基于改進AP 選擇的融合隨機森林室內定位算法
2021-12-14 08:32:06牟平凌銘胡銳
全球定位系統 2021年5期
牟平,凌銘,胡銳
( 上海工程技術大學 電子電氣工程學院,上海 201620 )
0 引 言
隨著無線局域網(WLAN)、云計算、智能終端以及傳感器的普及與高速發展,對位置信息的需求正在不斷增加. 位置信息的需求推動了基于位置服務(LBS)的高速發展,而定位技術是LBS 的核心. 目前室外定位采用全球衛星導航系統(GNSS),包括GPS和我國的北斗衛星導航系統(BDS)等,定位方法相對完善. 然而,室內GNSS 衛星信號弱或者根本無信號,導致室內無法利用GNSS 衛星信號進行正常定位. 特別是一些公共區域,如大型商場、地下停車場、大型圖書館都需要較為精確的位置服務[1],因此,對于室內定位精度的需求變得日益迫切.
自2000 年起,利用無線保真(Wi-Fi)位置指紋進行室內定位的概念被美國微軟研究院率先提出,同時推出室內定位系統Radar[2],由于Wi-Fi 的普及程度比超寬帶(UWB)和一些無線射頻識別(RFID)更為廣泛且定位過程中無需部署[3],所以近年來許多學者不斷研究如何在現有的指紋匹配定位模型上改進已有算法來提升定位精度以及定位性能,影響模型定位精度的關鍵因素之一是接收信號強度(RSS). 文獻[4]提出接入點(AP)選擇法融合K最近鄰算法(KNN)來進行室內定位,其融合效果比傳統KNN 精度上有較大地提升,但在實際定位過程中由于數據量較大,利用KNN 時間復雜度將會提升,同時也會帶來定位精度的下降. 文獻[5]利用每個AP 在參考點的分組定位和加權質心算法相結合,多方位測距減小誤差,以降低RSS 變化帶來的影響. 文獻[6]提出優化的隨機森林(RF),引入伯努利分布來減少選取訓練集中的冗余特征,使得弱分類器之間的隨機性和多樣性降低.
基于此,本文提出穩定性優先的AP 選擇方案來降低RSS 變化帶來指紋向量維度和值不同的影響,這樣能夠保證離線數據庫中的每個可用的AP 都是在定位過程中起重要作用的AP,同時融合集成學習中隨機森林的多個弱分類器來提高定位精度并減少定位時間,從而增加定位效率.
1 室內定位整體流程
本文采用Wi-Fi 位置指紋來進行室內定位,主要可分為離線階段和在線階段[7]. 離線階段需要移動終端獲取待定位區域的RSS 信號值,并對定位區域進行合理的網格劃分,將搜集到的RSS 數據發送至后臺,形成初步的指紋數據庫. 在后臺對初步指紋數據庫進行AP 選擇,選擇重要的AP,這里的重要AP 是指這些AP 的RSS 信號有利于定位,比如與地理位置的映射最為明顯、位置分辨能力最高、樣本波動小等,然后將所得指紋數據庫作為訓練集輸入到RF 訓練模型中[8];在線定位階段移動終端將搜集到的RSS 信息,根據離線階段所選擇出有用的AP,過濾掉在線搜集到的那些來源于其他AP 的RSS 信號,然后將過濾過后的信號發送至后臺進入訓練好的RF模型中得出最終的位置,其中介質訪問控制(MAC)為每個AP 的唯一標識. 圖1 為室內定位整體流程.
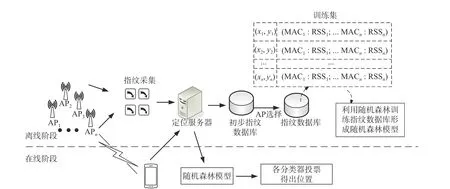
圖1 室內定位整體流程
2 改進的AP 選擇算法
2.1 AP 選擇的基本理論
在基于指紋的無線室內定位中,定位的精度受RSS 信號的嚴重影響,并且處于不斷波動的狀態. 即使是在同一個位置上接收來自同一個AP 的RSS 信號也有可能隨著環境發生變化. 在復雜的室內環境下,雖然可用的AP 很多,但是有很多AP 是無用的甚至會降低定位精度,因此需要選擇合適的AP 數目來提升定位精度,以確保離線階段數據庫的構建更準確[9].
在離線階段和在線階段均可以執行AP 選擇. 此外,AP 選擇過程可以為所有參考點選擇AP 的統一子集,可以是整個區域或由粗略定位選擇的子集,被稱為統一AP 選擇. 相反,基于參考點的選擇方法單獨為每個參考點選擇一組AP. 這樣,每個參考點可以包含與其他AP 不同的AP 集合[10]. 本文考慮改進離線階段的統一AP 選擇,利用AP 穩定性優先來衡量AP 質量,同時對于AP 選擇定義如下:對于定位區域中AP 集合P={P1,P2,···,Pn} ,我們需要找到其中的一個子集P′使得在該子集上完成定位的精度最高,即
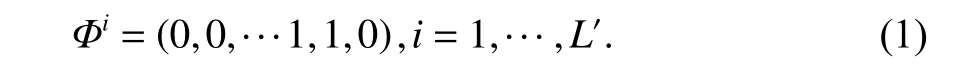
式中:Φi為除選定的AP 索引之外的所有索引歸零來定義所選AP;L′為子集P′的基數;Φ為選擇矩陣用來選擇眾多AP 中有用的AP.
2.2 改進的AP 選擇算法
傳統的基于信息增益(IG) AP 選擇算法[11],雖然考慮到AP 之間的相關性,但是并沒有考慮AP 的RSS 樣本數據的穩定性.因此,本文提出一種基于穩定性優先的AP 選擇算法,其中穩定性包含:每個AP的RSS 樣本的方差;在同一位置下AP 所出現的頻率.
在定位區域中,同一位置采集到來自同一AP 的RSS 樣本可能會隨時間以及環境的變化而變化. 對于參考點L,會接收到來自n個AP 的RSS 信號,AP 集合表示成 {AP1,AP2,···,APn} ,為了使指紋數據庫能更好地反映數據特征和數據維度以及減少在線階段的計算量.本文通過穩定性優先的AP 選擇算法從這n個AP 中選擇出合適的m個AP,主要流程如圖2所示.

圖2 改進AP 算法流程
在采樣點L上接收到第i個AP 的n次采樣數據為 {RSS1,RSS2,···,RSSn} ,于是該AP 的RSS 數據波動幅度可以通過方差計算得到,即

式中,RSS為n次RSS 數據的均值. 此處的n與上述保持一致,每個AP 的RSS 樣本方差實際上就反映了數據波動,同時考慮到方差可能為0,所以加入拉普拉斯平滑引入 ε 以避免方差為0 的情況,與此同時考慮到每個AP 在整個采樣點出現的頻率,結合數據波動與出現的頻率衡量RSS 樣本的穩定性,即
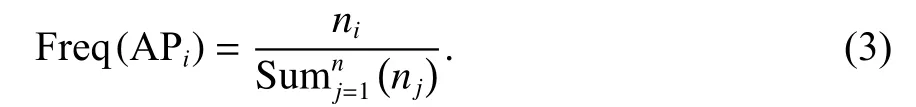

計算出穩定度之后對穩定度進行排序,選擇穩定度最高的前m個AP 用來作為AP 選擇的結果,并以此來構建指紋數據庫,根據對AP 數目對室內定位產生影響的相關研究[12-13],本文選擇AP 數目為5 個.
3 RF 算法
RF[14]模型是在2001 年提出的一種基于決策樹分類的集成學習算法,通過對訓練集進行N次有放回取樣構建基分類器. 在RF 中,訓練集中的樣本就是在離線階段所采集到的一條RSS 數據,其中的特征則是經過AP 選擇后離線數據庫中的每個AP 在采樣點對應的RSS 值,標簽是每個采樣點的位置信息. 隨機抽樣從特征中隨機選取幾個特征,因此基分類器是隨機的,最終N個隨機且彼此獨立的分類器決策樹構成隨機森林,當實時定位階段用戶發來經過篩選的RSS 信號后,進入隨機森林模型中,所有的基分類器產生預測結果,最終投票結果的眾數作為輸出位置.圖3 為隨機森林算法流程.

圖3 RF 算法
RF 算法流程為:
輸入:離線數據庫中的所有樣本和位置標簽作為初始訓練集,記為D.
輸出:對于待測樣本xt,N棵決策樹的輸出,即最終移動終端的.
開始
Fori=1,2,···,Ntree
1) 對初始訓練集D進行隨機抽樣,生成每個分類器的對應的訓練集Si;
2) 使用訓練集Si生成所對應的決策樹Ti,并從每棵決策樹結點上隨機選取最優特征,不斷的分裂樹至樹生長到最大.
在線階段發送經AP 篩選的RSS 信號進入隨機森林模型中得出最后移動終端的位置.
結束
隨機森林分類是指當訓練集的因變量是不連續變量時,此時輸出最終位置用式(5)表示為
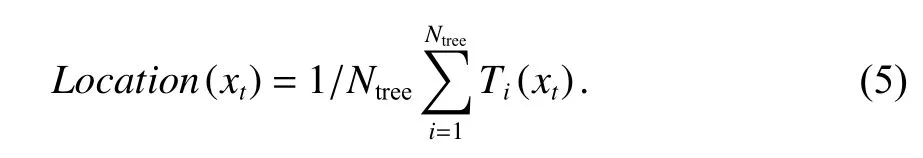
4 實驗驗證與分析
4.1 實驗環境
本文的實驗場地選在上海工程技術大學實訓樓四樓,實驗環境保持不變,測試環境周圍的AP 是利用學校布置的AP 點,不會隨意更改AP 或者加入其他AP. 其中測試區域結構如圖4 所示,信號采集所用的裝置為華為P20,采用的AP 是學校已有的AP,通過自主開發的軟件采集RSS 信息,其中每個網格點大小設置為1.5 m×1.5 m,并在每個網格點東南西北四個方向共采集100 組信號,采集的頻率為1 Hz.
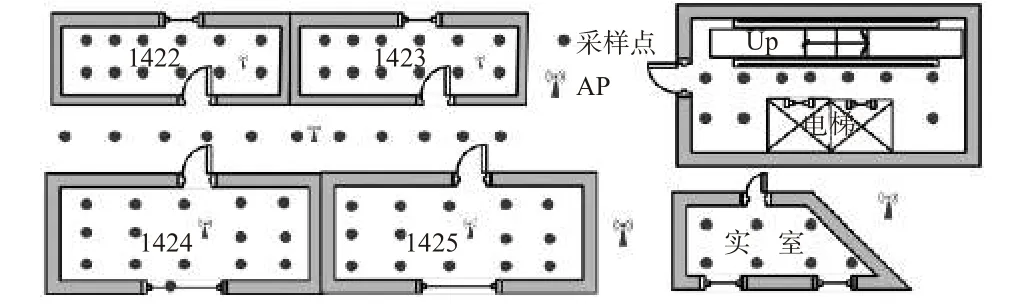
圖4 測試區域結構
實驗中采樣點共有205 個,為將定位結果量化,利用真實值與測量值之間的距離定義為誤差

4.2 實驗結果分析
本文利用改進的AP 選擇方法融合RF 來對位置做出更精確的估計,同時與基于IG 的AP 選擇融合RF,未經AP 選擇的RF 和改進的AP 選擇融合加權的K近鄰算法(WKNN)進行實驗對比. 本實驗中參數設置為:AP 最佳數目選擇為5,RF 分類器個數為500 個,WKNN 的K值選擇為4,對于權重的選擇為歐氏距離的倒數. 實驗所需的部分數據采集如表1所示.
表1 實驗采集的部分RSS 數據dBm
如圖5 所示,為了直觀顯示上述算法在定位誤差上的表現,統計了多組實驗求取平均定位誤差用來衡量算法的好壞. 由圖5 可知,改進的AP 和RF 算法的平均定位誤差為1.26 m,要比IG+RF、RF、改進的AP+WKNN 分別降低17.2%、29.3%、23.2%.
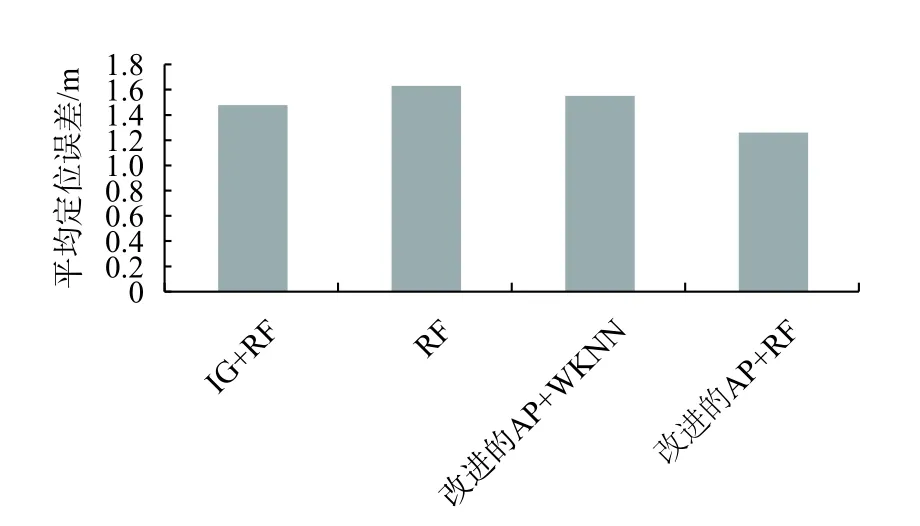
圖5 四種不同算法的平均定位誤差
圖6 為不同定位算法定位誤差的累計概率分布.由圖6 可知,改進的AP 選擇和RF 算法有78%的概率保證定位誤差在1.5 m 以內,90%的概率保證定位誤差在2 m 以內; IG+RF 有60%的概率保證定位誤差在1.5 m 以內,80%的概率定位誤差在2 m 以內;改進的AP+WKNN 有50%的概率定位誤差在1.5 m以內,63%的概率定位誤差在2 m 以內;RF 有42%的概率定位誤差在1.5 m 以內,57%的概率定位誤差控制在2 m 以內. 綜上可知,在定位精度上,本文提出的算法與其余三種算法相比有明顯提升.
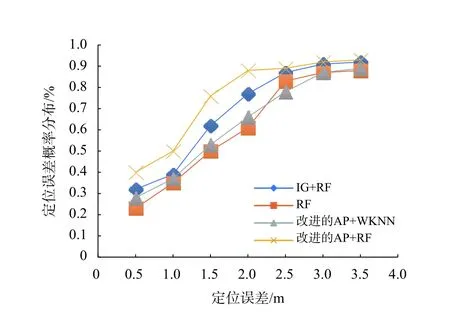
圖6 各種算法的定位誤差累積概率分布
由于RF 在離線階段需要訓練出RF 模型,所以需要一些時間,但定位系統實時性衡量的是在線定位階段是否能實時反映移動終端的位置信息. 因此,本文考慮的是在線定位階段上述算法的定位時間. 如圖7 所示,以6 個待定位點為例,展示上述算法在在線定位階段的定位時間. 驗證算法從圖7 可以看出,改進的AP+RF 的定位時間平均0.98 s,對于改進的AP+WKNN 而言數據量大的情況下,需要在線定位階段遍歷數據庫進行比對,通過統計100 組實驗下的平均定位時間分析可知,其定位時間比改進的AP+RF 長;由于RF 未經AP 選擇所以數據庫中包含有大量對定位結果無用甚至有害的AP,所以導致在線定位時間平均在1.3 s;IG+RF 算法利用信息增益最大化選擇AP 考慮到了AP 之間的相關性,但并未考慮數據穩定性,其中會存在一些不穩定AP 加大在線定位階段的計算量,導致定位時間平均在1.15 s.
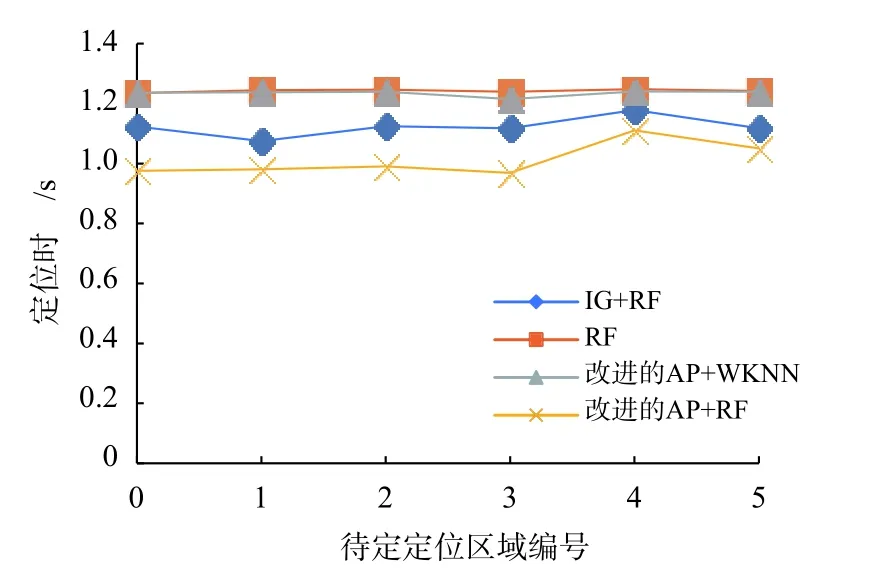
圖7 各個算法的定位時間
5 結束語
本文提出了改進的AP 選擇融合RF 的算法. 首先對初始指紋數據庫進行AP 選擇,根據每個AP 的RSS 樣本的穩定度來選取前5 個AP 作為定位AP,然后將處理好的指紋數據庫作為數據集進行RF 的訓練,形成RF 模型. 在在線定位階段通過離線階段已經選好的5 個AP 對RSS 數據篩選,然后經過RF模型投票得出最后的結果. 實驗結果表明:本文提出的算法在定位誤差以及定位時間方面優于其他算法,且改進AP+RF 的平均定位誤差穩定在1.26 m,在線定位時間平均也只有0.98 s;在Wi-Fi 室內定位中一定程度地減小了定位誤差和降低定位時間,在室內定位技術中有一定的意義.
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
中國生殖健康(2019年3期)2019-02-01 06:12:26
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
財經(2016年6期)2016-02-24 07:41:51
海軍航空大學學報(2015年3期)2015-11-11 17:20:00
