面向無人駕駛的井下行人檢測方法
2021-09-28 07:20:40劉備戰(zhàn)趙洪輝周李兵
工礦自動化 2021年9期
劉備戰(zhàn), 趙洪輝, 周李兵
(1.陜西陜煤榆北煤業(yè)公司, 陜西 榆林 719000;2.中煤科工集團常州研究院有限公司, 江蘇 常州 213015;3.天地(常州)自動化股份有限公司, 江蘇 常州 213015)
0 引言
煤礦井下巷道錯綜復雜且工作環(huán)境惡劣,將無人駕駛技術(shù)引入煤礦開采,實現(xiàn)礦用車輛自動化,有利于提高煤礦井下安全系數(shù)。行人檢測是煤礦井下無人駕駛的關(guān)鍵技術(shù),許多學者對此展開了研究。J. S. Dickens等[1]采用多信息融合技術(shù),結(jié)合3D傳感器和紅外成像傳感器實現(xiàn)了井下礦用車輛的行人檢測。董觀利等[2]先對圖像提取高斯模型前景,再對前景進行分類,可快速識別行人位置及越界方向。李偉山等[3]以深度學習通用目標檢測框架Faster RCNN(Faster Region-based Convolutional Neural Networks)為基礎(chǔ),對候選區(qū)域網(wǎng)絡結(jié)構(gòu)進行改進,采用3種不同尺度的卷積核來計算候選區(qū)域,提高了煤礦井下行人檢測的魯棒性。李現(xiàn)國等[4]對基于SSD(Single Shot MultiBox Detector)網(wǎng)絡的行人檢測方法進行改進:設(shè)計了一種基于DenseNet網(wǎng)絡的輕量級卷積神經(jīng)網(wǎng)絡作為SSD網(wǎng)絡的基礎(chǔ)網(wǎng)絡,以滿足井下視頻行人檢測實時性需求;同時設(shè)計了基于ResNet網(wǎng)絡的輔助網(wǎng)絡,提高了行人檢測準確性。魏力等[5]采用通道注意力機制,在增強圖像中人員前景特征信息的同時抑制背景信息,提高了在低分辨率、遮擋等影響下的目標判別能力。然而,受煤礦井下光照不均勻、背景復雜、紅外線干擾、光線昏暗和圖像中目標小且密集等影響,應用上述方法時檢測精度不理想。本文提出了一種面向無人駕駛的井下行人檢測方法。該方法通過融合可見光傳感器、紅外傳感器和深度傳感器獲得的圖像,可提高井下行人檢測精度;在ResNet的基礎(chǔ)上加入Dense連接來優(yōu)化RetinaNet網(wǎng)絡,優(yōu)化后的Dense-RetinaNet對小目標的檢測能力更加突出。
1 數(shù)據(jù)采集
為獲得足夠多的煤礦井下環(huán)境數(shù)據(jù),采用包含可見光傳感器、深度傳感器和紅外傳感器的Kinect攝像機(圖1)。將Kinect攝像機中3個傳感器安裝在井下防爆無軌膠輪車車頭,如圖2所示。

圖1 Kinect攝像機Fig.1 Kinect camera

圖2 傳感器安裝位置Fig.2 Sensors installation position
煤礦井下采集的原始數(shù)據(jù)以視頻方式保存,視頻數(shù)據(jù)處理流程如圖3所示。首先,將采集的視頻經(jīng)過OpenCV逐幀提取可視度良好的圖像幀來獲得單張圖像。其中,可見光圖像分辨率為1 920×1 080,紅外圖像和深度圖像分辨率為400×600。可見光圖像和紅外圖像的通道數(shù)為3;深度圖像格式為RGB-D,共4個通道,其中前3個通道為圖像色彩信息,最后1個通道為圖像深度信息。然后,對單張圖像進行數(shù)據(jù)增強(包括直方圖均衡[6]、雙邊濾波、反轉(zhuǎn)、旋轉(zhuǎn)、縮放和平移)。最后,選用LabelImg軟件對圖像進行手動標注標簽,標注的信息包括目標邊界、目標類別和目標中心坐標(每張圖像中包括的行人數(shù)量為1~10)。

圖3 視頻數(shù)據(jù)處理流程Fig.3 Video data processing process
經(jīng)處理后的煤礦井下行人圖像部分實例如圖4所示。可看出可見光圖像色彩豐富,成像距離長,但物體輪廓較模糊;深度圖像中物體輪廓凸出,但成像距離短,長距離成像稀疏;紅外圖像能夠過濾其他光線干擾,但同樣有成像距離短的缺點。



2 目標檢測網(wǎng)絡
2.1 分步多特征融合
為充分利用多個傳感器聯(lián)合來加強圖像中信息,基于Dense塊進行分步多特征融合,如圖5所示。首先,將紅外圖像和可見光圖像通過卷積之后送入各自數(shù)據(jù)流的Dense塊中提取特征,并在每一個特征層上執(zhí)行拼接操作。紅外圖像和可見光圖像經(jīng)過Dense塊處理后,輸出特征圖大小分別為13×13×1 024,26×26×512,52×52×256。然后,分別將這3種特征圖在其對應的尺度上進行特征融合,形成紅外圖像和可見光圖像特征融合金字塔。同時,深度圖像經(jīng)過3個卷積層后,對每一個卷積層結(jié)果提取深度信息,形成深度金字塔。最后,將深度金字塔和融合金字塔中大小對應的特征層進行拼接,形成融合特征。融合特征經(jīng)過一個1×1的卷積層后輸入到Dense-RetinaNet中。
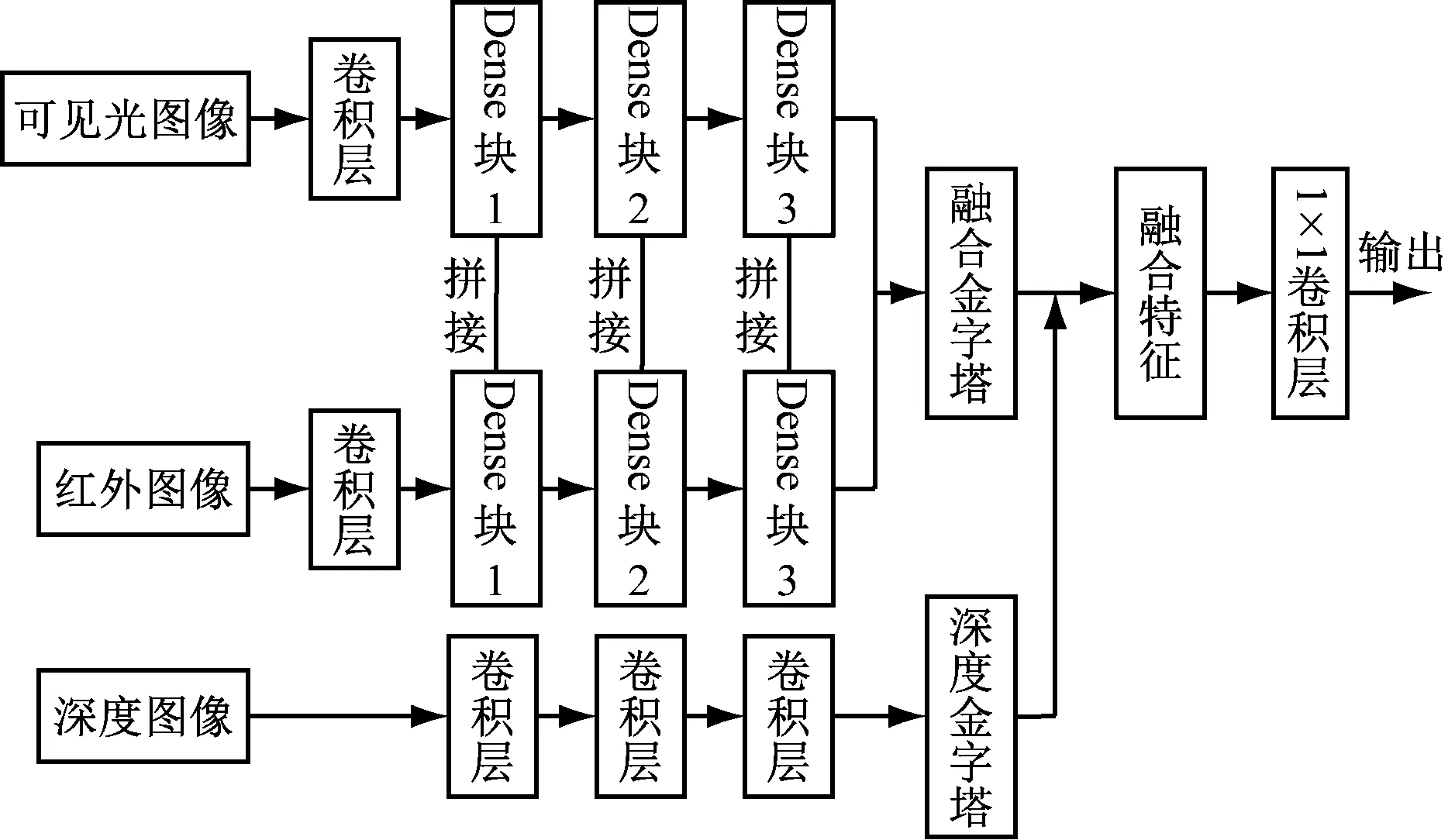
圖5 分步多特征融合原理Fig.5 Principle of step by step multi-characteristic fusion
2.2 Dense-RetinaNet
RetinaNet網(wǎng)絡由殘差網(wǎng)絡ResNet、特征金字塔和分類定位模塊3個部分組成[7]。ResNet作為特征提取器,可使網(wǎng)絡極大限度地保持圖像特征在傳遞過程中不會丟失。特征金字塔可從提取到的特征中計算出多尺度的候選區(qū)域[8],形成信息更具體、表達更強的特征圖。分類定位模塊是在特征金字塔中每一個特征層上定位和分類,以保證獲得多尺度檢測結(jié)果。
井下環(huán)境獲得的圖像所包含干擾更加復雜,為解決由光照等因素引起的井下圖像中小目標不明顯問題,本文對RetinaNet進行改進,在ResNet的基礎(chǔ)上加入Dense連接[9],形成一種具有層級相連結(jié)構(gòu)的Dense-RetinaNet,有助于在特征前向流動過程中使更多細節(jié)被保存,同時在反向傳播過程中計算梯度時信息會被更加充分利用。改進的ResNet結(jié)構(gòu)如圖6所示。改進的ResNet中包含5個Dense殘差塊,每個Dense殘差塊中有4個特征層,特征層之間進行局部特征連接,各殘差塊之間進行全局特征連接。通過對局部特征和全局特征的連接,使得特征能夠充分被傳遞,讓網(wǎng)絡可從圖像中提取更豐富的特征,并且可抵抗梯度消失問題。

圖6 改進的ResNet結(jié)構(gòu)Fig.6 Improved ResNet structure
2.3 損失函數(shù)
Dense-RetinaNet在分類上采用RetinaNet原有的Focal Loss損失函數(shù)。不同于標準的交叉熵損失函數(shù),F(xiàn)ocal Loss為了平衡正負樣本數(shù)量[10],特別加入了一個平衡因子ε(ε>0)。
交叉熵損失函數(shù)為
(1)
式中:l為真實樣本數(shù)據(jù);p為l=1的概率。
加入平衡因子后的Focal Loss損失函數(shù)為
Lf=-(1-Lc)εlog2Lc
(2)
定位損失函數(shù)Lloc為
Lloc=αLsize+βLpos+γLcof
(3)
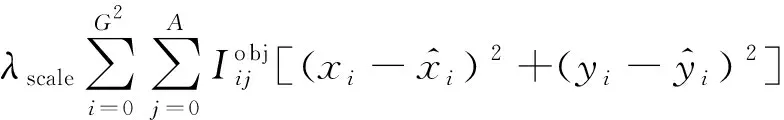
(4)
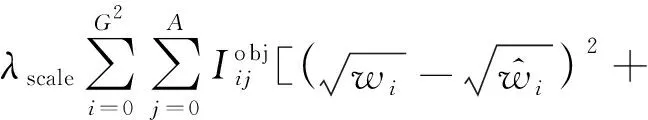
(5)
(6)
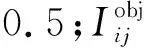
3 實驗及結(jié)果分析
網(wǎng)絡訓練平臺為NVIDIA AGX Xavier Developer Kit,內(nèi)存為32 GB,操作系統(tǒng)為Ubuntu 18.04 LTS,采用PyTorch開源框架。網(wǎng)絡訓練分為預訓練和調(diào)參2個階段。在PASCAL VOC2007+2012[12]數(shù)據(jù)集上預訓練網(wǎng)絡。將訓練好的部分網(wǎng)絡參數(shù)凍結(jié),在調(diào)參階段采用Adam優(yōu)化器,設(shè)置動量參數(shù)為0.9,均方根參數(shù)為0.999,學習率為0.001,批處理大小為32,迭代次數(shù)為3 000。
為驗證分步多特征融合的有效性,分別將可見光圖像和可見光圖像+紅外圖像+深度圖像輸入Dense-RetinaNet,檢測結(jié)果見表1。可看出經(jīng)過分步多特征融合的圖像有利于網(wǎng)絡在暗光和遮擋情況下提高mAP(mean Average Precision,平均精度均值),分別較單一可見光圖像時提高了14.02%和4.03%;但進行分步多特征融合時網(wǎng)絡要處理更多數(shù)據(jù),會增加運行時間。
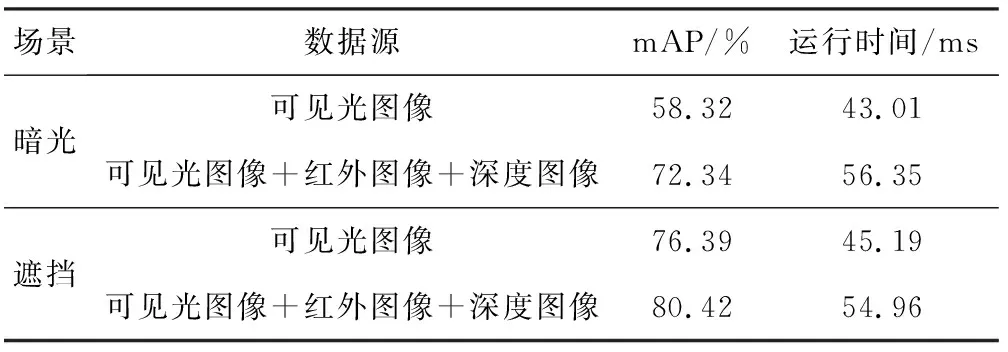
表1 不同輸入圖像下檢測結(jié)果對比Table 1 Comparison of detection results under different input images
為驗證Dense-RetinaNet的有效性,分別采用Dense-RetinaNet和RetinaNet對煤礦井下行人圖像進行檢測,結(jié)果如圖7所示。可看出Dense-RetinaNet比RetinaNet有更好的小目標和多目標檢測能力。

圖7 煤礦井下行人檢測結(jié)果Fig.7 Underground mine pedestrian detection results
RetinaNet和Dense-RetinaNet檢測結(jié)果對比見表2。可看出Dense-RetinaNet相較于RetinaNet在多目標檢測精度上提高了1.22%,小目標檢測精度上提高了6.49%。
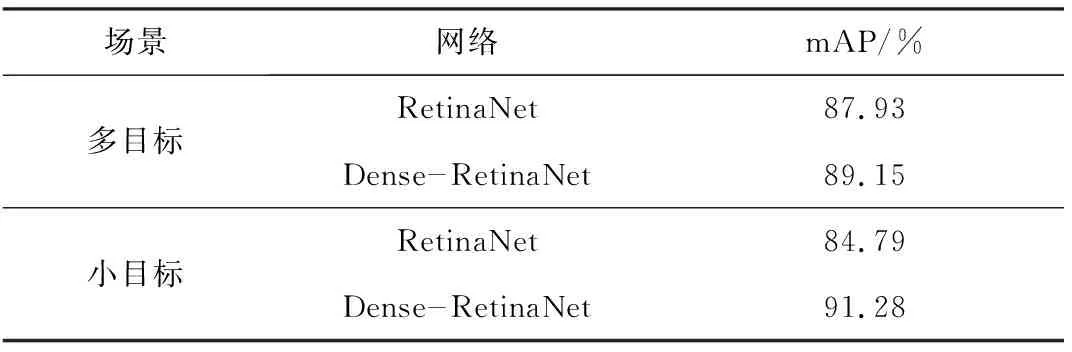
表2 RetinaNet和Dense-RetinaNet檢測結(jié)果對比Table 2 Comparison of detection results between RetinaNet and Dense-RetinaNet
4 結(jié)語
針對煤礦井下環(huán)境中光照復雜、目標尺度小等問題,提出了一種面向無人駕駛的井下行人檢測方法。該方法通過分步多特征融合方式將可見光傳感器、紅外傳感器和深度傳感器采集的圖像進行特征融合,獲得了更加豐富的圖像特征;在RetinaNet的基礎(chǔ)上,將Dense連接引入ResNet,形成一種具有層級相連結(jié)構(gòu)的Dense-RetinaNet網(wǎng)絡,能夠從輸入的多傳感器融合圖像中提取深層特征,增強了對小目標的檢測能力。實驗結(jié)果表明,多傳感融合圖像相較于單一圖像可獲得更加豐富的目標特征,有利于提高目標檢測精度;Dense-RetinaNet相較于RetinaNet在多目標和小目標檢測精度上均有所提高。
猜你喜歡
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數(shù)理化(高中版.高考數(shù)學)(2021年1期)2021-03-19 08:28:38
中學生數(shù)理化·七年級數(shù)學人教版(2020年11期)2020-12-14 06:59:52
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術(shù)品鑒證.中國藝術(shù)金融(2018年8期)2019-01-14 01:14:28
藝術(shù)品鑒證.中國藝術(shù)金融(2018年10期)2019-01-08 02:44:26
藝術(shù)品鑒證.中國藝術(shù)金融(2018年12期)2018-08-26 06:03:48
