語料庫語言學視域下數據驅動的數字人文研究*
——以《數字人文季刊》為例
2021-10-19 10:25:14徐彤陽王霞
圖書館論壇 2021年10期
徐彤陽,王霞
0 引言
隨著信息技術發展,數字人文領域不斷汲取其他學科的技術和方法。數字人文起源于人文計算,而人文計算發端于文學和語言學領域[1],數字人文在語言學方面的研究趨勢是基于大型語料庫的語料庫語言學[2]。數字人文是數字技術與人文學科的跨界融合產物[3],語料庫語言學是語言學在計算機技術發展過程中產生的新興學科,與數字人文學科的誕生有異曲同工之妙,二者在諸多方面有交融之處。Oberhelman[4]認為數字人文和語料庫語言學均實現從元學科領域的“近讀”到“遠讀”模式;Brooke等[5]認為在文學計算分析的語境中,數字人文學者和計算語言學家是天然的共生關系,兩個領域重疊度的升高為彼此發展產生強大的驅動力;Pastuch等[6]認為數字人文學科的發展對語言歷史學家的需求,以及在與數字人文學科不直接相關的語言學家中傳播數字人文學科發展成果的前景,使更廣泛的受眾能夠充分有效地利用數字人文成果。綜上,語料庫語言學無論被認為是一門學科還是一種研究方法,作為極具包容性的數字人文學科來講,運用其方法或研究范式進行數字人文研究無論是對于數字人文方法體系的進一步完善還是學科的方向探索都是大有裨益的。
1 相關概念的厘清
對語料庫語言學這一跨界與融合的產物,學界對于其學科論和方法論的歸屬存在爭議。本文既將它視作一門學科也視為一種方法,一種通過構建語料庫以揭示語言現象的學科和方法。從方法論講,語料庫語言學方法主要是采用專門的計算機軟件來分析被稱為語料庫的計算文本中產生的語言[7],是一種基于頻率分析和索引分析的量化的實證性研究方法[8]。從學科講,其主要應用于教學、翻譯、詞匯、詞義、詞典和語法等領域[9],除有專屬的研究范式和研究步驟外,主要關注宏觀(整個語料庫語言特征與文體類型)和微觀(具體的詞匯和語法等語言現象)兩個方面,對應兩種研究范式分別為基于語料庫方法和語料庫驅動[10]。基于數據驅動的研究范式與這二者之間的區別在于事先不對研究做任何假設,也不試圖推翻既定的理論和定理,讓數據指引研究者從語言中挖掘新的現象并作為下一階段研究依據。在將語料庫語言學引入數字人文的研究之前,需要厘清兩個領域的相關交叉概念:計算機語言學、文本挖掘、自然語言處理,通過剖析相關概念來為文章提供深層次的理論依據。
1.1 計算機語言學
語料庫語言學和計算機語言學兩者存在交叉關系。計算機語言學則是語言學的研究方法之一。Morante等[11]將計算機語言學定義為:使用計算機系統來理解和生成自然語言的方法,主要關注將計算機作為工具來對感興趣的語言論及其分支進行建模,應用領域為機器翻譯、信息檢索和人機交互。語料庫語言學是采用計算機處理和發現語言學的特定研究現象。計算機語言學的研究和應用范圍較語料庫語言學廣泛。
1.2 文本挖掘
文本挖掘(Text Mining,TM)指使用計算工具和技術從機器可讀文本或數據的聚合體中自動發現新信息和意外信息。文本挖掘需要準備源于研究問題的數據,包括數據或文本語料庫的整理、數據熟悉和清理、數據格式化以及分析方法的選擇。文本挖掘是一個通用術語,用于對大量文本進行計算分析,涉及不同研究領域和程度的分析技術,可以說語料庫語言學是語言學領域基于語料庫的文本挖掘,重點關注語言學的某種特定現象。
1.3 自然語言處理
自然語言處理(Natural Language Processing,NLP)是通過開發計算機系統來模仿人類語言行為,主要分為開發計算機程序來進行現實生活的仿真模擬交流和在更嚴格的層面(詞法、句法和語義)進行較大范圍的語篇分析兩個階段[12]。其中第二階段和語料庫語言學研究內容存在交叉關系,且自然語言處理技術如SGLM和XML標記系統為語料庫處理中的注釋階段提供了技術支撐。語料庫語言學可看作是自然語言處理的一個應用領域,同時也是數字人文學科在處理計算機可讀文本時的處理技術和手段。
2 數字人文和語料庫語言學結合的可行性
在厘清兩個領域交叉概念基礎上,對數字人文和語料庫語言學之間關系的剖析、二者跨領域結合的可行性探討很有必要。Brooke等[5]認為數字人文和語料庫語言學的關系是互惠互利、互動共生的,從數據和方法兩個維度來對數字人文和語料庫語言學進行對比[13]。首先,二者都是依賴數字技術解決領域傳統研究技術落后的新興學科,均實現了“定性-定量”二者結合的方法轉變。其次,語料庫語言學的研究對象——語料庫既可為語言學領域的研究提供數據基礎,又可利用語料庫提供的數字圖像和文本之間的關聯來支持自動語言處理和增強數字人文學科的資源[14];反之,數字人文研究成果可以為語料庫語言學提供研究數據的支撐。總體講,無論是數字人文還是語料庫語言學的發展不僅對傳統人文學科進入數字時代的發展困境,而且還為人類特有語言文本和其他形式的精神成果的數字化存儲、轉譯、處理、分析和檢索提供了新的思路。因此,恰當處理大數據時代數據和人文的平衡關系是數字人文學者需要重點關注的問題[15]。數字人文和語料庫語言學對比,詳見表1。
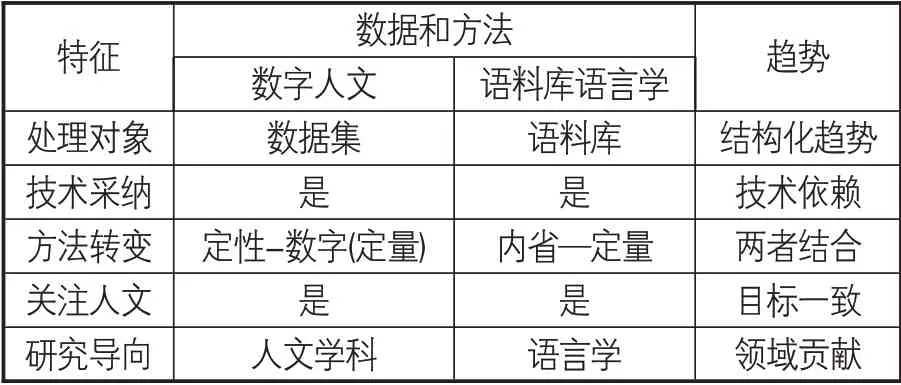
表1 數字人文和語料庫語言學對比
3 語料庫構建與工具選取
文章以《數字人文季刊》(Digital Humanities Quarterly,DHQ)作為語料庫構建的數據來源。從DHQ官方網站下載2007年和2019年數據,以基于數據—驅動的研究范式進行數字人文語料庫研究,采用同類型語料庫對比的研究方法[16]。需要說明的是,對比語料庫需要滿足代表性、同質性和可比較性3個原則[17]。
3.1 數據選取原則
(1)代表性。代表性作為一種重要的屬性和指標,衡量樣本語料庫是否能作為該領域語言整體來與一般語料庫進行比較[17]。代表性可以應用到專業領域的語料庫構建中,以揭示在特定領域中真實語料庫所反映的語言現象。文章采用DHQ作為數字人文領域的數據來源,因為該刊自2007年建刊以來在同行期刊中具有權威性,且以數字人文為專題建刊,對數字人文領域的文章收錄范圍廣、形式多樣,具有數字人文領域的代表性特征[18]。
(2)同質性。同質性主要針對兩個語料庫(非常規語料庫)間的對比,同質性重要之處在于能夠反映一個語料庫在某些特征與另一個語料庫的差異[19]。文章語料庫對比均來自DHQ,同屬數字人文領域的語料庫,因此具備同質性要求。
(3)可比較性。可比較性體現在兩個語料庫進行比較時,對于語料庫的選擇采用同樣的抽取方法[20]。文章采用DHQ語料庫中不同年份的子語料庫間的對比,通過分析語料庫的語言特征來揭示數字人文發展路徑和未來趨勢。
3.2 數據處理
(1)處理工具。采用英國蘭卡斯特(Lancaster)大學語料庫研究中心Paul Rayson等開發的基于網絡的語料分析工具Wmatrix,第四版本[21]。該工具在實現關鍵詞表、索引行、搭配功能基礎上,由關鍵詞分析向詞性、語義分析擴展[22]。詞性分析時采用CLAWS進行標記和注釋,在關鍵詞列表的生成過程中綜合考慮詞在句中語法重要性、詞的范圍和分布對關鍵詞表的影響。由內嵌的工具USAS對文本進行語義賦碼,將沒有成為關鍵詞但具有重要語法功能的低頻詞結合起來,實現語料庫整體的詞匯定量分析。
(2)2019年語料庫和2007年語料庫對比。2019年語料庫共32篇文章,純文本格式占1.2MB;2007年語料庫共12篇文章,純文本格式占520kb。參照語料庫選自BNC Sampler Written(968,267詞)[23]。
3.3 語料庫分析
3.3.1 關鍵詞分析
對兩個語料庫的比較先從詞的維度進行。由于不同語料庫中詞頻排序不同,所以不能直接比較詞的頻數,且語料庫大小不同,因此需要根據語料庫大小將頻數轉換為頻數占比進行標準化處理。另外,采用的LL值是對數似然比,Rayson[24]通過對不同顯著性差異指標對比,認為LL值更適合語料庫對比研究的統計分析。當自由度為1,(LL值計算采用2*2列聯表)在99%水平上,臨界值為6.63(p<0.0.1)時,兩個語料庫有1,145個過度使用或為充分使用的具有顯著差異的詞,但將臨界值調整為99.99%(p<0.0001)水平上臨界值為15.13時,具有顯著差異的詞僅有446個。去除“our”“we”“and”“if”等不做重點研究的詞外,排名前20的關鍵詞見表2。
居于第一位的詞是“projects”。“項目”一詞在2019年語料庫中出現462次而在2007年語料庫中出現13次,LL值為247.57>15.13。通過進一步查看該詞在索引行中的位置,如圖1所示,發現搭配的詞為“數字人文”“很多”“一些”等,用來修飾“項目”這個名詞。可以推斷,數字人文領域目前以項目制為主要研究形式。出現在第二位的“humanities”和第19位的“digital”在2019年語料庫中出現頻率分別為0.37%和0.63%遠大于2007年語料庫的0.08%和0.39%。除掉“人文”與“數字”共現外,人文都是獨立存在的,說明數字人文領域相關學者和研究人員對人文性的關注愈發凸顯。需要注意的是,“digital”一詞雖然在兩個語料庫中出現頻次都較多,但出現在表2的倒數位置,歸結為兩個原因:一是表2為2019年與2007年語料庫對比情況,旨在分析二者語言現象的差異,反過來會出現不同的結果;二是Wmatrix中關于詞維度的分析兼顧詞頻和詞在句子中的語法重要性程度,“數字”的出現頻率和在句子中的語法成分導致這種情況的出現。
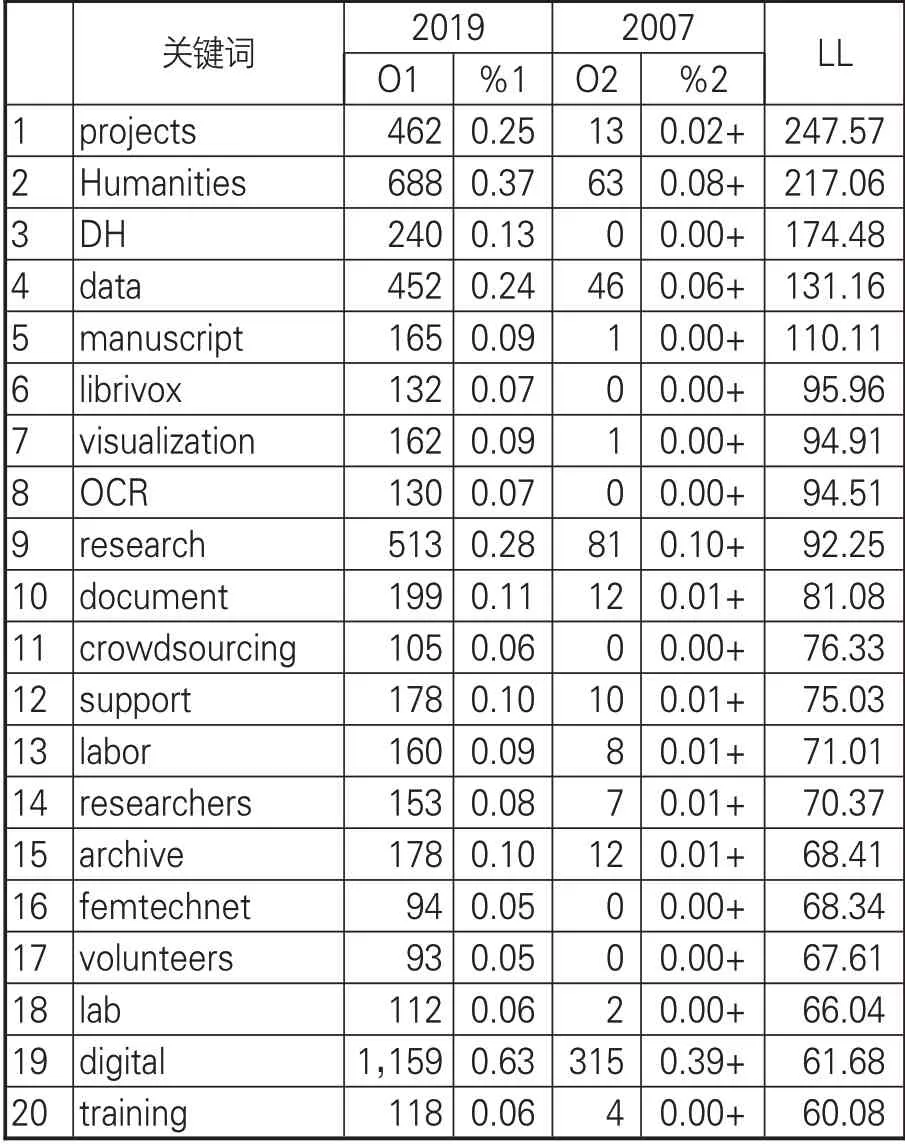
表2 2019年和2007年語料庫前20關鍵詞對比

圖1 “projects”一詞出現在對應句子中呈現的索引行列表
由于語料庫選擇的領域為數字人文,故“DH”出現頻率高不足為奇。“data”“manuscript”“document”“archive”4個詞都是對數字人文處理對象的描述。從檔案-文件-手寫稿-數據這樣一個數據形式過渡鏈,可以看出,數字人文研究對數據集的要求從結構化向非結構化過渡:從數字人文發展伊始以圖博檔機構的結構化程度較高的資源為研究基礎,至今以數據來統稱一切可作為數字人文的研究對象。這種轉變對大數據技術的發展應用提出了挑戰,也表明數字人文發展中研究范式逐漸傾向基于數據驅動的研究范式。
“visualization”“OCR”是兩種不同數據處理階段的技術。可視化技術一般出現在對數據的分析和處理階段,以直觀方式展示數據中包含的信息及發現新知識的過程。OCR(光學字符識別)技術是采用光學的方式將紙質的字符和圖片中的文字轉化為文本格式,供文字處理技術進一步編輯和加工處理。數字人文在發展進程中,不斷吸收前沿技術帶來的新鮮養分,幫助研究人員提高處理數據的效率,加深對數字人文研究的洞見。
“research”“researchers”兩個條目雖然詞根相同,但考慮其詞性在句中承擔的成分不同,故分別進行關鍵值計算,二詞均表達學科領域從事研究工作的參與者。很多語料庫工具在詞頻統計時,將這類詞作為一個詞來統計,忽略了部分詞的詞性不同其含義也不同的可能。“spring”一詞作為名詞譯為“春天”,作動詞時當“活躍、涌現”講,可見詞的隱喻性分析對于語言表達中隱喻含義的表征意義重大。
值得關注的是“librivox”“crowdsourcing”“volunteers”3個詞在2007年語料庫中沒有出現,說明與2007年相比,“有聲讀物數字圖書館”“眾包”“志愿者”已經成為2007年之后數字人文新的發展模式和趨勢。“眾包”已然成為數字人文項目發展模式,“志愿者”出現說明了傳統數字人文項目隊伍建設向眾包項目制數字人文研究隊伍建設的重整,“有聲讀物數字圖書館”網站提供了一個全球性的志愿者社區,致力于記錄所有作為免費有聲讀物的公共領域文本,是典型的眾包模式實踐。
“support”“labor”為2019年語料庫中具有顯著性意義的詞,可見數字人文研究和項目運行中需要跨學科、多領域展開廣泛的合作,不僅需要政策和資金的支持來保障數字人文研究項目順利進行,還要求大量科研機構和人員參與。查看“training”這一關鍵詞的索引行,發現“訓練”大多與數據和數據集搭配出現,表明數字人文研究對數據的處理基于訓練數據集,進而構建模型來實現大量數據的處理。利用機器學習等計算方法來對語料庫分析屢見不鮮,如Schl?r等[25]研究采用支持向量機和深度學習的方法對,對句子進行自動判斷與識別。盡管如此,句子、語言、古籍等人為產物是人的意識和思維的外顯,是有溫度的,如何平衡技術冰冷和人文性溫暖是未來在給人文研究插上數字翅膀時需要思考的問題。
3.3.2 詞性分析
Wmatrix的優勢之一在將關鍵詞分析擴展到詞性分析。多角度提供對語料庫數據語言現象和整體文本信息的挖掘。當自由度為1,p<0.01臨界值為6.63時在2019年和2007年語料庫中出現97個過度使用或未充分使用的具有顯著意義的詞性標記,在99.99%水平(p<0.0001)有31個顯著的詞性標記。前20標記對比見表3。最顯著的詞性標記PPIS2代表第一人稱復數主觀人稱代詞(we)。2019年語料庫對“we”的使用頻率相當于2007年的3倍。對于“we”的使用受到英語語言使用習慣的影響,在此不做深入分析。需要特別注意的是,ND1代表方向名詞的單數形式,檢索索引行發現,2007年“西方”這一方位詞的使用最多,2019年則以“南部”最為顯著,進一步分析索引行內容,發現DH2018年會首次在南半球舉行。FO代表公式、符號,索引行均為數字或者簡單數學公式、百分比等,可看出數字人文研究越來越多地融入數學、統計學學科理論,為數字技術環境下人文現象的發現和解釋提供客觀依據,其余詞性標記如名詞、動詞、形容詞等反映的語詞性質,需要依附在一定的關鍵詞才具有更豐富的研究價值。
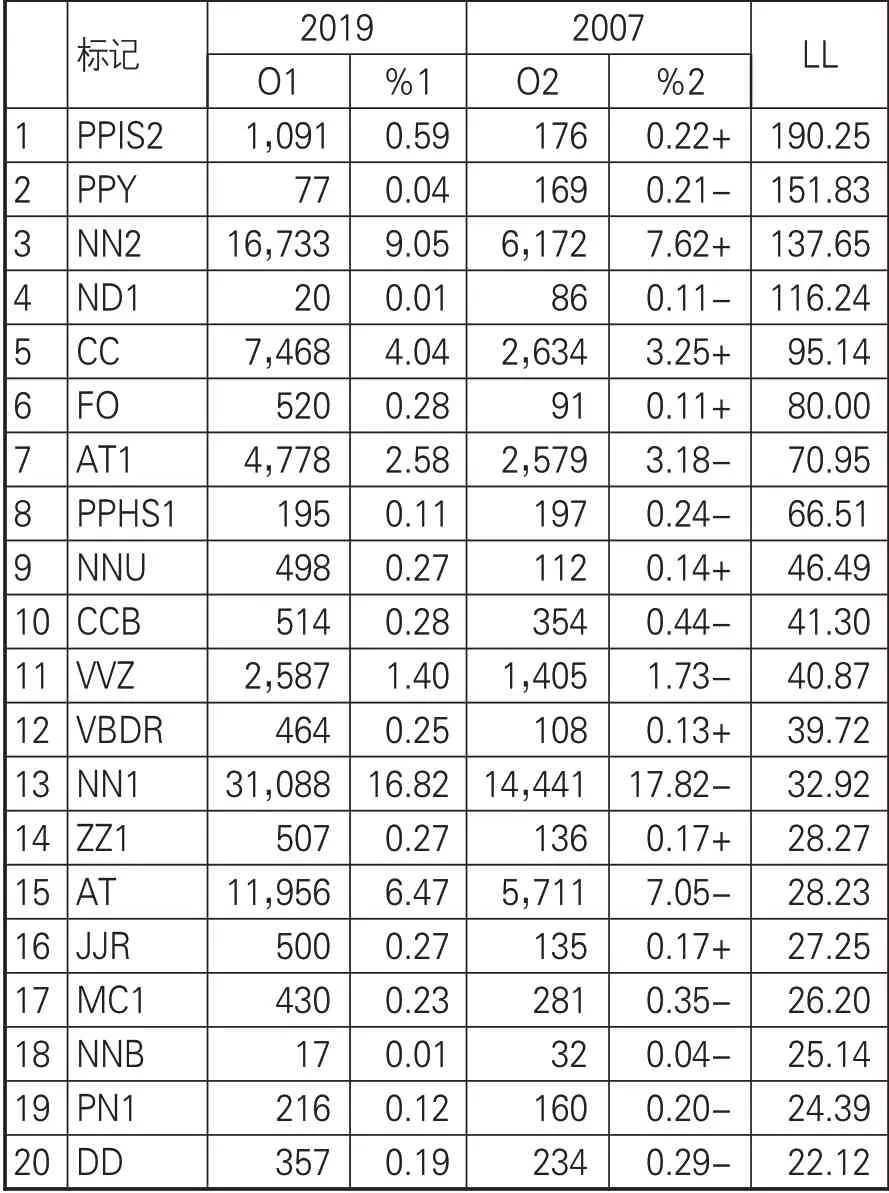
表3 2019年和2007年語料庫前20詞性標記對比
3.3.3 語義域分析
使用USAS標記為2019年和2007年語料庫分配語義域標簽。在自由度為1(P<0.1)臨界值為6.63時有140個有顯著差異的過度使用和未充分使用語義域標簽。在(P<0.0001)臨界值為15.13時有88個顯著差異的語義域標簽,表4列出前20語義域標簽。
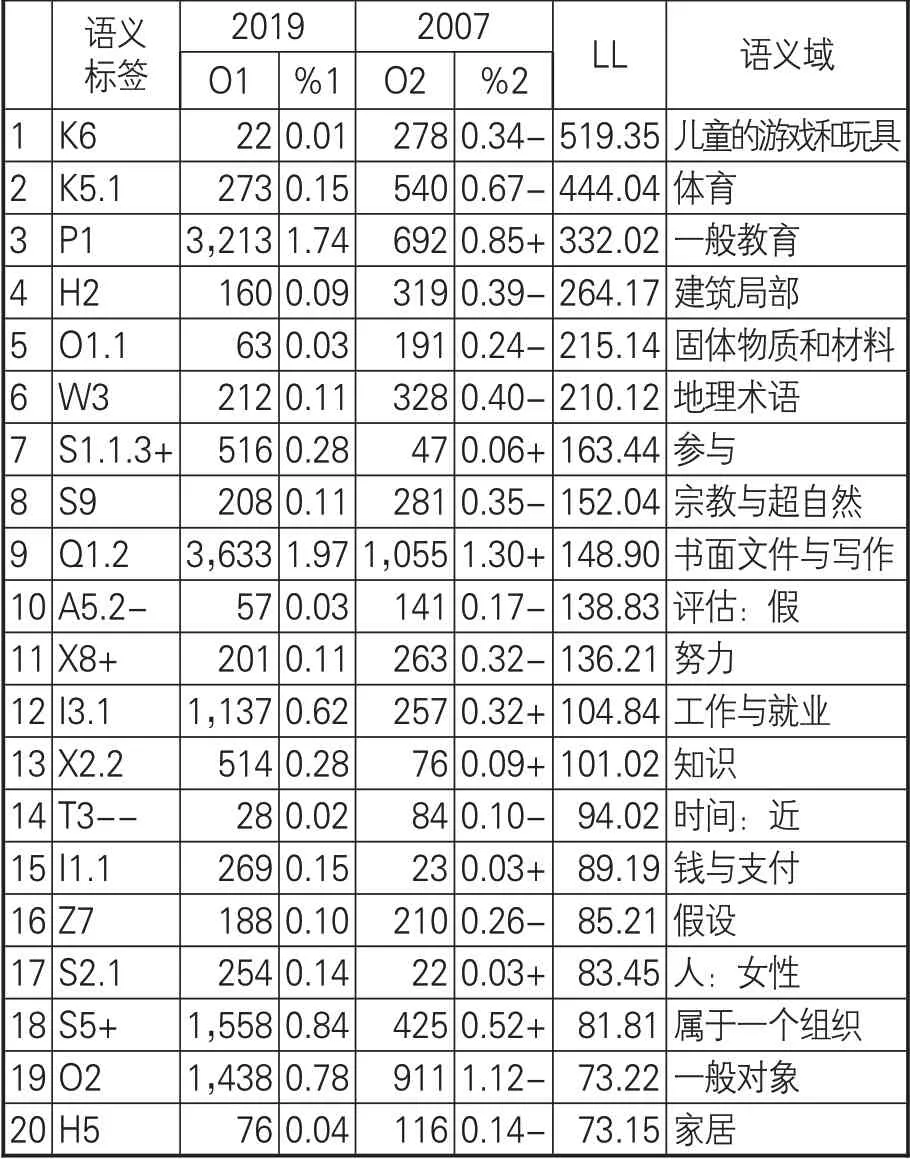
表4 2019年和2007年語料庫前20語義域標記對比
K6最具顯著性差異的LL值為519.35,但要關注排名第二的K5.1語義域中包含“game”“goal”。雖然在對照語料庫中兩個詞用來描述體育領域,但結合關鍵詞所在語境分析,“game”指游戲,“goal”指目標。將“game”與第一語義域中“player”等描述游戲詞匯匯總,得到語義域頻率:2019年頻率為137,2007年頻率為709,“-”代表“游戲”語義域在2007年語料庫中使用較多。P1代表“一般教育”,“+”說明教育在2019年語料庫中使用較多。H2語義域中以2007年語料庫中使用顯著,相關索引行顯示的“room”“departments”“threshold”“walls”“doors”等詞,并非使用詞本義,在語境中分析采用詞的引申含義,代表空間、阻擋和壁壘等含義。O1.1語義域中除去“Woods”作為人名的頻率,其余“stone”“cave”“steel”“mud”等詞在語境中以本意出現。W3語義域在2007年語料庫中使用較多,相關詞語為“hill”“valley”。S1.1.3+語義域代表“參與”的相關語義域詞匯,如圖2所示。
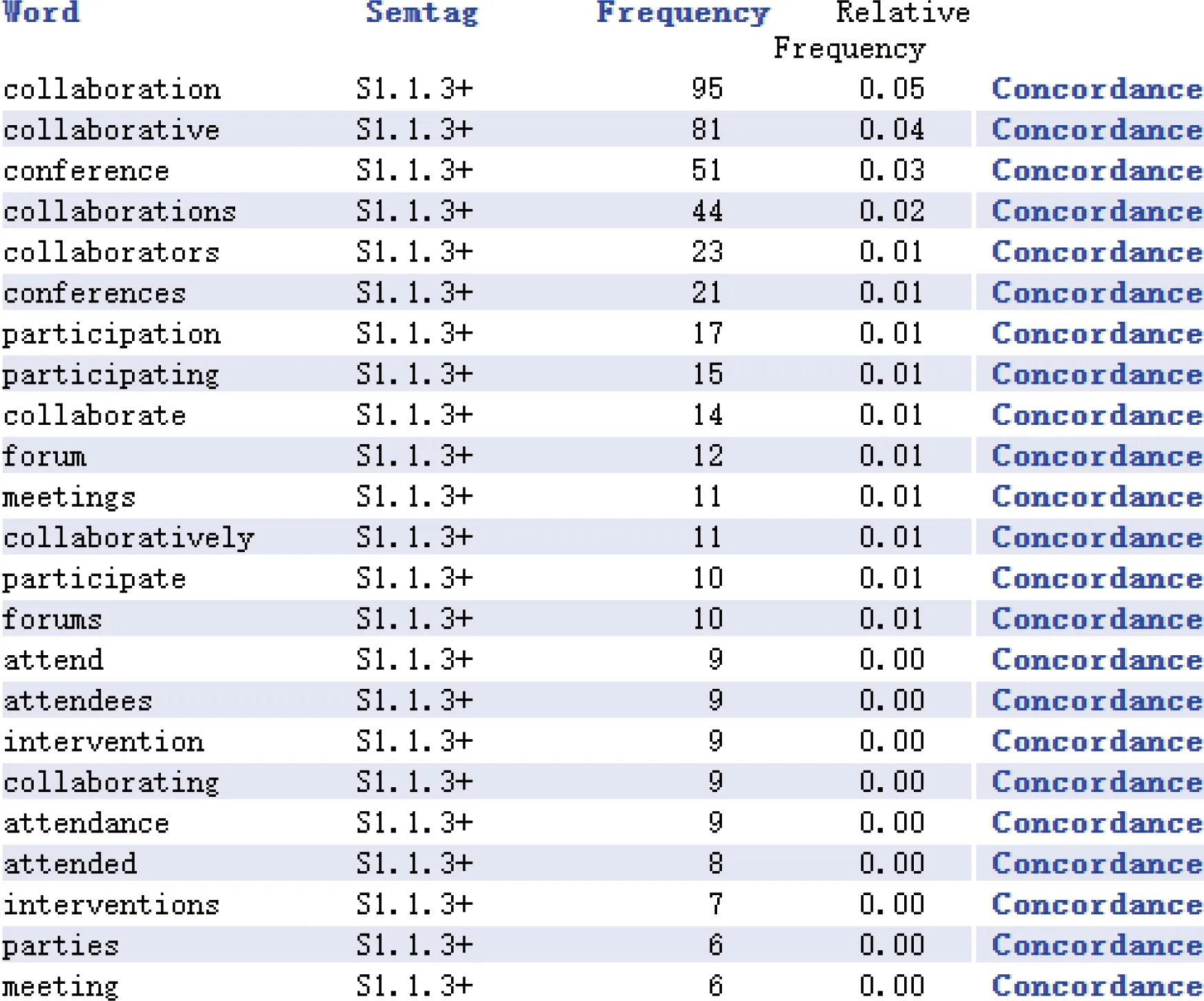
圖2 “參與”語義域的相關詞匯列表
S9代表“宗教與超自然”語義域,該領域在2007年語料庫中出現的背后原因在于宗教學科也是數字人文應用領域。Q1.2語義域以文本、列表、記錄和檔案等詞匯構成。A5.2-語義域以“虛假”“誤導”等詞為主,在2007年語料庫中使用較多,其中需要提出“fiction”一詞,該詞在相關語境中譯作“小說”,說明在2007年數字人文研究關注小說這一文學形式。X8+語義域的關鍵詞為“努力”“盡力”“斗爭”“試圖”等。I3.1語義域在2019年使用多于2007年,“團隊協作”“志愿者”“招聘”等詞反映了數字人文團隊構建和招聘等相關工作。X2.2、I1.1、S2.1、S5+等4個語義域在2019年語料庫中的頻率分別為0.28、0.15、0.14、0.84,其中X2.2代表知識,反映了數字人文研究以數據為基礎進行的知識挖掘;I1.1語義域突出了數字人文研究項目的資金支持與來源;S2.1語義域代表女性話題,映射出無論是女性數字人文研究者還是女權主義的發展研究者逐漸成為數字人文領域研究群體;S5+語義域以“組織”“機構”“團隊”等為主要關鍵詞,表明數字人文研究的隊伍建設情況。
T3--語義域在2007年語料庫中使用最多的詞匯是“avant-garde”,譯為前衛派思想或先鋒。Z7語義域——“假設”以“if(假如)”為關鍵詞。O2語義域雖然在2019年語料庫中頻率較高,但是頻率占比低于2007年,以“object(對象)”“model(模型)”為主要關鍵詞。H5語義域中包含歧義詞“table”,根據語境譯為“表格”,這里不做進一步研究。
綜上,去除有歧義詞語義域歸屬不恰當的標記后可知,“游戲”“阻礙”“地理術語”“宗教”“努力”“前衛思想”“假如”“對象”等關鍵詞為2019年與2007年語料庫對比中具有顯著性差異的語義域典型關鍵詞。其中,“游戲”和“宗教”作為數字人文的主要應用領域;“努力”和“假如”從語言學角度體現了學者對數字人文未來發展的憧憬和信心。2019年語料庫中使用較多的語義域中關鍵詞有“教育”,從側面揭示了數字人文在發展十余年來對教育開始重視并開展數字人文素質教育;“參與”“團隊”“組織”體現了數字人文團隊組織的要件,與第一部分詞分析結果中的眾包對組織構建的內涵屬同一范疇;“數據”一詞強調數據是數字人文研究的基礎;“機構”“資助”表明數字人文項目的開展需要政府機構和相關組織予以大力支持;“女性”表明了女性問題在數字人文研究中的關注度越來越高,無論是作為研究成員還是歷史上關于女性問題的研究。
3.3.4 進行可視化分析并對比Wmatrix分析結果
為了更直觀地觀察構建的DHQ語料庫文本中出現頻率較高的關鍵詞,選用可視化工具Voyant來對Wmatrix工具處理數據結果進行簡單驗證。
運用Stéfan Sinclair等開發的Voyant文本挖掘工具[26],對兩個語料庫進行可視化分析,作為Wmatrix工具分析結果的對比,見圖3-4。可以看到,兩個語料庫中關鍵詞的可視化分析與Wmatrix的分析結果基本吻合,關于頻數差異在于工具對多詞組合和詞的單復數形式統計標準不同導致。在2019年語料庫中出現的“work”在Wmatrix中沒有顯示,原因在于Wmatrix并不是單純基于統計和計量學角度進行詞頻統計,還結合語言學領域中詞在句中成分的重要性,讓更多頻率不高但處于語言學關鍵位置的詞析出,為關鍵詞分析提供不同的統計標準,有利于實現文本中不同詞匯現象和信息的深度挖掘。通過分析發現,不同的處理工具對于詞頻的統計方式、核心算法和研究側重點存在差異,導致全面把握領域研究內容有一定的誤差,但對于整體語料的解釋性方面是一致的。因此,構建領域語料庫、優化準確率較高的算法、改進語料庫處理準確性是未來重要的突破口。

圖3 Voyant工具中2007年語料庫關鍵詞

圖4 Voyant工具中2019年語料庫關鍵詞
4 結果與討論
傳統的數字人文熱點與發展趨勢研究基于關鍵詞、共詞、上下文、項目信息、作者合著等,這樣的模式可看作“遠讀”模式[27]。遠讀雖然可以從宏觀角度來俯視整個學科的發展脈絡,但是一些細微、具體的語言現象不被重視和發覺,語料庫語言學分析彌補了這樣的不足,兼顧“遠讀”和“近讀”模式,將具有重要語法意義的詞匯析出,彌補作為數字人文發展熱點分析的微觀體現,只有遠讀和近讀結合才能全面考量學科領域的整體發展狀況。本文對DHQ語料庫關鍵詞、詞性、語義域進行文本及可視化分析,下文進行結果討論。
4.1 研究對象:數據作為數字人文研究結構化形式的數據基礎設施
夏翠娟提出數字人文“數據基礎設施”為數字人文研究基礎設施的一部分[28],這一概念彰顯數據在數字人文研究中的重要地位,尤其是基于數據驅動的數字人文研究。這里是以數據本意來談基礎設施的,而筆者現在要研究的是數據的結構化形式。從文中的關鍵詞分析不難看出,數字人文實現了從最初的圖檔博館藏結構化資源到手寫稿再到數據的非結構化過渡,研究數據的細粒度化和包容性不斷提高,同時也揭示了數字人文的實踐和服務半徑在不斷擴展和延伸。
4.2 研究模式:眾包模式是項目制數字人文研究探索的新成果
本文的語料庫關鍵詞分析表明,出版公司和志愿者等詞匯頻繁出現,實現傳統數字人文以項目制研究模式到眾包模式的過渡和升級,是數字人文學科壯大發展的新成果。眾包模式從商業環境過渡到科研領域,核心在于創新協作模式。首先,數字人文為跨學科研究領域,需要人文學科、計算機領域等學者通力合作才能實現研究和實踐目標,因此眾包應運而生。其次,數字人文項目源于人文資源和人文課題,項目實施過程中不能完全依賴機器語言和思維來處理的資料和工作,往往需要公眾和志愿者參與貢獻時間、精力和智力。因此,眾包的出現是合乎數字人文學科本質和發展路徑的。
4.3 數字技術:自然語言處理和可視化技術成為剛需
數字人文概念提出后,不少學者關注數字人文的技術路徑并提出相應的技術體系。文中從語料庫中析出較為突出的自然語言處理,在應用中對數字人文處理數據的結構化要求降低,意味著對自然語言處理技術要求的提高。自然語言處理技術的廣泛應用可實現人類思維和計算機思維的有效通信,將大量紙質信息數字化是數字人文研究的基礎,基于此,進行形態學、詞匯、OCR識別、情感分析和命名實體識別等多層面的分析。另外,可視化技術可直觀地對數據采集、關聯和成果進行展示,并在此基礎上通過視覺特征引申出新的研究課題。最后,數字人文研究成果可視化有助于提高公眾的人文理解和激發公眾參與數字人文研究的積極性。
4.4 研究導向:不斷加強對人文性的重視
數字和人文兩個詞匯的頻率變化使對人文性重視的語言現象昭然若揭。從2007年到2019年“人文”一詞出現頻率大幅提高,說明數字人文學者在采用數字技術進行研究和實踐過程中,逐漸從數字技術為主的研究導向轉向以人文性為主、技術為輔的研究導向,讓以數字技術解決人文課題變得有溫度。對于人文性的關注,有學者提出,我國關于數字人文的討論最早來自傳播領域對于數字時代人文精神缺失的批判;而Spence等[29]認為數字人文不只是以軟件模型來代表人文學科的理論框架,數字人文的核心是人文學科,人文學科講究人文性。可見國內外數字人文發展的不同階段均對數字人文研究實踐的人文性予以重視,利用數字技術解決人文課題的同時最大限度保留人文性是人文學者的初衷。
4.5 研究群體:對不同角色女性群體的關注
女性一詞的首次出現值得關注,無論是女性人員參與數字人文研究和實踐活動,還是以某個時期女性的研究目標,均體現了女性參與職業準入的自由性和開放性,以及女性在漫長的歷史長河中實現角色獨立的努力和變革,也是數字人文對人文性重視的外顯。將女性作為研究對象,數字人文研究成果可為其他學科提供新的研究課題,女性參與此類數字人文項目和研究,對于研究的人文性關注是最大的體現。如我國有學者以慰安婦為研究起點,將增強現實技術引入南京地區侵華日軍慰安所研究[30]。
5 結語
對于數字人文學科發展和熱點趨勢的研究,很多學者從關鍵詞、作者合著、引用與被引等角度進行分析。但是在大數據視域下,數字人文學科的發展和實踐方向要走“大科學”的理論和思想路線,將眾多大規模、歷時性的信息碎片糅合,構造數字人文大局面,因此,挖掘新方法、采用新模式、融合新技術是數字人文發展的必然趨勢。文章以數字人文領域中具有同行代表性的期刊DHQ作為語料庫的數據來源,對其進行語料庫語言學分析,以反映數字人文領域的歷時性語言現象。數據的形式化要求、眾包新模式的探索、自然語言和可視化技術的應用、人文性的重視和對女性參與者及女性群體的關注,是本文從語料庫語言學視角對DHQ進行歷時語料庫整體分析的五個維度的發現,為數字人文未來與語言學的融合發展起到拋磚引玉的作用。
李慧楠等[31]對2019年數字人文年會各種形式的信息整理,基于“語料庫”一詞的頻率很高,提出語料庫建設一直是數字人文的核心工作之一。但是,目前數字人文領域還未構建專門語料庫,對于語義域賦碼很難做到專業的標記,而包含隱喻現象的詞匯處理準確率問題仍亟待解決,這也是本文的不足之處。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
開放教育研究(2020年2期)2020-03-31 01:54:14
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
