間信息丟失會導(dǎo)致空間遮擋和精度下降的問題。第二類算法通過對點云體素化進(jìn)行三維卷積操作提取點云特征并生成檢測框。ZHOU等人提出的VoxelNet[15]首先將點云劃分為體素,然后使用RPN 網(wǎng)絡(luò)進(jìn)行對象檢測;Second 網(wǎng)絡(luò)[16]同樣對點云進(jìn)行體素劃分,使用 Pointnet 對非空體素進(jìn)行特征提取。由于點云的稀疏性,這類算法進(jìn)行點云體素化大大增加了數(shù)據(jù)量,大量的空白體素會導(dǎo)致計算的浪費。
激光點云與圖像融合算法也可以分為兩類。Liang 等人[17]提出了多任務(wù)多傳感器檢測模型分別對激光點云和圖像進(jìn)行特征提取,然后輸入到同一神經(jīng)網(wǎng)絡(luò)進(jìn)行目標(biāo)分類和預(yù)測,屬于前融合方案。現(xiàn)有大部分前融合方案網(wǎng)絡(luò)本身較為復(fù)雜,難以實現(xiàn)實時性。Wu 等人[18]分別利用點云和圖像進(jìn)行行人檢測,再對檢測結(jié)果進(jìn)行匹配后輸出最終融合的結(jié)果,屬于后融合方案。但目前后融合方法應(yīng)用較為局限,極少能夠用于交通環(huán)境目標(biāo)檢測。
特征提取是目標(biāo)檢測的重要環(huán)節(jié),卷積作為一種特征提取方法已經(jīng)廣泛應(yīng)用于二維圖像目標(biāo)識別,但由于點云的無序性,卷積無法直接應(yīng)用于點云特征提取。Pointnet[19]首次提出了一種針對三維點云直接提取特征的網(wǎng)絡(luò)結(jié)構(gòu),但采用最大池化解決點云無序性問題,由于本地連接被忽略,僅能提取全局特征。為了解決這一問題,通常采用最遠(yuǎn)點采樣方法生成種子點對原始點云進(jìn)行分組,但這種方法只能保證覆蓋面廣,不能代表最優(yōu)選擇。為了優(yōu)化點云分組策略,本文提出了一種改進(jìn)的投票模型網(wǎng)絡(luò),利用神經(jīng)網(wǎng)絡(luò)優(yōu)化種子點的選擇并用于后續(xù)多尺度局部特征提取。
目標(biāo)檢測精度通常采用檢測框與實際目標(biāo)框的交并比(IOU)作為評價指標(biāo)。目標(biāo)檢測中一般使用L1 或L2 損失函數(shù)進(jìn)行檢測框的優(yōu)化,但是不同的L1 和L2 損失值可能具有相同的IOU 值,此時利用IOU 作為二維檢測損失函數(shù)會存在很大的不收斂風(fēng)險[20-21]。為了提升收斂性,文獻(xiàn)[22-23]通過 IOU 進(jìn)行優(yōu)化提出了 GIOU 和 DI?OU 損失函數(shù),但只適用于二維情況。為了解決三維目標(biāo)檢測問題,本文提出了一種適用于三維點云檢測的N3D_DIOU_loss 損失函數(shù)來統(tǒng)一損失函數(shù)和評估準(zhǔn)則,達(dá)到了較好的檢測效果。
本文充分利用經(jīng)過事先聯(lián)合標(biāo)定的二維圖像及三維點云信息,提出了融合二維圖像與三維點云的目標(biāo)檢測框架,利用二維圖像中檢測到的目標(biāo)提取三維點云中的截頭體來濾除多余的背景點,降低了三維計算成本;提出基于廣義霍夫變換的改進(jìn)投票模型用于多尺度特征提取,同時提出N3D_DIOU_loss 將DIOU 損失函數(shù)從二維拓展到三維,代替?zhèn)鹘y(tǒng)的L1 損失函數(shù)優(yōu)化回歸目標(biāo)框,使得目標(biāo)框的生成更精確。KITTI 數(shù)據(jù)集的消融實驗表明:與經(jīng)典方法相比,本文算法在三維目標(biāo)檢測精度和俯瞰圖檢測精度上均有較大提升,達(dá)到了較好的檢測效果。
2 基于投票模型的目標(biāo)檢測網(wǎng)絡(luò)
本節(jié)主要介紹融合二維圖像及三維點云的目標(biāo)檢測網(wǎng)絡(luò)整體結(jié)構(gòu)。如圖1 所示,目標(biāo)檢測網(wǎng)絡(luò)分為三個主要部分:(1)數(shù)據(jù)預(yù)處理;(2)投票模型網(wǎng)絡(luò);(3)RPN 網(wǎng)絡(luò)。目標(biāo)檢測網(wǎng)絡(luò)以三維原始點云和二維圖像作為輸入,用二維圖像檢測框?qū)?yīng)的平截頭體進(jìn)行點云過濾;過濾后的點云被初步聚類,并由改進(jìn)的投票模型網(wǎng)絡(luò)層進(jìn)行特征提取,然后使用FCN 網(wǎng)絡(luò)進(jìn)行多尺度特征融合,融合后的特征被輸入到檢測頭,包括分類頭(CLS)和回歸頭(REG),以預(yù)測檢測結(jié)果。
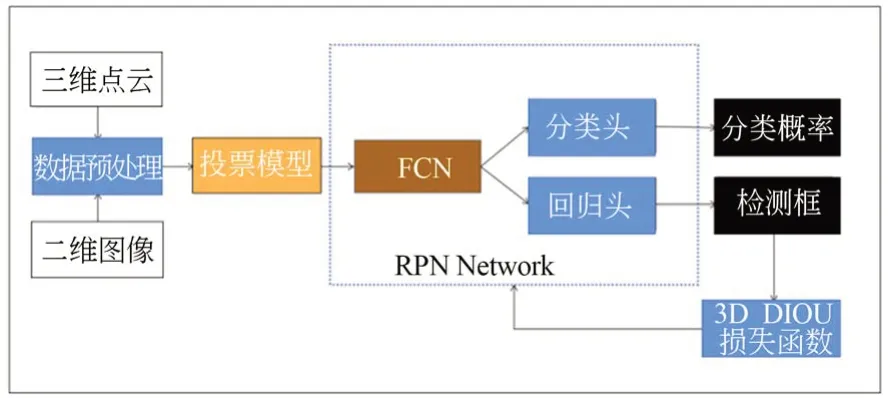
圖1 檢測網(wǎng)絡(luò)框架Fig.1 Detection network framework
2.1 三維點云預(yù)過濾處理
為了綜合利用二維圖像及三維點云提供的特征信息提升點云處理效率,假設(shè)激光雷達(dá)和攝像機(jī)已經(jīng)聯(lián)合校準(zhǔn),可以執(zhí)行坐標(biāo)轉(zhuǎn)換。由于二維圖像目標(biāo)檢測算法相對成熟且高效,本文首先使用二維檢測器在圖像中提取目標(biāo)框,然后用二維框所對應(yīng)的平截頭體過濾三維目標(biāo)點云,過濾后的點云圍繞二維圖像中對應(yīng)目標(biāo)中心點的空間點進(jìn)行旋轉(zhuǎn)直到中心線與坐標(biāo)軸Y對齊,以便于后續(xù)的點云聚合。其中,中心線是由二維被測物體中心反投影到三維空間生成的。
2.2 投票模型網(wǎng)絡(luò)
學(xué)習(xí)點云的語義特征,首先需要提取相鄰點的低層幾何特征。
過濾后的點云仍具有離散性和無序性的特點。為了對點云進(jìn)行分類和分割,一些算法使用最近鄰采樣來聚集點云,使用最遠(yuǎn)點采樣(FPS)生成原始種子點,F(xiàn)PS 雖然覆蓋的點云范圍很廣,但無法確定目標(biāo)的具體位置。另一類算法采用體素分割用于在同一體素內(nèi)聚集點云,然而這種體素分割方法無法獲得邊界的位置。
為了解決這些問題,我們提出了一個如圖2所示的改進(jìn)的投票模型網(wǎng)絡(luò)來生成原始種子點,該網(wǎng)絡(luò)主要由投票模塊、分組模塊和Pointnet 模塊組成。其中采用結(jié)合基于廣義霍夫變換的vote 投票模塊與基于最遠(yuǎn)點采樣的分組模塊進(jìn)行點云的聚類,采用Pointnet 進(jìn)行多尺度特征提取。
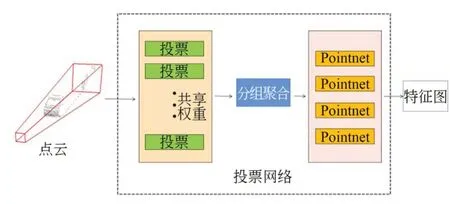
圖2 投票模型網(wǎng)絡(luò)Fig.2 Vote model network
首先將包含點云位置和激光反射強(qiáng)度特征的過濾點云輸入到由conv 層、BN 層和relu 層組成的投票模塊中,這些模塊共享權(quán)重模擬了廣義霍夫變換對中心點的投票過程尋找點云的聚類中心生成目標(biāo)中心。在此基礎(chǔ)上,本文進(jìn)一步基于目標(biāo)中心的深度和角度生成采樣中心以此改進(jìn)了投票模型,使得網(wǎng)絡(luò)可以獲得更精細(xì)的局部特征。目標(biāo)中心的位移偏移Δxi和特征偏移Δfi由投票模塊生成,并由L1 損失函數(shù)監(jiān)督。投票模塊生成目標(biāo)中心yi,再由分組模塊基于最遠(yuǎn)點采樣原理對過濾后的點云進(jìn)行聚合得到分組點。由于目標(biāo)的大小和點云的密度未知,所以使用四組不同的歐式距離劃定球形區(qū)域進(jìn)行粗略聚類,在球形區(qū)域中使用最遠(yuǎn)點采樣法對點云進(jìn)行降采樣獲得四組不同尺度的降采樣點云,最后將不同尺度的降采樣點云分別輸入到四個Pointnet 模塊就可以獲得四組不同尺度的點云特征圖。
2.3 基于 FCN 的 RPN 網(wǎng)絡(luò)
利用上述投票模型網(wǎng)絡(luò)完成了點云聚類和不同尺度的特征提取,四種特征的尺度大小分別為f1=L·d/4,f2=L·d/4,f3=L·d/2,f4=L·d,其中,L是采樣點數(shù),d是特征大小。為了進(jìn)一步對不同尺寸物體進(jìn)行目標(biāo)框預(yù)測,本文設(shè)計了如圖3 所示的對四種不同尺度特征進(jìn)行融合的FCN網(wǎng) 絡(luò) 結(jié) 構(gòu) 。 FCN 網(wǎng) 絡(luò) 由 conv 層 、deconv 層 和merge 層組成;merge 層也是 conv 層,用于特征圖融合;deconv 層用于調(diào)整特征圖大小,以保證需要融合的各特征圖具有相同的尺寸。
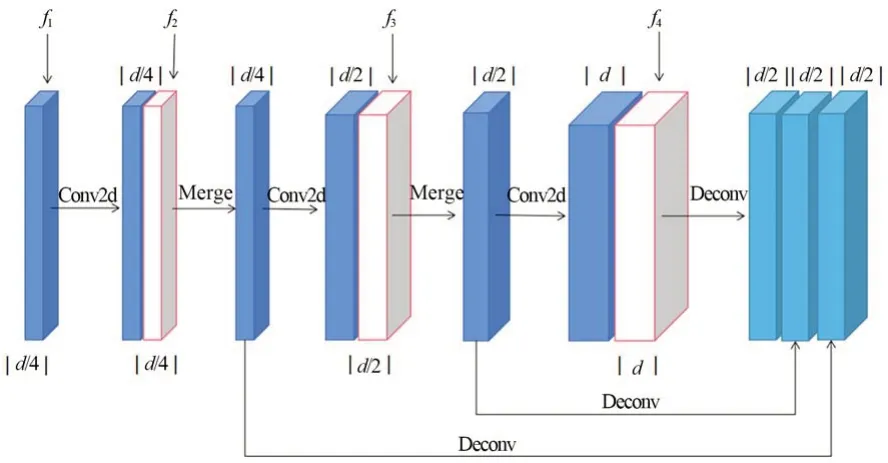
圖3 FCN 網(wǎng)絡(luò)結(jié)構(gòu)Fig.3 Structure of FCN network
經(jīng)過FCN 融合后的特征圖輸入分類頭和回歸頭,分類頭用于識別目標(biāo)的類別,采用softmax結(jié)構(gòu)輸出感興趣目標(biāo)的分類概率;回歸頭用于目標(biāo)的定位,輸出包含實例的最小包圍立方體參數(shù)(包圍框中心、長、寬和高)。回歸框與分類概率也一一進(jìn)行對應(yīng),因此可以用一個統(tǒng)一的多任務(wù)損失函數(shù)對分類與回歸進(jìn)行統(tǒng)一的優(yōu)化訓(xùn)練。
2.4 參數(shù)微調(diào)
為降低二維檢測精度對算法的影響,本文提出的方法參考 F-Convnet[24]進(jìn)行參數(shù)微調(diào),過程如下:
(1)根據(jù)坐標(biāo)對檢測出的三維框進(jìn)行歸一化,每個檢測框的中心作為它們各自坐標(biāo)系的原點,坐標(biāo)軸的方向統(tǒng)一到第一檢測框;
(2)在預(yù)處理過程中,將點云的過濾范圍擴(kuò)大并乘一個膨脹系數(shù),在本文中,這個膨脹系數(shù)被設(shè)為1.5;過濾范圍擴(kuò)大有助于降低檢測框定位不夠精確造成的點云過多的過濾,從而提高算法穩(wěn)定性;
(3)將(2)中過濾后的點云再次送入后續(xù)網(wǎng)絡(luò)重新訓(xùn)練,調(diào)整網(wǎng)絡(luò)參數(shù)。消融實驗表明,參數(shù)微調(diào)過程對提高探測精度具有顯著作用。
3 3D_DIOU 多任務(wù)損失函數(shù)
深度神經(jīng)網(wǎng)絡(luò)的訓(xùn)練實際上是基于梯度下降的一種優(yōu)化過程,設(shè)計合理的損失函數(shù)可以加快訓(xùn)練過程并獲得最優(yōu)解。為了完成多任務(wù)分類,本文設(shè)計了一種基于三維DIOU 的多任務(wù)損失函數(shù),包含分類損失函數(shù)Lcls與三維擴(kuò)展的DI?OU 損失函數(shù)N3D_DIOU_loss 兩部分。為了在訓(xùn)練期間將每個部分的損失函數(shù)保持在相似的范圍內(nèi),兩個部分分別乘以權(quán)重ω1和ω2,如公式(1)所示。
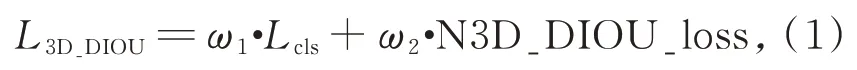
其中,權(quán)重ω1和ω2要保證訓(xùn)練過程中兩部分損失下降的速度相當(dāng),根據(jù)經(jīng)驗并基于上述原則優(yōu)化后的權(quán)重值為ω1=1 和ω2=8。
3.1 分類損失函數(shù)
由于RPN 預(yù)測的大多數(shù)檢測框都是負(fù)樣本,因此正樣本和負(fù)樣本之間存在很大的不平衡。這種不平衡使得訓(xùn)練過程中的負(fù)損失遠(yuǎn)大于正損失,這對網(wǎng)絡(luò)訓(xùn)練是有害的。為了解決這個問題,Lin[25]提出了焦點損失函數(shù)(FL),并表示為公式(2):
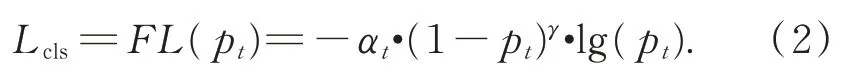
本文對于類別的預(yù)測即使用焦點損失函數(shù),其中:pt表示對應(yīng)邊框模型的評估概率值,參數(shù)αt=0.25,γ=2。
3.2 N3D_DIOU_loss
在二維圖像中,經(jīng)常使用L1 損失來優(yōu)化IOU 精度,但它不能完全代表網(wǎng)絡(luò)訓(xùn)練時IOU 的精度。對于具有不同IOU 精度的檢測框,可能有相同的L1 損失值。為了解決這個問題,F(xiàn)-Con?vnet 使用corner_loss 正則化三維框回歸。而更直觀的方法則是用IOU 作為損失函數(shù)[26],但如圖4(a)所示當(dāng)目標(biāo)框和檢測框之間沒有交集時,IOU 損失函數(shù)無法進(jìn)行訓(xùn)練。為解決這一問題,文獻(xiàn)[22]提出了 GIOU 損失函數(shù),但如圖 4(b)和(c)所示時,GIOU 損失函數(shù)在水平或垂直情況下退化為IOU 損失函數(shù),也存在無法較好收斂的風(fēng)險。因此,文獻(xiàn)[23]提出DIOU 損失函數(shù)進(jìn)一步提高訓(xùn)練過程的穩(wěn)定性和優(yōu)化性能,二維圖像中DIOU 損失函數(shù)的原始公式如公式(3)所示。
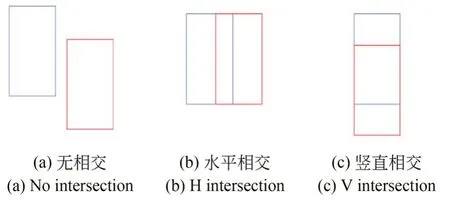
圖4 三個檢測框和目標(biāo)框之間的位置關(guān)系Fig.4 Relationship between three detection boxes and target boxes
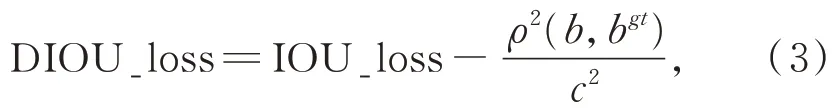
其中:ρ是檢測框中心點b與目標(biāo)框中心點bgt之間的距離,c是最小邊界框的對角線距離。
三維框和二維框的IOU 計算并不完全相同,由于三維框存在角度朝向問題,使得三維IOU 的計算更加困難。如圖5 所示,在計算三維目標(biāo)框和檢測框的IOU 時,重疊區(qū)域的計算更加復(fù)雜[27]。 為 此 ,本 文 提 出 了 下 面 的 N3D_DI?OU_loss 損失函數(shù):

圖5 存在角度偏差的目標(biāo)框與檢測框Fig.5 Target box and detection box with angle deviation
(1)將檢測框和目標(biāo)框旋轉(zhuǎn)并與坐標(biāo)軸對齊,利用max 和min 函數(shù)計算兩框的所有交點,并將這個過程定義為檢測框的正則化;
(2)三維DIOU 的計算退化為二維難度;
(3)對于角度,首先將其離散化,然后用L1損失函數(shù)監(jiān)督角度偏差,最后與正則化的三維DIOU 組合成多任務(wù)損失函數(shù)。由此簡化了三維DIOU 的計算,N3D_DIOU_loss 的偽代碼如算法1 所示。
算法1 N3D_DIOU_loss 偽代碼

4 實驗與分析
為了驗證算法的有效性,在公開的KITTI 數(shù)據(jù)集上進(jìn)行了實驗驗證,該數(shù)據(jù)集包括7 481 幀的訓(xùn)練集和7 518 幀的測試集。由于測試集的標(biāo)簽沒有公開,我們將訓(xùn)練集分為3 712 幀的訓(xùn)練集和3 769 幀的驗證集進(jìn)行網(wǎng)絡(luò)訓(xùn)練和驗證。主要檢測目標(biāo)分為三類,包括車輛,行人和騎自行車的人,數(shù)據(jù)分為簡單、中等和困難難度級別。根據(jù)官方標(biāo)準(zhǔn),當(dāng)IOU 值達(dá)到0.7 時,汽車被認(rèn)為分類正確。對于行人和騎自行車者,由于目標(biāo)較小,IOU 閾值降低為0.5。
4.1 投票模型網(wǎng)絡(luò)參數(shù)設(shè)置
投票模型生成的特征圖大小為f1=L·d/4,f2=L·d/4,f3=L·d/2,f4=L·d,其中L表示采樣點數(shù),d表示特征大小。為便于特征圖融合,對于汽車,L設(shè)置為 280,d設(shè)置為 512;對于行人和騎自行車的人,L設(shè)為 700,d仍是 512。投票模型網(wǎng)絡(luò)生成的中心點數(shù)量設(shè)置為[32,64,64,128],汽車的聚類距離設(shè)置為[0.25,0.5,1.0,2.0],行人和騎車人的聚類距離設(shè)置為[0.1,0.2,0.4,0.8]。
4.2 網(wǎng)絡(luò)訓(xùn)練參數(shù)設(shè)置
對于檢測網(wǎng)絡(luò)的訓(xùn)練,初始學(xué)習(xí)率設(shè)定為0.000 1,隨著訓(xùn)練epoch 的增加逐漸衰減到0.000 001,總 epoch 設(shè)置為 80。另外,使用 Adam優(yōu)化器進(jìn)行訓(xùn)練,優(yōu)化器的系數(shù)為0.000 1。整個訓(xùn)練過程是在兩個NVIDIA TITAN X GPU上進(jìn)行的多GPU 訓(xùn)練,批量batch 為32。整個訓(xùn)練過程大約需要6 個小時。
4.3 基于KITTI 數(shù)據(jù)集的實驗對比
為了驗證本文算法的有效性,表1 給出了KITTI 數(shù) 據(jù) 集 上 本 文 算 法 與 經(jīng) 典 的 MV3D[1],ContFusion[28],VoxelNet[16],F(xiàn)-Convnet[24],IP?OD[29]和 point columns[30],F(xiàn)-PointNet[31]先進(jìn)算法在三維檢測精度上的比較。其中,對于汽車的檢測,本文算法在各個難度上都優(yōu)于上述各算法,在典型的簡單難度下,本文算法較上述算法中表現(xiàn)最好的提升0.71%。對于行人的檢測,檢測效果隨著難度的增加而下降,在簡單難度下較上述算法中表現(xiàn)最好的提升了0.37%。
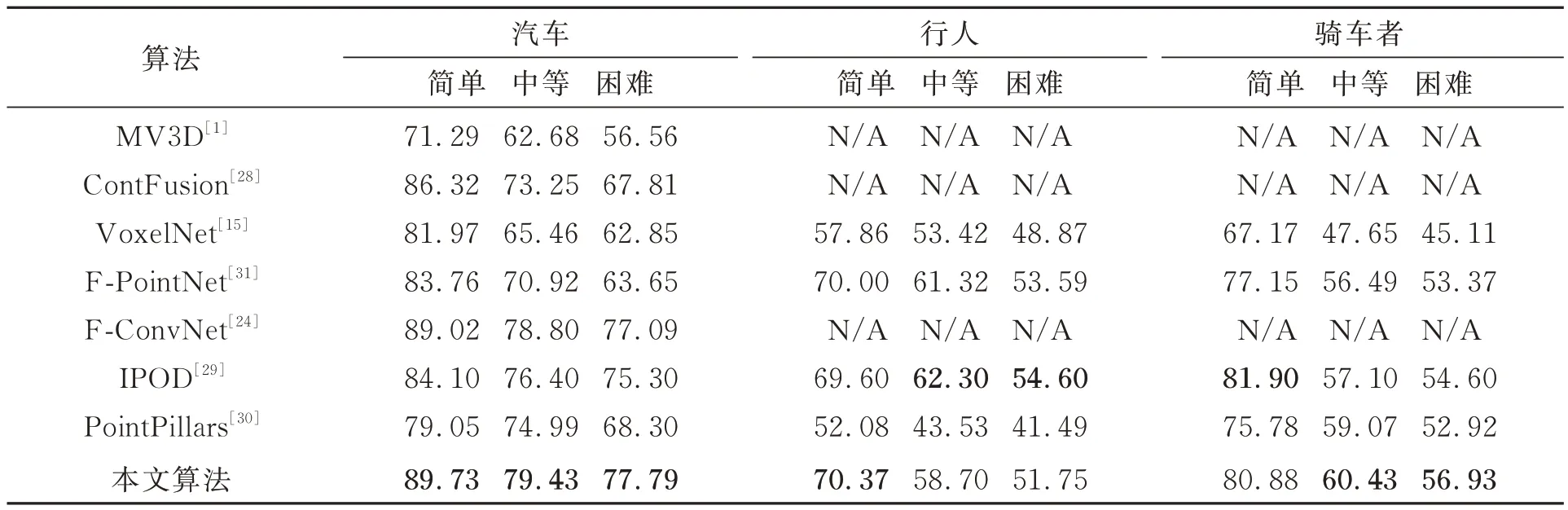
表1 KITTI 驗證集汽車、行人與騎車者三維檢測結(jié)果Tab.1 3D detection AP(%)of cars,pedestrians and cyclists on KITTI val set
除了三維檢測精度之外,表2 列出了本文算法與各個算法在俯視圖(BEV)檢測中的比較。應(yīng)用N3D_DIOU_loss 損失函數(shù),檢測框和目標(biāo)框之間的重合度相對較高,因此BEV 檢測精度提升較大。其中,汽車在典型的簡單難度下較上述算法中表現(xiàn)最好的提升了2.07%,而行人在簡單難度下提升了0.19%;對于騎車者,本文算法均達(dá)到了最好效果,在簡單、中等與困難難度下分別提升了1.91%,3.41% 與2.88%。由于行人與騎車者體積小更難于識別,所有算法在檢測精度上均低于汽車,但本文算法性能仍與表中最優(yōu)算法相近并在大部分情況下有所提升。
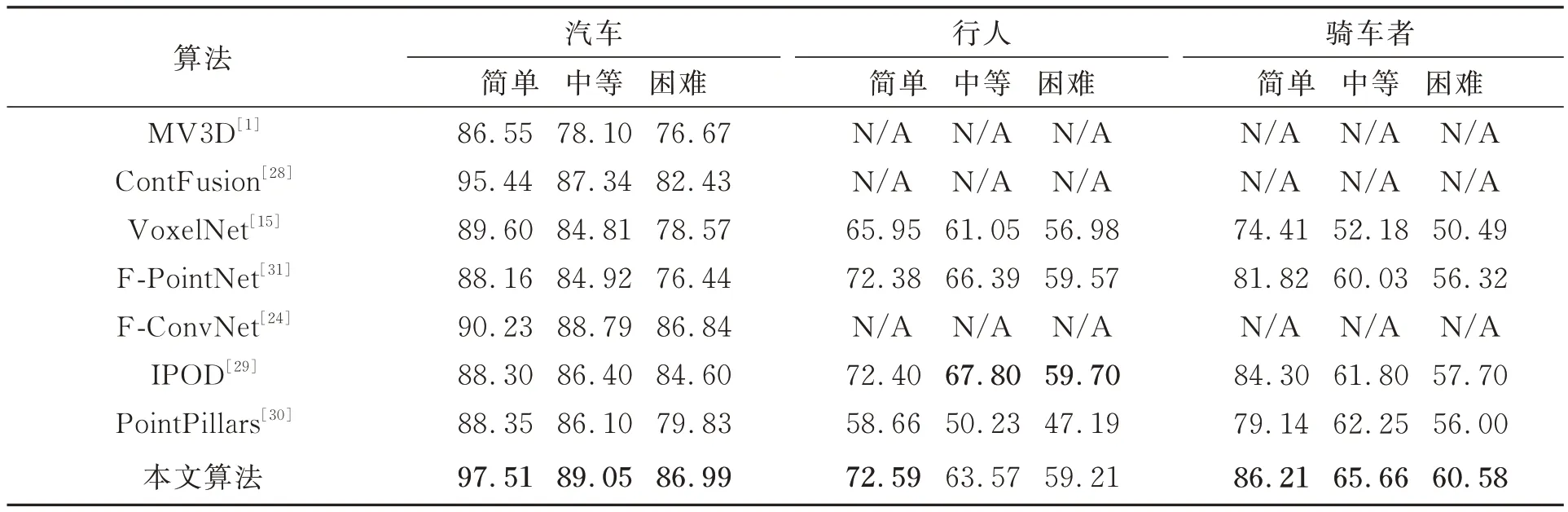
表2 KITTI 驗證集汽車、行人與騎車者BEV 檢測結(jié)果Tab.2 BEV detection AP(%)of cars,pedestrians and cyclists on KITTI val set
由于正負(fù)樣本的不平衡,檢測的召回率是算法性能重要的考慮指標(biāo)。圖6 顯示了汽車、行人和騎自行車者的三維檢測精度(Precision)隨召回率(Recall)的變化曲線。從曲線可以看出,在召回率達(dá)到60%的情況下,各監(jiān)測項均能實現(xiàn)超過60%的監(jiān)測精度,其中,汽車表現(xiàn)最優(yōu),在召回率達(dá)到80%的情況下檢測精度仍能超過80%,這表明了算法對于目標(biāo)檢測任務(wù)的有效性。

圖6 汽車、行人和騎自行車者的三維檢測精度和召回率曲線Fig.6 3D detection AP and recall curves for cars,pedestrians and cyclists
圖7 和圖8 顯示了KITTI 數(shù)據(jù)集上部分目標(biāo)檢測的可視化結(jié)果,包括汽車、行人和騎自行車者的檢測結(jié)果。其中,綠色框代表目標(biāo)框,紅色框代表檢測框,包括二維圖像中的二維框(左側(cè))和三維點云中的三維框(右側(cè))。圖7 中,在密集和稀疏點云中都能成功檢測到汽車,表明該網(wǎng)絡(luò)對點云的不均勻分布有很強(qiáng)的適應(yīng)性。另外,圖7(b)中遠(yuǎn)處遮擋嚴(yán)重、點云較少的車也能成功檢測出來。結(jié)果表明,該網(wǎng)絡(luò)對汽車具有良好的檢測效果。圖8 中,行人和騎車者的檢測性能較汽車差,圖8(a)中最前面的行人沒有被檢測出來,這是因為訓(xùn)練集中騎車者和行人相對較少導(dǎo)致網(wǎng)絡(luò)訓(xùn)練不足。另外,騎車者和行人的特征相似導(dǎo)致的誤判也降低了檢測精度。

圖7 汽車檢測結(jié)果可視化Fig.7 Visualization results of cars
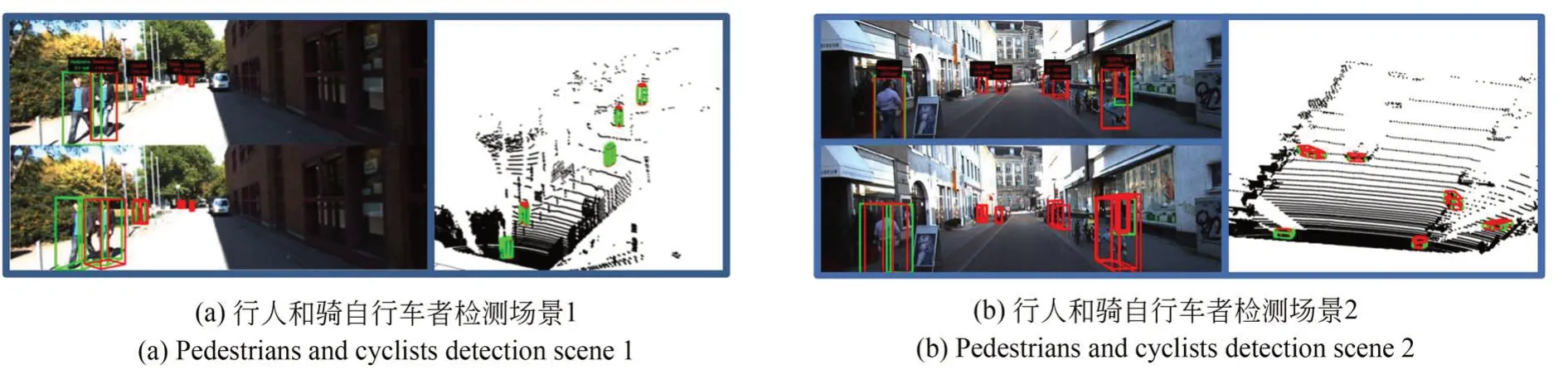
圖8 行人和騎自行車者檢測結(jié)果可視化Fig.8 Visualization results of pedestrians and cyclists
4.4 消融試驗
為了證明N3_DIOU_loss 和投票模型的有效性,以 F-ConvNet[24]為基準(zhǔn),增加了兩個網(wǎng)絡(luò)層在汽車目標(biāo)上進(jìn)行相關(guān)的消融實驗,結(jié)果如表 3~4 所示。表3 表明 N3D_DIOU_loss 和改進(jìn)的投票模型在精度的提高上具有顯著的作用。在3D 目標(biāo)檢測中,與傳統(tǒng)F-ConvNet 相比,改進(jìn)的投票模型可以有效地過濾并聚類點云,提高了0.21%的檢測精度;N3D_DIOU_loss 可以提高目標(biāo)框與檢測框之間的重合度,進(jìn)一步提升0.11%的檢測精度,兩者結(jié)合可以提升0.71%的檢測精度。表4 的結(jié)果證實網(wǎng)絡(luò)模型參數(shù)的微調(diào)可以對消融實驗中各種結(jié)構(gòu)的檢測網(wǎng)絡(luò)帶來精度的提升。

表3 三維及BEV 檢測對比Tab.3 3D and BEV detection performance

表4 參數(shù)微調(diào)實驗對比Tab.4 Comparison of parameter tuning experiments
5 結(jié) 論
針對三維點云識別計算量大、準(zhǔn)確率低的特點,本文提出了一種融合二維圖像與三維點云特征的目標(biāo)檢測網(wǎng)絡(luò)用于三維目標(biāo)檢測。論文首先利用二維圖像目標(biāo)檢測框?qū)?yīng)的平截頭體限定點云的處理范圍,然后提出改進(jìn)的投票模型用于多尺度特征提取,并通過構(gòu)造了包含分類損失函數(shù)與三維DIOU 損失函數(shù)N3D_DI?OU_loss 的多任務(wù)損失函數(shù)優(yōu)化了網(wǎng)絡(luò)訓(xùn)練過程及檢測精度。KITTI 數(shù)據(jù)集上的識別結(jié)果及消融實驗表明,本文算法提出的投票模型與N3D_DIOU_loss 對目標(biāo)檢測網(wǎng)絡(luò)精度提升起到了重要作用,在三維檢測精度上較F-ConvNet算法提高了0.71%,在BEV 檢測精度上則提高了7.28%。
猜你喜歡
中國設(shè)備工程(2022年12期)2022-07-11 04:33:00
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年9期)2019-11-25 07:34:36
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年9期)2019-11-25 07:34:34
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年12期)2019-05-21 02:53:50
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年12期)2019-05-21 02:53:48
