基于多任務學習和多態語義特征的中文疾病名稱歸一化研究
2021-11-25 09:32:08張展鵬
情報學報 2021年11期
韓 普,張展鵬,張 偉
(1.南京郵電大學管理學院,南京 210003;2.江蘇省數據工程與知識服務重點實驗室,南京 210023)
1 引言
近年來,隨著互聯網的飛速發展和公眾信息素養的提升,微博、微信和在線健康社區等社會化媒體逐漸成為人們獲取、傳播和分享醫療健康知識的重要渠道,這些平臺所產生的海量在線醫療健康數據已經成為醫療實體識別[1-2]、流行病預測[3-4]、情感分析[5-6]和藥物不良反應[7-8]等多個研究的重要數據源。與電子病歷中的專業化表述相比,在線醫療健康文本缺乏醫療術語規范,存在大量的疾病指稱和口語化表達,這對在線醫療健康信息抽取和知識挖掘帶來了極大的挑戰。在這種背景下,將用戶的非標準化表述映射到標準醫學術語的疾病名稱歸一化任務[9-10],受到了醫療健康信息抽取、知識庫和知識圖譜構建以及領域知識挖掘的重點關注[11-12],目前已經成為自然語言處理和信息抽取中的一個重要研究領域。
疾病名稱歸一化任務的主要挑戰表現是在線醫療健康文本中疾病指稱與標準術語往往并沒有字面上的關聯,基于規則的方法難以從字符層面實現歸一化;另外,在線醫療健康文本中的疾病指稱與標準術語存在一對多或多對多等復雜關系,傳統方法難以挖掘深層語義信息。與英文相比,中文文本表達方式和語法結構更為復雜,詞匯間無分隔符號,一詞多義和同形異義的現象較為普遍,導致語義分析的難度更大[13]。另外,中文疾病名稱構詞更為復雜,存在大量縮寫和翻譯詞匯,也缺少類似于UMLS(unified medical language system)和SNOMED CT(the systematized nomenclature of human and vet‐erinary medicine clinical terms)的疾病名稱知識庫資源[14-15],使得中文疾病名稱歸一化面臨著更大的挑戰。與通常的術語相比,中文疾病名稱專業性更強,尤其是在線醫療健康社區中不同用戶的表述多種多樣,并且有許多名稱是從外文翻譯而來,這些因素導致中文疾病名稱歸一化難度也遠大于普通的術語標準化。
本研究基于多任務學習視角,將CNN(convo‐lutional neural networks)、GRU(gated recurrent unit)、LSTM(long short-term memory)、BiGRU(bidirectional gated recurrent unit)、BiLSTM(bi-di‐rectional long short-term memory)與BERT(bidirec‐tional encoder representations from transformers)相 結合,以捕獲靜態和動態語義信息;同時引入注意力權重詞典作為輔助任務生成注意力矩陣以調節靜態向量,并將疾病名稱歸一化轉化為分類任務;最后在中文數據集上進行實驗,以驗證多任務學習對中文疾病名稱歸一化的效果。
2 相關研究概述
根據所采用的研究方法,疾病名稱歸一化可以分為無監督學習和有監督學習。在有監督學習方法中,多任務學習和BERT是學界近期的關注重點。
2.1 無監督學習
無監督學習方法主要是指采用字典查找或字符串匹配的方法進行歸一化。Ristad等[16]利用編輯距離計算字符串間的相似度,將歸一化任務轉化為相似度排序問題。2010年,美國醫學圖書館年發布了MetaMap工具[17],它首先通過詞典遍歷和淺層句法分析來識別名詞短語,然后將生物醫學文本與UMLS的CUIs建立映射關系。Tsuruoka等[18]利用邏輯回歸計算字符串相似度以實現歸一化,其效果優于傳統的規則匹配方法。Yang[19]從UMLS和SNOMED CT中提取了疾病相關特征,并改進了基于規則的歸一化方法。基于MetaMap工具,Khare等[20]建立了疾病和藥物的映射關系,并將藥物描述中的疾病作為候選名稱,結果表明該方法在疾病名稱歸一化上可達到較好的效果。基于UMLS中的疾病變體規則,Kate[21]提出了自動學習臨床術語變體的模型,從而對未包含在知識庫中的術語進行歸一化。Jonnagaddala等[22]提出了基于詞典查找的方法進行疾病名稱歸一化,并引入同義詞增強詞典以進一步提升實驗效果。通過上述分析可知,一方面,傳統的無監督學習方法依賴權威的醫學詞典或知識庫,難以應對未收錄疾病和疾病指稱的情況;另一方面,該方法主要利用語言形態信息進行處理,難以結合深層語義信息進行疾病名稱歸一化。
2.2 有監督學習
有監督學習方法主要是指利用機器學習或深度學習模型進行任務分類的方法,該方法往往將疾病描述文本與疾病名稱匹配視為文本分類任務,通過模型學習疾病描述特征表示以預測疾病分類,從而實現疾病名稱歸一化。基于成對學習思想,Leaman利用機器學習模型,構建了英文疾病名稱歸一化系統DNorm(disease name normalization)[10]。該系統利用計算相似度矩陣預測疾病描述文本與候選疾病名稱的關系,其F值在NCBI(National Center for Biotechnology Information)疾病數據集實驗中較MetaMap提升了25%。Shi等[23]利用字符級感知神經網絡學習書面診斷描述和ICD(international cassifi‐cation of diseases)編碼的隱藏表示,并引入注意力機制,實現了書面診斷與ICD編碼的歸一化映射。Liu等[24]利用word2vec和TreeLSTM生成了分布式特征表示并提取候選疾病名稱,通過計算疾病描述和候選疾病名稱間相似度進行分類,在英文數據集上取得了較好的實驗結果和較高的魯棒性。通過學習文本內在語義關系,Limsopatham等[25]發現CNN在疾病名稱歸一化上的效果優于RNN(recurrent neu‐ral network),其實驗準確率較DNorm高出13.79%。基于形態和語義信息,Li等[26]通過CNN計算疾病指稱和候選疾病名稱的語義相似度實現了生物醫學概念歸一化,實驗結果明顯優于基于規則的方法,驗證了引入語義特征可提高疾病名稱歸一化效果。Tutubalina等[27]提出了基于注意機制的雙向LSTM及GRU,并引入UMLS的TF-IDF(term frequencyinverse document frequency)特征和語義相似性特征,進一步驗證了語義特征對疾病名稱歸一化的影響。Huang等[28]基于RNN和CNN實現了MIMIC-III(medical information mark for intensive care)數據集到ICD編碼的映射,研究結果驗證了RNN和CNN較傳統的邏輯回歸和隨機森林等模型的疾病名稱歸一化效果均有明顯提升。
與無監督學習相比,有監督學習不但彌補了無監督學習中無法處理未收錄疾病名稱的不足,而且通過大規模訓練數據學習疾病特征,可充分利用文本語義信息進行疾病名稱歸一化。
2.3 多任務學習
多任務學習可聯合訓練多個子任務,通過共享參數提高模型的學習效率和泛化能力,近期在自然語言處理領域受到了學界的重點關注。Collobert等[29]在詞性標注、命名實體識別和語義角色標注等任務中,提出了基于多任務學習的CNN模型,驗證了多任務學習在自然語言處理上的優異表現。Liu等[30]基于LSTM設計了三種信息共享機制,使用特定任務的共享層對文本進行建模,研究發現子任務可以提升主分類任務效果;另外,Liu等[31]還在文本分類中提出對抗性的多任務學習框架,避免了共享和私有兩種特征的相互干擾,實驗結果表明所學習的共享知識可被遷移到新任務中。Yang等[32]以ELMo(embeddings from language models)作為向量嵌入提出了基于注意力的多任務BiLSTM-CRF模型,在電子病歷數據集上進一步提升了醫療實體識別和歸一化效果。Niu等[33]基于多任務學習思路提出了字符級CNN模型進行疾病名稱歸一化,較好地解決了未登錄詞的問題,并引入注意力機制優化模型效果,實驗結果在AskApatient數據集上達到了84.65%的準確率。由上文可知,在自然語言處理任務的不同應用場景中,多任務學習得到了廣泛的應用。本文將多任務學習思想引入中文疾病名稱歸一化研究中,利用多任務學習能夠共享多個子任務間參數以共同提升主任務的優勢,進一步推動中文疾病名稱歸一化研究進展。
2.4 BERT
BERT[34]是一種基于轉換器的雙向編碼表征模型,在多個自然語言處理任務中表現優異[35-36]。Li等[37]對大規模標注的電子健康檔案進行了BioBERT微調,進一步訓練了EhrBERT、BioBERT和BERT,研究結果發現,這些模型在疾病名稱歸一化上的效果均優于DNorm。Xu等[38]基于BERT設計了列表分類器并利用正則化UMLS語義類型對候選概念進行排序,在疾病名稱歸一化上達到了較高的準確率。Ji等[39]基于微調預訓練的BERT、BioBERT和Clini‐calBERT進行疾病名稱歸一化,在ShARe/CLEF、NCBI和TAC2017ADR三種不同類型數據集上的實驗均表明微調模型明顯優于基線方法。此外,Kalyan等[40]提出了一種基于BERT和Highway的醫學概念標準化系統,研究發現在CADEC和PsyTAR數據集上的效果優于傳統方法。本文基于多任務視角,結合當前主流的BERT模型,綜合利用文本形態信息和深層語義信息進行中文疾病名稱歸一化實驗,并引入多態語義特征以改進模型效果。
3 模型設計
本文設計的MTAD-BERT-GCNN模型結構如圖1所示。首先,根據好大夫、求醫問藥、好問康、THUOCL(THU Open Chinese Lexicon)、CCKS2017(China Conference on Knowledge Graph and Semantic Computing-2017)和ICD-10(International Classifica‐tion of Diseases-10)分別構建實驗數據集、特征訓練語料和注意力權重詞典;其次,利用word2vec和Glove在特征訓練語料上生成字詞向量;接著分別將疾病描述文本轉化為向量輸入到子任務;然后利用GCNN(graph convolutional neural network)和BERT同時對輸入向量進行特征訓練和提取,并引入注意力權重詞典以調節向量表示質量;最后,根據Softmax函數實現疾病名稱歸一化。其中,BERT輸入的是動態語義向量,GCNN輸入的是靜態語義向量。因此,MTAD-BERT-GCNN模型可以通過多任務學習捕獲特征向量的靜態和動態語義信息,并利用共享權重參數優化多個子任務深度挖掘語義信息,從而提升實驗效果。
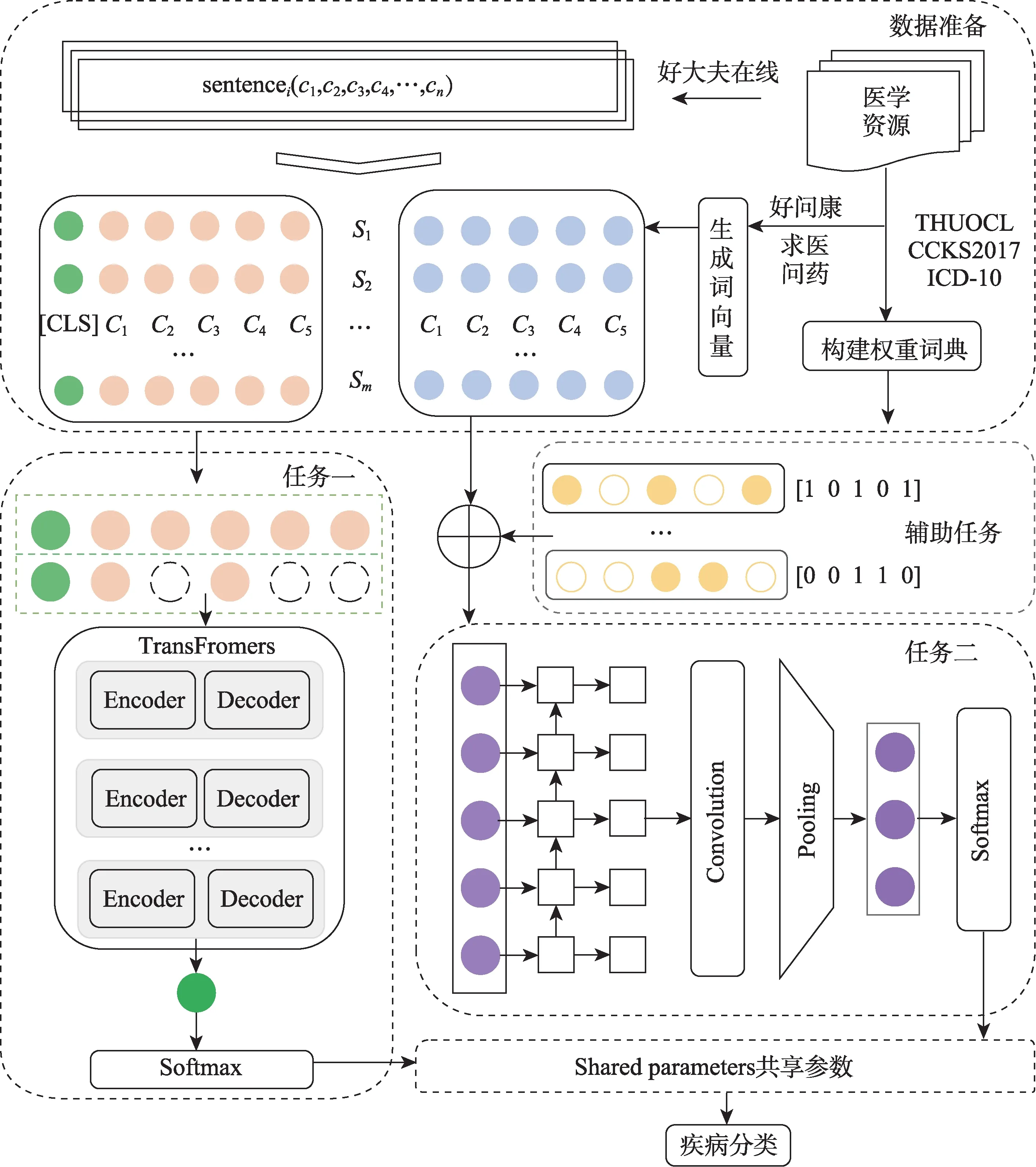
圖1 MTAD-BERT-GCNN模型結構圖
3.1 數據準備
1)構建實驗數據集
由于國內缺少公開的疾病名稱歸一化數據集,本文參照英文疾病名稱歸一化評測任務,構建了中文疾病名稱歸一化數據集(Chinese Disease Normal‐ization Data,ChDND)。具體過程包含兩部分。一是數據獲取及處理。從好大夫在線網站爬取了46140條疾病描述和537個疾病名稱,參照已有研究[27,41],去除出現頻次少于10的疾病名稱及其對應描述,并分別生成詞級和字級疾病描述;二是建立映射關系。基于網站的類別信息,將疾病描述與對應疾病名稱建立多對一的映射關系。最后,本文構建的數據集ChDND包含了407個疾病名稱和42891個疾病描述,平均每個疾病名稱對應105個疾病描述。數據集ChDND的示例如表1所示。

表1 中文疾病數據集實例
2)生成特征向量
基于求醫問藥和好問康在線醫療社區問答語料,利用word2vec和Glove兩種詞向量訓練模型,生成具有局部和全局語義特征的多特征融合向量,并作為本實驗靜態語義向量的輸入。BERT預訓練向量是谷歌提供的中文預訓練模型BERT-Base-Chinese。
3)構建注意力權重詞典
引入醫學詞典構建注意力權重詞典以提高領域關鍵詞的權重,降低非專業化表述的影響,進而提升關鍵特征的提取效果。本實驗所采用的醫學詞匯,一方面,來源于ICD-10和THUOCL中的專業醫學詞匯;另一方面,抽取了CCKS2017電子病歷數據集中的所有醫療實體。其中,ICD-10是國際疾病分類,包含1587個疾病類別,本實驗提取了5634個疾病特征詞匯;THUOCL是清華大學NLP組構建的中文詞庫,詞表來自主流網站的社會標簽、搜索熱詞和輸入法詞庫,本實驗提取了18749個專業醫學詞匯;CCKS2017是2017年全國知識圖譜與語義計算大會中文電子病歷命名實體識別競賽數據,包含2505條電子病歷,本實驗提取了13802個高頻實體詞匯。此外,ICD-10是標準的醫學術語,THUOCL中的醫學詞匯符合醫學術語規范;相比而言,經CCKS2017提取的詞匯主要來自電子病歷中醫生表述,其規范性略低于醫學詞典。
3.2 關鍵技術
1)LSTM
長短時記憶網絡[42](LSTM)是RNN的變體,它可解決文本序列中的長期依賴問題,該模型由忘記門、輸入門和輸出門組成。其中,忘記門決定細胞狀態丟棄的信息;輸入門添加細胞狀態中的新信息;輸出門則判斷細胞的狀態特征,聯合輸入層中的細胞狀態計算得到最終輸出。
2)GRU
GRU[43]是LSTM的變體,它將三門結構替換為更新門和重置門兩門結構,優化了網絡結構,在聯動表達式將前一節點和當前節點相結合以更新單元記憶。
3)BiLSTM、BiGRU
LSTM和GRU均采用正向傳播算法,僅能獲取文本序列正向的上文語義信息,而忽略了后向序列的語義影響。BiLSTM和BiGRU可以通過正反傳播獲取上下文全局語義特征。
4)CNN
卷積神經網絡[44](CNN)是一種前饋神經網絡,它通過多個卷積核提取文本信息。該模型包含輸入層、卷積層、池化層、連接層和輸出層。其中,輸入層將向量轉換成張量矩陣;卷積層提取輸入向量的局部特征和位置編碼信息,利用卷積核進行首次特征提取;池化層對文本向量進行二次特征提取,通過降維保留關鍵信息;全連接層用于拼接和擬合池化后的特征向量以降低模型損失值;輸出層根據任務目標選擇不同函數并輸出相應結果。
5)BERT
BERT是一種基于轉換器的雙向編碼表征模型,具有強大的特征提取功能。Transformer[45]是BERT的主要框架,它基于自注意力機制能夠更全面地捕捉語句間的雙向關系;BERT基于掩藏語言模型(mask language model,MLM)突破了單項語言模型的限制,利用MASK隨機替換輸入特征以提高模型對特征的辨識度。在具體分類任務中,BERT在每條數據前插入[cls]標記,并將Transformer輸出結果匯總到該標記,從而實現整個輸入序列的信息匯總,從句向量角度實現分類任務。
3.3 多任務
1)任務一
任務一基于動態語義向量進行BERT微調和疾病描述映射。首先,文本Si經過數據準備階段轉化為向量矩陣Ci=([cls],c1,c2,c3,…,ci,…,cn)并輸入到該任務,ci可與BERT預訓練嵌入層建立唯一映射關系;其次,BERT將輸入向量轉化為字向量特征Wi、位置特征Posi和分割嵌入Segi三種嵌入特征,并將三特征求和作為新的輸入向量矩陣,其中Segi在單句文本分類時記為0;接著,BERT經多層Transformer生成微調后的動態語義向量,輸入到下游任務計算分類向量CLSi=(cls1,cls2,cls3,…,clsi,…,clsn);然后,利用Softmax函數結合訓練的最佳權重和偏置(W1i和b1i)將CLSi轉換為概率向量Pi=(p1,p2,p3,…,pl),其中,pi為疾病描述文本映射到候選疾病名稱的概率;最后,利用交叉熵函數計算該任務損失,具體公式為
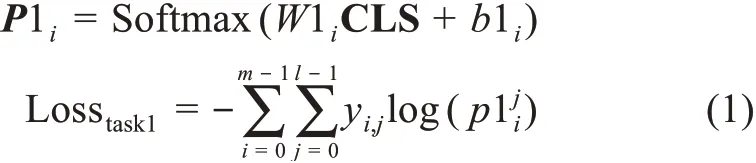
2)任務二
任務二基于靜態語義向量進行特征挖掘和疾病描述映射。首先,文本Si經過數據準備階段轉化為字符向量矩陣Ci=(c1,c2,c3,…,ci,…,cn)輸入到該任務,ci可與多特征融合嵌入層建立唯一映射關系;其次,利用GRU訓練向量矩陣,增強輸入文本序列間語義關系,計算得到向量矩陣Hi;接著,利用CNN提取該向量矩陣中的重要信息,保留輸入文本的關鍵語義特征,經過卷積池化后得到向量矩陣Fi;然后,利用Softmax函數結合訓練得到的最佳權重和偏置(W2i和b2i)將Fi轉換為概率向量Pi=(p1,p2,p3,…,pl),其中pi為疾病描述文本映射到候選疾病名稱的概率;最后,利用交叉熵函數計算該任務損失,具體公式為
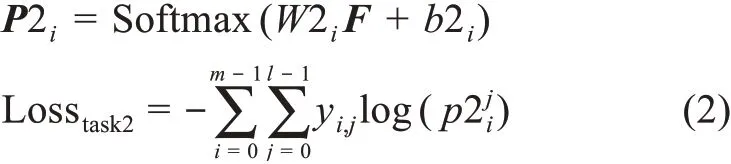
3)輔助任務
輔助任務可提取任務二中輸入文本的關鍵詞注意力權重。首先,將任意輸入文本Ti=(t1,t2,t3,…,ti,…,tn)與注意力權重詞典建立映射;其次,當輸入文本的詞匯在注意力權重詞典出現時,將該位置標記為1,否則標記為0,得到一個注意力矩陣ATi=(at1,at2,at3,…,ati,…,atn),其中ati=0,1;再次,將該矩陣ATi與任務二中的Ci矩陣相乘計算得到C_ATi,該向量經任務二特征提取得到向量矩陣F_ATi;最后,計算融入注意力權重后的概率向量P2i,具體公式為
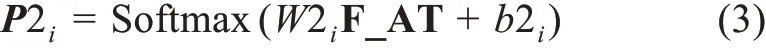
4)共享參數
多任務學習中,多個關聯任務間通過損失函數相互調節以共享信息,并優化參數,分別反饋到每個子任務以提高模型效果。其中,共享損失函數為
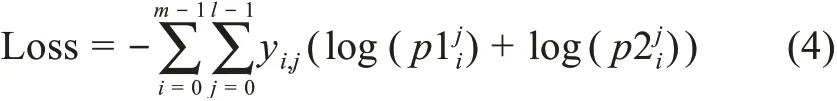
具體共享參數流程如圖2所示。
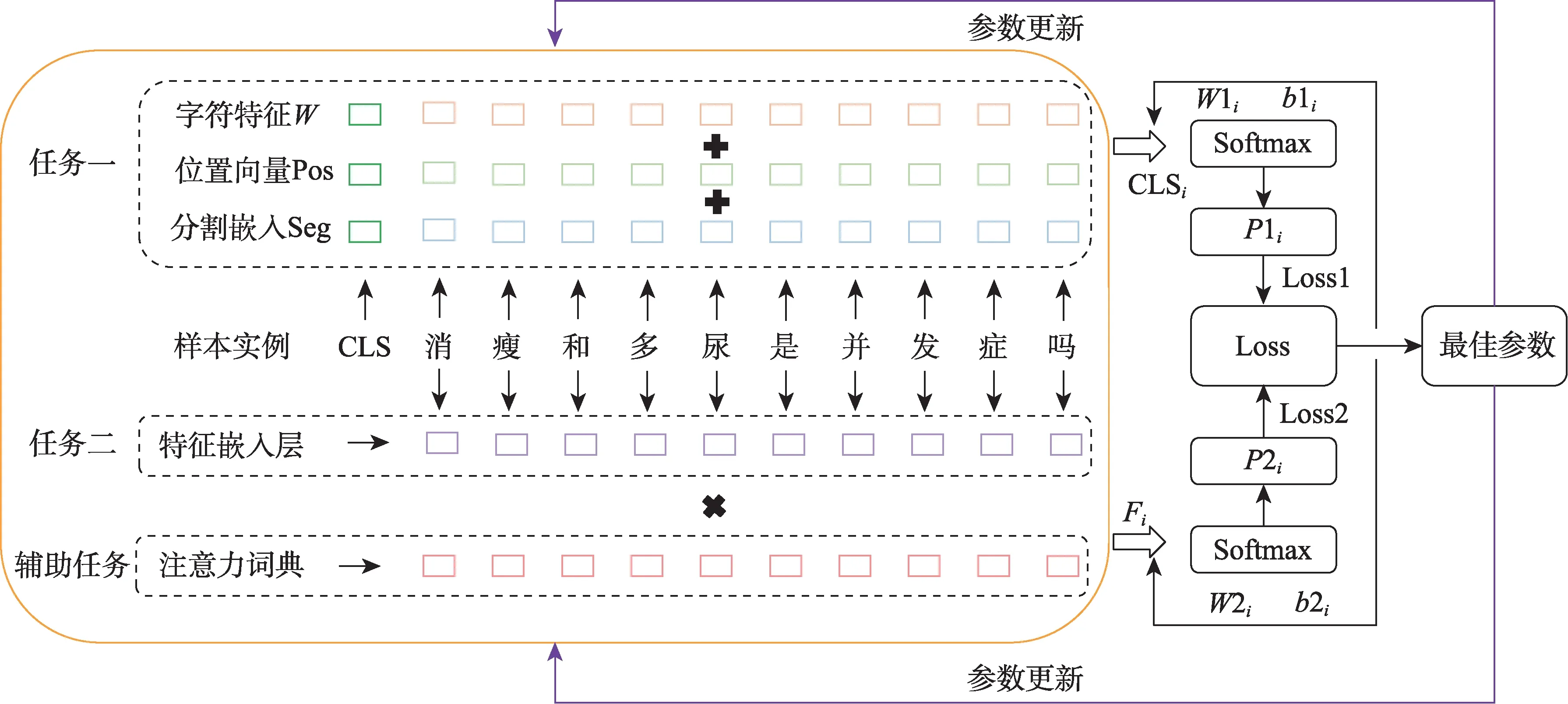
圖2 多任務共享參數流程
4 實驗分析
4.1 實驗設計
本文實驗目的如下。
(1)驗證基準模型在中文疾病名稱歸一化任務上的效果。
(2)驗證引入語義關系對中文疾病名稱歸一化實驗的影響。
(3)驗證引入多任務學習對中文疾病名稱歸一化實驗的影響。
基于上述實驗目的,本文共設計了三組對照實驗。每組實驗均采用五折交叉驗證,按7∶2∶1劃分為訓練集、驗證集和測試集,具體設計如下。
實驗一:對比分析CNN-WRv(CNN中嵌入詞級隨機向量)、CNN-CRv(CNN中嵌入字級隨機向量)、CNN-WGv(CNN中嵌入外部語義特征)以及BERT-Base(基于預訓練BERT進行微調)的實驗效果。
實驗二:在實驗一中實驗效果最佳CNN的基礎上,分別引入GRU、LSTM、BiGRU和BiLSTM訓練語義關系,分析語義訓練后不同特征向量對中文疾病名稱歸一化的影響。
實驗三:基于多任務學習,將實驗一和實驗二中表現最優的模型相結合,驗證多任務學習對中文疾病名稱歸一化的效果,并在此基礎上引入計算注意力權重的輔助任務,分析調節向量權重后模型對實驗的影響。
具體實驗思路如圖3所示。
4.2 實驗環境
本實驗環境是一臺內存20 GB、CPU型號為In‐tel(R)Core i5-7600K CPU、頻率3.80 GHz、GPU為型號Nvidia GeForce RTX 2080 Ti、顯存11 GB、操作系統為Windows 10的服務器。此外,實驗中還使用了jieba分詞庫、哈工大LTP語言云、word2vec和Glove詞向量訓練工具、BERT和Tensorflow框架。開 發 環 境 為python 3.6、Tensorflow 1.13、keras 2.2.4、cuda10.0、cudnn 7.3.1。
4.3 實驗參數
本實驗中的具體參數設置如表2所示。
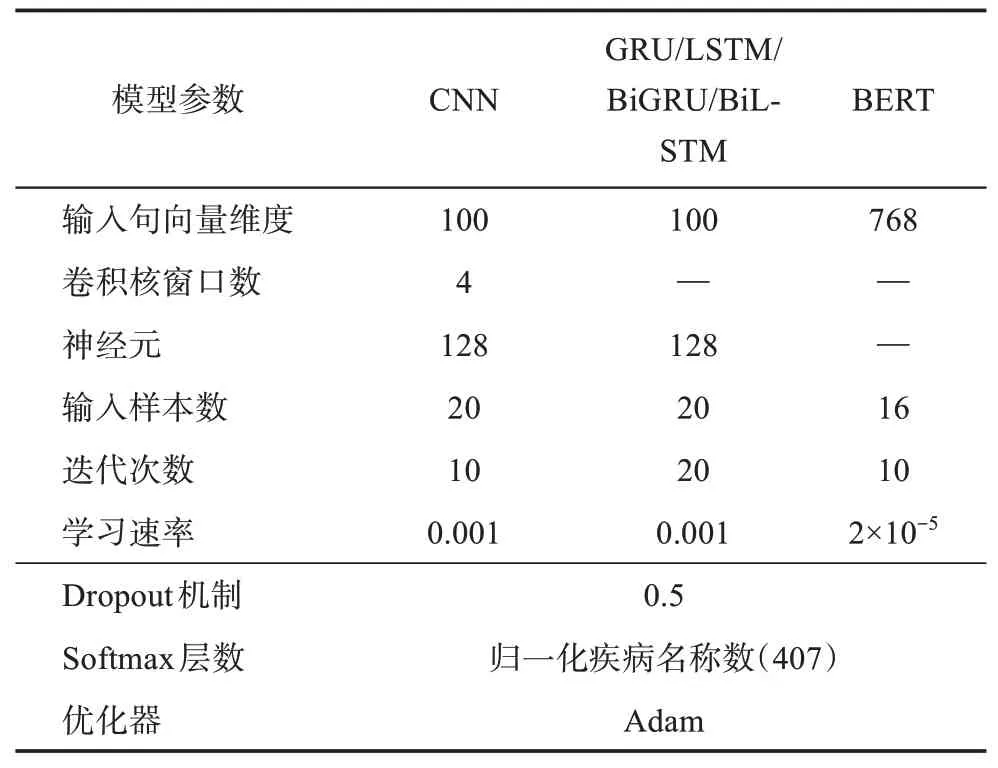
表2 模型參數設置
4.4 評價指標
參照已有研究[14,46-47],本實驗采用準確率(Ac‐curacy)指標進行歸一化評價,利用Accuracy@k評估疾病名稱歸一化效果,Accuracy@k表示前k個預測疾病中正確結果的占比。分別取排名前1、5和10個疾病作為預測疾病,計算Accuracy@1、Accura‐cy@5和Accuracy@10。由于多分類任務中難以計算負樣本對結果的影響,本實驗的歸一化評價指標為
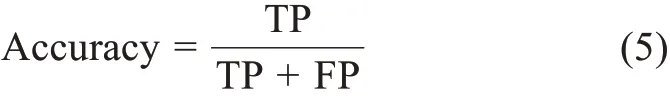
其中,TP為判斷為正確的疾病指稱;FP為判斷為錯誤的疾病指稱。
4.5 實驗結果與分析
4.5.1 基準模型實驗
為驗證基準模型在中文疾病名稱歸一化任務上的效果,分別利用CNN和BERT-Base進行實驗,結果如表3所示。
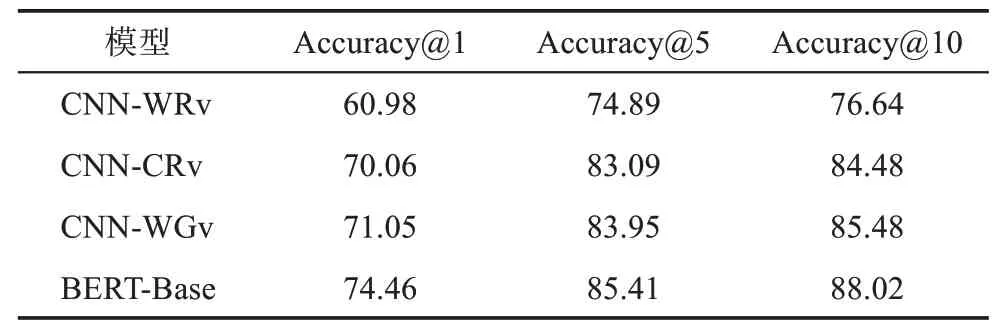
表3 基準模型實驗結果 %
由表3可知,在中文疾病名稱歸一化中,字級CNN效果優于詞級CNN;引入外部語義特征對模型效果的提升并不明顯;BERT微調后的效果較好,較CNN有明顯提升。
(1)字級CNN效果優于詞級CNN。CNN-CRv在Accuracy@1、Accuracy@5和Accuracy@10上 較CNN-WRv分別提升了9.08%、8.20%和7.84%,提升幅度較為明顯。通過分析可知,這是由于在線醫療健康文本中醫學詞匯和口語化表述經常混雜出現,導致分詞質量難以保證,從而影響到詞級向量;而通過分字生成的字級向量可獨立表示字符語義,因此在實驗中表現出更好的效果。
(2)引入外部語義特征對實驗的影響并不明顯。CNN-WGv在Accuracy@1、Accuracy@5和Ac‐curacy@10上較CNN-CRv分別提升了0.99%、0.86%和1.00%,提升幅度較小,表明詞向量嵌入層中語義特征對CNN的影響較小,這是由于隨機向量和外部語義特征均為唯一表示,不影響特征分布,但引入外部語義特征能夠豐富特征語義,對模型效果有小幅提升。
(3)BERT預訓練模型微調后的效果較好。BERT-Base在Accuracy@1、Accuracy@5和Accura‐cy@10上較最優的基線模型CNN-WGv分別提升了3.41%、1.46%和2.54%,提升效果較為明顯。這驗證了BERT能夠進一步提升疾病名稱歸一化效果,且顯著優于其他基線模型,表明BERT能夠更充分地捕獲文本深層特征。
4.5.2 引入語義關系的CNN實驗
通過實驗一可知,字級向量在CNN上有較高的準確率,在此基礎上,實驗二分別引入GRU、LSTM、BiGRU和BiLSTM驗證語義關系訓練對實驗結果的影響,具體如表4所示。
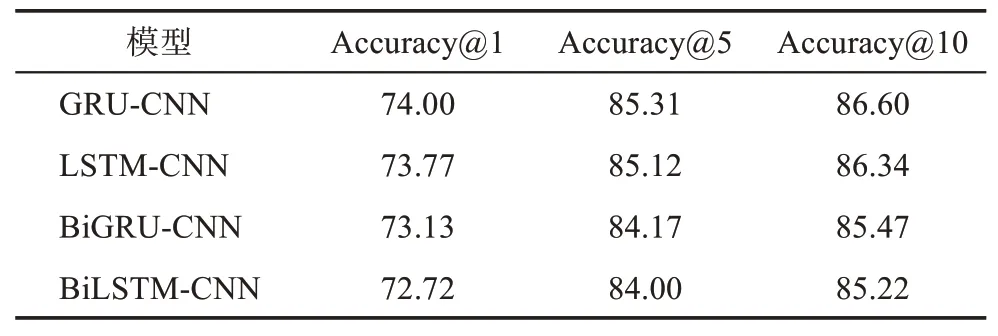
表4 基于語義關系的CNN實驗結果 %
由表4可知,在CNN上引入GRU、LSTM、Bi‐GRU和BiLSTM捕獲文本間語義關系后的模型效果較表3中CNN-WGv有較大提升。其中,GRU-CNN效果最優,在Accuracy@1、Accuracy@5和Accura‐cy@10上較引入外部語義特征的CNN分別提升了2.95%、1.36%和1.12%。該結果表明,通過引入文本向量間語義關系可提高向量質量,在CNN中可提取更關鍵特征以進一步提升模型效果。
研究分析發現,引入GRU和BiGRU的效果優于LSTM和BiLSTM,這是由于文本中大量的非醫療領域信息會影響模型學習疾病特征的語義質量,GRU網絡結構較LSTM更為簡潔,可減少因大量非醫療領域信息計算而出現過擬合的影響。此外,引入BiGRU和BiLSTM的實驗效果低于GRU和LSTM,這是由于醫療健康文本的語序對語義關系影響不大,而BiGRU和BiLSTM因同時學習文本正負向語義關系造成過擬合,反而降低了文本語義關系的表達質量。
4.5.3 多任務學習實驗
根據表3和表4可知,BERT-Base和GRU-CNN兩模型的表現最優,因此,在兩模型基礎上構建了MT-BERT-GCNN模型,用于驗證多任務學習對中文疾病名稱歸一化的影響。為了提高輸入向量質量,進一步引入注意力權重詞典來調節任務的特征輸入,構建MTAD-BERT-GCNN模型以提升實驗效果。多任務學習實驗結果如表5所示。
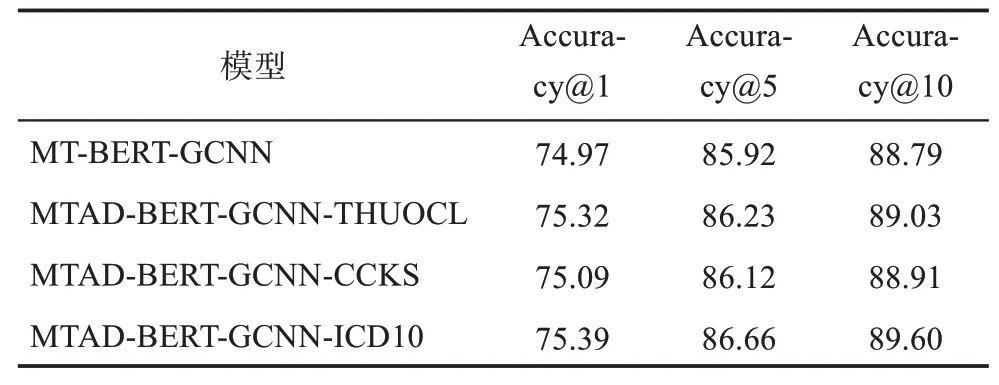
表5 多任務學習實驗結果 %
由表5可知,基于多任務學習構建的MT-BERTGCNN效果較BERT和GRU-CNN均有小幅提升,在Accuracy@1、Accuracy@5和Accuracy@10上,較GRU-CNN分別提升了0.97%、0.61%和2.19%,較BERT-Base分別提升了0.55%、0.51%和0.77%。這表明MT-BERT-GCNN的效果提升并非簡單線性效果相加,而是能夠利用多任務學習共享子任務參數,通過并行訓練學習更多特征信息可提升當前主任務學習性能,從而獲得更多代表性特征以提高疾病名稱歸一化的準確率。
進一步分析發現,引入計算注意力矩陣的輔助任務后,MTAD-BERT-GCNN效果較MT-BERTGCNN得到了進一步提升,表明引入輔助任務調節特征輸入可以篩選疾病的關鍵特征,對模型特征提取具有輔助作用。其中,MTAD-BERT-GCNNICD10的效果最佳,在Accuracy@1、Accuracy@5和Accuracy@10上,較MT-BERT-GCNN分別提升了0.42%、0.74%和0.81%,均略高于引入其他注意力權重詞典的模型。引入注意力權重詞典后,ICD10提升效果最佳,THUOCL次之。通過分析可知,ICD-10中包含了更多的專業醫學術語,因而能夠更充分地表示疾病特征;而CCKS中用詞規范性略低于專業醫學詞典,在篩選特征時出現了部分非醫學術語在輔助任務中權重分配錯誤的情況。
為了直觀地呈現模型組合及多任務學習在中文疾病名稱歸一化上的效果,圖4給出了三組對照實驗結果。可以發現,在Accuracy@1、Accuracy@5和Accuracy@10上,MTAD-BERT-GCNN-ICD10較 詞級CNN基準模型分別提高了14.41%、11.77%和12.96%,較字級CNN基準模型分別提高了5.33%、3.57%和5.12%,這表明本文所提出的MTAD-BERTGCNN可以在中文疾病名稱歸一化任務上取得最優效果。通過各模型匯總分析,實驗結果可歸納為MTAD-BERT-GCNN>MT-BERT-GCNN>BERT-Base>引入語義關系的CNN>字級CNN>詞級CNN。
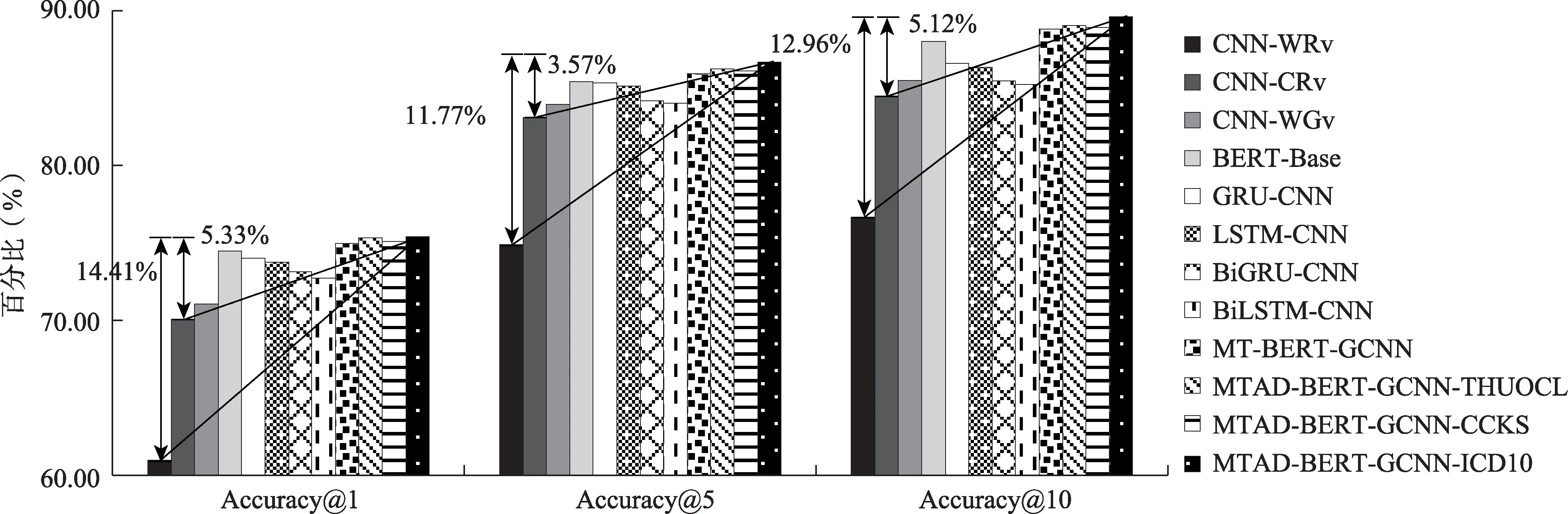
圖4 實驗數據對比分析
5 結論
本文基于多任務學習和多態語義特征提出了中文疾病名稱歸一化模型MTAD-BERT-GCNN,該模型能夠更好地利用多任務學習捕獲多態語義信息,通過共享多任務間權重參數以深度挖掘文本信息,從而達到最優效果。研究結果發現,在中文疾病名稱歸一化中:①字級CNN效果優于詞級CNN,引入外部語義特征對實驗效果有小幅提升,BERTBase較其他基準模型有大幅提升;②在CNN上融入GRU、LSTM、BiGRU和BiLSTM可捕獲文本語義關系,進而提升中文疾病名稱歸一化效果;③基于多任務學習思路構建的MT-BERT-GCNN結合不同子任務的特點,通過優化任務間的共享參數,可進一步提升實驗效果,并且引入輔助任務篩選特征構建的MTAD-BERT-GCNN可使中文疾病名稱歸一化效果達到最優,最終在Accuracy@1、Accuracy@5和Accuracy@10上的準確率分別達到了75.39%、86.66%和89.60%,在Accuracy@10上較詞級CNN和字級CNN分別提高了12.96%和5.12%。本研究將多任務學習思路應用于中文疾病名稱歸一化任務,并在中文數據集上驗證了模型效果,為中文疾病名稱歸一化研究提供了可借鑒的思路。
盡管國外對疾病名稱標準化和歸一化的研究較多,但中文領域疾病名稱歸一化研究尚未得到充分重視。在后續研究中,一方面,將考慮結合文本、圖片、語音和視頻等多模態信息,從多維度進行疾病歸一化研究;另一方面,將深入挖掘文本細微特征,以進一步推動中文疾病名稱歸一化研究進展。
猜你喜歡
中老年保健(2021年12期)2021-11-30 02:58:01
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
電子制作(2018年18期)2018-11-14 01:48:06
中華詩詞(2018年11期)2018-03-26 06:41:34
Coco薇(2016年8期)2016-10-09 02:11:50
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
