高光譜成像的機采籽棉雜質分類檢測
2021-11-11 05:23:48常金強張若宇龐宇杰張夢蕓
光譜學與光譜分析 2021年11期
常金強,張若宇,龐宇杰,張夢蕓,扎 亞
石河子大學機械電氣工程學院/農業農村部西北農業裝備重點實驗室,新疆 石河子 832003
引 言
近年來棉花全程機械化生產比例增加,機采籽棉需要在后續加工過程中進行多道清理工藝,但是清理機械會對棉花纖維造成損失,降低加工所得皮棉的品質,影響最終產品價格和經濟效益。因此對棉花雜質進行檢測,并將雜質進行分類判別,為調整棉花清理機械加工參數和工序提供參考依據,對提升皮棉品質具有重要實際生產價值和意義。
由于皮棉中異纖含量對價格影響較大,國內的研究主要集中在異性纖維檢測[1-2]。張志峰等[3]提出了一種基于改進的自適應迭代閾值法皮棉疵點快速檢測方法;張林等[4]采用LED與線激光的雙光源一次成像方法,可以檢測出各種顏色的異性纖維;張成梁等[5-6]、王昊鵬等[7]提取機采籽棉可見光圖像中雜質的顏色、形狀和紋理特征,對各類植物雜質進行分類檢測;倪超等[8]采用深度學習方法對短波近紅外高光譜圖像中的地膜進行檢測。
國外的研究主要集中在植物性雜質的檢測,Wang等[9]采用基于自動視覺檢測系統的偽異性纖維檢測方法,提高了棉花中異性纖維的分類精度。Fortier等[10]建立棉花中植物雜質的近紅外光譜庫,進行雜質光譜分類識別。Li等[11-15]基于高光譜成像技術,采用反射、透射和熒光等成像方式,應用降維、特征波段選擇、分類判別算法等分析方法,對皮棉中多種植物和異纖雜質進行檢測。
上述研究對象主要是皮棉,由于皮棉經過雜質清理和軋花去籽處理,雜質含量小,棉層均勻易于圖像中雜質的檢測;而機采籽棉中不僅含有較多雜質,且棉籽導致棉層不均勻,使得圖像檢測難度增大,使用傳統的檢測方法無法有效檢測各類雜質。
基于高光譜成像檢測技術,根據棉花和各類雜質的光譜特征,針對機采籽棉中存在的植物和殘膜雜質建立分類判別模型;并充分利用光譜圖像的空間信息,實現對機采籽棉各類雜質的像素等級分類判別,為棉花加工設備提供快速信息反饋。
1 實驗部分
1.1 樣本的制備
共取樣籽棉10 kg,其中籽棉取自棉花加工企業,地膜取自采收后的棉花地。將籽棉和雜質手動混合均勻,每個樣本(30±0.5)g,使用電子天平稱重(量程1 000 g,分度值0.01 g),共120個籽棉樣本。樣本中檢測的雜質有棉葉,棉枝,鈴殼(內和外)和地膜共5種雜質,如圖1所示。

圖1 機采籽棉和主要雜質
1.2 高光譜成像系統和圖像采集
高光譜圖像采集系統如圖2所示,由成像光譜儀(Imspectral V10E-QE,Finland)、CCD相機(C8484-05G, Hamamatsu Photonics,Japan)、鏡頭、光源(150 W鹵素燈,China)、電動位移平臺(PSA200-11-X,Zolix)和電動位移平臺控制器(CS300-1A,Zolix)、暗箱、PC計算機等組成;在PC上用Spectral軟件進行圖像采集軟件控制。高光譜成像系統光譜范圍為360~1 000 nm,光譜分辨率為2.7 nm,采集的圖像有256個波段。
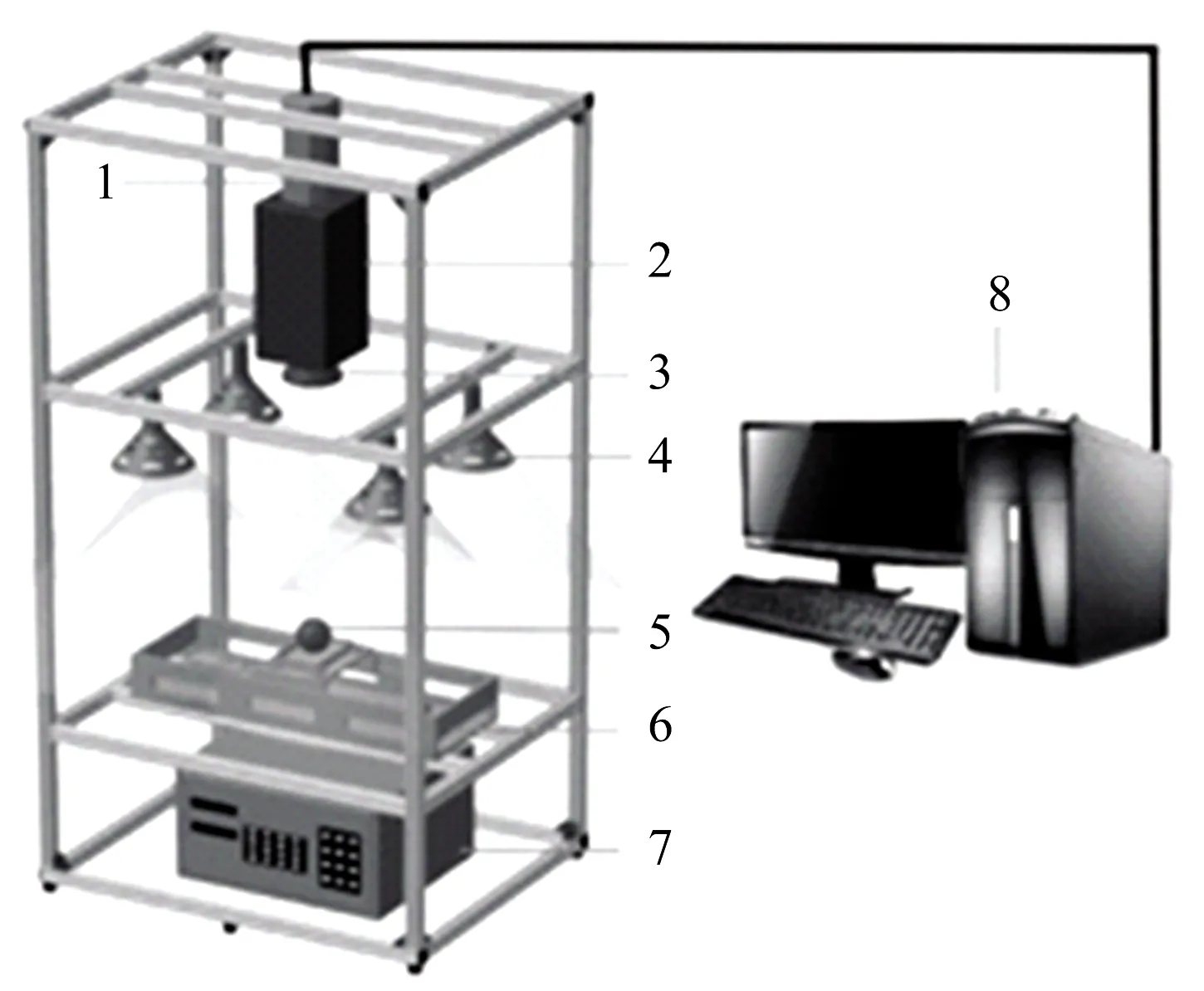
圖2 高光譜圖像采集系統
為保證視野足夠,調節鏡頭和樣本的間距為25.5 cm;為矯正速度不匹配帶來的空間畸變,使用一張打印有一個圓圈的A4紙調試平臺的速度,轉速設定為940 pulses·s-1;曝光時間為3.5 ms。
將樣本置于內部大小為15 cm×20 cm×3 cm的樣本盒中,分布均勻,將樣本盒固定于移動平臺上進行圖像采集。樣本盒覆蓋有黑色背景紙,有利于后期掩膜去除背景以及后續處理。
為減少光源光強分布不均勻導致的圖像信息噪聲影響,使用的高光譜成像系統在采集圖像之前需要進行黑白校正。掃描聚四氟乙烯白板獲得白校正圖像;鏡頭擰上鏡頭蓋并關閉光源采集黑校正圖像,該圖像包含有相機暗電流噪聲信息。圖像采集后用軟件SpecView(V2.9.2.7)按式(1)進行校正
(1)
其中:I為原始圖像,Ib為黑校正圖像,Iw為白校正圖像,Ia為獲取校正后的圖像。
1.3 機采籽棉數據分析和雜質多分類模型
使用PCA(principal component analysis,PCA)對平均光譜數據進行分析,將成百個相互高度相關波段數據降維至少數個新的主成分變量上,用來代替原來數據的大部分信息,并通過繪制分布散點圖體現原光譜數據的分類識別可行性。
采用LDA,SVM和ANN三種有監督的分類判別分析方法建立機采籽棉雜質多分類判別模型。模型訓練的過程為:首先將提取的平均光譜數據按照7∶3的比例,隨機劃分為訓練集和測試集;然后根據不同模型的參數特點和數據特性,使用訓練集采用5折交叉驗證,確定最佳的模型參數, 并使用測試集對模型結果進行評估。
2 結果與討論
2.1 高光譜圖像光譜曲線數據提取與分析
2.1.1 平均光譜曲線提取與變化規律
經過黑白校正后的圖像,在可見至近紅外波段上,共有256個波段。意味著在空間域上每個像素具有256個特征,這些特征組成該像素對應的光譜曲線。因高光譜圖像中存在噪聲,單一像素對應的光譜曲線可能在噪聲的影響下,表現出較大的變化。因為光譜成像儀的特性,高光譜圖像在首尾的波段圖像噪聲較大,有用信息較少,所以將這些波段剔除,即去除395 nm以前和970 nm以后的光譜圖像波段,將395~970 nm區間共226個光譜波段的數據作為后續分析數據。
從每幅圖像中提取10條平均光譜曲線,共1 200條光譜曲線,其中棉葉、殘膜、鈴殼外、鈴殼內、棉枝和棉花分別為457,173,88,193,63和226條。繪制機采籽棉中具有代表性的棉花和各類雜質的平均光譜曲線,如圖3所示:各類物質在430 nm處附近反射率均為最小,吸收最強;棉花的反射率較其他物質在大部分波段范圍高;殘膜整體上和棉花變化趨勢一致,但是數值比棉花低,驗證了從圖像上檢測殘膜的難度較大;鈴殼內的反射率在750 nm前低于棉花和殘膜,但是在750 nm后超過了棉花和殘膜;棉葉、棉枝和鈴殼外在趨勢和數值上都比較相似,但是棉葉在680 nm處出現了吸收峰,此現象對應了葉綠素的吸收波段。從630 nm開始到近紅外波段范圍內,鈴殼外的反射率比棉葉和棉枝都高。
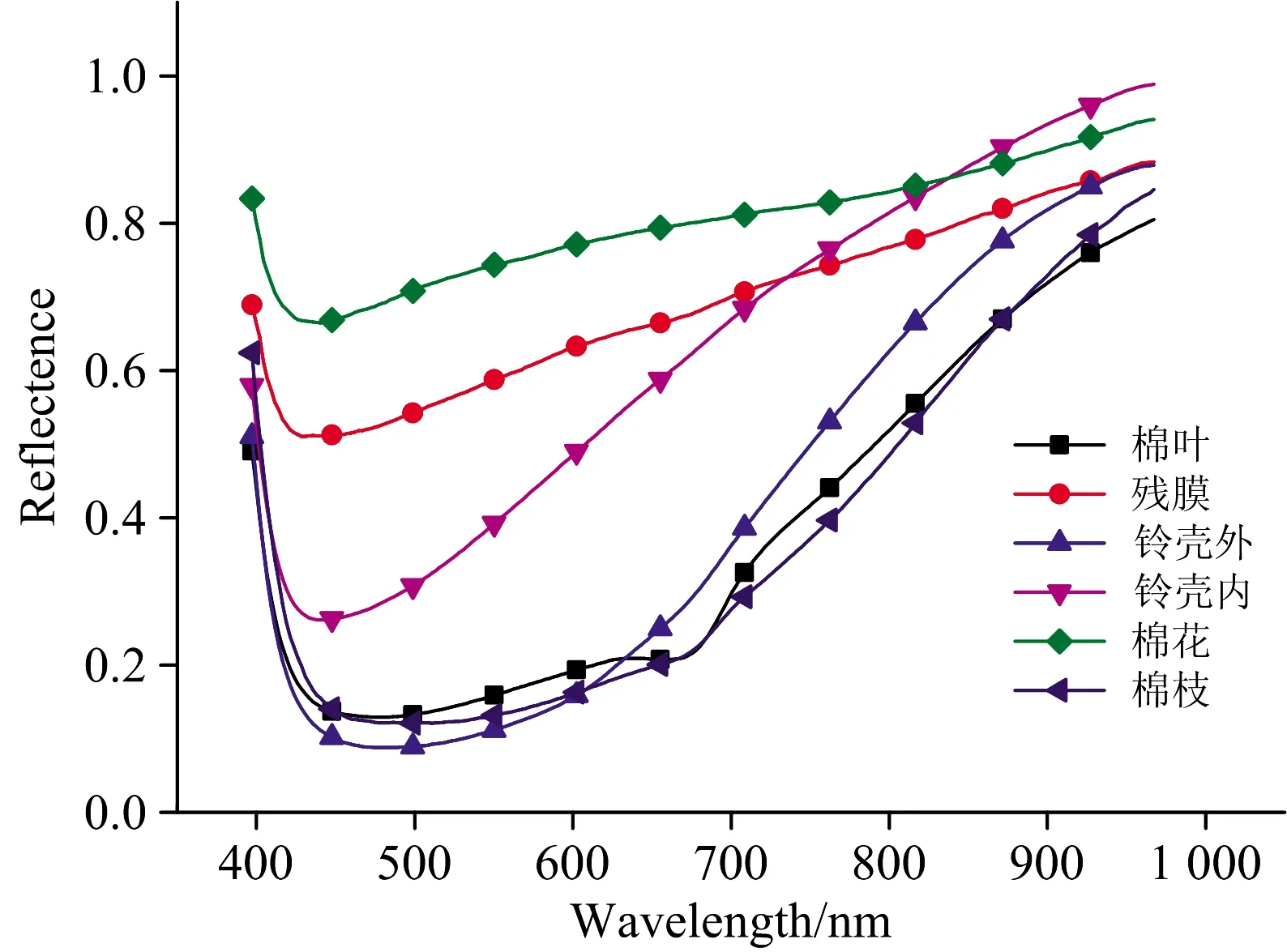
圖3 機采棉和各類雜質平均光譜曲線
綜上所述,雖然棉花和各類雜質的光譜曲線趨勢相同,但還是體現出不同的吸收和反射特性。不同種類物質(棉花、化學纖維和植物)之間的差異大于同類物質之間的光譜差異,同種物質之間的差異不能通過單個波段進行判別,所以需要進行數據分析和建模。
2.1.2 機采籽棉光譜曲線PCA分析
對提取的平均光譜曲線進行PCA變換,如圖4所示,前2個主成分的累計貢獻率達到了97.2%,前6個主成分的累計貢獻率達到了99.9%,能夠代表原始光譜數據的大部分信息。PCA前兩個主成分的散點圖如圖5所示,6類物質光譜變換后的新變量分布于整個空間中。由圖可知,棉花、殘膜和鈴殼外與其他三類相比,有較好的聚集性和可分性,但是由于棉葉、鈴殼內和棉枝三類的物質組成(纖維素和木質素)相似性較高,光譜特征相似,導致相互疊加在一起,空間分布存在嚴重交叉,無法有效區分類別。由于PCA為無監督降維方法,無法有效利用分類信息,因此需要使用有監督的數據建模方法,對光譜分類數據進行學習擬合,實現對雜質類別的準確識別。
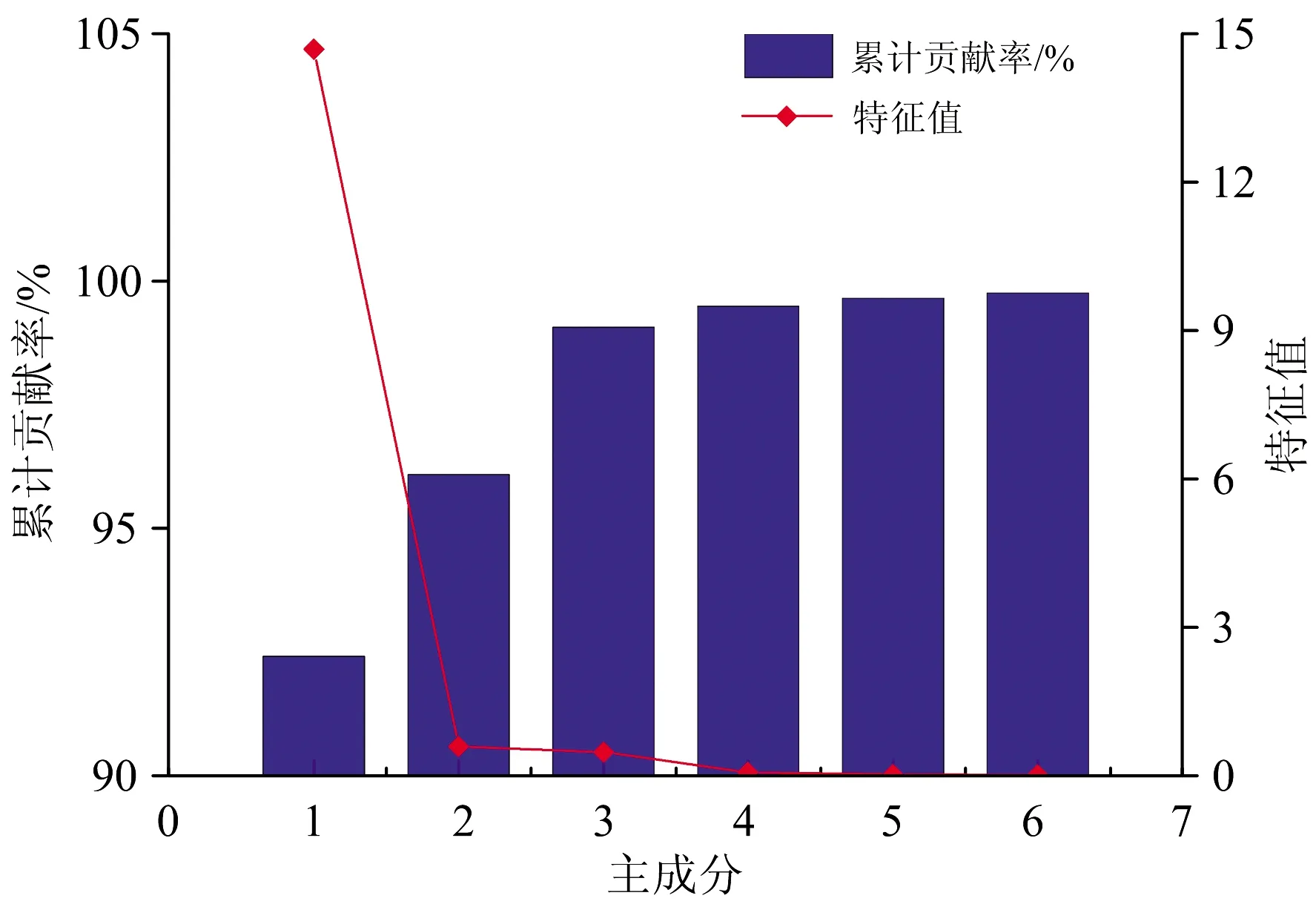
圖4 前6個主成分的特征值和累計貢獻率
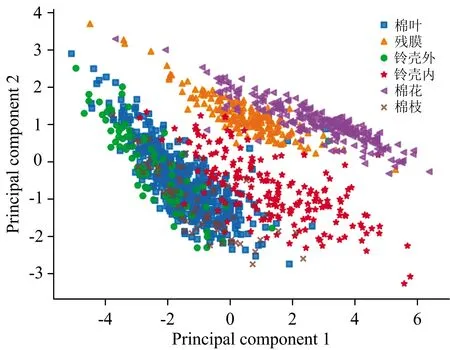
圖5 前2個主成分分類散點圖
2.2 機采籽棉雜質光譜多分類模型
2.2.1 線性判別分析(LDA)模型
線性判別分析(linear discriminant analysis, LDA)是將原始數據投影到更低的維度上,減少特征之間的線性相關性導致的特征冗余問題。通過LDA進行降維,可以達到提升分類準確率的目的。
與PCA中的分布相比,圖6(a)中棉花、殘膜和鈴殼外有更好的聚集性和可分性,表明有監督的LDA模型降維方法變換后的數據具有更好的可分性;但是棉葉、鈴殼內和棉枝這三類還是相互疊加在一起,空間分布存在嚴重交叉,無法有效區分類別。因此針對該三類重新進行了LDA降維,見圖6(b)中的棉葉、鈴殼內和棉枝表現出了較高的可分性,驗證了LDA模型在機采籽棉多分類上的可行性。
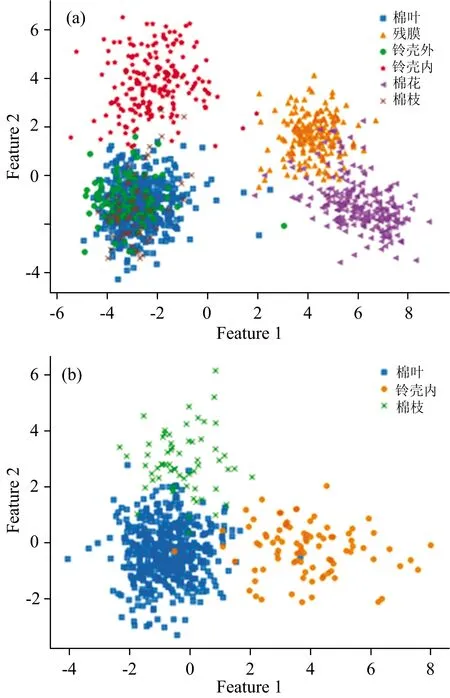
圖6 LDA前兩個特征的類別散點圖
因LDA易出現過擬合,因此在LDA模型構件中采用正則化防止過擬合,建立分類模型,得到訓練集準確率為86.4%,測試集準確率為86.2%,其差值較小,未出現過擬合現象。
2.2.2 支持向量機(SVM)模型
支持向量機(support vector machine, SVM)廣泛應用于建立分類判別模型。在SVM分類模型構建中采用RBF徑向基函數構建了分類模型,對gamma(g)和cost(C)兩個參數進行尋優,將Lg(g)和-Lg(c)參數區間設置為[0,10]。由圖7可知,在C=105、gamma=0.1時,交叉驗證集的準確率最高達到95.19%。根據最優參數模型得出訓練集準確率為83.42%,測試集準確率為83.40%,兩者差值較小,未出現過擬合現象。
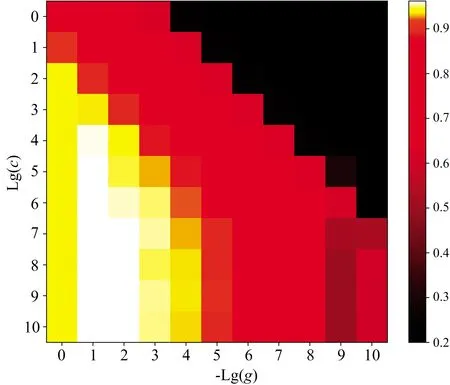
圖7 SVM模型尋優結果
2.2.3 人工神經網絡(ANN)模型
人工神經網絡(artificial neural network,ANN)是一種影響強、分類效果好的神經網絡分類算法,在解決非線性問題上具有較強能力。在ANN分類模型構建中,設置隱含層層數區間為[1,10],隱含層神經元個數區間為[1,18],激活函數選擇Relu函數進行參數尋優。由圖8可知,在隱含層層數為2,隱含層神經元個數為17,交叉驗證集的準確率達到最高為73.92%。以尋優所得到的參數,建立ANN分類模型并輸出,訓練集準確率為82.9%,測試集準確率為81.8%,沒有發生過擬合。

圖8 ANN參數尋優結果
2.3 模型效果比較
對上述的多分類模型準確率性能進行對比,如表1所示,結果顯示LDA模型的準確率高于SVM模型和ANN模型,訓練集和預測集的準確率達到了86.4%和86.2%。由于高光譜波段之間有較高的相關性,分類模型無法有效篩選信息,會引起誤差的產生。LDA在分類前對光譜特征進行了降維,減少了特征之間的相關性,保留了大部分類間信息,因此在多分類問題中,相較于SVM和ANN具有更好的效果。
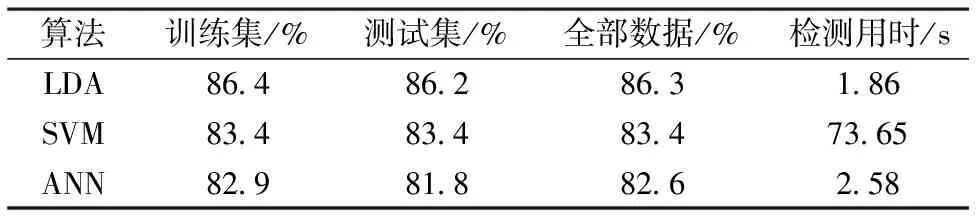
表1 光譜曲線分類模型準確率和時間
三個模型預測效果如圖9所示。在LDA模型中,地膜、鈴殼(內和外)和棉花的準確率較高,均高于90%;棉葉和棉枝的準確率較低,分別為59.84%和77.08%,其中有26.77%的棉葉被識別為棉枝,9.72%的棉枝被識別為棉葉,9.72%的棉枝和8.66%的棉葉被識別為鈴殼內;與LDA模型相比較,SVM模型和ANN模型的鈴殼內準確率有所降低,誤差類別分布一致但較高。分析認為這些識別錯誤的原因主要是棉葉、棉枝和鈴殼內的物質成分相似度高,導致在波段范圍內表現出光譜曲線相似的特點。
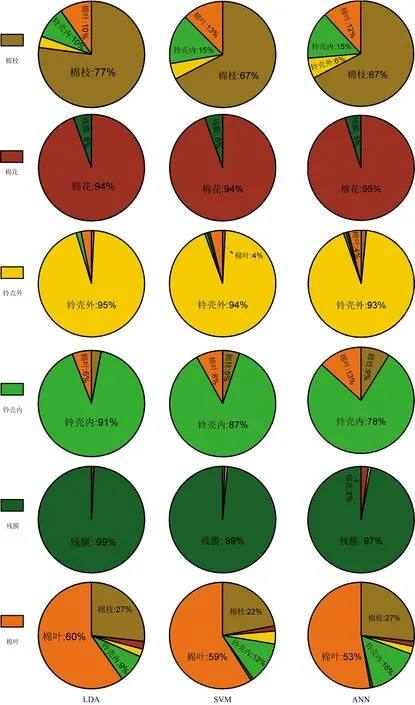
圖9 分類模型預測集效果
2.4 像素等級雜質分類判別
根據三種算法對120個高光譜圖像進行檢測分類,并將運行時間進行平均,得到每個模型檢測高光譜圖像所需運行時間。結果如表1所示,SVM,LDA和ANN的運行時間分別為73.65,1.86和2.58 s,綜合比較,LDA的分類準確率較高且運行時間少,確定LDA分類模型為最優模型。
使用訓練的LDA模型對高光譜圖像進行像素等級分類,分類效果如圖10所示。可看出棉花識別效果較好;部分棉葉和棉枝不能有效識別;地膜雖然被檢測出來,但因地膜的光譜曲線在大部分波段上和棉花相似,亮度較棉花低,所以部分棉花中表面不平導致的亮度較低的區域被識別為地膜。上述分類效果與雜質光譜的分類判別模型結果一致。

圖10 高光譜圖像像素等級分類識別結果
3 結 論
(1)通過參數優化,建立了三種機采籽棉雜質分類判別模型。其中LDA的分類準確率較高,訓練集和測試集的準確率分別為86.4%和86.2%。由于棉葉和棉枝的物質成分相似,光譜曲線相似,導致棉葉和棉枝雜質的分類準確率較低。
(2)對于像素等級雜質檢測,該方法能夠識別大部分雜質,檢測效果明顯。LDA算法需要的時間約為1.86 s,少于ANN的2.58 s,且遠少于SVM的73.65 s,能夠滿足實際生產對于檢測的需求,因此LDA為最佳模型。
(3)在后續研究中可以基于該方法,增加樣本數量,選擇覆蓋范圍更大的波段和加入紋理特征,提升棉葉和棉枝的檢測效果;并根據光譜圖像數據分析提取特征波段,開發多光譜成像檢測系統,實現更高效率的機采籽棉雜質實時檢測。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
