基于YOLOv5的小目標檢測
2021-10-18 00:31:38江磊崔艷榮
電腦知識與技術 2021年26期
江磊 崔艷榮


摘要:在進行目標檢測時,小目標會出現漏檢或檢測效果不佳等問題。本文將YOLOv5算法用于小目標檢測,YOLOv5有3個檢測頭,能夠多尺度對目標進行檢測,并對數據做了Mosaic數據增強、自適應錨框計算、統一圖片尺寸等數據預處理,對小目標有很好的檢測效果。基于YOLOv5的基礎上進行改進,把CIOU_Loss、DIOU_nms運用于YOLOv5算法中。實驗結果表明,基于YOLOv5的小目標檢測,準確率高,速度快,具有很好的性能。
關鍵詞:小目標檢測;YOLOv5
中圖分類號:TP18? ? ? 文獻標識碼:A
文章編號:1009-3044(2021)26-0131-03
開放科學(資源服務)標識碼(OSID):
Small Target Detection Based on YOLOv5
JIANG Lei, CUI Yan-rong
(Yangtze University,Jingzhou434023,China)
Abstract: in the process of target detection, small targets may miss detection or have poor detection effect. In this paper,YOLOv5 algorithm is used for small target detection. YOLOv5 has three detection heads, which can detect the target in multi-scale. The data are preprocessed by mosaic data enhancement, adaptive anchor frame calculation, unified image size and so on. It has a good detection effect for small targets. Based on the improvement of YOLOv5, the CIOU_Loss、DIOU_NMS is used in YOLOv5 algorithm. The experimental results show that the small target detection based on YOLOv5 has high accuracy, fast speed and good performance.
Key words:small target detection;YOLOv5
目標檢測是計算機視覺領域比較熱門的研究方向,已廣泛運用到國防、醫療、工業等領域。由于小目標的尺寸小、分辨率低,常用的目標檢測算法在檢測小目標時會出現漏檢或特征不明等問題。
近年來,隨著深度學習的不斷發展,許多基于卷積神經網絡的目標檢測算法被提出,卷積神經網絡可以對數據自主訓練學習,更新參數,得到一個比較準確的模型。基于卷積神經網絡的目標檢測算法可以分為兩大類。一類是雙步目標檢測算法,如R-CNN,SPP-net,Fast R-CNN,Faster R-CNN,Mask R-CNN等,這些算法把目標檢測分為兩步進行,先生成Region Proposal(候選區),在把Region Proposal(候選區)送入網絡結構中提取特征,并預測檢測目標的位置、識別檢測目標的類別。另一類是單步目標檢測算法,如YOLOv1,YOLOv2,YOLOv3,YOLOv4,YOLOv5等,此類算法不需要生成Region Proposal(候選區),而是直接把圖片分成S×S個網格,在網格的基礎上提取特征,并由算法得到目標的位置和類別。
雙步目標檢測算法要生成大約2000個Region Proposal(候選區),花費了大量的時間,它的檢測速度比較慢,但準確率相對較高。由于單目標檢測算法是在圖片劃分網格的基礎上提取特征,所以它的檢測速度很快,但是早期的YOLO算法會有一定的誤差,隨著技術的發展,YOLO中提出了anchor box(先驗框)機制,如YOLOv5中就有9個大小不同的anchor box(先驗框),能夠精準地檢測到不同尺度的目標,提高了檢測精度。
1 YOLO的發展
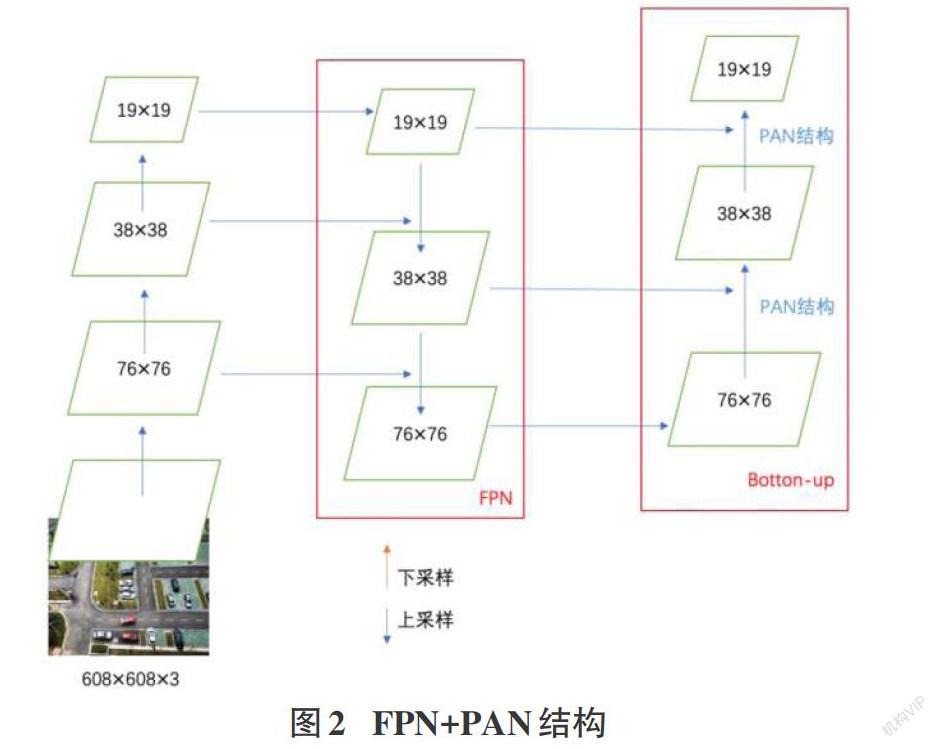
傳統目標檢測算法,主要分為三步:選擇區域框、提取特征、歸分類別,這就存在有兩個問題;一是區域選擇的方法效果不佳、且時間成本很高;二是提取的區域框魯棒性很差。隨后出現的R-CNN系列算法,需要提前生成大量的Region Proposal(候選區),在候選區的基礎上提取特征,花費很多時間。YOLOv1把生成Region Proposal(候選區)和提取特征歸為一步,圖片被劃分為S×S個grid(網格),在grid(網格)上提取特征,每個grid(網格)對應兩個Bounding box(邊界框),缺陷是:速度上提高了,準確率卻沒有那么高,很容易漏檢。YOLOv2的Backbone使用了Darknet-19,去掉了FC(全連接層),每個grid(網格)上使用5個anchor box(先驗框),YOLOv2使用ImageNet大量的分類樣本,聯合COCO的對象檢測數據集一起訓練,可以檢測出一些沒有學習過的對象,識別的對象更多。YOLOv2在YOLOv1的基礎上做了一些改進,如批量歸一化,多尺度圖像訓練,passthrough層檢測細粒度特征等,速度和準確率得到了提升,但是YOLOv2在小目標檢測方面還是不夠精準。YOLOv3采用了新的Backbone(主干網絡) Darknet-53,它含有53個卷積層,為避免梯度消失,使用了殘差網絡,Head部分利用多尺度特征檢測對象,在網絡中分別使用32倍下采樣,16倍下采樣,和8倍下采樣,每個下采樣尺度下設定3種anchor box(先驗框),可以檢測不同尺寸的對象。YOLOv4在YOLOv3的基礎上,把很多優良的方法結合在一起,結構得到優化、性能更加強大。YOLOv4的Input使用了Mosaic數據增強、cmBN(交叉小批量歸一化)、SAT自對抗訓練。Backbone使用CSPDarknet53,使用遺傳算法選擇超參數,用Dropblock防止過擬合,使用Mish和Leaky Relu激活函數。增添了Neck,Neck由SPP模塊和FPN+PAN結構組成。Head部分仍然采用YOLOv3的多尺度特征檢測[2-4]。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
