隨機森林算法在氣象與空氣質量分析中的應用★
2021-12-13 07:23:20邵凱旋吳映涵
山西建筑 2021年24期
關鍵詞:模型
邵凱旋,吳映涵,梅 鋼
(中國地質大學(北京),北京 100083)
1 概述
近年來,隨著經濟的高速發展和人民生活質量的不斷上升,社會對空氣質量的關注度日益增高。空氣質量是健康和生活的重要影響因素之一。局部環境空氣質量除了受局地大氣污染物排放的直接影響,也受局地氣象要素及氣候變化的影響。有研究表明,在污染源排放相對穩定的條件下,氣象條件對空氣質量起主導作用。研究氣象要素與大氣污染物的關系,并將氣候變化與其結合起來,預測未來各氣象要素變化對各大氣污染物的潛在影響,對我國節能減排政策的制定具有一定的指導意義。對同一地區而言,由于天氣狀況等自然條件的不斷改變極其他因素的影響,在同一地點對同一來源的污染物的監測結果也可能出現很大差異。北京作為我國首都,在國家發展中扮演著極其重要的角色,其空氣質量問題也常常受到全國人民的普遍關注。
機器學習是一種數據分析的方法,作為人工智能的一個分支,它可以自動化構建分析模型。它的理念是,系統僅需要最小的人工干預就可以從數據中學習,識別模式并且做出決策。機器學習的種類有很多,隨機森林便是一種非常簡便且易于使用的算法。作為一種監督學習算法,隨機森林具有很強的抗干擾能力,可用于許多不同的領域。它能夠處理具有很多特征的高維度數據,并在大多數情況下避免了過擬合問題,近年來越來越多地應用于人們日常生活的各個方面。隨機森林可以用多種編程語言實現。Julia作為一種新興的編程語言,擁有著簡潔的語法,優良的運行速度,強大的元編程能力,可以輕松使用Python,R,C/C++和Java多種語言中的庫,極大地擴展了Julia語言的使用范圍。除此之外,它還可以調用其他許多成熟的高性能基礎代碼。與其他編程語言相比,Julia非常易用,可以大幅減少需要寫的代碼行數,并有著更豐富的工具包和庫等,它不僅解決了許多傳統編程語言問題,還為機器學習和人工智能提供了強大的深度學習工具。
在世界范圍內的許多國家環境問題越來越受到政府和公民的重視,國內外的許多學者都對空氣質量的預測問題進行了多方面的分析與研究。周兆媛等[1]使用主成分分析的方法將多個氣象要素簡化為兩個主成分并進行線性回歸分析,根據回歸系數得到了氣象要素與空氣質量的相關關系;祁曉雨等[2]使用數據分析和挖掘的方法對北京六種大氣污染物濃度和五種氣象因子的數據集進行分析,通過擬合發現相較于單一氣象因子,多種氣象因子組合對大氣污染物濃度的影響更加顯著,并分析了相同的氣象因子對不同污染物的不同影響;任才溶等[3]在構建基于氣象參數的隨機森林預測模型時使用K-Means算法對訓練樣本進行聚類,對不同的聚類使用不同的分類模型,將每個模型的結果匯總得到最終的PM2.5等級預測結果;Efnan等[4]通過從空氣質量數據中提取統計特征并將其輸入線性和非線性分類器,提出了一種適用于大范圍地理區域的空氣質量預測模型;Paulo等[5]提出了一種基于隨機游走的時間序列預測體系,在不依托于其他外部信息的條件下,僅用過去的污染物濃度變化預測未來的污染物濃度;此外,神經網絡也是用于空氣質量預測的常見方法之一,鮑慧[6]等使用遺傳算法對BP神經網絡進行優化,通過研究往年空氣污染物濃度的變化規律,建立基于時間序列的網絡模型,得到了較好的預測結果,但神經網絡結構的設置缺乏一定的理論依據,且搜索過程具有一定的隨機性,無法確保最優解的得出。
在上述研究和分析中,國內外學者采用神經網絡、數據挖掘、隨機森林等多種方法對空氣質量預測問題進行了研究,但也存在著統計分析方法較單一、因子選擇具有一定的主觀性和隨機性、多重因素綜合作用的影響考慮不足等問題。本文采用準確度高、針對性強、綜合多因素的隨機森林算法對空氣質量預測問題進行了研究。在對空氣質量和氣象條件之間的關系進行研究的基礎上,本文選擇合適的特征作為依據,使用Julia語言建立隨機森林預測模型,借助易于得到的實時氣象條件數據,通過算法得到空氣質量相關數據,在應用程序進行預測的同時,本文對預測準確度與節點特征和決策樹數目的關系進行了研究,在對兩個參數進行調整后得到了較好的預測結果,對得到更加客觀準確的空氣質量及空氣質量的預測有較為重要的意義。
2 材料與方法
2.1 數據來源
本文所采用的數據為2017年1月至2018年1月北京市朝陽區奧體中心空氣質量監測站的實時空氣質量監測數據及其對應的氣象條件數據。其中,空氣質量數據包括該監測站點測得的PM2.5,PM10,NO2,CO,O3,SO2每小時內的濃度值;氣象條件數據包括該地區每小時內的氣溫、氣壓、濕度、風向、風速及天氣狀況。在本文中,為便于研究空氣質量與天氣狀況之間的聯系,以如下關系表示不同的天氣狀況:1=“Sunny/clear”;2=“Rain”;3=“Fog”;4=“Haze”;5=“Snow”;6=“Dust”;7=“Sand”。
北京市朝陽區空氣質量監測站和氣象站位置見圖1。
2.2 空氣質量評價等級
在日常生活中,人們通常習慣于根據大氣污染物的濃度對空氣質量的優劣進行評價,并將其劃分為優、良、輕度污染、中度污染、重度污染、嚴重污染等多個等級。根據我國發布的空氣質量指數的評級規定[7],本文根據表1所示的空氣質量指數及對應各項污染物濃度的參考值,將空氣質量數據的具體數值劃分為6個等級,并以字母A~字母F表示,用以代表各項污染物的嚴重程度,從而通過分類提高使用隨機森林對空氣質量進行預測的實用性和可操作性。
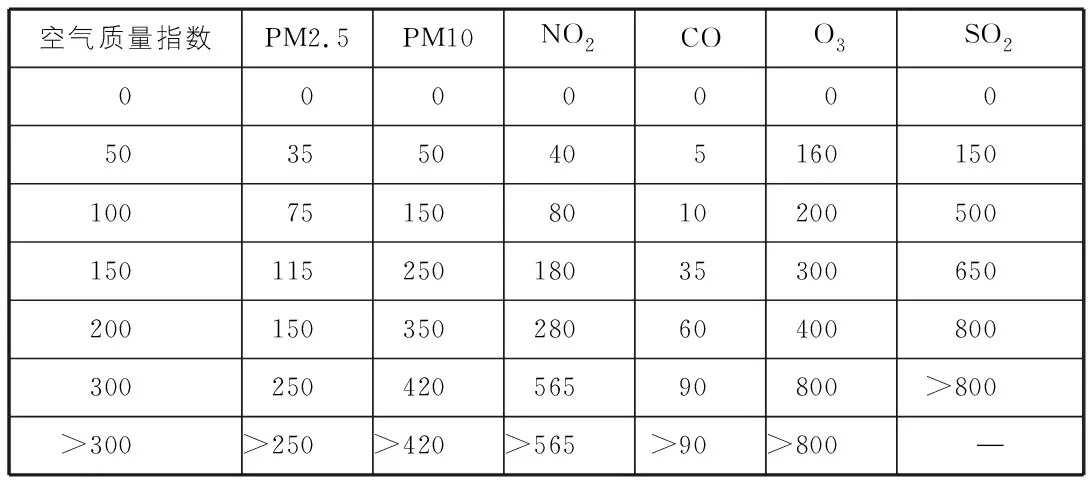
表1 空氣質量指數及各項污染物質量濃度參照表 μg/m3
2.3 分析方法
本文采用基于Julia語言的隨機森林算法對空氣質量預測問題進行研究。在對數據進行簡單處理的基礎上,本文通過空氣質量與時間因子和氣象條件的相關性的分析對特征因子的選擇進行了探究,并將選擇出的適當的特征因子作為參數輸入到隨機森林模型中進行空氣質量預測的應用研究。在隨機森林中,每一個決策樹的“種植”和“生長”都大致包含以下幾個步驟:
1)假設原始訓練集中的樣本個數為N,然后通過有放回地重復多次抽樣獲得這N個樣本,這樣的抽樣結果將作為我們生成決策樹的訓練集。
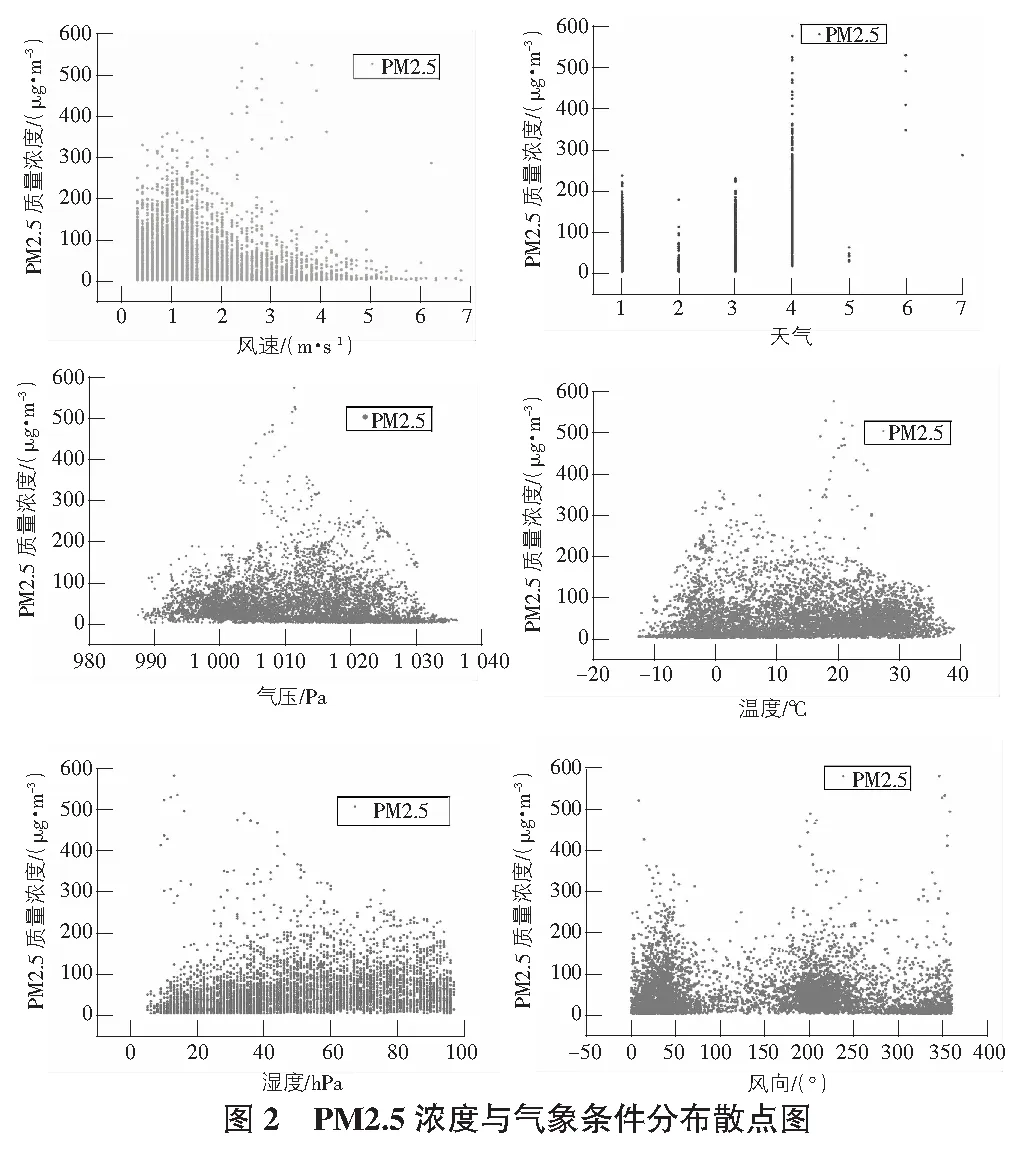
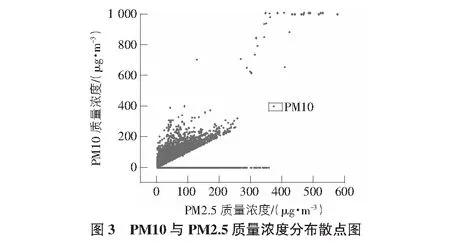
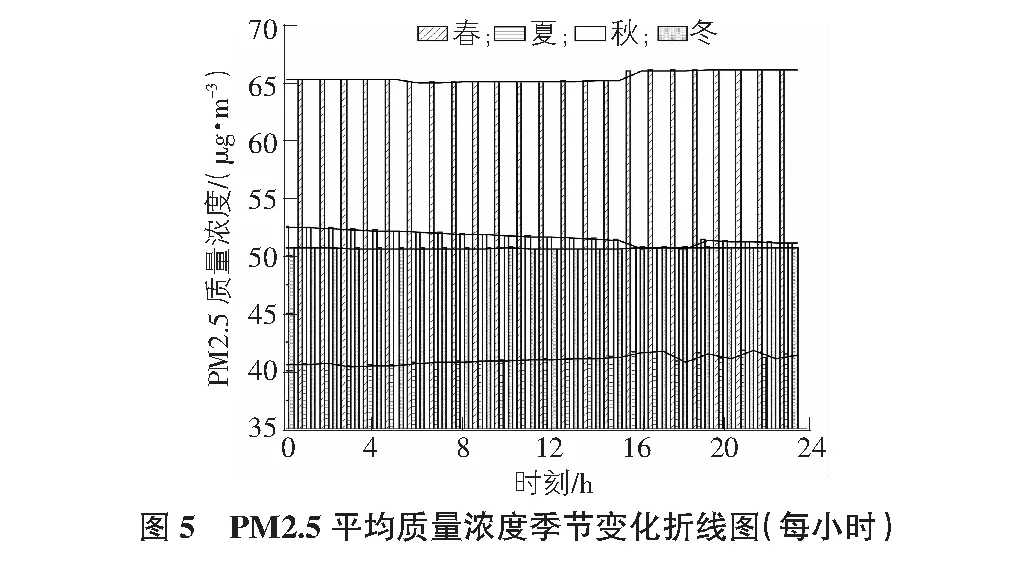
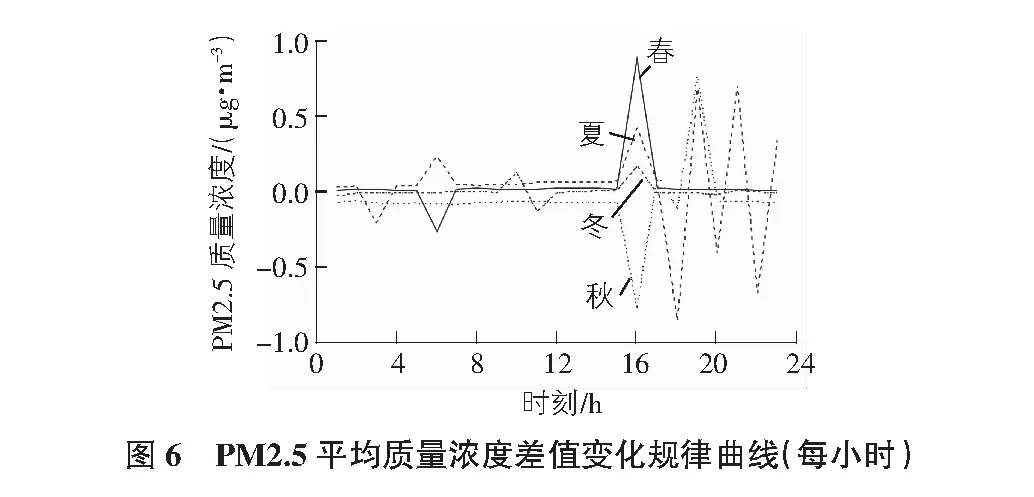
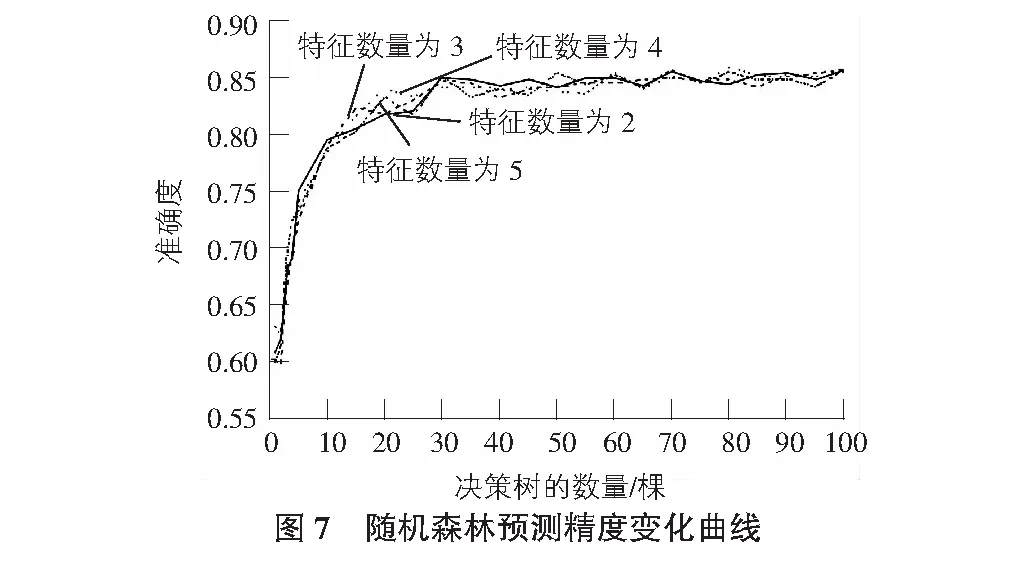
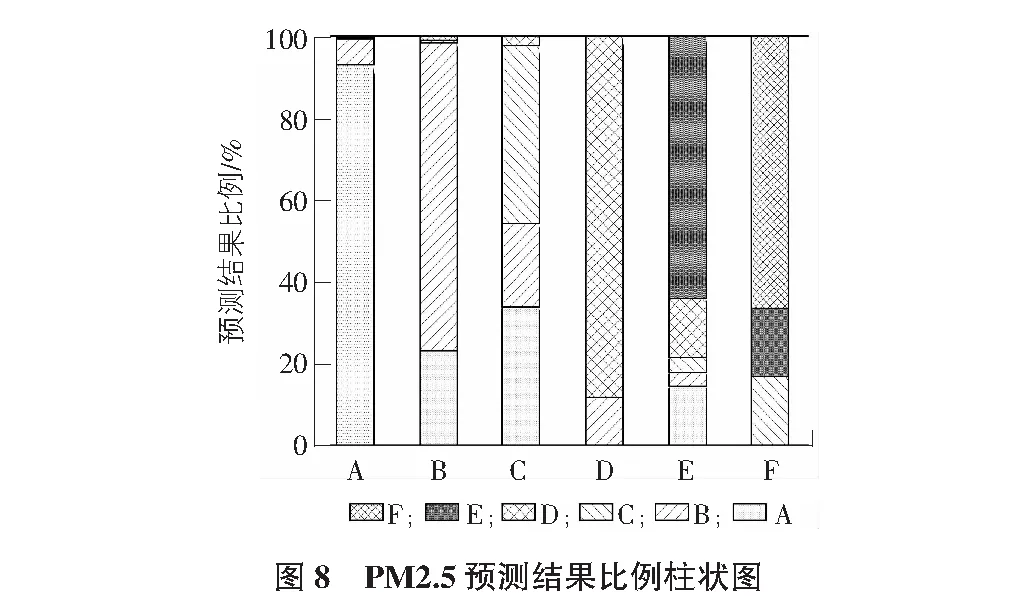
2)設有M個輸入變量,在每一棵樹每個節點都將隨機抽取m(m 3)每棵決策樹都最大限度地生長且不進行任何修剪。 4)將生成的多棵分類樹組成隨機森林來預測新的數據(在分類時采用多數投票,在回歸時采用平均)。 在應用程序進行預測的同時,本文對預測準確度與節點特征和決策樹數目的關系進行了研究,并對其預測結果進行了分析討論。 在本節中,本文首先對大氣污染物與各氣象條件和時間因子的相關性進行了分析,之后采用選擇出的特征值對隨機森林預測模型進行了訓練,最后應用經訓練的模型進行預測并對預測結果準確度進行了分析。 3.1.1 氣象因子的相關性分析 在人們通常的認識中,陰雨天氣往往比晴朗天氣更容易出現空氣污染較為嚴重的情況。顯然,空氣質量與氣象條件之間確實存在著一定的聯系,某些氣象條件可能會在污染物的流通擴散等過程中發揮著復雜而顯著的作用[8]。然而,衡量某地區氣象條件的內容通常是復雜多樣的。使用隨機森林方法進行預測的主要工作原理是在構建和應用隨機森林預測模型之前,如果不對空氣質量和氣象條件之間內在聯系進行分析并得出基本的認識,直接進行計算可能會帶有一定的主觀性和偶然性。因此,本文對大氣污染物與各氣象條件進行了相關性分析,從而幫助評價和修改預測模型。 以PM2.5與氣溫、風速等各氣象條件之間的相關性分析為例,表2給出了使用SPSS求得的PM2.5與各氣象條件之間相關系數的具體數值,圖2為根據PM2.5與各氣象條件數據繪制的散點圖。通過圖表并結合Pearman相關系數的計算可以看出,除天氣狀況以外,PM2.5與各氣象條件之間并無明顯的線性相關關系。 表2 PM2.5與各氣象因子相關系數表 結合Spearman相關系數進行分析,可見氣象因子與濕度和天氣狀況之間存在相對明顯的正相關關系,而與風速之間存在相對明顯的負相關關系。據此可以推斷較大的風速在一定程度上有利于PM2.5的擴散,從而使其觀測值降低;而濕度較大時,空氣中含量較高的水蒸氣可能有利于PM2.5的凝結,且水蒸氣的存在可能造成PM2.5的觀測值偏大的誤差。同時,天氣狀況在很多方面與PM2.5的擴散和沉積等過程有著密切聯系[9-10]。雖然相關系數顯示風向與PM2.5濃度相關性很低,但結合散點圖可以明顯看出PM2.5濃度較高值均大致集中在三個方向,可推斷該結果是在對應方向的上風向上存在排放量較大的企業或更密集的交通網等因素的影響下造成的。 此外,相關系數計算顯示出PM2.5與溫度之間存在著一定的正相關關系。而在其他研究中,北方地區在冬季往往處于采暖季,且由于氣溫較低往往容易出現逆溫層,對PM2.5的擴散產生不利影響。這與其研究結果和日常生活中溫度回暖,空氣質量狀況與供暖季相比有所改觀的認識存在著一定的差異。通過對PM2.5變化的具體時間段進行分析可以看出,其年度峰值出現在五一小長假期間,在假期末尾PM2.5升高尤為明顯,可推斷由于假期出行及返程等因素的影響下,出現了溫度較高時PM2.5濃度也存在明顯升高的現象。此外,本文數據主要來源于奧體中心空氣質量監測站,反映空氣質量變化的地區范圍有限,也在一定程度上影響了此處結果的出現。 通過對PM2.5與其他大氣污染物之間的相關性進行分析(見表3),可以看出PM2.5在很大程度上與其他大氣污染物存在著一定的相關性,PM2.5與各氣象條件的相關性分析對其他大氣污染物的分析而言同樣具有一定的參考價值,進而幫助選擇合適的因子用于預測并對模型進行評價和改進(見圖3)。 表3 PM2.5與其他大氣污染物相關系數表 3.1.2 時間因子的相關性分析 在應用氣象條件對空氣質量進行預測的過程中,考慮到氣象條件在時間上往往存在一定的周期變化規律,本文同樣對大氣污染物與時間或季節的相關性進行了研究。以PM2.5為例,其一年內的觀測數據與不同季節一天中的觀測數據隨時間的變化曲線如圖4~圖6所示。 由圖4~圖6可以看出,PM2.5濃度與時間具有較為明顯的相關性,其按季節劃分的變化規律較為明顯。其中,PM2.5在1 d內各時刻平均濃度的季節性差異較大,在該站點的觀測數據中,春季平均濃度最高,夏季平均濃度最低。而在1 d中的某些時刻,不同季節PM2.5濃度變化值的大小具有較明顯的同步改變現象。例如,在15:00~16:00這一時間段內,秋、冬、春三個季節的PM2.5濃度均存在明顯升高,夏季PM2.5濃度存在明顯降低。PM2.5濃度值不僅與季節和月份有關,在同一天的不同時段同樣存在著一定變化規律。 通過以上分析可以看出,大氣污染物濃度與時間之間同樣具有較為明顯的相關性。為了得到更加準確的預測結果,本文在應用氣象因子預測空氣質量的過程中同樣將時間因子作為預測的參考特征之一納入了考慮范圍,從而進一步提高預測結果的可靠性。 3.2.1 數據準備 在對數據進行分析之前的數據收集階段,盡管數據集已經被進行初步處理,但在分析的過程中依然存在很多問題。例如,在進行相關性分析時得到的圖2中可以明顯看到,在龐大繁雜的數據中,大氣污染物濃度較高的數據只占很小的一部分。目前現有的學習算法一般建立在各類數據數量相差不大的前提下。而在本文的數據集中,空氣質量較好的數據和較差的數據所占比例很不平衡,這便導致了在隨機森林學習和訓練的過程中,在空氣質量較好的方面能夠搜集到的數據和規律要比空氣質量較差的大的多,這便導致了在應用隨機森林進行預測的過程中,得到的結果更容易偏向于空氣質量較好的等級。數據集中不同等級的空氣質量數據分布不均勻使預測結果產生了一定的誤差。目前解決這類問題的主要方法有欠采樣方法(undersampling)、過采樣方法(Oversampling)及組合方法(Combination)等。本文采用過采樣方法,通過復制或內插的方式,將人工合成的樣本整合到原始樣本中,從而提高空氣質量較差數據的樣本容量,改善數據類別不平衡帶來的影響。 3.2.2 模型構建 根據空氣質量與氣象因子和時間因子的相關性分析,本文不放回地隨機選擇經過欠采樣后的2017年1月~2018年1月北京市朝陽區奧體中心空氣質量監測站的實時空氣質量監測數據及其對應的氣象條件的部分數據作為測試集,并將其余數據作為訓練集,選擇氣溫、氣壓、濕度、風向、風速、時間及天氣狀況作為特征值,并將其對應的空氣質量等級輸入模型進行訓練,按照“特征數量(number of features)=2、決策樹的數量(number of trees)=15、分段抽樣比例(ratio of subsampling)=0.5”的初始參數構建隨機森林。 3.2.3 模型應用 將測試集中的氣象條件數據輸入經過訓練的隨機森林預測模型之后,各項空氣污染物指標預測的準確率如表4所示。 表4 大氣污染物預測結果準確率表 在對隨機森林進行訓練的過程中,每次節點隨機分割時選擇的特征屬性是從原始的輸入因子中選取的,而隨機森林最終的預測結果是根據多棵決策樹的綜合預測結果得到的,因此,對隨機森林模型的預測性能影響最大的兩個參數分別是節點分割時選擇的特征屬性和決策樹的數量[11]。為進一步優化模型,以得到更好的預測效果,本文使用控制變量的方法,對兩個參數變化時的模型預測準確度的變化進行了探索[12-13]。以PM2.5為例,圖7給出了當節點分割時選擇的特征屬性數目分別為2~5時隨機森林模型預測結果準確度隨決策樹數量不同而變化的曲線。 分析圖7中的曲線可以看出,當決策樹的數量在30以上時,隨機森林的預測精度的變化趨于穩定。通過研究節點特征和決策樹數目對隨機森林預測精度的影響,可以幫助選擇合適的參數對模型進行改進。 經過模型構建和應用時對其預測性能與節點屬性數目和決策樹數量兩個參數之間關系的研究,同時考慮到預測準確度和運算速度兩方面對程序的影響,本文最終采用特征數量為2,決策樹數量為30作為隨機森林預測模型構建時的參數。其各等級的預測結果情況及準確率見圖8。 本文基于隨機森林算法研究了北京市氣象條件與空氣質量變化關系的相關性。通過以上研究發現:1)空氣質量與溫濕狀況、風速風向及天氣情況等氣象因子之間存在一定的相關關系;2)北京市空氣質量存在明顯的季節性變化,受浮塵天氣等因素的影響,春季空氣污染物濃度最高;3)各空氣污染物之間存在較明顯的相關性;4)在一定范圍內,隨機森林預測精度與決策樹數量成正相關。同時,對預測結果進行分析,PM2.5等級為優(A)的數據預測準確度最好,但其預測結果中包含的其他等級的種類也最多;PM2.5等級為輕度污染(C)的數據預測結果準確度相對較差,由此可見在該組數據中,PM2.5等級為輕度污染時其氣象條件的特征性相對較差,在程序的不斷優化中應對預測存在偏差的C類數據與氣象條件的關系進行進一步探索,通過增加C類典型樣本加強隨機森林的訓練或根據多次測試得出的誤差概率對C類結果進行補償等方式減小誤差。該模型不僅可用于PM2.5的預測,在對其他大氣污染物的預測中同樣具有良好的表現,對得到更加客觀準確的空氣質量及空氣質量的預測有較為重要的意義。采用該方法具有較強的針對性,但為保證較好的預測結果,對訓練集的特征性要求較高,在對其他地區的空氣質量進行預測時應重新選擇數據集對該模型進行訓練,對較大地理區域范圍內空氣質量的預測結果的準確性和普適性有待進一步研究。3 隨機森林預測模型的建立
3.1 特征值選取及相關性分析



3.2 模型的建立及應用

4 結論
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
