基于語義相似的中文數據清洗方法
2021-09-09 07:36:28李碧秋王佳斌劉雪麗
現代計算機 2021年19期
李碧秋,王佳斌,劉雪麗
(華僑大學工學院,泉州 362000)
0 引言
數據清洗是發現并解決數據質量問題的過程,通常包含對相似重復數據、異常數據、不一致數據等的清洗,通過數據清洗提高數據質量,使得企業能夠通過數據挖掘與數據分析做出科學判斷。針對相似重復數據的清洗可以降低數據庫的冗余度,提高數據庫的利用率。目前關于相似重復中文文本數據清洗主要包括通過預處理將句子文本這種非結構化數據轉化為結構化數據進行處理;基于詞語共現度或基于詞袋模型的詞向量判斷文本是否相似;針對不同領域的特點制定相應的清洗算法;考慮中英文的差異,從詞語語義角度分析記錄的相似性、精確度仍不夠理想。可見已有研究對中文數據清洗效率問題、算法普適性及相似性檢測的準確度方面還有很大提升空間。所以本文在現有研究基礎上提出利用BERT模型改進文本向量化過程,將文本轉化為計算機可理解的數學表達,再求可計算的文本之間的余弦相似度,利用K-means和Canopy算法將相似重復文本聚類,實現相似重復數據的清洗。
1 文本向量化
計算機不能直接對自然語言進行計算,所以需要將文本數據轉化為向量形式,再對其做數學計算。常用的文本向量化方法包括TF-IDF[1]、Word2Vec模型[2]、GloVe模型[3]、ELMo模型[4]等,但是上述方法缺失文本語義信息、不具有上下文的“語義分析”能力。2018年谷歌AI團隊發布的BERT模型[5]在問答任務與語言推理方面展示了驕人的成績。其亮點在于,與傳統雙向模型只考慮句子左右兩側的上下文信息不同,BERT還將融合在所有層結構中共同依賴的左右兩側上下文信息。此模型主要基于雙向Transformer編碼器[6]實現。BERT模型結構如圖1所示。
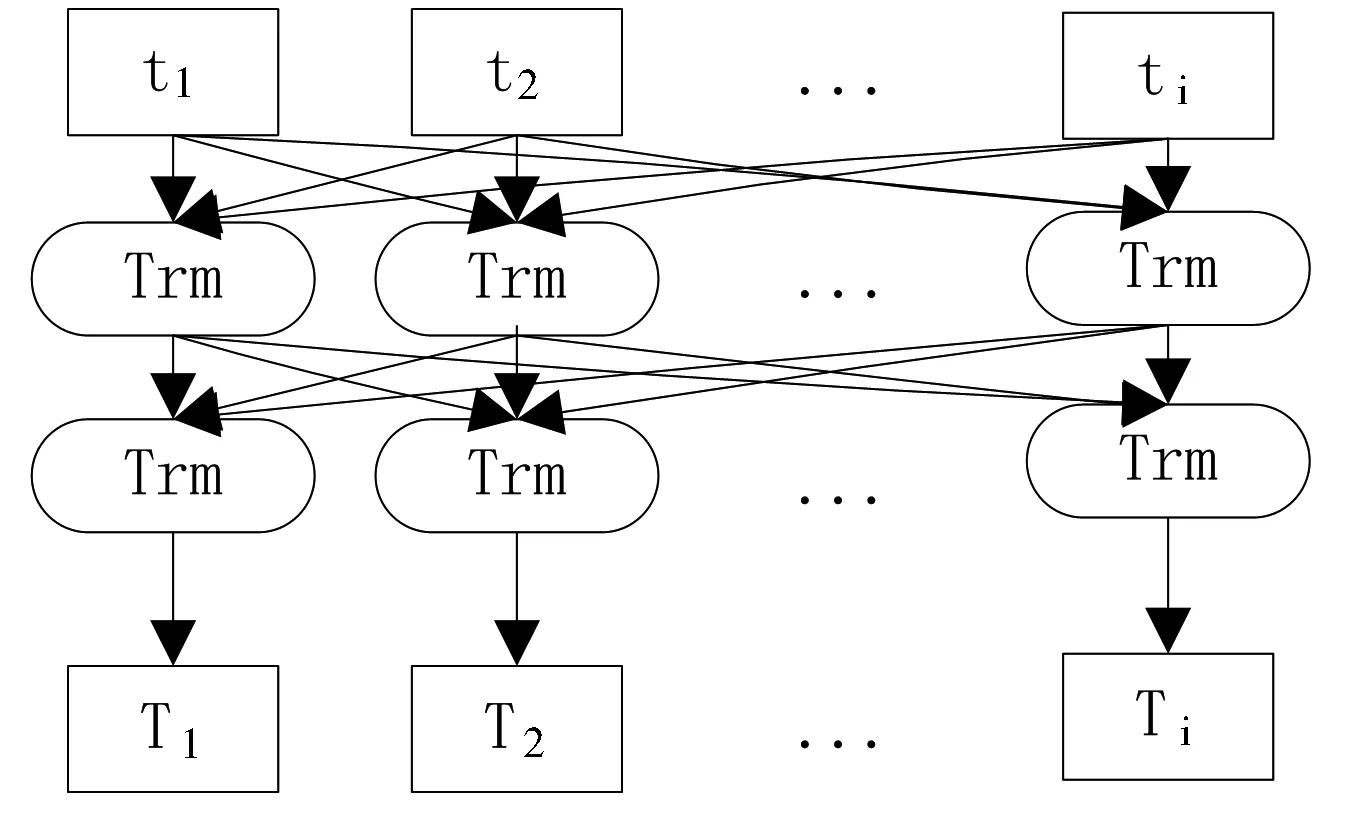
圖1 BERT模型結構
t1,t2...ti代表文本輸入,T1,T2...Ti代表經過Transformer處理后的文本向量化表示。
BERT主要用了Transformer的Encoder,而沒有用其Decoder。Transformer模型中Encoder的結構如圖2所示。
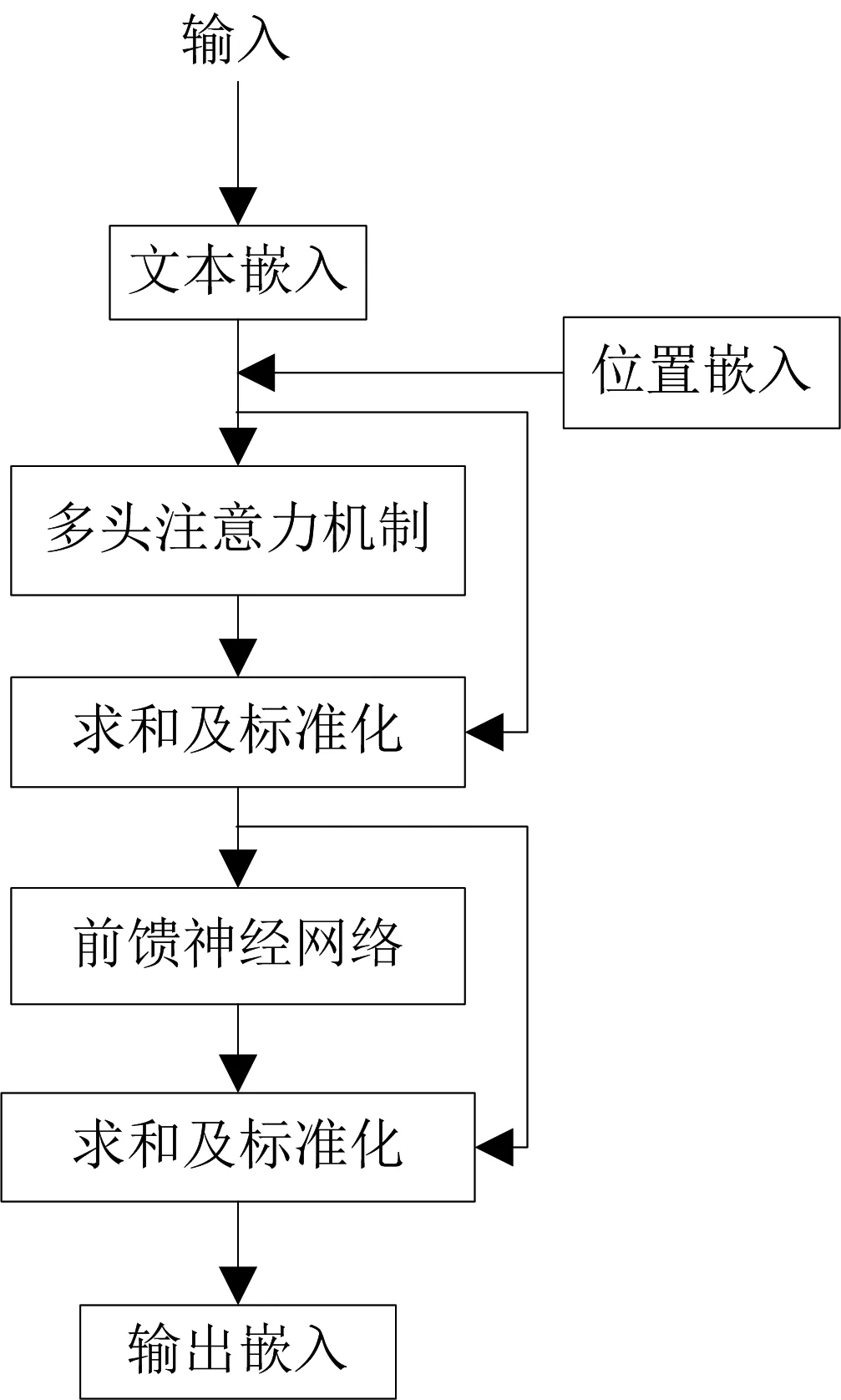
圖2 Encoder結構
圖2表示了自然語言序列經過計算得到文本的數學表達,Transformer模型沒有循環神經網絡的迭代操作,而是引入位置信息來識別語言中的順序關系。
此外,在BERT中提出了兩個新的預訓練任務Masked LM(Masked Language Model)和Next Sentence Prediction。Masked LM即隨機把一句話中15%的token替換成以下內容:
(1)這些token有80%的幾率被替換成[mask];
(2)有10%的幾率被替換成任意一個其他的token;
(3)有10%的幾率原封不動。
在Next Sentence Prediction任務中選擇一些句子對S1與S2,其中50%的數據S1與S2是一組有邏輯的句子,剩余50%的數據S2是隨機選擇的,學習其中的相關性,添加這樣的預訓練的目的是讓模型更好地理解兩個句子之間的關系。
基于以上理論,具體的向量化過程為:
Step1:文本預處理,去掉停用詞與特殊符號,留下有實際意義的文本;
Step2:將超過512字符的長文本數據的前128個字符與后382個字符相加代替原文本,使其符合BERT可接受的文本序列范圍;
Step3:構建字向量、位置向量、文本向量作為BERT模型的輸入;
Step4:通過BERT模型中的Transformer編碼器融合全文語義信息,得到文本向量。
向量化結果為{詞id:向量表示}
部分句子向量化結果如下:
{45466:11.464980125427246,45438:11.46498012
5427246,10419:3.8473434448242188,44612:11.46498
0125427246......7173:10.771833419799805}
2 相似重復數據聚類
經過向量化的文本即可進行余弦相似度的計算。用向量空間中的兩個向量夾角的余弦值作為衡量兩條記錄間的差異大小的度量,余弦值越接近1,就說明向量夾角角度越接近0°,也就是兩個向量越相似,就叫做余弦相似。計算方法為:
(1)
聚類算法是指將一堆沒有標簽的數據自動劃分成幾類的方法,這個方法要保證同一類數據有相似的特征,所以相似重復文本數據的清洗可以采用聚類的思路。K-means[7]首先隨機初始化質心,然后重復執行以下兩項操作:①計算每個成員與質心之間的距離,并將其分配給距離最近的質心;②使用每個質心的成員實例的坐標重新計算每個簇的質心坐標,直到類簇中心不再改變(或誤差平方和最小或達到指定的迭代次數)。
K-means聚類原理簡單,容易實現,聚類效果較優,可解釋度較強,整個過程只需調整參數k。該算法簡單的同時也帶來了一定的麻煩:①人為選取k值不一定能得到理想的結果,不同的k得到的最終聚類結果相差明顯,需要反復實驗才能找到最佳k值,這樣就會浪費大量的精力和時間,并且要求開發人員有相關的經驗。②k值選取不當會導致聚類結果的不穩定。所以本文先采用Canopy粗聚類[8]確定聚類中心,獲取聚類中心后執行K-means聚類算法,以此避免k值選取的隨機性。
3 實驗結果分析
本實驗數據來自某平臺運行過程中產生的日志數據,主要記錄了該平臺在運行過程中產生的業務流程信息,共317.11萬條記錄,其中包含了大量的相似重復記錄。
分別選擇100萬、150萬、200萬、250萬、300萬條數據作為實驗數據,對通過TF-IDF向量化的K-means算法、Canopy+K-means算法與本文提出的基于BERT的Canopy+K-means算法就查準率、查全率、F1值進行對比。
(1)查準率
查準率以預測結果為計算范圍,計算方法為預測為重復的記錄中實際也為重復的記錄與所有預測為重復記錄的比值,取值在0到1之間,越接近1,說明聚類正確的命準率越高,效果越好。結果如表1所示。
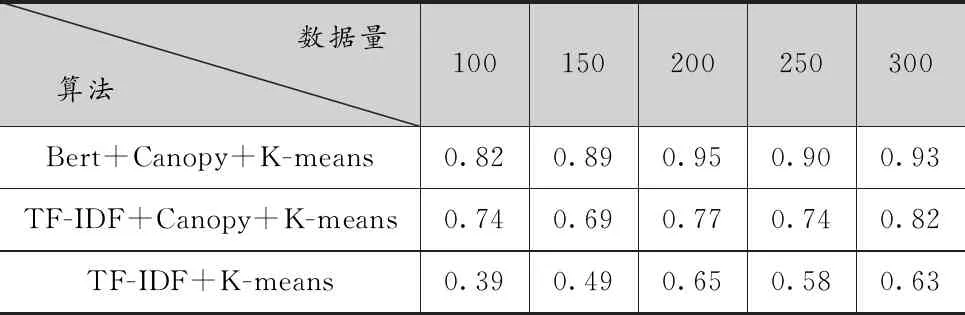
表1 查準率對比
從表1可以看出,經過BERT向量化的聚類結果準確率最高,而傳統K-means聚類最差,且效果不太穩定,當k值恰好取到合適的值時,其效果最好,但仍不夠理想,雖然經過Canopy大致確定k值,由于向量化不夠準確,本不相似的數據被聚到一個類里,導致最終聚類結果排名沒達到最優。出現以上結果的原因是,在日常表達中,同一個詞在不同語境下代表不同的意思,如“在商店里買了一袋蘋果”與“在商店里買了一部蘋果手機”,兩句話的詞語共現度達到了80%,意思卻明顯不同,第一句話中的“蘋果”代表一種水果,第二句話中的“蘋果”代表一種手機品牌,按照傳統的TF-IDF向量化表示,則將其識別為相似重復數據,而按照BERT模型學習之后,判斷這兩句話相似度很小,后續聚到不同的類里,準確度有所提升。再如“我比你高”與“你比我高”,兩句話的意思完全相反,而按照TF-IDF得到的結果是兩句話共同出現的字詞達到100%,認為這兩句話重復,這顯然是錯誤的。而BERT引入位置信息,得到恰當的向量表達,進而在計算句子間的相似度時更加準確,聚類結果也更加可信。以上結果說明BERT對存在一詞多義的文本進行相似性聚類有重要作用。
(2)查全率
查全率以原樣本為計算范圍,計算方法為:預測為重復的記錄中,實際也為重復的記錄占樣本所有重復記錄的比例。取值在0到1之間,越接近1,說明聚類覆蓋的越全面。結果如表2所示。
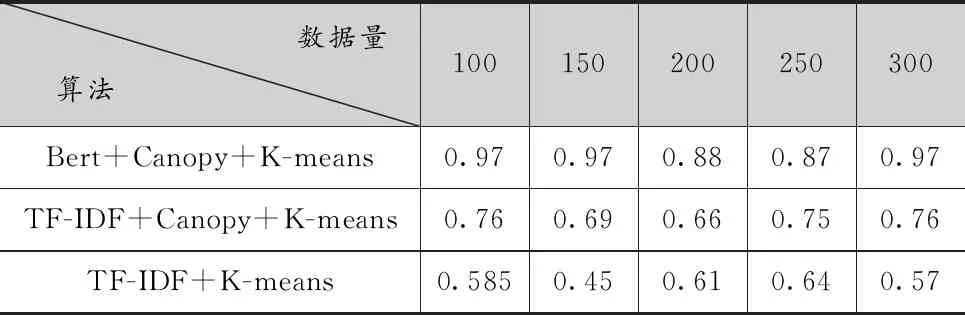
表2 查全率結果對比
從表2可以看出,K-means算法雖然在查準率上波動較大,但是在查全率大致穩定0.6附近,Canopy+K-means較之略有提升,大約在0.7附近,兩種方法都未能將所有的相似重復數據聚到一類中。而經過BERT文本向量化處理后的聚類則有優秀的表現,這是因為對于兩個文本,采用大量同義詞來表達相近的意思時,其詞語共現度很小,因此采用傳統TF-IDF向量化的K-means聚類難以將全部相似的文本聚類到一起,而經過BERT模型處理后,充分理解句子語義,從而將字面上看似不同的相似文本檢測出來并聚到一起。以上結果說明BERT對存在多詞一義的文本進行相似性聚類有重要作用。
(3)F1值
查全率與查準率是一對互斥的量,一般不能同時得到最優值,F1值是二者調和平均值,計算公式為:
(2)
F1取值在0到1之間,越接近于1,聚類效果越好。結果如表3所示。
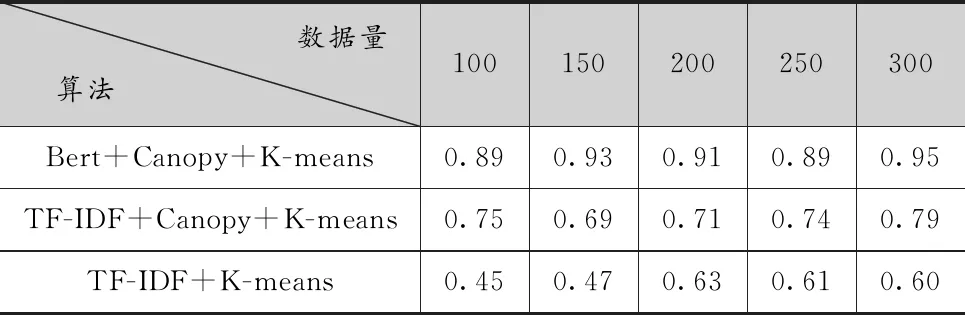
表3 F1值對比
F1值對前兩個指標做了一個平衡,從表3可以得知,本文提出的基于BERT的相似重復聚類表現最好,Canopy+K-means次之,傳統K-means最差。綜上可以看出,中文文本通過BERT模型生成向量后再進行相似聚類能得到更好的清洗效果。
4 結語
本文充分考慮了中文文本存在的不同語境下一詞多義與多詞一義的情況,引入了BERT語言模型,改進文本向量化過程,使文本的向量化表達更能承載真實的語義信息,從而使后續相似文本聚類更加準確。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
