基于改進EAST的場景文本檢測算法*
2021-10-08 13:55:08李玥束鑫常鋒
計算機與數字工程 2021年9期
李玥束 鑫常鋒
(江蘇科技大學計算機學院 鎮江 212003)
1 引言
自然場景圖像中的文本包含著重要的信息,對圖片中的文字進行檢測可以幫助人們理解不同的場景環境。如交通標志上的文字信息能夠為司機提供更加準確的路況信息;商品包裝上的文字信息能夠準確認識商品的種類和生產日期。但某些自然場景中的字符具有方向傾斜、字體模糊等問題,快速準確地在復雜背景中檢測文字仍面臨著巨大的挑戰。因此,國內外學者通過大量的實驗和研究,提出了許多自然場景文本檢測方法。
傳統的場景文字檢測方法主要依靠手工設計特征。Epshtein等[1]利用筆畫寬度變換(Stroke Width Transform,SWT)提取文本邊緣像素,得到候選文本區域;Neumann等[2]通過最大穩定極值區域(Maximally Stable Extremal Region,MSER)算法搜索候選字符特征,然后根據自定義規則或分類器將提取的特征組合成單詞或者文字區域。這兩種方法效率相對較高,但在光照不均勻的情況下表現力較差。Louloudis等[3]利用文本行之間上下邊緣平行或對稱的性質,實現了對文本候選框的有效檢測。Meng等[4]提出了一種通過邊緣融合和邊緣分類兩個步驟提取自然場景文本的方法,通過邊緣檢測算法分割圖像,然后合并有相似筆劃寬度和顏色的邊緣,準確率較高。但這些方法在精度和適應性方面都落后于近年來出現的深度神經網絡方法[5~7],特別是在處理低分辨率、幾何失真等具有挑戰性的場景時,圖片中的文本被復雜背景干擾,加大了文字檢測的難度。
基于深度學習框架的自然場景文本檢測方法大致分為三類[8~10]:第一類是基于局部文字的方法,第二類是基于單詞的方法,第三類是基于文本行的方法。Huang等[11]首先通過MSER算法找出候選字符,然后利用深度神經網絡算法作為分類器篩選出最終文本行。Jaderberg等[12]借助滑動窗口掃描圖像,并使用卷積神經網絡模型生成多尺度特征圖。Tian等[13]提出了一個創新性的模型——CTPN,通過結合CNN和RNN深度網絡提取特征,增強了文本行之間的聯系,提高了檢測精度,但是只能檢測水平方向的文本。由于普通卷積神經網絡的感受野范圍是有限的,直接檢測較長的文本行具有較大的挑戰性,所以Shi和Bai等提出了SegLink[14]文字檢測算法。該方法首先檢測單詞或者文本行的局部區域,然后將這些局部區域連接起來形成完整的單詞或文本行。雖然大多數方法都能夠準確地檢測到文本,但后續的處理方法復雜而緩慢,并且對感受野較長的文本效果不是很好。
本文針對以上問題,以現有的文字檢測算法EAST[15]為基礎,對其存在的不足進行分析與改進,設計了一種端到端的網絡模型,采用Resnet50[16]作為提取圖像特征的基礎網絡,改進了網絡結構,加入LSTM方法,增強了文本特征之間的聯系,優化了原始EAST的訓練方式,改進了文本檢測算法的性能。
2 算法流程
本節詳細介紹了本文算法的執行流程。1)標記出輸入圖像的文本位置坐標和文本內容并存儲在文件中,接著對圖像的大小進行隨機剪裁,去除部分與文本區域無關的位置;2)將圖像輸入以Resnet50為基礎網絡的EAST模型中,通過卷積提取出圖像文本特征,并使用特征金字塔結構(Feature Pyramid Network,FPN)融合多尺度的特征圖;3)輸出圖像中文本區域可能出現的位置和分數,用四邊形標注出候選框,并采用非極大值抑制(Non-Maximum Suppression,NMS)算法對候選文本框分數進行排序篩選,從而得到最終的文本候選框。文本檢測的總體框架如圖1所示。
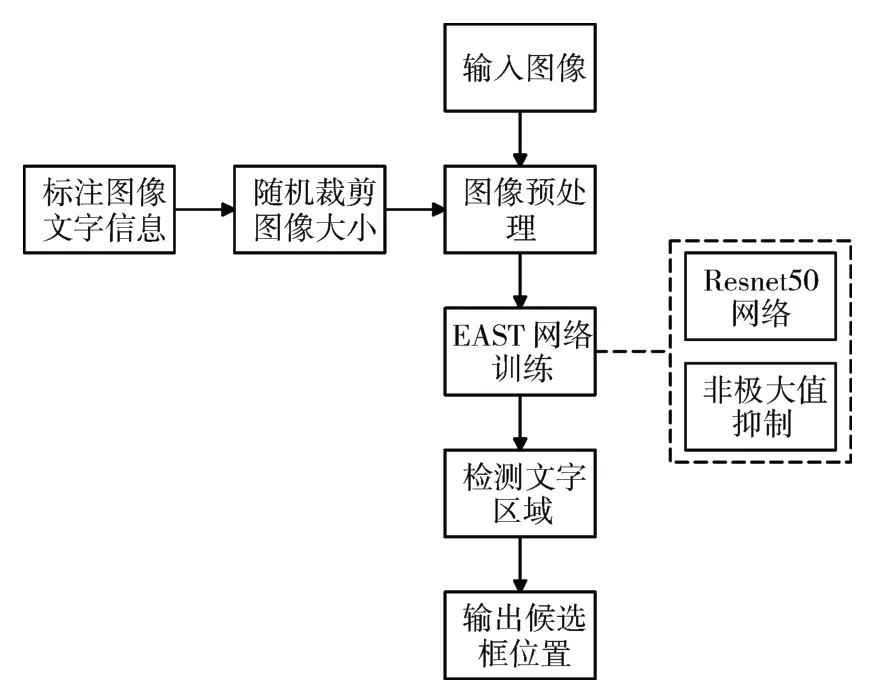
圖1 文字檢測框架圖
3 基于改進EAST模型的文字檢測
3.1 EAST算法介紹
傳統的文本檢測方法大多步驟較多,訓練時間較長,并且需要對多個參數調優,這勢必會影響最終的文字檢測效果,而且非常耗時。EAST網絡結構是一種高效準確的場景文字檢測模型,該模型可以直接預測圖像中任意方向的文本,省去了不必要的中間步驟,能實時處理自然場景中的圖片,達到較好的檢測效果。但同時它也存在著一些缺點,對于較長的文本,文字候選框定位會不完整。尤其是在中文場景中,EAST算法對連續出現的長文本進行檢測時就會丟失文本行的兩端,而不能完整地檢測出文本行,如圖2所示。

圖2 EAST算法對長文檢測效果圖
3.2 改進的EAST網絡模型
為提高EAST算法對長文本的檢測精度,本文對其網絡結構進行了改進,使感受野增大,能夠準確檢測出長文本。整個過程包括特征提取、特征融合以及生成分數特征圖score map和幾何特征圖RBOX。網絡結構圖如圖3所示。
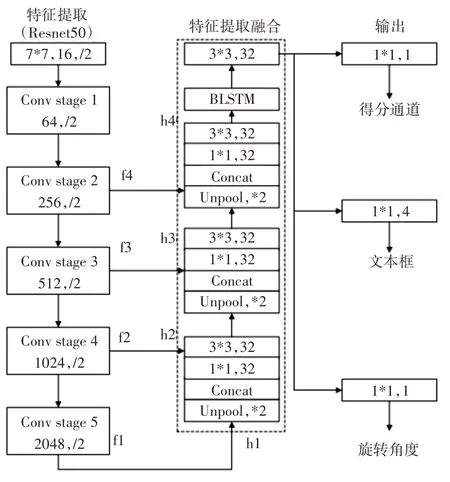
圖3 改進的EAST網絡結構
1)特征提取層
在特征提取層,首先對輸入的圖片進行文本信息標注和隨機裁剪大小。當文本區域較稀疏時,EAST模型可以很好地裁剪,并且保證文本行不會被切斷。但是當文本行較長且密集時,EAST模型的裁剪區域只能保留部分文本,為了確保不切斷文本區域,將忽略部分長文本。本文改進的EAST模型放寬了篩選條件,即可以切斷文本區域。首先確定要裁剪的區域,然后對落在該范圍內的文本區域進行采樣篩選,保留有兩個采樣點落在裁剪范圍內的文本區域,這樣就可以保留大部分長文本。使用Resnet50網絡結構提取圖像特征,提取的特征圖的大小分別為輸入圖像的1/32,1/16,1/8,1/4。
2)特征融合層
在特征融合層,首先融合提取到的文字圖像特征信息,融合公式如下:
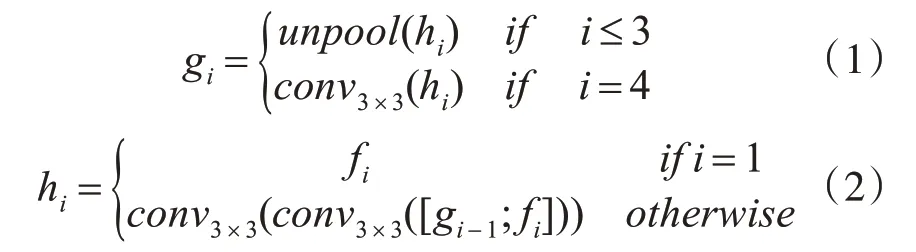
其中gi表示待融合特征量,hi表示融合后的特征圖,運算符[;]表示沿著通道軸線連接。
原始EAST網絡模型最后一個特征映射通過上采樣操作來增加感受野大小,雖然獲得了更多的圖像信息,但也增加了類之間的重疊,且易生成一些無效樣本,并且卷積網絡學習的只是感受野的空間信息。因為文字序列是連續的,而長短時記憶LSTM方法可以增強特征序列的關聯性,利用上下文信息篩除重復或無效的樣本信息,提高模型的學習能力。因此改進的EAST模型在融合階段加入了雙向長短時記憶(BLSTM)方法,即將兩個方向相反的LSTM相連。首先對模型最后一階段的特征圖進行上采樣操作,然后為了減小計算量,使用1×1和3×3的卷積核對特征圖進行卷積,接著與當前特征圖連接合并,最后將特征序列輸入到一個雙向的LSTM中,所以最終的特征層將輸出更多更大尺寸的感受野,保留了更多的文本特征信息,使得檢測結果更具魯棒性。
3)輸出層
輸出層包含文本得分、文本框和旋轉角度θ。
3.3 損失函數
損失函數是用來對網絡模型進行優化的代價函數。函數值越小,模型性能就越優越。所以本文算法的總損失函數公式如下所示:

其中Ls為文本框的得分損失,Lg為幾何圖的損失。λg表示損失權重。在實驗中設置λg為1。
為了簡化訓練過程,本文使用類平衡交叉熵[17]來計算得分通道損失,公式如下:
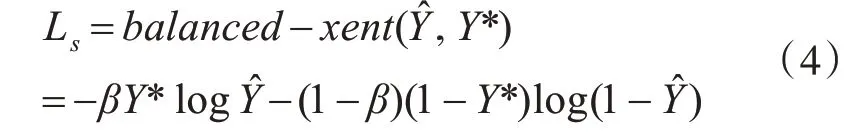
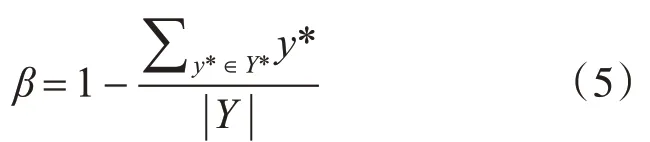
自然場景圖像中的文本大小差別很大,使用L1或L2損失函數會丟失一些長文本區域,從而影響最終結果。因此,本文的文本框回歸采用IOU損失函數[18],公式如下:
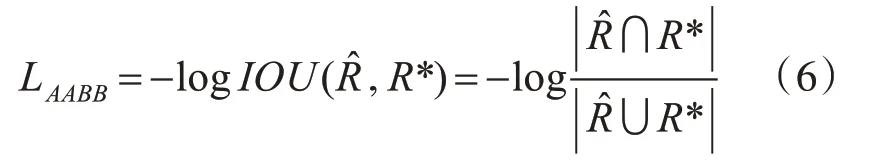
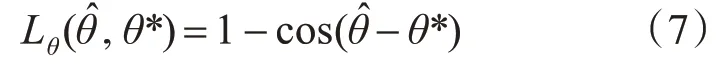
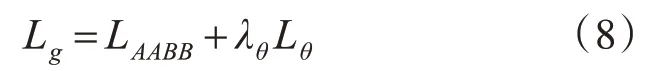
3.4 訓練參數設置
本文使用Adam優化算法在Ubuntu系統上進行訓練和測試。使用的顯卡為NVIDIA GTX 1080 Ti,內存為8G,深度學習框架是Tensorflow。針對短文本檢測效果較好,長文本部分檢測不到的情況,改進的EAST算法對訓練圖像進行旋轉操作,并調整圖像尺寸大小為256*256、384*384和512*512,先在小圖像訓練,再將模型遷移到大圖像;訓練批尺寸為24;初始學習率為1e-3,到1e-5停止。
4 實驗結果與分析
為了評估該算法的性能,將所提出的算法與當前先進的檢測模型進行了比較,測試數據為ICDAR2013[19]和ICDAR2015[20]。ICDAR 2013數據集共包含462張水平方向的文本圖像,其中訓練圖像229張,測試圖像233張。而ICDAR2015數據集比ICDAR2013數據集更豐富多樣,并且支持多方向文本檢測,包括1000張訓練圖像和500張測試圖像。本文分別從檢測率、準確率和召回率三個指標來分析算法的性能。實驗結果如表1、表2所示。
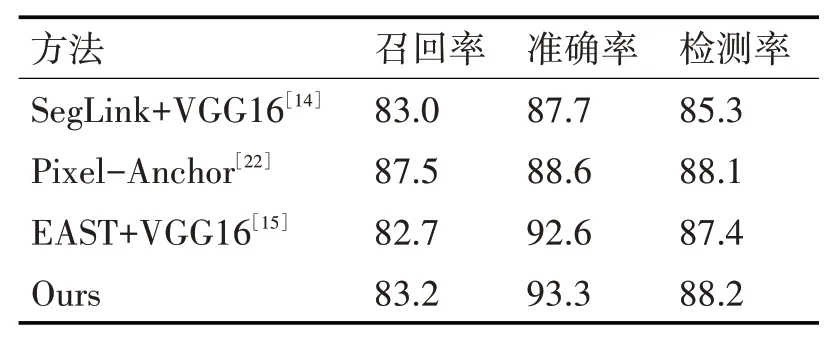
表1 ICDAR2013數據集檢測結果對比
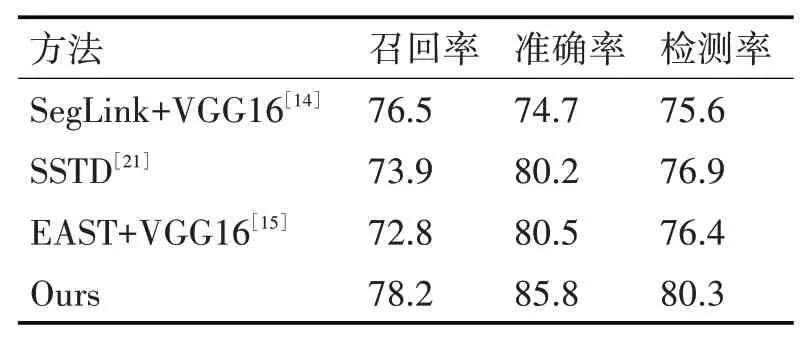
表2 ICDAR2015數據集檢測結果對比
如表1所示,本文算法在ICDAR2013數據集上的召回率、檢測率和準確率分別為83.2%、88.2%和93.3%,與SegLink[14]方法相比,本文算法的準確率提高了5.6%,檢測率提高了2.9%。與Pixel-Anchor[21]方法相比,本文算法雖然召回率降低了4.3%,但是準確率卻提高了4%以上,并且本文算法的檢測速度高于Pixel-Anchor方法,因為Pixel-Anchor方法采用八連通域,執行搜索次數要八次,在一定程度上影響了網絡的執行時間。與原始EAST算法相比,本文算法的召回率提升了0.5%,并且準確率和檢測率也提高了0.7%左右。
如表2所示,SegLink方法和SSTD[22]方法在ICDAR2015數據集中的檢測率分別達到75.6%和76.9%,而本文算法對于ICDAR2015數據集的準確率和檢測率均達到80%以上,明顯優于SegLink方法和SSTD方法。與原始EAST算法相比,本文算法的召回率增加了5.4%,準確率和檢測率都提高了5%左右。因為本文算法加入了LSTM方法,減慢了文字序列的執行速度,所以在執行速度上不如原始EAST算法,但是從其他各項指標值來看,本文算法性能更佳。
圖4是原始EAST模型和改進后EAST模型對長文本的檢測效果圖,其中,圖4(a)為原始EAST模型對應的檢測效果圖,圖4(b)為改進后的EAST模型對應的檢測效果圖。

圖4 檢測效果對比圖
由圖4(a)可以看到,對于圖片中的英文網址,原始EAST模型雖然也能夠完全檢測出英文字符,但是卻是用四個文本框標記出文本位置的,并且圖片中的中文字符也只能檢測出部分區域,如字跡較淺的“洪福電子”和字體較小且連續出現的“消費者保障”等區域。
由圖4(b)可以看到,改進后的EAST模型只需一個文本框就可以完整標記出英文文本的位置并且對于連續出現的中文字符也能夠標記出大部分區域,但是對于較小的、字跡模糊的中文區域表現力還有些不足。
5 結語
本文提出了一種基于改進EAST的自然場景文本檢測算法,采用Resnet50網絡提取圖像特征,并在EAST模型中加入了長短時記憶網絡LSTM,調整了訓練過程,改善了網絡感受野的尺寸,均衡了特征樣本,使算法能夠快速準確地檢測圖片中的文本。和經典EAST算法以及目前流行的檢測算法相比,精度和性能上都有了顯著的提升,但是對于長文本的檢測還有一些不足,有的區域并不能完整檢測出來。后續工作中我們將進一步優化網絡結構和參數,調整損失函數權重,并融合其他方法,使其能夠應對日常更復雜的場景環境。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
小學教學參考(2015年20期)2016-01-15 08:44:38
電測與儀表(2015年5期)2015-04-09 11:30:52
語文知識(2014年1期)2014-02-28 21:59:13
