Word Sense Disambiguation Model with a Cache-Like Memory Module
2021-10-20 06:55:02LINQianLIUXinXINChunlei辛春蕾ZHANGHaiying張海英ZENGHualin曾華琳ZHANGTonghui張同輝SUJinsong蘇勁松
LIN Qian(林 倩), LIU Xin(劉 鑫), XIN Chunlei(辛春蕾), ZHANG Haiying(張海英), ZENG Hualin(曾華琳), ZHANG Tonghui(張同輝), SU Jinsong(蘇勁松)
School of Informatics, Xiamen University, Xiamen 361005, China
Abstract: Word sense disambiguation (WSD), identifying the specific sense of the target word given its context, is a fundamental task in natural language processing. Recently, researchers have shown promising results using long short term memory (LSTM), which is able to better capture sequential and syntactic features of text. However, this method neglects the dependencies among instances, such as their context semantic similarities. To solve this problem, we proposed a novel WSD model by introducing a cache-like memory module to capture the semantic dependencies among instances for WSD. Extensive evaluations on standard datasets demonstrate the superiority of the proposed model over various baselines.
Key words: word sense disambiguation (WSD); memory module; semantic dependencies
Introduction
Word sense disambiguation (WSD) aims to accurately identify the specific meaning of an ambiguous word according to particular context. As a fundamental task in natural language processing (NLP), it is beneficial to the studies of many other NLP tasks, such as neural machine translation (NMT), question answering (QA) and sentiment analysis. Therefore, how to construct a high-quality WSD model has attracted much attention in academia and industry.
To achieve this goal, previous studies usually resorted to artificial features containing linguistic and other information. Generally, these models can be grouped into four categories: unsupervised[1-3], supervised[4-5], semi-supervised[6-8]and knowledge-based[9-10]approaches. Recently, with the rapid development of deep learning, the studies of WSD have evolved from conventional feature engineering based models into neural network architectures. From this point of view, the common practice is to use word embeddings. For example, the word embeddings were leveraged as WSD features in different ways[11]. In addition, recurrent neural networks (RNN) effectively exploiting word order have been proven to be effective. Some researchers[12-13]mainly focused on long short term memory (LSTM) based WSD models, which can capture the sequential and syntactic patterns of the given sentence and thus achieve competitive performance in this task. Despite their success, previous studies conducted WSD in isolation, while neglecting the semantic dependencies among instances: the considered words with similar context should have the same sense, which has been adopted in many NLP tasks, such as entity linking[14-15]. As shown in Fig.1, for the target worddykes, the same word senses appear in similar contexts.

Instance 1 Assuming that magnetizations in the South Mountains granodiorite,Telegraph Pass granite and felsic dykes were acquired before and during ductile extensional deformation,we interpret these data as demonstrating that the South Mountains footwall has not been significantly tilted after mylonitic deformation.Sense_id: dykeXl:06:00::Instance 2 Similarly,assuming that magnetizations in the microdiorite dykes were acquired during initial stages of brittle deforma-tion,we interpret these data as demonstrating that the South Mountains footwall has not been significantly tilted after the brittle sta-ges of deformation.Sense_id: dykeXHiOO::
In this paper, we propose a novel WSD model with a cache-like memory module. It is a significant extension of the conventional LSTM-based WSD model[13]. The introduced cache-like memory module is used to memorize the sense disambiguation results of other instances for the same target word, and thus provide helpful information to the current WSD. We design this module based on the fact that the sense disambiguation result may be the same based on the similar context. Besides, since the memory can be traced back to training examples, it might help explain the decisions that the model is making and thus improve understandability of the model, so that the memorized value could help to improve the model accuracy, as verified in the studies of other NLP tasks[16-17]. It is worth mentioning that, the introduced cache-like memory is composed of key-value pairs. The keys denote the semantic representations of instances, and values are the corresponding sense disambiguation results. We compute the dot product similarities between the current hidden state and the stored keys in memory. Then, according to these dot product similarities, we summarize the memorized sense disambiguation results as the weighted sum of the values. This summarized vector can be incorporated into the conventional decoder to refine the sense disambiguation result of the current instance. According to this, our proposed model is able to fully exploit the semantic similarities among instances to refine the conventional WSD model. To investigate the effectiveness of our proposed WSD model, we carry out multiple groups of experiments on benchmark datasets. Experimental results and in-depth analysis show that our model outperforms previous WSD models.
The related work mainly includes WSD and memory neural network. WSD has been one of hot research topics in the community of NLP. More specifically, the previous studies on WSD can be roughly classified into the following aspects: unsupervised WSD, supervised WSD, semi-supervised WSD, and knowledge-based WSD. Unsupervised WSD is based on the assumption that similar word senses appear in similar contexts. Therefore, studies on unsupervised WSD mainly focuses on how to automatically learn the sense tags of target words from unlabeled data. The typical approaches take sense disambiguation task as a clustering problem which aims to group together examples with similar contexts[1-3, 18-19].
Different from unsupervised WSD, supervised WSD mainly uses manually sense-annotated to train a classifier for WSD. Zhong and Ng[4]used a linear kernel support vector machine as the classifier. Shenetal.[5]also trained a multiclass classifier to distinguish categories[5]. Experimental results on many datasets demonstrate that these approaches can achieve satisfying performance in this task.
Apparently, it is costly to obtain sense annotated corpora so that it is harder to extend the supervised WSD to the new domain. To deal with this problem, many researchers paid attention to semi-supervised WSD, which can simultaneously exploit both label and unlabeled datasets[6-8, 20-25].
Unlike the above-mentioned approaches, dominant methods in this aspect mainly resort to leveraging external knowledge resources to identify the senses of target words such as knowledge bases, semantic networks and dictionaries[9, 19, 26-33]. However, knowledge-based WSD cannot been widely used due to the fact that external knowledge resources are rare for many languages and domains.
Recently, with the rapid development of deep learning, neural network based WSD has attracted increasing attention and become dominant models in this tasks[9, 11, 34-36]. Compared with traditional methods, neural network-based models can automatically learn features that are beneficial to WSD. Particularly, some researchers use LSTM networks to capture the relationship between the context and word meaning by modeling the sequence of words surrounding the target word[12, 13, 37]. However, all above work conducts WSD in isolation.
Recently, due to the role of memory in storing previous results and capturing useful history, memory neural network has been widely used in many NLP tasks, such as language modeling[38-40], QA[41]and NMT[16, 17, 42]. To the best of our knowledge, our work to introduce a memory module into WSD is meaningful, which directly utilizes the memorized useful information from similar examples, and thus makes better use of semantic dependencies between instances.
The remainder of this paper is organized as follows. Session 1 describes our proposed model, including details on the model architecture and objective function. Experimental results are presented and analyzed in section 2, followed by conclusions in section 3.
1 Proposed Model
In this section, we will describe our proposed WSD model in detail. Our model is a significant extension of the conventional LSTM-based WSD model[13]. However, it is worth to note that our introduced cache-like memory is also applicable to other neural network based WSD model.
Figure 2 illustrates the model architecture, which is composed of a conventional LSTM-based WSD model and a cache-like memory module.
1.1 LSTM-based WSD model

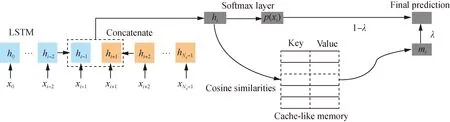
Fig. 2 Architecture of our WSD model
Given a target wordxiand its contextual hidden statehi, we introduce a softmax layer to predict the probability distribution over its candidate senses. Formally, we produce the probability distribution of candidate senses as:
(1)
(2)
1.2 Cache-like memory module
In order to better identify the sense of a target word, we explicitly model the semantic dependencies among instances to refine the neural based WSD model. To this end, we introduce a cache-like memory module which memorizes the sense disambiguation results of other instances as an array of key-value pairs. Our basic intuition is that the more similar the context of current instance with other instances in memory, the closer their word sense disambiguation results should be.
To exploit the cache-like memory information, we summarize the memorized sense disambiguation results as a memory vectormi. Formally,miis defined as the sum over the valuesvtweighted by the normalized similarities {st}:
(3)
Then we incorporate the memory vectormiinto the final output as
(4)
(5)
whereσis the sigmoid function, the dynamic weightλis used to control the effect of the cache-like memory module andW(3),W(4), andW(5)are learnable parameter matrixes. The basic idea behind our strategy is that the same target word of different instances requires different sizes of context to be disambiguated. For one considered instance, if our model is able to retrieve another instance with the similar context from the cache-like memory, it is more reasonable for our model to exploit the disambiguation result of this instance, and vice versa.
1.3 Training objective function
Given a training corpusD, we train the model according to the following cross-entropy with parametersθ:

(6)
whereS(xi) is the sense set of the target wordxi, andtj(xi) is thejth element of the sense distributiont(xi) forxi. We will describe training details in section 2.1.2.
2 Experiments
2.1 Setup
2.1.1Datasets
To evaluate our proposed model, we carry out WSD experiments on the lexical sample task of SensEval2[43]and SensEval3[44].
Table 1 provides the details of experimental data sets, including training set and testing set. Our baseline is a BiLSTM-based WSD model, proposed in Ref. [13].
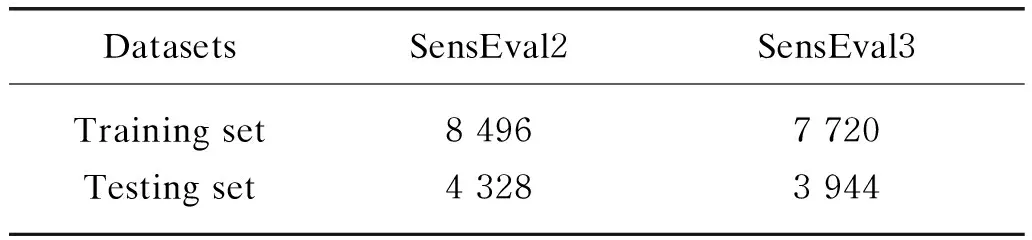
Table 1 Details of experimental data sets
We train the proposed WSD model in two steps: pre-training and fine-tuning. In the pre-training step, from Ref. [13], we train a WSD model based on BiLSTM, with hyper-parameter setting presented in Table 2. Please note that we also train the baseline model under the same hyper-parameters, insuring the fair comparison.
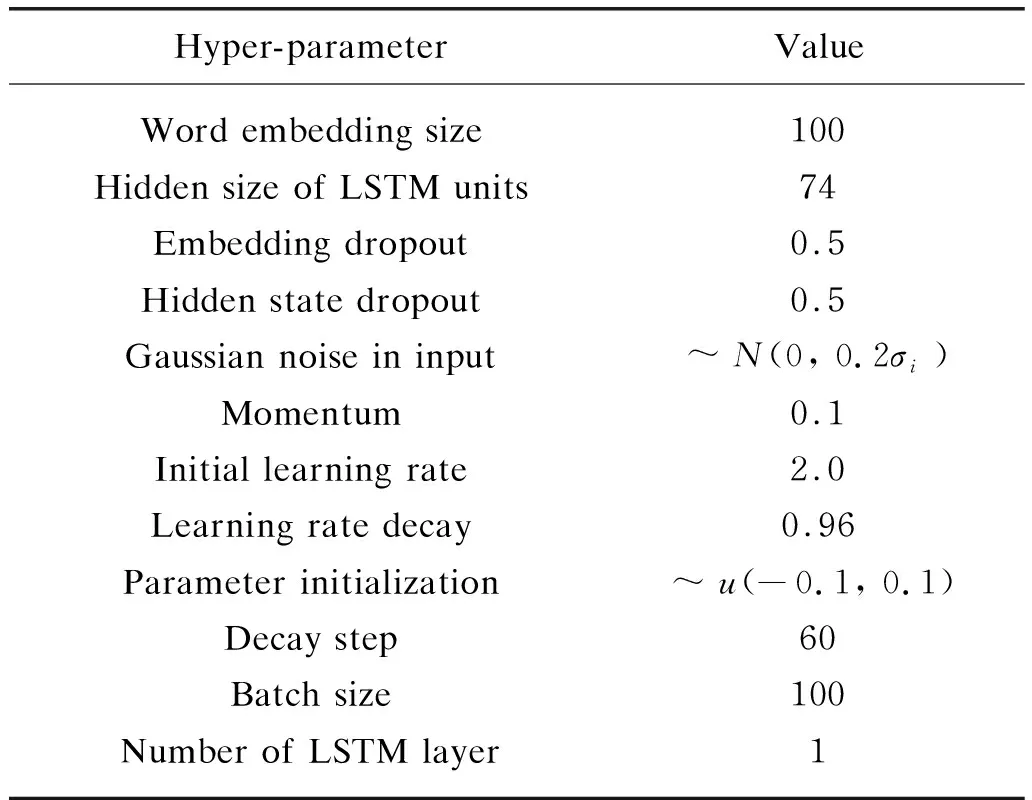
Table 2 Hyper-parameter settings at the pre-training
2.1.2TrainingDetails
Since our training datasets is not in large scale, it is better to employ dropout to prevent the model from over-fitting. Specifically, we set both dropout rates of embedding and hidden state as 0.5. Besides, we add Gaussian noise ~N(0, 0.2σi) to the word embeddings of input sentences, whereσiis theith dimension standard deviation in word embeddings matrix. In addition, we randomly discard some input words with rate 0.1 to further alleviate this issue and also we use theGloVevectors to initialize word embedding. For the out-of-vocabulary (OOV) words not appearing in the Glove vocabulary, we directly initialize these words according to the uniform distribution ~u(-0.1, 0.1).
We apply stochastic gradient descent(SGD) algorithm to optimize model training. In order to balance the performance and the training speed of the model, at the early stage, we first use a large learning rate to ensure that the model can quickly descend after finding the gradient descent direction, and then at the later stage, a smaller learning rate is adopted to make the parameters slowly change to approximate the optimal parameters. The decay factor of the learning rate is set as 0.96 every fixed 75 steps.
At the fine-tuning stage, we add a cache-like memory module into our WSD model. Note that before fine-tuning, we have stored the hidden states and sense disambiguation results of all training instances as key-value pairs into our cache-like memory, where these key-value pairs are fixed during fine-tuning. The hyper-parameters of the cache-like memory module is shown in Table 3. To avoid the slow training caused by a smaller learning rate, we limit the learning rate using a threshold. In addition, we clip the gradient to deal with the gradient vanishing problem.

Table 3 Hyper-parameter settings at the cache-like
2.1.3Baselines
We refer to our model as MEM-BiLSTM and compare it with the following baselines.
(1) 100JHU(R)[45]. It exploits a rich set of features for WSD.
(2) IMS+adapted CW[34]. It uses a feedforward neural network to incorporate word embeddings into WSD model.
(3) BiLSTM[13]. It is a commonly-used WSD model, which is based on bi-directional LSTM.
2.2 Experimental results
2.2.1Performance
The results of different models measured in terms of F1 score are given in Table 4. Compared with the previous models, our reimplemented baseline achieves better or similar performance on the two datasets, respectively. This result demonstrates that our reimplemented baseline is competitive. Furthermore, when equipped with the baseline with our cache-like memory module, our WSD model achieves the best scores on SensEval2 and SensEval3 with varying degrees of improvements. Specifically, on the two datasets, our WSD model outperforms the reimplemented BiLSTM baseline by 0.4 and 0.3, respectively, which strongly proves that adding the memory module can help the WSD model.
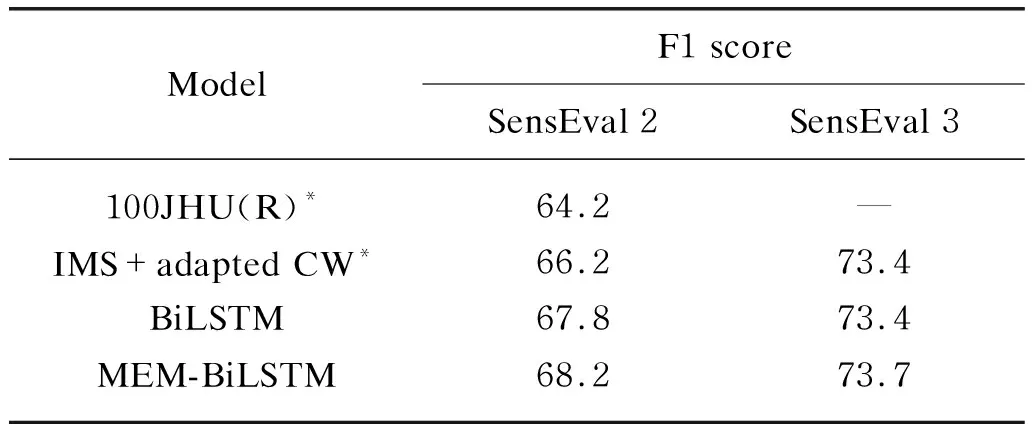
Table 4 Results for SensEval 2 and SensEval 3 on the
2.2.2Generality
To verify the generality of our proposed model, we also train different models using different sizes of training corpora: 10%, 25%, 50%, 75% and 100%, and then report the performances in Table 5. We can observe that with the increase of the amount of training data, the performance gap between the baseline and ours become larger. The underlying reason is when using the large training data, our model is able to exploit more similar instances to refine WSD.
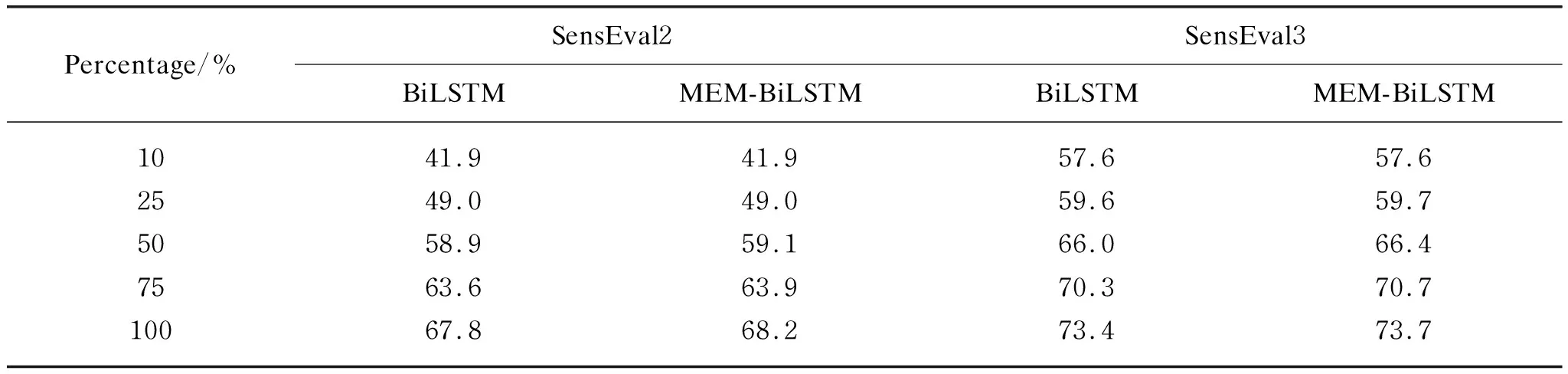
Table 5 Results for SensEval 2 and SensEval 3 on the English lexical sample task
2.3 Case study
To analyze why our model can outperform the baseline, we compare the WSD results of different models. Figures 3-5 show three examples, respectively. We can observe that in comparison to BiLSTM, our proposed model is able to make correct predictions with the help of the semantic related instances from the memory. Moreover, we simultaneously provide the three most similar instances for target words “argument”, “activate” and “hearth” in the last three rows of Figs. 3-5, respectively.

Instance: ... When it fell to Dukes to introduce the second stage of the Bill empowering the referendum,he was forced to address himself specifically to the bishop, arguments in their letter (text,Irish Times,15 May 1986).Reference: argument0Zol: 10:02::BiLSTM: argumentyol: 10:03::MEM-BiLSTM: argumentyol: 10:02::The most similar instance 1: ...This has some affinity with the Marxist position. In a published argument between Scholes and Hir-sch, the former made the following statement, on the assumption that the conservative Hirsch would disagree with it ...The most similar instance 2: ... he accepted Chinas offer of a seat on the Basic Law Drafting Committee, helping to write Hong Kong SAR Chinas post - 1997 mini - constitution, and was embroiled in more unsuccessful arguments for direct elections, op-posed by mainland communists and Hong Kong conservatives ...The most similar instance 3: ...Although the banks will begin to present their arguments today,Mr Scrivener said: this court is not concerned with private rights ...

Fig. 3 The first example

Fig. 4 The second example
3 Conclusions
In this paper, we proposed a novel WSD model with a cache-like memory module. As an improvement of the conventional LSTM-based WSD model, our model incorporates a cache-like memory module composed of key-value pairs, where the keys denote the semantic representation of instances, and values are the corresponding sense disambiguation results. We first compute the dot product similarities between the current hidden state and the stored keys in memory. Then, we summarize the memory values as a memory vector according to these dot product similarities, and then the induced memory vector is exploited to refine the WSD results of the current instance. Extensive experiments also validate the effectiveness of our proposed model.
In the future, we plan to design more effective architectures to better exploit semantic dependencies between instances for WSD. Besides, how to introduce graph neural networks into WSD is also one of our focuses in future researches.
 Journal of Donghua University(English Edition)2021年4期
Journal of Donghua University(English Edition)2021年4期
- Journal of Donghua University(English Edition)的其它文章
- Influence Mechanism of Clothing Anchor Features on Consumers’ Purchase Intention
- Performance Evaluation of a Molten Carbonate Fuel Cell-Graphene Thermionic Converter-Thermally Regenerative Electrochemical Cycles Hybrid System
- Long Text Classification Algorithm Using a Hybrid Model of Bidirectional Encoder Representation from Transformers-Hierarchical Attention Networks-Dilated Convolutions Network
- Estimating Mechanical Vibration Period Using Smartphones
- Meta-Path-Based Deep Representation Learning for Personalized Point of Interest Recommendation
- Design and Characterization of Electrical Connections for Conductive Yarns