基于協同過濾算法的學習資源推薦模型研究
2021-09-28 10:11:08覃忠臺張明軍
計算機技術與發展 2021年9期
覃忠臺,張明軍
(廣州大學華軟軟件學院,廣東 廣州 510990)
0 引 言
隨著互聯網技術的發展以及教育信息化的普及,在線學習平臺被廣泛應用于教育培訓行業中,用戶通過學習平臺推薦系統輕松獲取自己的學習資源[1]。隨著網上學習資源日趨豐富,加之不同的學習用戶其屬性特征如學習風格、學習偏好和學習水平等會影響用戶在學習平臺中精準獲取自己需要的學習資源[2]。傳統的推薦算法在新、舊用戶之間的相似度計算時,當存在新用戶對學習資源未進行評價或者沒有評價過任何學習資源,會產生數據稀疏、延展性差等問題,導致學習資源推薦結果解釋性不強;此外,傳統的推薦算法由于忽略了用戶的行為特性而導致存在用戶冷啟動問題,使得推薦結果不能給用戶帶來驚喜[3-5]。針對上述問題,許多學者從不同的技術角度對學習資源進行個性化推薦算法研究,其中協同過濾推薦算法應用最為廣泛[6],在推薦算法中綜合考慮用戶的各種潛在行為信息為用戶推薦感興趣的資源[7-9]。文中提出了基于協同過濾算法的學習資源推薦模型。通過對學習用戶和學習資源進行知識建模,利用協同過濾算法,將學習用戶模型和學習資源模型融入推薦過程。根據學習用戶的屬性特征進行學習資源個性化推薦,有效緩解傳統推薦技術存在的數據稀疏和冷啟動問題。
1 模型構建
學習資源推薦平臺包括學習用戶、學習資源、關系數據集和CF推薦模塊四部分。構建的學習資源推薦模型如圖1所示。

圖1 學習資源推薦模型
學習用戶模型存儲學習用戶的學習水平、學習風格、學習偏好等屬性特征信息。學習資源模型儲存多媒體和文本等格式的學習資源。關系數據集儲存學習用戶與學習資源本體領域知識的活動行為的關系數據信息。CF推薦模塊通過學習用戶與學習資源本體領域知識的關系數據集合信息計算目標用戶評分的相似度和預測評分,生成目標用戶Top-N學習資源推薦列表。最后結合目標用戶的屬性特征信息將學習資源個性化推薦給目標用戶。
1.1 學習用戶模型
對學習用戶進行學習資源個性化推薦是構建一個完整的用戶特征信息庫。包括學習風格、學習水平、學習偏好等學習特征以及用戶對學習資源的評論、下載、點贊和收藏等行為特征[10]。
定義1:學習用戶信息u形式化定義為一個五元組
定義2:用戶學習風格s形式化定義為一個二元組
定義3:用戶學習水平h形式化定義為一個三元組
定義4:用戶偏好信息p形式化定義為一個二元組
定義5:用戶行為日志v形式化定義為一個五元組
假設給定行為觸發因子λ的值,0為未觸發,1為觸發;R為行為評分,R=[1,5],β為行為激勵因子,β=[0,1],βd、βc、βf、βl分別表示四種行為的激勵因子,若存在學習資源對象i和用戶u,i∈I,u∈U,du,i、cu,i、fu,i、lu,i表示學習用戶u對學習資源i的四種行為評分,則λ*du,i*βd+λ*cu,i*βc+λ*fu,i*βf+λ*lu,i*βl反映用戶u對學習資源i的興趣。
根據上述定義,應用本體描述語言OWL和Protégé工具進行知識建模[11]。構建的學習用戶模型如圖2所示。
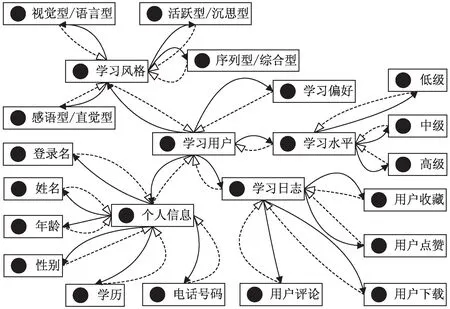
圖2 學習用戶模型
將學習用戶的屬性特征信息存儲在模型中,模型中的數據隨用戶的屬性特征變化而更新,形成個性化學習用戶知識庫。
1.2 學習資源模型
在線學習平臺上的資源具有學科多樣性。通過挖掘學科知識點的關聯關系,從知識點中提取相關的實體列表并進行分類,包括音頻、視頻、動畫、圖像、課件、教案、案例、作業、試題等,以學科為核心建立學習對象層和學習資源層。
定義6:學習對象層o形式化定義為一個二元組
定義7:學習資源層i形式化定義為一個六元組
根據上述定義,基于Protégé的本體知識建模構建的學習資源模型如圖3所示。
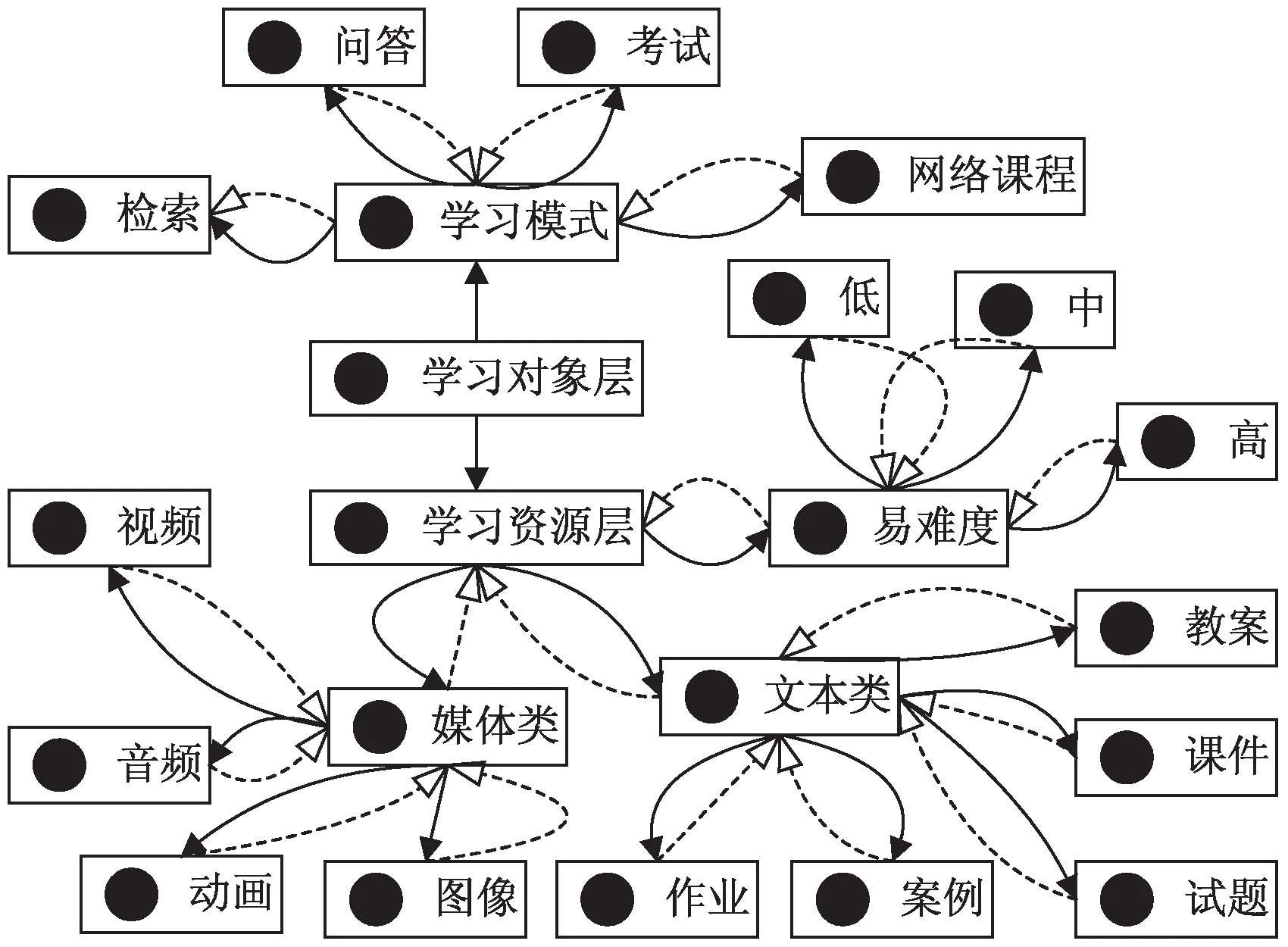
圖3 學習資源模型
構建的學習資源模型體現了學習用戶之間、學習用戶與學習資源之間以及學習資源知識點之間的關系,CF推薦模塊通過關系數據集中學習用戶和學習資源之間的語義關系對學習資源對象之間進行相似性計算并對目標用戶進行預測評分。
1.3 CF推薦模塊算法
CF推薦模塊通過用戶-學習資源評分矩陣構成的關系數據集來計算學習用戶對已評分的學習資源對象的相似度,獲得學習資源對象的鄰居集,預測目標用戶對學習資源對象的評分,最后根據學習用戶模型的屬性特征信息生成個性化學習資源推薦列表并推薦給目標用戶。
(1)構建評分矩陣。
學習用戶對所有學習資源評分的數據集D形式化定義為一個三元組
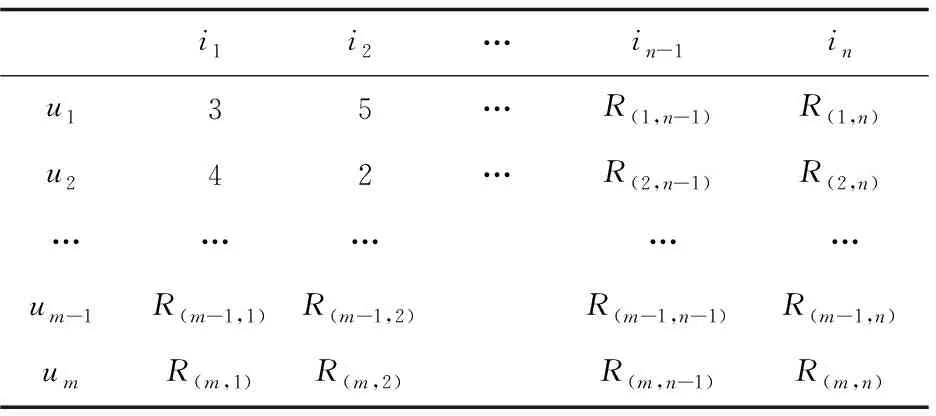
表1 用戶-學習資源評分矩陣
(2)相似度計算。
相似度計算是CF推薦模塊的關鍵步驟。常用的相似度計算方法有皮爾遜(Pearson)相關相似度、余弦(Cosine)相似度和修正的余弦相似度[11-13]。對于學習資源平臺,用戶的興趣具有固定性和持久性,資源的更新頻度具有一定的時間周期性。在建立的學習用戶和學習資源模型的基礎上,結合學習用戶對學習資源的評分,文中采用基于修正的余弦相似度的改進計算方法(標記為MS)來計算相似度。將學習用戶的下載、評論、收藏和點贊等行為作為相似因子加入計算式中以提高相似度計算的置信度。假設Ru,i為用戶u對學習資源對象i的評分,Ru,j為用戶u對學習資源對象j的評分。根據定義5,則有:
Ru,i=λ×du,i×βd+λ×cu,i×βc+λ×fu,i×βf+
λ×lu,i×βl
(1)
Ru,j=λ×du,j×βd+λ×cu,j×βc+λ×fu,j×βf+
λ×lu,j×βl
(2)
學習資源對象i和j的相似度計算公式sim(i,j)如下:
sim(i,j)=MS=
(3)
(3)預測評分。
根據式(3)得到的最近鄰居集,預測目標用戶對學習資源對象的評分。假設Pu,i為目標用戶u對學習資源對象i的預測評分;N為與學習資源對象i的鄰居集,由式(3)計算得來,且k∈N,k為鄰居集N中的學習資源對象之一,sim(i,k)為學習資源對象i與鄰居集N中的學習資源對象k的相似度;Ru,k為目標用戶u對學習資源對象k的評分。則目標用戶u對學習資源對象i的預測評分為:
(4)
1.4 模型實例的執行及CF算法流程
定義8:學習用戶模型實例w形式化定義為一個六元組
定義9:學習資源模型實例k形式化定義為一個四元組
根據定義8和定義9,用W表示所有學習用戶模型實例的集合,W={w1,w2,…,wn}。用K表示所有學習用戶與學習資源本體領域知識的關系數據集合,K={k1,k2,…,kv},其中kj={wj,ij}。用R表示學習用戶對學習資源的評分集合,R={1,2,3,4,5}表示評分范圍。用戶進入E-learning平臺參與在線學習活動的過程:
(1)用戶從定義8的W中啟動用戶實例w。如果用戶第一次進入平臺,從定義1中進行個人信息注冊。獲取該用戶實例名稱n,建立一個新的用戶實例結構u,其中Wu=nw。
(2)通過學習平臺推薦模型進行語義搜索,分析學習用戶屬性特征并確定學習偏好、風格及水平。當?St=?,則St←0‖1‖2‖3;當?Pd=?,則Pd←用戶填寫偏好信息;當?Hg=?,則Hg←隨機進行學習水平測試。
(3)在CF推薦模塊中輸入I,K,R,分析用戶行為日志,顯式獲取學習用戶Vd、Vc、Vf、Vl等行為信息。算法流程如圖4所示。
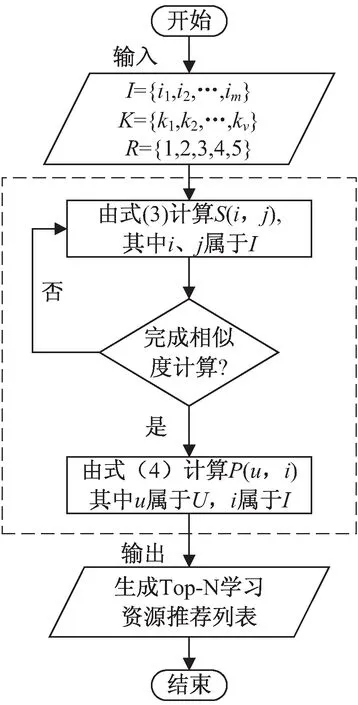
圖4 CF推薦算法流程
(4)CF推薦模塊計算出目標用戶w對未評分學習資源對象i的預測值,然后根據預測值由高到低確定n個排在最前的項作為top-N推薦集結果。在分析學習用戶屬性特征的基礎上,當?St=0‖1‖2‖3,則nw←推薦適合學習用戶學習風格的資源;?Pd≠?,則nw←推薦適合學習用戶偏好的資源;當?Hg=0‖1‖2,則Hg←推薦適合學習用戶水平層次的資源。
(5)由上述推薦結果,用戶從定義9的I中啟動推薦的學習資源實例i。獲取該學習資源實例名稱n,建立一個新的學習資源實例結構p,其中Ip=ni。
(6)當?nw→ni,則系統記錄用戶日志行為:Vd←下載,Vc←評論,Vf←收藏,Vl←點贊。
將構建的學習用戶和學習資源模型融入CF推薦模塊,提高學習資源檢索的效率與準確度,當新用戶進入學習平臺推薦模型時,會根據學習用戶屬性特征信息進行語義搜索、分析并確定其學習偏好,與學習用戶模型進行匹配,從而為目標用戶實現學習資源個性化推薦,緩解了用戶的冷啟動問題。
2 模型測試及實驗分析
2.1 測試數據集
實驗數據來源于本校精品資源網絡課程學習平臺,目前學習平臺注冊用戶有6 000多人,用戶評分過的學習資源超過1 000個。從系統中抽取300個用戶數據進行實驗測試,數據集結構如表2所示。
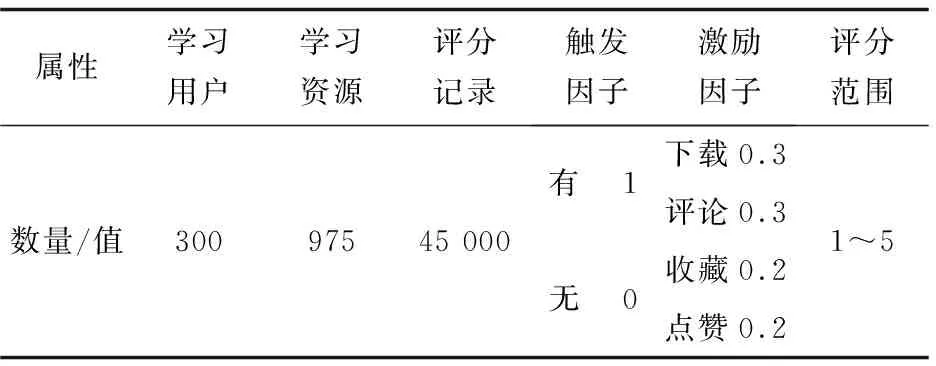
表2 數據集
分析數據集中的用戶行為日志,若有下載、收藏、評論、點贊等行為,將觸發因子設為1,反之設為0,為每種行為設定0~1之間的激勵因子。根據表1設計的評分矩陣,評分范圍為1~5,1為非常不感興趣,5為非常感興趣,0為未評分。將實驗數據隨機分成5份,其中4份用作訓練集數據進行學習訓練生成推薦結果,構建推薦模型;另外1份用作測試集數據進行驗證推薦結果,實驗時進行多次交叉驗證。
2.2 測試結果與分析
為驗證文中提出算法的有效性,將MS相似度算法與余弦相似度(Cosine)和皮爾遜(Pearson)相關相似度進行評價比較。評價標準采用推薦算法的MAE評價指標[14],通過MAE的平均絕對誤差準確預測學習用戶的評分來評估算法的有效性。計算公式為:
(5)
其中,MAE為平均絕對誤差,yi為學習用戶對學習資源的預測評分,xi為學習用戶對學習資源的實際評分,n為預測評分的次數。在測試過程中,設置近鄰個數按照步長為10,從10增加到100,計算使用MS、Cosine和Pearson三種不同相似性度量方法時的MAE值,三種算法的MAE實驗結果如圖5所示。

圖5 Cosine、Pearson和MS的MAE值
由圖5可看出,在相近鄰居不斷增加的情況下,MS算法的MAE值均比Cosine和Pearson的MAE值低,且逐步遞減,這說明了數據的稀疏性在降低,MAE值越低,算法的準確率越高。從走勢線圖可看出,MS在測試的后面是逐步勢于平穩,顯示出MS算法在鄰居集數量進一步增加情況下的推薦性能具有一定的平穩性。實驗證明,在融入學習用戶的屬性特征信息的MS算法提高了用戶鄰居集的識別精度,有效緩解了數據的稀疏性和用戶冷啟動問題,提高了學習資源的個性化推薦,具有較強的解釋性,推薦結果優于傳統的推薦算法。
3 結束語
針對在線學習平臺在傳統的推薦算法中存在的數據稀疏性和冷啟動問題,研究了基于協同過濾算法的學習資源推薦模型。在給出學習資源推薦模型的基礎上構建了學習用戶模型和學習資源模型,使用基于修正的余弦相似度的改進計算方法進行相似度計算和預測評分,獲得潛在的推薦學習資源對象,將學習用戶的學習風格、學習水平、學習偏好等屬性特征融入推薦過程進行學習資源個性化推薦。通過與傳統的推薦模型對比,該推薦模型在推薦精度和個性化方面具有一定的優勢,有效緩解了傳統推薦算法的數據稀疏性和冷啟動問題。
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
資源再生(2017年3期)2017-06-01 12:20:59
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
山東青年(2016年1期)2016-02-28 14:25:25
創業家(2015年5期)2015-02-27 07:53:25
當代修辭學(2014年3期)2014-01-21 02:30:44
