漢信碼技術優勢與技術原理解析
2021-11-21 02:16:42王毅鄧惠朋董曉文
中國自動識別技術 2021年5期
王毅 鄧惠朋 董曉文/文
本世紀初,為解決PDF417、QR等國外碼制不支持中國漢字以及漢字信息表示效率不高等問題,中國物品編碼中心(以下簡稱編碼中心)牽頭我國企業共同研發了“漢信碼”二維碼碼制。2007年,GB/T 21049-2007《漢信碼》國家標準正式發布,2011年漢信碼成為國際AIM Global權威行業標準,2015年,漢信碼正式成為國際ISO標準項目。2021年,ISO/IEC 20830《信息技術 自動識別與數據采集技術漢信碼條碼符號規范》國際標準正式發布,標志著中國人具有了完全自主知識產權的二維碼碼制技術,實現了我國又一底層技術的零的突破。
漢信碼是我國第一個制定了國家標準并且擁有自主知識產權的二維碼,如圖1所示,在漢字信息表示方面漢信碼達到國際領先水平,在數字和字符、二進制數據等信息的編碼效率、符號信息密度與容量、識讀速度、抗污損能力等方面達到了國際先進水平。經歷十余年的打磨,ISO版漢信碼相比2005年研發完成時的技術更為成熟。ISO漢信碼在技術上完全涵蓋并兼容原有漢信碼(指GB/T 21049 2007)國家標準中規定技術,還增補擴展了Unicode模式、URI模式、GS1模式三個針對重要應用領域的新型信息編碼與譯碼模式,大幅提高了漢信碼針對我國國際化應用的適用性,填補了國際二維碼碼制在這些領域的空白。

圖1 漢信碼碼圖外觀
漢信碼技術優勢
漢信碼技術的設計與工程實現是在理論和技術研究基礎上,針對我國二維碼應用的切實問題進行的不斷自主創新,因此,漢信碼在技術方面不僅綜合了各個碼制的優勢,更能夠在許多方面推陳出新,實現后發優勢。
在碼圖設計、糾錯能力以及信息編碼方面,漢信碼注重在識讀速度、碼制可靠性與信息密度和容量的統籌兼顧,實現了漢信碼在信息編碼、糾錯能力與符號抗畸變的完美平衡,如圖2所示。
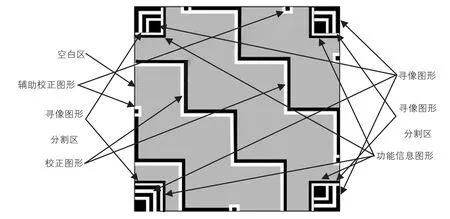
圖2 漢信碼碼圖結構
漢信碼具有九大技術優勢,具體如下:
知識產權免費
作為完全自主創新的一種二維碼碼制,漢信碼的九項技術專利成果歸編碼中心所有。編碼中心早在漢信碼研發完成時即明確了漢信碼專利免費授權使用的基本原則,更不需要向編碼中心以及其他任何單位繳納專利使用費。漢信碼具有完全自主知識產權,《糾錯編碼方法》《數據信息的編碼方法》《二維條碼編碼的漢字信息壓縮方法》《生成二維條碼的方法》《二維條碼符號轉換為編碼信息的方法》《二維條碼圖形畸變校正的方法》《漢信碼的物流信息編碼方法、裝置及設備》《字符串編碼的方法和裝置》《編碼方法、裝置、設備及計算機可讀存儲介質》等9項核心發明專利,全部免費公開,使用漢信碼不存在任何專利問題,沒有任何的專利風險與專利陷阱。
極強抗污損、抗畸變識讀能力
由于考慮了物流等實際使用環境會給二維碼符號造成污損,同時由于識讀角度不垂直、鏡頭曲面畸變、所貼物品表面凹凸不平等原因,也會造成二維碼符號的畸變。為解決這些問題,漢信碼在碼圖和糾錯算法、識讀算法方面進行了專門的優化設計,從而使漢信碼具有極強的抗污損、抗畸變識讀能力。現在漢信碼能夠在傾角為60度情況下準確識讀,能夠容忍較大面積的符號污損。因此漢信碼特別適合在物流等惡劣條件下使用,如圖3所示(見下頁)。
識讀速度快

圖3 漢信碼污損畸變符號識讀
為提高二維碼的識讀效率,滿足物流、票據等實時應用系統的迫切需求,漢信碼在信息編碼、糾錯編譯碼、碼圖設計方面采用了多種技術手段提高了漢信碼的識讀速度,目前漢信碼的識讀速度比國際上的主流二維碼Data Matrix要高,因此漢信碼能夠廣泛地在生產線、物流、票據等實時性要求高的領域中應用。
糾錯能力強
根據漢信碼自身的特點以及實際應用需求,采用最先進的Reed-Solomon糾錯算法,設計了四種糾錯等級,適應于各種應用情形。此外,為適應二維碼的各類應用環境,漢信碼對于各版本和各糾錯等級的糾錯分組和信息排布進行了專門優化,在容錯性能和計算速度上實現了平衡,最大糾錯能力可以達到30%,在性能上接近并超越現有國際上通行的主流二維條碼碼制。
信息密度高
為提高漢信碼的信息表示效率,漢信碼在碼圖設計、字符集劃分、信息編碼等方面充分考慮了這一需求,從而提高了漢信碼的信息特別是漢字信息的表示效率,當對大量漢字進行編碼時,相同信息內容的漢信碼符號面積只是QR碼符號面積的90%,是Data Matrix碼符號的63.7%。
信息容量大
漢信碼最多可以表示7829個數字、4350個ASCII字符、2174個漢字、3262個8位字節信息,支持照片、指紋、掌紋、簽字、聲音、文字等數字化信息的編碼。
表達漢字能力強
漢信碼是目前唯一全面支持我國漢字信息編碼強制性國家標準GB 18030-2005《信息技術中文編碼字符集》的二維碼碼制,能夠表示該標準中規定的全部常用漢字、二字節漢字、四字節漢字,同時支持該標準在未來的擴展。在漢字信息編碼效率方面,對于常用的雙字節漢字采用12位二進制數進行表示,在現有的二維碼中表示漢字效率最高。
此外,ISO版漢信碼擴展支持了Unicode壓縮模式,這一新模式在保持漢信碼漢字高效編碼的基礎上,極大提高了漢信碼支持多種語言文字的信息編碼能力。
因此,漢信碼是表示漢字信息的首選碼制。
適合移動商務應用
目前二維碼的應用熱潮,主要是由于二維碼的移動應用推動起來的,通過手機掃描或手機展示二維碼,實現購物、乘車、健康碼等應用已經成為大眾生活的主流,這些二維碼中承載的內容主要是URL,俗稱網址。URL是URI,即統一資源標識符的一種形式,用于在規定的網絡協議下進行資源定位。這些二維碼中的URI通常為短URI,用戶通過掃描二維碼獲取URI,通過APP定義的方式引導用戶訪問網絡資源,二維碼已經成為事實上的移動商務入口。
現有的二維碼,如日本的QR碼等并沒有針對目前如此廣泛的二維碼移動應用進行優化,現有碼制僅僅將網址視為由字母、數字、其他字符組成的字符串進行編碼,且大多采用效率最低的8字節編碼模式,造成編碼空間的浪費,損失編碼效率。
針對目前二維碼主要的網址應用模式,漢信碼ISO標準中設計采用了高效的URI編碼模式。相同的網址,使用漢信碼較其它碼制的編碼效率更高,碼圖面積更小。例如,對于網址:https://www.ten?cent.com/zh-cn/index.html的編碼符號,漢信碼(圖4 A)的模塊數為25×25,QR碼(圖4 B)的模塊數為29×29,相同模塊大小的前提下,漢信碼面積僅為QR碼的74%,如圖4所示。

圖4 漢信碼僅為QR碼面積的74%
某些特殊網址,漢信碼編碼效率更高,編碼信息序列長度甚至僅為QR碼的一半,甚至更低。這對提高二維碼識讀效率,小包裝商品的二維碼印制,降低企業印制成本具有積極的現實意義。
支持主流的GS1編碼和全球任意語言文字編碼
針對目前國際主流的GS1編碼,ISO版漢信碼也增加了GS1模式,高效承載GS1編碼。GS1 Global主席米蓋爾公開表示支持漢信碼碼制上升成為國際GS1二維碼碼制之一。
由于二維碼具有信息容量大、成本低廉等優勢,二維碼技術應用目前已經形成全球性的熱潮,而在以二維碼作為描述性、文字類數據載體的應用中,由于各國采用的語言文字不同,從而造成在某一個國家編制生成的二維碼,在另一個國家譯碼時,由于應用軟件、操作系統采用的編碼字符集不同,出現二維碼譯碼結果為亂碼的現象,這對二維碼技術的全球性廣泛應用造成了嚴重阻礙。
引起這一問題的原因主要是歷史遺留的文字信息編碼問題。在全球信息化過程中,由于各種原因,語言文字的編碼采用的技術方案各不相同,在早期的7位、8位編碼以及16位編碼階段,過渡到目前的基于多個編碼平面的各類大字符集過程以及主流應用軟件和操作系統的升級過程中,各個主要國家都累積了不同的信息編碼字符集。漢字在日本、韓國等漢字集中同樣存在,不同的字符集編碼中,同樣的漢字編碼不同,同一個編碼取值,指代的字符不同,同時這些字符集的應用主要表現為確定區域的特色。在文字編碼中,漢字編碼是最為復雜的問題之一,除了我國的GB 2312、GB 18030字符集之外,日本、韓國的現行字符集中也包含了大量漢字。據不完全統計,目前國際上已經存在的編碼字符集有數百個,相關字符集內的字符碼位與相互映射關系非常復雜,跨系統的信息交互采用兩個字符集間的映射不大可行。
為解決多國文字的自適應高效編碼問題,產業界研發了Unicode(統一碼、萬國碼、單一碼)業界標準,并同步修訂完成了ISO/IEC 10646標準。Uni?code是國際組織制定的可以容納世界上所有文字和符號的字符編碼方案。目前的Unicode字符分為17組編排,0x0000至 0x10FFFF,每組稱為平面(Plane),而每平面擁有65536個碼位,共1114112個。然而目前只用了少數平面。Unicode是一張非常巨大的字符碼表,每個字符都賦予了“U+”開頭的編號,例如:U+4E25為漢字“嚴”字;Unicode的唯一字符編碼,可以采用多種方式編碼為二進制形式,如UTF-8、UTF-16、UTF-32等,且其中UTF-8是最通用、支持最廣泛的字符編碼。
為解決二維碼字符編碼在譯碼時的問題,編碼中心開展了漢信碼信息編碼技術研究,通過研究發現全面支持各類語言高效編碼的實現路徑應采用全面支持Unicode的方式實現,從而開發了Unicode壓縮模式,這一新模式在保持漢信碼原有的漢字等多種文字高效編碼的基礎上,極大提高了漢信碼支持多種語言文字的信息編碼能力。目前,漢信碼是第一個也是唯一一個同時支持英文、日文、德文、阿拉伯文、希伯來文等全系列語言文字高效編碼的碼制,能夠實現針對多國文字的自適應高效編碼。
優勢實現的技術背景
漢信碼強大的技術優勢源自于底層嚴密的技術設計,碼圖設計決定了抗污損、抗畸變能力和快速的識讀水平,URI模式極大提高了網址表達效率,更加符合網絡時代下二維碼作為網址跳轉載體的現實應用需求,Unicode模式則解決了多國文字的自適應高效編碼問題,成為唯一能夠實現全球任意語言表達的二維碼碼制。
碼圖設計
碼圖分為功能圖形區和編碼信息區。為了達到快速定位的目的,漢信碼采用掃描特征比例的方式進行碼圖尋像與定位,碼圖尋像圖形由位于碼圖四個角上的位置探測圖形組成。碼圖的校正圖形是由黑白兩條線組成階梯形的折線,通過折線的交點來達到分塊校正碼圖的目的。為了能有效利用碼圖編碼空間,版本設計時,相鄰版本之間的模塊變化為每邊相差2個模塊。在信息編碼區,將數據碼字和糾錯碼字按照一定的編排規則組合后對碼字進行交織編排,并按指定的布置規則進行碼圖布置。同時,為了使信息編碼區符號的黑白模塊比例均衡,盡量減少影響圖像快速處理的圖形出現,對編碼信息區添加掩模,使黑白模塊的比例接近1:1。其功能信息區則布置著碼圖的版本信息、糾錯等級、掩模方案等。
尋像圖形包括四個位置探測圖形,分別位于符號的左上角、右上角、左下角和右下角,如圖5所示(見下頁)。各位置探測圖形形狀相同,只是擺放的方向不同,位于右上角和左下角的尋像圖形擺放方向相同,這樣設計的目的是為了使整個碼圖有明顯的方向特性。以左上角的位置探測圖形為例,它的大小為7×7個模塊,整個位置探測圖形可以理解為將3×3個深色模塊,沿著其左邊和上邊外擴1個模塊寬的淺色邊,后繼續分別外擴1模塊寬的深色邊、一個模塊寬的淺色邊、一個模塊寬的深色邊所得。其掃描的特征比例為1:1:1:1:3和3:1:1:1:1(沿不同方向掃描所得值不同)。符號中其它地方遇到類似圖形的可能性極小,可以在視場中迅速識別可能的碼制符號。識別組成尋像圖形的四個位置探測圖形,可以明確地確定視場中符號的位置和方向。

圖5 尋像圖形結構圖
定位圖形設計
從對QR、DataMatrix等各種二維碼的分析來看,通過對具有簡單幾何比例特征的模式進行多方向掃描的方式是最簡單快速的解碼方式。
為了定位上的快捷方便,在碼圖的四個角上各放置一個定位圖形,并確定了定位圖形在碼圖中的放置方式,這樣放置不僅保證碼圖具有對稱性,同樣能體現漢信碼的方向性,使得漢信碼的碼圖具有明顯的不同于已有二維碼的特征,而且使得漢信碼具有更好的快速定位的能力,如圖6所示。

圖6 漢信碼定位圖形放置
定位圖形位于符號的4個角上。各元素的相對寬度的比例是1:1:1:1:3或3:1:1:1:1,因此需要同時探測的比例是1:1:1:1:3和3∶1∶1∶1∶1。在水平和垂直方向尋找滿足1:1:1:1:3或3:1:1:1:1比例的模式,搜索結果即為圖像的四個定位符號的位置信息。設條碼區圖像為G(x,y),條碼在圖像中的高度和寬度分別記為H、W,圖像二值化時的閾值為 T,得到條碼的邊界 E(x1,x2,…xw)時,即

從當前位于 E(x1,x2,…xw)上的邊界點出發,搜索并得到從X軸方向和Y軸掃描圖像中的比例是1:1:1:1:3或3:1:1:1:1的模式,則為漢信碼的尋像符號的特征模式。
校正圖形設計
對于一種碼制來說,通常會采用定位圖形和校正圖形相組合的方式來達到抗畸變能力。在漢信碼符號較大的情況下,需要增加校正圖形,采用分區的方式將二維碼分成小區域。因為符號較大時,整體可能會產生較大的畸變,但是小區域內的畸變會相對較小,這樣才能保證漢信碼的抗畸變能力。
漢信碼的校正圖形由一組或幾組單模塊寬,長度不同的臨接連續深淺模塊(簡稱校正折線)組成的,橫豎連續排布的階梯形折線,以及排布于碼圖四個邊上的2×3(5個淺色,1個深色)個模塊組成的輔助校正圖形共同構成,如圖7-1、7-2、7-3所示(見下頁)。對于某一個漢信碼符號版本,校正圖形折線的長度(連續模塊數)取值有兩種,其中碼圖最左邊與最下邊區域的校正折線長度(寬度)取特殊值r,而剩余區域的校正折線長度(寬度)為k。當校正折線位于符號邊緣時,校正折線設定為單模塊寬的深色連續模塊。輔助校正圖形為2×3(或3×2)個模塊組成的,位于碼圖邊緣的特殊圖形,其中符號邊緣的3模塊序列中心模塊為深色,其余模塊為淺色,深色模塊位置位于附近校正折線延長線與符號邊緣相交的模塊位置。對不同版本的碼圖,其校正圖形的排布各有差異,各版本校正折線的r與k的值以及平分為k模塊寬的個數m取值滿足關系:n=r+m*k(n≥3),(詳見漢信碼國家標準)。而對于版本小于3的碼圖,則沒有任何校正圖形。
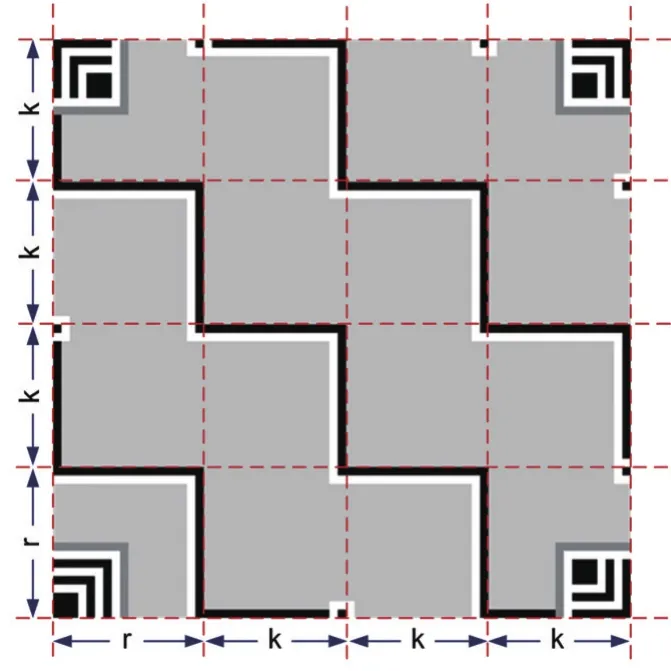
圖7-1 漢信碼的校正圖形
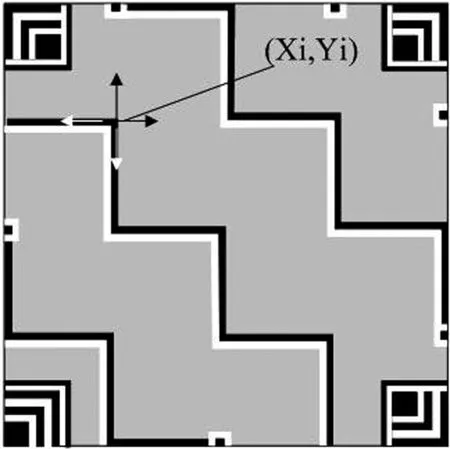
圖7-2 校正圖形的中心坐標
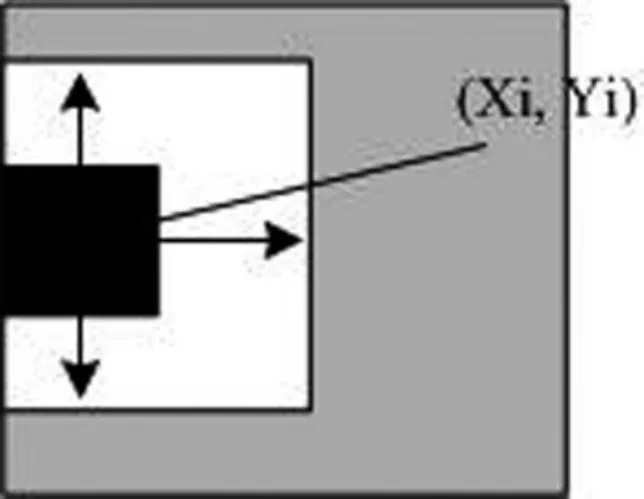
圖7-3 輔助校正圖形的中心坐標
URI模式的設計
URI是互聯網工程方面的標準化組織IETF制定的RFC3986標準中規定的統一資源標識符語義結構,由協議、主機名、域名、默認端口號、資源路徑等組成,順序與結構固定,然而相關真正使用的協議域名等相對很少,將各部分單獨進行編碼,可極大提高編碼效率。
漢信碼的URI模式是專門針對二維碼的移動應用量身定制的一種信息編碼模式。將字符按照使用頻率分為三個字符集,分別為URI-A,URI-B,URI-C。其中URI-A是最常用的字符集,包含小寫字母、數字、部分協議頭、常用頂級域名等62個最常用字符,滿足大部分URI編碼需求,可滿足大部分短網址的查找需求。URI-B則涉及百分號編碼、ASCII中的其他符號、GS1關鍵字等。URI-C可視為A和B的總集,在大多數情況下,只需查找URIA字符集中的62個字符,并結合URI-B中的百分號編碼,即可完成一個URI的編碼或解碼。通過這種方式,極大提高了二維碼承載短網址的效率,相同的網址,使用漢信碼較其它碼制的編碼效率更高,碼圖面積更小。
漢信碼URI模式的模式指示符為(1110 0010)bin,URI模式的模式結束符為(111)bin。
輸入的URI字符串的分析方法和步驟如下:
a)按照下述規則對輸入的URI字符串進行分析,查找并記錄輸入URI字符串的每個字符或字符序列的初始編碼:
1)如果字符“%”后面有兩個字符,并且這些“%XX”字符序列符合RFC 3986定義的百分號編碼的要求,則對這些“%XX”字符使用百分號編碼字符方法。
2)如果字符或字符序列可以使用URI-A字符集和URI-C字符集進行編碼,則首選使用URI-A字符集。
3)如果字符或字符序列可以使用URI-B字符集和URI-C字符集進行編碼,則首選使用URI-B字符集。
4)如果使用URI-A字符集在同一位置對字符或字符集序列進行編碼有兩種方式,則使用編碼值較大的方法作為首選方法。
5)如果使用URI-C字符集有兩種方法在同一位置對字符或字符集序列進行編碼,則使用編碼值較大的方法作為首選方法。
b)用a)進行初步分析之后,對數據分析結果進行優化步驟如下:
1)如果字符串使用URI-A字符集和URI-B字符集共同進行編碼,計算共計產生的編碼位數。計算單獨使用URI-C字符集對該字符串進行編碼產生的編碼位數。只有在前者小于或等于后者時,才使用URI-C字符集進行編碼。
2)如果字符串使用URI-B字符集和URI-A字符集進行編碼,計算共計產生的編碼位數。計算單獨使用URI-C字符集對該字符串進行編碼產生的編碼位數。只有在前者小于或等于后者時,才使用URI-C字符集進行編碼。
3)如果字符串使用URI-A字符集和URI-C字符集進行編碼,計算共計產生的編碼位數。計算單獨使用URI-C字符集對該字符串進行編碼產生的編碼位數。只有在前者小于或等于后者時,才使用URI-C字符集進行編碼。
4)如果字符串使用URI-B字符集和URI-C字符集進行編碼,計算共計產生的編碼位數。計算單獨使用URI-C字符集對該字符串進行編碼產生的編碼位數。只有在前者小于或等于后者時,才使用URI-C字符集進行編碼。
5)如果字符串使用URI-C字符集和URI-A字符集進行編碼,計算共計產生的編碼位數。計算單獨使用URI-C字符集對該字符串進行編碼產生的編碼位數。只有在前者小于或等于后者時,才使用URI-C字符集進行編碼。
6)如果字符串使用URI-C字符集和URI-B字符集進行編碼,計算共計產生的編碼位數。計算單獨使用URI-C字符集對該字符串進行編碼產生的編碼位數。只有在前者小于或等于后者時,才使用URI-C字符集進行編碼。
7)重復上述步驟中描述的步驟,直到不再進行優化。
根據以上分析結果,用字符集指示符和相應的字符集對輸入的URI字符串進行編碼,字符集指示符編碼,見表1(下頁):
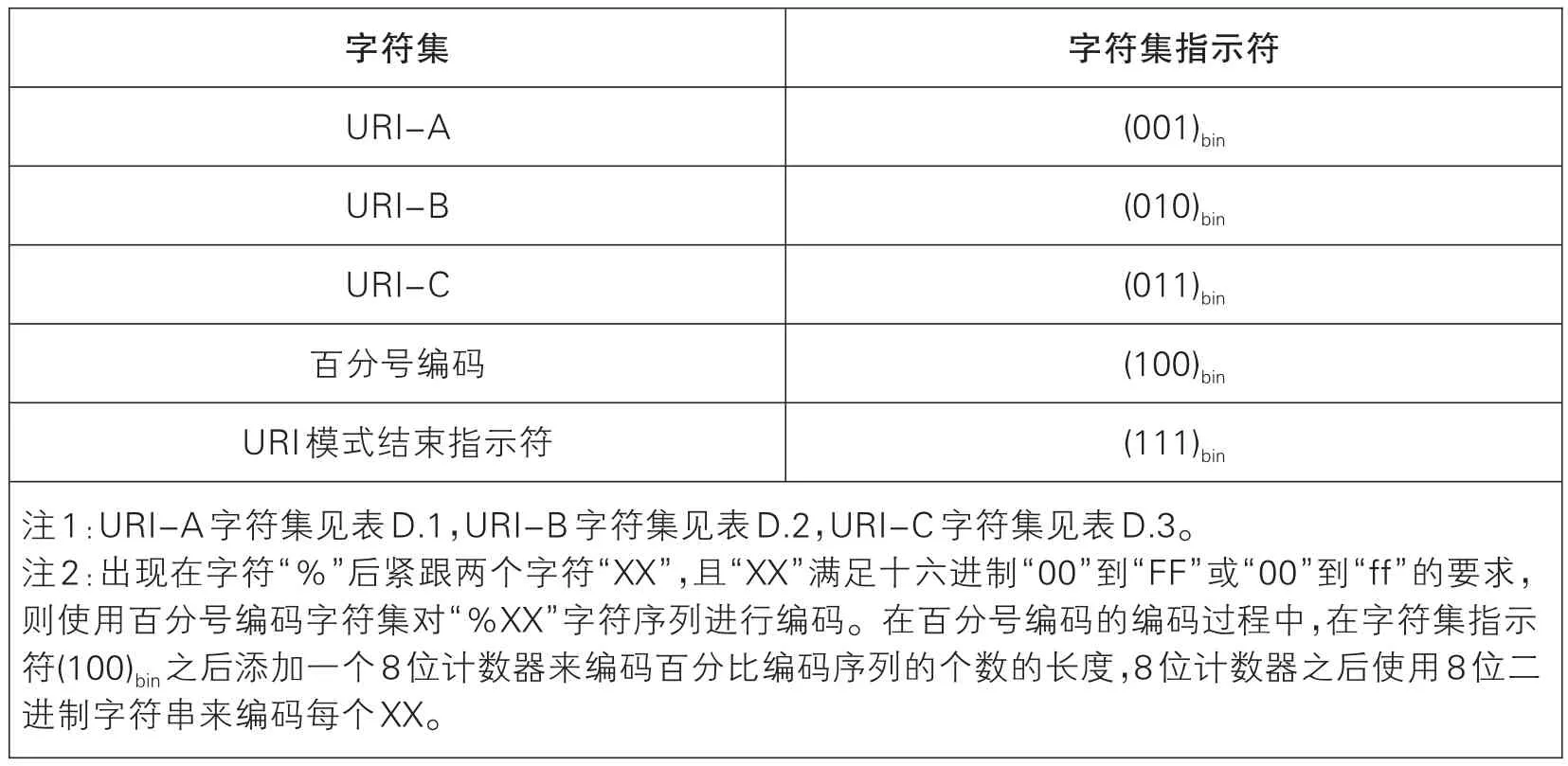
表1
Unicode模式的設計
漢信碼的Unicode模式的主要技術過程是,對Unicode字符集的UTF-8編碼模式,采用自適應游程編碼的數據編碼模式,將其轉換為漢信碼的數據碼字流。在將Unicode轉換為漢信碼信息編碼過程中,設立了4種編碼格式(1字節格式、2字節格式、3字節格式和4字節格式),分別對UTF-8字符集采用不同編碼模式進行預編碼,對所得到的預編碼長度進行比較,選取最有效的編碼模式,從而有效保證了編碼效率。漢信碼是目前已經標準化的ISO各種二維碼碼制中唯一支持Unicode模式編碼的碼制,同時編碼效率進行了充分優化,編碼效率與原固有信息編碼模式效率相近或更優。輸入數據由可用1字節、2字節、3字節或4字節表示的字符組成。Unicode模式應按照自適應數據分析算法分析輸入數據。首先,將輸入數據劃分并組合成1字節格式、2字節格式、3字節格式或4字節格式預編碼子序列,然后按照游程數據壓縮算法對輸入數據的每個子序列進行編碼。使用以下步驟分析編碼數據:
a)對輸入數據進行初步分析,得到初始字節模式分析結果:
1)讀取數據的前12個字節進行分析:
①如果整個數據長度小于12字節,則跳轉到③;否則,轉到下一步。
②使用1字節格式、2字節格式、3字節格式和4字節格式對前12字節數據進行編碼,選擇同字節格式中(編碼位/字節計數)具有最低預編碼比特率的字節模式作為前12字節的初始字節模式。如果此字節模式為4字節格式,則轉到⑧;否則,轉到下一步。
③讀取前9個字節的數據,如果整個數據長度小于9個字節,則轉到⑤;如為9個字節,轉到下一步。
④使用1字節格式、3字節格式預編碼前9字節數據,選擇同字節格式中編碼比特率最低的字節模式作為前9字節的初始字節模式。如果此字節格式為3字節格式,則轉到⑧;否則,轉到下一步。
⑤讀取前6個字節的數據,如果整個數據長度小于6個字節,則轉到⑦;如滿足6個字節,轉到下一步。
⑥使用1字節格式、2字節格式預編碼前6字節數據,選擇字節編碼比特率最低的字節模式作為前6字節的初始字節模式。如果此字節格式為2字節格式,則轉到⑧;否則,轉到下一步。
⑦使用1字節模式作為第一個字節的初始字節模式。
⑧利用初始數據字節序列中的初始字節模式,將數據的下一個分析位置設置為初始字節序列的下一個字節。
2)對于下一段數據分析位置,如果到達數據的末尾,則初始分析結束;否則,讀取下一個12字節的數據,進行分析:

①如果下一個分析位置的整個數據長度小于12字節,則轉到③;如長度滿足12字節,轉到下一步。
②使用1字節格式、2字節格式、3字節格式和4字節格式預編碼接下來的12字節數據,選擇同字節格式中(編碼位/字節計數器)編碼比特率最低的字節格式作為下一個12字節的初始字節格式。如果此字節模式為4字節格式,則轉到⑧;否則,轉到下一步。
③讀取頭9字節的數據,如果該數據長度小于9字節,則轉到⑤;否則,轉到下一步。
④使用1字節格式、3字節格式對該9字節數據進行編碼,選擇同字節格式中編碼比特率最低的字節模式作為9字節的初始字節格式。如果此字節模式為3字節格式,則轉到⑧;否則,轉到下一步。
⑤讀取頭6個字節的數據,如果下一個分析位置的整個數據長度小于6個字節,則轉到⑦;否則,轉到下一步。
⑥使用1字節格式和2字節格式對該6字節數據進行編碼,選擇同字節格式中編碼比特率最低的字節格式作為該6字節的初始字節模式。如果此字節格式為2字節格式,則轉到⑧;否則,轉到下一步。
⑦使用1字節格式作為下一個字節的初始字節格式。
⑧如果數據系列的初始字節模式與先前數據字節系列的先前初始字節模式不同,則將初始字節模式設置為數據系列的數據模式,并通過增加字節序列的長度來移動數據的下一個分析位置,返回2;否則,如果數據字節序列的初始字節模式與先前數據的先前初始字節模式相同,則分析并決定是否將兩個數據字節序列合并為一個。數據組合分析是為了計算和比較使用兩個單獨字節模式的編碼位以及用于集成到一個單字節序列的編碼位:
?如果集成到一個字節序列中的編碼位數不大于使用兩個單獨字節模式的編碼位數,則不要更改前一個字節模式進行編碼,而是要注意更改每個字節的長度、差值和最小值字節模式;
?如果集成為一個字節模式的編碼位數大于使用兩個單獨字節模式的編碼位數,則啟動一個新的字節模式進行編碼;
?對于上述兩種情況,通過添加新的已分析字節模式的長度來移動下一個分析位置。
b)優化初始字節模式分析結果,具體步驟如下:
1)如果數據序列與之前的數據序列使用相同的字節模式。計算兩個相鄰數據序列的兩個單獨字節模式(不同長度、差值和最小值)的編碼位和兩個數據序列的單字節模式的編碼位:
①如果集成到一個單一字節模式的編碼位大于使用兩個單獨字節模式的編碼位,則無需更改字節模式;
②如果集成到一個單一的字節模式的編碼位不大于使用兩個單獨的字節模式的編碼位,則將兩個單獨的字節模式集成為一個單字節模式,但要注意改變長度,差值和最小值的每個字節的字節模式。
2)如果2字節模式的總字節長度小于16。使用兩個單獨的字節模式(不同的長度、差和最小值)計算兩個相鄰數據序列的編碼位,并使用一個本地單字節模式(1字節模式)計算兩個數據序列的編碼位:
①如果集成到一個本地單字節模式的編碼位不少于使用兩個單獨字節模式的編碼位,則不必更改字節模式;
②如果集成到一個本地單字節模式的編碼位少于使用兩個單獨的字節模式的編碼位,則將兩個獨立的字節模式集成到一個本地單字節模式。
3)重復此步驟中描述的步驟,直到無法進行任何優化為止。
利用以上的分析結果,使用以下步驟對輸入數據進行編碼:
a)對于1、2、3或4字節格式的每個數據序列,選擇相應的字節格式指示符作為編碼的起始位,見表2。
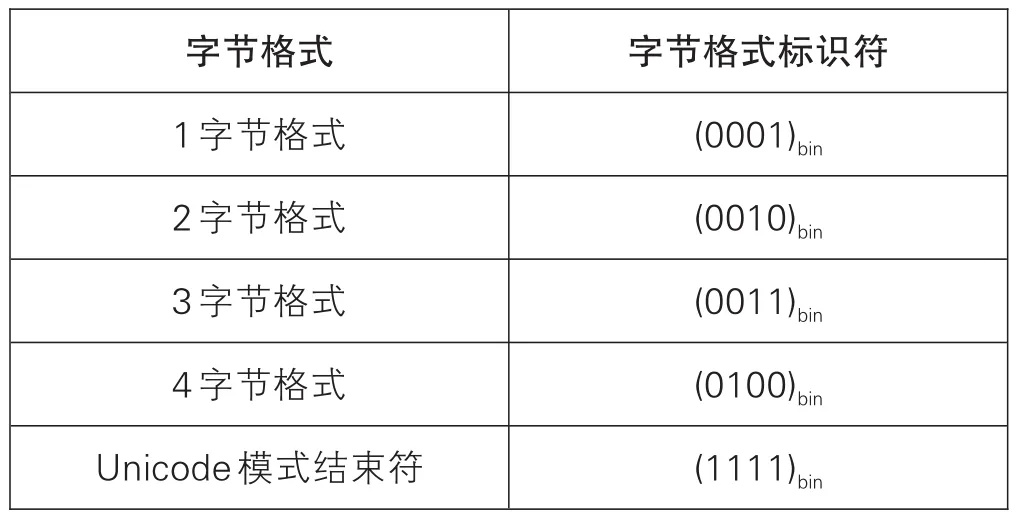
表2
b)Unicode模式下字節模式計數器的編碼格式見表3,對該字節模式的數據序列的字節格式計數器進行編碼(字節模式計數器基于字節模式,而不是字節長度,例如計數器2的3字節模式具有6字節):
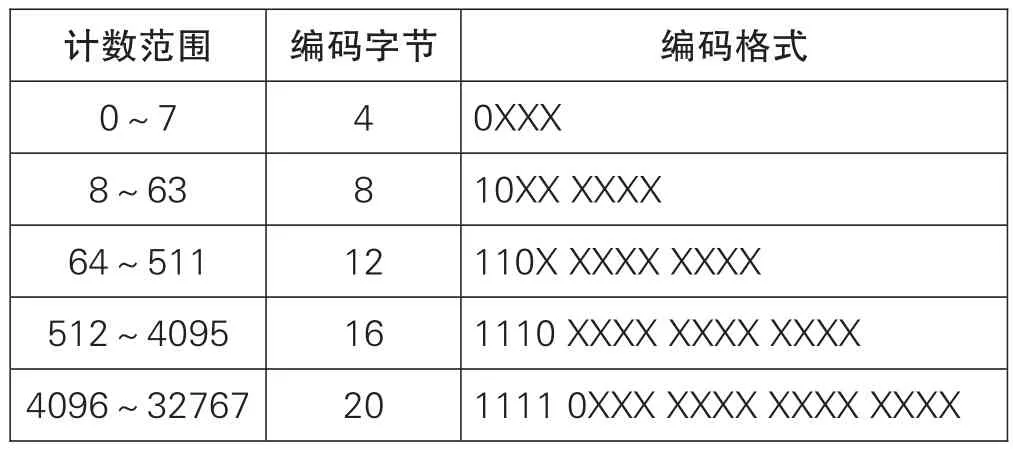
表3
c)找出每個1、2、3或4字節分組的字節序列最小值,計算并重新編碼1、2、3或4字節組的每個字節序列與分組字節序列最小值相比的所有差異。此外,需要將1、2、3或4個字節各字節分組的差異長度標識符添加到編碼位流中,該指示符采用不同的長度表示方法可以支持多個字節分組差異值的長度。
