JavaScript混淆惡意代碼檢測方法
2021-11-17 04:32:00牟永敏張志華崔展齊
計算機仿真 2021年2期
王 婷,牟永敏,張志華,崔展齊
(北京信息科技大學網絡文化與數字傳播北京市重點實驗室,北京 100101)
1 引言
隨著互聯網規模的快速增長和用戶人數的迅速增加,互聯網公司在產品的用戶體驗上有著越來越高的追求。前端部分的重要性日益凸顯,導致大量的業務邏輯由服務端轉移到客戶端。Bichhawat等人[1]的研究結果表明超過95%的Web應用選用JavaScript語言進行前端開發。JavaScript語言所具有的跨平臺、可遠程嵌入、能動態執行的特性在為用戶提供更好的交互體驗的同時,也給Web應用帶來了更多的安全上的風險和威脅[2]。大量的安全報告表明,惡意網頁已成為攻擊者針對 Web客戶端進行攻擊的主要途徑和平臺[3]。因此,惡意JavaScript代碼的檢測成為一項影響Web應用安全的重要研究課題。
網頁中的攻擊代碼常常具有多樣化和隱蔽性的特點,其中17.1%的攻擊行為是通過混淆JavaScript代碼進行.代碼混淆是一種為了避免安全系統檢測而改變數據形態的技術[4]。另外,Web前端應用為減少代碼體積,加快網頁加載速度,通常會對代碼進行優化與壓縮。壓縮后的代碼常常與混淆后的代碼一樣失去可讀性,同時也為惡意代碼的隱藏提供了便利。隨著JavaScript代碼壓縮與混淆技術的成熟,惡意代碼的檢測也變得越來越困難。
研究表明,惡意代碼的行為常常具有某種規律[5]。如惡意代碼通常會更多地調用某幾種JavaScript語言的內置函數以實現代碼惡意代碼的偽裝和隱藏,且為完成某種惡意功能,函數的調用順序以及函數之間的調用圖會具有某種一致性。而常用的代碼自動壓縮與混淆工具為保證代碼在混淆前后語義上的等價,通常會保持原有的函數調用信息不變[5]。因此,利用已知的惡意代碼中各函數的調用信息可以為新的惡意代碼檢測的提供參考。
針對以上問題,本文提出了基于函數調用信息的JavaScript混淆惡意代碼檢測方法。通過提取JavaScript代碼中的函數調用序列和函數調用關系圖,比較混淆前后函數調用關系的序列相似度和圖相似度,得到混淆前后代碼中函數的對應關系,為JavaScript混淆代碼中惡意函數的檢測提供參考。
2 國內外研究現狀
2.1 惡意代碼檢測技術
網頁中惡意代碼檢測的研究已經歷了十余年的發展。自2004年開始,基于瀏覽器的客戶端蜜罐(honeypot)系統已成為一類檢測客戶端惡意代碼攻擊的有力工具。這些工具通常采用將可以網頁加載到易受攻擊的瀏覽器中并觀察系統總文件、注冊表和進程的變化來檢測網頁中的惡意代碼[6]。
2.1.1 靜態分析的方法
Canali等[7]提出的Prophiler是一個利用靜態分析進行惡意代碼和良性代碼分類的系統。Prophiler利用HTML及其關聯的JavaScript代碼以及URL信息構建有監督學習的監測模型,對代碼進行初步分類。再對被判定為惡意的代碼利用更精細的工具進行分析。Prophiler的不足是無法應對混淆后的惡意代碼。
Curtsinger等[8]提出的ZOZZLE是一個靜態的JavaScript惡意代碼檢測工具,其原理基于這樣的假設:惡意的JavaScript代碼一定會在最終執行前被反混淆。ZOZZLE利用JavaScript語言或宿主環境提供的可實現從字符串到代碼的轉換的函數(如document.write, eval)對代碼進行反混淆,并將反混淆后的代碼轉換為抽象語法樹、然后將從抽象語法樹中提取的特征輸入到樸素貝葉斯分類器中。
2.1.2 動態分析的方法
Xu等[5]提出的JStill通過分析器方法調用信息捕捉混淆惡意代碼中的特征,結合靜態分析和輕量級的運行時檢查,檢測混淆后的代碼中的惡意代碼。JStill的設計思想基于如下假設:混淆后的惡意代碼在被執行前需要進行一定程度的反混淆以完全實現其惡意功能,而反混淆的過程必然會調用特定的一組函數,因此這組特定函數的調用情況可以作為判斷惡意代碼的一個依據。JStill將函數調用分為了原生函數(native function)、內置函數(built-in function)、DOM方法以及用戶定義函數四類。JStill總結了惡意代碼在函數調用上與良性代碼的差別,包括:惡意代碼會從靜態的角度隱藏一些在反混淆中常用的函數的參數,使得這些參數不會被靜態分析工具獲取或分析,因為參數通常會暴露代碼的惡意行為;惡意代碼會隱藏函數定義,使得從靜態分析的角度解析不到函數的定義等。JStill主要關注基于編碼/加密的混淆惡意代碼的檢測。
Gorji等[6]提出了一個基于內部函數調用序列檢測混淆惡意代碼的方法。該方法的檢測分為兩個階段。首先是行為收集階段,通過在瀏覽器中加載真實的惡意的網頁,利用瀏覽器的調試工具收集函數調用信息。然后基于正則化的編輯距離將具有相似函數調用序列的網頁聚集為等價類,并且為每個等價類生成相應的行為簽名(behavior signature)。完成行為收集后,進入檢測階段。一個網頁只有在它的函數調用序列至少和一個已知的行為簽名匹配時,才會被判定為惡意的。實驗表明,該方法生成的行為簽名可以有效檢測出混淆的惡意JavaScript代碼,并且具有較低的誤報率。
AbdelKhlek等[9]提出了一個JavaScript代碼反混淆工具JSDES。JSDES利用自主構建的Mozilla的SpiderMonkey JavaScript解釋器作為JavaScript執行環境的仿真器。JSDES在仿真器中實現了JavaScript惡意代碼中常用的函數,并根據代碼的運行日志分析各類函數的執行信息,對惡意代碼實現反混淆。
2.2 代碼混淆技術
2.2.1 數據混淆(Data Obfuscation)
數據混淆通常在代碼中將字符串分割成多個變量或子串然后再拼接成原始字符串的策略來對原始字符串進行偽裝。拼接可通過調用document.write, eval等函數實現。攻擊者還可能通過改變變量的順序來給代碼分析帶來更多困難。
2.2.2 編碼混淆(Encoding Obfuscation)
編碼混淆的方法大體上有兩種。第一種是將字符轉換成對應的ASCII或Unicode編碼值,以便繞開靜態分析程序的檢測。第二種是利用自定義的加密函數來對原始代碼編碼。攻擊者編寫一對加密和解密的函數,使用加密函數將原始代碼加密,并在代碼執行時調用解密函數將代碼解密為原始代碼
2.2.3 標識符重命名混淆(Variable and Function (Re-)Name Randomization Obfuscation)
標識符重命名混淆指在不改變程序語義的條件下對標識符做局部或全局的替換,替換后的標識符通常為隨機生成的字符串,可讀性大大減弱。標識符重命名混淆通常用于加大手工代碼分析的難度[9]。
2.2.4 邏輯結構混淆(Logical Structure Obfuscation)
攻擊者可以通過改變代碼邏輯結構的方式來改變程序的控制流。一個典型的例子是在運行時插入一段永遠不會被執行的代碼。
2.2.5 動態生成和運行時計算混淆
動態生成(D-Gen, Dynamic Generation)和運行時計算(R-Eval, Runtime Evaluation)是惡意JavaScript代碼混淆的常用手段[5]。D-Gen可以在運行時從文本中生成代碼,R-Eval可以將字符串表達式轉成代碼。而惡意代碼檢測工具通常會在檢測過程中忽略字符串常量,從而使得混惡意代碼繞過檢測。D-Gen和R-Eval這兩個JavaScript語言的特性提供了從字符串到代碼的轉換方法,因此常被用作惡意代碼的混淆的手段。
然而,D-Gen和R-Eval特性也常在正常代碼中使用,如條件加載,即只在相應的條件滿足時加載對應的組件。如JavaScript代碼包含只能在運行時取得的信息時(如用戶輸入、客戶端與服務端的交互等),可以借助R-Eval實現條件加載。因此,正常代碼和惡意代碼因壓縮和混淆技術的廣泛使用而變得更加難以區分。
3 相關定義
本文將函數調用信息形式化為函數調用關系圖和函數調用序列。
IBM Watson實驗室在其開發的的WALA靜態開源分析框架中實現了調用圖的構建,并針對JavaScript語言的特性,開發了將JavaScript代碼標準化的工具JS_WALA,在此基礎上實現了面向JavaScript語言的基于指針分析的調用圖構造分析以及基于域的調用圖構造分析[10]。
劉星[11]等人提出了一種基于函數調用圖的惡意代碼相似性分析方法,通過函數調用圖的相似性距離來度量兩個惡意代碼函數調用圖的相似性,進而分析得到惡意代碼的相似性。
定義 1:函數調用關系圖G=(V,E)
函數調用關系圖G是一個二元組,其中V代表圖中的所有節點,E代表圖中的所有邊。每個節點v代表一個函數,每條邊e:v->w代表一個函數調用關系,令v,w為兩個函數,若在v的定義中出現了對w的調用,則稱v調用了w,v與w具有調用關系。
函數調用關系圖反映了函數之間的調用關系,對于簡單的代碼混淆,函數名可能會被混淆器重構,但函數之間的調用關系保持具有某種不變性,因此可以利用函數調用關系圖檢測混淆前后的代碼。
以代碼1為例,其函數調用關系圖如圖1所示。
代碼1
function f0() {
f1();
}
function f1() {
f2();
f3();
}
f0();
f1();
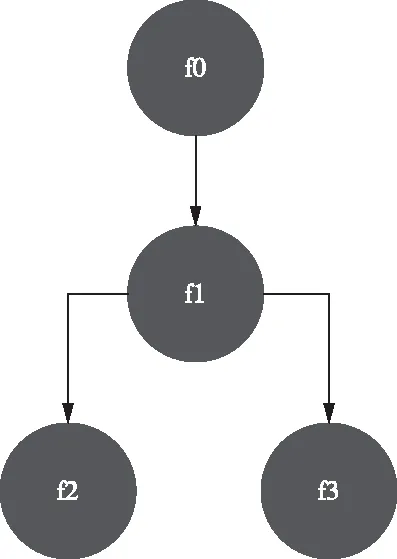
圖1 函數調用關系圖示例
定義 2:函數調用序列 Seq
函數調用序列Seq是一個由函數組成的線性序列,其中相鄰的函數v, w在源代碼的語法樹中具有中序遍歷的順序關系。
張志華[12]等人提出的函數調用路徑用于解決回歸測試中的路徑爆炸問題,將函數的業務流程抽象為函數調用路徑,簡化了對函數執行過程的描述。
函數調用序列表達了函數在統一代碼片段中的書寫順序,對于簡單的混淆的,函數調用序列具有不變性,因此可以用于匹配混淆前后的代碼。
代碼1的函數調用序列如下圖所示:
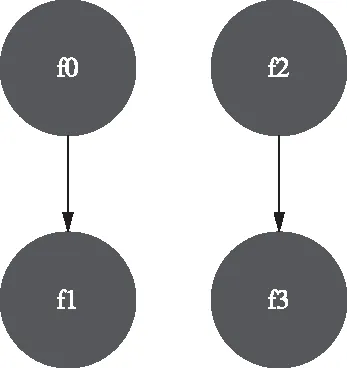
圖2 函數調用序列示例
4 基于Closure Compiler的代碼混淆
4.1 Closure Compiler的混淆方法
Closure Compiler是Google開發的一個JavaScript代碼優化和壓縮工具,經優化和壓縮后的JavaScript代碼可以被瀏覽器更快地加載和執行。與一般的JavaScript代碼編譯器不同的是,Closure Compiler并不是將JavaScript編譯為機器碼,而是將它編譯為運行更快的JavaScript代碼。Closure Compiler通過解析JavaScript代碼,移除無用代碼(dead code)然后重寫并壓縮有用代碼,并且檢查語法、變量引用以及類型,對JavaScript代碼中常見的陷阱(pitfalls)給出警告。
Closure Compiler提供了三個級別的編譯選項。分別是只移除空白符、簡單優化和高級優化。
1) 只移除空白符(Whitespace-only)的編譯等級會將代碼中的所有注釋和換行符、不必要的空白符和無關的標點(如多余的括號或分號)等字符移除。此等級輸出的JavaScript代碼在功能上和原始代碼等價。
2) 簡單優化的編譯等級首先進行和只移除空白符的編譯等級相同的處理,然后在表達式和函數層級進行優化,包括將局部變量和函數參數名重構為更短的標識符。這樣的重命名可以在一定程度上減小代碼的字節數。由于此等級只對函數內部的局部變量和參數進行了重命名,因此不會影響到此代碼和其他JavaScript代碼的交互。
3) 高級優化的編譯等級首先進行前兩個等級的處理,然后加入一些更復雜的全局優化,使得輸出的代碼的體積進一步壓縮。高級優化會移除無用代碼(dead code),此功能在引入龐大的外部庫后打包代碼時非常有用,可以對沒有用到過的庫中的代碼進行刪除以精簡代碼。高級優化還會對一些函數調用進行“內聯”,也就是將函數體展開在函數調用的地方,用以替換函數調用語句。高級優化也會對一些常量進行內聯。
4.2 函數調用信息的不變性
通過觀察Google Closure Compiler的編譯方法,發現簡單優化雖然改變了函數和變量的標識符,但函數之間的嵌套調用關系以及順序執行關系具有某種不變性,由此可以通過提取并比較兩份代碼的函數調用信息來為代碼行為的相似性提供依據。另外,對于一些內置函數的調用,混淆并不會改變函數名,因此JavaScript語言或宿主內置的函數名在混淆前后的不變形也為函數調用序列一致性的檢測提供了線索。
本文將函數調用信息形式化為函數調用關系圖和函數調用序列,將代碼相似性的檢測問題規約為圖相似度和序列相似度的計算問題。以函數調用關系圖和函數調用序列作為代碼結構信息的載體。
5 基于函數調用信息的JavaScript代碼混淆惡意代碼檢測方法
本文利用Antlr4構建JavaScript代碼解析器,首先進行詞法分析,得到token序列,再進行語法分析,得到抽象語法樹;然后遍歷抽象語法樹,并通過在遍歷器中設置提取函數調用信息的事件監聽器,在遍歷的過程中收集函數調用關系圖和函數調用序列。最后采用基于圖和序列相似度的比較算法計算函數節點的相似度。函數調用信息的提取流程如圖3所示。
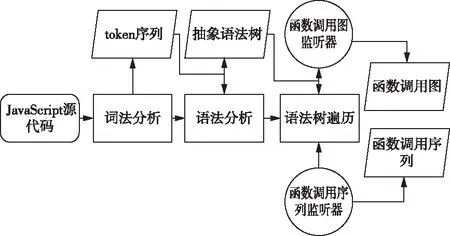
圖3 函數調用信息提取流程
5.1 函數調用關系圖的提取
函數調用關系圖的提取是在遍歷到函數調用節點時記錄當前的被調函數和調用函數,將相應的節點和邊納入函數調用關系圖。
Algorithm Function Call Graph Extraction
Input:
file: JavaScript source file
Output:
graph: Function call graph
tokens=lexer.tokenize(file)
AST=parser.parse(tokens)
listener=FunctionCallGraphListener()
graph=walk(AST, listener)
return graph
FunctionCallGraphListener:
If enterMethodDefinition:
currentFunction=this.method
If enterMethodInvocation:
graph.addEdge(currentFunction, this.method)
5.2 函數調用序列的提取
Algorithm Function Call Graph Extraction
Input:
file: JavaScript source file
Output:
graph: Function call graph
tokens=lexer.tokenize(file)
AST=parser.parse(tokens)
listener=FunctionCallSequenceListener()
graph=walk(AST, listener)
return graph
FunctionCallSequenceListener:
If enterMethodInvocation:
sequence.add(this.method)
return sequence
5.3 函數調用信息相似度的比較
本文對函數調用序列的相似度采用混合的正則化編輯距離計算。對函數名、函數內部特征及函數參數信息分別計算編輯距離,然后取平均值。
6 實驗
6.1 實驗數據集
本實驗采用使用廣泛的開源JavaScript庫Underscore和jQuery,以及部分Alexa網站發布的網站的代碼作為良性的代碼數據集,并利用Google Closure Compiler對原始JavaScript代碼進行混淆,得到混淆后的對比數據集。
實驗原始數據集及靜態分析得到的信息如表1所示,原始代碼數據來自cdnjs.com。
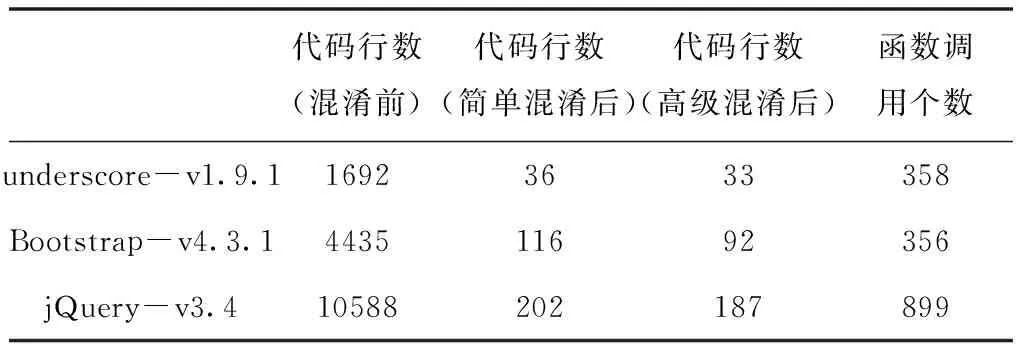
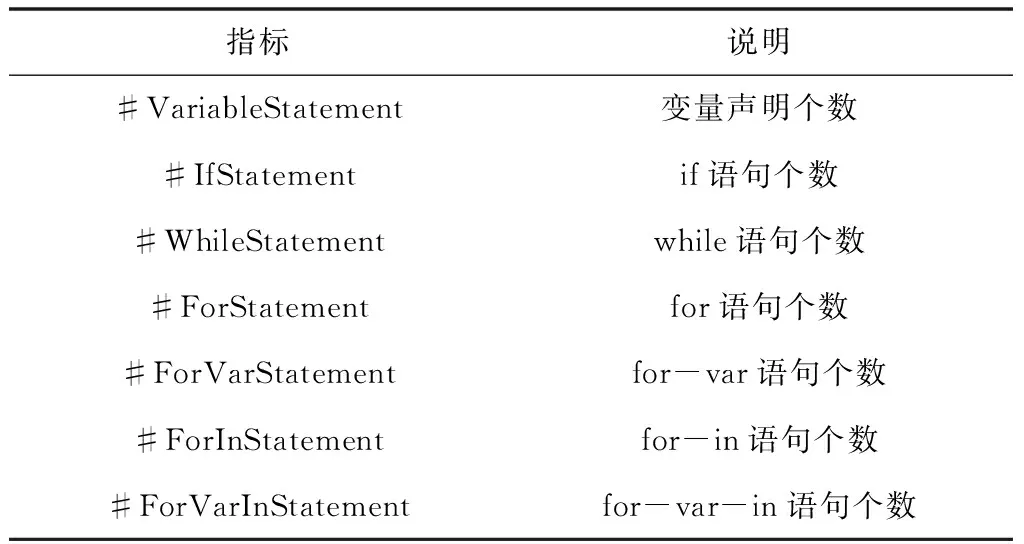
表1 實驗數據集統計信息
混淆前后的樣例代碼如下:
∥ Trim out all falsy values from an array.
_.compact=function(array) {
return _.filter(array, Boolean);
};
∥ Internal implementation of a recursive `flatten` function.
var flatten=function(input, shallow, strict, output) {
output=output || [];
var idx=output.length;
for (var i=0, length=getLength(input); i < length; i++) {
var value=input[i];
if (isArrayLike(value) && (_.isArray(value) || _.isArguments(value))) {
∥ Flatten current level of array or arguments object.
if (shallow) {
var j=0, len=value.length;
while (j < len) output[idx++]=value[j++];
} else {
flatten(value, shallow, strict, output);
idx=output.length;
}
} else if (!strict) {
output[idx++]=value;
}
}
return output;
};
simple級別混淆后的樣例代碼如下:
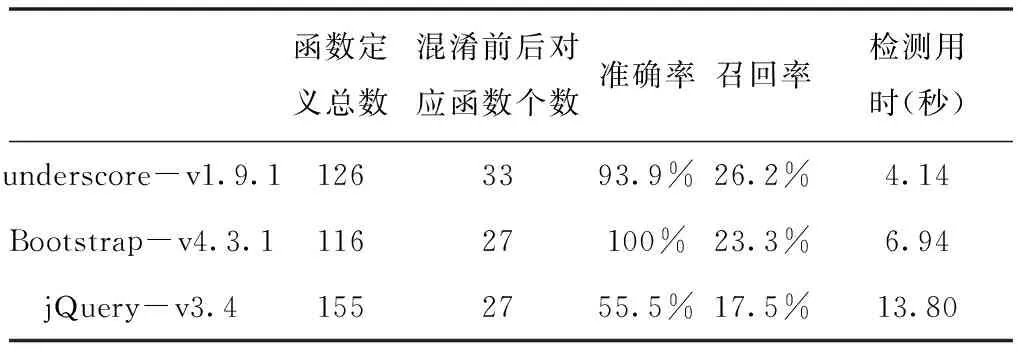
_.compact=function(c){return _.filter(c,Boolean)};var flatten=function(c,f,g,a){a=a||[];for(var d=a.length,e=0,k=getLength(c);e advanced級別混淆后的樣例代碼如下: c.compact=function(a){return c.filter(a,Boolean)};c.flatten=function(a,b){return v(a,b,!1)}; 本文的方法首先分別對混淆前后的代碼進行詞法和語法分析,并以函數定義為單位將語法樹切分為函數子樹。然后提取每棵函數子樹的調用信息,包括函數調用關系圖和函數調用序列。再對混淆前后的函數集合各自攜帶的函數調用信息進行兩兩比較,取相似度高于一定閾值的函數對,得到混淆前后函數的對應關系列表。 函數調用信息的相似度根據函數調用序列的三組正則化編輯距離值確定。具體如表2和表3所示。 表2 函數的內部的三組編輯距離 表3 函數內部metric列表 函數內部的metric向量對函數邏輯和結構的反應足夠充分,因此對metric向量設置了較高的閾值。而函數名會在混淆后發生改變,因此設置了較低的閾值。函數調用序列因函數名的改變而變得難以確定函數節點的對應關系,因此也設置了較低的閾值。 實驗環境為一臺具有2.3 GHz Intel Core i5處理器的PC機,內存為16G。實驗程序采用Java語言實現。 對于得到的混淆前后函數的對應關系,采用人工評判的方式確認結果。結果統計如表4所示。 表4 實驗結果 觀察實驗結果,發現對于代碼規模較小的underscore數據集,找到的函數定義個數反而最多,究其原因,與函數調用信息提取所用的解析器的實現有關。本文在實現解析器時,以underscore數據集作為樣例,因此對其中出現最多的函數表達式形式定義的函數支持較好,而忽略了其他兩個數據集中函數定義常用的形式。 三個數據集普遍準確率大大高于召回率,這主要由于為函數內部metric設置了較高的閾值。假陽性數據則是因為兩個函數名相近(如later與b.after)。 JSNice是一款JavaScript語言的重構與反混淆工具,可以根據代碼上下文推測出函數原本的具有語義的名字。本文將混淆后的實驗數據用JSNice進行反混淆,發現JSNice對部分混淆后的函數并不能準確推測出原有的函數名,如underscore數據集中的_.where函數,在混淆后被換名為c.Xa,而JSNice給出的反混淆結果中此函數名為_.Xa。 檢測用時與代碼規模成正比,與JSNice的反混淆過程用時基本相當。 本文分析了常用的JavaScript代碼混淆器Google Closure Compiler的混淆手段,針對其中的換名策略,觀察到了函數調用關系圖和調用序列在結構上保持不變的特點,提出了基于函數調用信息的JavaScript混淆惡意代碼的自動檢測方法。實驗表明,此方法可檢測出混淆后的惡意代碼和混淆前代碼的對應關系,并且在檢測效果上優于一般的JavaScript反混淆工具。6.2 實驗方法與環境

6.3 實驗結果與分析
7 結論
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中華手工(2017年2期)2017-06-06 23:00:31
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
