基于關聯規則的人事檔案信息資源分類方法
2021-11-01 06:21:56周毛青海民族大學青海省西寧市810007
江西通信科技 2021年3期
周毛 青海民族大學 青海省西寧市 810007
0 引言
企業的發展離不開人才的引進,針對此,主要有兩個途徑,一方面是以定向的方式進行有針對性的人才招聘,另一方面就是在缺乏明確目標的情況下,在海量的人才市場中篩選出符合招聘需求的人才[1]。與前者相比,篩選式的人才招聘將面對海量的信息資源,因此,對這些信息合理地分類是十分必要的[2]。由于在復雜的社會環境下,每個人的工作經歷都呈現出明顯的個性化特征,但又由于行業之間的內在聯系,導致不同崗位之間也存在一定的互通性,這就對檔案的分類工作提出了更高的要求[3]。
為了提高分類的可靠性,許多學者均針對信息資源分類問題進行了研究。其中,文獻利用DenseNet遷移學習對分類信息之間的相似性進行計算,并通過設置閾值,實現對信息資源的分類,該方法的分類結果對閾值設定的依賴性較強,因此穩定性較低;文獻[5]提出以深度卷積網絡為基礎的分類方法,通過對信息的特征進行聚類處理,實現分類,有效提高了分類的效率,但分類后數據之間的距離較大;文獻為了避免卷積神經網絡粒度問題對分類結果產生的負面影響,將分類信息中的表型信息作為特征提取的基礎,實現了高精度的信息分類,但適用范圍較小,對于部分不包含表型信息的資源,難以實現其分類效果;文獻在對分類信息進行數據增強處理的基礎上,利用貝葉斯卷積神經網絡實現資源分類,取得了良好的分類效果,但數據增強階段的工作較為復雜,對操作人員的技術水平要求較高,因此,難以實現普及性應用。由此可以看出,加強信息資源分類方法的研究具有十分重要的意義和價值。
基于此,本文提出了一種基于關聯規則的人事檔案信息資源分類方法研究。在準確提取信息特征的基礎上,利用關聯規則挖掘信息之間的內在關系,以此提高最終分類結果的可靠性。并通過實驗驗證了所提方法的有效性。通過本文研究,以期為信息資源的分類工作提供有價值的參考。
1 基于關聯規則的信息分類方法
1.1 信息特征提取
信息資源分類的基礎是對數據特征的準確提取,考慮到人事檔案信息的類型存在明顯的多樣化特征,因此,本文將信息增益作為特征提取的依據。
首先,作為一種較為常用的機器學習方法,信息增益的應用相對成熟。在提取人事檔案信息資源特征時,以信息中的特征作為增益計算的依據,統計目標特征詞在信息中出現的次數。假設在某人事檔案中,對于類別A的特征詞a出現的次數為xa,那么其對應的信息增益可以表示為:

式中,IG(a)表示關于關鍵詞a的信息增益。通過這樣的方式,以此計算出待分類數據中,關于不同分類類別以及對應關鍵詞的信息中信息增益。將信息增益的差值作為信息特征的判定結果,其表示為:
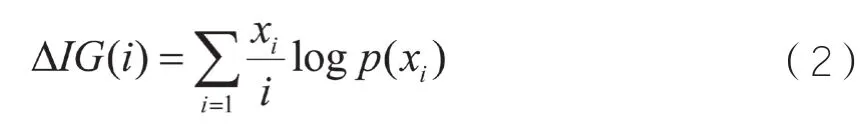
式中,ΔIG(i)表示信息增益的差值,i表示信息資源中的屬性特征,xi表示i類別特征詞的數量,表示頻率。為了確保分類結果滿足不同的分類要求,通過對ΔIG(i)的標準進行設定,調整特征提取的精度,使分類結果具有不同的支持度。
1.2 基于關聯規則的數據挖掘
根據上文的特征提取結果,建立了關聯規則,挖掘不同屬性特征下信息資源之間的深層關系,提高分類結果的可靠性。
首先,本文以信息資源特征提取結果為基礎,建立評估函數,以此實現對不同信息之間特征相似性的計算。為此,以ΔIG(i)值為標準,令ΔIG(i)=0作為中心,計算信息到中心的距離,該過程可以表示為:

根據這樣的方式,對信息資源之間的內在關系進行分析,為后續的分類提供基礎。
1.3 信息資源分類
在上述得到信息之間關聯的基礎上,實現對人事檔案信息資源的分類。為此,本文通過3個步驟實現該過程。
(1)確定項集
首先對待分類信息以二元的形式表示,用0表示二元變量表中的空,用1表示二元變量表中的非空,這樣做的目的是將信息與特征分離。由于特征詞的多樣性,一條信息資源中可能存在多個特征,因此,將信息與資源分離后,以具有相同類型特征的信息作為一個訓練項集,確保特征分類的全面性。
(2)分類訓練
考慮到關聯規則下特征之間的目標距離是決定最終分類結果的關鍵因素,因此,本文通過訓練的方式對不同距離下的分類結果進行分析,計算不同距離下的分類準確性,并將最高準確率對應的距離作為最終分類的目標距離。
(3)最終分類
最終,將訓練結果中的最佳距離作為信息分類的目標距離,對信息特征之間的關聯程度作出準確計算。同時,比較同一信息中對應的特征計算結果,根據計算結果,實現對信息的準確分類。
2 實驗分析
為了對所提方法的實際應用效果作出客觀評價,進行了實驗分析研究,將文獻方法和文獻方法作為對比方法,通過對比所提方法、文獻方法和文獻方法的分類結果,分析所提方法的分類效果。
2.1 實驗環境
本文進行測試的硬件設備內存為64GB,實驗數據的屬性設置為n個,共10組數據,其中,每組數據都包含所有屬性,且包含50條信息。同時,設置數據的最小支持度為20%,最小置信度為100%。以此為基礎,分別采用三種方法對數據進行分類。為了準確評價分類結果的可靠性,本文定義平均準確率為評價指標表示為:

2.2 實驗結果
在確定最終的分類結果前,所提方法對數據組進行訓練,訓練集的大小從100逐漸增加至500,考慮到待分組數據的總量500條信息,因此訓練集的大小設置為1500。以此為基礎,統計了當最小支持度分別為3%、5%、7%時的訓練結果,統計結果如表1所示。
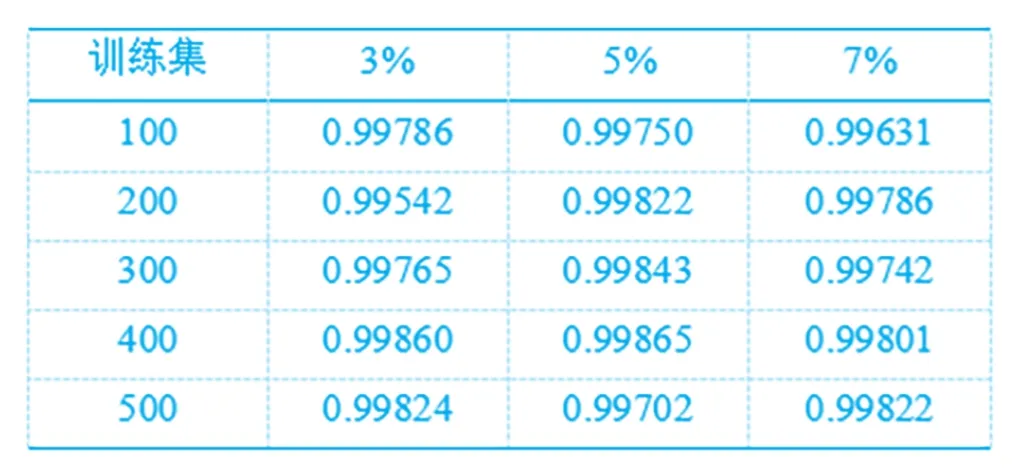
表1 不同最小支持度下所提方法訓練結果
從表1中可以看出,在不同的最小支持度下,所提方法的訓練結果始終具有較高的準確性,且當最小支持度為3%時,其訓練結果的可靠性依然保持在99.5%以上。以此為基礎,分別以3%、5%、7%的最小支持度對待分類數據進行分類處理,并與文獻和文獻的分類結果進行對比,結果如圖1所示。
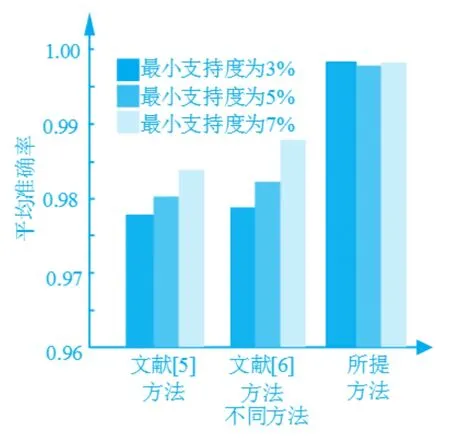
圖1 不同方法的分類結果
從圖1中可以看出,隨著最小支持度的增大,文獻[5]方法和文獻[6]方法分類結果的平均準確率均呈現出明顯的上升趨勢,差異程度較為明顯,且當最小支持度達到7%時,兩種方法的平均準確率也未達到0.99以上。相比之下,所提方法的分類結果較為穩定,平均準確率始終保持在0.995以上,且并未由于最小支持度的變化而出現較大波動。由此可知,所提方法的分類結果具有較高的可靠性。這主要是因為所提方法實現了對數據間內在關聯的深層挖掘,因此具有更加可靠的分類依據。
3 結束語
人事檔案信息資源的分類結果直接關系到后續信息查找的效率以及相應工作進程的推進速度,雖然與其他部門相比,檔案管理工作更加枯燥,但其意義是十分重大的。為此,如何實現海量信息資源的快速準確分類也成為了檔案管理部門的一項重要工作內容。本文提出基于關聯規則的人事檔案信息資源分類方法研究,有效提高分類結果的可靠性。通過本文的研究,以期為信息分類工作的開展提供幫助。
猜你喜歡
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
學苑創造·A版(2018年11期)2018-02-01 06:29:20
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
讀者(2017年5期)2017-02-15 18:04:18
