基于注意力機制的LSTM液體管道非穩態工況檢測
2021-12-06 07:59:26于濤張文煊
油氣與新能源 2021年5期
于濤*,張文煊
(1.國家管網集團數字化部;2.昆侖數智科技有限責任公司)
0 引言
長輸液體管道利用SCADA(數據采集與監視控制)系統實現遠程調控運行,運行過程中對異常工況的發現處置,均由調控人員根據設備狀態量報警信息及壓力、流量等參數閾值分析確定。一般而言,液體管道的判斷分析處置時間較短,對調控人員的業務技能、事件應急能力、工作狀態等要求較高;尤其是對于泄漏等工況,若不能及時發現,將影響后續工況的識別和應急處置,從而危及管道運行安全,嚴重時可能產生較大的次生災害,進而造成環境污染等問題。同時,工況實時檢測是未來管道智能化的前提,只有實時性、準確性提高后,檢測結果才可用于后續管道的工況智能識別和控制。
近年來,隨著管道SCADA系統的推廣應用,信息傳送、數據收集存儲等方面的完善提升,企業積累了大量的實際生產數據。長輸油氣管道生產數據具有工業大數據的“6V”特性[1],同時具有更強的專業性、關聯性、流程性、時序性和解析性等特點。國內外學者利用數據驅動智能應用和控制,實現了工業設備監測[2]、工況識別[3-4]、參數預測等功能[5-6]。可見,探索基于數據驅動的算法模型,研究油氣管道非穩態工況檢測和智能識別是未來管道智能調控的方向[7-8]。
目前對于油氣管道異常工況的研究多側重于泄漏工況的識別與特征提取[9-11]。武瑞娟[12]通過實驗模擬傳感光纖主體在輸油溫度和應力變化環境中的監測穩定性、精度,實現管道泄漏的檢測;陳志剛等人[13]提出基于多元支持向量機的管道泄漏診斷方法,并建立了識別模型,實現多種工況下對壓力波動信號的分類識別,從而提高泄漏工況識別準確性。當前學者的研究成果主要針對特定設備與泄漏等工況,沒有將管道非穩態工況作為整體納入研究,無法應用于未來管道工況的智能識別與控制。本文利用 LSTM(長短期記憶網絡)可學習并記憶序列長期信息的優點,提出了一種基于注意力機制的LSTM時間序列預測的算法,該算法可用于長輸液體管道非穩態工況檢測。
1 理論和方法
1.1 算法原理
1.1.1 LSTM網絡原理
LSTM是 RNN(循環神經網絡)的一種變體,由于其彌補了RNN的梯度消失或爆炸,以及長期記憶不足的問題而被廣泛使用于各個領域[14-16]。每個LSTM單元包括輸入門i(t),遺忘門f(t),輸出門o(t)以及兩個神經元狀態c(t)和h(t)。LSTM神經元的前向傳播計算過程見式(1)~式(5),其中W和b為相應權重。
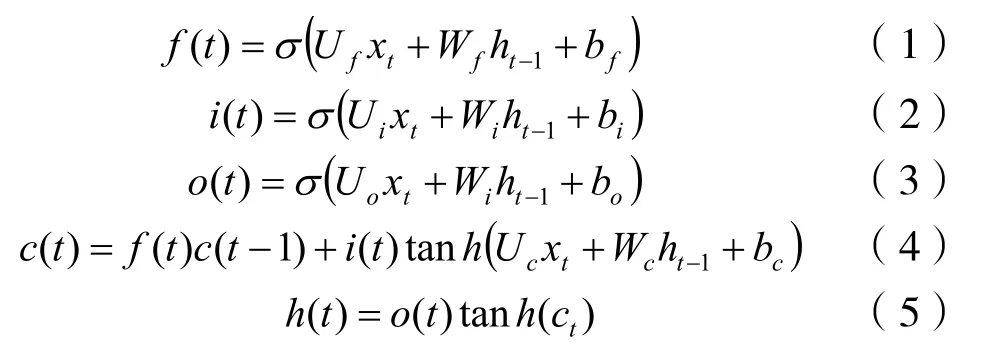
在時間序列分析中,深度學習通常由多層LSTM單元來實現,即每一層的輸出作為下一層的輸入。循環神經網絡的訓練通過基于時間的反向傳播算法實現,包括以下幾步:①前向傳播計算神經網絡的輸出;②計算誤差并在深度和時間兩個方向上反向傳播至每個神經元;③計算每個權重的梯度;④根據梯度更新權重。求解過程可以由多種梯度最優化算法實現,如,隨機梯度下降 AdaGrad、Adam、RMSProp等。
1.1.2 注意力機制
針對 LSTM的 Encoder-Decoder(編碼-解碼)框架因中間碼保存的信息量有固定上限,當輸入信息量大于中間碼時,導致信息丟失解碼準確度下降,陶云松等學者引入注意力機制用于圖像處理[17],其本質是對感興趣的特征中的每個特征用 softmax函數打分。通常注意力機制的輸入是當前狀態h(t)和側重關注的f=(f1,f2,···,fn),輸出是對n個特征的softmax打分s= (s1,s2,···,sn),在后續處理中,使用該打分功能進行過濾[18]。
增加注意力機制可看成在單獨的編碼、解碼器框架上,增加了一個單層RNN,輸出數據對應輸入數據的注意力權重,不僅受輸入數據的隱藏層決定,還取決于前一個數列的隱藏層,通過softmax獲得概率值,如式(6)~式(8)和圖1所示。
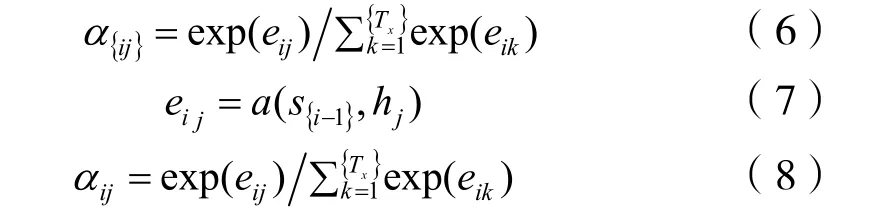

圖1 包含注意力機制的編碼、解碼框架
首先,單獨計算si-1與每個隱層狀態h一個數值,再通過softmax獲得i數據對應的Tx個編碼時隱層狀態內的注意力權重分配,從而求出ci分配向量權重。如式(9)~式(11)和圖2所示:
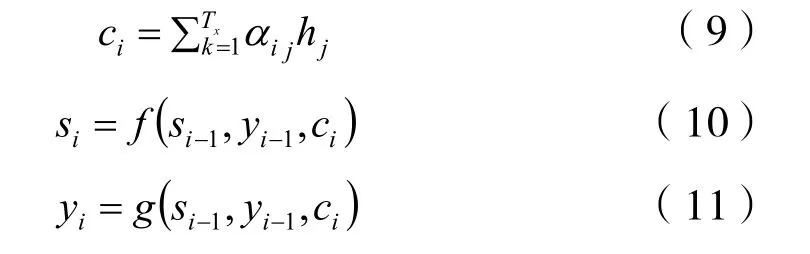
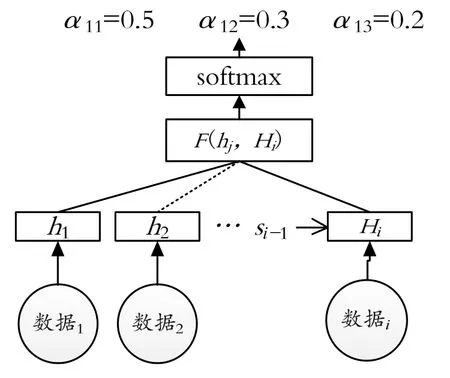
圖2 編碼器解碼器結構圖
1.2 非穩態工況檢測模型架構
根據液體管道SCADA系統數據特點,非穩態工況檢測研究架構如圖3所示。
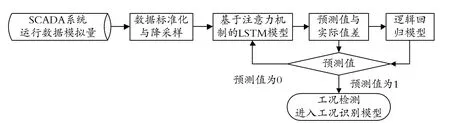
圖3 非穩態工況檢測模型結構圖
非穩態工況檢測模型包含兩部分:一是使用一個基于LSTM的時間序列預測模型學習正常數據的行為模式,并對未來數據給出時間序列預測;二是通過建立注意力機制調整模型輸出值,對預測數據與實際數據的誤差進行評分,給出是否異常的分類。基于注意力機制的LSTM網絡結構如圖4所示,其具體實施過程如下:
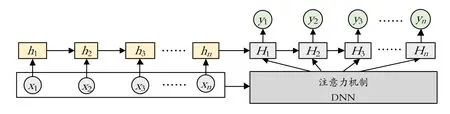
圖4 基于注意力機制的LSTM網絡結構
首先,LSTM作為時間序列預測模型,使用當前時間的前一時間點作為輸入值,后一時間點作為輸出值,輸出層的維度與管道的數據集特征維度相符。由于模型用于回歸問題的訓練,本文使用線性激活函數,并使用MSE作為損失函數。
其次,使用深度神經網絡實現注意力機制,利用注意力機制調整模型輸出,增強模型應對多種數據變化模式的能力。深度神經網絡由3層全連接層構成,維度與 LSTM模型的神經元輸量一樣,使用 Sigmoid函數作為激活函數,并使用MLE(極大似然估計法)作為損失函數。
最后,模型輸入參數5個維度,隱藏層100節點個數,循環50次數,學習率0.001。
工況檢測模型的訓練基于如下假設:一是利用穩態運行數據訓練的LSTM模型,模型工況檢測時,在工況數據區間上給出的預測誤差應比正常數據上的誤差更大,從而可使用平均對數誤差對預測誤差進行評估,指導調整 LSTM輸出結果;二是模型的預測誤差符合高斯分布。
1.2.1 算法步驟
將樣本數據分為四組進行訓練和驗證:①訓練集N,僅包含正常數據;②驗證集VN,僅包含正常數據;③驗證集VA,同時包含正常與異常數據;④測試集T,同時包含正常與異常數據。
(1)N被用來訓練檢測模型;
(2)使用驗證集VN防止訓練早期出現模型的過擬合;
(3)對N上的預測誤差使用注意力機制進行訓練,并使用MLE對誤差進行評估;
(4)對檢測模型的預測結果在VA上再次進行訓練,并更新注意力機制的權重;
(5)根據模型的輸出結果設定非穩態工況閾值,對輸出進行二值化處理;
(6)使用測試集T估計模型的效果。
在算法中,使用 Adam優化器對模型超參數進行訓練,并根據模型效果對訓練集的大小與窗口進行調整與優化。
1.2.2 MLE估計非穩態工況得分
假設時刻ti非穩態工況得分pi隨重建誤差ei呈高斯分布[19],即p~N(μ,Σ)利用 MLE 在數據集NV1上對參數μ,Σ進行估計。MLE參數估計步驟如下:

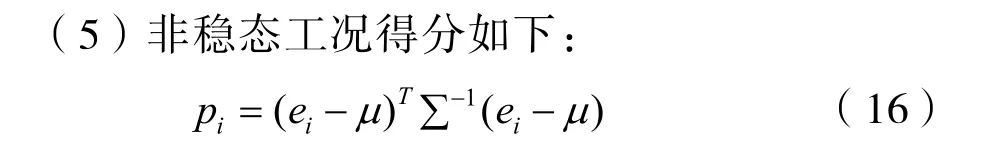
1.2.3 非穩態工況判定
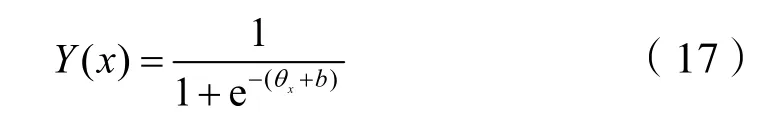
式中:Y——決策值;x——特征值。對于常見二分類,邏輯回歸通過一個區間分布進行劃分,即:如果Y值大于等于0.5,則屬于正樣本,如果Y值小于0.5,則屬于負樣本。判別函數如下:
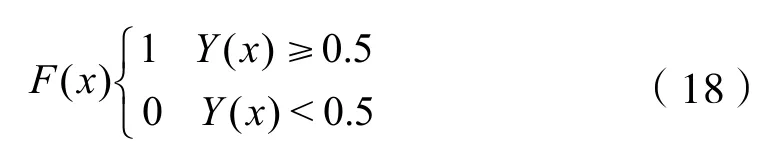
建立模型的目標是保證各類工況的檢測率,同時盡量篩選出更多的穩態工況數據,即在其他工況召回率100%的情況下,盡量提高正常運行數據的召回率。
1.3 實驗過程
1.3.1 數據準備
本文使用SL原油管道SCADA系統實際生產數據作為模型訓練驗證樣本,數據點包括各個站場重點監控的變量,包括各站的進出站壓力、流量以及主泵匯管的進出壓力,管道站場設置及數據采集點如表1所示。各管道數據采集自2018年2月至11月,選取記錄兩個管道操作較少的時間段:5:00—6:00和19:00—20:00,每次持續1 h,采樣頻率為1 s,由業務人員對數據進行梳理,剔除異常值及穩態工況值,提升數據的質量。
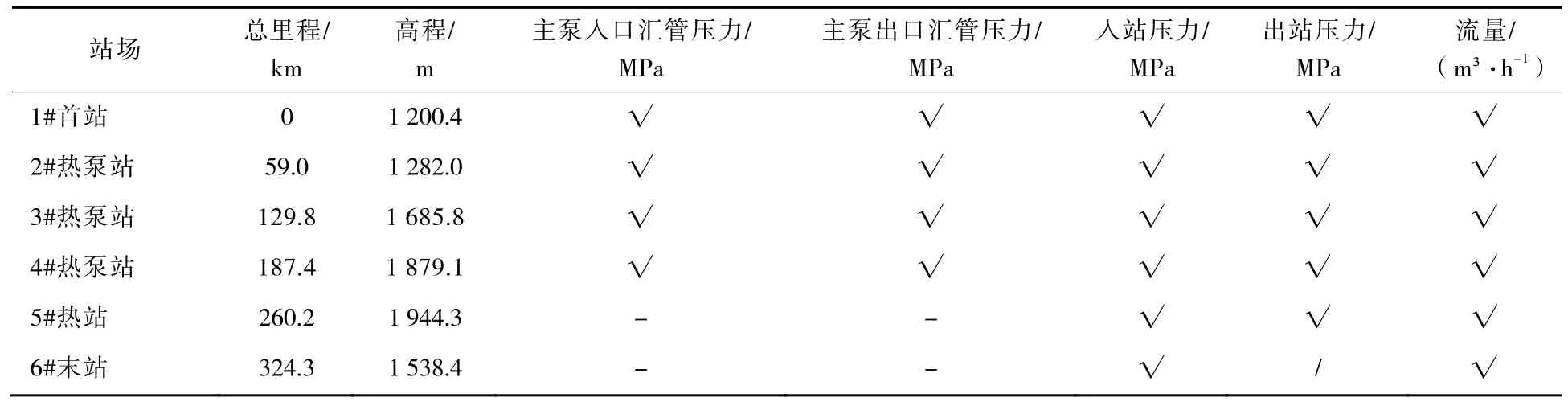
表1 SL原油管道站場參數及數據采集點
1.3.2 數據預處理
由于采集數據的分布隨時間差異較大,首先進行數據標準化。具體過程為,將各變量映射至零均值、單位標準差的分布上,計算公式如下:

式中:μ和σ取樣本x當月及所在晝夜對應樣本集的均值和標準差。通過此標準化過程,保證數據分布在不同時間段大體相似。
1.3.3 模型評價標準
本文采用Recall(召回率)作為模型性能評價指標,表示的是樣本中的正例有多少被預測正確,即:使用所有樣本數據作為分母,檢索到的作為分子,計算公式如式(20)。利用Accuracy(準確率)表示預測結果的準確度,針對預測結果而言的,表示預測為正的樣本中有多少是真正的正樣本,計算公式如式(21):
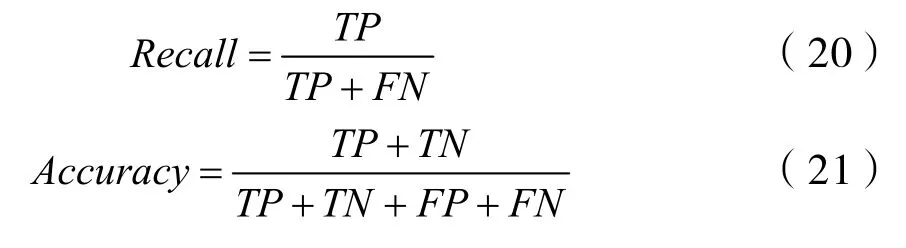
式中:TP——正類預測為正類數目;FP——負類預測為正類數目;TN——負類預測為負類數目;FN——正類預測為負類數目。使用分析速度作為模型效率評價指標,反映若模型在部署至真實環境下時所需的系統資源開銷以及可能帶來的延遲。
2 結果和討論
2.1 模型測試分析
使用實際生產數據驗證預測模型,并與RNN、one-class SVM與IF(孤立森林)等在機器學習領域常用的非穩態工況檢測模型進行對照實驗。各模型均使用表1的數據進行訓練,選擇使用SL原油管道在2019年6月的生產運行數據進行測試。測試結果如表2所示,其包括下載燃料油、切罐及甩泵等工況數據,實現管道壓力快速劇烈變化和較小變化的捕捉,通過下載燃料油模擬管道泄漏工況,利用模型將不同工況非穩態的水力特點與正常工況進行識別區分,實現壓力的異常檢測。
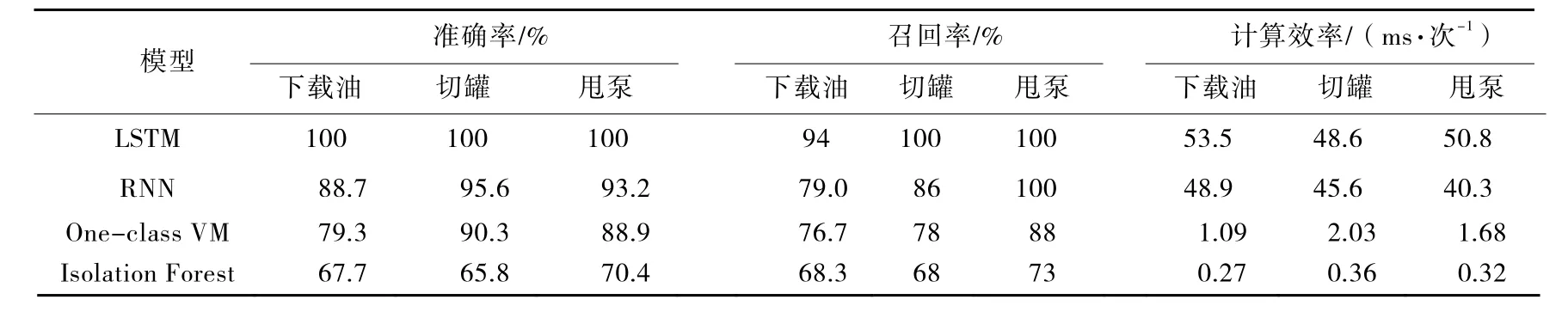
表2 模型對比分析
由表2可知,RNN與one-class SVM兩種模型對下載燃料油的預測誤差較大,切罐和甩泵的準確率和召回率均較好,說明RNN和one-class SVM對于穩態工況數據的學習效果較好。但對于下載燃料油工況這兩種模型的準確率較低,實驗過程中嘗試多種窗口和批量大小,仍然無法改變兩種模型對下載燃油工況的判斷精度,經分析主要原因可能在于下載燃料油的持續時間過長,以及壓力、流量變化相對平緩,導致無法將下載燃料油工況的開始階段與正常運行數據有效區分。Isolation Forest對工況檢測的檢測精度最低,無法實際應用。
相比其他模型,基于注意力機制的 LSTM模型不僅能夠更好地記憶穩態工況的狀態與模式,還不受長時間工況與復雜變化的影響,模型對數據的變化狀態與正常工況進行比較和計算,最終達到準確率100%的效果。
2.2 模型實際應用
利用構建的工況檢測模型,識別SL原油管道甩泵、下載燃料油工況,其工況趨勢圖和預測偏差,如圖5、圖6所示。
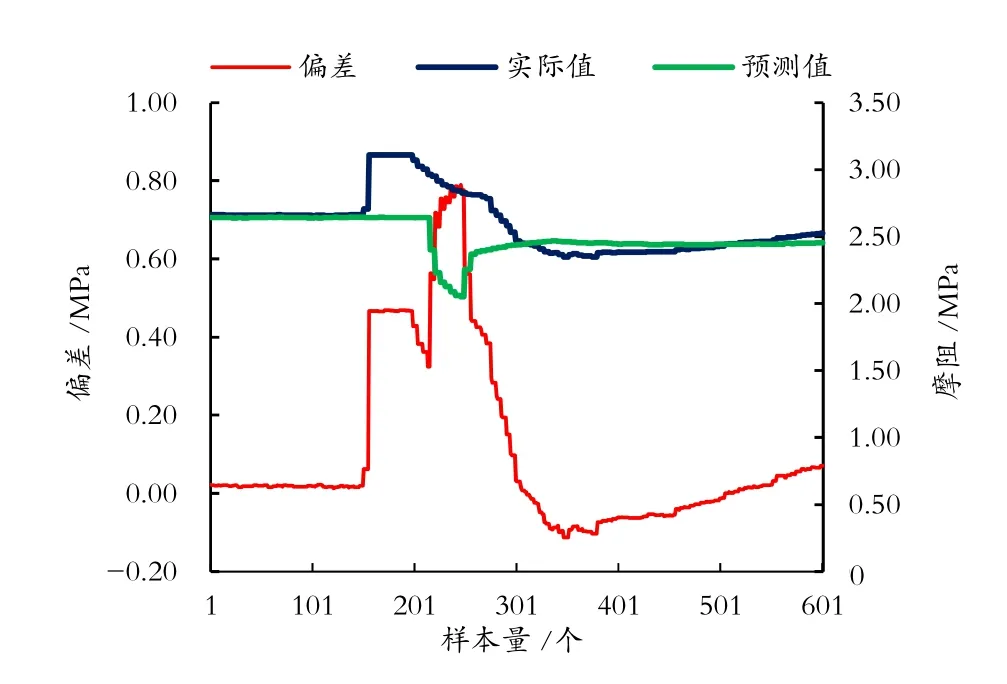
圖5 SL管道2#泵站甩泵工況
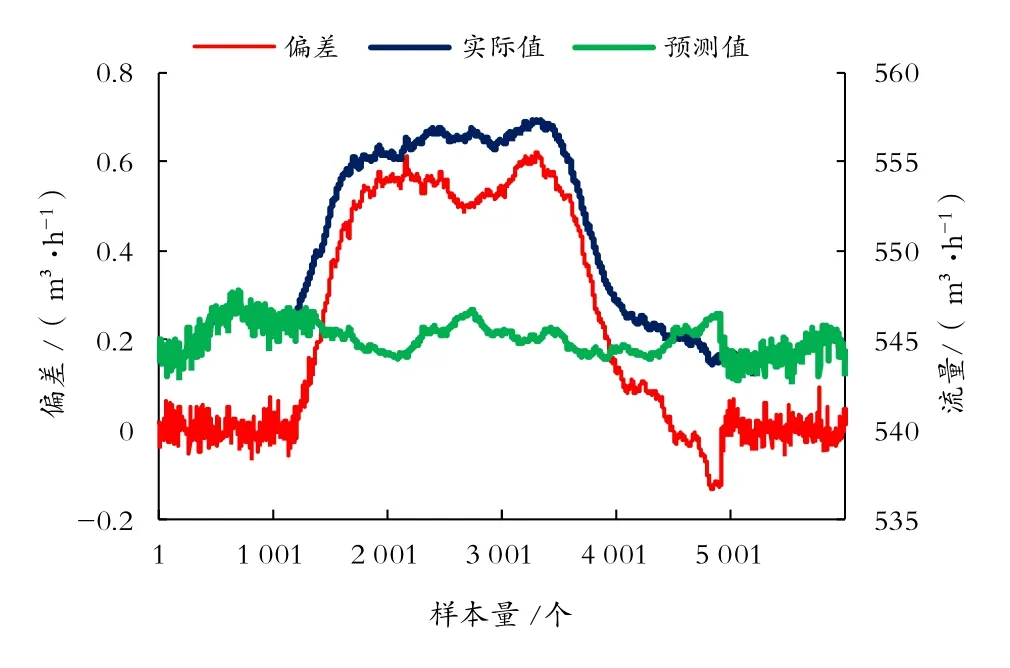
圖6 SL管道2#泵站下載燃料油工況
由圖5、圖6可知,將基于注意力機制的LSTM工況檢測模型用于實際工況檢測,通過設定實際值與模型預測值的偏差閾值(本實驗的閾值為0.03 MPa),可實現工況的實時準確檢測。
3 結論
根據原油管道工況發生后的數據特點,提出了利用 LSTM神經網絡對參數重建的工況檢測方法。針對 LSTM神經網絡在輸入信息量大于中間碼時,導致信息丟失解碼準確度下降等問題,提出了利用注意力機制提高模型準確性的方法。使用LSTM神經網絡預測管道的未來數據,利用注意力機制調整模型輸出值,對預測數據與實際數據的誤差進行MLE評分,設定評分閾值,利用二分法區分閾值實現工況的實時檢測,最終研究建立了基于注意力機制的LSTM工況檢測模型。
基于注意力機制的 LSTM網絡結構既保證了穩態工況的數據可以長時間不受復雜變化的影響,同時還可以有效的對非穩態工況數據進行比較計算,提升預測準確率。
非穩態工況檢測模型實現了穩態工況和非穩態工況的有效區分,模型的準確應用是工況智能識別的研究前提,其可有效降低工況智能識別模型的系統資源開銷,提高模型運行效率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2018年21期)2018-11-09 01:23:06
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國衛生(2015年9期)2015-11-10 03:11:12
