基于報文特征的DNS隱信道檢測技術研究
2021-11-17 06:35:50楊路輝馬雪婧翟江濤戴躍偉
計算機仿真 2021年8期
楊路輝,馬雪婧,翟江濤,戴躍偉,
(1.南京理工大學自動化學院,江蘇 南京 210094;2.中國船舶重工集團第七二四研究所,江蘇 南京 211153;3.南京信息工程大學電子與信息工程學院,江蘇 南京 210044)
1 引言
近年來以高級持續性威脅(Advanced Persistent Threat,APT)為代表的各種網絡失竊泄密事件此起彼伏給網絡安全帶來嚴重威脅。APT惡意軟件在入侵系統后,為了保證與服務器的通信不被現有的防火墻設備發現并阻斷,往往會使用網絡隱信道技術以躲避網絡審查。網絡隱信道的定義為:在公開信道中建立的一種實現隱蔽通信的信道,用于信息傳輸[1]。目前已知的網絡隱信道包括在IP、TCP、ICMP、HTTP等常見網絡協議的冗余位進行信息的嵌入,而域名系統(Domain Name System,DNS)協議作為網絡通信中必不可少的協議,一般不會被防火墻策略阻攔,由于DNS的遞歸查詢策略需要本地DNS服務器與其它DNS服務器進行通信,這樣即使在一個受到嚴格安全策略管控的網絡環境下,同樣能夠通過DNS協議與外界網絡環境進行通信,這就為網絡隱信道的構建提供了必要的條件。DNS隱信道能夠為惡意軟件提供高隱蔽性的數據傳輸通道,文獻[2]中作者對惡意軟件進行了長達一年的數據收集,發現不少僵尸網絡和蠕蟲均在使用DNS進行惡意數據傳播。相對與DNS隱信道可能造成的危害,DNS隱信道的檢測方法卻不多,尤其是缺乏快速、準確的檢測方法。
針對DNS隱信道的檢測,早期的研究者們通常使用單個或少數幾個相關特征進行檢測,文獻[3]提出使用詞頻分析的方法檢測DNS隱信道,并將檢測特征由單個字母的頻率統計推廣到多個字符的頻率統計;文獻[4]提出了基于二元詞頻統計特征的檢測算法。文獻[5]根據真實網絡環境中DNS的響應類型,提出了一種針對TXT響應類型的隱信道檢測方法。隨后,更多的特征被提出,并且開始使用機器學習的方法進行分類,文獻[6]提取了基于DNS請求和響應數據的長度、請求頻率等12個數據分組特征,利用樸素貝葉斯、邏輯回歸和決策樹等常見的機器學習分類器對其數據分組特征進行分類。文獻[7]提出了基于DNS請求和響應的長度、響應時間等12個數據特征結合貝葉斯分類器和邊界分類器的檢測算法,并在文獻[8]中使用貝葉斯、神經網絡(Neural Network,NN)、支持向量機(Support Vector Machine,SVM)、臨近算法(k-Nearest Neighbor,kNN)等分類器進行分類。文獻[9]在前人基礎上提出了16維特征,并使用隨機森林算法進行分類。為了克服單分類器對DNS隱信道檢測效果不佳的問題,文獻[10]提出了一種混合分類算法,結合樸素貝葉斯、決策樹和SVM三種算法進行綜合加權分類。考慮到DNS隧道交互的行為模式,文獻[11]提出一種基于DNS行為交互特征的DNS隧道檢測算法。文獻[12-13]提出建立DNS會話并提取行為特征,進而采用分類器進行分類。
使用特征工程結合機器學習的方法能夠對DNS隱信道進行較為全面的檢測,同時對未知的DNS隱信道方法有一定的檢測能力。然而在現有的檢測方法中,所采用的多維特征都包含了多個連續的DNS請求組成的流信息,然而在觀察實際的DNS請求過程中,發現要將基于UDP協議的DNS數據的流關聯信息提取出來,只能使用五元組信息加二級域名信息的方法進行分流,然而部分DNS隧道工具可以偽造源IP,且二級域名可以用動態生成的方法,這就導致不一定能獲取到完整的DNS交互數據,確定能夠獲取的DNS數據為一個請求和對應的響應。基于一對DNS請求,提取相關數據特征進行DNS隱信道的判定,能夠實現快速的DNS隱信道檢測,同時更具有實際使用意義。
本文根據DNS單次交互的請求和響應數據,分析其數據特征和交互行為特征,提出了一種基于單次請求報文特征的DNS隱信道檢測算法。本文分析了DNS請求和響應的報文內容和交互行為,提出了19維包含長度、字符特征、響應時間等維度的特征,同時使用樸素貝葉斯、決策樹、SVM和隨機森林四種機器學習分類器進行分類,并與文獻[6]中的算法進行了對比,實驗結果表明,本文算法在相同的數據條件下,能夠實現比對比算法更好的檢測效果。
2 DNS隱信道特征分析
DNS隱信道通信主要是通過DNS遞歸查詢的原理,通過合法DNS服務器的數據轉發從而與惡意服務器進行通信,該通信方式由于沒有直接與惡意服務器通信,是一種高隱蔽性的隱信道。分析了DNS隱信道的基本原理,對DNS隱信道的數據報文特征進行分析,發現在請求域名的長度、響應域名的長度以及二元詞組詞頻特征上,正常DNS通信數據與DNS隱信道數據存在較為明顯的區別,通過三個特征的組合,進一步驗證了多維特征對于DNS隱信道檢測的有效性。
2.1 DNS隱信道原理
DNS隱信道的基本原理是利用DNS遞歸查詢策略,在公網架設一臺DNS服務器,并注冊NS信息,DNS服務器系統通過NS記錄查詢得到服務器IP,本地DNS服務器可將DNS查詢的數據報文轉發到這臺服務器上,然后服務器給出響應。整體結構如圖1所示。
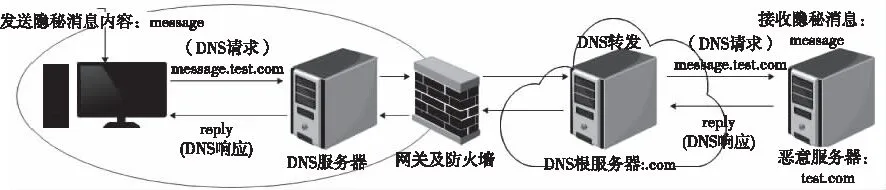
圖1 DNS隱信道整體結構圖
抗菌藥說明書[適應癥]不符合抗菌藥說明書撰寫技術指導原則的主要表現有:適應癥沒有按照“本品適用于治療由對本品敏感的XXX、XXX和XXX菌引起的YYY病。”的規范描述;沒有遵循“如果獲得的證據僅僅支持用于較大人群的亞群(例如,疾病輕微的患者或特殊年齡組的患者)應予說明”的規定;沒有遵循“在某些情況下有理由限制適應癥,例如,建議藥品不作為某種感染的一線治療”應予描述的規定;遺漏使用限制的內容。
2.2 特征分析
首先分析了DNS請求報文的負載長度,由于DNS隱信道的被控端會向控制端發送數據或者狀態信息,DNS隱信道請求報文的負載長度會比正常的DNS請求報文的負載長度更長,通過圖2可看出,DNS隱信道的請求報文負載長度明顯大于正常DNS數據,然而單個特征還不足以完全將隱信道和正常數據區分開來。
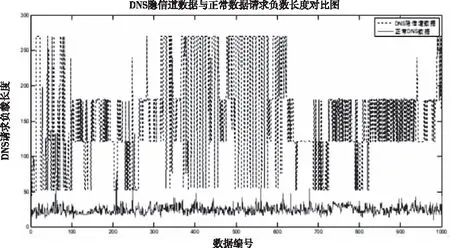
圖2 隱信道與正常DNS請求長度對比
對于DNS響應報文,由于控制端需要向被控端發送數據或者控制指令,DNS隱信道響應報文負載的長度也會比正常的DNS響應報文負載的長度要長。通過圖3可以看出,DNS隱信道響應報文負載的長度大于正常DNS隱信道。
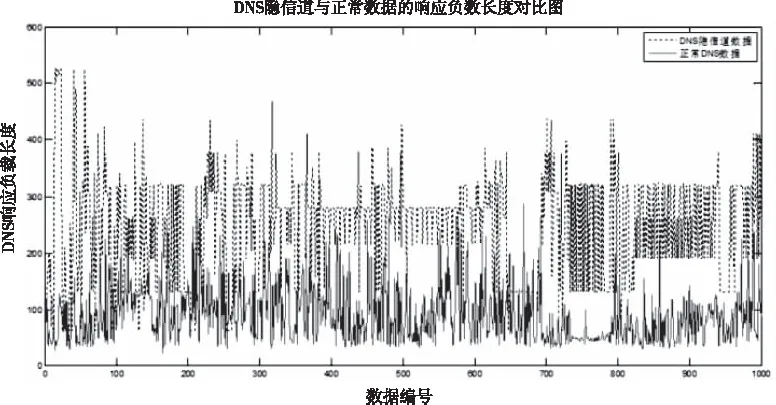
圖3 隱信道與正常DNS響應報文長度對比
誤檢率=FP/N×100%
將一個域名切分成m個n-gram單詞組,分別為w1,w2,…,wm,計算這m個單詞組的組合概率
機械電氣設備電抗器故障問題較為常見,通常表現為電抗裝置燒壞、冒煙及起火等。當電抗裝置出現故障后,極有可能造成電抗器絕緣性能下降,電源泄露等,大大增加了維修風險,需相關維修人員對電抗裝置進行及時維修,防止故障進一步演化為事故。
DNS隱信道傳輸的隱秘信息通常隱藏在請求的域名當中,假定需要傳遞的隱秘信息為“message”,惡意服務器注冊的域名為“test.com”,則,客戶端發出DNS請求,請求的域名為“message.test.com”,本地DNS服務器向“.com”根服務器請求相關信息,根服務器將請求轉發至惡意服務器“test.com”,這樣,惡意服務器即可接收到隱蔽消息,且避免直接與客戶端通信。
P(w1,…,wm)=P(w1)P(w2|w1)…P(wm|w1,…,wm-1)
(1)
組建后,獨家管網形成新的高度壟斷,只是將一家或數家國企壟斷變為另一家國企壟斷,既有龐大的現有管網,又有新建管網沿線土地資源,無法實質性解決油氣管道的自然壟斷問題。不僅如此,管網建設依賴上游資源,目前還需要大規模的投資,拆分管網將影響現有石油公司繼續投資管道建設的積極性,而且新組建的公司籌資身份難確定,籌資將更加困難。由于缺乏競爭動力,投資積極性降低,建設力量單一,組建獨立的管網公司后天然氣管道的建設速度可能放緩,很難跟上我國天然氣產業快速發展的需要,很可能由此形成新的發展制約。自從管網獨立改革消息傳出后,中國的天然氣管道建設速度明顯放緩,現有管道運輸企業新建管道積極性大幅受挫[6]。
作物轉入外源基因使作物生長勢、越冬性和抗性得到明顯提升,轉基因作物發生基因漂流,對逆境有極強適應性,其后代發揮外源基因的優勢與原有種成競爭關系[17]。此外,若近緣種是雜草,基因漂流的結果可能產生攜帶抗性基因的雜草,由于失去天敵克制,淪為惡性雜草,從而占據生存空間。1998年加拿大發現部分油菜可以抗1~3種除草劑,只能用毒性更大的除草劑才能殺滅[18]。轉基因作物向非轉基因作物進行基因漂流時,攜帶外源基因的后代可能產生抗性積累,致使除草劑使用增加、土壤污染、生物多樣性遭到破壞[19]。由此可見,轉基因作物大規模種植可能會給植物群落造成極大的負面影響,導致生物入侵。
P(wi|w1,…,wi-1)=P(wi|wi-n+1,…,wi-1)
(2)
取n=2,即bigram詞頻概率為
(3)
取其平均對數或然率為
由于第i個單詞組的出現近似符合n-1階馬爾科夫模型,即出現wi的概率只與wi的前n-1個字符有關,即
(4)
使用局域網抓取的五千個DNS請求域名以及Alexa網站排名前五千的域名作為bigram訓練樣本,最終得出的正常DNS和隱信道DNS域名的平均對數或然率對比情況如圖4所示,正常DNS的Avg_Log值明顯大于DNS隱信道數據。
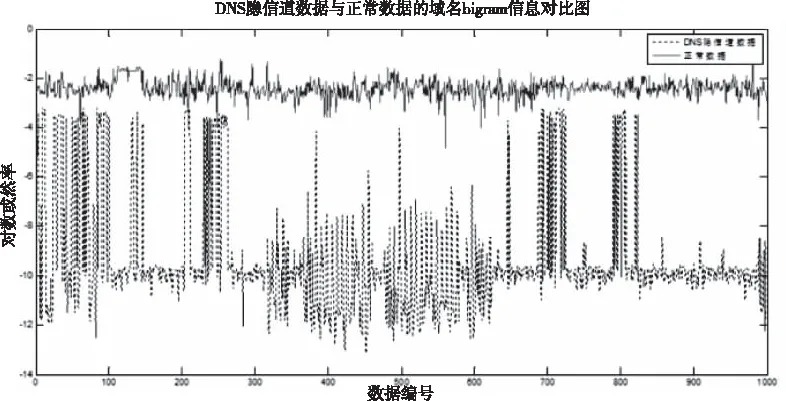
圖4 隱信道與正常DNS Avg_Log值對比
實驗使用的數據主要包括DNS隱信道數據和正常DNS數據,訓練樣本為10000個正常DNS數據和10000個DNS隱信道數據,測試樣本包2500個正常的DNS請求,2500個DNS隱信道數據,隱信道數據主要由iodine工具產生,由于iodine支持多種類型的DNS隱信道,同時支持數據包長度的控制,僅使用iodine產生隱信道訓練樣本,數據包含了A記錄、CNME記錄、TXT記錄、NULL四種DNS請求類型,隱信道請求的DNS域名長度由15到200不等。機器學習工具使用weka3.6完成。
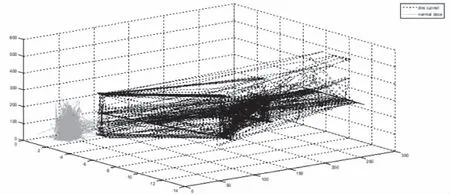
圖5 隱信道與正常DNS三維特征分類效果
3 基于報文特征的DNS隱信道檢測模型
3.1 DNS隱信道報文特征
檢測率計算公式為

表1 DNS報文19維特征
3.2 檢測模型
為實現快速而準確的DNS隱信道檢測,設計了一個兩級的DNS隱信道分析模型,模型第一級采用域名長度L2和字符的平均對數或然率Avg_Log進行快速分類,當L2大于設定的閾值,且Avg_Log小于設定的閾值時,進入下一級分類器,第二級分類器采用完整的19維特征結合機器學習分類器進行分類。第一級分類器主要用于快速過濾大量的正常域名,減小第二級分類器的壓力,第二級分類器對域名進行準確分類,輸出分類結果。具體檢測流程如圖6所示。
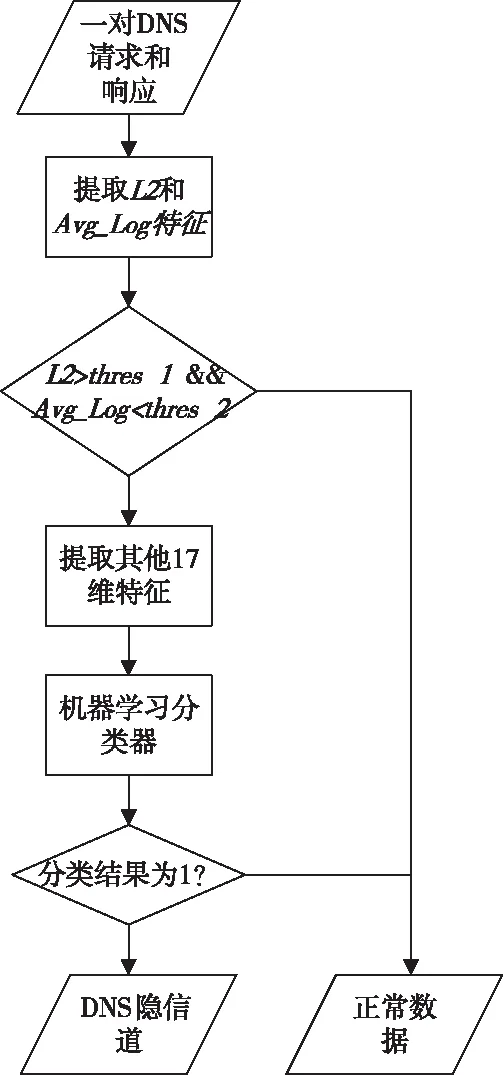
圖6 DNS隱信道檢測模型
4 實驗及結果分析
4.1 實驗數據和工具準備
通過對單個特征的直方圖分析,確定了單個特征難以準確區分隱信道數據和非隱信道數據。將上述三個特征進行結合,在三維空間內進行分類,結果如圖5所示,隱信道數據和正常數據的區分度更大了,為了更加準確的分類DNS隱信道數據和非DNS隱信道數據,需要更多維的特征。
合理的合同條款設置可以有效降低工程量清單風險。依據工程項目各分部工程要求,共有可調總價合同、固定總價合同、單價合同等幾種類型。為了避免合同漏洞導致工程招標方規避工程價款索賠風險,可在合作協議簽訂期間,利用可調總價合同控制分部工程實際工程量與工程量清單中工程量差額在±5.0%以內,若工程量上升幅度在標準限度外,則需要依照綜合單價的95%執行。
4.2 實驗結果
選擇了四種常見的機器學習算法來建立模型,分別為樸素貝葉斯、SVM、J48決策樹、隨機森林。模型的準確性通過十折交叉驗證法驗證。檢測結果如表2所示。評價指標采用檢測率、誤檢率和建模時間三個指標來比較不同分類器的檢測效果。建模時間為使用訓練樣本訓練模型所需的時間,建模時間越小表示模型復雜度越低,檢測速度越快。

表2 DNS隱信道分類結果
通過對DNS隱信道報文進行分析,歸納總結了19維DNS報文特征,其特征維度涵蓋了DNS報文長度、報文長度統計量、響應時間、域名字符特征等維度,具體特征及描述如表1所示。
再次,確定核心目標。每一名問題學生背后都一個深層次的原因造成了一系列問題的發生。在確定教育轉化問題學生的目標后,我們要撥云見日,找到那個深層次的原因,并根據這個原因確定核心教育目標,以便解決根源性問題,把力量用在刀刃上。根源性問題不解決,所有工作都是隔靴搔癢。
檢測率=TP/P×100%
(5)
由于DNS隱信道在通信過程中將信息編碼在域名中,這必然會導致生成的域名與一般以自然語言為基礎的域名存在差別,將其n-gram詞頻特性作為DNS隱信道的一種特征。
(6)
其中,TP表示DNS隱信道被正確分類為DNS隱信道的數量,P表示DNS隱信道的測試樣本總數。FP表示正常DNS報文被錯誤分類為DNS隱信道的樣本數量,N表示正常DNS測試樣本數量。
2.1 4組患者治療前后肺部感染及留置胃管情況比較 治療4周后,3個觀察組肺部感染及留置胃管率較治療前及對照組治療后顯著下降(均P<0.05);3個觀察組之間肺部感染及留置胃管率比較差異無統計學意義。見表2。
四種分類器的檢測效果不同,其中,隨機森林的檢測率最高,可達到99.7%,同時誤檢率最低,為0.1%,但是由于模型復雜度高,建模時間較長,為7.72秒。樸素貝葉斯檢測率和誤檢率均為最差,分別為79.1%和1.8%,然而模型簡單,建模時間最快,為0.11秒。SVM模型檢測率為98.6%,誤檢率為0.5%,建模時間為0.52秒,檢測效果好于樸素貝葉斯。J48決策樹檢測率為99.4%,誤檢率為0.2%,建模時間為0.37秒,檢測效果僅次于隨機森林,且建模時間較短,僅次于樸素貝葉斯。綜合來看,SVM、J48決策樹和隨機森林三種分類器檢測效果均能夠滿足實際需求,如果考慮到模型復雜度,J48決策樹最適合需要快速檢測的實時檢測環境。
4.3 對比實驗
在同樣僅使用一對DNS請求和響應報文的情況下,將本文提出的檢測模型與文獻[6]中的模型進行了對比,分別比較了本文采用的報文特征與文獻[6]所采用的報文特征結合樸素貝葉斯、SVM、J48決策樹三種分類器的檢測效果。對比實驗結果如表3所示。

表3 對比實驗結果
實驗結果表明,在同樣的數據條件下,使用相同的分類器時,本文提出的檢測算法對DNS隱信道的檢測結果均優于文獻[6]中的算法。
5 結論
本文針對真實網絡環境中DNS交互報文難以完全收集完整,從而容易導致現有的檢測算法模型失配的問題,提出了一種基于單次DNS請求與響應報文的檢測算法,該算法提取了19維報文特征并采用機器學習分類器進行分類,并與其它文獻中的算法進行了對比實驗,實驗結果表明,在相同的數據條件下,本文提出的算法整體檢測效果好于對比算法。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
