Long Text Classification Algorithm Using a Hybrid Model of Bidirectional Encoder Representation from Transformers-Hierarchical Attention Networks-Dilated Convolutions Network
2021-10-22 08:24:36ZHAOYuanyuan趙媛媛GAOShining高世寧LIUYangGONGXiaohui宮曉蕙
ZHAO Yuanyuan(趙媛媛), GAO Shining(高世寧), LIU Yang(劉 洋) , GONG Xiaohui(宮曉蕙) *
1 College of Information Science and Technology, Donghua University, Shanghai 201620, China 2 Engineering Research Center of Digitized Textile & Apparel Technology, Ministry of Education, Donghua University, Shanghai 201620, China
Abstract: Text format information is full of most of the resources of Internet, which puts forward higher and higher requirements for the accuracy of text classification. Therefore, in this manuscript, firstly, we design a hybrid model of bidirectional encoder representation from transformers-hierarchical attention networks-dilated convolutions networks (BERT_HAN_DCN) which based on BERT pre-trained model with superior ability of extracting characteristic. The advantages of HAN model and DCN model are taken into account which can help gain abundant semantic information, fusing context semantic features and hierarchical characteristics. Secondly, the traditional softmax algorithm increases the learning difficulty of the same kind of samples, making it more difficult to distinguish similar features. Based on this, AM-softmax is introduced to replace the traditional softmax. Finally, the fused model is validated, which shows superior performance in the accuracy rate and F1-score of this hybrid model on two datasets and the experimental analysis shows the general single models such as HAN, DCN, based on BERT pre-trained model. Besides, the improved AM-softmax network model is superior to the general softmax network model.
Key words: long text classification; dilated convolution; BERT; fusing context semantic features; hierarchical characteristics; BERT_HAN_DCN; AM-softmax
Introduction
Text classification is aimed at simplifying messy text data and summarizing information from unstructured data[1]. It is a basic task in natural language processing (NLP) and can be applied to sentiment classification, web retrieval, and spam filtering systems[2]. Specific classification rules are a necessary process for automatic text categorization, which mainly include text feature extraction and word vector representation.
For text feature extraction, experts have proposed a variety of methods, which can be summarized into the following: expert systems, machine learning, and deep neural networks, which are also the three main stages of NLP development. The expert system uses experts with relevant field expertise and experience to summarize rules and extract features for classification, which makes it difficult to deal with the flexible and changeable characteristics of natural language, and long-term dependence on manual feature extraction requires huge manpower. Machine learning algorithms[3-4]is a shallow feature extractor and this kind of feature engineering is based on manual extraction and is not able to automatically extract features from training sets.
However, in most of the above-mentioned feature extraction methods, high dimension and data sparseness result in poor performance[5]. With the rise and popularity of deep learning, neural networks have acquired excellent achievement in the field of image processing[6-7], and related scholars began to utilize deep learning[8-13]for NLP, which has been known as the feature extraction unit and has gained extraordinary accomplishments. The most representative neural network is convolution neural networks (CNN)[8]which is strong in feature learning, and it improves the feature extraction ability by modifying hyperparameters or increasing the number of layers of convolution, but at the same time facing the problems of a large amount of calculation and parameters adjusting. Dilated convolution network (DCN) is a variant network of CNN network. DCN is able to extract more global features with less parameter-adjusting works[14], but it often loses key information and context structure semantic information in obtaining global information. Attention mechanism can calculate the key information in characters and sentences[9]. Traditional attention mechanism usually performs on characters, but it is inadequate for the acquisition of semantic information, and afterwards Yangetal.[15]proposed a hierarchical attention neural network (HAN). HAN is composed with a two-level attention mechanism on characters and sentences, which cound effectively identify features, structural information and key value semantics. However, at the same time it lost its global features extraction and may generate partial semantic loss.
In the aspect of vector representation, unsupervised training is essential in vector representation of text, and the pre-trained CNN[16-17]are widely used to fine-tune the downstream tasks[18-19]gaining significant enlarged ability in feature extraction, transfer learning and dynamically fetch context semantics. The traditional models, such as fast text[20]and Glove[21], intend to obtain the semantic information of each word, discarding the semantic relevance with preceding texts, and is prone to the problems of dimension explosion and data sparseness[22]. Bidirectional encoder representation from transformers (BERT) is one of pre-trained word vector models that constructed with then-layer transformer models with strong coding ability, and is able to calculate the semantic weight of each word with others in the sentences. Therefore, the pre-trained language model BERT is used as migration learning to fine-tune downstream tasks.
With the explosive growth of numbers of texts, a single classifier is not able to accomplish the tasks with high accuracy and precision, and many studies with mixed models have been proven more effective compared to single models in dealing with text classification problems[23-26]. A feature-fused HAN-DCN model was presented in this manuscript, the BERT model trained word vectors to initially understand the text semantics, HAN network obtained the structural dependency between word vectors, and the DCN extracted global and edge semantics in parallel. The features obtained from the two channels are spliced to be more efficient in improving the weight of the key information in the two levels of words and sentences, and extracting global semantic features as much as possible to improve the accuracy. Since softmax is aiming to maximize the probability of categorization by optimize the variances between different classes, and it is unable to minimize the differences within the same category, AM-softmax[27]is used to deepen the feature learning in improving the accuracy and efficiency of news text classification. The feasibility of the BERT_HAN_DCN model based on AM-softmax is verified through a series of experiments and it shows certain advances in improving generalization ability and model convergence speed.
1 Model Architecture
The entire architecture of this manuscript is indicated in Fig. 1. Firstly, the data is processed by BERT to initially get a rudimentary idea of the text so that we can obtain the dynamic semantic representation. After receiving the vector of the individual word in the long sentence, the digital vector is sent to the parallel network, which is composed by a three-layer DCN, which can acquire a larger receptive filed with fewer amount of calculation and HAN hybrid model to extract more abundant semantic information and contextual features information. In the relevant image processing, the mesh effect appears in the dilated convolution, resulting in the loss of characteristic information[28-29]. Therefore, in this network design, a three-layer dilated convolution is adopted to overcome the influence of the mesh effect, and the coefficients of expansion of each layer are set to 1, 3, and 5, respectively. Thus, the feature representation of the text is formed by combing the feature information of these two parts. In the end, the softmax function is used to normalize and classify the output probability according to the probability size. The mixed model architecture is shown in Fig. 1.
1.1 Input of representation layer
BERT could obtain dynamic and nearly comprehensive semantic information of the text. The BERT model uses a transformer with a bidirectional structure to fuse left and right characters to obtain contextual semantics, complete the two tasks of masking language model (MLM) and next sentence prediction (NSP) at the same time, and conduct joint training to obtain the vector representation of words and sentences. BERT’s embedding layer consists of token embedding (vector representation of words), segment embedding (vector representation of two sentences in a sentence pair, similarity of the sentence pair) and position embedding (learning the order properties of the sentence) to convert Chinese characters into input vectorsW1,W2, …,Wn, and the model can dynamically generate the context semantic representation of words by bidirectional transformer structure[30]to perform the two tasks mentioned above (MLM and NSP) as shown in Fig. 2. The final transformer output of the hidden layer vector with semantic information is avilable from the self-attention layer, the remaining connection and the normalization layer, and the obtained output is the superposition of the character-level vector. The output layer vectors processed by BERT areE1,E2, …,En, which are obtained by multi-layer transformers. In this experiment, BERT_BASE_CHINESE model is used, which is composed by a 12 layers-multi-head attention mechanism transformer.
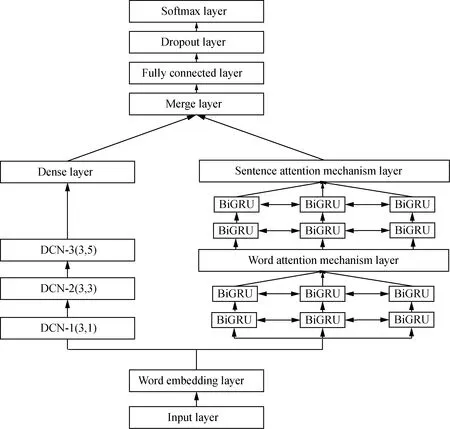
Fig. 1 Overall framework of BERT_HAN_DCN
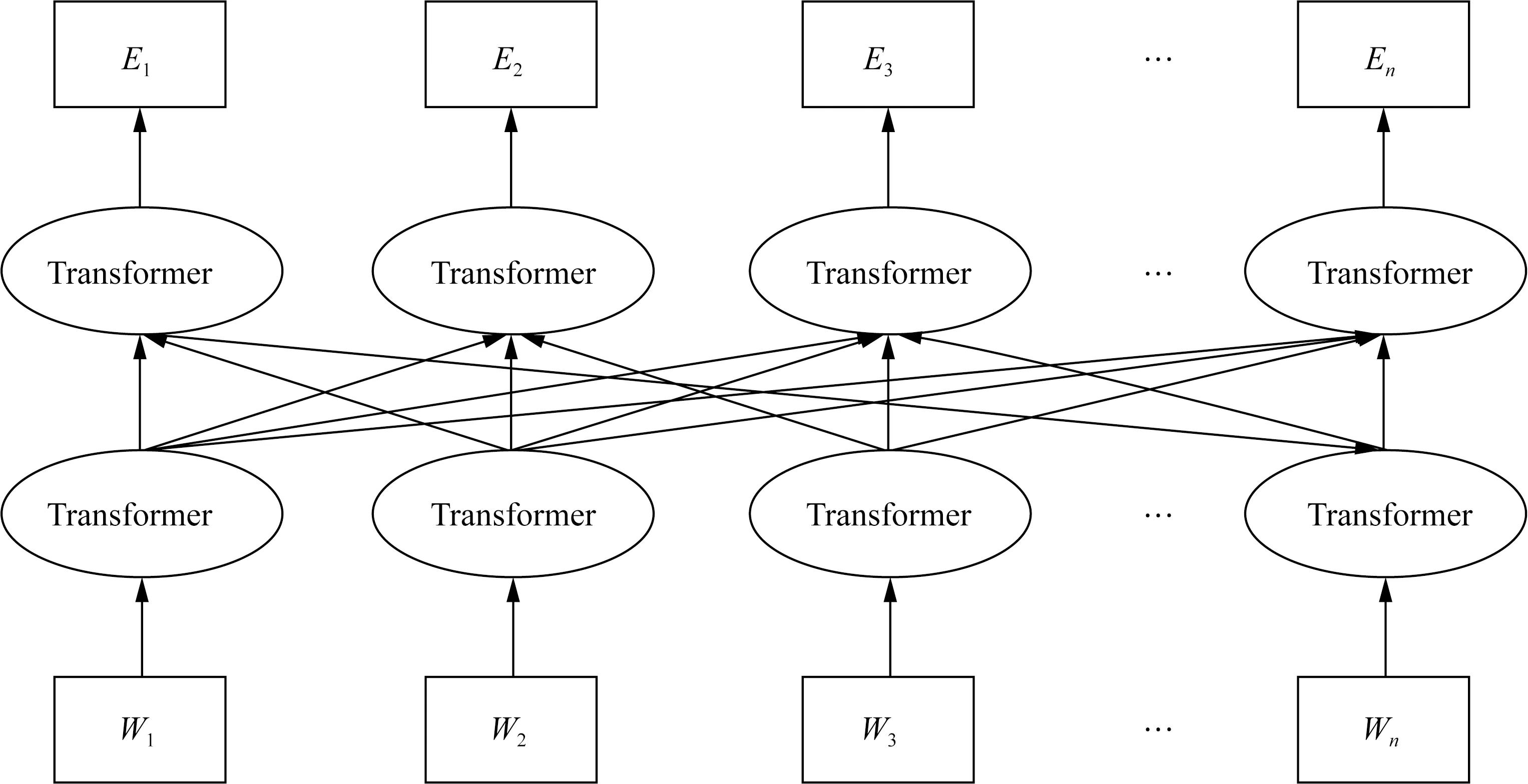
Fig. 2 BERT model structure
1.2 HAN layer
As illustrated in Fig. 3, the HAN model is composed by Chinese character and sentence level attention network, and this hierarchical structure is in line with people’s habitual thinking of understanding articles. In essence, each layer in attention network is composed by two layers of BiGRU, which has the advantage of serialization learning text features in the dotted box in Fig. 3. Considering the hierarchical structure of the network, it is necessary to set the fixed length of each sentence when dividing sentence attention. Thus, in this manuscript, we maximize the characters of the longest sentence in the article as 256, and each sentence is divided into segments with 16 characters. HAN is composed of four parts: word encode, word attention, sentence encode and sentence attention, which will be explained the calculation process in detail.
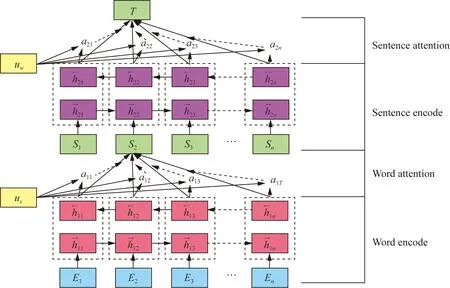
Fig. 3 HAN model structure
(1) Word encode
In this part, the embedding layer vector is word-encoded. The vectors are initialized and then used as the input of the two-layer BiGRU. The specific conversion method is shown as
xin=EeEn,n∈[1,t],
(1)
(2)
(3)
(2) Word attention
The splicing vectorsh11,h12,...,h1nof the forward hidden state and the reverse hidden state are used as the overall expression of the word. In this part, calculate the size of the attention weight matrix of each word in the sentence. The calculation method is
u1n=tanh(wsh1n+b),n∈[1,t],
(4)
(5)
(6)
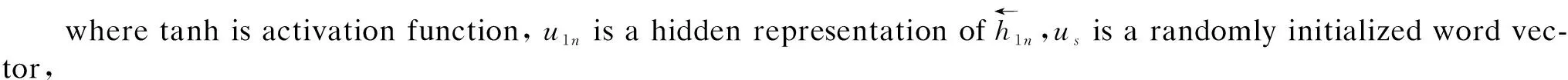
(3) Sentence attention
(7)
(8)
The purpose of adding a mechanism in this step is to discover the significant meaningful words in the sentence. We can get the final output of the HAN network as illustrated in Eq. (9), in which the vectorω1is the significant local characteristic of the mixed neural network, which is defined as
ω1=∑nα2nh2n,n∈[1,t],
(9)
whereω1is the document vector as well as the final features extracted by HAN, which sums up all the information of the sentence in long text.
1.3 Dilated convolutional networks layer
As shown in Fig. 2, the DCN layer is composed of three hollow convolutional blocks with the same structure, and the input of each dilated convolutional layer is the output of the earlier layer. Changing the dilated convolution rate of each layer allows the receptive field of the convolutional layer to quickly cover all input data. As the input expansion rate of each layer increases, the obtained feature information increases exponentially.
DCN and HAN are parallel network structures, taking the output of the embedding layer, which initialized by BERT as the input, and the input of each word in the sentence areEi∈RB×N×D, whereBis batch_size which is set to 64,Nis the number of words, andDis the word vector dimension of BERT output. The feature extraction of the input text sentence by dilated convolution is completed by setting the filter size. The convolution calculation is shown as
ci=f(ω·Ei:i+k+(k-1)(r-1)+b),
(10)
wherefis a non-linear function,ωis the random initialization weight matrix the convolution kernel,kis the size of the convolution kernel, andris the hole rate of the hole convolution;Ei:i+k+(k-1)(r-1)isi:i+k+(k-1)(r-1) the sentence vector composed ofitoi+k+(k-1)(r-1), andbis the bias term.
Therefore, after the feature extraction of the dilated convolutional layer, the final vectors obtained areC.The concrete vector representation ofCis shown as
C=[c1,c2,…,ci+k+(k-1)(r-1)].
(11)
The output of HAN is going to be serialized continuous vectors, which needs to keep the dimensions consistently. Connect the vector obtained from the three layers dilate convolution networks and convert the vector into a feature matrixw2, which is as shown in
w2=[C1,C2,...,Ci],i∈[1,n],
(12)
whereCiis the feature matrix of the output of dilated convolutional neural networks.
1.4 Classification layer
The classification layer is composed of the following four parts: feature fusion layer, fully connected layer, dropout layer and softmax layer. It consists of a simple softmax classifier (at the top of HAN and DCN) to calculate conditional probability distributions on predefined classification tags. Using Keras’s add function at the model fusion layer, we can get the merge layer vectorω, shown as
ω=w1⊕w2,
(13)
wherew1andw2represent the features output vectors of HAN and DCN respectively, and ⊕ represents a splicing operation. After realizing merge layer operation, the obtained feature vectors are combined. Then extracting the feature vector again, each input unit of the fully connection layer represents the value of each feature vector. In order to avoid overfitting of the model, we use the dropout mechanism. The final feature representations are obtained from the dropout layer, and these feature representations are classified by softmax classification algorithm. The classification algorithm calculates the probability ofωinto categoryz, and the concrete calculation formula is shown as
(14)

2 Experiments and Results
In this section, for verifying the effectiveness of BERT_HAN_DCN model, we use two real-world experimental datasets. We which are extracted the portion from SogouCS and THCNews datasets, explicate the details of the experiment, evaluate the performance of the hybrid model, and analyze the experimental results.
2.1 Experimental datasets
The datasets used in this experiment are Chinese text classification datasets launched by the NLP Laboratory of Tsinghua University and Sogou labs. The detailed data amount of the train group, the validation group and the test group are shown in Table 1.
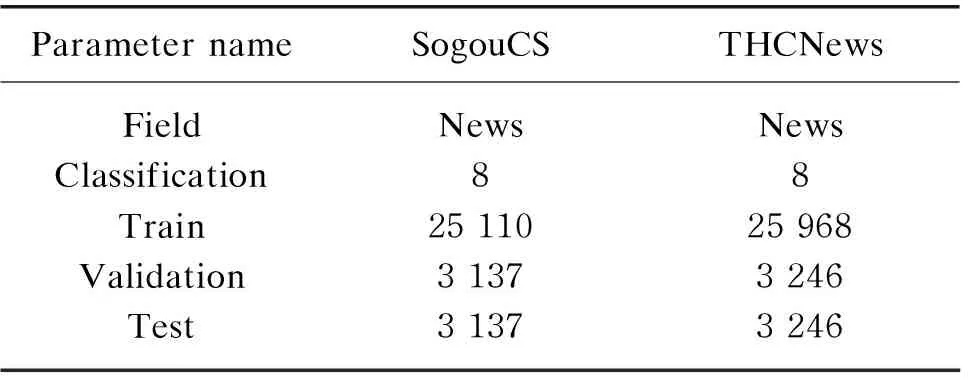
Table 1 Details of the text classification datasets
2.2 Multi-classification evaluation index
On the course of training process of the text classifier, it is indispensable to select appropriate criteria to evaluate the ability of the classifier. The confusion matrix is shown in Table 2 and there are four commonly used criteria in the field of NLP: precision (P), accuracy (A), recall (R), andF1-score (F1).

Table 2 Confusion matrix
(1) Accuracy(A)
He cried so much that the glass splinter swam out of his eye; then he knew her, and cried out, Gerda! dear little Gerda! Where have you been so long? and where have I been? And he looked round him
(15)
whereAis measuring the ability of the classifier to distinguish the whole data set, the higher the value of A represents the better classification ability the model has.
(2)F1-score (F1)
(16)
wherePis shown in
(17)
andRis shown in
(18)
F1 is a comprehensive index which is the harmonic evaluation value of precision and recall. It can be seenF1 combines the results ofPandR, and whenF1 gets closer to 1, it can indicate that the model method is more effective.
2.3 Main initialization hyperparameters
In order to train a better classification model, we should set the appropriate hyperparameters settings of the model. The hidden vector dimension of BiGRU and DCN models are respectively set to 64 and 128, the size of batch is 64, the dropout rate of BiGRU is set to 0.1, the maximum input length of data set is set to 256, and the learning rate is 0.000 05. The other main initialization hyperparameters settings of this experiment are shown in Table 3.

Table 3 Main initialization hyperparameters
Using optimizer Adam[31]to update network weights and cross-entropy cost function is used for calculating loss. In addition, early stopping is used to prevent over fitting. After multiple training processes in the models, it is found that 3 is the most suitable parameter for all experimental models. Complicated neural networks trained on small data sets often result in overfitting[32-33]. Because of the fewer data sets in this experiment, a certain dropout rate is adopted to prevent the overfitting of the model. Consequently, five groups of experiments were designed to explore the influence of dropout rate on the model effect and the optimal parameters were suitable for this fusion model. When we change the dropout rate, every 0.1 change has an impact on the accuracy of the model. Finally, we found the most appropriate parameter dropout for SogouCS dataset is set to 0.6, while THCNews dataset is set to 0.8.
2.4 Analysis of experimental results
This manuscript focuses on two kinds of news data sets. A total of three groups of comparative experiments are designed, which are using the standard BERT to connect the fully connection layer directly, and using the BERT as the embedded representation layer, HAN and DCN as the feature extraction layer respectively. The accuracy and loss rate of the two data sets during the training process are plotted separately, as shown in Fig. 4. The models are trained for 10 epochs on two datasets. Over the course of training data, it can be seen from Fig. 4 that the BERT_HAN model plays a significant role in improving accuracy. However, the model tends to be unstable in the first few iterations. The reason for this phenomenon is the complex structure of HAN model network. In the early stage of learning, the error is relatively large, and some important features may be lost when focusing on local important features. With the constant updating of parameters and BERT_HAN’s strong learning ability, the accuracy and stability of prediction are constantly improved. The BERT_DCN model is more stable than BERT model in both data sets. In addition, the accuracy of data set SogouCS and THCNews improved by 2.89% and 2.03% respectively compared with the BERT model.
From the experiment results, in SogouCS and THCNews, BERT_HAN_ACN model achieved accuracy value of 91.42% and 95.66% respectively and the loss rate of 39.95% and 17.83% respectively. The accuracy of the BERT_HAN_DCN model in the verification set is higher than that of other models, and it is more stable in the training process than the other models. Compared with other groups of models are showed the best effect which has improved considerably and shows that the designed model fusion is feasible, which can extract deep characteristics of long text and improve the effect of news text classification model.
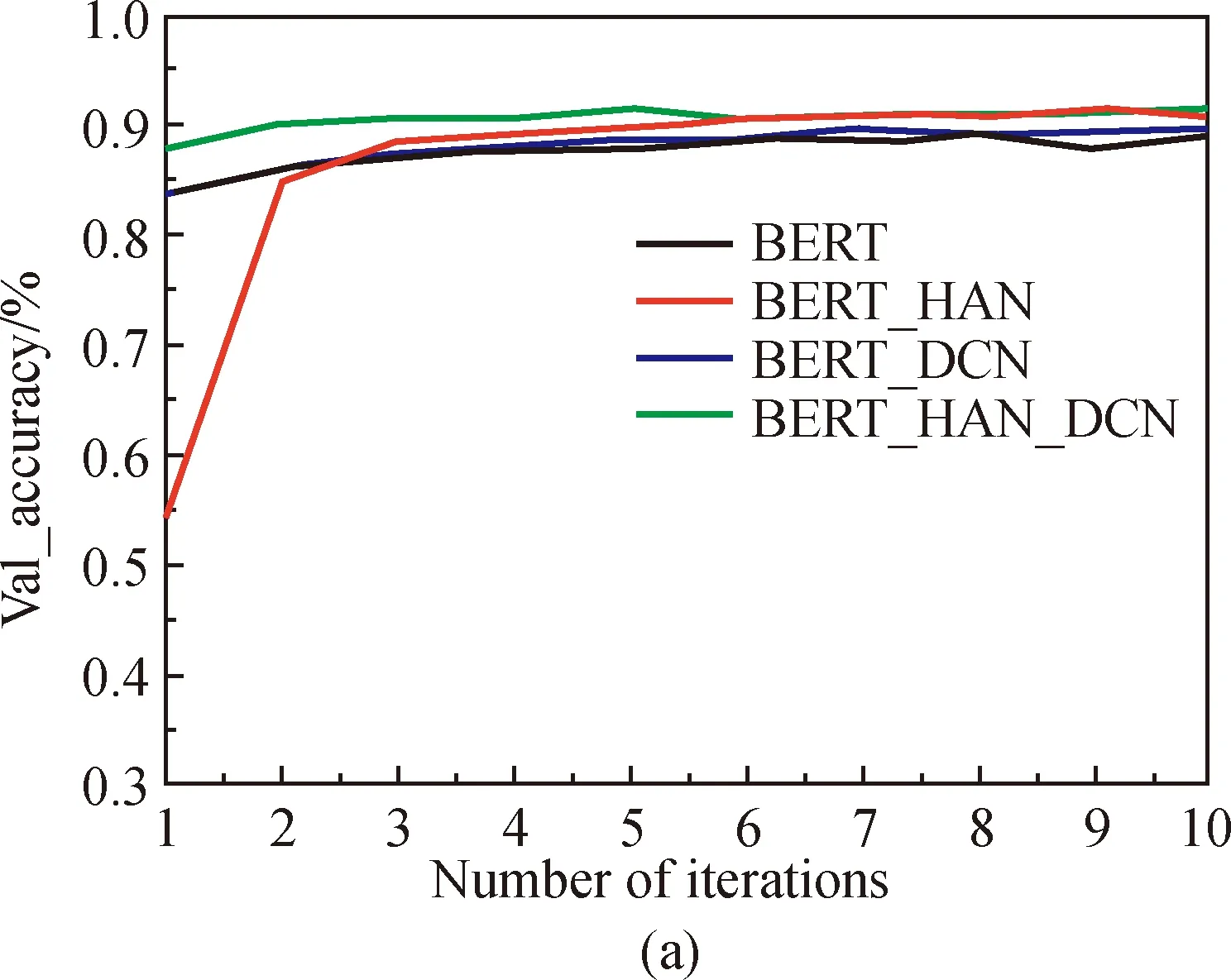


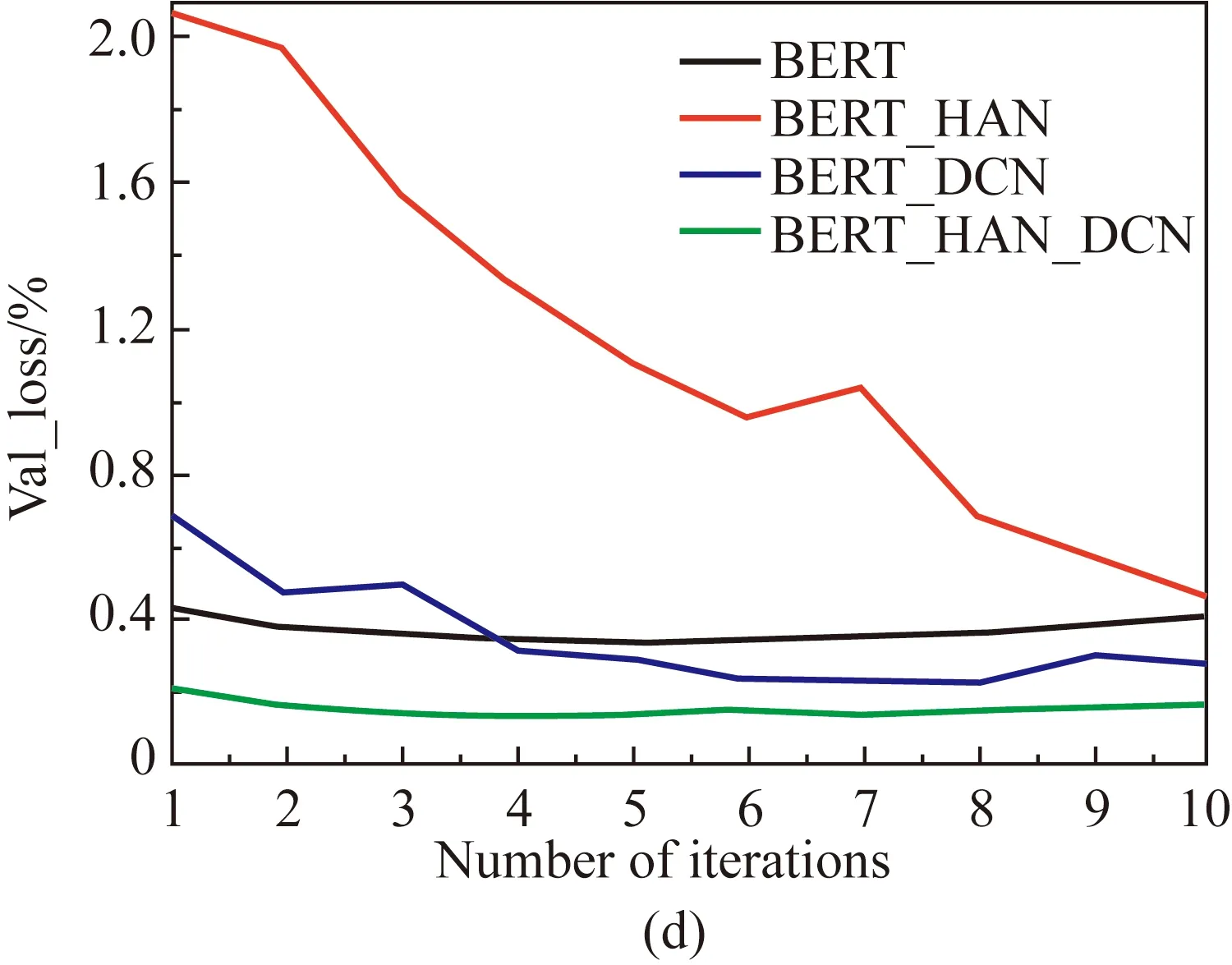
Fig. 4 Training performance comparison between the presented model and other basic models: (a)-(b) training curves of verification accuracy and loss of SougoCS; (c)-(d) training curves of verification accuracy and loss of THCNews
2.4.2ImpactofAM-softmax
AM-softmax has achieved remarkable results in the field of face recognition. Unlike softmax, AM-softmax can reduce the probability of correct label and increase the effect of loss, which is more helpful to the aggregation of the same class. The specific AM-softmax is shown as
(19)
where cosθyjis to calculatexjin the categoryyjregion;mis the area between categories which is at leastmapart. The value ofmhere is set to 0.35 which needs to consider whether there is a clear boundary between the distribution of data in the real scene. The cosine value is between [0, 1], which is too small and cannot effectively distinguish the difference. After increasingstimes to improve the difference of distribution andshere is set to 30. And with the increase of the number of training epochs, the accuracy of validation sets of different models changed as shown in Fig. 5.
From the accuracy of the verification sets, it can be concluded that after 5-6 times of model training about two datasets, the mixed model BERT_HAN_DCN which based on AM-softmax tends to be stable and finally achieves higher accuracy.
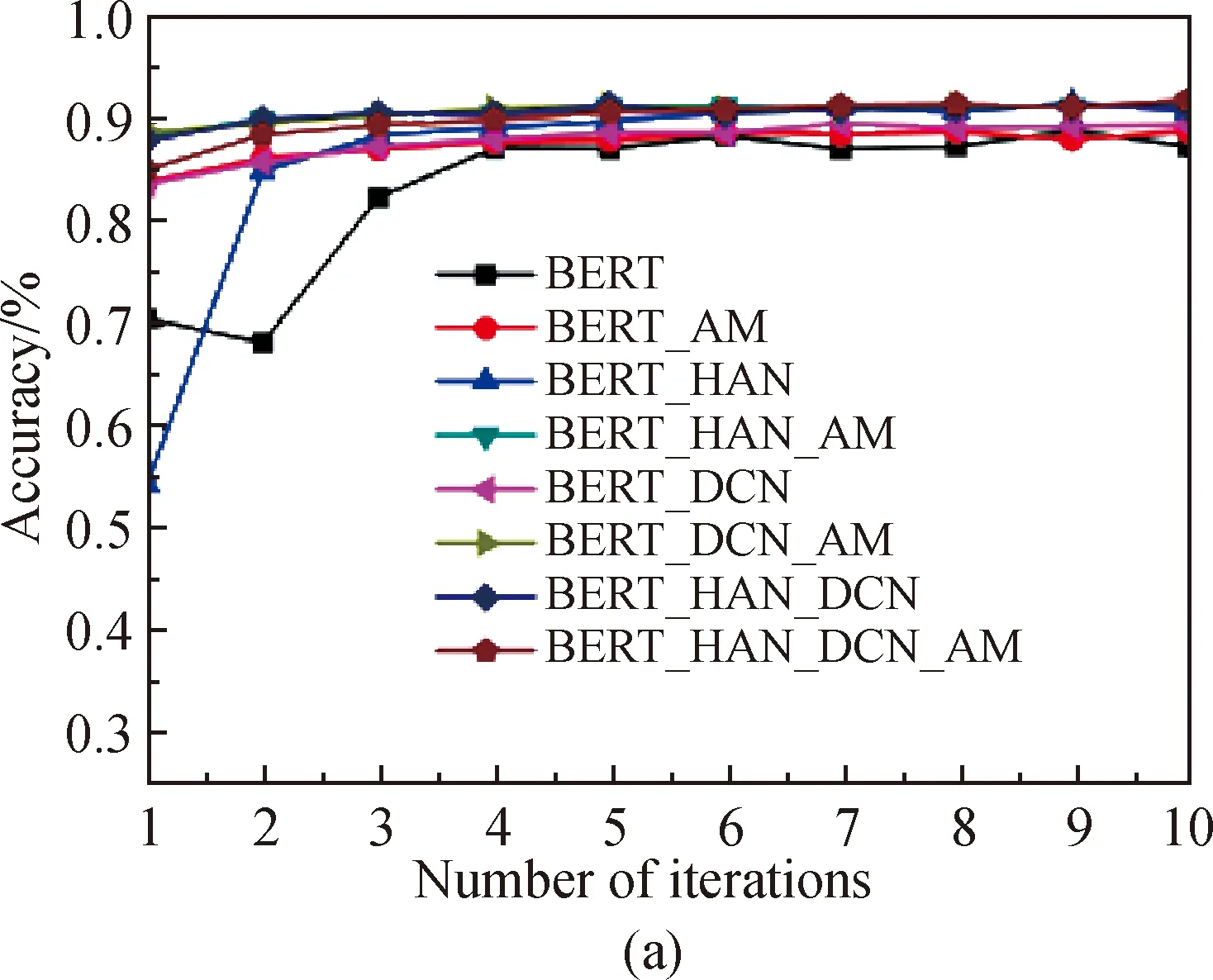
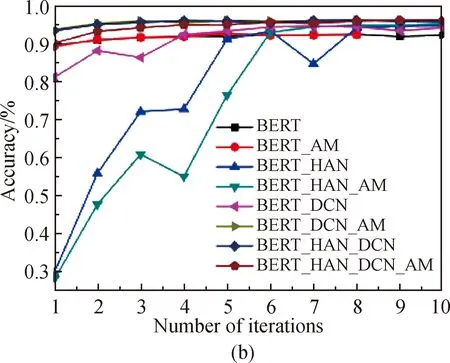
Fig. 5 Training performance comparison between different models: (a) training accuracy curves of SougoCS based on AM-softmax models and the original models; (b) training accuracy curves of THCNews based on AM-softmax models and the original models
The training models were verified by the validation set after 10 epochs. The precision, recall,F1 value and accuracy of the 8 categories of the two data sets are obtained respectively as shown in Tables 4-5.
As shown in Tables 4-5, the models using AM-softmax as loss function have slight improvement in both accuracy rate andF1 value compared with the original models. Although the improvement effect is small, it also proves that changing the way of calculating loss is also a way to improve the feature extraction ability of the training model. Finally, for SogouCS dataset, we find that the finalF1-score and accuracy of the hybrid model are respectively increased by 0.56% (from 91.42% to 91.98%) and 0.55% (from 91.42% to 91.97%). For THCNews dataset, we find thatF1-score and accuracy of the hybrid model are respectively increased by 0.34% (from 95.69% to 99.06%) and 0.3% (from 95.66% to 95.69%).
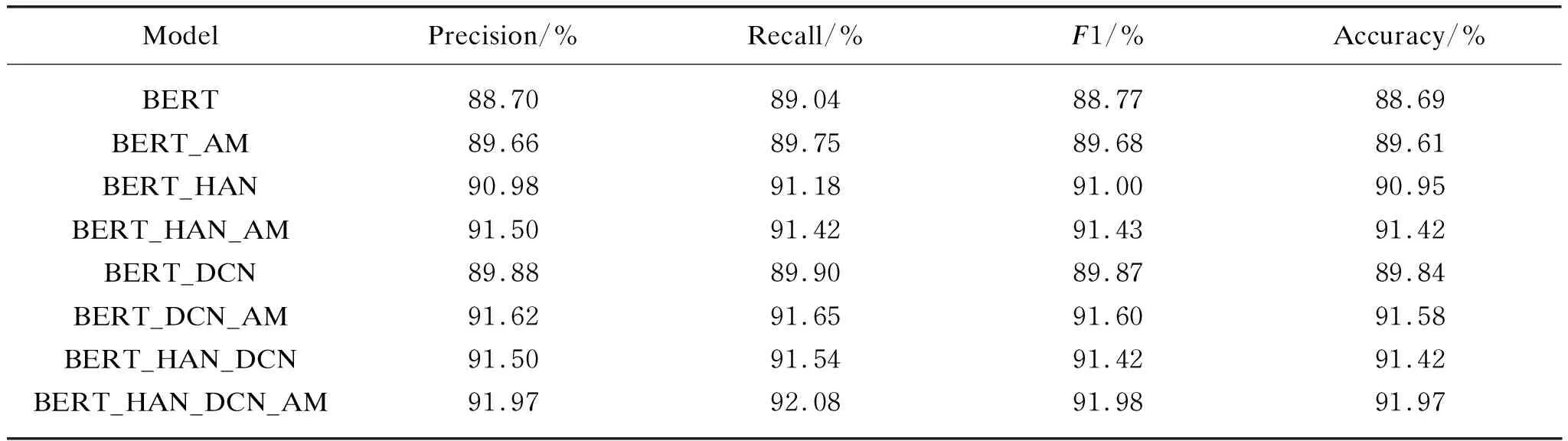
Table 4 Model comparison result on SogouCS dataset
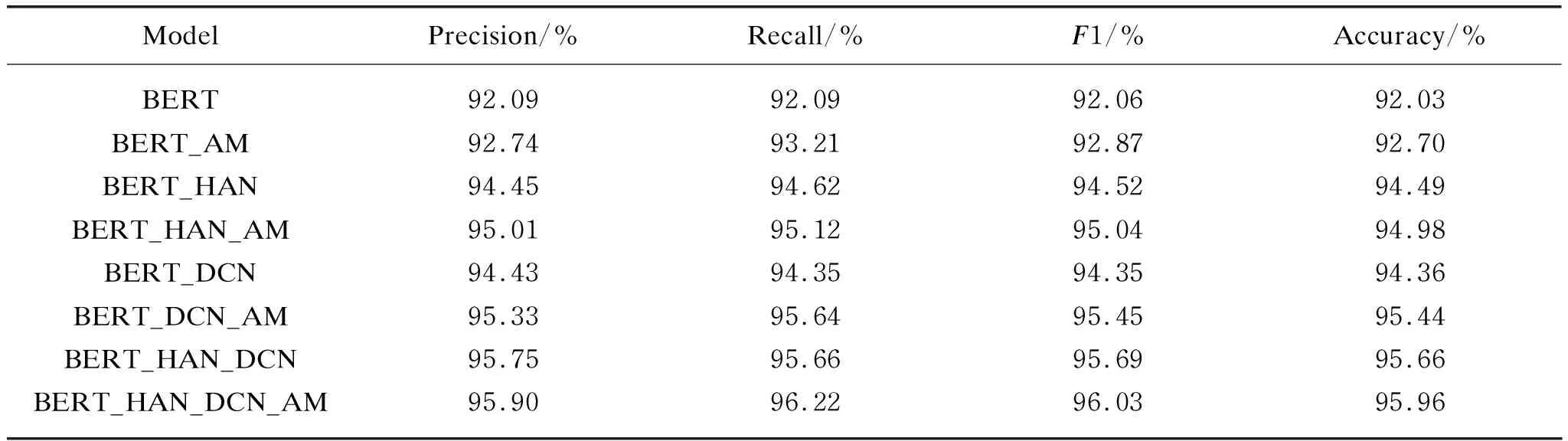
Table 5 Model comparison result on THCNews dataset
2.4.3Timecomplexitycomparisonexperiment
Under the same parameter settings, the algorithm running time of 8 different modules was compared, and the effectiveness of the algorithm was verified. The time complexity comparison experiment results are shown in Table 6.
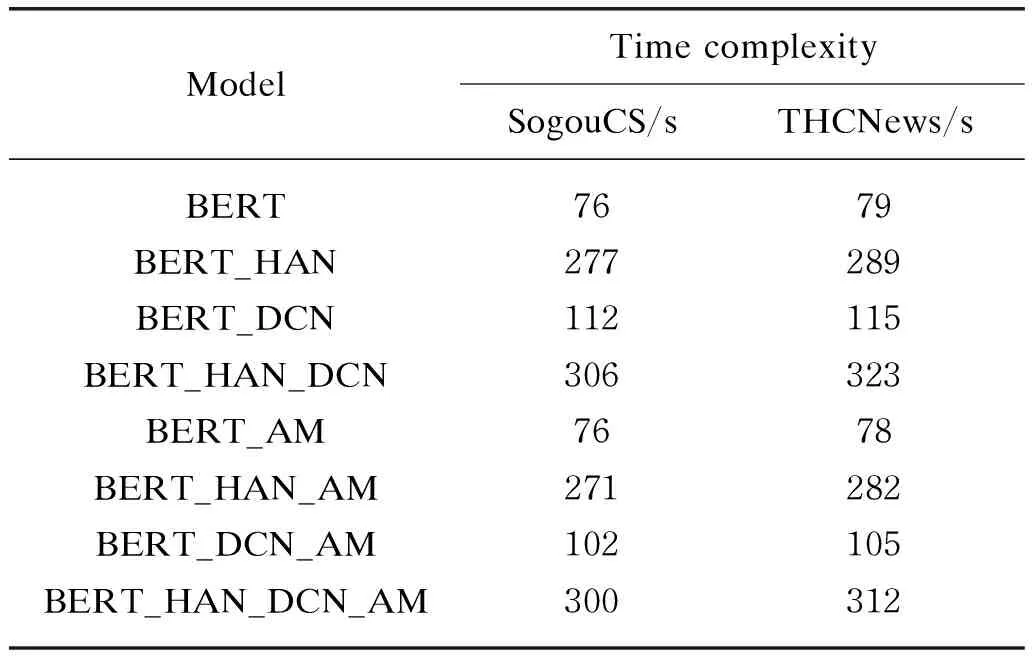
Table 6 Time complexity comparison
From Tables 4-6, experimental results show that the mixed model has higher time complexity. However, the accuracy andF1 are much better. For SogouCS and THCNews datasets, the average calculation time per epoch of the hybrid model are 230 s and 244 s longer than BERT, respectively, but the accuracy is improved. It is obvious that the addition of hierarchical attention mechanism increases the complexity of the computing complexity but effectively improves the accuracy of the model. The calculation time of all AM-softmax-based models is less than that of the original models. For the SogouCS dataset, the average calculation time of each round of the hybrid model is reduced by 6 s, and for the THCNews dataset, the average calculation time of each round of the hybrid model is reduced by 11 s. This proves that the calculation of changing the loss improves the convergence speed of the model to a certain extent and slightly reduces the complexity of the model.
3 Conclusions
This manuscript adopts the BERT_HAN_DCN model of the composite network and applies it to the task of Chinese long text classification. Compared with the single BERT model, BERT_HAN, BERT_DCN, the accuracy andF1 value of the model are the highest. The results show that the fusion of HAN and DCN is effective and can learn deep features and contextual information in long text.
In addition, by improving the loss function, the accuracy andF1 of the single model and the mixed model are improved and relatively reduced training time which proves that the mixed model can be better applied to Chinese text classification tasks. This also shows that in the process of model training, not only the ability of feature extraction and word vector transformation, but also the impact of loss function on model accuracy should be paid attention to.
However, a more complex hybrid model requires more network parameters, which requires more computing power and longer training time. In the following research, we intend to further optimize and improve the details of the algorithm and we will improve this work by building a larger dataset.
 Journal of Donghua University(English Edition)2021年4期
Journal of Donghua University(English Edition)2021年4期
- Journal of Donghua University(English Edition)的其它文章
- Influence Mechanism of Clothing Anchor Features on Consumers’ Purchase Intention
- Performance Evaluation of a Molten Carbonate Fuel Cell-Graphene Thermionic Converter-Thermally Regenerative Electrochemical Cycles Hybrid System
- Estimating Mechanical Vibration Period Using Smartphones
- Meta-Path-Based Deep Representation Learning for Personalized Point of Interest Recommendation
- Design and Characterization of Electrical Connections for Conductive Yarns
- Influence of Fe2O3 on Release Mechanism of NH3 and Other Nitrogen-Containing Compounds from Pyrolysis of Three Typical Amino Acids in Urban Sludge