基于注意力機制的深度神經網絡分割算法在胎盤圖像上的應用
2021-10-01 12:38:02高書陽
科海故事博覽 2021年20期
高書陽
(湖北方源東力電力科學研究有限公司,湖北 武漢 430000)
1 前言
在胎兒的醫療診斷過程中,準確地識別胎盤圖像中胎兒位置對評價胎兒和母親的健康狀況很重要。現有的方法主要是借助超聲波掃描儀獲得胎盤圖像,再由專業的超聲波圖像解析人員識別出胎兒位置并采集各項數據(例如:頭圍、腹部寬度等),由于解析人員的專業知識和長時間的識別疲勞,導致胎兒位置的識別結果在不同的觀察者那里會存在很大的差異;超聲波解析人員在采集各項數據時,主要使用卡尺作為測量工具,卡尺的放置位置會對測量結果產生很大的誤差。
傳統的圖像分割方法,包括閾值法、邊緣法和區域法等,這些都沒有考慮像素之間的相關性,分割的效果不理想。基于圖論的分割方法是將圖像中的每個像素點看成圖的頂點,像素點之間的關系看作圖的邊,像素之間的相關性看作邊的權值,建立一個關于邊的能量函數,通過最小化能量函數實現對圖像的分割;基于能量泛函的分割方法是利用類間方差或像素間梯度構造能量泛函,求解泛函極值時圖像的分割狀態。近年來,卷積神經網絡以其超強的特征提取能力被廣泛地應用于圖像檢測和分割領域。圖像分割主要分為語義分割和實例分割,語義分割是區分圖像中不同物體類的分割,它不需要區分圖像中某個物體類的不同個體,從早期的全卷積網絡(Fully Convolutional Networks,FCN)[1]、U-Net[2],發展到現在的金字塔場景分析網絡(Pyramid Scene Parsing Network,PSPNet)[3]、DeepLab[4]等,這些都是單階段直接預測掩碼。實例分割需要分清圖像中每個類的不同個體,代表性是Mask Rcnn[5]網絡,它的特點是需要在檢測出目標的基礎上對目標掩碼進行預測,能夠提高分割的精確性。而注意力機制方法,可以是網絡更關注感興趣區域,得模型能夠關注圖像中的重點信息。[6]
由于傳統方法無法區分目標與背景邊界的問題,同時考慮到胎盤圖像背景的復雜性,本文提出了一種基于注意機制的深度卷積神經網絡的圖像分割方法,可以有效的解決胎盤圖像分割問題。總的來說,本文主要貢獻點可以歸納如下:
1.本文采用先定位后分割的方法,構建類別預測和檢測框回歸模塊粗定位出目標的區域,在定位區域里進行胎盤分割,提升了分割精度,同時也降低了分割難度。
2.本文為了將關注點放在目標區域的有效位置,提出了基于注意力機制的掩碼預測分支細定位目標的位置,可以使網絡關注有效特征信息。
3.本文在公開的數據集上,進行大量實驗本文提出方法的有效性,并與當前主流的六種圖像分割方法進行對比,結果表明,無論在視覺感知還是三個量化指標上,均優于其他方法。
2 相關工作
2.1 與圖像分割網絡相關工作
2.1.1 FCN
FCN 主要由提取高層語義的下采樣層和預測掩碼的上采樣層組成。其基本結構如圖1 所示,輸入通過多層的卷積層和池化層下采樣得到通道數為256的卷積特征圖,再將該特征圖通過三個全連接層得到通道數為2的高層語義特征,最后將該特征通過多層的反卷積層上采樣得到預測的掩碼。其中,在下采樣的過程中,最后三層的特征圖將被保留并添加到上采樣層相對應的尺寸輸出中。
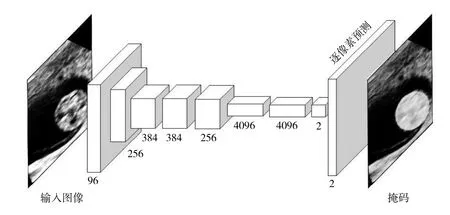
圖1 FCN 結構圖
2.1.2 U-Net
U-Net 一種U 型網絡,是一種編碼和解碼結構,考慮了不同分辨率的圖像特征,將圖像的高分辨率和低分辨率特征結合,編碼層是學習圖像的初級特征,解碼層是將圖像高層語義特征與初級相結合來還原細節信息,并且逐步還原圖像精度。
2.1.3 PSPNet
PSPNet 在FCN的基礎上加入了金字塔池化模塊,取出FCN 網絡下采樣過程中得到的高層語義特征圖F,將F 經過金字塔池化模塊中四種不同尺度的池化層下采樣得到{P1,P2,P3,P4},此下采樣方式考慮到了不同尺度的特征,減少了信息的丟失,再將P1 到P4 經過上采樣后得到的特征圖與F 合并,最后通過反卷積上采樣預測掩碼,結構圖見圖2。

圖2 PSPNet 結構圖
2.1.4 DeepLab
Deeplab 引入了空洞卷積,在傳統卷積的基礎上加入了卷積空洞,相同參數的條件下極大地提高了卷積的感受野。DeepLab 在特征池化時引入了空洞空間金字塔池(Atrous Spatial Pyramid Pooling,ASPP)[7]模塊,能夠在高層特征層中極大效率的利用圖像的全局特征。在主干特征提取網絡方面,DeepLab 采用了Xception 結構,它采用深度可分離卷積,能夠在網絡參數量保持基本不變的情況下帶來很好的特征提取效果。
2.2 與注意力機制相關工作
從注意力機制的可微分性來看,注意力機制大體可以分為軟注意力機制和硬注意力機制。
2.2.1 軟注意力機制
在圖像處理領域,軟注意力機制關注圖像的特征區域和特征通道,可以通過網絡的自身學習來生成,并添加到原始特征上,使得模型能夠關注圖像中的重點信息。由于它是可微分的,所以在神經網絡的學習過程中可以計算出梯度,并且前向傳播和反向傳播反饋來學習得到注意力的權重。
2.2.2 硬注意力機制
硬注意力機制更關注于圖像中的目標點或區域,它通過學習一個定位物體部分的網絡,通過神經網絡強大的學習能力首先定位出物體的大致位置,提取定位后的區域特征,再將該特征用于下一步的任務,如果該特征對整體任務有促進作用,該特征區域在后續的學習過程中將會被更加關注。
3 基于注意力機制的Mask RCNN 網絡
本文提出了基于注意機制的深度卷積神經網絡胎盤圖像分割方法,將注意力機制與Mask RCNN 結合,采用先定位后分割,使網絡更關注感興趣信息,能夠有效的提高分割的準確性(本文的總體網絡結構如圖3 所示)。
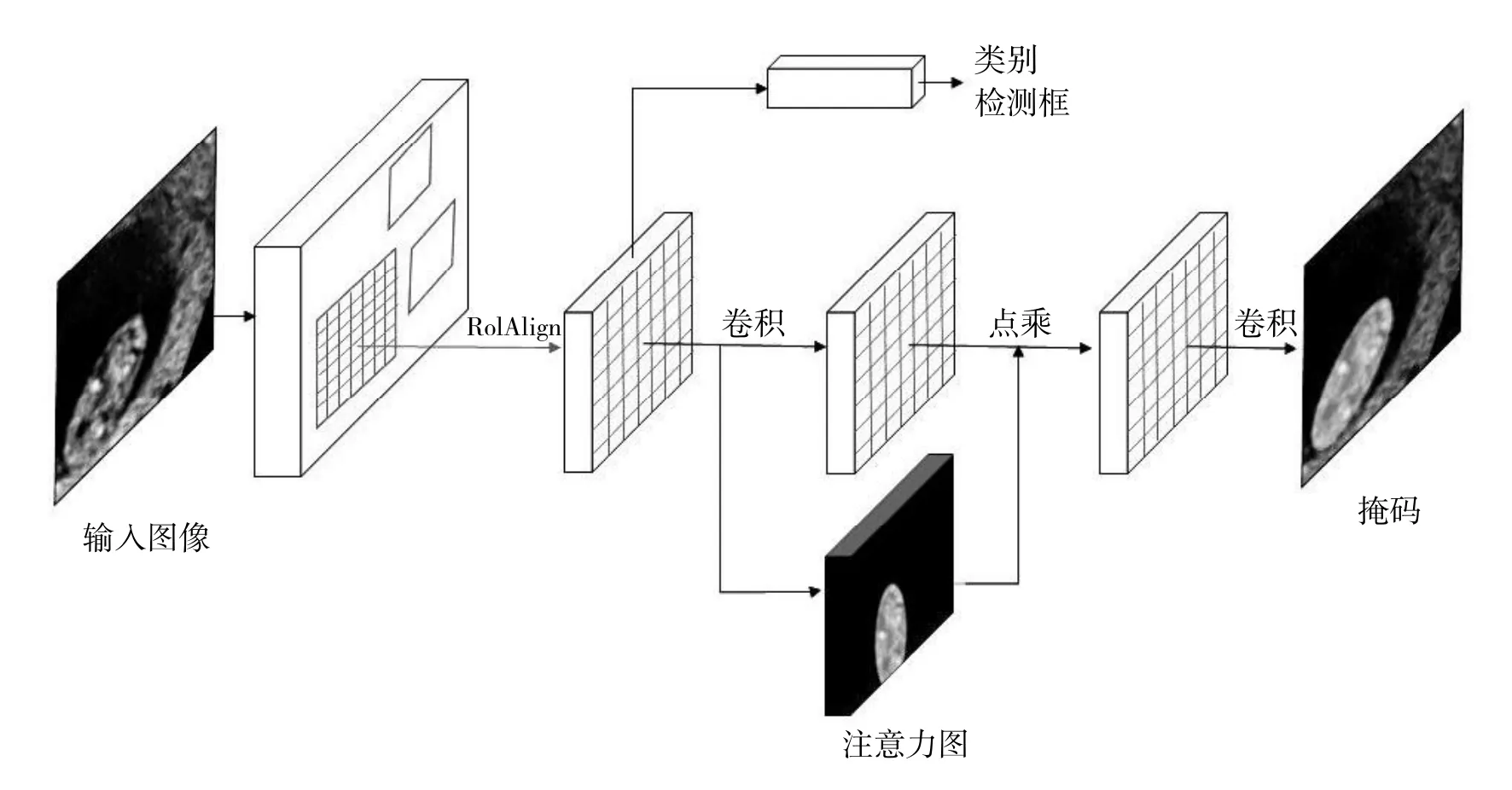
圖3 總體結構圖
3.1 Mask RCNN 網絡的構建
本文采用檢測定位加上分割的方法分割目標區域,首先檢測出目標的大體區域,然后在目標區域內分割目標。
3.1.1 檢測定位
取出ROIAlign 后的特征圖F1,經過全局平均池化后得到的特征向量F2 送入類別預測和檢測框回歸分支,其中:

Meank*k表示在k*k的區域內求平均,F1的每個通道求平均得到F2,輸出的維度是1*1*1024。
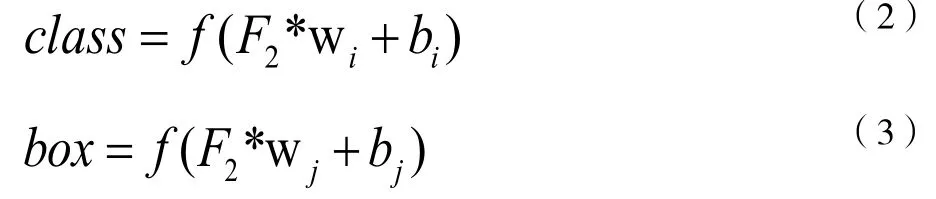
式中,wi和wj分別為類別預測分支和檢測框回歸分支到F2的連接權值,bi和bj為相對應的偏置。
3.1.2 目標分割
將ROIAlign 得到的特征圖F1經過若干個注意力機制模塊后得到F3,其中:

式中,Atten 表示若干個注意力機制模塊。
帶有注意力的特征圖F3經過反卷積上采樣得到預測的掩碼,反卷積的步長為2,其中:
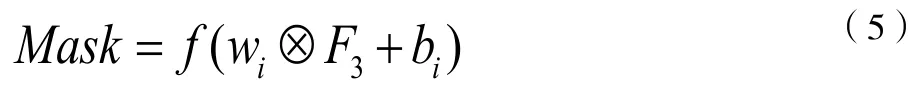
式中,?表示反卷積操作,f 為激活函數,wi 為第i 個卷積核,bi 表示偏置。
3.2 注意力機制
由于胎盤圖像具有重影、目標模糊的特點,且胎盤圖像中背景和其他物體會干擾胎兒目標的分割,因此,本文采用自注意力機制將模型的關注區域放在胎兒目標上,其結構如圖4 所示。
儒家追求盡心而成性,進而到達圣人之境,最終擁有理想的人格。“圣人”始終是儒家所求的理想人格的代稱,由此,儒家認可的理想人格最直接的標準就是圣人所代表的概念。而胡宏對此的理解,不僅對許多先賢大儒的眾多理論予以了承繼,而且還進行了積極的探究,進而使其提出的圣人理論極具個人特色。
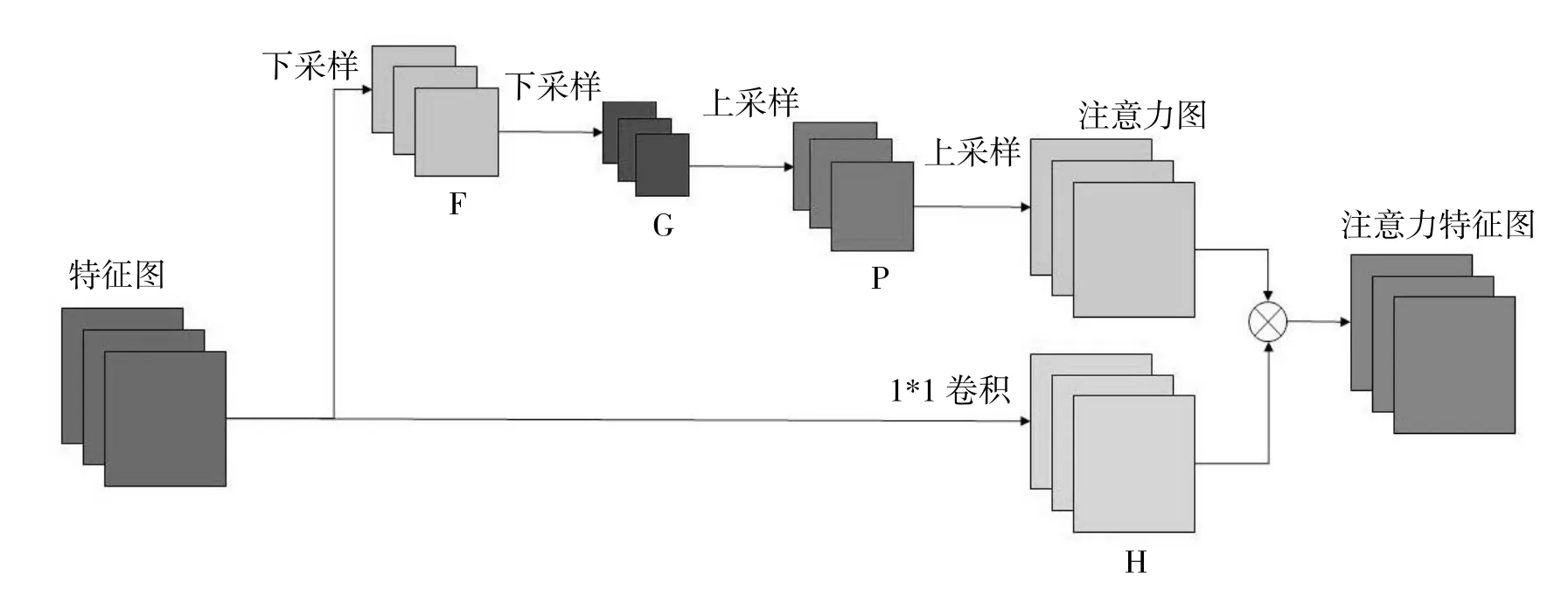
圖4 注意力機制結構圖
首先將輸入的特征圖F4經過一維卷積運算得到特征圖H,其中:
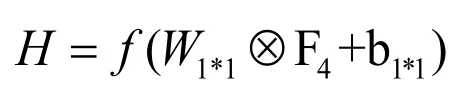
式中,?表示卷積操作,f 為激活函數,W1*1表示一維卷積核的權值,b1*1表示一維卷積核的偏置。
再將特征圖F4分別經過兩次下采樣(DS)和兩次上采樣(US)得到注意力圖,其中:
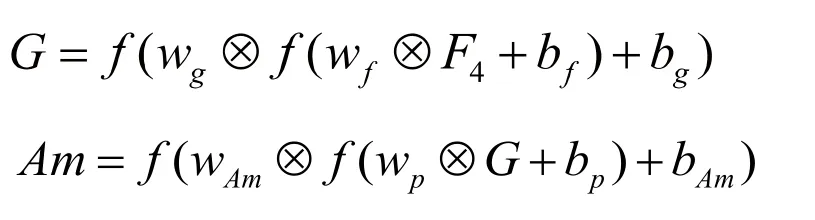
其 中,wk(k=f、g、p、Am)和bk(k=f、g、p、Am)分別表示生成特征圖F、G、P 和注意力圖時卷積核的權值和偏置。
最后將注意力圖和特征圖點乘得到帶有注意力機制的特征圖Afm,其中:
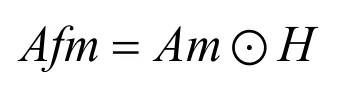
3.3 損失函數構建
本文采用先檢測定位后分割目標的方法,共有三個損失函數,分別是將背景和目標區分開的分類損失函數Lcls、回歸目標檢測框坐標的L2損失函數Lbox和預測目標掩碼的二值交叉熵損失函數Lmask,由于預測目標掩碼任務的難度最大,回歸目標檢測框坐標任務次之,本文構建式*所示的損失函數。
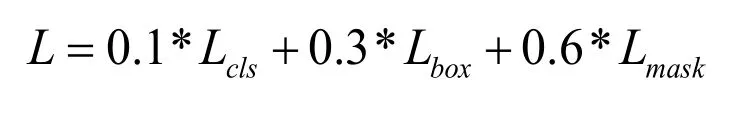
3.4 評價指標
本文選用三種評價指標,分別是Dice、BF scores 和Hausdorff,Dice的計算公式:
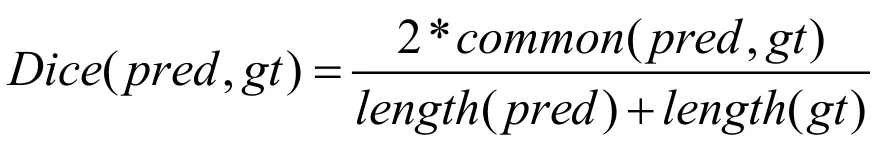
式中,pred和gt分別表示預測結果和標簽,common(pred,gt)表示預測結果和標簽的相同部分,length 表示計算長度。
BF scores的計算公式為:
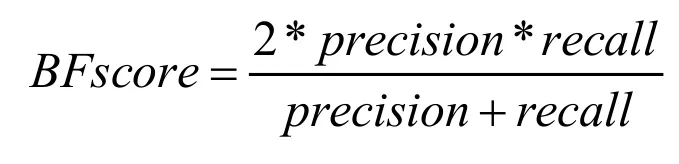
式中,precision 表示預測結果的精確度,recall 表示預測結果的召回率。
Hausdorff的計算公式為:
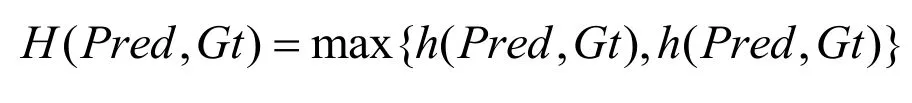
其中h(Pred,Gt)和h(Gt,Pred)分別表示Pred 到Gt 和Gt 到Pred的Hausdorff 距離,計算公式見式*和*:
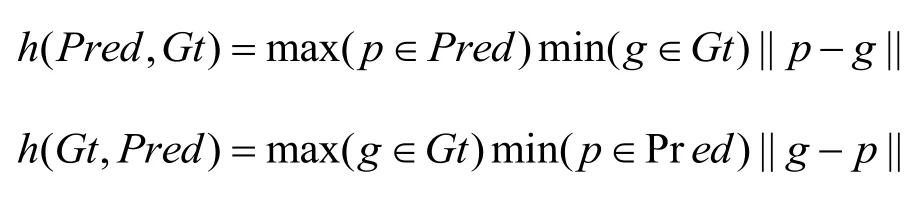
其中max(p ∈Pred)min(g ∈Gt)||p-g||表示取出Pred 中的每個點p,求出Gt 中距離點p 最近的點g,取所有||p-g||的最大值作為h(Pred,Gt),h(Gt,Pred)同理可得。
4 實驗結果與分析
4.1 數據集制作
本次實驗中,數據集來自https://hc18.grand-challenge.org 公開的胎盤數據集,該數據集一共有999 張圖像,每張圖像對應一張標簽圖像,標簽圖像的內容是一個形狀為橢圓的曲線,曲線部分為白色,其他部分為黑色。以1:9的比例將數據集劃分為899 張圖像的訓練集和100 張圖像的測試集。從100 張測試集圖像的實驗結果中隨機挑選出4組圖像,驗證本文提出方法的有效性。
4.2 實驗環境與訓練參數
本文實驗基于深度學習框架Tensorflow 在一臺NVIDIA GeForce GTXGTX1080Ti GPU的計算機上進行訓練和測試。
在訓練階段,采用大小為256×256的圖像的進行訓練,每次迭代輸入4 張圖像。網絡通過Adam 來更新網絡參數,RMSprop 具體參數為:權值超參數,初始學習速率設置為0.001,網絡每層卷積采用He K 均勻分布初始化方法,偏置為0,總訓練Epoch 為15,前10 個Epoch的學習率為10-4,后5 個Epoch的學習率為10-6。
4.3 實驗結果評估
為了衡量本文算法的性能,本文選取在測試集上實施了大量實驗,并與當前主流的六種圖像分割算法進行實驗對比,分別為PSPNet、DeeplabV3、DeeplabV3+、U-Net、注意力機制U-Net、Mask-Rcnn。同時采用三個量化指標來客觀定量的平均圖形分割結果。
視覺感知。為了更好衡量評估本文算法胎盤圖像分割的視覺效果,本文選取了四幅圖像來展示分割效果。
圖5 中:測試集隨機挑選出四組圖像的二值圖預測結果:(a)原始圖像、(b)標簽二值圖、(c)PSPNet、(d)DeeplabV3、(e)DeeplabV3+、(f)Unet、(g)Unetattention、(h)Maskrcnn、(i)Maskrcnn-attention。

圖5
圖6 中:測試集中隨機挑選出四組圖像及預測結果輪廓圖:(a)原始圖像、(b)標簽二值圖、(c)PSPNet、(d)DeeplabV3、(e)DeeplabV3+、(f)Unet、(g)Unet-attention、(h)Maskrcnn、(i)Maskrcnn-attention。
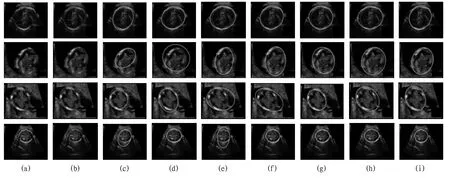
圖6
隨機從測試集中挑選出4 組圖像,從圖5 和6 可以看出,PSPNet的預測效果最差,DeeplabV3 和DeeplabV3+次之,Unet 和Unet-attention 對胎盤圖像具有良好的預測能力,加上Attention 機制的Mask rcnn的預測效果與掩碼標簽是最為接近的。
4.4 客觀定量指標
為了驗證模型的有效性,統計七種方法下,測試集上的Dice 系數、BF scores 和Hausdorff,如上表1 所示。

表1 七種方法下測試集Dice、BF scores 和Hausdorff的比較
Dice 系數越大表示預測結果和標簽之間的重疊部分占比越大,BF_scores 值越大,表示預測結果的輪廓與標簽之間越相似。
從測試集中隨機挑選出10 組圖像統計Dice、BF scores 和Hausdorff 指標(如圖7 所示),可以看出Mask rcnn-attention的分割結果具有最高的Dice、BF scores 和Hausdorff,能夠非常精確地對圖像中的目標進行分割。Unet-attention、Unet、Mask rcnn、DeeplabV3、DeeplabV3+和PSPNet 等方法的評價指標均沒有Mask rcnn-attention 高。
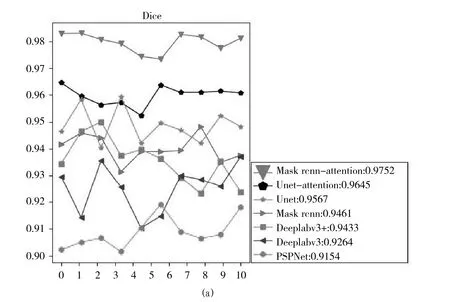
圖7
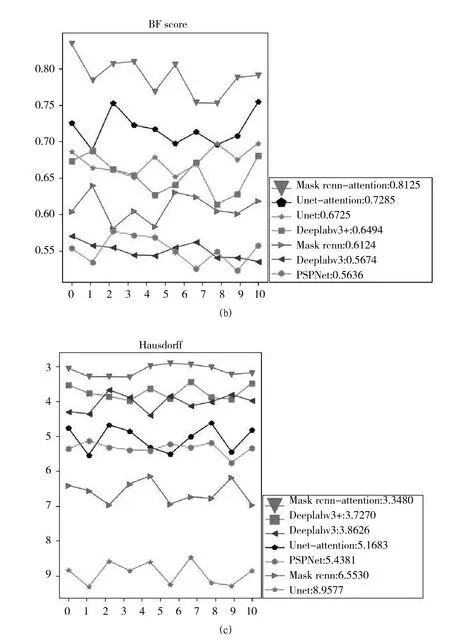
圖7
考慮到模型預測的時效性,本文將以上七種方法分別統計了單張圖像的模型推斷耗時,如上表2 所示。

表2 七種方法下單張圖像模型推斷耗時(T)的比較(單位:秒)
可以看出,Attention-MaskRcnn 由于模型更為復雜導致推斷耗時最長,但也是毫秒級別,整體而言影響不大。
5 結論
本文提出的基于注意力機制的深度卷積神經網絡包括兩個部分:(1)在深度神經網絡特征提取器后加上類別預測和檢測框回歸模塊,粗定位出目標的位置;(2)在粗定位的位置上加上帶有注意力機制的掩碼預測模塊預測掩碼。由于本方法是針對胎兒頭部位置的兩階段定位分割,與其他的單階段直接預測掩碼相比,本方法能夠更為精確的定位出胎兒頭部位置并預測掩碼。多組實驗結果均表明,本方法與其他分割性能優越的Unet、Unet-attention、DeeplabV3 和DeeplabV3+相比,分割效果整體更好。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
文苑(2018年21期)2018-11-09 01:23:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
中國衛生(2015年9期)2015-11-10 03:11:12
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中國衛生(2014年3期)2014-11-12 13:18:12
中國火炬(2014年4期)2014-07-24 14:22:19
