基于依存關系的自然語言可視化仿真系統
2021-09-28 10:17:02袁雨軒陳科淇
計算機技術與發展 2021年9期
袁雨軒,李 放,陳科淇,韓 正
(1.大連東軟信息學院 數字藝術與設計學院,遼寧 大連 116023;2.華威大學 華威商學院,考文垂 CV4 7AL)
0 引 言
自然語言處理技術是在程序設計中常用的人工智能算法,也是人工智能的熱點研究方向。主要應用場景包括個性化推薦、搜索糾錯等。神經網絡是自然語言處理以及人工智能領域最重要的方法之一。為了讓計算機理解自然世界的知識,可以根據具體研究對象的特征構建不同的神經網絡結構,如適用于圖像處理的卷積神經網絡(convolutional neural networks,CNN)、適用于文本和序列數據的遞歸神經網絡(recurrent neural networks,RNN)和長短期記憶網絡(long short-term memory neural networks,LSTM)等[1-2]。盡管這些網絡結構在處理不同的任務時表現出不同的性能,對于具體任務仍很難確定使用哪種網絡結構[3],所使用模型的訓練過程同樣需要耗費大量時間。為了覆蓋更多的語言場景,本系統依賴百度AI開放平臺的自然語言處理技術接口。百度AI開放平臺提供了全面的語言處理基礎能力和語言處理應用技術,并以標準化的接口封裝。且該平臺的訓練語料以中文為主,對中文輸入的接受能力較強。
對自然語言處理技術來說,其最細的劃分粒度是詞語。而在計算機仿真領域中可以使用三維模型、圖片等來模擬名詞,使用動畫、聲音等交互系統模擬動詞。由于中文的能指極其復雜,在自然語言處理技術難以解決的詞語多義性問題上更是雪上加霜。文獻[4]提出了中文句式的三個層級:(1)表層:形式結構,語言中語法項的線性配列式。如主語+謂語構成SV句式等。(2)中介層:表現法,語言中線性配列的特定樣式。如抒情、描寫手法等。(3)深層思維方式:反映說話者心理的主體意識。并提出深層思維方式的表達注重于主觀感受的抒發,即為了滿足句子表層結構的語法在表達中的正確性,其深層思維方式可以不嚴格滿足語法規則。由于深層思維方式不執著于邏輯和形式結構規范,其表達與所指的聯系也更緊密。
基于以上分析,文中將深入討論句子中不同實體之間的依存關系,排除中介層和表層結構中的修飾成分,從而得到易于計算機理解句子深層邏輯的輸入。并提出了一種可視化的虛擬仿真解決方案,用實體所指代的對象代替中文復雜的能指,并以視頻的形式可視化呈現。
1 系統開發中的關鍵技術
1.1 中文依存關系的研究
聚類(cluster)是一組數據對象的集合,在文中對應著人們使用自然語言輸入、不利于計算機理解的句子。文獻[5]在引用中總結到,聚類的基本劃分方法存在需要事先給出樣例的缺陷。而人工定義的語法規則也是難以窮舉、無法事先給出的。同時,中文的依存句法分析區別于英文,需要對句子進行分詞[6]。對過于復雜而無法進行預處理的數據可以考慮使用基于深度學習算法的模型。百度AI依存句法分析接口提供了使用百度日常搜索內容做訓練數據的Query模型,該模型擅長對口語Query句式的處理。以及來源于全網網頁數據的Web模型,該模型偏向表達規整的書面語法。以上模型可以解析出共34種依存關系。對此可以根據集合學習的思想,構建多個對不同數據的處理效果有明顯偏好的模型,整合出一個更強大的模型做最后決策。
為了研究解析出的不同依存關系對句子深層邏輯的影響程度,實驗1.2將使用百度AI的短文本相似度接口,采用CNN模型驗證去除不同依存關系后對句子結構的影響,相比于該接口提供的詞袋模型(bag-of-words model,BOW)和RNN模型,CNN模型的顯著特點是對序列輸入敏感,但是語義泛化能力較弱。本實驗更關注實體之間的邏輯,在對比實驗的過程中僅去掉某一個依存關系對應的實體,因此對詞語泛化能力的要求較低,且CNN模型對句子保留的局部特征更敏感,因此選擇CNN模型可以在實驗中獲得更理想的結果。
1.2 實 驗
中文的語言特點決定了多數的語言場景需要以復句的形式完成。處理復句的難點在于各個分句間語義關系的準確識別。文獻[7]提出了一種基于句內注意力機制的多路CNN網絡結構,可以識別分句間的關聯特征,以及正確識別復句的邏輯關系。文中虛擬仿真工作產生的效果主要來自各分句中的名詞模型,其中的邏輯關系由該分句中的謂語提供,并且中文的表達習慣可以保證句子輸入的語序與視頻播放的時順相對應,因此各分句之間可獨立看待。為了研究使用自然語言輸入的單個句子中詞語之間的依存關系,以“袁明吃蛋撻”為例,表1將展示該例句在去掉不同依存關系所對應的詞語后與原句子的短文本相似度,該數值介于[0,1]之間,反映了被去掉的依存關系對句子邏輯的影響程度。首先排除由復句產生,或無實際意義的虛詞產生的依存關系,如標點符號、關聯詞等共計17種。
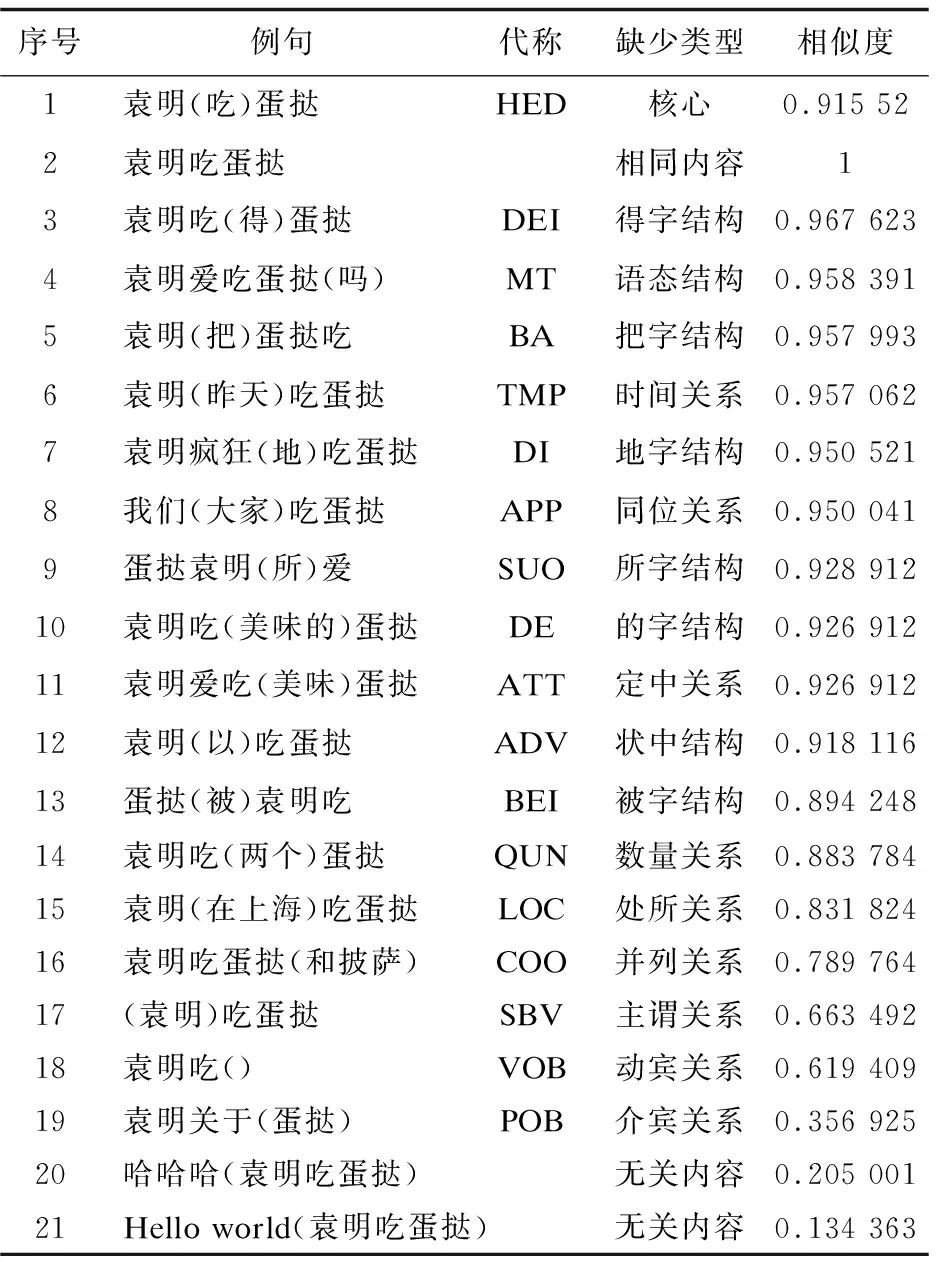
表1 語義相似度對比實驗
1.2.1 討 論
相似度是一個十分復雜的概念[8]。根據實驗序號2可知,兩個完全相同的句子相似度為1,序號20和21是兩個與原文無關的句子,其相似度在本實驗中的樣例均小于0.3。序號19介賓關系是另一個相似度接近0.3的樣本,原因是丟失掉賓語后與原句本身差異過大。對以上結果可暫時作如下假設:短文本相似度接近0.3甚至更小的句子與原文的出入較大,故應取大于相似度0.3的結果做討論。
文獻[9]在文本相似度計算中提到了句子的關鍵成分與修飾成分的概念,而人們往往從關鍵成分就可以了解一個句子的大概意思。在介于(0.9,1)區間內存在十種依存關系,除核心關系外,其他的依存關系均是對句子邏輯影響較小的結構成分或修飾成分。以上兩種成分的存在保證了句子表層語法規則的正確。以“地”字結構為例,其語法解析樹如圖1所示。該依存關系僅修飾動詞“吃”。去掉修飾成分對句子要表達的深層邏輯影響很小,此句子的動畫依然可以由“袁明吃蛋撻”來表示。對此結果不妨假設在(0.9,1)區間內的修飾成分在生成動畫時可以忽略。
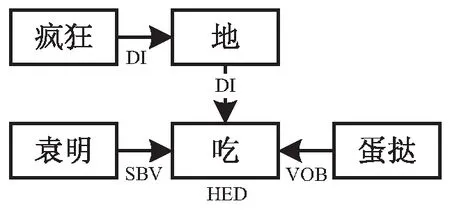
圖1 例句“袁明瘋狂地吃蛋撻”
文獻[10]中的例句驗證了,在以中文復句輸入所返回的語法生成樹中,關系詞都是動詞。關系詞在復句中常作為分句的核心節點出現,因此本實驗的單句中核心節點的作用類同于復句中的關系詞。
對于圖2所示的核心關系需要特別討論,因為動詞“吃”是SVO句式的關鍵成分而不是修飾成分,顯然與上文的假設相矛盾。這是因為本實驗使用的CNN模型雖然對局部特征敏感,但是“袁明”和“蛋撻”之間沒有任何成分解釋兩個詞之間的邏輯關系,于是該模型默認把“袁明”作為修飾成分,原句的意思被泛化成圖3描述的“袁明牌蛋撻”了。CNN模型在卷積層內部狀況為詞向量的拼接。詞向量是計算機理解詞匯的媒介,這種表示方式是將詞語映射到一個高維且稠密的向量空間中,用空間距離的形式反映兩個詞之間的系。文獻[11]提到,將詞語在計算機中向量化表示的常用方法有one-hot、詞向量和Word2vec模型等。雖然百度AI平臺沒有描述短文本相似度接口使用的CNN模型中的詞向量在卷積層內部的具體情況,但該平臺語言處理基礎能力的SDK中也提供了詞向量表示接口。詞向量模型訓練過程的初始狀態下,對語料庫內包含的所有詞向量隨機賦初值,按照詞語在樣本句子中的位置相應地調整詞向量在空間中的位置,以“袁明吃蛋撻”為例句訓練詞向量,該句子由人名+動作+賓語組成。如圖4所示,當再次輸入“韓明”和“蛋撻”時,“吃”字在空間中的優先級會小于其他的動詞如“買”。輸入“李明”和“吃”之后“蛋撻”的優先級同樣會高于其他名詞。類似的,使用訓練集中的句子不斷調整詞向量的位置,多次訓練后的詞向量可以作為特征值用于在計算機中表示該詞語。

圖2 例句“袁明吃蛋撻”
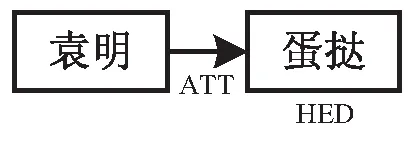
圖3 例句“袁明蛋撻”
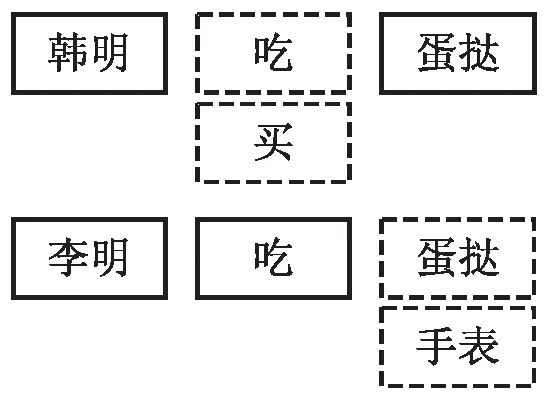
圖4 例句“袁明吃蛋撻”的詞向量訓練
基于以上結論,對例句詞語分別調用百度AI的詞向量表示接口,返回類型為1024維空間大小的詞向量,其中對“袁明”的返回值為[-0.074 207 4,-0.458 546,-0.010 252 2,0.010 083 9,…],對“吃”的返回值為[0.015 029 4,1.488 3,-0.482 325,-0.740 492,…],對“蛋撻”的返回值為[0.015 029 4,1.488 3,-0.482 325,-0.740 492,…]。CNN模型檢測文本相似度方法的內部情況是將以上三個詞向量拼接成矩陣表示,在池化層完成對數據降維的工作[12]。文獻[13]詳細描述了目前主流的池化方法:
(1)平均池,選擇池窗口中的平均值表示池區信息。
(2)最大池,選擇池窗口中的最大值,該方法可以獲得池區的最優值,也是最常用的方法。
(3)K-max池,選擇池窗口中的最大K值,該方法是最大池方法的擴展,可以更好地保持文本特征。
(4)多池,該方法是針對文本任務的特點,獲得文本的一維向量表示,并在一維向量上使用其他池化方法分段。
該方法的優點是能保留一些詞序信息,可以視為最大池的一種變體。本項目對于文本相似度接口返回的數值為離散數據,且難以描述實際意義,可以考慮使用聚類方法處理。參考多池的分段方法,研究返回的三個詞向量之間的關系可以通過計算歐氏距離表示詞向量在二維空間下的位置關系,其中D為絕對距離,X,Y為實體,x,y為特征值,計算方法如下:
最終計算“袁明”到“蛋撻”的距離為17.433 217 41,句子“袁明吃蛋撻”的距離之和為39.262 644 02。另一個例子,“袁明跳蛋撻”是一句顯然不符合表達習慣的句子,此句子與“袁明蛋撻”的相似度為0.767 38,且符合上一節中介值于(0.3,0.9)之間的假設,這個句子的距離之和為46.659 304 67。將以上距離關系映射到二維空間下的表示如圖5所示,由于詞向量的特征值僅代表在向量空間下的絕對位置,因此該坐標系下的單位僅作運算,無實際意義。
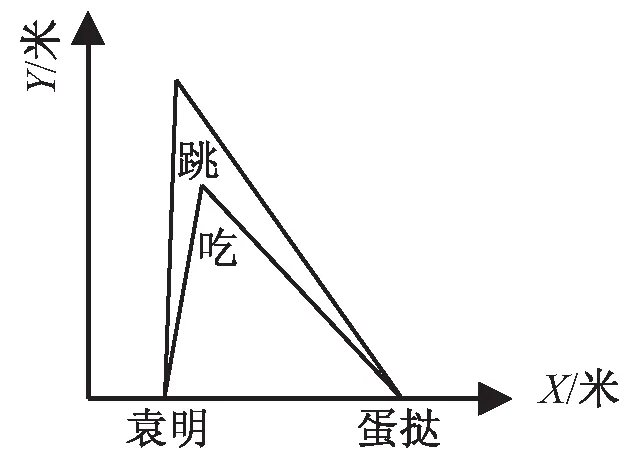
圖5 詞向量在二維空間下的映射
由數據降維后的結果可見,“吃”字對卷積運算的結果影響較小,以上結果是因為CNN模型運算詞向量時對特征敏感而本例句過于簡單所導致,所以為了保持句子的完整結構,核心關系應作為特例保留。
1.2.2 結 論
基于上文的實驗,文本相似度處于(0.3,0.9)區間的依存關系有主謂關系、介賓關系和動賓關系以及做特例的核心四種依存關系作為句子的關鍵成分,相似度同樣處于(0.3,0.9)區間的處所關系、并列關系、數量關系和“被”字結構是對句子邏輯影響比較大的修飾成分或結構成分。利用已經確定好的八種重要的依存關系,可以重新組合出更接近句子深層含義的SVO句式。在不改變句子本身邏輯的前提下,去掉盡可能多無需以動畫展示的修飾成分,對第二節中生成動畫的工作顯然是更友好的。
2 系統的設計與實現
2.1 系統架構設計
基于依存關系的自然語言可視化仿真系統使用C/S分離式架構設計,其時序圖如圖6所示。使用.net框架中的TCP協議通信,分離式架構的優點是可以方便本系統在應用層面開發時的擴展[14],例如將模型資源保存在服務器上的數據庫中以減少客戶端資源的使用,以及在不修改客戶端的條件下更新數據。本系統的核心問題是對以上依存關系合理性的驗證,故暫時不考慮在架構上做性能優化。
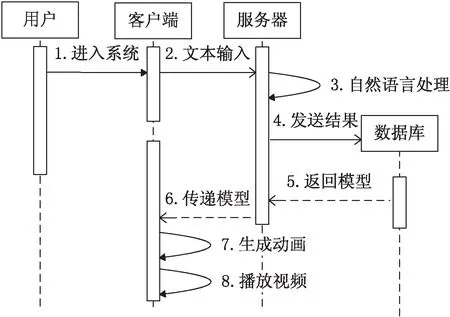
圖6 UML序列圖
2.2 服務器的系統開發
服務器的開發需要調用百度AI開放平臺的自然語言處理接口。使用前需要在官方網站申請API_KEY、SECRET_KEY和APPID并下載C#平臺的SDK,在Visual Studio中新建項目,添加對SDK中類庫的引用,并創建InputHandle類和NetWork類。調用接口時的請求文本應采用GBK編碼,而此編碼在.NET Core平臺上不可使用。在程序啟動時注冊RegisterProvider能提供平臺不可使用的編碼格式,具體代碼如下:
System.Text.Encoding.RegisterProvider(System.Text.CodePagesEncodingProvider.Instance);
System.Text.Encoding.GetEncoding("GB2312");
2.2.1 InputHandle類
InputHandle類包含了調用自然語言處理接口和聲明Json解析的方法。首先,將輸入的句子傳入到依存句法分析方法中,使用正則表達式解析返回的Json結果,并放入到如下格式的結構體數組中。
public struct Word{
public int head;//頭節點
public string word;//詞
public int id;//節點編號
public string deprel;//關系
};
根據此結構體數組,可以獲得一棵有序的語法解析樹,使用Equals()方法判斷結構體中deprel的取值。關鍵代碼如下:
string Subject,Verb,Object;
foreach(Word w in Words) {
if (Equals(w.deprel,"SBV") Subject =w .word;
if (Equals(w.deprel,"HED") Verb = w.word;
if (Equals(w.deprel,"QUN") Verb = w.word;
if (Equals(w.deprel,"BEI") Verb = w.word;
if (Equals(w.deprel,"COO") Object = w.word;
if (Equals(w.deprel,"VOB") Object = w.word;
if (Equals(w.deprel,"POB") Object = w.word;
if (Equals(w.deprel,"LOC") Object = w.word;
}
將以上代碼賦值后的Subject、Verb、Object變量有序地存入字符串數組,此方法封裝到DepPraseHandle類中,并將字符串數組作為參數傳遞給NetWork類。
2.2.2 NetWork類
對于服務器和客戶端之間的通信問題,本系統采用.net基于套接字為TCP協議擴展的TcpClient類和TcpListener類共同實現。TcpListener類可以偵聽來自TCP網絡客戶端的連接。由于TCP協議是以穩定字節流的形式將數據在網絡間傳輸[15],TcpClient類中的GetStream()方法可以返回用于發送和接收的網絡流。對于字節類型可以使用BinaryWriter類和BinaryReader類共同實現將基元類型讀取和寫入的二進制值的操作,以上提及的兩個類位于命名空間System.IO下。創建ReceiveMessage()方法,包含使用BinaryReader讀取到網絡流中客戶端發送的句子,并作為參數按上文所述的順序調用InputHandle類中的方法,最終根據返回的消息找到模型在服務器上保存的位置,并使用FileStream類的方法寫入流數據,關鍵代碼如下:
public byte[] FileReader(string path)
{
FileStream fileStream = File.Open(path, FileMode.Open);
Console.WriteLine(path);
byte[] array = new byte[fileStream.Length];
fileStream.Read(array, 0, array.Length);
fileStream.Close();
return array;
}
創建SendMessage()方法,包含將返回的字節數組使用BinaryWriter.Write()方法寫入到網絡流NetWorkStream中。其中NetWorkStream位于命名空間System.Net.Sockets下。將上述方法封裝于NetWork類,最終的服務器UML類圖如圖7所示。

圖7 服務器UML類圖
2.3 客戶端的系統開發
2.3.1 命名實體處理
在Unity3D中將每個實體模型制作為GameObject類型的預制體,并以實體的含義命名后保存在數據庫中。
(1)名詞類。
由于需要表示的動畫不僅是由模型組成,在Unity3D中實現名詞還可以意味著動畫、天空盒子、粒子系統、聲音、視頻等功能,故需要根據詞語創建模型,并對非模型類的命名實體掛載一個繼承自MonoBehaviour類的腳本,并在Start()方法中調用不同組件的Play()方法,以便在生命周期開始時執行。
(2)動詞類。
動詞類在中文的單句中作為語法樹的根節點或度大于一的節點控制前后名詞類的邏輯,不僅需要訪問名詞類,還要根據動詞本身的意思讓名詞類執行不同的操作如的開始、結束、改變位置、復制多個等,在動詞類中創建FunSubject()、FunVerb()、FunObject()三個方法,分別對應著與名詞的主動關系、動作和被動關系。通常情況下,數量關系、處所關系等修飾成分充當謂語成分時對應著FunObject()方法的實體,表示賓語被動產生的動作。而核心HED往往由動詞產生,對應著FunSubject()方法,表示主動發起的動作。以FunSubject()方法為例,獲取名詞所對應命名實體的代碼如下:
public Inventory Bag;
public GameObject Mod;
public string Subject;
foreach (GameObject b in Bag. itemList){
if (Equals(b.name,Subject) == true)Mod = b;
}
獲取到模型后,首先要分析該動詞的含義,在FunVerb()方法中以低代碼化的方式添加簡單的代碼片段。例如下面的代碼為動詞“害怕”添加了音頻并向后移動了主語模型的位置。
public void FunVerb(){
Instantiate(audioSource);
Mod.transform.position += new Vector3(0, 0, -1);
}
2.3.2 背包系統實現
根據系統架構設計,客戶端需要接收服務器發送的字節數組。并按照字節數組中的順序在客戶端寫入文件并序列化地生成模型,可以考慮使用GameObject類型的泛型列表保存模型,這種方法的優點是易于根據名稱隨機讀取模型。
創建背包的方法如下:
public class Inventory : ScriptableObject{
List
}
2.3.3 控制器設計
首先創建Receive()方法接收到服務器以字節流格式發送的命名實體,其關鍵代碼如下:
publicstring Receive()
{
byte[] recvBuf = new byte[102400];
networkStream.ReadTimeout = 2000;
int bytesRead = networkStream.Read(recvBuf, 0, 102400);
if (bytesRead > 0)
string message = Encoding.UTF8.GetString(recvBuf);
return message;
}
創建FileWrite()方法,用于將字節數組寫入文件。在寫入時需要注意判斷服務器寫入文件的順序,可以使用標簽或分批發送的方式區分好不同實體,下面以動詞為例,寫入方法如下:
public void FileWrite(string message)
{
int a = message.IndexOf("%YAML 1.1");
//在a下標的100位之后繼續尋找下一個文件的報頭
int b = message.IndexOf("%YAML 1.1", a + 100);
string verb = message.Substring(a, b - a);
FileStream vFile = new FileStream(@"AssetsResourcesVerb.prefab", FileMode.Create ,FileAccess.ReadWrite);
StreamWriter Vwriter = new StreamWriter(vFile);
Vwriter.WriteLine(verb);
Vwriter.Close();
}
若制作的實體僅由Unity3D自帶的模型組成,可以直接使用UTF-8格式編碼后使用StreamWriter以字符串的形式寫入文件,這種方法相比直接操作字節而言更易于計算。否則需要把制作的命名實體及相關資源以unitypackage包的形式導出,使用BinaryWriter將二進制值寫入文件后導入項目。最終將生成的實體放入背包中,方法如下:
Bag.itemList.Add(Resources.Load("Verb") as GameObject);
在執行了以上部分的代碼后,此時已獲取到句子中涉及到的所有模型和對應關系,名詞類模型包含了具體的屬性,動詞類模型可以獲取到名詞的屬性并執行相應的事件。要實現動畫的播放,則只需要依次從背包中取出對應的實體并實例化在場景中即可,關鍵代碼如下:
public Inventory Bag;
void FindVerbsInBag () {
foreach(GameObject go in verbBag.itemList){
if (go.name == Subject)Instantiate(go);
if (go.name == Verb)Instantiate(go);
if (go.name ==Object)Instantiate(go);
}}
在控制器腳本的生命周期結束時,還應添加資源銷毀機制并清空背包,避免該場景在下一次激活時執行寫入或查找操作出現異常,可以參考如下代碼:
private void OnDestroy(){
File.Delete("Assets/Resources/Verb.prefab");
File.Delete("Assets/Resources/Subject.prefab");
File.Delete("Assets/Resources/Object.prefab");
bag.itemList.Clear();
}
該方法在添加時需要慎重考慮,因為在復句或較復雜句式的處理中,該模型與下一個句子可能仍然存有聯系。應考慮具體需求靈活變動,例如在銷毀前增加條件判斷或創建緩存機制等。
3 系統測試
以“袁明害怕小狗”,“袁明坐飛機去上海”為例,為這句話中出現的命名實體制作相應的模型,這兩句話在本系統中的運行效果如下:圖8(a)按順序出現了模型,并播放了聲音表示害怕,同時人物的模型向后移動了一段距離。圖8(b)按順序出現了模型,并在視頻播放完成后更換了天空。

(a)例句“袁明害怕小狗”

(b)例句“袁明坐飛機去上海”
在不銷毀以上模型的條件下,輸入一個重新組合的句子“袁明到上海,小狗挨著香蕉”,再次制作命名實體“香蕉”對應的模型,添加動詞“到”和“挨著”,并識別逗號用做分隔符以兩個分句的形式連續調用上述方法。本系統將以兩個單句的效果播放動畫,最終效果如圖9所示。
4 結束語
在現實生活中,人們通常更加熟悉該詞語本身所指代的對象,只是不熟悉這一對象在某種語言下的表示中所使用的語言符號。文中為能指與所指之間提供了一種可視化的解決方案,在處理SVO結構單句時可以表現出理想的效果,適合應用于漢英字典例句的可視化翻譯、同一語料庫內的內容的可視化。對于復句或結構更復雜的句式可以在輸入時根據需求切分并逐條處理,以滿足大多數應用場景。但是對于不符合語法規則的口語句式或輸入錯誤時表現出的處理結果并不理想。除此之外,標注大量模型的工作是另一個難題。筆者將在日后繼續研究此系統的實用性擴展。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
意林原創版(2016年10期)2016-11-25 10:28:30
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
