基于樹到串模型強化的神經機器翻譯模型構建
2021-11-17 04:31:54鄒德芳胡秦斌
計算機仿真 2021年2期
鄒德芳 ,胡秦斌
(1.廣西中醫藥大學,廣西 南寧 530200;2.南寧師范大學計算機與信息工程學院,廣西 南寧 530001)
1 引言
人工智能與自然語言[1]技術蓬勃發展,利用計算機的機器翻譯對自然語言進行自動轉換成為了重要的研究方向。機器翻譯不僅可以打破語言屏障,實現國家與民族之間信息的有效傳遞,而且對文化交流、民族團結以及對外貿易等方面,均具有著強有力的推動作用。機器翻譯經歷了主導時期為理性主義方法與經驗主義方法的兩大發展階段,盡管前者根據人提取到自然語言間的轉化規律來描述翻譯知識,可以對自然語言進行分析、轉換與形成,但隨之而來的還有增加的翻譯知識整合難度、較長的開發周期以及高額的人工成本等諸多弊端;大數據與云計算的飛速進步,掀起了經驗主義方法的盛行之風,采用數學模型完成自然語言的轉換,統計機器翻譯就是該時期的典型代表。由于統計機器翻譯性能具有嚴重的依賴性,且通過局部特征無法獲取全局關系,因此,使神經機器翻譯得到了迅速普及,因其翻譯質量的明顯提升,從而在各個翻譯領域占有了重要的一席之地,演變為機器翻譯研究的前沿熱點。
文獻[2]通過數據增強技術,擴充了資源貧乏語種的訓練數據量,從而使神經機器翻譯的泛化性能得到加強;而文獻[3]則提出亞詞及單詞的維漢神經機器翻譯模型,把詞的翻譯單元轉換成詞與亞詞的混合翻譯單元,將ALU的非線性單元作為GRU的神經非線性單元,進而對神經機器翻譯模型進行改進。
由于上述翻譯模型無法完成結構差異較大的語言對翻譯任務,構建了基于樹到串模型強化的神經機器翻譯模型,通過連續性的神經網絡編碼,取得詞向量及其對應的隱狀態,利用源輸入文本矢量來界定編碼器隱狀態輸出,從而得到輸入層、輸出層以及正反向編碼層之間的權重關系,依據接收的終止標識符開啟解碼操作,將編碼器輸出的中間矢量更改為目標矢量進行輸出,并計算目標詞匯的條件概率,基于句法分析與翻譯構成的樹到串模型,采用GHKM算法提取對齊結構中的翻譯規則,通過搜索最優推導強化樹到串模型,根據解碼器葉子節點推算出非葉子節點狀態,最后利用各神經網絡單元構建神經機器翻譯模型。
2 傳統神經機器翻譯模型分析

圖1 神經機器翻譯模型示意圖
在機器翻譯領域中引入深度學習網絡,按照網絡性能對神經機器翻譯模型進行分類,能夠得到兩個模塊,分別是解碼器與編碼器。前者涉及到的算法為樹搜索算法,兩模塊的連接部分為關注力機制;而后者則常常會對詞向量、長短期記憶[4]網絡等重要技術進行應用。
編碼器將輸入端的源語言文本,通過神經網絡轉變為矢量空間內的向量表示。
神經機器翻譯的源輸入文本表達式如下所示
X={x1,x2,x3,…,xn}
(1)
其中,句子中的詞匯個數為n。
在編碼的初始階段,編碼器的Embedding層將對源輸入文本的所有詞匯xi(i∈n)進行編碼,將其轉換成下式所示的詞向量[5]表達式
Wi∈R|V|
(2)
其中,i=1,2,…,T,且Wi=[n1,n2,…,nm],ni∈R,源語言詞匯大小為V。
通過連續性的神經網絡編碼,所有詞向量Wi都會產生一個隱狀態hi,該隱狀態含有當前的詞匯信息,將當前的隱狀態作為神經網絡下一刻的輸入,其會在門閥機制的效用下,對當時的隱狀態信息實施保存,因此,在對最后的單詞xn進行編碼時,隱狀態hn將蘊含句子的所有隱狀態信息。由于大多數的隱狀態均為提取的語義信息[6],所以,利用源輸入文本矢量來界定編碼器隱狀態輸出。
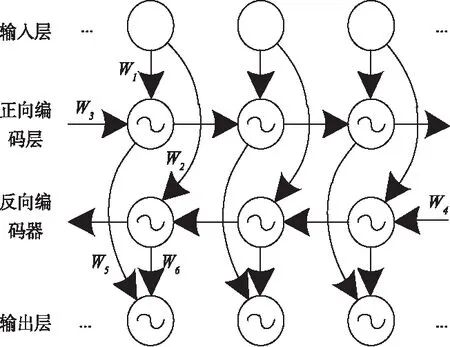
圖2 循環神經網絡結構示意圖
圖2中,輸入層到正向編碼層的權重為W1,到反向編碼層的權重為W2,正向編碼層的自循環權重為W3,反向編碼層的自循環權重為W4,正向編碼層到輸出層的權重為W5,反向編碼層到輸出層的權重為W6。所有的時刻流程均將重復利用到上述六個權重,而正、反向編碼層箭頭流向的去除,也使結構的非循環特性得到了保證。
解碼器通過將編碼器輸出的中間矢量更改為目標矢量后實施輸出操作。如果源輸入文本的終止標識符被編碼器所接收,則停止編碼,解碼階段開啟。將源輸入文本的矢量表示設定為初始化解碼器[7]單元,即s1=hn。
解碼就是對所有目標詞匯在已知部分輸出時的條件概率進行計算的過程。根據當前解碼器的隱狀態sj與前j-1個輸出成功的目標詞,就能夠推算出第j個目標詞的條件概率,其計算公式如下所示
P(yj|yj-1,x)=g(sj)
(3)
式中,非線性函數表示為g,其中的sj則通過下列公式進行表示
sj=f(yj-1,sj-1)
(4)
模型通過條件分布的學習,在已知一個源輸入文本的前提下,采用樹搜索算法,就可以對具有最大似然估計值的目標詞匯進行輸出,即翻譯輸出。
3 樹到串模型強化策略
樹到串強化模型劃分翻譯過程為句法分析和翻譯兩個階段。設置中文為源語言,英文為目標語言,創建樹到串強化模型,如圖3所示,該模型主要由源句法分析樹、目標串和源端與目標端文本串之間的對齊信息等部分架構而成。

圖3 樹到串強化模型示意圖
通過GHKM算法對上圖里的對齊結構進行樹到串翻譯規則的提取,其規則樣例如表1所示。

表1 規則樣例統計表
上表中規則內容的左邊指代一棵樹片段,其中,非終結符表示為x;右邊則為對應的翻譯信息。因為樹到串模型提取的規則,蘊含著較為充盈的層次信息,所以,該模型相對于同步上下文文法的表達性能也具有明顯的優越性。
抽取訓練集內所有的翻譯規則,并利用一個規則統計表對其進行整合,基于句法分析[8]樹的全部推導D,完成解碼器對最優推導d*的搜索,然后依據匹配規則統計表的翻譯原則,實現推導與目標翻譯的轉換。所以,采用下列優化目標函數,對樹到串強化模型的目標進行描述
(5)
上式中,規則統計表的匹配原則表示為r。
由于規則4和7的左邊無法匹配完全,在實際情況中將存在較大差異,但該樹到串強化模型均將源端的詞匯化節點“shalong”翻譯為目標端的“Sharon”,證明了該模型具有良好的性能發揮。
4 基于樹到串模型強化的神經機器翻譯模型構建
傳統模型無法對不同語言的差異性進行有效處理,不僅丟失了源語言語法信息,而且也對目標端的翻譯內容造成了不流暢的影響。而樹到串模型強化的神經機器翻譯模型將詞匯、短語進行有機結合,利用結構化信息[9]的提取能力,使語句富有一定規則的結構化信息,從而實現在機器翻譯中引入更多的語法信息。
解碼器屬于連續性神經網絡解碼器,如果將其葉子節點狀態用隱狀態hj來表示,則可以推算出其非葉子節點狀態,表達式如下所示
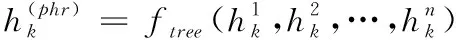
(6)
其中,解碼器的葉子節點個數為n。
基于長短期記憶結構分析翻譯模型的解碼器,將每個長短期記憶單元作為解碼器的各個節點,所以,各層節點都包括下一層節點所提取的結構化信息。
該翻譯模型的各神經網絡單元j均由輸入門ij、輸出門oj、記憶單元cj以及隱狀態hj所組成,其門向量與記憶單元的更新主要依賴于其所有子節點的狀態,且該神經網絡的所有子節點k都存在一個對應的忘記門fjk,由此導致其神經元可以在各子節點里完成信息的提取與融合。通過創建的翻譯模型,既能夠在一個語義相關的語料[10]內對強調的語義進行學習,也可以從情感分類任務里對情感信息豐富的子類實施保存。假設神經機器翻譯模型源序列內詞匯j的一個輸入矢量為xj,依據不同的輸入形式,將模型中樹到串模型強化的神經網絡劃分成子類與樹形長短期記憶、N維樹形長短期記憶兩個類別。
若一棵樹存在一個節點j,其全部子節點的集合設定為C(j),那么,下列各式即為子類與樹形長短期記憶神經網絡的轉換表達式

(7)

(8)

(9)

(10)
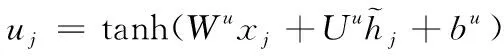
(11)
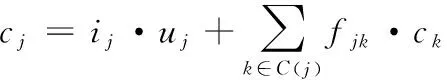
(12)
hj=oj·tanh(cj)
(13)
上列表達式內的所有參數矩陣,都可以直觀地理解成神經網絡單元里隱藏狀態hk與輸入向量xj的編碼相關參數。以依存樹的應用為例,如果輸入的是語義信息相對關鍵的動詞詞匯,輸入門ij的取值約等于1,相反,輸入的是比較次要的語義信息詞匯,輸入門ij的取值約等于0,那么,模型就能夠對權重參數Wi進行求取。
而N維樹形長短期記憶處理的樹到串場景則是分支數量為N,且子類呈有序狀態的結構。不同于子類與樹形長短期記憶的是,該類神經網絡的所有隱狀態hj均能在經過訓練后,得到結構上相對應的權重矩陣Uj。通過將矩陣添加到所有子類中,令基于單元子類狀態方面的N維樹形長短期記憶相比子類與樹形長短期記憶,具有更好的學習能力,從而獲取更多的微調條件。因此,采用下列各式對N維樹形長短期記憶神經網絡轉換進行描述
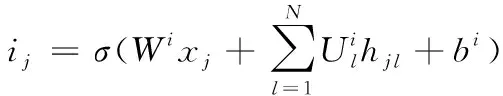
(14)

(15)

(16)

(17)

(18)
hj=oj·tanh(cj)
(19)
5 仿真研究
5.1 仿真環境
為驗證所提方法的有效性,設計仿真對比實驗。仿真環境的電腦硬件配置為64位Windows7 SP1旗艦版操作系統,實驗任務內容為中英翻譯,語料的相關信息如表2所示。

表2 實驗語料信息統計表
根據表中數據顯示,句子結構長度均值比提取最長名詞短語的句子長度均值減少了9.22,而相對于提取最長名詞短語的句子長度均值,最長名詞短語長度均值則下降了14.75。
表3所示為樹到串模型強化的神經機器翻譯模型參數統計表。

表3 翻譯模型參數統計表
在模型仿真的過程中,通過樹搜索算法獲取譯文,將束大小取值10。
5.2 句子敏感性分析
采用文獻[2]方法和文獻[3]方法作為對比方法,采用對比方法模型與所提模型,分別對實驗語料進行翻譯,以獲取句子長度與譯文質量的影響關系,圖4為不同句長分布的譯文質量BLEU示意圖。

圖4 基于不同句長分布的各模型譯文質量對比
通過上圖可以看出,句長的不斷上升導致了譯文質量的持續降低,尤其是句長大于20之后,文獻模型的下降幅度顯著變大,但所提模型的曲線走勢始終處于相對平緩的狀態,波動較小。從側面說明,句長對所提模型的影響并不明顯,且當句長超過一定數量時,所提模型的性能愈發優越。
5.3 翻譯效率分析
采用三種不同的模型翻譯實驗語料50000詞,得到翻譯效率對比結果如圖5示。

圖5 各模型翻譯效率對比
分析圖5可知,文獻[2]模型對50000詞的平均翻譯時間為17s,文獻[3]模型的平均翻譯時間為23s,所提模型的平均翻譯時間為5s。
所提模型利用樹搜索算法,對具有最大似然估計值的目標詞匯進行輸出,有效減少了翻譯時間,翻譯輸出較快。由此可見,所提模型的翻譯耗時較短,翻譯效率好。
6 結論
本文對基于樹到串模型強化的神經機器翻譯模型進行構建。經過分析傳統神經機器翻譯模型的運行原理,獲取編碼器與解碼器的具體工作流程與性能發揮,通過GHKM算法實施對齊結構的翻譯規則提取,采用優化目標函數架構樹到串模型強化策略,根據語句的結構化信息,實現語法信息的引入,利用隱狀態與長短期記憶結構,使神經機器翻譯模型構建得以完成。該模型為今后相關領域的探索提出了指導性的建議與方針,具有一定的現實意義與理論意義。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
中外會展(2014年4期)2014-11-27 07:46:46
中華胰腺病雜志(2012年3期)2012-11-07 05:18:45
