基于Mask R-CNN的車位狀態智能識別算法
2021-11-17 04:31:48程遠航
計算機仿真 2021年2期
關鍵詞:檢測
程遠航,余 軍
(貴州大學科技學院,貴州 貴陽 550003)
1 引言
圖像目標檢測技術隨著深度學習技術的成熟得到快速發展。作為主要深度學習技術之一,R-CNN(Reigions with CNN features,遞歸神經網絡)算法是典型的目標檢測算法[1],該算法主要在GPU內實現,計算效率與準確性能夠得到保障。因此R-CNN算法普遍應用在圖像目標檢測領域中。近些年,R-CNN算法在目標檢測領域中不斷創新,先后提出Fast R—CNN、Faster R—CNN、YOLO、SSD等算法[2]。Mask R—CNN算法是在Fast R—CNN算法基礎上添加了并行的mask分支[3],可針對不同ROI構建一個像素級別的二進制掩碼。利用Mask R—CNN算法不僅能夠分割圖像邊界框,同樣適用于圖像內物體的細粒度分割,并且具有較高的檢測精度與效率。因此,將Mask R—CNN算法應用于車位狀態智能識別過程中,提出基于Mask R-CNN的車位狀態智能識別算法。
2 車位狀態智能識別算法
2.1 Mask R-CNN網絡
Mask R-CNN網絡的本質為Faster R-CNN網絡的并行擴展,通過增添一個分支網絡不僅完成目標檢測,并且能夠分割目標像素。利用該算法可實現目標檢測、圖像實例分割與車輛關鍵點檢測等過程。圖像檢測技術后的下一過程即實例分割,通過圖像目標檢測分類不同單體目標并逐一標記后,通過實例分割在各像素上明確目標的具體類別[4]。Mask R-CNN網絡模型框架如圖1所示。
利用Mask R-CNN網絡檢測圖像目標過程中,首先確定圖像內的ROI(感興趣區域),利用ROI ALign修正各ROI內像素,利用Faster R-CNN網絡框架預測各ROI實例類別,由此獲取圖像實例分割結果。將Faster R-CNN網絡內添加的mask分支作為Mask R-CNN網絡內的損失函數,其表達式為:
S=Scls+Sbox+Smask
(1)
上式內,Scls、Sbox和Smask分別表示分類誤差、檢查誤差和分割誤差,其中Smask描述各ROI內像素通過sigmod函數獲取的平均熵誤差。采用mask編輯輸入目標空間布局的代碼。預測ROI過程中主要采用m*m的矩陣,主要是由于這樣可以最大限度上確保ROI空間信息的完整性[5]。在智能查找停車位過程中,ROI區域內通常為“車輛”,所以式(1)內的Smask可理解成“車輛”的分支的mask。Mask R-CNN網絡整體由三部分組成[6],分別是特征提取階段的主干網絡、識別分類邊界框的頭結構和區分不同ROI的mask預測。
Mask R-CNN網絡與Faster R-CNN網絡的區別是該算法中針對當前RCNN頭結構進行了擴展。
2.2 基于Mask R-CNN圖像中汽車檢測
在具有時變性與復雜性的交通路線內查找并定位車位[7],可通過視頻監控實現,檢測停車位視頻圖像內的車輛,同時確定不同幀圖像內車輛是否產生位移,以此預測車位位置。
檢測視頻圖像內車輛信息時在GPU內采用Mask R-CNN網絡,可實現數幀/s的高分辨率目標檢測。用Mask R-CNN網絡在確定視頻圖像內不同對象位置的同時,還可以描述不同對象的大體外框結構。

圖2 Mask R-CNN圖像檢測
在訓練Mask R-CNN網絡過程中選用內涵object masks注釋圖像的COCO數據集。同時,針對我國實際交通狀態特征,在數據集中選取海量汽車圖片并追蹤選取圖片內的全部汽車。另外,針對待檢測的視頻圖像,在獲取汽車信息的同時,同樣需要綜合交通信號燈、樹木、行人等信息。
在視頻圖像中利用Mask R—CNN網絡模型檢測汽車目標能夠獲取四種不同類型的信息[8]。分別是:①視頻圖像內對象類型,通常用整數描述,對COCO數據集中數圖像Mask R—CNN網絡模型可檢測出75種以上、如汽車、人、建筑等不同類型的常見物體。②視頻圖像內物體目標檢測的置信度,其值同Mask R—CNN網絡模型準確識別對象的概率之間成正比關系。③視頻圖像內檢測目標的邊界框,同時檢測目標所在位置通過橫、縱坐標位置比描述。④呈現邊界框內部分像素歸屬于檢測目標和像素不歸屬,檢測目標的位圖“mask”,分析并處理這部分數據,由此確定檢測目標的外框結構。
目標識別與分割過程如下:利用Mask R—CNN網絡模型檢測目標之前,需先訓練該模型。因采集視頻圖像數量較少,為避免Mask R—CNN網絡訓練過程出現過擬合問題,首先訓練COCO數據集,該數據集內包含近9萬個樣本,且各樣本內的物體類別僅具有語義標注,適用于圖像目標檢測與分割。分別采集錐形、圓柱形、球形、正方形等常見目標物體,通過LableMe標記獲取標簽圖[9]。選取數據增廣方式隨機旋轉原圖像角度獲取新圖像,由此降低樣本多樣性缺陷的問題。為降低光照電度與顏色波動對于目標識別產生的副作用,選取新的數據增光方式變化視頻圖像RGB通道強度,對RGB視頻圖像像素值實施主成分分析后,將視頻圖像內各像素增加一個隨機倍數的主成分,公式描述為:
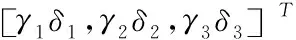
(2)
上式內,y表示RGB視頻圖像像素值的3*3協方差矩陣的特征向量,γ表示隨機變量,δ表示協方差矩陣的特征值。其中γ符合高斯隨機分布。
視頻圖像中通常存在一定程度的噪聲干擾,因此在進行Mask R-CNN網絡訓練時需實施中值濾波操作[10]。訓練流程如圖3所示。
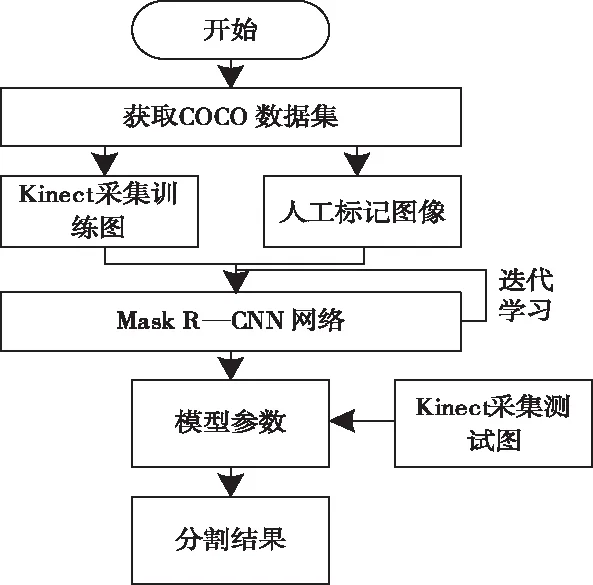
圖3 Mask R-CNN網絡訓練流程圖
Mask R-CNN網絡訓練總共由三部分組成,分別是:利用學習率為0.001訓練頭部輸出網絡層;利用學習率為0.001訓練四層以后的網絡層;利用學習率為0.0001訓練整體Mask R-CNN網絡層。當模型訓練誤差固定時訓練結束。
為確定訓練后Mask R-CNN網絡分割結果的性能,以重疊率為指標評價視頻圖像目標識別與分割的準確度,式(3)描述重疊率計算過程

(3)
上式內,ZE和ZH分別表示Mask R-CNN網絡預測分割的區域的實際視頻圖像中目標區域。
通過上述目標識別與分割過程能夠檢測到視頻圖像內的汽車對象,并得到各汽車的邊界框和坐標位置,如圖4和表1所示。

圖4 汽車邊界

表1 汽車坐標位置
2.3 識別車位狀態
通過Mask R-CNN網絡獲取單幀視頻圖像內汽車外邊框與像素坐標位置后,連續檢測多幀視頻圖像,若汽車坐標位置未出現變化,則可判斷此區域為停車位。
經過分析Mask R-CNN網絡檢測汽車邊界框的結果可知,汽車邊界框與停車位邊界框存在部分交叉區域,因此可通過IOU(Intersection over union)法判斷兩個邊界框交叉區域的像素數量,同時確定其與兩個汽車目標覆蓋區域像素總量的商值。
IOU法實現過程如圖5所示。利用Mask R-CNN網絡檢測視頻圖像內目標后,得到不同目標的邊界框和坐標位置,將得到的全部信息輸入IOU法內。
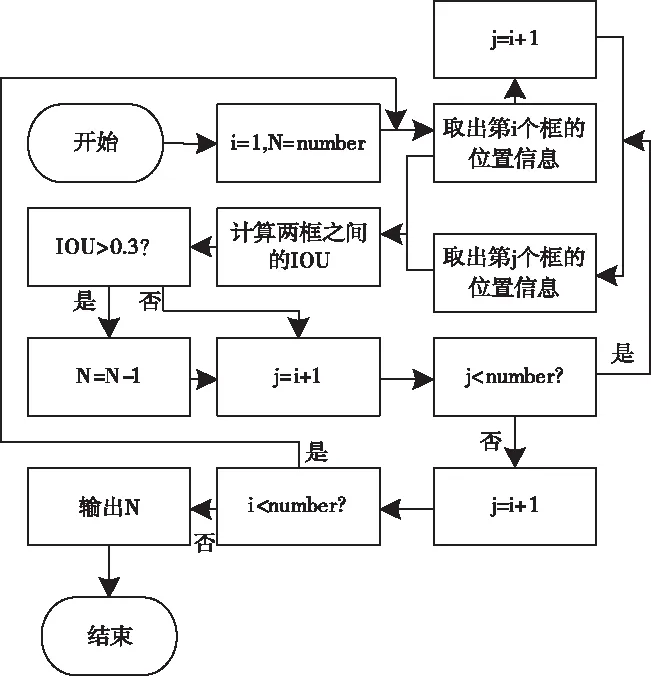
圖5 IOU法實現過程
圖5中number和n分別為Mask R-CNN網絡檢測出的汽車數量和通過IOU法過濾后視頻圖像中實際車輛數。
通過 IOU法可大致確定視頻圖像中停車位邊界框與汽車邊界框之間的交叉程度。設兩個邊界框整體交叉時IOU值為1,在IOU值不大于0.15時,表示停車位絕大部分區域沒有被汽車占據,這說明停車位當前處于空閑狀態;在IOU值大于0.5時,表示停車位大部分區域被汽車占據,表明停車位當前處于非空閑狀態。
3 實驗分析
為驗證本文提出的基于Mask R-CNN的車位狀態智能識別算法的有效性,選取我國南方某城市中凌河區為實驗區域,設定實驗環境與訓練數據集后,進行車位狀態識別,結果如下。
實驗環境:i7處理器,64G內存。
訓練數據集:COCO數據集。
圖6所示為本文算法車位狀態識別的結果,其中紅色邊框為非空閑車位,綠色邊框為空閑車位。

圖6 車位狀態識別結果
由圖6可知,在不同視頻圖像中采用本文算法均可有效檢測出不同環境中的停車位,并準確識別出車位是否為空閑狀態,由此可知本文算法可有效實現車位狀態識別目的。
表2所示為針對上述三幅視頻圖像,本文算法、基于邊緣檢測的識別算法和基于四元數劇理論的是識別算法在目標檢測的精度與用時。

表2 目標檢測的精度與用時對比
由表2得到,包括本文算法在內的三種算法中本文算法的目標檢測精度均在99%以上,而其它兩種算法精度在90%—94%之間,其中基于邊緣檢測的識別算法精度略高于基于四元數劇理論的識別算法。本文算法目標檢測用時顯著少于兩種對比算法,而基于邊緣檢測的識別算法所需時間略高于基于四元數劇理論的識別算法。由此可知本文算法在目標檢測方面的性能顯著由于對比算法。
表3所示為三種算法對于車位狀態識別的精度與所需時間。

表3 車位狀態識別的精度與時間對比
分析表3得到,本文算法在識別車位狀態時的精度達到100%,而所需時間也少于對比算法。綜合表2內容得到本文算法在識別車位狀態時具有較高的精度和效率。
為測試本文算法在識別車位狀態過程中的實時能耗,分別采用本文算法、基于邊緣檢測的識別算法和基于四元數學理論的識別算法識別實驗區域內車位狀態,對比不同算法識別過程中的實時能耗,結果如圖7所示。

圖7 不同算法車位狀態識別過程能耗對比
如圖7可知,本文算法在識別車位狀態過程中的實時能耗控制在0.60J/s之下,平均能耗大約為0.35J/s。基于邊緣檢測的識別算法和基于四元數劇理論的識別算法實時能耗上限值分別達到1.1J/s以上和1.0J/s以上,平均能耗與本文算法相比分別提升0.4J/s以上。上述實驗結果說明本文算法識別車位狀態過程中實時能耗顯著低于對比算法。
不同停車位狀態識別算法的核心技術對比如表4所示。通過對比不同算法核心技術的優、劣勢,驗證本文算法的適用性。
分析表4中的內容可得,相較于其它幾種對比算法,本文算法最適合作為車位狀態識別算法,這是由于本文算法在查找停車位過程中使用的攝像頭成本較低,安裝與維護相對簡單,利用一個攝像頭可監控數個停車位,這將顯著降低硬件裝配過程的工作量。并且本文方算法的劣勢主要針對高速移動車輛,但汽車在駛進/駛出停車位時通常速度不會太快,因此這一劣勢可忽略。
由此可知本文算法具有較高的適用性,可普遍推廣。

表4 不同車位狀態識別算法的核心技術對比
4 結論
相較于以往普遍使用的目標檢測算法,Mask R-CNN網絡模型檢測精度更高,且不通過滑動窗口即可高效檢測整副圖像內的全部目標,所以本文提出的基于Mask R-CNN的車位狀態智能識別算法的尋找效率較高。但通過后續大量實驗測試與應用反饋得到,在某些條件下單幀圖像內會存在少量汽車被漏檢的現象,因此要實際查找車位并判斷車位是否空閑時需檢測7、8幀的連續視頻圖像,避免因單幀視頻圖像漏檢問題導致識別偏差。同時這也是后續研究中的主要研究方向。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
