基于深度圖神經網絡方法的領域知識結構探測
2021-11-25 09:32:06劉非凡羅雙玲夏昊翔
情報學報 2021年11期
劉非凡,張 爽,羅雙玲,夏昊翔
(1.大連理工大學系統工程研究所,大連 116024;2.大連理工大學大數據與智能決策研究中心,大連 116024;3.大連海事大學航運經濟與管理學院,大連 116026)
1 引言
結構化的學科領域知識反映出科學的內在邏輯與聯系。如何客觀準確地度量出學科領域主題是情報工程研究人員試圖解決的基礎問題。清晰的學科領域知識結構有助于研究者把握領域研究的發展態勢、支持科技管理活動以及完善科技政策的制定。自20世紀以來,科學界各個學科領域都取得了前所未有的蓬勃發展,新興研究領域層出不窮。從數量上來看,科學文獻發表量自1900年起呈現出指數型增長的趨勢,文獻涉及的學科領域知識單元也呈現出線性增長的趨勢[1];從Web of Science科學文獻數據庫的統計結果來看,至2015年前后,日益增長的科學文獻所涌現出的新詞匯規模已達到了每年4萬個[2]。另外,大科學時代領域知識結構呈現出三個重要特征:學科領域知識網絡規模持續擴展、維度高速膨脹以及結構動態多變[3]。學科體系日益復雜、交叉學科領域不斷涌現為厘清領域知識結構帶來了巨大挑戰[4]。
領域知識結構探測的核心任務是準確、全面地識別領域科學文獻中所涵蓋的知識單元實體,并挖掘出這些知識單元之間的關聯程度。信息技術的發展、網絡科學的興起以及大規模可獲取的科學文獻數據為科技情報人員解決該問題提供了重要的理論指導與研究基礎。首先,大規模可獲取的文獻數據使得更加全面、系統和完整地識別和探測學科領域的知識結構成為可能。其次,網絡科學的興起,特別是引文網絡分析、社會網絡分析以及復雜網絡分析理論,豐富了領域知識結構探測研究的內涵。最后,計算機學科的發展,尤其是圍繞大數據與機器學習的相關軟硬件及人工智能算法研究,為領域知識實體識別與結構分析提供了重要的技術支撐。
當前,圍繞領域知識結構的識別與探測問題,國內外網絡科學、計算機科學、科學學以及情報學等各領域的學者都開展了諸多研究。網絡科學研究人員主要聚焦于普適視角下的網絡構建方式、凝聚子群的識別,以及網絡社區的劃分[5]。計算機學科研究人員憑借機器學習、統計學習以及神經網絡等新興研究領域的發展,開發了更先進的自然語言處理工具與主題抽取模型[6],對文檔內容的挖掘與分析日趨深入。科學學研究人員則重視從科研活動視角探討領域知識的交叉融合模式[7]。情報學研究人員則廣泛吸收和借鑒了不同學科的理論與方法工具,研究范圍涵蓋了科技文獻引證分析、期刊分群、文本內容特征提取、主題詞共現網絡結構探測以及文檔全文挖掘等主題[8-10]。近年來,也有學者利用深度學習等先進的文本語義分析手段測度學科知識結構[11]。
人工神經網絡領域的快速發展加速了自然語言處理技術的更新迭代,并且為網絡科學的研究帶來了新的研究范式。在文本內容分析領域,相較于傳統的主題發現方法,深度學習技術展現出了語義捕獲更準確和結果更具解釋性的特點。在情報工程應用上,傳統的文本內容分析手段,如TF-IDF(Term Frequency-Inverse Document Frequency)[12]、共詞[13]、LDA(Latent Dirichlet Allocation)及其衍生方法[14-15],正在被新型研究手段所取代[11]。在網絡分析研究領域,已經出現了利用流形學習方法對高維文本特征數據降維可視化的研究,如t-SNE(t-Distributed Stochastic Neighbor Embedding)算法[16]。另外,有學者利用淺層圖網絡表示學習方法來解決學者科研合作預測的問題[17]。
總體而言,領域知識結構探測問題是一個典型的跨學科研究問題,不同學科的研究人員借助自身的學科優勢對該問題開展了廣泛探索。領域知識結構探測的基本思路可以歸納為兩個方面:一方面是文本內容分析,利用自然語言處理方法直接抽取科技文獻的文本內容,通過度量文本之間的相似性識別出領域知識結構;另一方面是引文網絡分析,通過領域文獻之間的直接引用、耦合引用或共被引關系構建引文網絡,利用文獻聚類算法挖掘出領域知識關聯。這兩種方法在目前的領域知識結構探測中均取得了良好的效果。文本內容分析方法(簡稱“內容分析法”)的優勢在于直接從文獻的文本內容中抽取主題,或者利用文本特征表示方法轉化為低維主題向量,進而通過向量相似度度量出文本之間的差異度。內容分析法的效果直接取決于文本的預處理過程是否完善以及主題模型的選擇與應用是否適當。引文網絡分析方法(簡稱“引文分析法”)的有效性源則自研究人員的引用動機,即假設研究人員總傾向于將與自己論文主題相近的文獻選入參考文獻列表中。
然而,這兩類方法都存在一定的局限。圖1以vi和vj兩個節點在兩類方法中的不同分類結果反映了引文分析法與內容分析法的缺點。其中,vi是高被引文獻,vj是文本內容缺失或者與主題1和主題2的內容相似度均接近的文獻。在這兩種分析方法下,vi由于擁有極高的引用關系,會吸引來自不同子領域的引用關系,導致該文獻及其具有施引關系的其他相關文獻出現“內容差異大,但被分到同類別”的情況。對于vj來說,文本內容缺失或者與其他多個主題之間區分度過小都會導致其無法被準確分類。而如果vi具有可區分的文本內容,那么vi通過內容關聯就可以獲得正確分類;vj則可以依據引用關聯得到更為恰當的分類結果。也就是說,這兩種方法的有效融合有望解決上述單一方法存在的問題,即文本挖掘往往受制于“一詞多義”現象以及領域語料庫的缺乏;而引文分析則受限于高被引文獻對領域學科網絡結構的影響,可能會造成將不同主題的文獻匯總到同一主題下的情況。
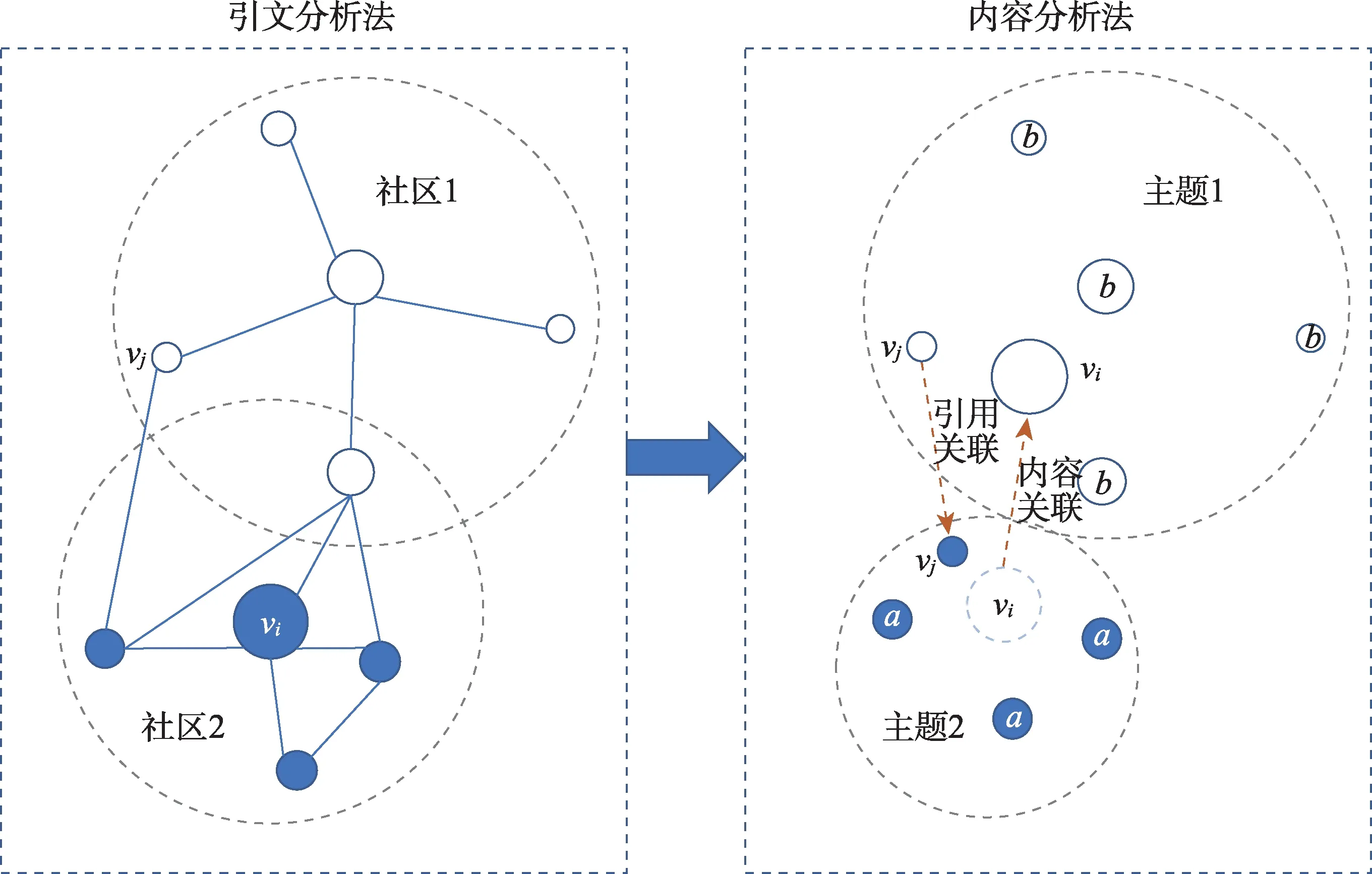
圖1 引文分析法與內容分析法的局限示意圖
盡管也有學者將兩類研究方法試圖結合起來[18-20],但多局限于啟發式地混合兩者的相似度矩陣,未實現文獻的內容特征以及引用關系特征的直接融合。同時,這些方法無法結合傳統的專家分類方法,在研究范圍、規模擴展性以及預測性等方面也存在先天缺陷。因此,本文擬引入近年來在機器學習領域中新涌現的深度圖表示學習方法,通過直接融合文獻的內容特征以及引用網絡的結構特征,以期獲得更準確的領域知識結構探測與識別結果。
2 研究框架
2.1 基于深度圖神經網絡方法的領域知識結構探測研究框架
鑒于目前研究方法的局限,為了準確探測和識別領域知識結構特征,本文提出了基于深度圖神經網絡學習表示方法的研究框架,具體研究流程如圖2所示。

圖2 基于深度圖神經網絡模型的領域知識結構探測研究框架
本文所提出的研究框架由數據預處理模塊、特征抽取模塊、圖網絡模型模塊以及領域知識結構可視化模塊4部分組成。
(1)在數據預處理階段,搜集整理所要分析領域的文獻題錄信息及文獻之間的相互引用關系信息。本文以文獻的標題以及摘要作為文獻的核心內容表征信息,并對文本進行合并、轉換大小寫、去除符號標點數字、剔除學術停用詞以及版權聲明等預處理。
(2)特征抽取階段可分為文檔表示學習和文獻引用網絡構建兩個步驟。具體來說,運用文檔表示學習算法Doc2Vec獲得表征文本內容特征信息的高維向量。根據領域內文獻之間的施引關系,構建直接引用網絡,并篩選出最大的連通子圖,利用Lou‐vain社區劃分算法得到文獻節點的社區標記。
(3)圖網絡模型學習階段是本文框架的主要創新點。深度圖神經網絡模型具有既可以嵌入節點屬性特征,又可以學習節點結構特征的優勢。因此,在該階段將特征抽取模塊得到的文本向量特征以及直接引文網絡結構信息作為深度圖神經網絡的輸入。通過模型的學習訓練,得到融合了文本內容特征和網絡結構特征的文獻節點表征向量。
(4)在最后的領域知識結構可視化階段,運用流形學習算法UMAP(Uniform Manifold Approxima‐tion and Projection)對節點高維向量實施降維轉換,并實現可視化。
經過上述4個階段,可測度并繪制出融合文獻內容主題特征及引用關系的領域結構知識圖譜。第2.2節和第2.3節將對本文研究框架中涉及的幾類深度學習表示算法和引文網絡社區劃分方法加以簡要介紹和說明。
2.2 深度學習表示方法
2.2.1 文檔表示學習
文檔表示學習是指通過人工神經網絡方法,對文本進行數值化處理的手段。相比于傳統的詞袋模型、TF-IDF以及LDA等方法,文檔表示學習由于考慮了詞與詞之間、短語與短語之間以及句子中語義語序等綜合信息,表現出了更加準確且易解釋的文檔表示結果[21]。本文具體使用的文檔表示學習方法是Doc2Vec[22],該方法是Mikolov等[21]基于Word2Vec模型提出的一種神經網絡語言模型。它可以將句子、段落或者文檔表示為一種低維的、實值的向量形式,且向量中的每一維度對應特定的語義信息。Doc2Vec有兩種訓練架構:PV-DM(Distributed Mem‐ory Model of Paragraph Vectors)和PV-DBOW(Dis‐tributed Bag of Words of Paragraph Vector)。對于大多數任務,PV-DM表現較好,所以本文選擇PV-DM法進行訓練。訓練模型的構建主要依賴基于Python語言的主題相似度測度包Gensim[23],該方法已被廣泛應用于文本的特征提取、文本相似度度量以及文本主題聚類等領域。
2.2.2 圖網絡表示學習
圖網絡表示學習是近年來在人工神經網絡領域異軍突起的前沿領域。不同于以往機器學習領域研究對象主要集中在文本、圖像、音頻以及視頻等類型,圖網絡表示學習將研究對象從序列數據和二維化數據擴展到了網絡數據類型上。其研究任務旨在試圖將大規模高維度的動態網絡化數據編碼到低維向量空間中,并盡可能地保留原始數據中的重要特征。
本文所采用的淺層圖卷積神經網絡模型是Node2Vec[24],四種深度圖卷積神經網絡模型分別是GCN(Graph Convolutional Network)[25]、GAT(Graph Attention Network)[26]、GIN(Graph Isomorphism Network)[27]和GNNEXPLAINER(Graph Neural Net‐work Explainer)[28]。Node2Vec是由斯坦福大學Les‐kovec教授團隊提出并被廣泛應用的淺層節點嵌入神經網絡模型算法。該算法將文檔表示學習模型Word2Vec的基本思想遷移到網絡節點表示中,利用帶偏的隨機游走原理平衡了網絡中的同質性以及結構均衡性兩種特征,實現了網絡節點的低維度表征。同類型的淺層圖網絡神經算法還有Deep‐Walk[29]、TADW(Text-Associated DeepWalk)[30]和LINE(Large-scale Information Network Embedding)[31]等。2017年 前 后,Kipf等[25]借 鑒CNN(Convolu‐tional Neural Network)模型,將卷積與池化等概念引入圖神經網絡模型中,被稱作圖卷積神經網絡模型(GCN)。相比于淺層圖神經網絡模型,GCN在多項分類任務中表現出了更高的準確度。同時,此類卷積模型在訓練過程中實現了不同層級神經元之間的參數共享與層數拓展。因此,GCN縮短了網絡表示學習模型的訓練時間,提升了算法的效率。隨后,有學者將自然語言處理中已被驗證有效的注意力機制引入圖神經網絡模型中,并稱之為圖注意力網絡模型(GAT)。此類處理序列數據的算法思想在表征網絡節點特征時同樣取得了良好的效果,并且GAT被認為比GCN在基于半監督學習的節點分類、邊預測等問題上性能更佳。2019年,盡管圖神經網絡算法已經在圖表征學習方面取得了突破性進展,但Xu等[27]認為,先前的深度圖神經網絡學習算法并沒有深入考慮區分潛在的網絡同構現象,因此,提出了圖同構網絡模型(GIN)解決了該問題,并提出了分析GNN模型表征力的理論框架。GNNEXPLAINER的提出,則是試圖解決由于GNN同時融合了節點結構和屬性特征信息,導致無法區分兩種節點特征信息在網絡中的實際影響力差異的問題。這幾項研究將節點嵌入研究從之前淺層的表示方法推向了更具表征能力的深度圖卷積神經網絡方法。
本文選擇上述算法的理由:①Node2Vec作為代表性淺層網絡節點表示學習算法,在本文中用于與其他深度圖表示學習算法得到的結果加以比較對照分析;②GCN和GAT經過近年來的發展已逐漸成為了該領域的兩大類典型算法,GIN算法的獨特之處在于能夠避免網絡中存在的同構問題;③深度圖神經網絡架構的核心優勢是模型通過融合節點的屬性特征以及結構特征,能夠更好地反映出一個現實網絡特征的真實情況,并同時顯著提高模型的運算效率。
2.2.3 流形學習算法
傳統的網絡分析軟件,如NetDraw[32-33]或Gephi等[34],往往難以清晰地呈現出規模龐大的網絡結構。流形學習,又稱作非線性數據降維算法,其主要目的是將高維數據轉換到低維空間中,以便于發現和挖掘出高維數據的淺層語義信息,同時盡可能地在數據轉換過程中保留數據中蘊含的核心特征信息。因此,本文將流形學習算法UMAP應用于高維網絡節點向量的降維可視化過程中[35],以契合本文關于領域知識結構可視化的研究需求。該算法的優點在于運算速度快、計算資源耗費低以及據稱能夠保留高維數據中的全局信息[36]。
2.3 引用網絡構建與社區劃分
本文在分析領域知識結構時選擇了文獻之間的直接引用關系構建網絡。相比于文獻耦合網絡和同被引網絡,直接引用網絡的優勢在于:這兩類網絡實質上是從引文網絡映射衍生出來的網絡形式,不是文獻之間的一級信息關系的表征。通過共同施引關系構建的網絡會很大程度上受到高被引文獻的影響,而通過同被引關系構建的網絡則在文獻選擇方面具有一定的時滯性[37]。
現實世界中的網絡常常具有模塊化特征,即社區內節點相互連接緊密,但社區間節點相互連接稀疏,領域知識結構網絡也不例外。為了有效劃分出網絡的社區結構,復雜網絡科學研究學者提出了基于模塊度計算的劃分算法[38]和基于生成模型推斷的SBM(Stochastic Block Model)算 法[39]。本 文 對 網絡的結構劃分選擇了基于模塊度優化的Louvain社區劃分算法。模塊度優化是NP-Hard(Non-deter‐ministic Polynomial Hard)問題,因此,學者們為解決該問題提出了許多啟發式算法,如層級集聚、極值優化、模擬退火等算法。最終脫穎而出并廣為復雜網絡研究人員所應用的是Louvain算法。通過多種社區劃分算法的比較分析,其被認為是耗時最短、性能最好的算法之一[40-41],并且提出該算法的論文[38]也成為了網絡科學領域中的高被引文獻。需要注意的是,本文運用社區識別算法劃分出網絡的模塊化結構有兩個目的:①作為與其他文檔表示學習算法結果,以及圖神經網絡模型學習表征結果進行比較的基準;②便于清晰地展示運用流形學習算法降維后得到的領域知識結構可視化結果。
3 實證研究
3.1 數據集
為了驗證本文所提出的研究框架在不同學科領域的普適性和有效性,分別選擇了基礎學科領域的代表“物理學”和新興研究領域“區塊鏈”。由于相對更為成熟的基礎學科與新涌現的研究領域知識單元的匯聚程度不同,本文選取了兩個處于不同發展階段的領域,通過對比或許可以揭示不同演化時期領域知識結構的形態差異。
物理學學科:選取1985—2009年美國物理學會(American Physical Society,APS)期刊文獻,并剔除《現代物理評論》600余篇綜述性文章,最終獲得17.4萬篇論文,以及其相互之間產生的65.1萬條直接引用關系。已有研究表明[42],物理學科的各個子領域在這一時間階段保持了較為穩定的發展,學科結構總體上呈現出以“凝聚態”和“理論物理”子領域為核心的中央-邊緣結構特征,處于相對邊緣位置的子領域包括“聲學”“光學”“核物理”“天文物理”以及“交叉物理領域”等。文獻題錄元數據和引用關系數據均從微軟MAG(Microsoft Academic Graph)學術數據中抽取獲得[43]。
“區塊鏈”領域:以Web of Science核心數據庫為數據源,設置檢索式TS=(“blockchain”or“block chain”or“block-chain”),檢索時間跨度為2008年至2020年6月5日。去除掉化學領域同樣使用blockchain作為關鍵詞的無關文獻、題錄信息缺失的文獻以及不在引文網絡最大連通子圖中的文獻后,共剩余3624篇論文及其之間的12549條直接引用關系。從高頻關鍵詞來看,該領域的研究熱點主要有“Smart Contract”(智能合約)、“Bitcoin”(比特幣)、“Internet of Things”(物聯網)和“Distrib‐uted Ledger”(分布式賬本)等。
3.2 實驗環境和參數設置
本文實驗環節主要涉及引文網絡社區劃分、文檔表示學習算法以及圖神經網絡模型的訓練。實驗環境:單機,8核,CPU@3.4 GHz,內存36 GB;編程環境:PyTorch[44]。主要實驗參數的設置參照各類模型和算法的通用設置方法,具體參數如表1所示。

表1 實驗參數設置
3.3 實驗結果
為了探究深度圖神經網絡模型在領域知識結構探測方面的特點,本文開展了多組對照試驗。采用具體的樣本案例分析了模型學習結果,以體現出該方法融合文獻內容特征以及文獻知識結構特征的核心優勢。
3.3.1 領域文獻內容特征及引用網絡結構特征抽取
本文按照圖2中的研究框架思路,首先以文獻引用關系構建直接引文網絡,采用Louvain算法劃分引文網絡社區,并將引文關系及所得的文獻社區結果用于后續圖神經網絡節點分類任務。然后,利用文檔表示學習算法Doc2Vec將預處理后的文獻標題、摘要和關鍵詞數據轉化成為高維向量,以此表征領域文獻集的內容特征。所獲文檔向量也將作為文獻的內容屬性特征嵌入到深度圖神經網絡模型的訓練中。最后,利用網絡分析軟件Gephi和UMAP降維算法分別可視化引文網絡和高維領域文本特征。具體結果如圖3和圖4所示,其中,節點代表文獻,顏色表示所屬社區。
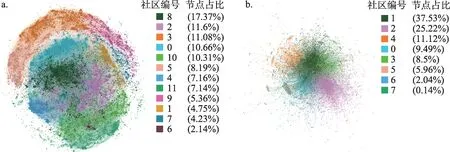
圖3 物理學科(a)和“區塊鏈”(b)領域直接引用網絡社區劃分結果(彩圖請見http://qbxb.istic.ac.cn/CN/volumn/home.shtml)

圖4 基于UMAP降維的物理學科(a)和“區塊鏈”(b)領域文本內容可視化結果(彩圖請見http://qbxb.istic.ac.cn/CN/volumn/home.shtml)
由圖3可以看出,物理學科和“區塊鏈”領域的引用網絡均展示出了較為清晰的模塊化結構。具體來說,物理學科直接引用網絡結構的模塊度是0.81,最終劃分出了12個社區;區塊鏈領域引文網絡模塊度是0.46,劃分出8個社區。需要注意的是,后續文檔表示學習模型以及神經網絡模型的結果都將以引文網絡社區劃分的結果作為基準。領域知識網絡結構可視化階段的著色以及圖神經網絡模型中的標簽,都將以文獻節點的引文關系社區劃分結果作為參照。基于文檔表示學習和流形學習算法得到的領域文本內容分析結果如圖4所示。
對比兩者可視化結果發現,物理學科的引文社區呈現出更好的聚集特征,而“區塊鏈”領域的內容分析結果與引文網絡社區結果更加不一致,表現為同類引文社區在內容上聚集程度較低。按照引文網絡社區著色后能夠更加明顯地發現,文檔表示學習的確可以對較為成熟的物理學科知識結構進行良好的表征和度量。但對于新興“區塊鏈”領域來說,文檔表示學習與引文網絡結構社區劃分方法得到的結果差異相對較大。其原因或在于,新興領域處于早期探索階段,與其他領域相融合的態勢初步顯露但尚未形成明晰的主題或子領域,不同研究內容的論文被該領域學者選入參考文獻列表中,從而導致同一引文社區內文獻的實際研究主題并不高度相似。
總而言之,上述結果顯示,一方面,這兩個領域知識結構呈現出相近知識單元互相匯聚、相異知識單元彼此分離,但不同主題的知識單元之間的由跨主題知識單元橋接串聯的基本結構特征。另一方面,從模塊化程度的差異也看到,相對更為成熟的基礎學科要比新涌現的研究領域其模塊化程度顯著更高,反映出不同學科領域的發展階段和科研活動的差異性。
3.3.2 多層感知機與淺層圖神經網絡模型結果
為了對比僅嵌入文獻內容特征、僅學習表征文獻引用網絡結構特征以及融合兩者特征信息的神經網絡模型結果,本文以嵌入了文獻文本主題特征的多層感知機(Multi-Layer Perceptron,MLP)和淺層圖神經網絡模型Node2Vec開展了領域知識結構探測實驗。需要注意的是,MLP的局限在于模型中神經元無法通過訓練迭代學習到文獻網絡的引用結構信息;Node2Vec模型則無法嵌入文本的內容特征信息。具體來說,將上一階段用文本學習算法獲得的文本特征嵌入MLP作為輸入層,500輪訓練后,MLP測試準確度趨于穩定,不再顯著提升。以引文網絡的社區劃分結果作為基準,MLP的測試集精度維持在0.63(物理)附近,Node2Vec圖神經網絡模型的測試集精度結果大約在0.84(物理)。兩類神經網絡模型對領域知識結構的探測可視化結果如圖5和圖6所示,其中,節點代表文獻,顏色表示所屬社區。
圖5 和圖6的實驗結果表明,嵌入了文本內容主題特征的多層感知機和能夠學習表征引用關系特征的淺層圖神經網絡模型均可以在一定程度上探測識別出文獻知識單元之間的匯聚特征。相較而言,淺層圖神經網絡模型已經比多層感知機模型取得了更好的表征效果。但是,這兩類模型共同的缺點是無法同時綜合文本內容和引用結構信息,因此,本文引入了深度圖神經網絡模型,以更加精準地探測出學科的領域知識結構。
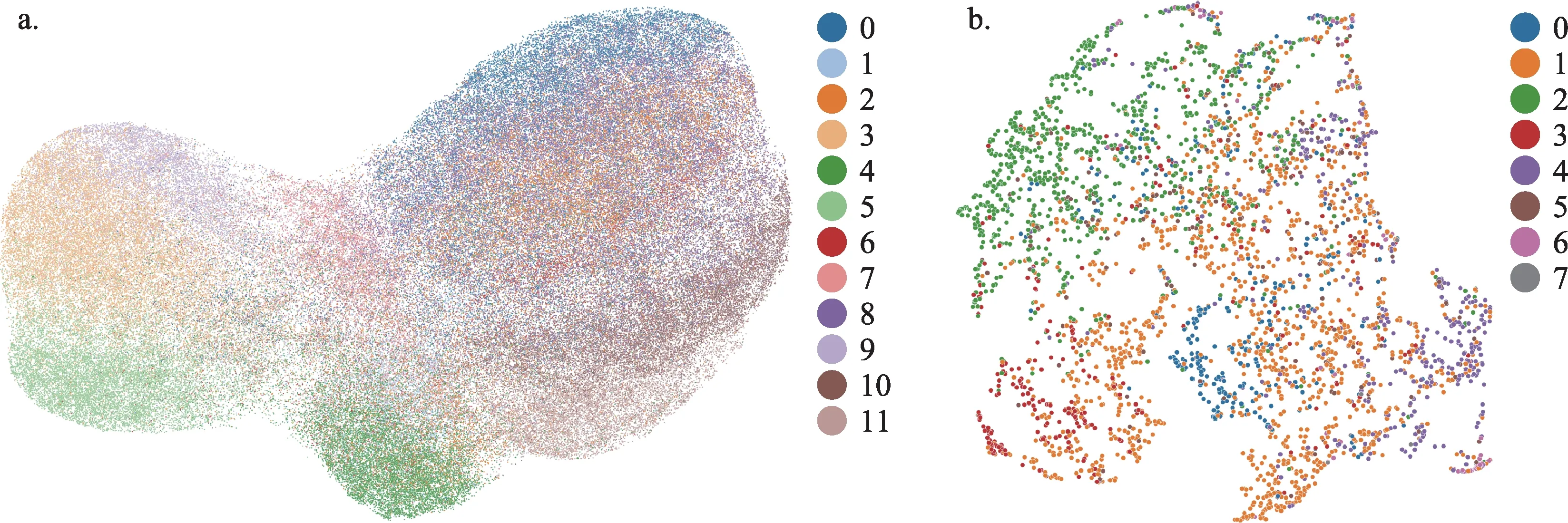
圖5 僅嵌入文獻主題特征的物理學(a)和“區塊鏈”(b)MLP模型結果(彩圖請見http://qbxb.istic.ac.cn/CN/volumn/home.shtml)
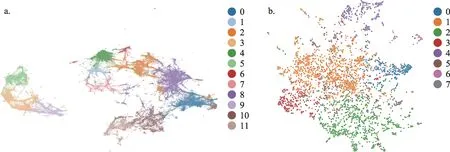
圖6 僅表征文獻引用網絡結構特征的物理學(a)和“區塊鏈”(b)Node2Vec模型結果(彩圖請見http://qbxb.istic.ac.cn/CN/volumn/home.shtml)
3.3.3 深度圖神經網絡模型結果
本文將運用三種代表性的新型深度圖神經網絡模型對物理學和“區塊鏈”領域的知識結構開展探測實驗,包括GCN(圖卷積神經網絡)模型、GAT(圖注意力神經網絡)模型以及GIN(圖同構神經網絡)模型。主要實驗步驟如下:首先,準備深度圖神經網絡輸入層和訓練過程所需的三類數據,即預先訓練完成的文獻內容表征數據、文獻之間的引用關系數據以及作為預測標簽的引文網絡社區數據。其次,搭建和設計神經網絡。本文三組實驗均采用了1層輸入層、2層隱藏層、1層輸出層的神經網絡結構。在模型初始化過程中,設置每個節點的屬性維度及擬輸出的節點嵌入向量維度。實驗具體涉及的激活函數、優化器和損失函數等參照了現有模型中的常規參數配置方式。最后,500輪次學習訓練后,三種類型的GNN模型精度不再顯著提高,保持在了相對穩定的水平,模型訓練終止。仍然以引文網絡社區劃分結果作為節點標簽空間來看,GCN、GAT以及GIN在精度上分別達到了0.869(物理)和0.819(區塊鏈)、0.848(物理)和0.728(區塊鏈)、0.885(物理)和0.780(區塊鏈)。將三種不同模型訓練學習后得到的節點向量利用UMAP降維后,得到的領域知識結構可視化結果如圖7所示。其中,節點代表文獻,顏色表示所屬社區。

圖7 融合文獻內容特征和引用網絡結構特征的物理學和“區塊鏈”深度神經網絡模型結果(彩圖請見http://qbxb.istic.ac.cn/CN/volumn/home.shtml)
由圖7可以看出,與圖5和圖6中的實驗結果相比,融合了文獻內容和網絡結構特征的領域知識結構分類結果更加清晰、噪音節點或隨機分布節點更少。相比于其他方法,其計算資源耗費更少,計算時長更短。以物理學數據集為例,在第3.2節所述的實驗環境下,同等規模采用Node2Vec模型實驗500次訓練耗時48小時,而GCN模型訓練耗時僅為52分 鐘,GAT訓 練耗 時2小時23分 鐘,GIN訓 練耗時2小時3分鐘,并且后三種GNN模型的節點可以同時融入文獻特征信息進行訓練,表征學習能力更強。
但是,由于兩種類型的網絡規模過大,即便從宏觀層面上領域整體知識結構已經被清晰地可視化,但微觀視角下節點層面的分類結果,即同時融合內容特征和結構特征的特點尚未得到明確顯現。因此,有必要選取文獻樣例,以具體地展現深度圖神經網絡模型的優勢。本文選擇了“區塊鏈”領域具有代表性的兩篇文獻,考察了在深度圖神經網絡模型學習過程中,與這兩篇關系最緊密的相鄰節點子圖結構。選擇這兩篇論文的依據是:第一篇文獻雖然在引文網絡社區中被劃分到了同一個類別,但在文檔表示學習實驗中,文本內容向量與同網絡類別的其他文獻差異顯著;第二篇文獻雖然在文檔表示結果中向量距離相近,但在引文網絡中是跨社區節點。這兩篇文獻分別代表了前文提到的單一的文本內容表征學習和引文網絡結構探測領域知識結果潛在的問題和方法局限。借助GNNEXPLAINER模型,得以呈現出GNN模型具體學習到的相鄰節點屬性特征以及結構特征。
圖8 和圖9展示了上述兩篇文獻在深度圖網絡模型學習過程中影響最大的節點的子圖,其中節點顏色區分引文社區,邊顏色的透明程度反映鄰居節點對該節點的影響程度。與節點的原始引文網絡關系子圖所不同的是,圖8和圖9中的文獻關聯子圖是節點同時融合了內容特征和引文關系特征的子圖。因此,對于特定的文獻來說,由于深度圖神經網絡會同時考慮到相鄰文獻之間的內容特征差異程度,盡管存在多條施引或者被引關系,但不一定所有的引用關系都在影響該文獻的知識單元分類結果。
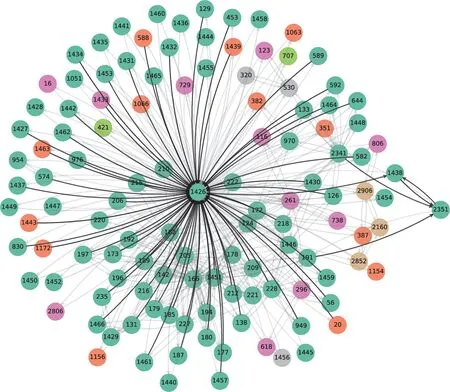
圖8 同一引文社區中文本內容差異顯著的文獻在GNN中的核心關聯節點(ID:1438)
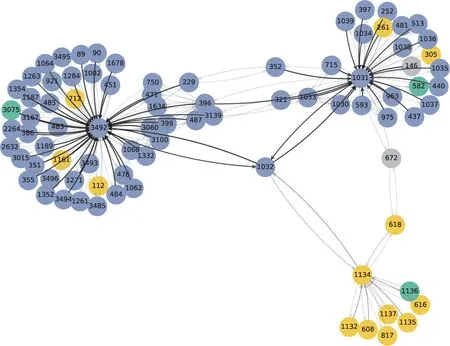
圖9 文本內容相近但所屬不同引文社區的文獻在GNN中的核心關聯節點(ID:1032)
3.4 討論
從研究結果來看,本文所提出的領域知識結構探測研究方法既考慮了文獻的內容特征,又融合了文獻之間的引用關系特征,可以更加準確地探測學科領域的知識結構,以應對和解決當前大數據時代背景下復雜網絡信息的規模性、高維性和動態性等問題。基于深度圖神經網絡模型的探測手段要比傳統的領域知識結構方法具備三個方面的優勢:可預測性、規模可擴展性以及更強的適應性。
可預測性是指深度圖神經網絡模型不需要所有節點的標簽特征就可取得更好的節點分類結果。盡管在本研究中,所有節點的標簽都是以引文網絡社區劃分的結果作為基準,但已有研究表明,圖神經網絡實際上只需5%~20%的真實節點標簽,通過學習就能夠使節點分類任務精度高達80%左右[45]。這為與領域知識探測相關的其他研究提供了更廣闊的探索空間。例如,在文獻分類問題上,可以與專家分析法相結合,通過專家標注少量子領域文獻完成對整個更大領域的關聯文獻分類的任務。
規模可擴展性是指在同等計算資源條件下,深度圖神經網絡模型比傳統的基于引文網絡的領域知識探測算法以及淺層圖神經網絡模型更適合處理大規模的領域知識網絡;并且,模型學到的大規模高維節點特征可以通過流形學習算法降維轉化為低維向量,進而用于可視化處理分析,其聚類結果也更易理解且具備解釋性。
適應性是指盡管領域知識結構網絡往往是動態變化的,但深度圖神經網絡模型無需因為少量節點和邊關系的調整變化就重復學習整個網絡。傳統的網絡聚類或者文本分析方法,由于其研究對象基本上只停留在靜態網絡結構分析中,而無法適應現實領域知識網絡中文獻內容和引用關系動態變化的情況。深度圖網絡模型具有半監督學習的特征,因此,有學者提出了時序圖神經網絡模型[46],適用于預測變動的領域知識單元及其關聯關系特征。
總之,在識別領域知識結構方面,借助深度圖神經網絡的網絡表示學習方法是更具前景、更順應大數據及人工智能時代發展的研究范式和研究手段。
4 結論
針對目前領域知識結構探測方法中,文本內容分析方法和引文網絡分析方法存在的局限性,本文提出了基于深度圖網絡學習方法的研究框架,融合了兩類主流方法的各自優勢。為了驗證本文所提方法的有效性,分別選擇了代表基礎學科的物理學和代表新興學科的區塊鏈領域進行實證分析。實驗結果表明,深度圖網絡學習方法能夠更清晰地識別出領域知識結構。基于深度圖神經網絡算法的結構探測思路或許是更適應當前大規模復雜網絡信息時代的新興研究范式。受個人機計算資源的限制,本文僅驗證了兩個學科領域,后續研究擬借助超算平臺,將該方法思路拓展到更大范圍的學科領域,例如,對整個自然學科的文獻進行學科領域識別及其可視化,以充分發揮出該研究思路的特點和優勢。同時,后續考慮進一步拓展和豐富基于領域知識度量的科研活動模式與規律的探索和研究。由于本文結合多種深度學習模型方法,未來工作將通過多組消融實驗,如調整隱藏層層數、神經元數量、文本特征向量維度、訓練輪次等,以進一步提高模型的精度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
