基于代價模型的多平臺分析任務流調度優化
2021-11-12 02:17:02徐超一劉曉清
智能計算機與應用 2021年9期
徐超一,劉曉清,顧 淼,王 巍
(1 復旦大學 計算機科學技術學院,上海 200441;2 新浪,北京 100193)
0 引 言
數據量爆炸式增長的同時,數據分析的重要性也日益凸顯。多年來,數據分析的各類需求日益旺盛,人們對數據分析的要求也不再局限于更強的數據處理能力,多個計算(分析)平臺共同進行一個分析任務流的需求也隨之而生。
現實中,人們經常根據數據分析需求的不同,來確定分析任務所使用的執行平臺,甚至一個分析任務流中的分析算子,也可能運行在不同的計算平臺上。分析任務流在不同平臺之間的調度成為人們關注的一個重要問題。
RHEEM[1]是卡塔爾大學開源的跨平臺數據處理系統,其支持在一個任務流中自動調用多種平臺,來優化處理時間和處理性能。RHEEM借由內部的優化器,通過代價模型自動為任務流中的算子選擇平臺,獲取最優的執行計劃。Apache Beam[2]為開源的統一編程模型,用于進行跨平臺的大數據分析處理。Beam是基于Google 的Dataflow Model[3]論文的一種實現。通過對數據分析的多維度規范和總結,構成了一套編程范式,實現了不同平臺間的統一,但并沒有關注任務流的調度問題。Kumar等人基于Actors模型[4]研發了一個帶圖形界面的任務流系統Amber[5]。但Amber的研究側重于任務流執行過程中的實時調試,而不關注任務的調度順序。而目前針對單個任務流調度的研究已經趨于成熟,HEFT[6]、CPOP[7]、PETS[8]等算法,以較高的調度效率被廣泛接受。但其都需要知道每個算子的時間、資源開銷以及算子間的傳輸開銷,并且都沒有考慮多平臺的條件。
為此,本文研究了多平臺環境下,數據分析任務流的調度和優化問題。具體研究內容包括:根據多平臺的特性,提出了一種基于啟發式規則優化的拓撲調度算法,來完成任務流調度;針對SQL算子加入了代價模型,能對任務流的SQL分析開銷做出估計;訓練了GBDT樹,為用戶動態選擇機器學習任務的運行平臺并確定開銷;通過實驗,驗證了調度算法的優化性能和代價模型的準確率。
1 問題描述
通常來說,一個大任務可以拆分成一個子任務的集合(不同的子任務間存在一定的依賴關系)。此時,可以通過一個有向無環圖DAG(Directed Acyclic Graph)的形式來表示這些關系,形成了任務的DAG模型。因此,任務流的調度問題就轉化為DAG的調度問題。顯然,當考慮任務調度時,首要滿足的是子任務之間的依賴關系。
1.1 拓撲排序
拓撲排序,是指對一個有向無環圖G進行排序。對于圖中邊的集合E(G),若存在邊
Kahn算法[9]是進行拓撲排序的常見算法,由Kahn在1962年提出。其中心思路是:每次取出一個沒有先驅節點(即入度等于0)的節點,將其放入排序序列中,然后將這個節點的所有后繼節點的入度減一,重復這一過程直至排序完成。該算法的時間復雜度為O(E+V)。但需要注意的是:有效的拓撲序列并不是唯一的,每次使用Kahn算法得到的拓撲序列也不一定是一致的。
1.2 拓撲排序的局限性
如圖1所示,給出的一種存在兩個不同平臺算子的任務流。從A算子讀取輸入后,分別通過后續的其它算子計算,直至結束。對于這樣一個任務流,其拓撲序列顯然不唯一。可能的序列有(A,B,C,D,E,F,G,H,I,J,K,L),(A,B,D,F,C,E,G,I,J,K,L,H)等等。在非常多的可能序列中,再次考慮兩種比較極端的調度序列。第一種是序列L1(A,B,C,D,E,J,F,G,K,I,L,H),第二種是序列L2(A,B,D,F,C,E,G,H,I,J,K,L)。顯然,序列L1和序列L2都是滿足拓撲排序的序列,但序列L1的調度效果是一個平臺P1的算子和平臺P2的算子交錯運行。而序列L2的調度效果是優先將滿足依賴的同平臺算子全部調度完后,再考慮調度其他平臺的算子。
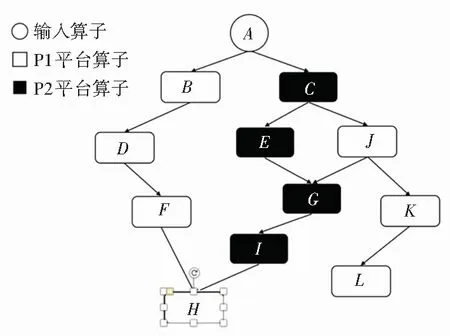
圖1 多平臺任務流示例
對于序列L1來說,頻繁的平臺切換會帶來額外的切換開銷。更關鍵的是在進行平臺切換的同時,需要將之前的計算結果保存,又會帶來額外的內存開銷。而過多的中間結果緩存會在一定程度上影響后續節點的計算速度。以Spark平臺為例,過多的中間結果被緩存,會導致可用內存不足。此時,在讀入當前節點數據時,需要進行GC和內存置換,從而會降低任務的處理速度。另一方面,如果一個平臺內的算子操作可以連續進行,那么計算的中間結果可以用平臺的內部結構表示,不僅使得整體的運算速度變快,也使整個流程的類型十分安全,可以應對復雜的計算流程,大大提高系統的魯棒性。而例如Spark這樣的平臺,其原生數據結構還使得運算結果的展示具有極高的靈活性。
可以想象,當任務流的復雜度提升,或是任務流中平臺數量增加,這兩種調度序列所帶來的開銷差別是巨大的。
1.3 問題定義
樸素的拓撲排序可以解決任務流的調度問題,但在任務流的整體開銷上,普通的拓撲排序是存在一定問題的。由于拓撲序列是不唯一的,對于一個給定的任務流J,使用不同的拓撲序列對其進行調度,最終整體的內存和時間開銷是不同的。
因此,該問題的描述是給定一個有向無環圖G(V,E),圖中節點E表示系統中不同平臺的算子,圖中有向邊V表示算子之間的依賴關系。在滿足依賴關系約束的情況下,本文希望找到一種節點序列,使得通過該順序執行任務流時,較少的其它中間結果被緩存,且進行的平臺切換最少,從而能優化整體的時間開銷。
2 算法描述
針對這一問題,如果預先將所有的拓撲序列求出,再一一進行比較,選出最優解,算法的復雜度會過高。所以本文選擇通過啟發式規則來求解。
2.1 基于啟發式規則的拓撲調度
本算法思路:先將輸入節點置入結果序列,然后將其指向的節點入度減1,每次選擇下一個節點(入度為0的節點)時,遵循三條規則:
(1)總是優先選擇與之前節點同平臺的節點;
(2)如果有多個同平臺的節點,優先選擇當前節點的后繼節點;
(3)如果不存在同一平臺的節點,則選擇任意滿足依賴約束的節點。算法偽代碼如算法1所示。
算法1基于啟發式規則優化的拓撲調度算法
輸入有向無環圖G=(V,E),S為入度為0的節點集合
輸出調度序列L
L={}
WhileSis not empty do
//啟發式規則優化
ifShas the same-platform-node with tail ofL
ifShas the successor of the tail ofL
remove the successornfromS
addntoL
else
remove the same-platform-noden’ fromS
addn’ toL
else
remove another nodekfromS
addktoL
for each node m with edge e fromntomdo
remove edgeefromG
ifmhas no other incoming edges then
insertmtoS
returnL
仍以圖1為例,序列L1(A,B,C,D,E,J,F,G,K,I,L,H)和序列L2(A,B,D,F,C,E,G,I,H,J,K,L)。其中序列L2為本算法得出的調度序列。輸入算子A與后繼算子的切換不計入考量,L1序列總共切換了8次平臺,L2序列總共切換了2次。同時可以看出,L1序列中,在計算大部分節點時,都有無關的中間結果被緩存。如在計算G節點時,節點F和節點G的結果緩存,則增加了內存和時間開銷。而在L2序列中,基本保證了任務能夠以一種近乎深度遍歷的方式執行,減少了與當前計算無關的中間結果的緩存。
如算法1所示,本算法對圖中的每個節點和每條邊都會進行一次遍歷。因此,本算法的復雜度為O(E+V),其中E為圖中的節點數,V為圖中的邊數。
2.2 代價模型
本文主要考慮的任務流算子為SQL類算子和機器學習算子,這些算子的主要運行平臺是Spark和Python。因此,本文針對這兩種情況分別加入相應的代價模型。
2.2.1 針對SparkSQL的代價模型
代價模型涵蓋了3個基本的SQL操作:Projection、Selection和Join。
首先,系統收集一些SparkSQL相關的物理參數。參考Baldacci[10]等人的工作,系統收集的物理參數見表1。
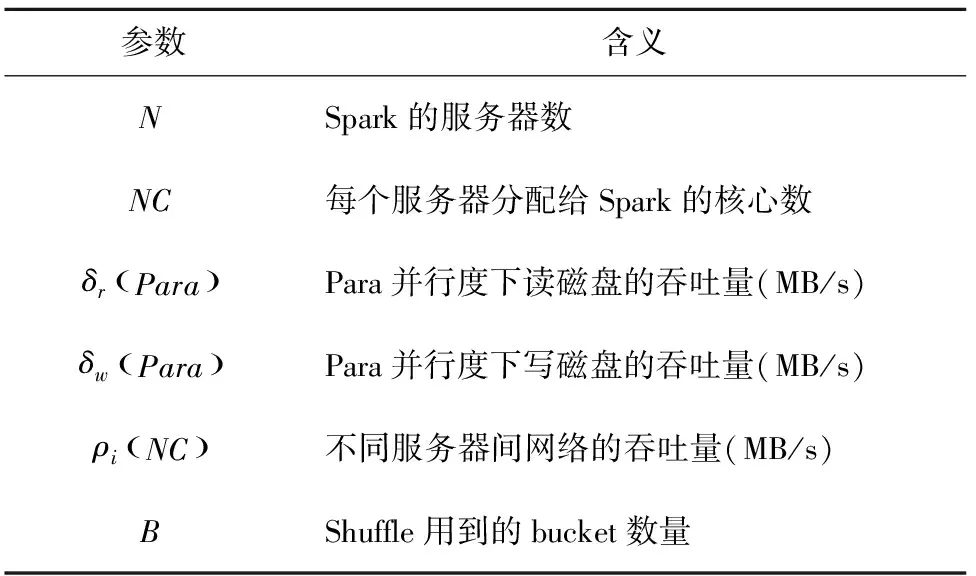
表1 物理參數收集表
根據表1可以初步得到公式(1)和公式(2):
(1)
(2)
其中,Read(RSize)為根據讀入大小得到的讀入時間,Write(WSize)為根據寫出大小得到的寫出時間。
計算執行開銷最簡單的方式就是將其運行一遍,但這樣就失去了代價模型的意義。事實上,代價模型不需要知道一個精確的代價,而只需要一個估計值。所以,代價模型可以對結果的數據量進行估計,再通過數據量的估算值來推斷執行的代價。
在查詢語句中,用戶常常會使用一些過濾條件(即本文中提到的Filter操作),在SystemR[11]中對過濾條件的估算只考慮到了數據連續且分布均勻的情況。但現實中的數據往往不是連續均勻分布的。所以考慮數據的分布情況,對數據量的估計是至關重要的。
其中,直方圖是一種能夠表示數據分布的統計方式。其通過分桶策略對數據做出劃分,從而得到大致的分布情況。本系統選擇了等深直方圖來了解數據分布情況。與普通的等寬直方圖不同,等深直方圖盡可能的保證桶的深度相同。Piatetsky-Shapiro[12]的研究指出,等深直方圖的魯棒性更強。
直方圖的構建需要有序數據。考慮到數據量增大后導致的排序開銷,所以本系統使用蓄水池采樣,采樣后再進行排序和直方圖的構建。
系統將過濾條件分為3類:單列的范圍查詢、單列的等值查詢、多列查詢。下面將分別介紹3種情況的估計方法。
(1)單列范圍查詢。對于單列的范圍查詢,可以通過等深直方圖來進行估計。對于給定的一個范圍查詢,只需要知道其覆蓋范圍內的所有桶的深度即可。如果遇到桶的范圍與查詢范圍有部分交集的情況,可以交集占桶大小的比例再做一次估算。此時,需要假設數據的分布是均勻且連續的。對于其它類型的數據,一般是將其映射成數字后再計算比例。
(2)等值查詢。對于等值查詢,需要知道記錄出現的頻率。對于一般情況下頻率的計算,人們傾向于使用HashMap來統計。而當數據量非常大時,一則要求的內存非常大,二則當HashMap的沖突很高時,時間復雜度的上升,導致無法滿足實時性的需要。
本系統使用了Count-Min Sketch[13]算法,其是一種可以處理等值查詢的方法,可以提供很強的準確性保證。該算法的基本思路是維護一個初始為0的D×W大小的數組。對于數據中出現的每一個值,分別用D個獨立的哈希函數進行映射和計數。查詢頻率時,依舊對其進行D次哈希,找到每一行中對應的計數值,再取其中的最小值作為估計值。
Count-Min Sketch可以看作布隆過濾器在統計方面的一個變形。其缺點是估計值總是大于等于真實值。
(3)多列查詢。本系統假設不同列之間是相互獨立的,只需要把不同列的過濾結果相乘即可。
綜上,可以得到一個函數Filter(cols,type)。
其中,cols表示過濾的列,type表示過濾的種類。可得對Project操作的估計,如公式(3)所示:
(3)
其中,projCols表示被選中的列;all表示表中所有列;attr.Size表示該列的平均大小。
接下來可以考慮就可以完成代價模型,本文考慮3種任務。
第一種任務類型是全表掃描任務,記為SCAN。SCAN任務可以包含Filter、Project和Aggregate操作。在SparkSQL中,Filter操作和Project操作被Spark的優化器Catalyst,通過謂詞下推和列值剪裁來優化執行,減小無用的元組和列對整體開銷的影響。此時,數據大小的估計如公式(4)所示。
WSize=RDDSize·Project(projCols,all)
·Filter(projCols,type)
(4)
若不存在聚合操作,則整個任務可以在一個管道中邊讀入,邊寫出,整體開銷如公式(5)所示。而存在聚合操作時,任務的寫出必須在所有數據被讀入后才能進行。此時,整體開銷如公式(6)所示。
Write(WSize))
(5)
Write(WSize))
(6)
(7)
其中,TableSize為表大小,RDDSize為Spark的RDD分區大小。若不存在寫出操作,Write(WSize)取0。
如果涉及Join操作,SparkSQL將根據不同情況,使用以下幾種不同的Join方式:
(1)Broadcast Hash Join應用于小表(默認閾值為10 MB)和大表之間的Join。使用Broadcast的方式來完成Join操作,犧牲空間換取時間。此時,通過將小表廣播到每個運行節點上,避免了Shuffle帶來的大量時間開銷。
(2)Shuffle Hash Join適合較小表和大表之間的Join。如果小表的大小大于10 MB,此時將小表廣播出去會造成較大的數據冗余和帶寬內存消耗,使得運行節點的壓力較大。所以,SparkSQL轉為使用Shuffle Hash join,通過Join的key將兩張表進行分區,即Shuffle操作。集群內的每個工作節點都會參與Shuffle操作,每個工作節點處理每個Bucket的一部分,然后對每個分區內的記錄進行Hash Join的操作。
(3)Sort Merge Join則適合兩張大表之間的Join。Hash Join的方法是將其中一張表完全讀入內存中,然后使用哈希的方法對另一張表進行探測和連接。而當兩張表都較大的情況下,使用哈希方法對內存的壓力過大。此時SparkSQL通過Join Key將兩張表進行Shuffle分區,以便后續的分布式處理,然后分別對每個分區進行排序和合并。
第二種任務類型是Broadcast Join任務。該任務的開銷可以用函數BJ()表示。在進行Broadcast Join時,大表仍然通過一個SCAN任務讀入,而小表要進行廣播,所以不需要寫操作。Broadcast過程的開銷,參考文獻[10]的研究,得到公式(8)。
(8)
由于整個Broadcast Join是在內存中,通過Hash的方式來完成,速度非常快,瓶頸主要體現在最后寫出的速度上。所以Broadcast Join的開銷函數如公式(9)所示:
(9)
其中,PartitionNum為Spark中設置的分區數。
第三種任務類型是Shuffle Join。因為Shuffle Hash Join和Sort Merge Join的開銷瓶頸都是Shuffle階段,所以其開銷都可以通過Shuffle Join任務來描述。該任務的開銷可以用函數SJ()來表示。在進行Shuffle Join時,顯然Shuffle的過程是瓶頸所在。另外,Shuffle Join只有在整個分區的數據都被讀入后才能進行,不能邊讀邊寫。但是在第一階段的Shuffle過程中,數據是一邊被分配到分區,一邊被讀取的。Shuffle階段的開銷如公式(10)所示:
(10)
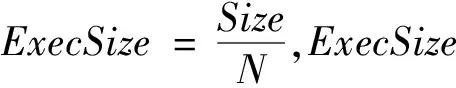
對于Shuffle Join階段的開銷如公式(11)所示:
(11)
綜上所述,不同任務的開銷可以通過上述3種函數的組合來計算。
2.2.2 針對機器學習任務的代價模型
由于本文考慮的機器學習任務的運行平臺包括Spark和Python(Scikit-Learn),因此會在確定運行平臺后完成對機器學習任務的開銷估計。
在確定了運行平臺之后,就可以根據硬件信息、平臺選擇、任務種類(分類、聚類、回歸)和訓練數據的維度、數量等信息估計出這個機器學習分析算子的大致時間開銷,可通過一個回歸任務來完成這一開銷估計。考慮到GBDT(Gradient Boosting Decision Tree)的本質是回歸樹,且具有很強的泛化能力,因此本文使用GBDT回歸樹來完成對機器學習算子時間開銷的估計。
3 實驗結果與分析
本文在 Spark 集群上進行實驗,其中包括 1 個 master 節點和 2 個 worker 節點。節點的硬件配置如下: Intel(R)Xeon(R)Silver 4208@2.10 GHz,24核;64 GB 內存;8 TB硬盤。軟件配置為:Linux Ubuntu 18.04、Spark-2.3.1、Python 3.6.8版本。
用于數據分析流程的訓練數據為Numpy隨機生成。而用于文本分析流程的數據,來源于新浪公司CMS內容管理系統真實發布的新聞文章(為2019.01.01~2019.04.22發布在新浪新聞娛樂頻道的所有新聞文章),去重后共有2 172 925篇。實驗時先根據關鍵詞篩選出1 000篇文章進行訓練。
第一組實驗:測試調度算法的優化對系統性能的影響。
實驗比較了樸素拓撲調度和基于啟發式規則優化的拓撲調度在任務流調度中的開銷差異。
本文首先通過Numpy生成了12 GB的訓練數據,并限制系統內存為10 GB,模擬復雜任務下的情況,并使用多種不同的算子組合構成任務流,進行實驗。其中一種任務流如圖2所示。實驗結果見表2。
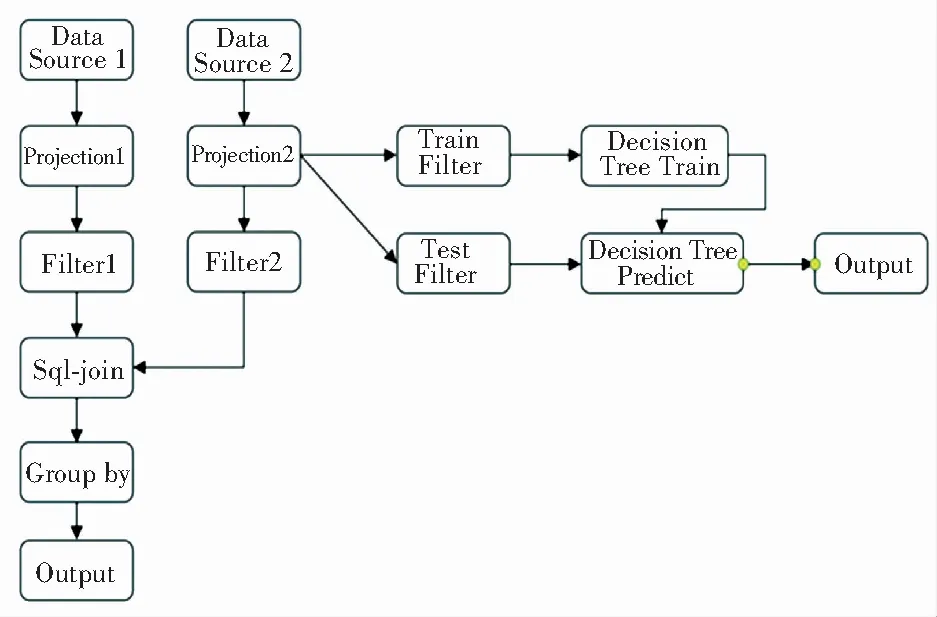
圖2 實驗任務流示例

表2 調度性能測試
第二組實驗:測試代價模型的準確率。
本文在TPC-H的標準下,生成了12 GB的表數據。分別測試了不含Join操作的簡單SQL和包含了Broadcast Join或Shuffle Join操作的稍復雜SQL的實際執行時間,并將之與代價模型給出的預估時間進行對比。實驗結果見表3。

表3 代價模型準確性測試
誤差率的定義如公式(12)所示:

(12)
由表3中可以看出,Join操作帶來的復雜性提升,使得不含Join的簡單SQL的估計更加準確,對帶Join的SQL的開銷估計則稍微有所下降。而在兩種Join類型之間,由于Shuffle Join涉及兩張表的分桶和更多的數據傳輸,其過程更加復雜,使得這種類型下的平均誤差率最高,達到了33%。但3種情況下,代價模型的誤差控制在35%以內,達到了預期。
4 結束語
針對多平臺條件的任務調度問題,本文提出了基于啟發式規則優化的拓撲調度算法,并且結合代價模型完成了對SparkSQL任務和機器學習任務的開銷估計。通過實驗證明了調度算法的有效性。在后續工作中,可以結合歷史運行數據,通過一個端到端的機器學習模型完善和改進系統的代價模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
兒童時代·幸福寶寶(2022年12期)2022-12-09 11:24:14
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
