教育數(shù)據(jù)的可視化研究與設(shè)計
2021-09-10 03:59:17肖永財李社蕾
科技風(fēng) 2021年25期
肖永財 李社蕾

摘 要:針對于教育中數(shù)據(jù)處理難度大的問題,提出一種針對于教育數(shù)據(jù)可視化的處理方法。獲取數(shù)據(jù)后,對數(shù)據(jù)先進(jìn)行指標(biāo)分類,接著使用Python和Excel對數(shù)據(jù)進(jìn)行清洗,再接著結(jié)合機(jī)器學(xué)習(xí)對清洗后的數(shù)據(jù)分析,最后將分析出來的數(shù)據(jù)以應(yīng)對不同場景的可視化圖表將數(shù)據(jù)展示出來。
關(guān)鍵詞:數(shù)據(jù)清洗;機(jī)器學(xué)習(xí);數(shù)據(jù)處理;可視化
1 緒論
隨著科技的不斷發(fā)展,計算機(jī)不斷快速更換和替代,互聯(lián)網(wǎng)用戶數(shù)量也是指數(shù)性的爆發(fā)增長。計算機(jī)性能的不斷提高,在許多固定化的處理上,計算機(jī)都比人處理得更快更準(zhǔn)確。在許多方面,人們都開始使用計算機(jī)進(jìn)行處理,以達(dá)到更高的工作效率以及更少的失誤出現(xiàn)。
數(shù)據(jù)可視化能夠幫助人們在數(shù)據(jù)處理時更加快速、便捷,這樣容易接近人們?nèi)粘I睿瑵M足人們實際需求,便于挖掘數(shù)據(jù)背后的內(nèi)容。在數(shù)據(jù)可視化中,使用標(biāo)記等方法,不但讓可視化更加專業(yè),也能及時找到所需數(shù)據(jù),避免數(shù)據(jù)分析錯誤。[1]
教育中的數(shù)據(jù)往往是多且復(fù)雜的,人為的對數(shù)據(jù)處理相對于機(jī)器的處理是耗時、耗力,且容易出錯的,因此通過機(jī)器處理數(shù)據(jù)是必然的。而在教育中大數(shù)據(jù)分析目的在于提高學(xué)生成績,服務(wù)教學(xué)設(shè)計。在教育中的數(shù)據(jù)中有一些重要的信息往往被人所忽視。通過大數(shù)據(jù)的分析和可視化的展示,尋找重要信息,對于提高教育精準(zhǔn)化有很大的幫助。利用大數(shù)據(jù)的學(xué)習(xí)分析向教育工作者提供有價值的信息,來達(dá)到解決一些現(xiàn)實中不太好回答的問題。
2 系統(tǒng)概述
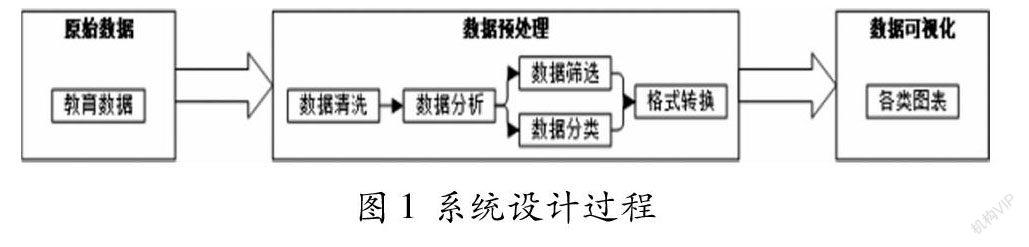
本系統(tǒng)主要用于對教育中數(shù)據(jù)的可視化,方便對教育數(shù)據(jù)的各類數(shù)據(jù)進(jìn)行分析,客觀地分析出數(shù)據(jù)蘊含的含義,用以對學(xué)生成績的提升。圖1為教育數(shù)據(jù)可視化總體設(shè)計過程。總體上來說,全過程分為原始數(shù)據(jù)提取、數(shù)據(jù)預(yù)處理、數(shù)據(jù)可視化三個主要步驟。
3 教育數(shù)據(jù)處理與可視化設(shè)計
3.1 數(shù)據(jù)處理前分析
對教育數(shù)據(jù)處理,需要選擇合適的輔助工具,對泛化的數(shù)據(jù)進(jìn)行選取和組合,將處理好的數(shù)據(jù)按指標(biāo)進(jìn)行存儲,利用合適的數(shù)學(xué)模型對處理后的數(shù)據(jù)進(jìn)行分析,最終以合適的方式展示出來。大數(shù)據(jù)處理的基本流程主要包括收集數(shù)據(jù)、數(shù)據(jù)預(yù)處理、數(shù)據(jù)存儲、數(shù)據(jù)分析處理、數(shù)據(jù)可視化等幾個步驟。在整個大數(shù)據(jù)處理流程中,數(shù)據(jù)的質(zhì)量決定了最終的處理效果,數(shù)據(jù)處理中的每一個步驟都影響著數(shù)據(jù)質(zhì)量。如果想要一個好的大數(shù)據(jù)產(chǎn)品,就要有夠大的數(shù)據(jù)規(guī)模、精準(zhǔn)的數(shù)據(jù)抽取、優(yōu)秀的數(shù)據(jù)可視化以及簡明易懂的數(shù)據(jù)解釋。
3.2 數(shù)據(jù)預(yù)處理
從數(shù)據(jù)存儲服務(wù)器中獲取的原始數(shù)據(jù),為學(xué)生姓名、ID編號、民族、成績,班級等各種數(shù)據(jù)信息。在數(shù)據(jù)預(yù)處理階段使用Python和Excel進(jìn)行數(shù)據(jù)清洗,接著以機(jī)器學(xué)習(xí)對數(shù)據(jù)進(jìn)行分析,最終將數(shù)據(jù)格式成JSON格式實現(xiàn)教育數(shù)據(jù)的可視化。
在數(shù)據(jù)預(yù)處理層面中,因?qū)τ谠紨?shù)據(jù)中會存在缺省值、格式錯誤等問題,因此使用Python和Excel進(jìn)行數(shù)據(jù)清洗。數(shù)據(jù)預(yù)處理沒有一個標(biāo)準(zhǔn)的流程,通常針對任務(wù)和數(shù)據(jù)集屬性的不同而不同。數(shù)據(jù)預(yù)處理的常用流程為:去除唯一屬性,處理缺失值,屬性編碼,數(shù)據(jù)標(biāo)準(zhǔn)化正則化,特征選擇,主成分分析[2]。如圖2所示,針對教育數(shù)據(jù)的特點,采用如下所述的步驟進(jìn)行數(shù)據(jù)預(yù)處理。
教育數(shù)據(jù)的處理流程與傳統(tǒng)數(shù)據(jù)處理流程幾乎一樣,主要區(qū)別在于:傳統(tǒng)的數(shù)據(jù)要處理大量泛化的數(shù)據(jù),教育數(shù)據(jù)已經(jīng)是較為結(jié)構(gòu)化的數(shù)據(jù),在處理數(shù)據(jù)時可以并行處理。
以機(jī)器學(xué)習(xí)中深度學(xué)習(xí)為核心的教育數(shù)據(jù)分析,替代人來完成那些簡單、枯燥的數(shù)據(jù)分析,同時按照一定的規(guī)則學(xué)習(xí),預(yù)測分析未來一些事件的可能性,進(jìn)而實現(xiàn)教育數(shù)據(jù)的最終變現(xiàn)。和聯(lián)機(jī)分析處理OLAP不同,對教育數(shù)據(jù)的深度分析主要基于大規(guī)模的半監(jiān)督學(xué)習(xí),半監(jiān)督學(xué)習(xí)模型的訓(xùn)練過程可以歸結(jié)為一個最優(yōu)化定義于大規(guī)模訓(xùn)練教育數(shù)據(jù)上的目標(biāo)函數(shù)并且通過一個循環(huán)迭代的算法實現(xiàn)。其數(shù)學(xué)描述如下:
目標(biāo)函數(shù):
θ→=argmaxθ→Σ({xi,yi}Ni=1;θ→)+Ω(θ→)(1)
迭代優(yōu)化:θ→←隨機(jī)值;
for(t=1)
{
其他操作;
θ→(t)←g(θ→(t-1),∠θθ→=θ→(t-1));
其他操作;
}
returnθ→(T);(2)
(1)迭代性:機(jī)器學(xué)習(xí)算法,最終都要求助于計算機(jī)解決,它又表現(xiàn)為在特定函數(shù)空間按某種優(yōu)化目標(biāo)去搜索一個解出來。通常問題沒有范圍解或迭代變量震蕩于某個點,對迭代變量并不能一次完成,需要進(jìn)行多次的循環(huán)迭代以及變量更改才能逼近最優(yōu)點。
(2)適應(yīng)性:深度學(xué)習(xí)的算法設(shè)計和模型設(shè)計說明可能有非最優(yōu)值解的出現(xiàn),而多次迭代的特性也會在循環(huán)的過程中產(chǎn)生一些誤差,但深度學(xué)習(xí)的適應(yīng)力較強,在這些變量最終會被允許存在,但模型最終的收斂不受影響。
以基于Hadoop架構(gòu)的分布式計算對教育數(shù)據(jù)進(jìn)行處理歸為MapReduce實現(xiàn),進(jìn)而達(dá)到簡化編程接口和提高容錯性的目的。設(shè)計兩個函數(shù)map函數(shù)和reduce函數(shù),在map階段處理原始數(shù)據(jù),過濾掉丟失、不可靠或錯誤的教育數(shù)據(jù)。接著在reduce階段,尋找出合適的數(shù)據(jù)。通過這兩個階段將一個完整的迭代運算分解為多個不間斷的map和reduce操作。通過讀寫HDFS文件,將上一輪循環(huán)運算結(jié)果傳入到下一輪完成數(shù)據(jù)的交換。
3.3 數(shù)據(jù)可視化設(shè)計
在人與計算機(jī)的相處過程中,界面是機(jī)器對人產(chǎn)生較大的一個影響因子,因此對界面的設(shè)計是一個不可忽略的因素。將界面置于用戶的控制之下,控制用戶情緒走向,保持界面的一致性是本團(tuán)隊對教育數(shù)據(jù)可視化設(shè)計的方向。工作流程上分為結(jié)構(gòu)設(shè)計、交互設(shè)計、視覺設(shè)計三個部分。
結(jié)構(gòu)設(shè)計是界面設(shè)計的核心。通過對用戶的研究與分析,設(shè)計出系統(tǒng)的整體框架。
猜你喜歡
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2022年3期)2022-08-22 00:32:50
心理學(xué)報(2022年4期)2022-04-12 07:38:02
云南化工(2021年8期)2021-12-21 06:37:54
水泵技術(shù)(2021年3期)2021-08-14 02:09:20
海洋信息技術(shù)與應(yīng)用(2020年1期)2020-06-11 12:43:56
傳媒評論(2019年4期)2019-07-13 05:49:14
時代金融(2016年27期)2016-11-25 17:51:36
科教導(dǎo)刊(2016年26期)2016-11-15 20:19:33
科學(xué)與財富(2016年28期)2016-10-14 21:19:17
中國慣性技術(shù)學(xué)報(2015年1期)2015-12-19 13:12:17
