小波變換結合連續投影算法優化茶葉中咖啡堿的近紅外分析模型
2021-11-15 05:37:02趙靜遠熊智新寧井銘謝德紅
分析科學學報 2021年5期
趙靜遠, 熊智新*, 寧井銘, 謝德紅
(1.南京林業大學輕工與食品學院,江蘇南京 210037;2.安徽農業大學茶樹生物學與資源利用國家重點實驗室,安徽合肥 230036)
茶葉中的咖啡堿是茶葉生物堿的主體成分,約占干物質質量的2%~4%,其有興奮、利尿、解毒、強心,促進血液循環的作用[1 - 3]。咖啡堿可以作為茶葉的特征性化學物質之一,可用于判斷茶葉的真假[4]。近紅外光譜(Near Infrared Spectroscopy,NIRS)作為一種高效、快速、低成本、無污染的在線檢測的分析技術,在農業[5]、醫藥[6]、煙草[7]和食品[8]等行業得到廣泛地重視和應用。目前,國內外學者已利用近紅外光譜對茶葉進行了定性分類和定量研究[9 - 13]。利用近紅外光譜定量分析咖啡堿依賴于模型的可靠性,但是近紅外光譜信息復雜和全譜建模的預測能力不足會影響模型的穩定,通常采用波長變量選擇方法,篩選出信息強且對外界影響因素不敏感的波長,從而建立更穩健的模型[14]。已有文獻報道[15 - 18]連續投影算法(Successive Projections Algorithm,SPA)能夠有效消除眾多波長變量間的共線性影響,降低模型復雜度,以其簡便、快速的特點得到廣泛應用,在多種樣品組分的特征波長選取中取得了很好效果。
近紅外漫反射光譜由于受到儀器條件、測量環境、樣品狀態等諸多因素影響,其中含有各種高頻的隨機噪聲、基線漂移、信號本體、樣品不均勻和光散射等干擾[19]。已有研究多采用多元散射校正等[20,21]方法盡可能消除這些因素對光譜的干擾,但究竟應該采用何種預處理方法更有利于SPA算法挑選波長,目前所見相關報道較少。本文研究重點即采用小波變換(Wavelet Transform,WT)、多元散射校正(Multiplicative Scatter Correction,MSC)、標準正態變量變換(Standard Normal Variate Transformation,SNV)以及一階微分(First Derivative,1stD)等預處理方法單獨或組合對光譜進行預處理,再結合SPA算法建立茶葉中咖啡堿的偏最小二乘回歸(Partial Least Square Regression,PLSR)預測模型。通過比較各模型的精度,探討SPA算法和各種預處理方法結合的最佳途徑,以期在消除各種低頻和高頻噪聲干擾的基礎上,充分發揮SPA波長選擇能力,獲得最佳共線性的波長變量子集,提高所建模型的質量。
1 實驗部分
1.1 儀器及試劑
德國布魯克公司生產的MPA型多功能傅里葉變換近紅外光譜儀,帶有RT-PbS檢測器、OPUS/OVP(OPUS validation program)自檢功能,附有內置鍍金漫反射積分球、樣品旋轉器和石英樣品杯等配件。
茶葉樣本包括2007年度不同地區的高、中、低檔茶葉樣本158個,由寧波市進出口檢驗檢疫局、中國農業科學院茶葉研究所和鎮江市林業局提供。其中包括龍井、碧螺春等優質名茶、大宗茶,市售一般綠茶等。由于樣本大多數取自于各茶廠的送檢樣品,故每份樣品只編號未標注具體的茶葉品種和送檢單位。同時為擴大模型的適用性,實驗中未細分綠茶品種。所有送檢樣品均已密封保存4個月。
1.2 實驗方法
1.2.1 咖啡堿含量測定稱取茶葉樣品30±1 g,置于HY-02小型磨碎機(北京環亞)中研磨10 s,按照我國國家標準(GB/T 8303-2012)[22],將磨碎樣品過100目篩(150 μm),按照國家標準(GB/T 8312-2013)[23]規定方法測定茶葉樣品中咖啡堿的含量,每個樣品進行3次平行檢測。
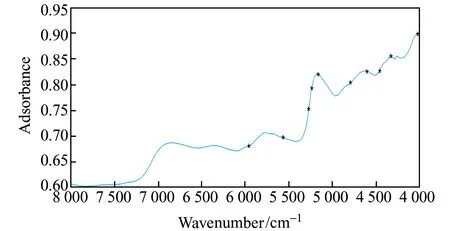
1.2.2 光譜采集茶葉樣品光譜采集范圍:12 800~4 000 cm-1,分辨率:4 cm-1。實驗溫度:20 ℃,相對濕度:40%。均以儀器內置鍍金為背景。因在8 000~4 000 cm-1波段茶葉近紅外光譜圖中的波峰較多且比較明顯,故截取該波長范圍內共1 038個波長點用于分析研究。圖1為部分樣品的近紅外光譜圖。
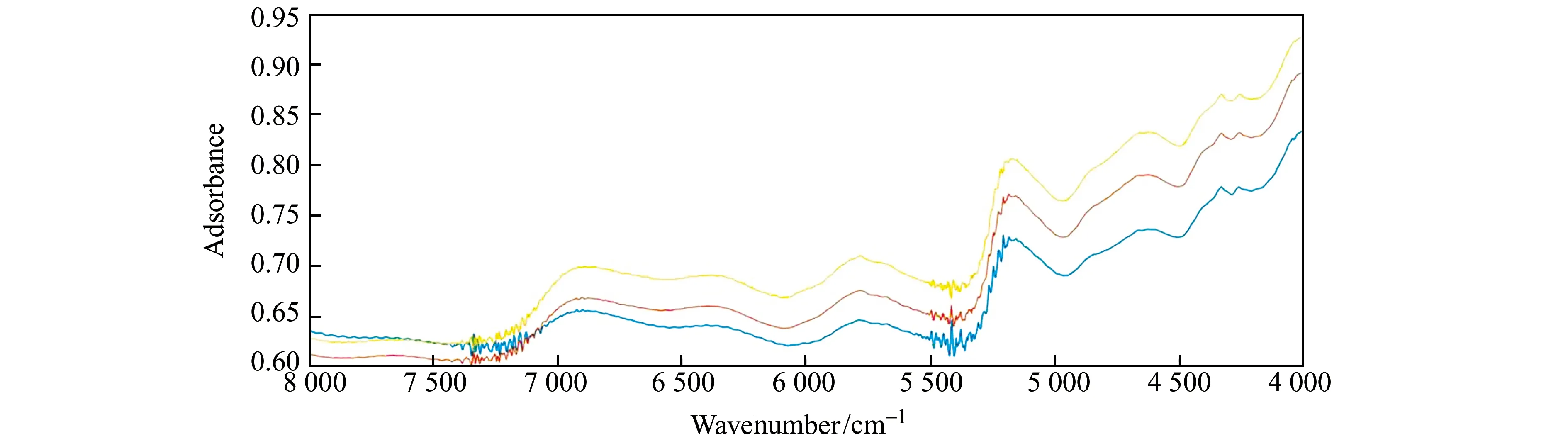
圖1 部分茶葉樣品的近紅外光譜圖Fig.1 Near-infrared spectra of tea samples
1.2.3 樣品集的劃分本文采用主成分分析(Principal Component Analysis,PCA),利用提取的光譜主成分得分向量來代替光譜向量計算樣本的馬氏距離(Mahalanobis Distance)[24],將超出設定的馬氏距離閾值的異常樣本進行剔除,最終從158個樣本中剔除兩個異常樣品,然后采用SPXY[14]將剩余的156個樣本劃分為校正集和預測集。SPXY在計算樣品距離時同時將變量x和變量y考慮在內,分別計算各變量和變量之間的距離,分別見式(1)和式(2):
(1)
(2)
在式(1)和式(2)中,n和m表示任意兩個樣品,Z是總的樣本數,l為光譜的波數點,dx(n,m)表示兩條光譜的空間距離,dy(n,m)表示對應咖啡堿之間的距離。
兩個樣品間的SPXY標準距離計算公式如式(3)所示。
(3)
最終156個樣本用SPXY法以3∶2的比例,劃分為93個校正集樣本和63個預測集樣本。校正集用于建立茶葉咖啡堿近紅外模型,預測集用于驗證所建模型的準確性和可靠性。樣品集劃分結果見表1。

表1 茶葉樣本中咖啡堿的含量分布Table 1 Content of caffeine in tea samples
1.2.4 光譜預處理方法分別采用WT、MSC、SNV以及1stD對光譜進行預處理,探討各種方法及它們之間的組合對模型精度的影響。小波變換的實質[25]是將信號x(t)投影到小波基函數ψa,b(t)上,即x(t)與ψa,b(t)的內積,得到小波變換系數。按照分析的需要對小波變換系數進行處理,然后利用處理后的小波系數得到反變換信號。小波變換用于處理光譜原始數據的一般方法為:首先對原始光譜進行小波分解變換分解得到高頻和低頻小波系數;然后通過閾值法去除小波系數中被認為是表示噪聲的元素(濾噪),或去除小波系數中的高頻(低尺度)元素;最終用經過處理系數進行反變換即可得到濾噪后的光譜信號。
由于小波變換中用到的小波函數不具有唯一性,同一問題用不同的小波函數進行分析有時結果相差甚遠,因此小波函數的選用是小波變換實際應用中的一個難點,目前都是基于經驗或不斷實驗后通過結果比較來選擇最佳的小波函數[14]。本文即采取實驗方法選擇不同小波函數處理茶葉近紅外光譜并建模,結果表明采用db3小波函數并分解為7層能較好地分辨光譜低頻和高頻信號并予以處理,建模精度較高。本文后續即選擇db3小波7層分解開展光譜數據處理研究。
1.2.5 變量篩選方法SPA是一種前向循環變量選擇方法[26]。從選定一個波長開始,每次循環都計算在未入選波長上的投影,將投影向量最大的波長引入到波長組合。每一個新入選的波長,都與前一個線性關系最小。在波長選擇中,假設n為初始波長數,為m波長點個數,k(0)為初始波長點。SPA的計算步驟如下:
(1)第一次迭代(Z=1)開始前,在光譜矩陣中任選一列波長向量Xj。記為Xk(0),即k(0)=j,j∈1,…,n;
(2)將未入選的列向量位置集合記為S,S={j,1≤j≤n,j?{k(0),…k(Z-1)}};
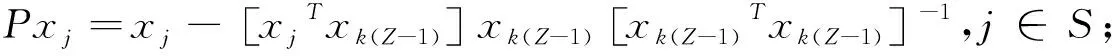
(4)提取最大的投影值的波長變量序號:k(Z)=arg[max(‖Pxj‖)],j∈S;
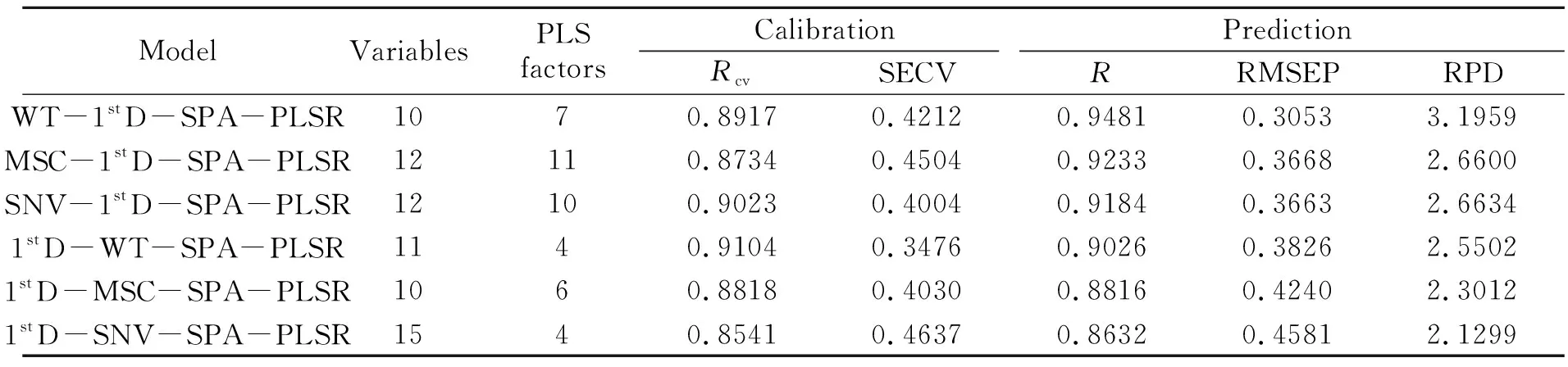
(5)令xj=Pxj,j∈S;
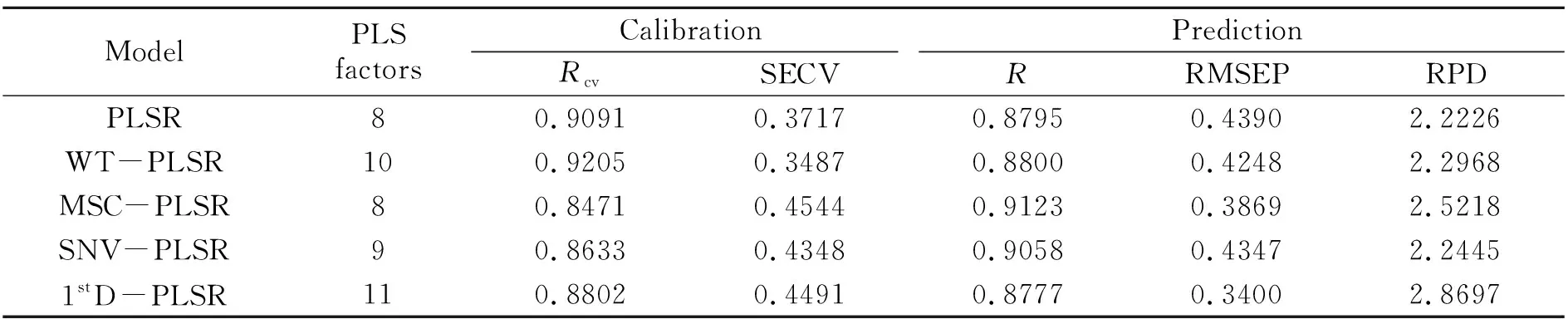
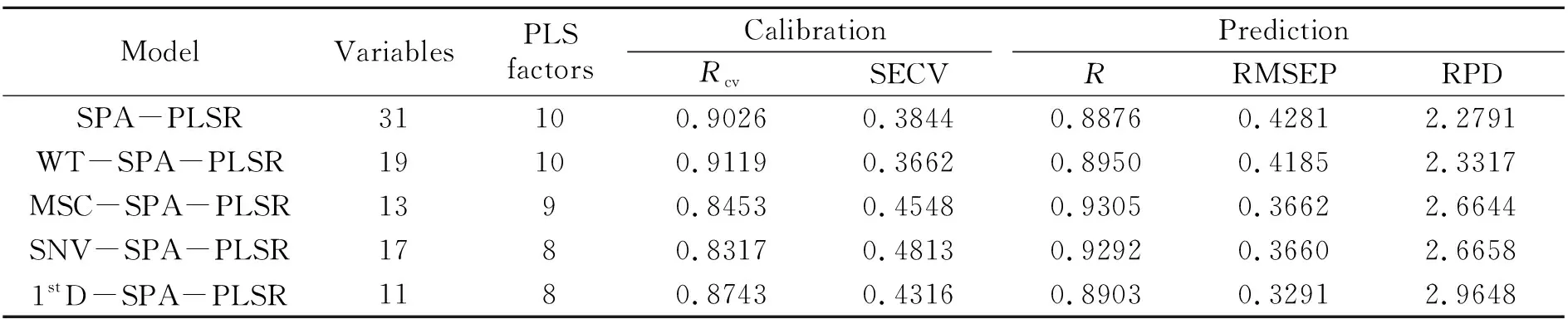
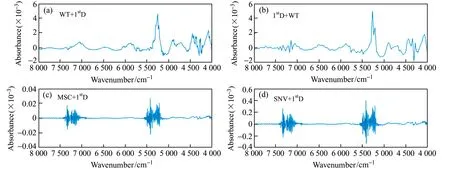
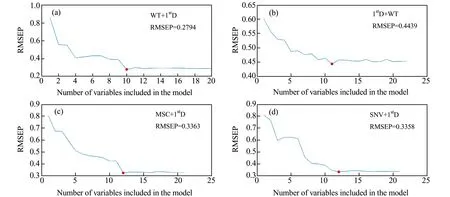
(6)Z=Z+1,如果Z {k(Z),Z=0,…,m-1}為最終選取的波長變量組合。算法對每次選擇的結果進行建模預測分析,以最小均方根誤差(RMSEP)來決定所建模型的優劣,它所對應的即為波長集合的最佳初始波長點n和最佳波長點個數m。 研究中采用粉末狀茶葉樣品測量近紅外光譜,因此由茶粉顆粒分布不均勻及顆粒大小不同產生的散射誤差將是信號中的主要干擾,其通常表現為基線的平移、旋轉(低頻)和二次和高次曲線(高頻)等[25]。在各種預處理方法中,SNV、MSC通常用于校正低頻散射信號、1stD可以消除信號的旋轉,而WT基于多分辨分析原理,則可以同時消除光譜信號中的高頻和低頻噪聲。分別以WT、MSC、SNV和1stD預處理光譜后采用PLSR建模統計結果列于表2。使用驗證集相對分析誤差(RPD)對模型進一步評價,如果RPD≥3.0,說明定標效果良好,建立的定標模型可以用于實際檢測;如果2.5 表2 采用不同預處理方法的全波段PLSR模型性能Table 2 Performance of full-band PLSR models using different preprocessing methods 分別用WT、MSC、SNV和1stD處理近紅外光譜,再利用SPA算法挑選波長并建立相應的PLSR預測模型,模型的預測結果見表3。從表3可看出,通過三種預處理方法結合SPA波長選擇方法,能有效地減少入選波長數量(從原始1 038個波長減少到31個以下),且模型的精度總體上也有了一定地提升,其中1stD入選波長最少(11個)。 表3 不同預處理方法結合SPA的PLSR模型預測結果Table 3 PLSR model prediction results of different pretreatment methods combined with SPA 圖2分別為WT、MSC和SNV分別結合1stD預處理方后的光譜圖,為便于比對,圖中還列出先1stD再WT處理結果(圖2(b))。表4則是在1stD+SPA基礎上分別與MSC、SNV、WT等預處理方法結合后的建模效果。 表4 小波變換結合1stD+SPA的PLSR模型預測結果及比較Table 4 Prediction results and comparison of PLSR models combined with wavelet transform and 1stD+SPA 從圖2中可以看出,茶粉近紅外光譜經WT-1stD或1stD -WT預處理后在6 000~4 000 cm-1波段有較明顯的吸收峰,幾乎不受噪聲干擾,而MSC-1stD和SNV-1stD處理后峰信息則完全淹沒在噪聲信號中。從表4中可以看出,WT結合1stD(WT-1stD或1stD -WT)最終建模效果總體優于其它幾種預處理方法,而又以WT-1stD -SPA-PLSR組合所建模型最好,且只用10個入選波長建模。這說明利用WT預先消除光譜信號中的大部分高頻噪聲,有利于1stD方法提高分辨率和提供更清晰的光譜輪廓變化,減少近紅外原始重疊譜帶波長之間高共線性,挑選出更有代表性的特征波長。其挑選出的波長數10和通過交叉驗證確定的最佳PLS成分數7也比較接近,表明WT-1stD預處理后采用SPA方法所選波長具有較好的代表性和相對獨立性,由此建立的模型比較穩健,故其校正精度和預測精度均較高。 從表4還可以看出,1stD和MSC、SNV、WT結合處理先后順序對模型結果影響明顯,而且先1stD后進行其它預處理總體建模效果略差。其原因可能在于原始信號經1stD處理后,有效信號和被放大的高頻噪聲混疊嚴重,后續的WT、SNV和MSC分別采用頻域方法和統計方法抑制高頻信號的同時也削弱了有效信號。比較圖2(a)和圖2(b)可以看出,對于1stD -WT處理,由于WT對1stD放大的噪聲以及微分信號都進行了去高頻處理,故其信號較WT-1stD平滑,可能損失部分譜峰信息而降低建模效果。 圖2 茶葉近紅外光譜分別經WT、MSC和SNV并結合1stD預處理圖Fig.2 The near-infrared spectra of tea pretreated by WT,MSC and SNV combined with 1stD 圖3是不同方法與1stD及SPA組合預處理光譜并建模計算RMSEP值的結果。由圖3(a)可以看出,經過對校正集數據進行WT-1stD預處理后,在SPA選擇過程中均方根誤差的變化情況。在選擇4個光譜波長變量之前曲線下降趨勢很大,表明茶葉中咖啡堿含量的光譜波長變量應該至少選擇4個以免產生過擬合的問題;選擇4個到10個光譜波長變量時均方根誤差曲線下降至最低值;之后選擇10個以上的光譜波長變量時,曲線雖有升降但總體趨于平緩。最終選擇10個光譜波長變量,其均方根誤差(RMSEP)達到最小為0.2794。其它幾種預處理方法組合也有類似趨勢,但最終入選波長均大于10個,但大都少于未用1stD處理入選波長數(表3)。這都說明正是1stD提高了光譜分辨率,利于后續SPA算法挑選出少數特征波長。 圖3 WT、MSC和SNV結合1stD及SPA選取特征波長數及RMSEP值Fig.3 The number of selected characteristic wavelength and RMSEP by WT,MSC and SNV combined with 1stD and SPA 圖4譜圖上標出了經WT-1stD -SPA預處理并建立咖啡堿近紅外分析PLSR模型所選擇的10個波長點(4 003、4 350、4 473、4 627、4 812、5 175、5 244、5 275、5 583和5 984 cm-1)位置。咖啡堿又名1,3,7-三甲基黃嘌呤,其碳氮嘌呤環結構由一個嘧啶環和一個咪唑環稠合而成,雜環上含有三個-CH3和兩個C=O[4]。由于茶葉作為組分復雜的自然產物,各有機組分官能團在近紅外光譜帶重疊嚴重,一般很難清晰地指出各譜峰對應的具體基團信息,但根據近紅外主要譜帶歸屬仍可對所選波長合理性做出必要分析。由于甲基吸收譜帶位于4 200~4 440 cm-1,為C-H鍵伸縮振動與彎曲振動的合頻區;羰基吸收譜帶位于5 050~5 210 cm-1,為C=O鍵伸縮振動的二級倍頻區[14]。而且由于核酸中的嘌呤核苷酸,蛋白質中的蛋氨酸、甘氨酸、谷酰胺、天冬氨酸等都和咖啡堿的合成有關[4],因此可以推斷在蛋白質的特征吸收區4 545~4 655 cm-1、4 854~4 878 cm-1,以及蛋白質仲酰胺(CONH)中的C=O伸縮振動二級倍頻吸收(5 208 cm-1)等[28]波段附近應該存在茶葉咖啡堿的特征吸收。對照已選出的10個波長點可以看出,它們大部分都落在以上譜帶區域內或附近,表明挑選出的各峰位較好地反映了咖啡堿的吸收特征[29,30]。 圖4 最佳模型選取的最優特征波長點Fig.4 Optimal characteristic wavelength points selected by the best model (1)利用全波段建立茶葉咖啡堿近紅外分析模型,處理數據量大,建模時間長,同時可能引入更多的背景干擾。SPA方法則可以通過挑選特征波長,簡化模型,并消除多重共線性,有利于提高模型的簡潔性和精度,但該方法易受到重疊峰、高低頻噪聲和基線漂移的影響。 (2)采用WT-1stD相結合預處理光譜,可實現兩者優勢互補,即WT有去高、低頻噪聲及基線漂移的作用,1stD則進一步提高重疊峰的分辨率,方便后續SPA算法挑選更具代表性的最小共線性的波長變量子集。建模實驗表明,WT-1stD預處理方法顯著地提高了茶葉咖啡堿近紅外SPA+PLSR預測模型的精度。 (3)通過WT-1stD預處理后,SPA算法提取特征波長較好地分布于茶葉咖啡堿主要官能團吸收區域,提高了咖啡堿近紅外分析模型的可解釋性。2 結果與討論
2.1 不同預處理方法結果分析
2.2 不同預處理方法結合波長選擇結果分析
3 結論
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50數學物理學報(2020年2期)2020-06-02 11:29:24兒童故事畫報(2019年5期)2019-05-26 14:26:14意林原創版(2016年10期)2016-11-25 10:28:30光學精密工程(2016年6期)2016-11-07 09:07:19Coco薇(2016年2期)2016-03-22 02:42:52核科學與工程(2015年4期)2015-09-26 11:59:03Coco薇(2015年1期)2015-08-13 02:47:34小雪花·成長指南(2015年7期)2015-08-11 15:03:12
