基于邏輯回歸評分卡的石油企業供應商風險模型研究
2021-12-06 07:59:24曹杰張巖松劉速楊文軍高峰劉增霞
油氣與新能源 2021年5期
關鍵詞:模型
曹杰*,張巖松,劉速,楊文軍,高峰,劉增霞
(昆侖數智科技有限責任公司)
0 引言
石油企業是一個龐大的生產運營綜合體,涉及上、中、下游復雜的業務鏈,集勘探開發、煉油化工、物流運輸、成品油銷售、天然氣銷售、石油貿易、裝備制造、工程技術等業務于一體[1]。在實際生產經營中,石油企業及下屬單位與大量供應商有著交易往來。供應商作為供應鏈的源頭,在石油企業物流中有著不可替代的作用。面對良莠不齊的供應商,如何識別和評估供應商存在的各類風險,降低采購成本,有針對性地選擇優質供應商,成為石油企業采購管理的核心。
對采購供應商進行風險識別和評估,是采購管理的關鍵環節,且采購是最為重要的成本開支之一,每年采購的進項發票有幾千萬張,金額巨大,業務范圍廣、采購種類多、供應商數量多,采購過程中一般基于歷史采購經驗、招投標和合作往來的方式進行供應商評選。隨著“電算化”時代的到來和大數據技術的迅速發展,數字化技術為企業管理提供更有效的手段[2],采購行為信息能夠以結構化或半結構化的數據形式存儲,大量數據資源形成了龐大的數據庫,蘊含著巨大的價值,通過深入挖掘數據標簽和風險因素,建立供應商風險模型能夠助力石油企業采購管理的提升,輔助供應商評估。
供應商風險模型的建立在不同行業存在一定的差異,許多學者將各類模型算法應用在相應的領域。梁梁等在供應商管理庫存中運用歐式和美式期權對供應商經營風險進行分析[3]。梁澤彬等基于灰色層次分析和灰聚類相結合的分析方法,建立了供應商風險評價模型,并應用在物流企業的供應商風險管理[4]。李輝運用粗糙集與模糊綜合評價,從交互能力風險、合作風險、服務風險指標維度對一家混泥土外加劑生產企業建立供應風險評價模型[5]。繆琳以物流企業為例,運用物元和可拓理論建立供應商風險評價模型[6]。胡爽等以航空企業的供應商風險管理為例,應用層次分析法建立供應商風險評估體系[7]。祝思佳等基于航空轉包生產行業的復雜性,采用TOPSIS(熵權)算法模型對航空轉包供應商進行風險評估[8]。耿俊成等基于基本屬性、用電行為、95598信息等維度數據運用邏輯回歸模型建立電力客戶停電敏感度評分卡[9]。邏輯回歸評分卡是一種成熟的風險評估模型,在客戶信用風險評估和金融風險控制領域有著廣泛的應用,其原理是從歷史數據中探查良與不良客戶或供應商的特征,運用邏輯回歸算法基于WOE離散化后的模型變量進行二分類,建立數據模型,為信用評估提供依據。相較于層次分析法及物元和可拓理論依賴專家主觀評價、熵權法對樣本量要求較高且僅適用于計算權重,邏輯回歸評分卡基于供應商特征數據進行邏輯回歸模型訓練,實現簡單,訓練速度快,結果客觀可信,因此在供應商評價中得到廣泛應用。
本文以石油企業進項發票數據和供應商主數據為數據來源,結合石油企業的采購特性,運用邏輯回歸評分卡建立石油企業的供應商風險模型。
1 發展環境分析
1.1 邏輯回歸評分卡模型
邏輯回歸是廣義的線性回歸,常用于信貸評估等二分類問題,包含因變量和自變量兩種變量類型,其中因變量屬于二元分類變量,自變量呈現供應商或客戶的信息。
設邏輯回歸模型有r個自變量,用x1、x2、…,xr表示,因變量y∈{1,0}表示供應商良與不良信息這一事件,y=1表示不良的供應商,y=0表示良好的供應商。y=1事件概率以p表示,其公式為:
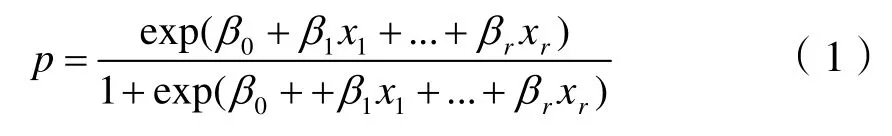
式中:β0、β1、…、βr——模型參數;β0——截距項[10]。經轉換簡化公式為:
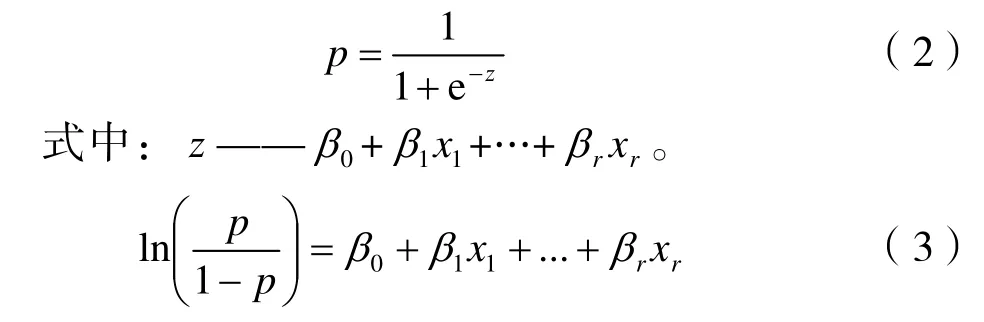
式中:1-p——供應商良好的可能性;p(1-p)——不良事件與良好事件發生的可能性比,被稱為odds。對odds取對數,得到線性函數。邏輯回歸通過尋找最佳的參數β0、β1、…、βr實現模型優化。
采用最大似然估計函數測算β0、β1、…、βr模型參數,設有m組觀測數據,則極大似然函數為:

式中:分別對參數β求偏導數,求得使對數似然函數最大的邏輯回歸系數的估計值。
1.2 邏輯回歸評分卡
邏輯回歸評分卡是指基于邏輯回歸算法生成的評分卡,最常見的是信用評分卡,它是根據客戶屬性和行為數據,利用邏輯回歸模型計算客戶信用評分,據此建立客戶信用等級,輔助貸款、授信等業務決策。
結合評分卡和邏輯回歸的基本原理,評分卡的分值以發生比的對數線性表達式表示:

式中:A與B是常數,高分值代表低風險,低分值代表高風險。
結合公式(3)和公式(6),評分卡分值計算公式表示為:
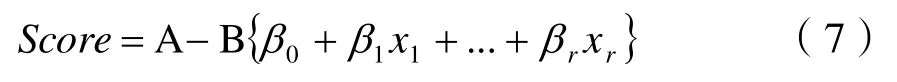
式中:x1、x2、…、xr——入模變量。經WOE轉換后以 (βiωij)δij形式表示:
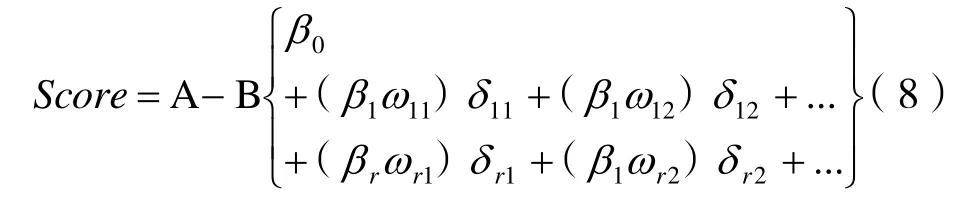
式中:A-Bβ0——基礎分值;ωij——第i個變量的第j個分箱的WOE值;βi——回歸方程系數;δij——二元變量,表示第i個變量的取值。
2 石油企業供應商風險模型構建
隨著數字化時代的發展,石油企業建立了多項成熟的管理系統,存儲了大量業務數據,其中發票作為商品(服務)交易的原始憑證,是石油企業采購交易的體現,可以提煉出供應商的交易往來、主銷商品、稅務風險、歷史開票行為等特征,供應商主數據包含:單位性質、企業類型、注冊資本等自然屬性特征,能夠為模型評估提供豐富的數據基礎。本文以石油企業進項發票和供應商主數據為數據來源構建供應商風險模型,構建流程如圖1所示。
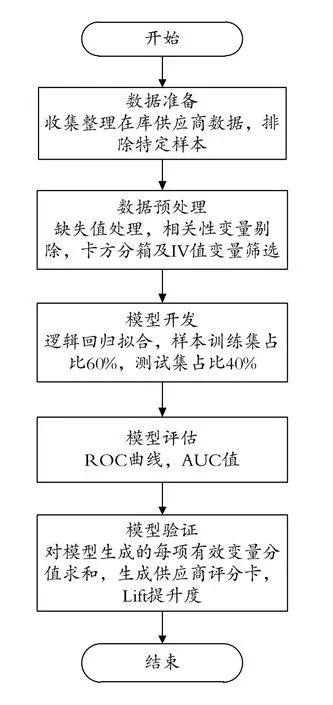
圖1 石油企業供應商風險模型構建流程
2.1 數據準備
從石油企業進項發票數據和供應商主數據提取62項供應商相關的屬性,主要包括以下3類數據:①基礎屬性數據,如供應商稅號、單位性質、企業類型、所屬集團、所屬板塊、所屬行業等。②經營表征數據,如經營現狀、注冊資本、內部合作單位數、主銷商品等。③發票表征數據,如開票數量、開票金額、作廢發票、失控發票、異常發票、紅沖發票、風險發票等。
為了保證字段變量的完整性,選取具有較好代表性的樣本,訓練集樣本量為22 544條,占比60%,測試集樣本量為15 029條,占比40%,總計樣本量37 573條。其中訓練集好樣本20 844條,壞樣本1 700條,測試集好樣本13 895條,壞樣本1 134條,訓練集和測試集好樣本合計34 739條,壞樣本合計2 834條。樣本數據分布如表1所示。
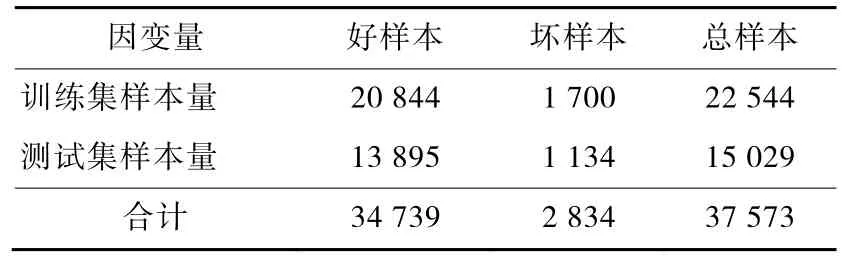
表1 樣本數據分布表 單位:個
2.2 數據預處理
模型經過缺失值處理、相關性變量剔除、數據轉換(分箱離散化)及IV值變量篩選等優化過程,變量從最初62項到最終選定9項作為模型的特征指標,具體優化過程如下。
2.2.1 缺失值處理
本次研究初步提取 62項供應商相關的屬性數據,但其中不少變量包含大量缺失值且部分變量與目標變量無關(如國家、編碼等字段),因此將缺失比例在50%以上的變量及無關變量一并剔除。經過本次剔除,對剩余39個變量進行缺失值賦值,本文對缺失值處理,采用變量的眾數進行插補。
2.2.2 相關性變量剔除
邏輯回歸模型中自變量間若存在高度的多重共線性會影響模型估計結果,如偏回歸系數估計困難,偏回歸系數的估計方差會隨自變量相關性的增大而增大,偏回歸系數估計值的不穩定性增強,偏回歸系數假設檢驗的結果不顯著等。因此,本文研究中考慮變量之間的相關程度,根據 Pearson相關系數剔除相關系數在 0.6以上而對目標變量影響相對較小的變量。經過相關性剔除,篩選11個變量進入分箱處理。
2.2.3 卡方分箱及IV值變量篩選
分箱的目的是實現數據的離散化,降低過度擬合風險。信息價值IV是衡量變量預測能力的指標,能夠判斷特征變量對結果的重要程度,IV值越大表示特征變量的預測能力越強。對于分組變量,IV值計算公式如下:
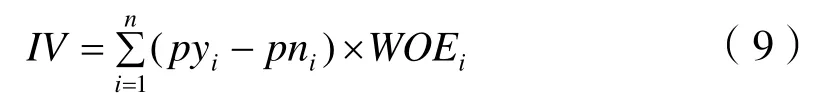
式中:pyi——當前分箱中不良供應商占樣本中不良供應商的比例;pni——該分箱中良好供應商占樣本中良好供應商的比例;WOEi——當前分箱中不良供應商和良好供應商的比值和樣本中不良供應商和良好供應商比值的差異。差異越大,該分組里的樣本響應的可能性就越大。計算公式為:
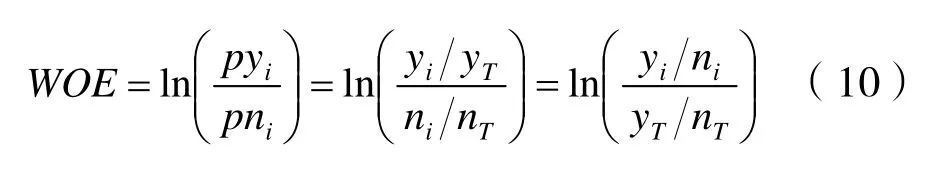
式中:yi——當前分箱中不良供應商的數量;ni——該分箱中良好供應商的數量;yT——樣本中不良供應商的數量;nT——樣本中良好供應商的數量。
特征變量的IV值如表2所示,選取IV值大于0.01的9個變量作為入模變量,分別是歷史作廢發票數量比例、歷史年均交易頻次、近三個月作廢發票金額、歷史開發數量、供應商近一年內部合作單位數、供應商歷史上內部合作單位數、所屬板塊、所屬集團、單位性質。
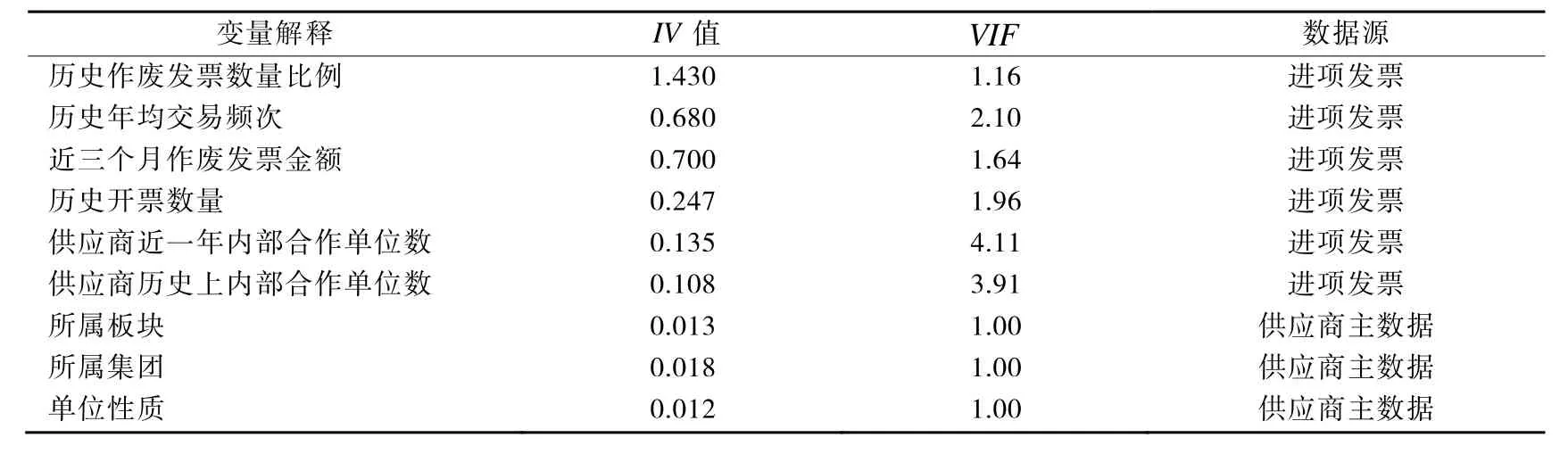
表2 入模變量IV值表
2.3 模型開發
采用最大似然估計法計算回歸系數的估算值,模型擬合結果如表3所示。入模變量9項,其中歷史作廢發票數量比例、歷史年均交易頻次、近三個月作廢發票金額、歷史開票數量、所屬板塊p值遠小于 0.01,具有非常顯著的意義,單位性質p值小于0.05有顯著意義。
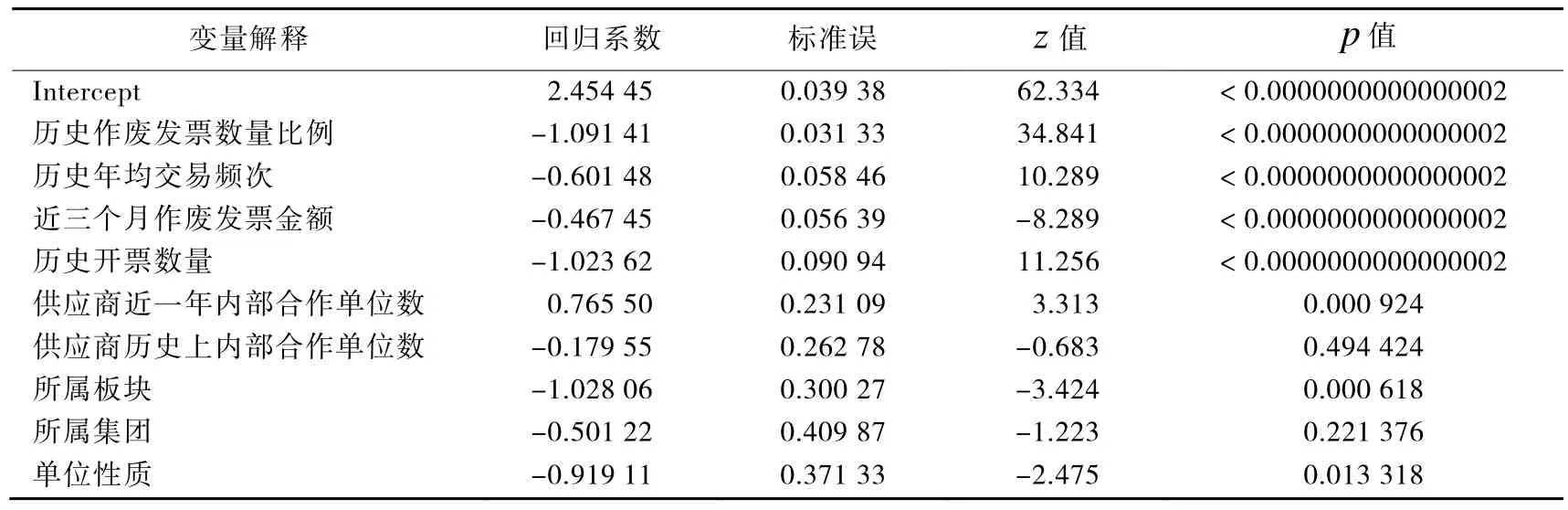
表3 邏輯回歸結果
此外,根據表3邏輯回歸系數顯著性檢驗結果,變量顯著性指標多為進項發票指標,考慮供應商評價應綜合考慮多個業務維度,因此在不影響邏輯回歸模型整體效果的前提下,將供應商歷史上內部合作單位數、所屬集團兩個變量納入評分卡模型。
基于邏輯回歸算法模型輸出的回歸系數和WOE編碼對每個入模變量按照不同的分箱建立評分刻度,如表4所示。邏輯回歸評分卡模型通過綜合計算入模變量的評分值和初始基礎分,來統計每個供應商的總體得分。當有新的供應商數據進入模型時,模型會自動計算出供應商的分數,從而實現供應商風險的判斷。
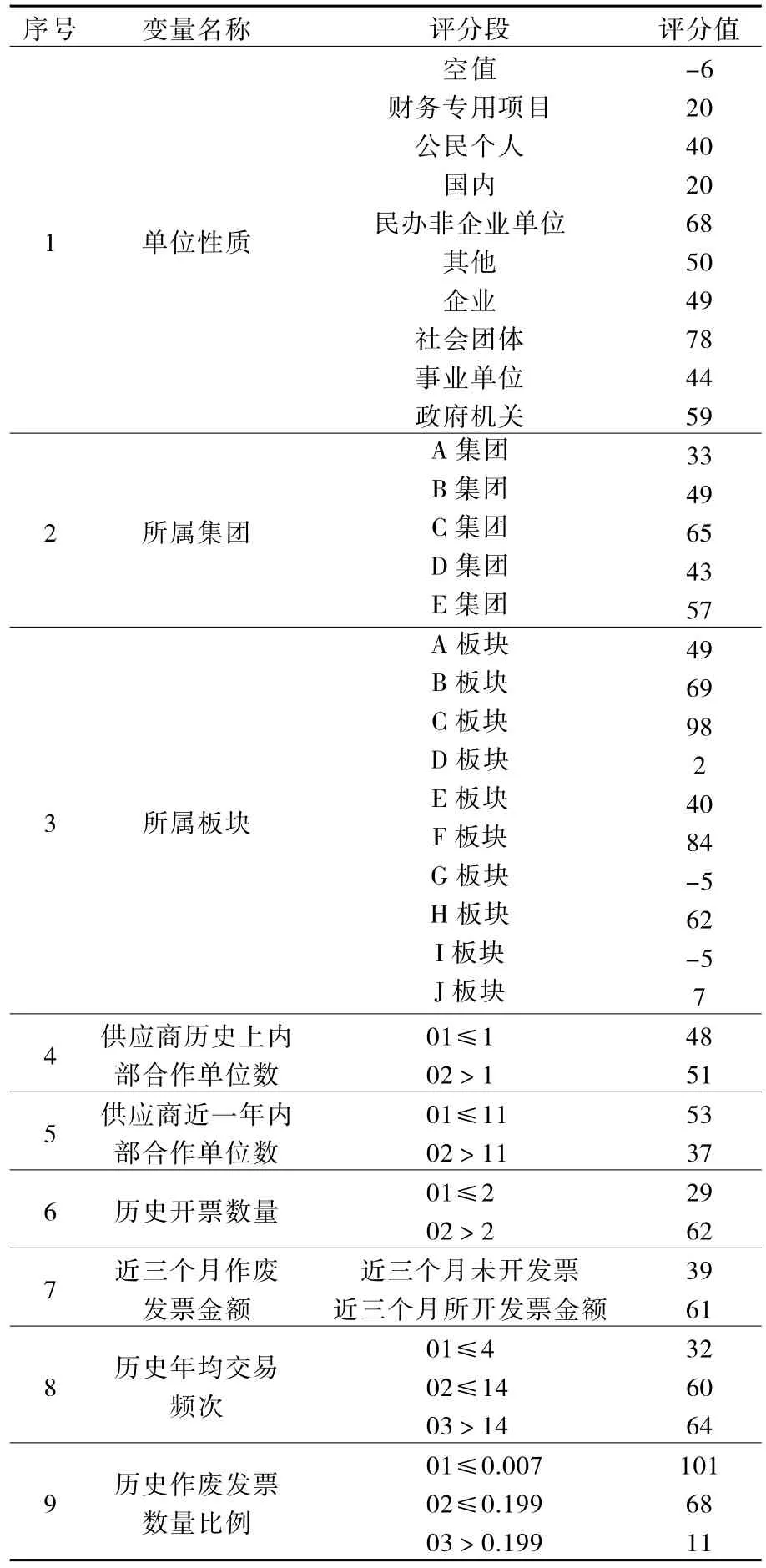
表4 評分刻度表
2.4 模型評估
二分類問題常見的評價指標有準確率、精準率、召回率、F1值、ROC(感受性曲線)曲線和AUC等。準確率是指分類正確的樣本占總樣本的比率,在不均衡的樣本集上度量效果較差。精準率是指預測為正的樣本中實際為正的比率。召回率是指正樣本中被預測為正的比率。F1值是精準率和召回率的調和平均。ROC曲線是以真正率為縱坐標、假正類率為橫坐標繪制的曲線[11]。AUC值被定義為ROC曲線下的面積,AUC越接近于1,模型效果越好,其中AUC介于0.5~0.7,模型效果一般;AUC介于0.7~0.9,模型效果較強;AUC大于0.9,模型效果很強。相比于其他評價指標,當樣本集中正負樣本不均衡時,ROC曲線能夠保持相對的穩定,而精準率、召回率等會出現較大的變化。因此,本文采用ROC曲線和AUC面積值作為模型的評價指標。由圖2訓練數據和圖3測試數據的ROC曲線可以看出,曲線明顯高于對角線,證明模型是有強規則性的,且曲線上凸于縱坐標軸,AUC面積區域接近于梯形狀,證明模型分類效果較好。該模型測試AUC為0.82,說明模型分類能力較好。
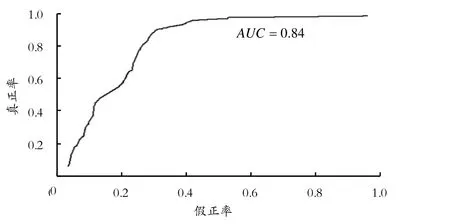
圖2 訓練數據ROC圖

圖3 測試數據ROC圖
2.5 模型驗證
測試樣本共有15 029個供應商,其中不良供應商1 134個。基于邏輯回歸評分卡對測試樣本數據進行評分計算和驗證,分值段按照供應商數量劃分,每段供應商數量約為5%,以分值從低到高排序,見表5和圖4。
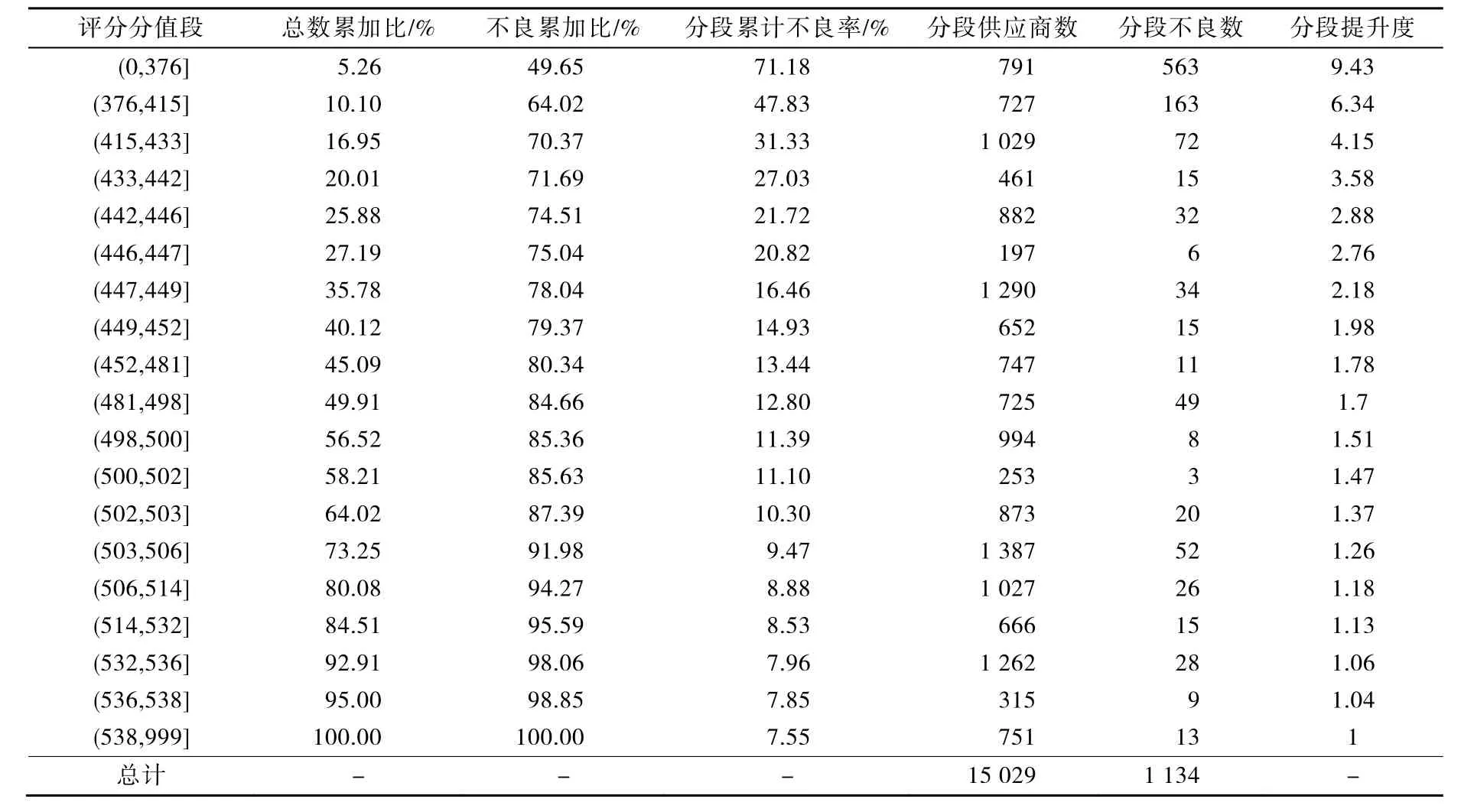
表5 驗證數據表
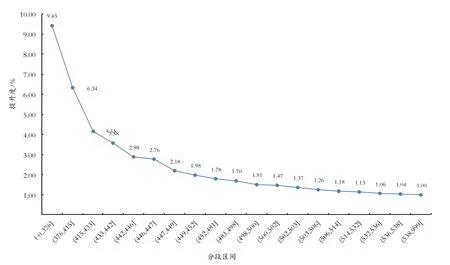
圖4 分段提升度
分段提升度作為評估預測模型有效性的度量指標,衡量的是一個模型(或規則)對目標中“響應”的預測能力優于隨機選擇的倍數。通過驗證數據表,測試集中供應商自然不良率為 7.55%,(0,376]分段不良率71.18%,比自然不良率提高了9.43倍,提升度顯著大于1,在(0,447]低分段區間,分段提升度均大于2.5,預測能力明顯優于隨機選擇,說明算法性能較好,且提升度曲線單調下降,呈“L”型,表明模型分類效果良好。
建立評分卡的目的是根據供應商的模型評分,對供應商做出風險判斷,采取相應的防范措施。結合 Lift提升度曲線,(0,447]分段區間的提升度均大于2.5,相比自然隨機抽取有較大的概率提升,存在風險供應商的可能性較大,基于分值區間的劃分和業務考慮,將(0,376]劃分為高風險,(376,433]劃分為中風險,(433,447]劃分為低風險。通過應用供應商風險模型,采購管理者一方面能夠掌握供應商警示名單等信息,對447分段內的供應商重點關注,另一方面可以洞察供應商有關風險影響指標,輔助采購決策。
3 結論
石油企業進項發票數據和供應商主數據是本文運用邏輯回歸評分卡建立供應商風險模型的主要數據來源,經過特征篩選選定了9項特征變量進行邏輯回歸擬合,模型驗證效果良好。供應商風險模型將可能存在風險的供應商劃分為高、中、低三個等級,風險等級越高,存在生產經營風險的可能性越大。石油企業在進行采購交易時,可參考本文提出的供應商風險模型,并結合實際采購需求做出合理的判斷,對于高風險供應商重點關注,盡量避免交易往來;對于中風險供應商綜合評估采購需求,慎重交易;對于低風險供應商進一步分析風險指標項,綜合評估采購的關聯性,減少交易風險。
本文供應商風險模型的數據來源存在一定局限性,隨著司法風險、立案信息、經營狀況等外部數據的引入能夠進一步豐富模型變量,提升適用范圍。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
