基于機器學習的氣象網(wǎng)絡數(shù)據(jù)安全研究
2021-09-28 10:16:30何恒宏韓春陽
計算機技術與發(fā)展 2021年9期
鐘 磊,何恒宏,韓春陽,李 楠
(國家氣象信息中心,北京 100081)
0 引 言
隨著氣象信息網(wǎng)絡的快速發(fā)展,氣象行業(yè)面臨的信息安全威脅不斷增加。通過對近三年國家級信息網(wǎng)絡安全事件進行統(tǒng)計,各類APT(advanced persistent threat,高級可持續(xù)威脅攻擊)和利用漏洞的滲透事件數(shù)量的年增長率均超過30%。安全事件不斷增加的原因主要有以下三個方面:第一,業(yè)務系統(tǒng)在設計過程中沒有將信息安全充分納入考量,造成系統(tǒng)上線后暴露的安全問題難以徹底解決;第二,部分人員安全意識不足,在使用過程存在不安全操作;第三,安全監(jiān)控和防護能力不足,無法做到所有終端數(shù)據(jù)流量的實時檢測和分析。
近年來,機器學習的有關算法在網(wǎng)絡空間安全方面取得了一些研究成果,有關技術也在不同行業(yè)進行了實踐[1],以機器學習為基礎的態(tài)勢感知系統(tǒng)和以流量回溯為代表的分析系統(tǒng)能夠及時發(fā)現(xiàn)正在進行的網(wǎng)絡攻擊,但對已存在的安全問題難以提供解決方案[2]。
現(xiàn)階段國家級氣象網(wǎng)絡的安全防護存在一定不足:第一,各類安全監(jiān)控系統(tǒng)和檢測設備主要部署于互聯(lián)網(wǎng)出口;第二,對內(nèi)部網(wǎng)絡的終端安全防護和檢測手段相對較少,僅能通過探針等設備獲取局域網(wǎng)內(nèi)部分系統(tǒng)間數(shù)據(jù)交互的信息,當終端設備出現(xiàn)異常時,無法第一時間進行定位和溯源;第三,氣象業(yè)務數(shù)據(jù)交互頻繁,探針獲取的有關日志信息數(shù)量較為龐大,傳統(tǒng)的巡檢方式無法高效地發(fā)現(xiàn)有關異常,亟待對日志信息進行篩選過濾。
文中以國家級業(yè)務數(shù)據(jù)交互的日志信息為基礎,通過機器學習的有關算法還原出現(xiàn)異常終端的網(wǎng)絡數(shù)據(jù)交互的拓撲,確定有關異常設備的位置和可能近一步受到影響的系統(tǒng);再以有關系統(tǒng)的IP為檢索條件,對有關日志信息進行過濾,通過訓練有關模型對日志的核心信息進行提取,有利于深入分析異常終端的問題根源。以上述研究為基礎,確定下一步的問題處理方案,從而在一定程度彌補原有安全防護體系結(jié)構(gòu)的不足,對提高業(yè)務網(wǎng)絡中各系統(tǒng)的安全性和可靠性有一定的幫助。
1 算法與設計
1.1 Louvain算法原理
Louvain算法是一種基于多層次優(yōu)化的算法,具有快速、準確的特點,被認為是性能最好的網(wǎng)絡或圖的發(fā)現(xiàn)算法之一[3-4]。Louvain算法中的Modularity函數(shù)是衡量發(fā)現(xiàn)算法結(jié)果質(zhì)量的重要參數(shù),能夠刻畫發(fā)現(xiàn)網(wǎng)絡的緊密程度,Modularity函數(shù)的定義如下:
(1)
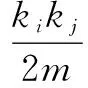
(2)
當ci=cj時節(jié)點i和節(jié)點j之間存在網(wǎng)絡連接,此時函數(shù)的值為1,當ci≠cj時函數(shù)的值為0。
參數(shù)ΔQ為模塊性改變量,其公式定義如下:
(3)
對以上公式化簡可得如下結(jié)果:
(4)
當每次聚類完成時,都需要重新計算公式中的ΔQ,當Q的值不再變化,說明所有的頂點都被分組成了一個巨型聚類或者已有的類無法進一步合并,此時計算停止,輸出此時的分組信息和Q的數(shù)值[4-5]。
1.2 Louvain算法應用設計
本次研究中,原始數(shù)據(jù)信息由序號、時間、日志類型、源IP、源端口、目的IP、目的端口和數(shù)據(jù)流量等幾個部分組成。序號為事件信息編號,時間為采集事件的具體時間,日志類型為采集的傳輸形式,源IP、源端口、目的IP、目的端口是具體傳輸和接收設備信息,數(shù)據(jù)流量是本次源IP和目的IP數(shù)據(jù)交互的數(shù)據(jù)總量。本次研究數(shù)據(jù)為14天內(nèi)不同系統(tǒng)相同時次的數(shù)據(jù)交互信息,本次算法中主要采用源IP、目的IP、源端口、數(shù)據(jù)流量為研究對象,算法具體步驟如下:
(1)對原始數(shù)據(jù)進行清洗,去除暫不使用的部分。研究中設定目的IP在惡意地址庫中或單次源IP和目的IP交互數(shù)據(jù)流量超過30 GB視為高危行為,源端口和目的端口使用存在風險的端口則視為異常行為[6-8]。
(2)將原數(shù)據(jù)轉(zhuǎn)換為N階矩陣A,當源IP和目的IP有數(shù)據(jù)交互時,對應的aij為1,否則aij為0[9]。
(3)初始分配每個頂點到其自己的團體,隨后計算整個網(wǎng)絡的模塊性Q。
(4)當每個點對至少被一條單邊鏈接,如果有兩個點融合到一起,則計算由此造成的模塊性改變ΔQ。
(5)取ΔQ出現(xiàn)最大增長的改變量,然后融合。再為這個聚類計算新的模塊性Q,并記錄下來。
(6)當所有的頂點都被分組成一個巨型聚類或者被分成的類之間已無任何關系時,整個計算過程結(jié)束。隨后檢查這個過程中的記錄,找到其中返回最高的聚類模式和此時的最大值Q。
(7)統(tǒng)計各系統(tǒng)與其他業(yè)務的鏈接情況,形成匯總表。
(8)將研究結(jié)果與已知惡意IP、高風險端口列表進行對比,當具體業(yè)務訪問惡意IP或流量異常時,則相關終端標記為紅色;當源IP通信端口為高風險端口,則相應終端標記為藍色;其余正常終端標記為綠色。
(9)根據(jù)步驟(7)和步驟(8)的結(jié)果生成最終數(shù)據(jù)交互圖。
1.3 TF-IDF算法原理
TF-IDF(term frequency-inverse document frequency,詞頻-逆向文件頻率)算法是一種用于檢索與探勘的常用加權(quán)技術。TF-IDF是一種統(tǒng)計方法,用以評估一個字詞在一個文件集或一組文字庫中的重要程度[10]。字詞的重要性一般隨著它在文件中出現(xiàn)的次數(shù)成正比,同時隨著它在語義庫中出現(xiàn)的頻率成反比。對于某一特定詞語的逆向文件頻率,可以由總文件數(shù)目除以包含該詞語之文件的數(shù)目,再將得到的商取對數(shù)得到最終結(jié)果。
TF-IDF的基本原理是當某個詞或短語在一段文字中出現(xiàn)的頻率較高,并且在其他文章中很少出現(xiàn),那么就認為這個詞或短語具有很好的類別區(qū)分能力,適合用來做分類[11]。IDF的主要思想是當包含詞條t的文檔越少,權(quán)重越小,當IDF變大時說明詞條t具有很好的類別區(qū)分能力。實際的文字信息中,當一個詞條在一個類的文檔中頻繁出現(xiàn),說明該詞條能夠很好地代表這個類的文本的特征,這樣的詞條將被賦予較高的權(quán)重,可作為該類文本的特征詞以區(qū)別于其他類文檔[12-14]。在算法方面,TF-IDF算法采取如下方式進行計算:
首先,對于特定的詞語ti,其在文本中的重要性可以表示為:
(5)
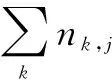
然后,逆向文件頻率idfi可由公式(6)計算取得:
(6)
其中,|D|為文件中文字的總數(shù),|{j:ti∈dj}|為包含ti的文件數(shù)目。
最后,計算最終結(jié)果tfidfi,j,由公式(7)求得最終結(jié)果。
tfidfi,j=tfi,j×idfi
(7)
1.4 TF-IDF算法應用設計
本次研究中,采用anaconda作為集成開發(fā)環(huán)境,jieba作為中文分詞工具,TfidfVectorizer作為詞頻逆文檔頻率向量化模型,Logistic回歸分析作為權(quán)重調(diào)節(jié)的參考依據(jù)[15]。
在算法方面,算法和應用的步驟如下:
(1)采集原有各系統(tǒng)同時段的日志信息。
(2)使用jieba作為中文分詞工具,對監(jiān)控信息做分詞處理。
(3)采用TF-IDF算法進行判斷[16]。
(4)通過Logistic回歸分析對權(quán)重進行調(diào)節(jié)[17]。
(5)重復步驟3和步驟4中的過程。
(6)分別用90%的數(shù)據(jù)進行訓練,10%的數(shù)據(jù)進行驗證。
(7)用訓練結(jié)果對日志信息進行分析驗證,對有關結(jié)果進行分析。
2 實驗結(jié)果與分析
2.1 終端數(shù)據(jù)交互研究結(jié)果與分析
研究中采用1.2節(jié)的設計并進行實驗驗證,基于某氣象業(yè)務系統(tǒng)的部分實驗結(jié)果如圖1所示。
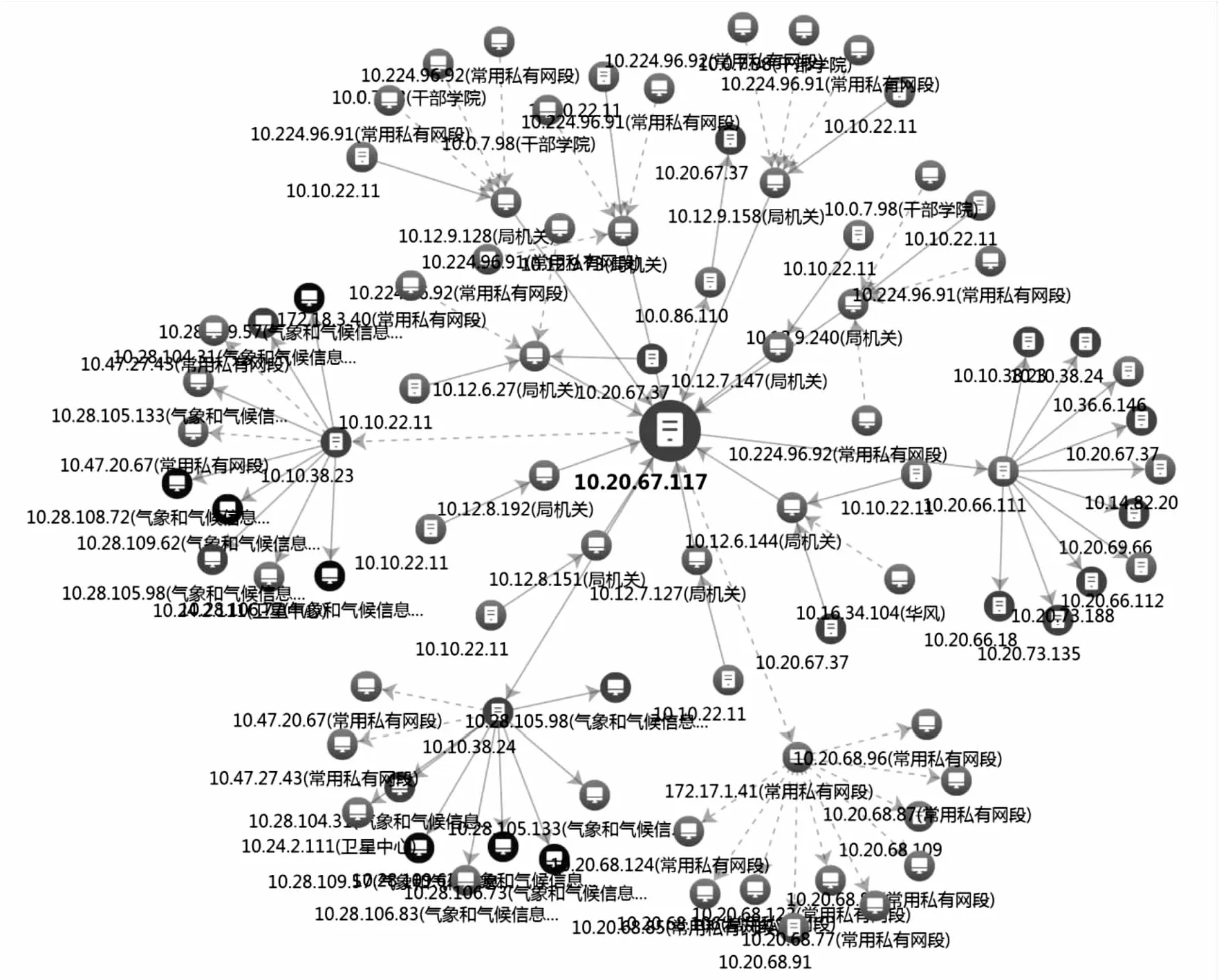
圖1 數(shù)據(jù)業(yè)務交互實驗結(jié)果
由實驗結(jié)果可知,和該業(yè)務存在數(shù)據(jù)交互的系統(tǒng)中有7臺終端存在高危異常,與其進行通信的網(wǎng)絡結(jié)構(gòu)能夠清晰地進行表示,對于及時發(fā)現(xiàn)安全問題有很好的幫助作用。通過對其中存在高危的終端,以該終端的IP作為過濾條件生成對應數(shù)據(jù)交互拓撲,某高危異常終端的數(shù)據(jù)交互如圖2所示。通過圖2可以清晰地發(fā)現(xiàn)其他存在安全風險的主機,分析該IP的終端日志等可以逐步進行溯源,確定風險來源,同時消除對應風險。

圖2 基于Louvain算法生成的某高危終端數(shù)據(jù)交互圖
2.2 告警信息數(shù)據(jù)分析結(jié)果與分析
本次實驗中,以90%的原始數(shù)據(jù)進行訓練,10%的數(shù)據(jù)進行驗證,部分訓練結(jié)果如圖3所示。由于標題重要性較高,因此不做任何分詞處理,日志詳細內(nèi)容中能夠提取到關鍵短句“WannaCry攻擊”、445端口攻擊“”,地址信息中提取到關鍵詞語“10.28.107.*”,同時給出有關分詞提取的可信度數(shù)值。由于日志告警形式較為統(tǒng)一,當重復出現(xiàn)告警并經(jīng)過大量訓練后,相關告警的可信性得到增加,可信度數(shù)值有一定的提高[18]。對該高危IP地址主機的行為進行分析和梳理后的結(jié)果進行匯總后,可得到如圖4所示的行為畫像[19]。
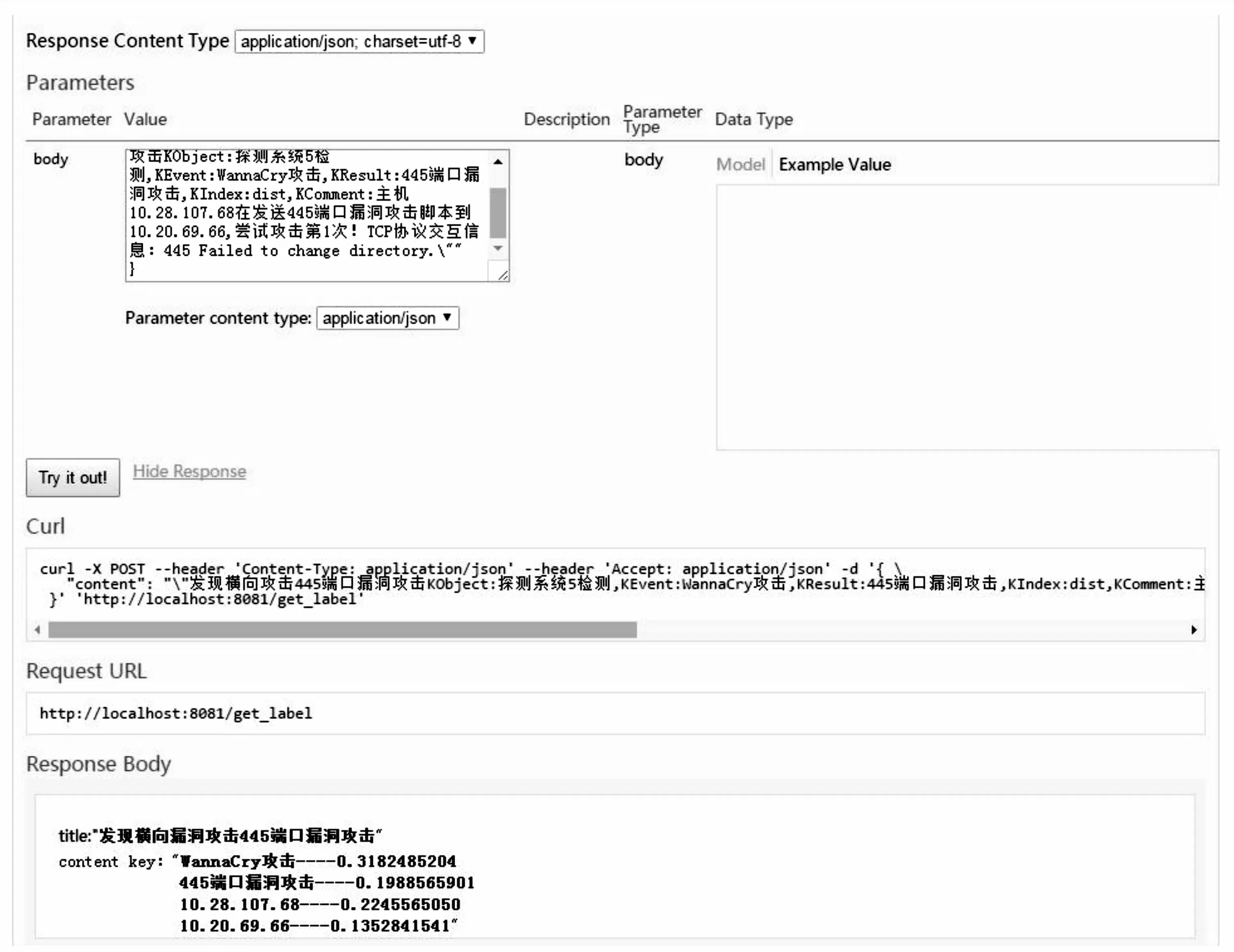
圖3 訓練結(jié)果示意圖
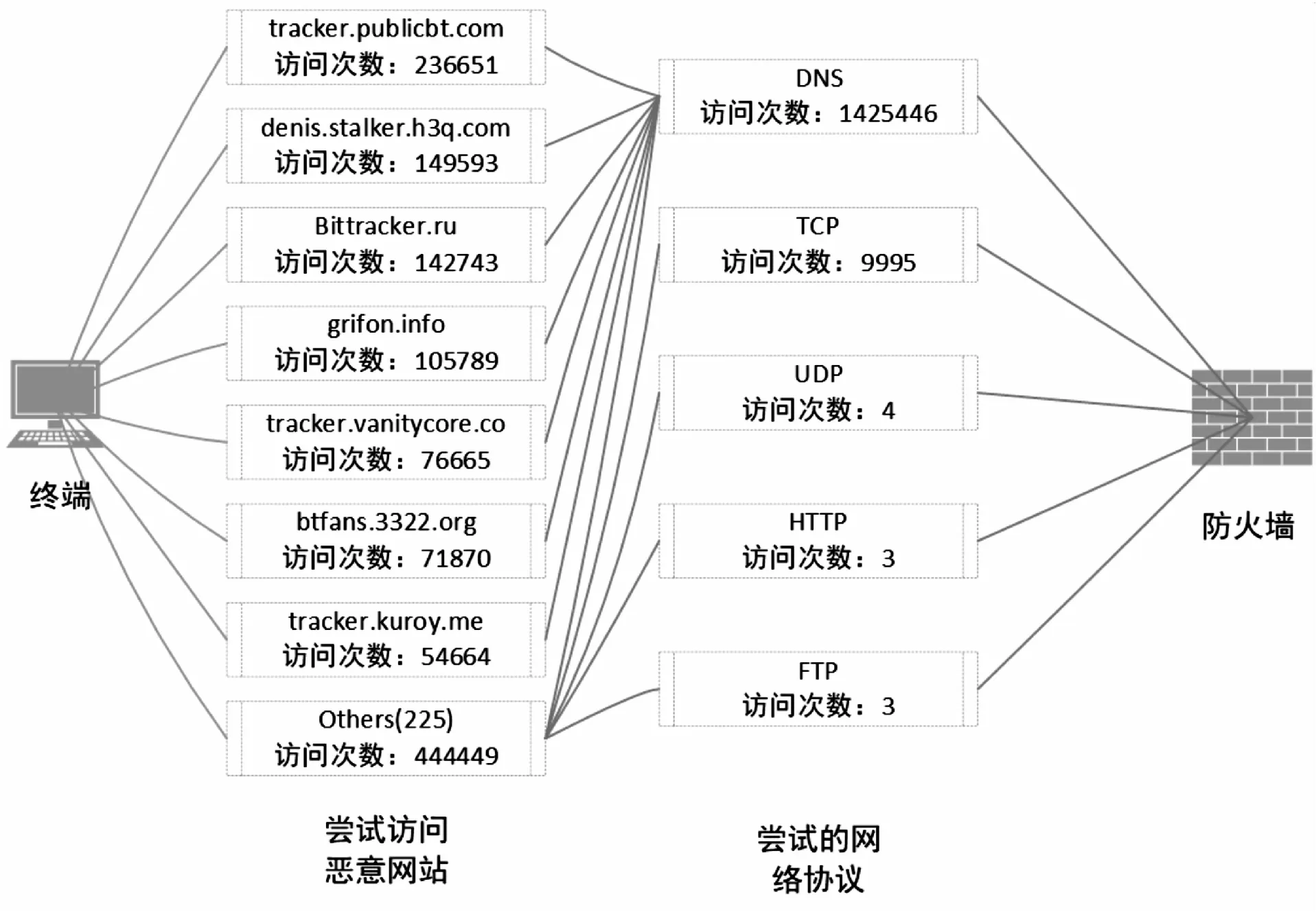
圖4 某高危用戶網(wǎng)絡行為畫像分析圖
在通過Louvain算法進行拓撲生成和告警信息關鍵信息提取后可知,圖4中的終端因未及時修補MS17-010漏洞同時未關閉445端口而被其他被控主機攻陷,攻陷后主機被植入后門并嘗試連接已知惡意網(wǎng)站并對局域網(wǎng)內(nèi)其他終端進行惡意掃描。重復利用Louvain算法和TF-IDF算法進一步分析可進行攻擊溯源并發(fā)現(xiàn)其他存在安全風險的終端存在的安全問題并確定解決方案。
3 研究應用與對比
通過機器學習算法分析和對終端安全問題進行處理,對2018年和2019年同期安全事件告警數(shù)量進行對比,安全事件數(shù)量出現(xiàn)較為明顯的下降,業(yè)務終端的安全性得到大幅提高。應用前后安全事件數(shù)據(jù)對比如圖5所示。
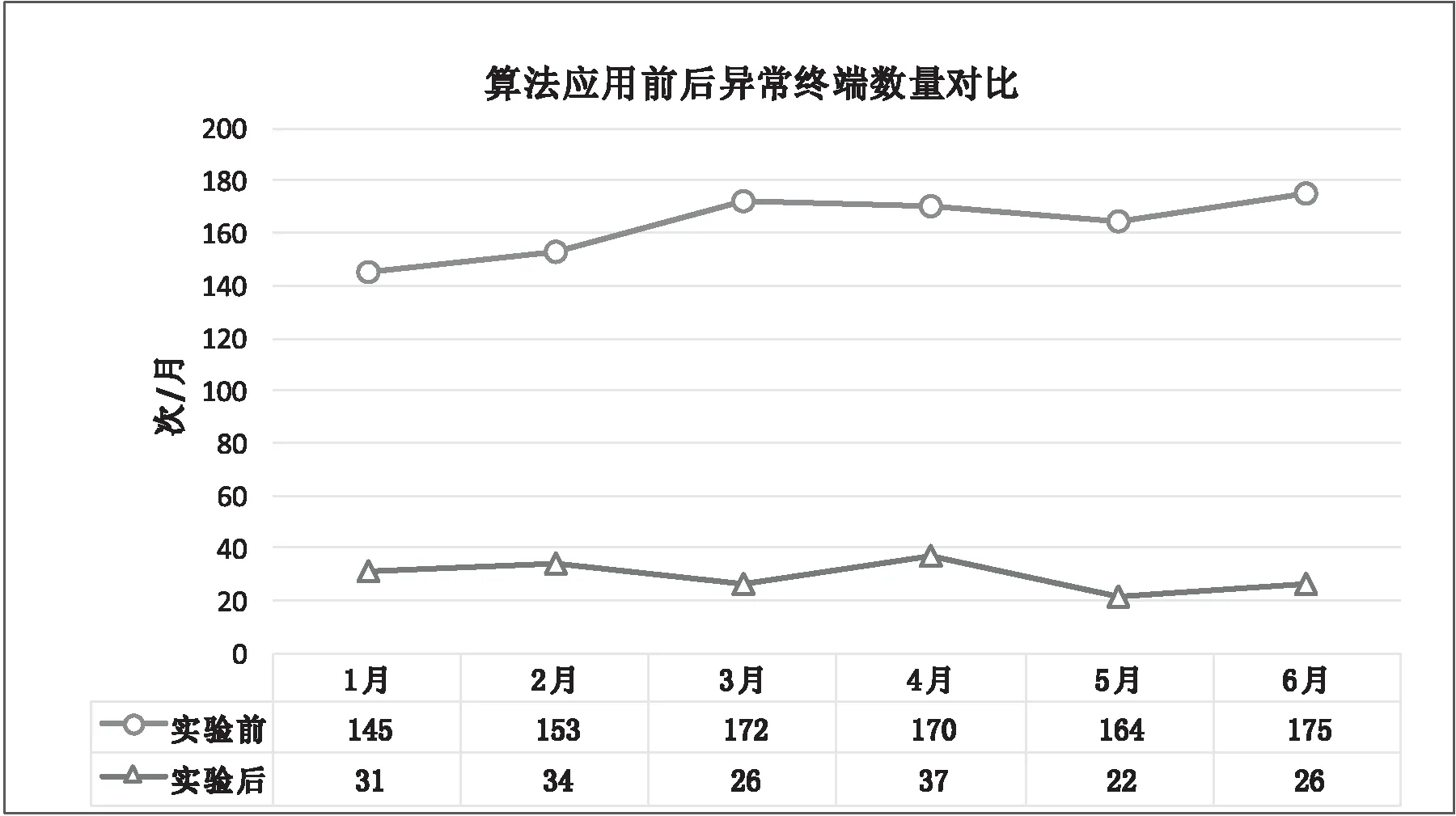
圖5 算法應用前后異常終端數(shù)量對比
4 結(jié)束語
該研究通過機器學習的有關算法對氣象網(wǎng)絡安全數(shù)據(jù)進行了分析,實現(xiàn)了對氣象網(wǎng)絡存在安全隱患的終端進行定位和日志信息關鍵短句的提取,進而對有關終端安全問題進行修復,一定程度上解決了對業(yè)務終端安全監(jiān)控不足的問題,提高了氣象網(wǎng)絡和業(yè)務終端的安全性。
該研究對國內(nèi)氣象系統(tǒng)安全數(shù)據(jù)分析具有一定的參考價值和借鑒意義。
同時,該研究還存在一些不足:整體分析過程中還無法做到全自動化地完成,部分步驟需要人工干預;個別安全信息重要內(nèi)容較多,通過現(xiàn)有算法無法做到全部提取,未來的研究將針對以上的不足繼續(xù)進行探究與完善。
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
中華手工(2017年2期)2017-06-06 23:00:31
山東工業(yè)技術(2016年15期)2016-12-01 05:31:22
中外會展(2014年4期)2014-11-27 07:46:46
中國中醫(yī)藥現(xiàn)代遠程教育(2014年11期)2014-08-08 13:23:44
終身教育研究(2014年5期)2014-02-28 01:23:06
建筑創(chuàng)作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
祝您健康(1987年2期)1987-12-30 09:52:28
