基于改進FCOS 的擁擠行人檢測算法
2021-09-11 03:13:58齊鵬宇王洪元張繼朱繁徐志晨
智能系統(tǒng)學報 2021年4期
齊鵬宇,王洪元,張繼,朱繁,徐志晨
(常州大學 信息科學與工程學院,江蘇 常州 213164)
行人檢測屬于計算機視覺領(lǐng)域一個重要的基礎(chǔ)研究課題,對于行人重識別、自動駕駛、視頻監(jiān)控、機器人等領(lǐng)域有重要的意義[1-3]。而行人檢測領(lǐng)域在實際場景下面臨著行人交疊、遮擋等問題,此類問題依然困擾很多研究者,也是目前行人檢測面臨的巨大挑戰(zhàn)。
在現(xiàn)有的目標檢測算法[4]中,兩階段目標檢測器(如Faster R-CNN[5]、R-FCN[6]、Mask RCNN[7]、RetinaNet[8]、Cascade R-CNN[9])精度高但速度稍慢,單階段目標檢測器(如YOLOv2[10]、SSD[11])速度快但精度稍低。Zhi 等[12]認為錨框(anchor)的縱橫比和數(shù)量對檢測性能影響較大,在需要預設候選框的檢測算法中,這些anchor 相關(guān)參數(shù)需要進行精準的調(diào)整。而在多數(shù)的兩階段算法中,由于anchor 的縱橫比不變,模型檢測anchor 變化較大的候選目標時會遇到麻煩,特別是對于小目標的物體。多數(shù)檢測模型需要在不同的檢測任務場景下重新定義不同的目標尺寸的anchor,這是因為模型預定義的anchor 對模型性能影響較大。在訓練過程中,大多數(shù)的anchor 被標記為負樣本,而負樣本的數(shù)量過多會加劇訓練中正樣本與負樣本之間的不平衡。基于無預設候選框(anchor-free)的檢測算法容易造成極大的正負樣本之間不平衡,檢測的精度也不如anchor-base算法。而近年來的全卷積網(wǎng)絡(fully convolutional network,F(xiàn)CN[13])在眾多計算機視覺的密集預測任務中取得了好的效果,例如語義分割、深度估計[14]、關(guān)鍵點檢測[15]和人群計數(shù)[16]等。由于預設候選框的使用,兩階段檢測算法取得了好的效果,這也間接導致了檢測任務中沒有采用全卷積逐像素預測的算法框架。而FCOS[12]首次證明,基于FCN的檢測算法的檢測性能比基于預設候選框的檢測算法更好。FCOS 結(jié)合two-stage 和one-stage 算法的一些特點逐像素檢測目標,實現(xiàn)了在提高檢測精度的同時,加快了檢測速度。
由于擁擠場景下行人目標會出現(xiàn)交疊、遮擋和行人目標偏小等問題,本文提出新的特征提取網(wǎng)絡提取更具判別性行人特征。對于FCOS 檢測算法,行人檢測中行人尺度問題對模型性能的影響較大,針對該問題,本文改進多尺度預測用于檢測小目標行人,有效地解決了行人目標偏小、擁擠等場景下行人檢測精度不高的問題。
1 相關(guān)工作
1.1 FCOS 框架
FCOS 首先以逐像素預測的方式對目標進行檢測,無需設置anchor 的縱橫比,然后利用多級預測來提高召回率并解決訓練中重疊預測框?qū)е碌钠缌x,這種方法可以有效提高擁擠場景下行人檢測精度,緩解行人擁擠而導致的檢測困難的問題。實際上,諸如Unitbox[17]之類基于DenseBox[18]的anchor-free 檢測算法,難以處理重疊的預測框而導致召回率低的問題,該系列的檢測算法不適合用于一般物體檢測,F(xiàn)COS 的出現(xiàn)打破這一局面。FCOS 表明,使用多級特征金字塔網(wǎng)絡(feature pyramid networks,FPN[19])預測可以提高召回率,提高檢測精度。
FCOS 在訓練中損失定義如下:
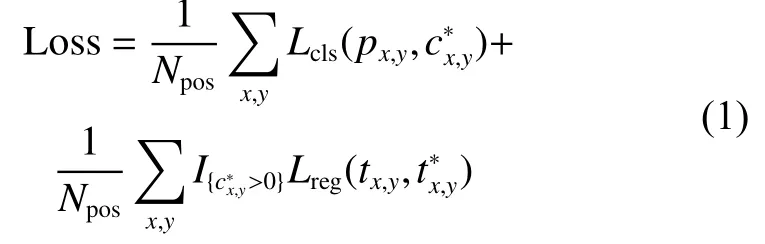
式中:x、y表示特征圖上的某一位置;px,y表示預測分類分數(shù)表示真實分類標簽;tx,y表示回歸預測目標位置表示真實目標位置,Lcls是Focal Loss 分類損失,Lreg是IOU Loss 回歸損失,并且在預先的實驗中發(fā)現(xiàn),擁擠行人檢測任務中,I OU Loss效果要稍優(yōu)于GIOULoss[20]。Npos表示正樣本的個數(shù),表示激活函數(shù),當時為1,否則為0。
此外,F(xiàn)COS 還具有獨特的中心度分支預測,可以抑制低質(zhì)量框的比例。由于逐像素預測,很多像素點雖然處于真值框內(nèi),但是越接近真值框中心的像素點預測出高質(zhì)量預測框的概率也越大,因此提出預測中心度損失函數(shù),如式(2)所示:

式中:l?、 r?、t?、b?分別表示當前像素點到真值框邊界的距離,這里使用開方來減緩中心損失的衰減。中心損失值在范圍[0,1],因此使用二值交叉熵(BCE)損失進行訓練,將中心度損失加到訓練損失函數(shù)式(1) 中。當回歸中心在樣本中心時,中心度損失會盡可能的接近1,而當偏離時,中心度損失會降低。測試時,通過將預測框的中心損失與相應的分類分數(shù)相乘來計算最終分數(shù),且該分數(shù)用于對檢測到的預測框質(zhì)量進行排序。因此,中心度可以降低遠離目標中心的預測框的分數(shù),再通過最終的非極大值抑制(non-maximum suppression,NMS)過程可以過濾掉這些低質(zhì)量的預測框,從而顯著提高行人檢測性能。相比基于預設候選框的一類檢測算法,F(xiàn)COS 算法實現(xiàn)更好的檢測性能。
1.2 原始FCOS 特征提取網(wǎng)絡
如圖1 所示,F(xiàn)COS 算法的特征提取網(wǎng)絡采用主干網(wǎng)絡(Backbone) 加上FPN,Backbone 選用ResNet[21]提取特征,在FPN 中,P3、P4、P5分別由C3、C4、C5橫向連接產(chǎn)生,P6、P7由P5、P6通過步長為2 的卷積產(chǎn)生。每層檢測不同尺度大小的目標,Pi層檢測當前像素點處滿足條件的目標,目標公式定義如下:
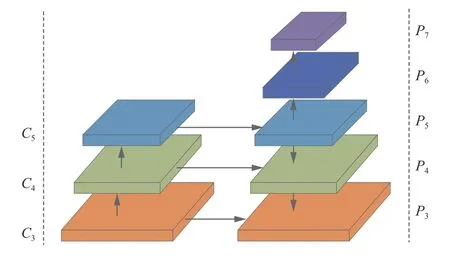
圖1 FCOS 特征提取網(wǎng)絡Fig.1 FCOS feature extraction network
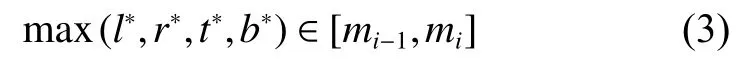
式中:l?、r?、t?、b?分別表示當前像素點到真值框邊界的距離;[mi?1,mi]表示Pi層回歸目標范圍,m2、m3、m4、m5、m6和m7分別設置為0、64、128、256、512 和 ∞,其中 ∞ 表示無窮大。這是一個非常有創(chuàng)造性的想法,這樣的設計使得FCOS 檢測算法是一個多尺度的FPN 檢測算法。
2 基于FCOS 的行人檢測
2.1 主干網(wǎng)絡VoVNet
深度學習中,特征提取網(wǎng)絡對于模型有著非常大的影響,針對不同的數(shù)據(jù)集可以直接影響其檢測性能。針對ResNet 不足,本文運用VoVNet作為行人特征的提取網(wǎng)絡。
DenseNet[22]在目標檢測任務上展示出了較好的效果,特別是基于anchor-free 的目標檢測模型,這是因為相比于ResNet,DenseNet 通過特征不斷疊加達到好的效果,其缺點是在后續(xù)特征疊加時,通道數(shù)線性增加,參數(shù)也越來越多,模型花費時間增加,影響模型速度。
VoVNet 認為在特征提取方面,中間層的聚集強度與最終層的聚集強度之間存在負相關(guān),并且密集連接是冗余的,即靠前層的特征表示能力越強,靠后層的特征表示能力則會被弱化。VoVNet[23]針對DenseNet 做出改進,提出一種新的模塊,即一次性聚合(one-shot aggregation,OSA) 模塊。OSA 模塊將當前層的特征聚合至最后一層,每一卷積層有兩種連接方式,一種方式是連接至下一層,用于產(chǎn)生更大感受野的特征,另一種方式是連接一次至最終輸出的特征圖上,與DenseNet 不同,每一層的輸出不會連接至后續(xù)的中間層,這樣的設計使得中間層的通道數(shù)保持不變。VoVNet采用更加優(yōu)化的特征連接方式,通過增強特征的表示能力,提高特征的提取能力,進而提高模型的檢測性能。
2.2 SE 模塊
本文為了更好地契合復雜的行人特征,在VoVNet上使用SE 模塊[24]加強特征表示能力,并且在特征圖上使用SE 模塊進行權(quán)重分配,使得深度特征更加多樣化。
SE 模塊首先依照空間維度來進行特征壓縮,將每個二維的特征通道變成一個實數(shù),輸出一個二維空間,它的維度與特征通道數(shù)相等,即二維空間表示對應特征通道上的分布結(jié)果。之后生成一個具有權(quán)重的二維空間,表示特征通道間的相關(guān)性。最后將對應的特征圖乘上權(quán)重特征,實現(xiàn)一個特征的權(quán)重分配,突出重要的特征,完成在通道維度上對原始特征通道上重要性的重標定。
SE 模塊類似于注意力機制,本文將其使用在VoVNet 上,如圖2 所示,在每層特征下采樣時,將特征進行SE 權(quán)重分配。根據(jù)VoVNet 的特征連接方式添加SE 模塊權(quán)重機制,本文方法可以提供更加多元化的特征,使得行人特征更好地表達,提高行人檢測的精度。并且SE 模塊可以在幾乎不增加模型時間復雜度的情況下提升模型的檢測性能。

圖2 修改后框架Fig.2 Update framework
2.3 多尺度檢測
原始模型FPN 采用5 層不同尺度回歸目標,這5 層尺度回歸的目標大小分別為[0,6 4]、[64,128]、[128,256]、[256,512]和[512,∞],分別對應FPN 中的P3、P4、P5、P6和P7。針對行人目標的特點,本文發(fā)現(xiàn),不論是在常用的行人數(shù)據(jù)集中,還是在真實檢測場景中,行人檢測的難點在于擁擠行人和小目標行人的檢測。對于FCOS 模型,每層每個像素點都會回歸固定尺度大小范圍內(nèi)的目標。相對地,如果目標行人擁擠在某個尺度范圍內(nèi),將會使得檢測層的任務過重,導致檢測效果降低,此問題也是影響模型性能效果的原因之一,在多目標檢測場景中會導致FCOS 模型的檢測性能稍有降低,同時也說明,當檢測任務復雜,檢測目標數(shù)量較多時,本文提出的多尺度檢測會使FCOS 檢測性能提高。
如圖2 所示,減小P3層的回歸尺度,設置P3層回歸尺度為[32,64],減少P3層的檢測任務量;增加P2層,P2層由C2層橫向連接和P3層向下連接組成,P2層回歸尺度為[0,32]的目標,這樣的網(wǎng)絡設計既能減少P3層的回歸目標數(shù),也能更好地利用特征檢測小目標行人,提高行人檢測精度。在最終的FPN 上,本文的方法在FPN 上擁有6 層特征圖以檢測6 個不同尺度范圍的目標。
總體網(wǎng)絡框架如圖3 所示,相較于未改進FCOS 算法,預測特征圖由5 個增加到6 個,而后對特征圖上每個點進行逐像素預測,每個點均需預測目標回歸框、目標類別、目標中心度,以上3 種預測結(jié)果對應圖3 中3 個預測分支,假設當前特征圖大小為W×H,則有W×H像素點需要進行預測。
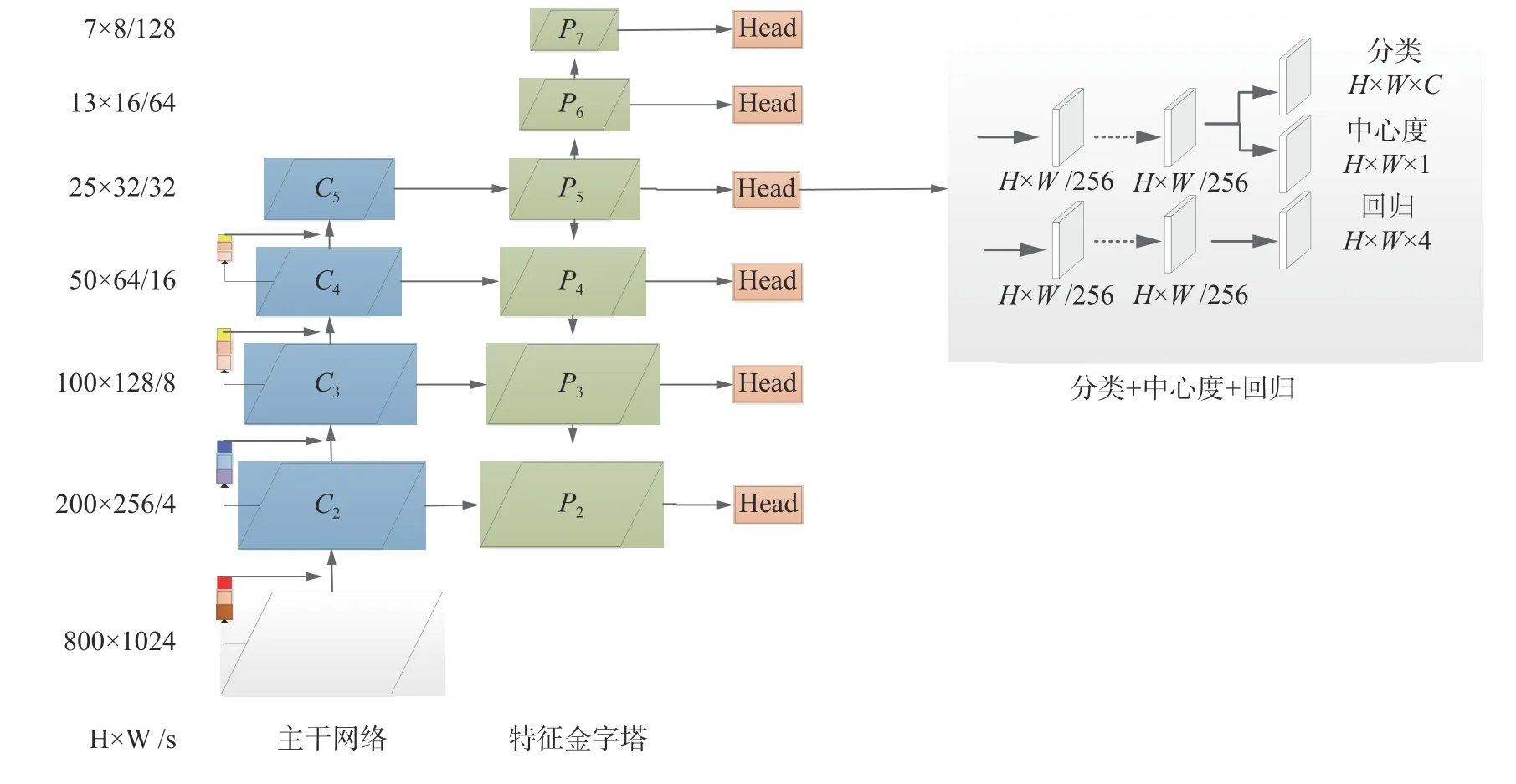
圖3 總體框架Fig.3 Final framework
3 數(shù)據(jù)集和評估
本文實驗主要使用CrowdHuman[25]和Caltech 行人數(shù)據(jù)集。行人數(shù)量多、場景擁擠是行人檢測中一個巨大的挑戰(zhàn),針對這一問題,曠視發(fā)布CrowdHuman 數(shù)據(jù)集,用于驗證檢測算法在密集人群行人檢測任務中的性能。CrowdHuman 數(shù)據(jù)集中15 000、4 370 和5 000 個圖片,分別用于訓練、驗證和測試。針對CrowdHuman 數(shù)據(jù)集,本文只使用全身區(qū)域標注用于訓練和評估,由于還未公布測試集,參考相關(guān)文獻[25-26]后,實驗結(jié)果在驗證集上進行測試。Caltech 行人數(shù)據(jù)集時長約為10 h 城市道路環(huán)境拍攝視頻,數(shù)據(jù)集中隨機分配訓練集、測試集、驗證集,其對應比例為0.75∶0.2∶0.05,3 個集相互獨立,測試集圖片約為24 438 張。
本文采用MR?2(miss rate)和AP 的評估準則,MR?2表示在9 個FPPI(false positive per image)值下(在值域[0.01,1.0]以對數(shù)空間均勻間隔)的平均丟失率值,F(xiàn)PPI 定義如下:

式中:N表示圖片的數(shù)量;FP 表示未擊中任意一個真值框的預測框數(shù)量。MR?2是目前衡量行人檢測一個非常重要的指標,也是本文主要采用的評價指標。其數(shù)值越低說明行人檢測模型性能越好。
AP 表示平均精度,PR(Precision-Recall)曲線所圍成的面積即為AP 值大小,AP 值越大檢測精度越高,其中AP、Recall、Precision 計算公式如下:
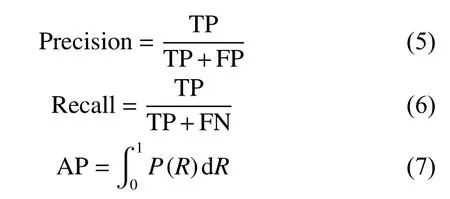
式中:TP 是檢測出正樣本的概率;FN 是正樣本檢測出錯誤樣本的概率;FP 是負樣本檢測出正樣本的概率。
4 實驗
本文實驗環(huán)境為Ubuntu18.04、Cuda10 和Cudnn7.6,使用4 塊2080Ti 的GPU,每個GPU 有11G 內(nèi)存,由于FCOS 算法要求較高,存在內(nèi)存不夠的問題,實驗通過線性策略[27]調(diào)整了batch_size 大小和IMS_PER_BATCH 的數(shù)量。其余參數(shù)沿用FCOS 在COCO 數(shù)據(jù)集上基礎(chǔ)參數(shù)配置,算法基于detectron 框架。
4.1 CrowdHuman 數(shù)據(jù)集實驗結(jié)果
如表1 消融實驗所示,其中6stage 表示多尺度檢測方法,SE 表示SE 模塊。在FCOS 上采用VoVNet 作為Backbone 起到了極大的提升作用,相較于主干網(wǎng)絡為ResNet,AP50提升11.2%。在FPN 中多添加一個尺度的回歸層,對于行人檢測的效果有極大的提升,這是因為密集的行人檢測受尺度變化影響較大。相較于原始FCOS 方法,本文方法在指標AP50上提升了15.0%。針對于不同主干網(wǎng)絡,S E 模塊在指標A P50上有0.2%~0.3%的提升,說明SE 模塊能增強行人特征提取能力。模型由5 個尺度增加到6 個尺度,指標AP50提升3.5%,并且對于模型檢測小目標行人有著極大的提升,可以看到指標APS提升8.5%,實驗結(jié)果也印證多尺度改進能有效地提升模型檢測小目標行人的性能。
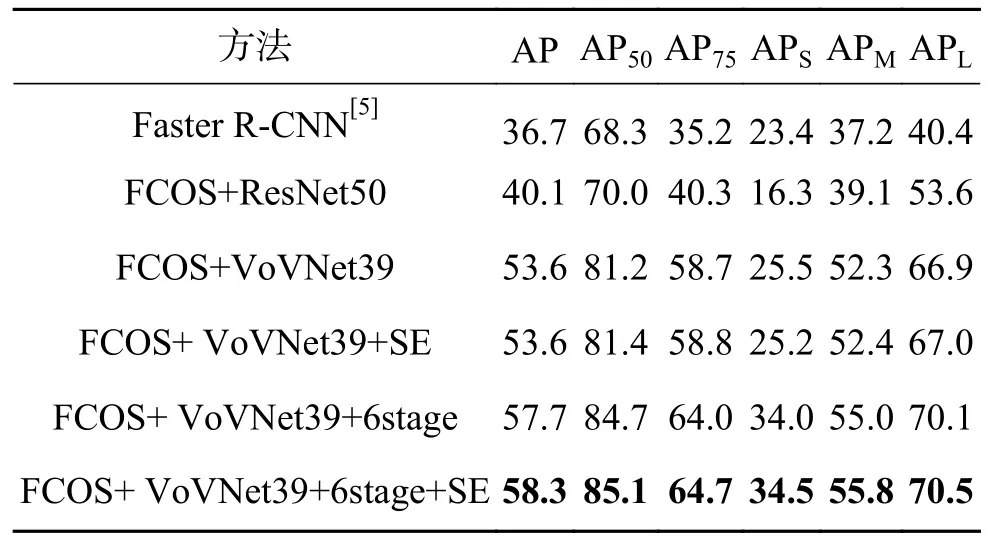
表1 CrowdHuman 數(shù)據(jù)集APTable 1 AP on CrowdHuman
CrowdHuman[25]數(shù)據(jù)集中采用指標MR?2,本文采用相同指標并對比了CrowdHuman[25]中部分實驗,表2 可以看到,在CrowdHuman 數(shù)據(jù)集上,通過消融實驗表明:采用VoVNet 相較于采用ResNet,指標MR?2降低26.91%。擁有SE 模塊的檢測模型相較于沒有SE 模塊的檢測模型,指標MR?2降低0.9%。改進多尺度回歸后的檢測模型相較于未改進的檢測模型,指標 MR?2降低6%。本文提出的方法相較于原始方法,指標MR?2降低了33.62%。實驗結(jié)果證明,本文的方法在擁擠場景下的行人檢測效果提升較為明顯。

表2 CrowdHuman數(shù)據(jù)集MR?2Table 2 MR?2onCrowdHuman
如表3 所示,針對CrowdHuman 數(shù)據(jù)集,NMS 的IOU 閾值設定也是不同的,原始FCOS 算法在COCO 數(shù)據(jù)集上IOU 閾值設置為0.7,而針對擁擠行人場景,本文發(fā)現(xiàn)IOU 閾值設置為0.5 時,模型整體性能較好。圖4(a)表示PR 曲線圖,圖4(b)表示MR-FPPI 曲線,可以清晰地看到本文方法總體上提升較大。在采用了VoVNet后,對模型性能有了極大的提升,說明VoVNet 更加適合于FCOS 在擁擠場景下提取行人特征。多尺度檢測方法在擁擠場景下的行人檢測也是有效的,提升效果明顯。
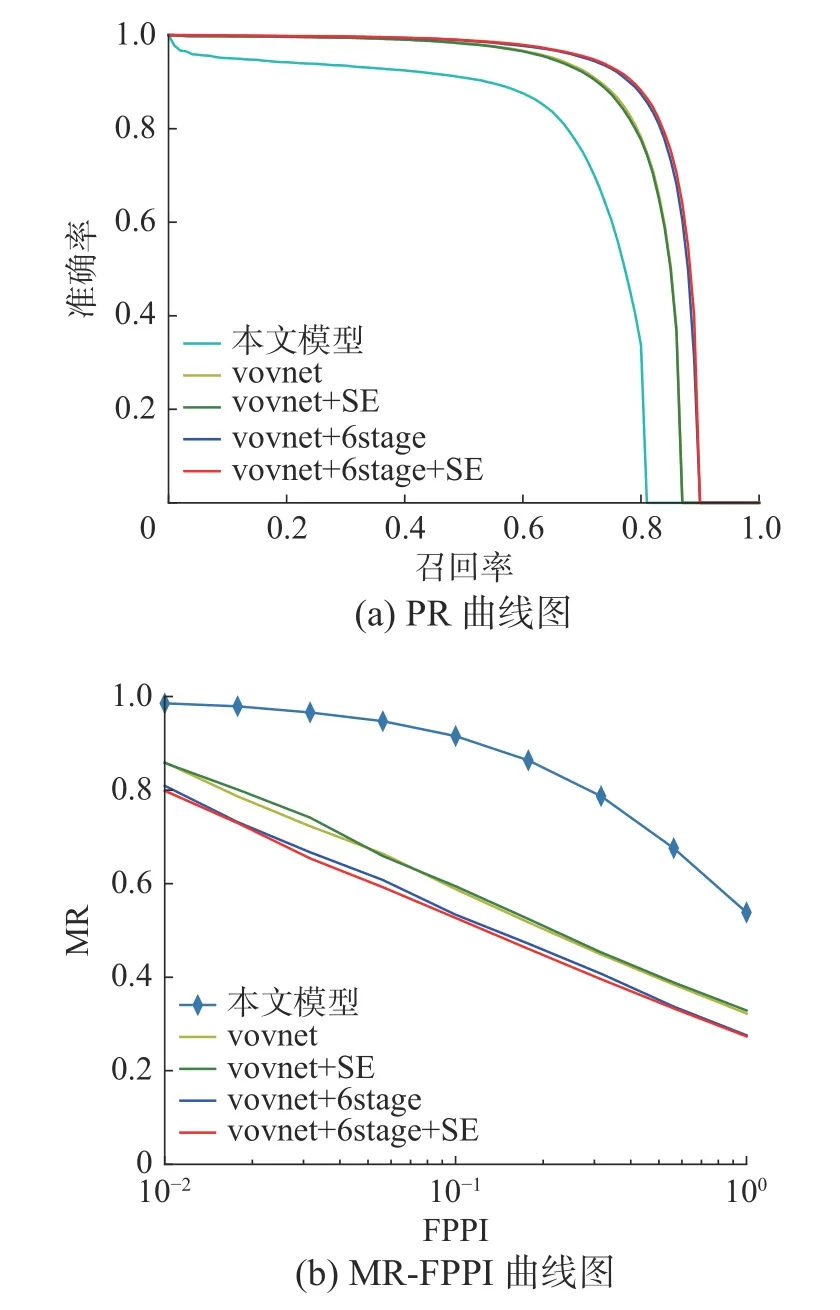
圖4 CrowdHuman 曲線圖Fig.4 CrowdHuman curves
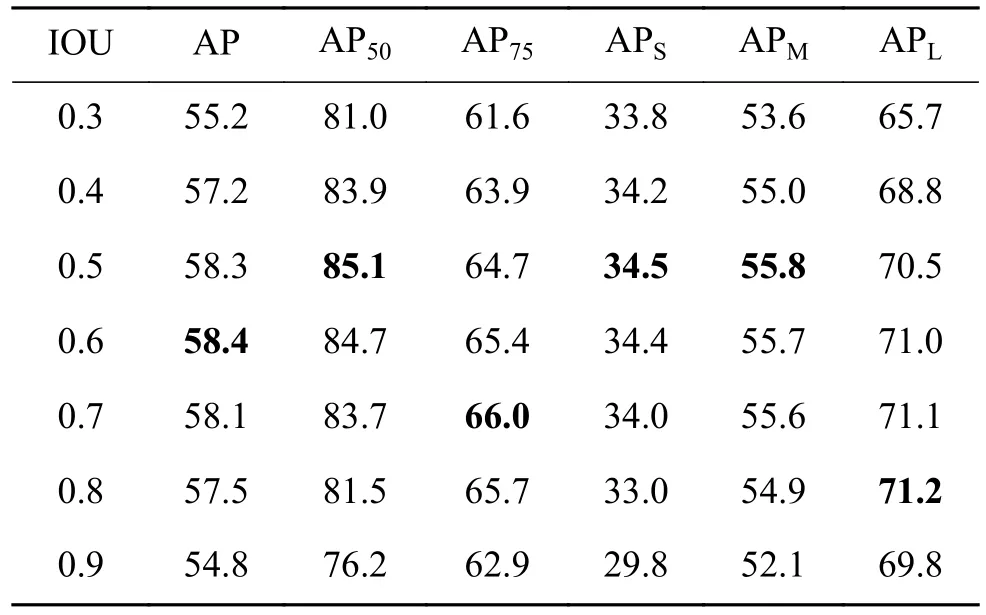
表3 CrowdHuman 數(shù)據(jù)集IOU 閾值Table 3 IOU threshold on CrowdHuma
4.2 Caltech 數(shù)據(jù)集結(jié)果
如表4 所示,在車載攝像頭的行人數(shù)據(jù)集Caltech 上本文提出的方法也有一定提升,相較于原始YOLOv2 方法,AP 實現(xiàn)了2% 的提升。在Caltech 數(shù)據(jù)集上的提升,說明本文模型的魯棒性較好。

表4 Caltech 行人數(shù)據(jù)集Table 4 Caltech pedestrian datasets
4.3 實際場景檢測結(jié)果
本文的模型使用CrowdHuman 訓練集進行訓練,在實際場景下的檢測也有不錯的效果,本文挑選出實際場景下一張室內(nèi)行人和一張室外行人進行檢測。因為本文算法無需設置anchor 的尺寸和縱橫比,所以在實際場景中的行人檢測魯棒性較好。如圖5 所示,圖5(a)、(c)表示原始FCOS 方法在擁擠行人中的效果,圖5(b)、圖5(d)表示本文方法的最終效果,可以看到,原始FCOS可以較好地檢測出圖片中的行人,漏檢率較低,但是仍存在偽正例,相比于圖5(b),可以看到圖5(a)右上角小目標行人未檢測出來,遠處的行人檢測效果也不如圖5(b)的檢測效果,而相比于圖5(d),可以看到圖5(b) 右邊出現(xiàn)置信度為0.64 的錯誤預測框。本文提出的方法可以較好地檢測行人,減少FP 出現(xiàn)的情況,在實際擁擠場景下能較好地檢測目標行人。但當行人目標交疊時,或者對于有遮擋的行人,檢測的效果大部分僅能檢測出可視的部分,無法將全身區(qū)域標注出來,導致與真值框交并比的值較低,被視為負類。這也是目前本文方法面臨的主要問題之一。

圖5 實際場景檢測效果Fig.5 Actual scene detection effect
5 結(jié)束語
針對行人目標檢測中行人擁擠、目標偏小等問題,本文提出一種基于FCOS 框架的行人檢測算法。通過融入新的 Backbone 并且在 FPN 中添加一層P2層,實現(xiàn)行人目標的多尺度檢測。通過融入SE 模塊進行特征的權(quán)重分配,更好地提取行人特征,提高行人檢測精度。本模型方法無需設置anchor 縱橫比等參數(shù),參數(shù)設置少。相較于目前先進方法,可以達到有較強競爭力的檢測效果。在實驗中也發(fā)現(xiàn),本文提出的方法受行人深度特征影響較大,如何在擁擠遮擋等實際場景下進行更高精度行人檢測是我們進一步要研究的內(nèi)容。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
