流式大數據數據清洗系統設計與實現
2021-10-08 00:46:07于起超韓旭馬丹璇羅登昌
計算機時代 2021年9期
關鍵詞:大數據
于起超 韓旭 馬丹璇 羅登昌
摘? 要: 為了解決傳統數據清洗工具面對海量數據時復雜度高、效率低的問題,設計實現了流式大數據數據清洗系統。利用分布式計算技術清洗數據,以解決性能低的問題。該系統由統一接入模塊、計算集群和調度中心三部分組成,實現了多種數據源的統一接入,分布式處理,并通過Web界面進行清洗流程的交互式配置。實驗結果表明,面對海量數據的時候,流式大數據數據清洗系統的性能強于傳統的單機數據清洗,提高了清洗效率。
關鍵詞: 數據清洗; 大數據; 流式; 分布式架構
中圖分類號:TP311? ? ? ? ? 文獻標識碼:A? ? 文章編號:1006-8228(2021)09-01-04
Abstract: A streaming big data ETL system was designed and implemented so that the problem of high complexity and low efficiency of traditional ETL tools in the face of big data can be resolved. The system uses distributed computing technology to clean the data to solve the problem of low performance. The system consists of the unified access module, computing cluster and dispatching center. It realizes the unified access of multiple data sources and distributed processing, and the interactive configuration of cleaning process through web interface. The experiment results show that in the face of big data, the performance of the streaming big data ETL system is better than the traditional single machine ETL ones, which improves the cleaning efficiency.
Key words: ETL; big data; streaming; distributed architecture
0 引言
大數據的來臨改變了很多傳統工作方式,其中就包括ETL。ETL即數據抽取(Extract)、轉換(Transform)、清洗(Cleaning)、裝載(Loading)的過程,是數據倉庫建設的重要環節,負責整個數據倉庫的調度[1]。其效率的高低和清洗數據質量的高低,直接決定數據倉庫建設和決策的正確性。傳統的數據清洗框架有如下幾個問題。
⑴ 數據清洗性能低
傳統的數據清洗方式處理的數據量往往很小。在大數據時代數據量很可能每天成TB級別增加,加上有些清洗算法消耗很高的計算能力,導致傳統的數據清洗方法異常緩慢,甚至很難正常運行[2]。
⑵ 數據源多樣性
大數據的多樣性導致數據源的復雜多樣[3]。數據倉庫的數據往往來源于許多不同的系統,每個系統又包含多個模塊,每個模塊又包含單獨的數據源。從數據結構來看,不僅包括結構化數據還包括各種復雜的半結構化數據[4],這不僅提高了ETL程序的復雜性,也加大了維護的難度[5]。
針對現有數據清洗面臨的問題文中提出了流式大數據數據清洗系統,系統采用Kafka做中間件將接入數據與處理數據進行解耦[6],在一定程度上解決了傳統數據清洗框架普遍存在的問題。
1 系統設計
1.1 系統總體架構設計
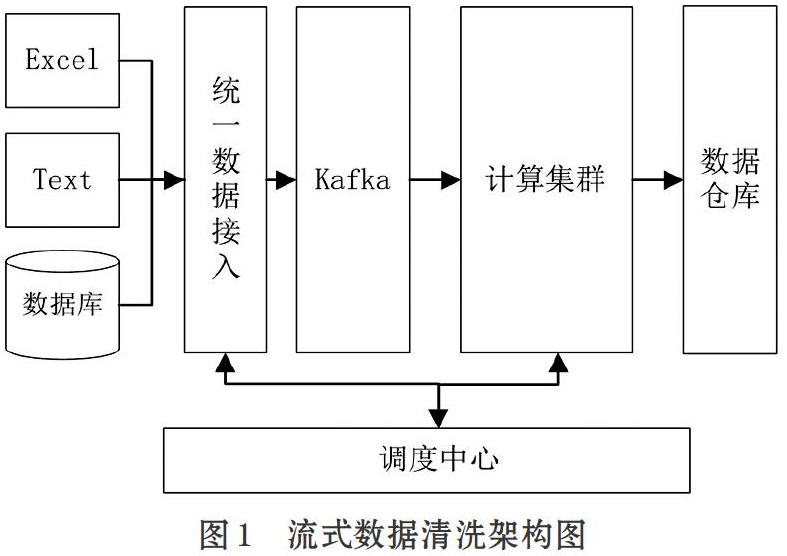
流式數據清洗架構如圖1所示。系統涉及多種數據源,包括Excel、監測日志、關系型數據庫等。數據源通過統一數據接入模塊進行統一封裝后推送入分布式消息隊列Kafka中。計算集群消費數據并執行清洗操作,最終將清洗后的結果輸出到數據倉庫中。
這種架構主要有以下優勢:①將不同類型數據都轉換成流的形式,使不同數據在形式上進行統一。清洗數據的計算節點只需關心具體數據不需要處理數據來源問題。②清洗數據采用并行分布式方式處理,提高了數據清洗的性能。計算節點可以根據實際負載情況進行擴展,具有很強的擴展性。③交互式的調度中心可以根據需求對清洗流程進行可視化配置,降低了數據清洗的復雜度。
1.2 統一數據接入模塊設計
1.2.1 統一數據接入架構設計
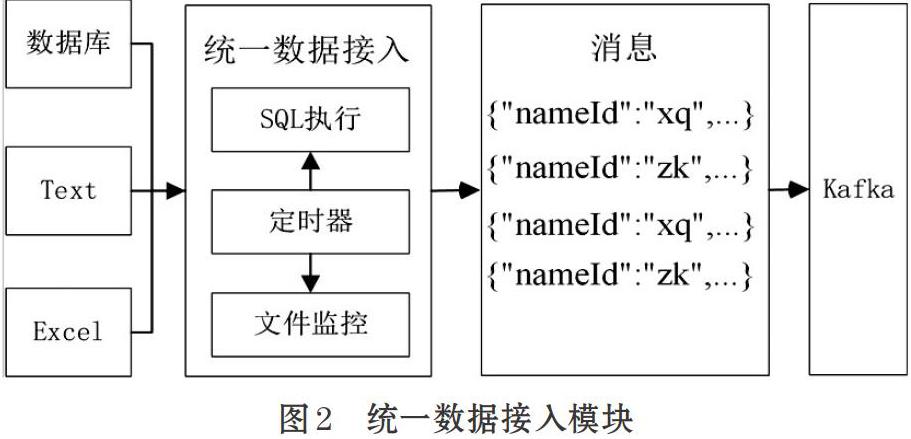
如圖2為統一數據接入的架構圖,統一數據接入模塊主要包括定時器,文件監控,SQL執行三大子模塊。
⑴ 定時器
定時器模塊為文件監控模塊和SQL執行模塊提供定時功能,通過定時來控制數據的采集速率。用戶通過界面配置定時,可針對于每一種數據源定制執行周期。
⑵ 文件監控
文件監控模塊是針對于日志文件的采集而設計的模塊。當監控的文件夾內有文件增加時,文件監控模塊讀取新增文件,將文件按照約定的解析規則進行解析,生成規定的統一數據協議并推送kafka中。
⑶ SQL執行
SQL執行模塊實現對Mysql,Oracle,SQL Server等關系型數據庫的采集。SQL執行模塊定時從數據庫中讀取一批次的數據,并轉化為統一數據協議推送Kafka中。
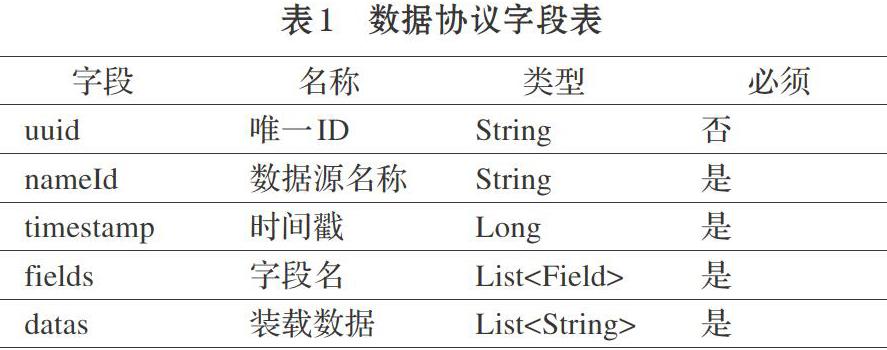
1.2.2 統一數據協議設計
統一數據協議如表1所示。主要有以下幾個字段。uuid為動態生成的每條數據的唯一id,nameId為數據源的唯一id,timestamp為生產這條數據的時間。fields為一個字符串數組,存放關系型數據庫的字段名稱或者Excel的列名。dates存放具體的數據值。
1.3 計算集群模塊設計
計算集群由多個計算節點組成,計算節點架構圖如圖3所示。
⑴ 接口
接口模塊用于和調度中心模塊和統一數據接入模塊進行通信,包括數據源配置接口、集群管理接口、流程調度接口等接口。接口模塊采用RPC接口協議,RPC協議即Remote Produce Call遠程過程調用協議,是一個計算機通信協議。該協議允許運行于一臺計算機的程序調用另一臺計算機的子程序,而程序員無需額外地為這個交互作用編程。RPC基于高效的二進制傳輸,與HTTP協議相比,字節大小和序列化耗時更低。
⑵ 同步器
同步器模塊用來與數據庫中調度作業進行同步。該模塊保存作業運行的實時狀態,并在作業重啟后讀取作業最后運行狀態,從而保證清洗作業的正確運行。
⑶ 元數據
元數據模塊保存數據源數據結構的信息,緩存清洗數據的字典碼表信息。
⑷ 流程解析器
流程解析器模塊通過接口模塊讀取作業清洗流程的配置信息,并將配置信息解析成數據清洗對應的有向無環圖。
⑸ 算子執行器
算子執行器讀取配置的清洗參數,并調用算子中的清洗方法進行清洗。算子執行器無需關心具體的清洗流程,只需關注于算子中的清洗方法,使得數據清洗具有可擴展性。
1.4 調度中心模塊設計
調度中心模塊作為系統用戶交互的窗口,為用戶提供可視化的清洗流程配置界面,方便各種復雜清洗里的配置。調度中心模塊有數據源管理、集群配置、算子管理、清洗字典管理、清洗流程管理等功能模塊,如圖4所示。
⑴ 數據源管理
數據源管理模塊針對不同的數據源提供統一的配置管理功能。該模塊對數據源提供接入規則,主要包括定時周期、監控文件夾、抽取SQL語句、統一數據協議等,并與統一數據接入模塊進行交互,控制統一數據接入模塊的啟動與停止。
⑵ 集群管理
集群管理模塊對統一接入模塊集群和計算集群提供管理和監控功能,如監控集群的上線和下線、監控集群資源的利用情況、監控清洗作業執行情況并對錯誤作業提供預警功能。
⑶ 算子管理
算子管理模塊提供對計算算子進行統一管理功能。計算算子分為計算算子和輸出算子。計算算子用于數據清洗,輸出算子用于清洗結果的輸出。常用的輸出算子有Elasticsearch輸出算子、Hive輸出算子、數據庫輸出算子、Kafka輸出算子等。在添加算子的時候需要配置算子的執行函數、算子描述、參數名、參數類型等。
⑷ 清洗算子字典管理
清洗算子字典管理模塊針對于字典替換算子而設計的。該模塊提供字典配置功能,并將映射關系緩存Redis中。字典替換算子讀取Redis緩存,并作字典映射處理。
⑸ 清洗流程管理
清洗流程管理模塊為用戶提供交互式的清洗流程配置功能。用戶通過Web界面,在畫布上拖拽清洗算子,配置每一個清洗算子對應的清洗參數,并按照清洗規則進行連線,形成一個由起點到輸出的流程圖。這種可視化的配置方式,給用戶提供了直觀的清理流程控制,降低了數據清洗的復雜度。
2 系統實現
2.1 計算節點數據清洗的實現
計算節點的清洗流程如圖5所示。計算節點主動從Kafka拉取消息,并獲取消息中的nameId,判斷nameId是否存在清洗規則庫,若清洗規則庫不存在則跳過清洗流程,若存在則進行清洗環節。計算節點從調度中心臨時庫獲取對應的清洗流程圖,并遍歷流程圖中的每一個算子。算子利用JAVA的反射原理調用清洗算子中的清洗函數執行清洗工作。
2.2 計算算子的實現
計算算子將清洗規則進行封裝形成一個完整的可控的工具類,主要包括數據驗證,數據轉換,數據去重,缺失插值等[7]。
本文計算算子的設計參考了Hive的UDF的設計理論,UDF(User Defined Function)提供了一種接口,可以對流中的每一條消息進行相應的處理[8]。算子類繼承接口UDF,并實現接口evaluate的函數,evaluate函數有兩個參數一個是從流中獲取的一條消息protocol,args是從調度中心獲取的自定義參數。
3 實驗分析對比
3.1 實驗環境
為了對比傳統方式和基于流式計算分布式清洗框架數據清洗的性能,本實驗采用三臺服務器來部署計算集群,用一臺服務器部署傳統清洗方式Kettle。具體的配置如表2所示。
實驗數據來自與地質的險情日志數據,現采用100萬、300萬、500萬與800萬條日志數據進行實驗測試。測試計算算子有字典替換算子,輸出算子是Elasticsearch批量輸出算子。
3.2 實驗結果
如圖6所示為傳統Kettle單機方式和分布式數據清洗方式所用時間的折線圖。通過折線圖可以看出,隨著數據量增加,分布式方式斜率變緩,且所用時間明顯小于Kettle的傳統方式。
4 結束語
隨著大數據技術的不斷發展,數據清洗在異構數據集成和數據倉庫等領域的研究與應用越來越引起人們的重視[9]。但由于數據的復雜性,數據清洗具有很大的難度[10]。本文從數據清洗的概念出發,分析了大數據背景下數據清洗所面臨的困難與問題。提出了一種基于流式計算的數據清洗框架,并對框架架構和各個模塊進行剖析,并通過實驗對比分析,證明了系統在運行效率有良好的表現。可以看出系統具有很強的擴展性,通用性,大大簡化了數據清洗的操作流程,具有一定的實際價值[11]。此框架待完善的方面有:①數據流程圖目前只能支持簡單的流程配置,更為復雜的流程還未適配到調度中心。②算子的擴展性有待提高,目前支持的算子有限。③支持的數據源有限,目前只支持三種數據類型,未來可增加更多的數據種類。④計算集群計算能力有待提高,未來可將計算集群移植到Spark,Hadoop等并行計算框架上[12]。
參考文獻(References):
[1] 劉佳俊,喻鋼,胡珉.面向城市基礎設施智慧管養的大數據智能融合方法[J].計算機應用,2017.37(10):2983-2990
[2] 何剛.基于Hadoop平臺的分布式ETL研究與實現[D].東華大學,2014.
[3] 黃毅,鐘碧良.基于XML的異構數據庫間數據遷移的研究[J].科技管理研究,2008.28(8):173-174
[4] 劉華,胡燕,王濤.Web數據清洗研究[J].軟件導刊,2007.3:75-77
[5] 葉舟,王東.基于規則引擎的數據清洗[J].計算機工程,2006.32(23):52-54
[6] Garg N.Learning Apache Kafka-Second Edition[J].2015.
[7] Kandel S, Heer J, Plaisant C, et al. Research directions in data wrangling:visualizations and transformations for usable and credible data[J]. Information Visualization,2016.10(4):271-288
[8] 范會麗,彭寧,任薇.基于Hadoop平臺的數據清洗研究[J].電腦知識與技術,2020.16(5):33-34
[9] 李垚周,李光明.分布式數據清洗系統設計[J].網絡安全技術與應用,2020.2.
[10] Rahm E, Do Honghai. Data Cleaning: Problems and? Current Approaches[J].Data Engineering,2000.23(4).
[11] 王銘軍,潘巧明,劉真,et al.可視數據清洗綜述[J]. 中國圖象圖形學報,2015.20(4):468-482
[12] Li X, Mao Y. Real-Time data ETL framework for big real-time data analysis[C]//IEEE International Conference on Information & Automation.IEEE,2015.10.
猜你喜歡
中國市場(2016年36期)2016-10-19 04:41:16
中國市場(2016年36期)2016-10-19 03:31:48
中國市場(2016年35期)2016-10-19 01:30:59
商(2016年27期)2016-10-17 06:26:00
今傳媒(2016年9期)2016-10-15 23:35:12
今傳媒(2016年9期)2016-10-15 22:09:11
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
