多目標(biāo)跟蹤下點(diǎn)跡凝聚的實(shí)時(shí)優(yōu)化算法
2021-10-15 01:33:36吳春林曹運(yùn)合
兵器裝備工程學(xué)報(bào) 2021年9期
吳春林,曹運(yùn)合,王 蒙
(1.海軍航空大學(xué)青島校區(qū), 山東 青島 266041; 2.西安電子科技大學(xué), 西安 710071;3.北京機(jī)電工程研究所, 北京 100074)
1 引言
點(diǎn)跡凝聚作為雷達(dá)信號(hào)處理過(guò)程中重要的一環(huán),幫助雷達(dá)在大量雜波干擾下準(zhǔn)確的獲取目標(biāo)的距離、速度、方位角等信息,為后續(xù)的目標(biāo)跟蹤等算法提供有力的支撐。
在脈沖多普勒體制的雷達(dá)系統(tǒng)中,為了提高采樣信號(hào)的質(zhì)量,一般雷達(dá)系統(tǒng)的采樣頻率會(huì)大于奈奎斯特采樣頻率。這樣會(huì)導(dǎo)致對(duì)同一個(gè)目標(biāo)點(diǎn)有多個(gè)檢測(cè)點(diǎn),恒虛警處理后,還是會(huì)留下多余的點(diǎn)跡,所以需要使用點(diǎn)跡凝聚算法對(duì)其進(jìn)行處理,保留最能反應(yīng)目標(biāo)參數(shù)的點(diǎn),而篩除掉其他虛假的目標(biāo)點(diǎn)[1-3]。
在需要凝聚的點(diǎn)數(shù)較少的情況下,常規(guī)的做法可以滿足實(shí)時(shí)性的需求。但針對(duì)現(xiàn)在的多目標(biāo),群目標(biāo)跟蹤,由于目標(biāo)個(gè)數(shù)的增加,恒虛警處理之后會(huì)產(chǎn)生大量的待凝聚點(diǎn)跡。當(dāng)需要凝聚的點(diǎn)跡數(shù)量劇增時(shí),常規(guī)的實(shí)現(xiàn)方案[4]就不能滿足實(shí)時(shí)性的需求了。為了能提升大數(shù)據(jù)量下點(diǎn)跡凝聚算法的實(shí)時(shí)性,有很多針對(duì)于特定平臺(tái)下的實(shí)現(xiàn)優(yōu)化[5-9],點(diǎn)跡凝聚算法的實(shí)現(xiàn)還可以通過(guò)優(yōu)化數(shù)據(jù)結(jié)構(gòu)的使用和充分發(fā)掘并行性進(jìn)行優(yōu)化。本文中在常規(guī)的點(diǎn)跡凝聚算法的實(shí)現(xiàn)方案[10-15]基礎(chǔ)上,通過(guò)預(yù)排序、HashMap優(yōu)化和多線程優(yōu)化來(lái)降低算法的執(zhí)行時(shí)間。在待凝聚點(diǎn)數(shù)較大時(shí),最優(yōu)方案相對(duì)于常規(guī)的實(shí)現(xiàn)方案在點(diǎn)跡數(shù)量為有著顯著的加速效果。
2 常規(guī)點(diǎn)跡凝聚算法實(shí)現(xiàn)方案
點(diǎn)跡凝聚算法在工程上的常規(guī)實(shí)現(xiàn)方案是以恒虛警處理后目標(biāo)回波的幅度值大小作為判斷依據(jù),根據(jù)點(diǎn)跡在距離-多普雷矩陣中的位置確定凝聚處理的窗大小,進(jìn)行凝聚處理。
假設(shè)有N個(gè)待凝聚的點(diǎn)跡,最終凝聚出來(lái)M個(gè)有效目標(biāo),算法主要的時(shí)間消耗在了2個(gè)步驟上:
1) 從剩余目標(biāo)中找幅值最大點(diǎn);
2) 遍歷所有剩余點(diǎn)確定是否在凝聚窗內(nèi)。
這2個(gè)操作都需要進(jìn)行M次循環(huán),每次循環(huán)需要操作的點(diǎn)跡個(gè)數(shù)為當(dāng)前輪次的剩余點(diǎn)跡個(gè)數(shù),設(shè)每次循環(huán)排除的點(diǎn)跡個(gè)數(shù)分別為n1,n2,n3,…,nM,操作每個(gè)點(diǎn)跡的時(shí)間為t,那么總的時(shí)間消耗為
Ttotal=(2N+2(N-n1)+2(N-n2-n1)+…+
2(N-nm-…-n2-n1))*t=
(2NM-[n1+(n2+n1)+…+
(nm+…+n2+n1)])*t
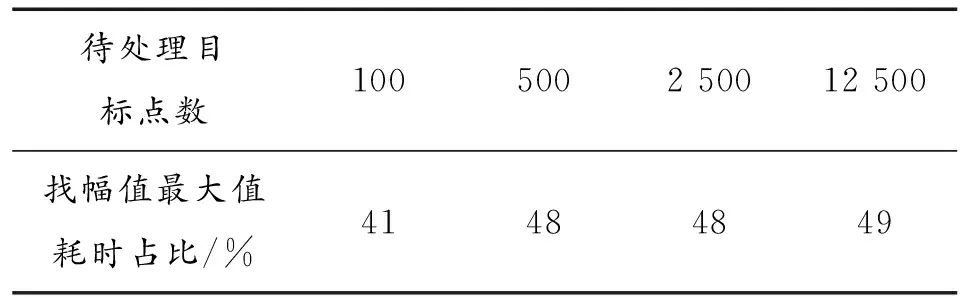
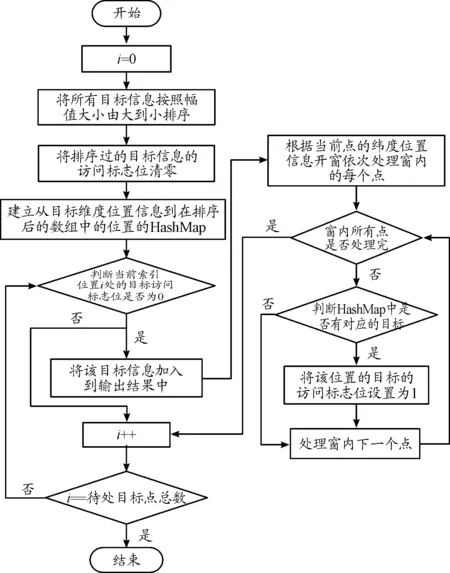
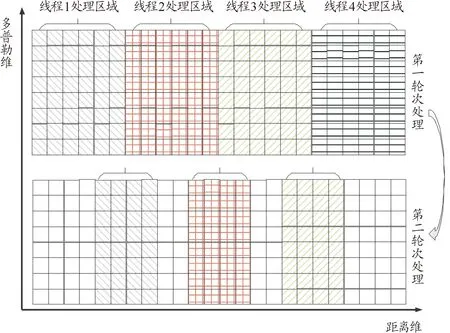
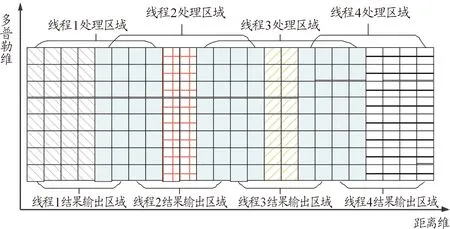
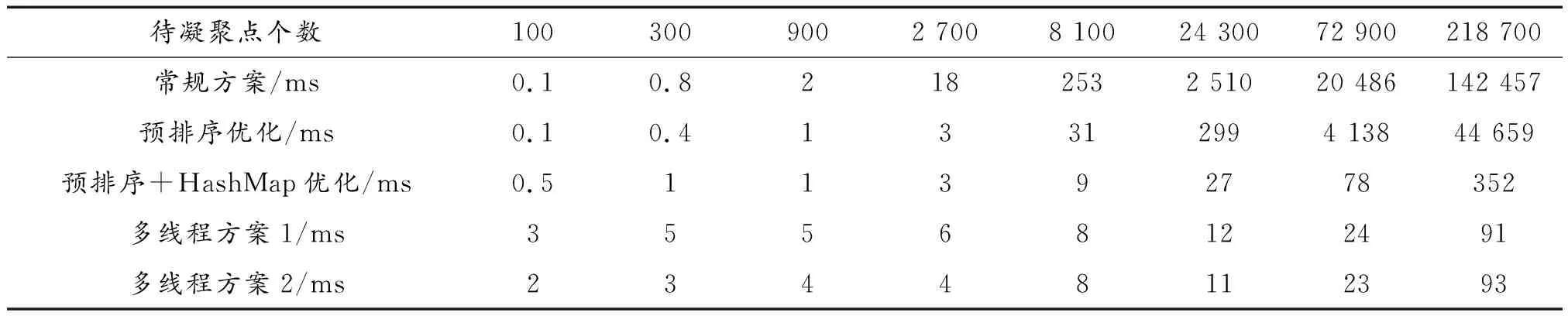
NMt 因此算法的時(shí)間復(fù)雜度為O(NM)。算法的優(yōu)化方向主要在優(yōu)化那2個(gè)耗時(shí)步驟上。 執(zhí)行流程如圖1所示。 圖1 常規(guī)方法實(shí)現(xiàn)點(diǎn)跡凝聚程序流程框圖Fig.1 Flow chart of conventional plots centroid method 算法實(shí)現(xiàn)偽代碼如下: Algorithm 1 點(diǎn)跡凝聚算法的常規(guī)實(shí)現(xiàn) Input: CFARRes Output: CentroidRes 1 leftCFARRes=CFARRes; 2whileleftCFARRes is not emptydo 3 maxAmpItem=leftCFARRes[0]; 4foritem in leftCFARRes do 5Ifitem.amplitude > maxAmpItem.amplitude then 6 maxAmpItem=item; 7endif 8endfor 9foritem in leftCFARRes do 10ifitem in maxAmpItem’s centroid window then 11 delete item; 12endif 13endfor 14 insert maxAmpItem to CentroidRes; 15endwhile 對(duì)基本實(shí)現(xiàn)方案進(jìn)行編程實(shí)現(xiàn),對(duì)程序分塊計(jì)時(shí)分析由表1可知,算法執(zhí)行時(shí)間近半耗費(fèi)在從剩余點(diǎn)跡中獲取幅值最大點(diǎn)的操作。可以通過(guò)對(duì)點(diǎn)跡根據(jù)幅值信息進(jìn)行預(yù)排序進(jìn)行優(yōu)化。工程上常用的排序算法是快速排序算法,因此我們選擇快速排序算法對(duì)算法進(jìn)行優(yōu)化。 表1 常規(guī)實(shí)現(xiàn)方案中找幅值最大值時(shí)間消耗占比 執(zhí)行流程如圖2所示。 圖2 使用預(yù)排序優(yōu)化的程序流程框圖Fig.2 Flow chart of using pre-sort optimization 算法實(shí)現(xiàn)偽代碼如下: Algorithm 2 使用預(yù)排序優(yōu)化點(diǎn)跡凝聚算法的實(shí)現(xiàn) Input: CFARRes Output: CentroidRes 1 sort CFARRes with quick sort algorithm by amplitude; 2i=0; 3whilei 4ifCFARRes[i].visited == 0 then 5 Insert CFARRes[i] to CentroidRes; 6j=i+1; 7whilej 8ifCFARRes[j] in 9 CFARRes[i]’s centroid windowthen 10 CFARRes[j].visited=1; 11endif 12j++; 13endwhile 14endif; 15i++; 16endwhile 相對(duì)于常規(guī)方案的點(diǎn)跡凝聚算法,本方案的優(yōu)化點(diǎn)在于優(yōu)化了尋找剩余點(diǎn)跡中幅值最大點(diǎn)這一操作,凝聚窗內(nèi)點(diǎn)跡的方法不變。對(duì)N個(gè)點(diǎn)跡,如果經(jīng)過(guò)算法處理最終凝聚成M個(gè)目標(biāo),其快速排序的時(shí)間復(fù)雜度為O(NlogN),而常規(guī)方案中,尋找剩余點(diǎn)跡中幅值最大點(diǎn)的操作的時(shí)間復(fù)雜度為O(MN)。這里,還可以采用基數(shù)排序的方法對(duì)待凝聚點(diǎn)跡進(jìn)行排序,基數(shù)排序的理論算法復(fù)雜度更優(yōu)。基于上述可以分析出,當(dāng)需要凝聚的點(diǎn)數(shù)較多時(shí),應(yīng)該采用預(yù)排序的方法對(duì)執(zhí)行時(shí)間進(jìn)行優(yōu)化。 在預(yù)排序的前提下,還可以進(jìn)一步優(yōu)化凝聚窗內(nèi)點(diǎn)跡的操作。對(duì)于每一個(gè)目標(biāo)點(diǎn),我們?cè)谄渚嚯x維和多普勒維開(kāi)一個(gè)窗口,判斷剩余點(diǎn)跡是否在這個(gè)窗內(nèi),需要遍歷所有的剩余點(diǎn)跡,我們可以預(yù)先建立點(diǎn)跡在距離-多普勒矩陣中的位置到其在排序后的點(diǎn)跡數(shù)據(jù)中的位置的映射,便可以在常數(shù)時(shí)間內(nèi)鎖定窗內(nèi)的點(diǎn)是否在點(diǎn)跡數(shù)組中。使用HashMap的數(shù)據(jù)結(jié)構(gòu)可以實(shí)現(xiàn)這種映射關(guān)系。 使用HashMap這一數(shù)據(jù)結(jié)構(gòu)的關(guān)鍵點(diǎn)在于鍵值key的選取、桶的個(gè)數(shù)的確定和沖突解決方案的選擇。假定點(diǎn)跡在距離-多普勒矩陣中的坐標(biāo)為(x,y),經(jīng)過(guò)分析和測(cè)試,最終選擇(x<<16)+y作為鍵值,使用大于點(diǎn)跡個(gè)數(shù)的最小素?cái)?shù)作為桶的個(gè)數(shù),使用拉鏈法來(lái)解決哈希沖突的方案來(lái)構(gòu)造HashMap這一數(shù)據(jù)結(jié)構(gòu)。該方案能夠較為均勻的將點(diǎn)跡分布在各個(gè)桶里,保證能在常數(shù)時(shí)間內(nèi)確定映射關(guān)系。 相對(duì)于常規(guī)的實(shí)現(xiàn)方案,使用HashMap進(jìn)行優(yōu)化的點(diǎn)集中在降低凝聚窗內(nèi)點(diǎn)跡的復(fù)雜度上。對(duì)于N個(gè)點(diǎn)跡,凝聚成M個(gè)目標(biāo)來(lái)說(shuō),之前的方案中這一操作的時(shí)間復(fù)雜度為O(MN),使用HashMap優(yōu)化后,時(shí)間復(fù)雜度降低為O(M),這種優(yōu)化對(duì)性能的提升是巨大的。 算法的程序流程如圖3所示。 圖3 使用預(yù)排序+HashMap優(yōu)化的程序流程框圖Fig.3 Flow chart optimized using pre-sorting+HashMap 算法實(shí)現(xiàn)偽代碼如下: Algorithm 3 使用預(yù)排序+HashMap優(yōu)化點(diǎn)跡凝聚算法的實(shí)現(xiàn) Input: CFARRes Output: CentroidRes 1 sort CFARRes with quick sort algorithm by amplitude; 2 initial hashMap by build map relationship 3 from target position to its index in CFARRes; 4i=0; 5whilei 6ifCFARRes[i].visited == 0then 7 insert CFARRes[i] to CentroidRes; 8foritem in CFARRes[i]’s centroid windowdo 9ifitem’s position in hashMapthen 10 CFARRes[hashMap(Item’s position)]. visited=1; 11endif 12endfor 13endif 14i++; 15endwhile 隨著摩爾定律的逐漸失效,現(xiàn)代處理器的處理主頻已經(jīng)接近其物理上限了,不能夠像之前一樣,通過(guò)提升處理器主頻來(lái)提升處理器的性能。多核便成為了現(xiàn)代處理器必然的發(fā)展方向。核心數(shù)32個(gè)的商用桌面級(jí)CPU已經(jīng)很常見(jiàn),TI的c66x系列DSP的最高核心數(shù)也達(dá)到了8個(gè)。為了使算法能夠利用多核處理器的優(yōu)勢(shì),需要充分的發(fā)掘算法執(zhí)行中的并行性,使用多線程的優(yōu)化方案是建立在預(yù)排序和HashMap優(yōu)化的基礎(chǔ)上。本文給出2種多線程的優(yōu)化方法。這2個(gè)方案都是建立在需要凝聚的點(diǎn)跡在距離-多普勒矩陣中的分布是呈現(xiàn)多點(diǎn)聚簇的樣式,對(duì)于在大范圍內(nèi)連續(xù)的點(diǎn)跡是不適用的。 方案1:假設(shè)處理器有N個(gè)核心,則開(kāi)辟N個(gè)線程。N個(gè)線程根據(jù)點(diǎn)跡的距離單元來(lái)劃分各自負(fù)責(zé)的區(qū)域,各線程之間的處理沒(méi)有重疊。各線程進(jìn)行第一輪點(diǎn)跡凝聚之后,再開(kāi)辟N-1個(gè)線程,每個(gè)線程負(fù)責(zé)的區(qū)域?yàn)榈谝惠喚€程間的鄰接部分。距離維的長(zhǎng)度為設(shè)置的距離維的窗的大小。 舉例說(shuō)明,距離-多普勒矩陣的大小為24*8,距離維窗大小為4,線程數(shù)為4。在第一輪次的處理中,線程1負(fù)責(zé)的距離單元為[1,6],線程2負(fù)責(zé)的距離單元為[7,12],線程3負(fù)責(zé)的距離單元為[13,18],線程4負(fù)責(zé)的距離單元為[19,24]。將第一輪此凝聚出的點(diǎn),選擇出距離單元在[5,8]∪[11,14]∪[17,20]的點(diǎn)跡,繼續(xù)進(jìn)行第二輪次的凝聚,第二輪次的線程數(shù)為3,線程1負(fù)責(zé)的距離單元為[5,8],線程2負(fù)責(zé)的距離單元為[11,14],線程3負(fù)責(zé)的距離單元為[17,20]。第二輪凝聚結(jié)束,即得到了最終的凝聚結(jié)果。示意圖如圖4。 圖4 多線程方案1示意圖Fig.4 Diagram of multi-threading scheme 1 方案2:假設(shè)處理器有N個(gè)核心,則開(kāi)辟N個(gè)線程。N個(gè)線程根據(jù)點(diǎn)跡的距離單元來(lái)劃分各自負(fù)責(zé)的區(qū)域,各線程之間的處理有一定的重疊。重疊區(qū)域的大小大于等于設(shè)定的距離維窗大小,對(duì)每個(gè)線程凝聚出的點(diǎn)跡進(jìn)行篩選,每個(gè)線程只負(fù)責(zé)輸出重疊區(qū)域中靠近自己處理的非重疊部分的半邊。 在點(diǎn)跡凝聚的處理中,線程1負(fù)責(zé)的距離單元為[1,8] 的點(diǎn)跡,線程2負(fù)責(zé)的距離單元為[5,14] 的點(diǎn)跡,線程3負(fù)責(zé)的距離單元為[11,20] 的點(diǎn)跡,線程4負(fù)責(zé)的距離單元為[17,24] 的點(diǎn)跡。在點(diǎn)跡的輸出過(guò)程中,線程1負(fù)責(zé)輸出距離單元為[1,6] 的點(diǎn)跡,線程2負(fù)責(zé)輸出距離單元為[7,12] 的點(diǎn)跡,線程3負(fù)責(zé)輸出距離單元為[13,18] 的點(diǎn)跡,線程4負(fù)責(zé)輸出距離單元為[19,24] 的點(diǎn)跡。示意圖如圖5。 圖5 多線程方案2示意圖Fig.5 Diagram of multi-threading scheme 2 方案1中,優(yōu)點(diǎn)在于每一輪次各線程負(fù)責(zé)的距離單元數(shù)是均勻的,且相對(duì)于方案二較少,但會(huì)有第二輪次的處理,第二輪次處理的點(diǎn)數(shù)較少,但線程調(diào)度的開(kāi)銷不小。方案2,只有一個(gè)輪次的處理,但每個(gè)線程負(fù)責(zé)的距離單元數(shù)要大于方案1,且第一個(gè)和最后一個(gè)線程的負(fù)載相對(duì)于其他線程不同,優(yōu)點(diǎn)在于沒(méi)有第二輪次的處理。 上述的2個(gè)多線程方案中目標(biāo)在距離維呈現(xiàn)均勻分布時(shí)才能取得良好的加速效果。由于實(shí)際情況中,目標(biāo)的分布狀況是未知的。為了提高多線程方案的適用性,需要在進(jìn)行多線程處理前,使用任務(wù)預(yù)分配方法合理劃分每個(gè)線程的處理區(qū)間。方法的執(zhí)行步驟和復(fù)雜度分析如下所述。 第一步需要維護(hù)一個(gè)長(zhǎng)度等于距離單元個(gè)數(shù)的計(jì)數(shù)數(shù)組,該數(shù)組初始化為零,然后對(duì)所有的目標(biāo)點(diǎn)進(jìn)行一次遍歷,在遍歷過(guò)程中,記錄對(duì)應(yīng)距離單元的目標(biāo)數(shù)。第二步從起始位置遍歷計(jì)數(shù)數(shù)組,對(duì)計(jì)數(shù)數(shù)組中每個(gè)點(diǎn)(對(duì)應(yīng)著不同的距離單元),累加統(tǒng)計(jì)從起始位置到該距離單元的目標(biāo)數(shù)。第三步根據(jù)目標(biāo)的總個(gè)數(shù)除以劃分的線程個(gè)數(shù)可確定每個(gè)線程要處理的目標(biāo)點(diǎn)個(gè)數(shù),再?gòu)牡诙降挠?jì)數(shù)數(shù)組中找到每個(gè)線程的合理處理區(qū)間,該劃分可盡最大可能平均每個(gè)線程處理的目標(biāo)點(diǎn)個(gè)數(shù),從而使整體獲得良好的平均加速效果。 對(duì)于N個(gè)目標(biāo)點(diǎn),第一步的時(shí)間復(fù)雜度為O(N),第二步和第三步實(shí)現(xiàn)時(shí)可合并處理,對(duì)于L個(gè)距離單元,其時(shí)間復(fù)雜度為O(L)。任務(wù)預(yù)分配方法的整體時(shí)間復(fù)雜度是線性的,不改變算法的整體時(shí)間復(fù)雜度。 為了對(duì)比各執(zhí)行方案的執(zhí)行效率,編程實(shí)現(xiàn)所有的方案并在同一環(huán)境下進(jìn)行性能測(cè)試。實(shí)驗(yàn)環(huán)境如表2所示,點(diǎn)跡凝聚算法的參數(shù)如表3所示。 表2 實(shí)驗(yàn)環(huán)境 表3 算法參數(shù) 為了保證測(cè)試的公平性,在測(cè)試時(shí)對(duì)以下幾點(diǎn)做出保證:確保每種方案的代碼經(jīng)過(guò)同等級(jí)的優(yōu)化,不刻意從代碼實(shí)現(xiàn)層面制造性能差異;對(duì)于多線程代碼,為降低線程建立之類的系統(tǒng)調(diào)用對(duì)程序性能的影響,預(yù)先執(zhí)行一遍多線程代碼,在再次重復(fù)執(zhí)行時(shí)對(duì)程序進(jìn)行計(jì)時(shí);性能測(cè)試結(jié)果采用多次測(cè)試取平均值的方案。最終的測(cè)試結(jié)果如表4所示。 表4 各方案執(zhí)行性能 1) 在需要處理的待凝聚點(diǎn)數(shù)較少的情況下,常規(guī)的實(shí)現(xiàn)方案的性能和優(yōu)化的方案差別很小,由于優(yōu)化帶來(lái)的額外的開(kāi)銷,常規(guī)的方案甚至略有優(yōu)勢(shì)。 2) 隨著待凝聚點(diǎn)數(shù)的增加,常規(guī)方案的執(zhí)行時(shí)間大幅增加,使用預(yù)排序+HashMap優(yōu)化的方案能夠大幅降低算法的執(zhí)行時(shí)間,具有很大的優(yōu)勢(shì)。 3) 多線程代碼相對(duì)于單線程代碼,在待凝聚點(diǎn)數(shù)較少時(shí),由于線程調(diào)度之類的開(kāi)銷的存在,使得執(zhí)行時(shí)間比單線程還長(zhǎng)。但隨著數(shù)據(jù)規(guī)模的增加,多線程方案相對(duì)于單線程的執(zhí)行時(shí)間比近似于1:線程數(shù),有著明顯的加速效果。 4) 多線程的優(yōu)化方案相對(duì)于單線程的方案,在數(shù)據(jù)規(guī)模較大時(shí),加速比接近線程數(shù)目,可充分利用現(xiàn)代處理器的多核特性。優(yōu)化措施和多線程處理,能夠使得點(diǎn)跡凝聚算法在大數(shù)據(jù)量下仍能滿足雷達(dá)信號(hào)處理實(shí)時(shí)性的需求,對(duì)今后的工程實(shí)現(xiàn)有著巨大的意義。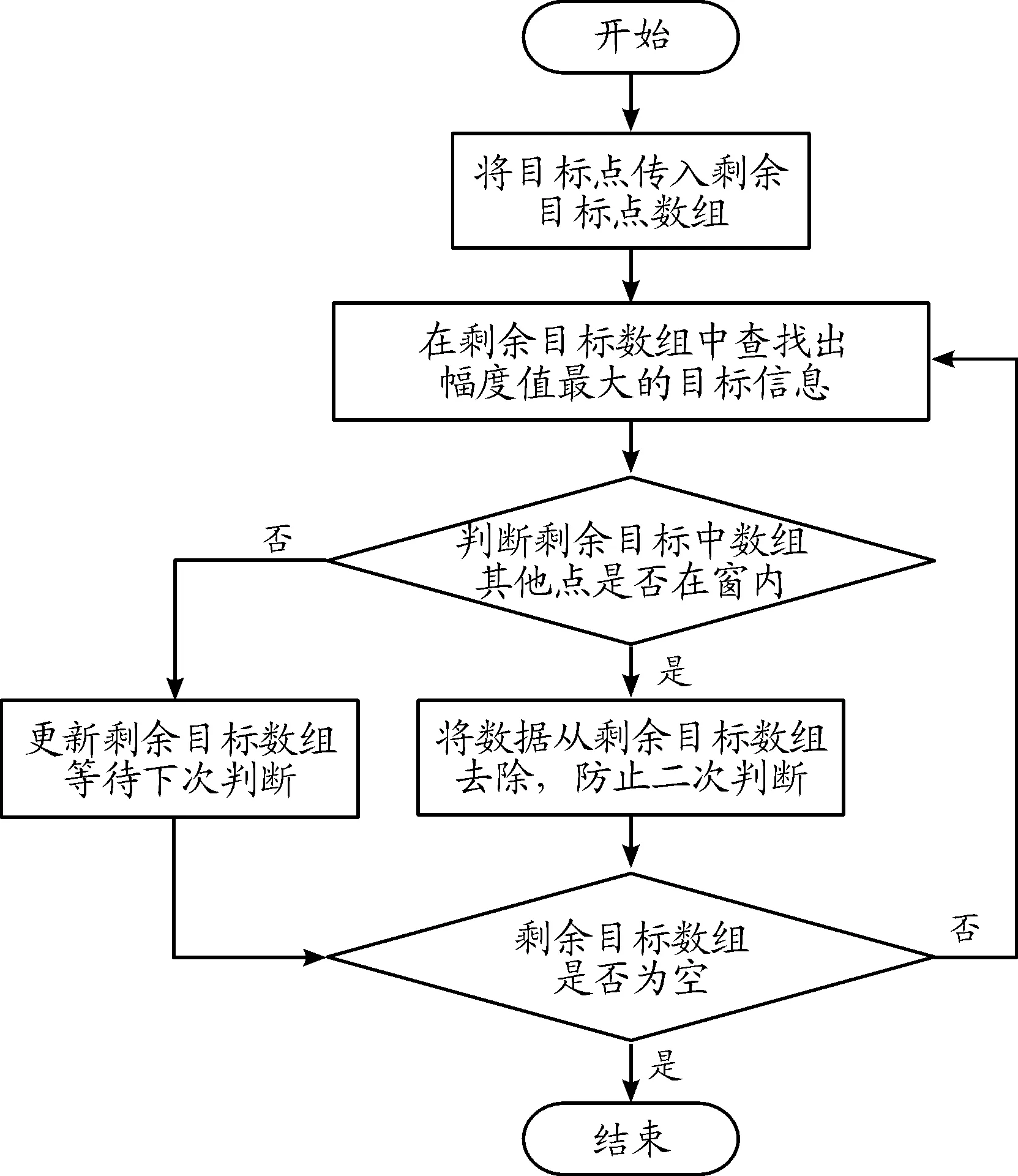


3 使用預(yù)排序優(yōu)化算法的實(shí)現(xiàn)
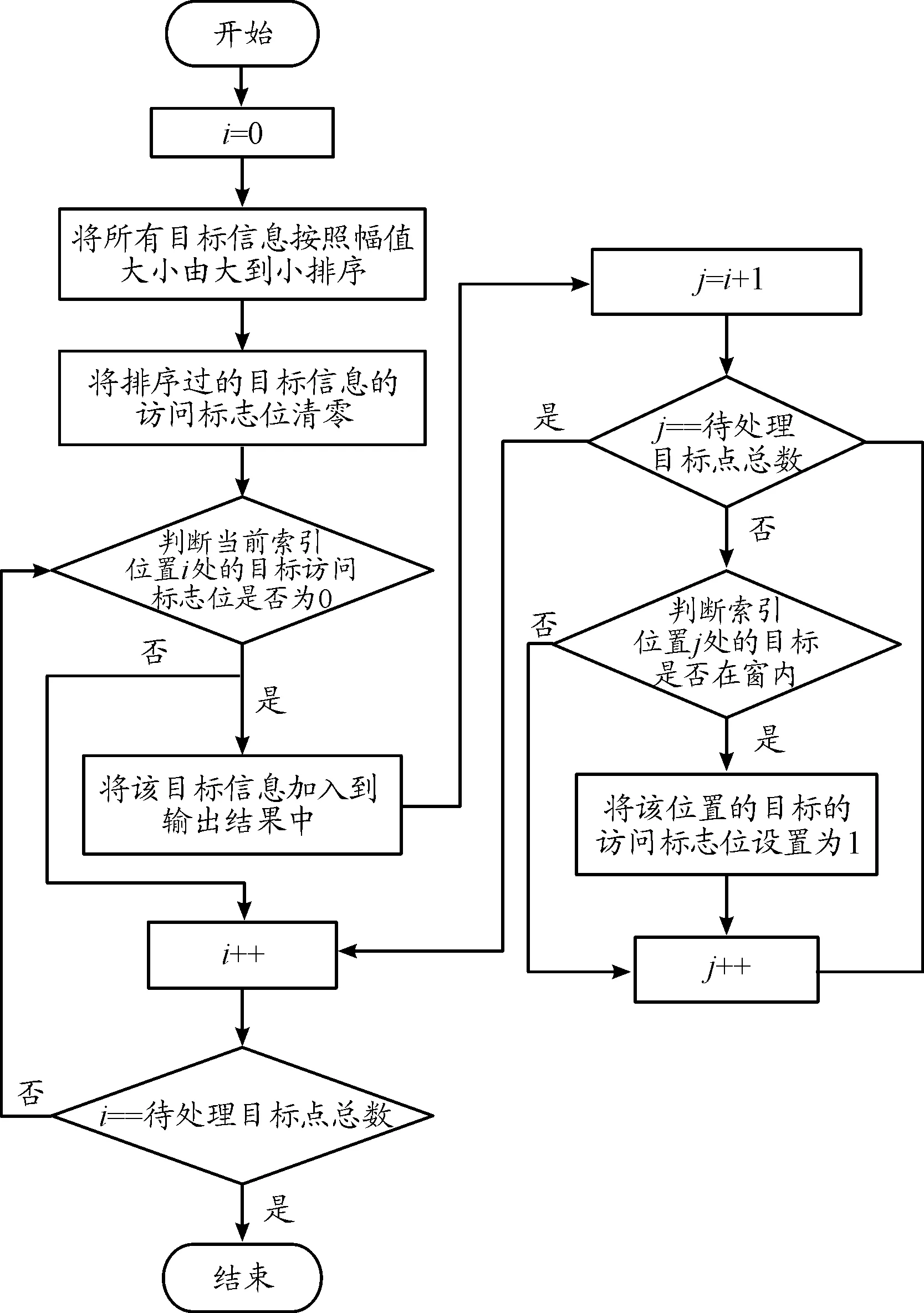

4 HashMap優(yōu)化算法實(shí)現(xiàn)

5 多線程優(yōu)化算法的實(shí)現(xiàn)
6 各案執(zhí)行情況


7 結(jié)論
猜你喜歡
兒童時(shí)代·幸福寶寶(2022年12期)2022-12-09 11:24:14房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2022年11期)2022-02-14 07:14:12建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年12期)2021-03-08 01:28:50科普童話·學(xué)霸日記(2020年1期)2020-05-08 16:45:11小天使·一年級(jí)語(yǔ)數(shù)英綜合(2019年2期)2019-01-10 11:57:30兒童繪本(2018年5期)2018-04-12 16:45:32
