同步輻射納米CT圖像配準方法研究*
2021-09-03 08:26:34蘇博陶芬李可杜國浩張玲李中亮鄧彪謝紅蘭肖體喬
物理學報 2021年16期
蘇博 陶芬 李可 杜國浩 張玲 李中亮鄧彪? 謝紅蘭 肖體喬
1) (中國科學院上海應用物理研究所, 上海 201800)
2) (中國科學院大學, 北京 100049)
3) (中國科學院上海高等研究院上海光源中心, 上海 201204)
基于同步輻射的X射線納米成像技術是無損研究物質內部納米尺度結構的強大工具, 本文總結了圖像配準技術在納米CT成像領域的研究和應用, 并根據發展階段進行分類分析.首先, 通過統計近年以來圖像配準文獻的發表情況, 分析并預測納米尺度圖像配準的未來研究方向.其次, 基于圖像經典配準算法理論, 詳細介紹了圖像配準算法在納米成像領域最有效的前沿應用.最后, 介紹了基于深度學習的圖像配準方法的前沿研究, 并討論深度學習在納米分辨圖像配準領域的適用性及發展潛能, 根據納米尺度圖像數據的特點及各種深度學習網絡模型的特性, 展望了同步輻射納米尺度圖像配準技術的未來研究方向及挑戰.
1 引 言
基于同步輻射的X射線納米成像是無損研究物質內部納米尺度結構的重要技術, 主要包括: 全場透射X射線顯微鏡(transmission X-ray microscope, TXM)、納米斷層成像(nano computer tomography, Nano-CT)、納米探針掃描成像(X-ray nanoprobe)、相干衍射成像(coherence diffraction imaging, CDI)和幾何放大投影成像(projection imaging, PI)等, 空間分辨率可高達幾十納米甚至幾納米, 近年來發展迅速, 已廣泛地在材料科學、化學催化、生命科學、環境科學等多個領域深度應用[1,2].
在納米級分辨率下, 機械、環境等的不穩定性也變得顯而易見.在CT掃描成像過程中, 假設投影數據只有已知旋轉角度的變化, 沒有其他任意方向的移動.由于機械不穩定性、機械精度、輻射熱膨脹、射線強度波動及探測器響應不一致等因素影響, 會造成樣品位置偏移、旋轉中心偏移、投影襯度不均等誤差.這些誤差對低分辨CT成像影響不大, 甚至可視情況忽略不計, 但在納米級分辨的納米CT上就被放大到明顯可見, 導致投影數據失準, 嚴重影響樣品的重建質量甚至無法正確重建.如圖1示例, 為失準投影數據合成的Sinogram圖(a)和對應的重構圖像(b), 由于位置偏移誤差、射線能量波動等原因, Sinogram圖上存在曲線不光滑、明顯截斷痕跡及襯度不均等問題.因此在圖像重構之前, 必須解決圖像失準的問題.

圖1 失準投影合成的Sinogram圖及重構切片圖 (a)發生偏移誤差時; (b)發生X射線能量變化時[3]Fig.1.Sinogram graph synthesized by misalignment projection: (a) With translation errors including vertical and horizontal movement at each projection; (b) when the X-ray density of projection is changed during the beam time[3].
目前, 解決納米尺度圖像失準的方法按工作原理可分為兩類: 一類是通過硬件, 提高機械穩定性或在線機械校準的方法; 一類是通過軟件, 在圖像后處理中進行圖像配準.
現代納米成像裝置上通常采取使用高剛度材料、調頻防止器件共振及添加隔離墊等措施盡量減小樣品掃描過程中發生振動, 也可以利用激光干涉儀等裝置在線校正掃描過程中的跳動誤差[4], 如圖2所示.但是, 在長時間的納米CT全角度掃描中,保持旋轉軸和樣品穩定轉動, 將旋轉樣品的抖動偏移量控制在幾十納米內仍是機械控制領域的技術瓶頸之一, 尚不能達到三維重構的納米級精度要求.針對該問題, 上海光源的程甲一等[5]利用可見光顯微鏡記錄樣品轉動過程中的漂移軌跡, 采用配準算法預測樣品的漂移規律, 再利用機械手段在線自動校正由轉動產生的樣品漂移, 將漂移控制在1 μm精度內, 如圖2(c)所示..雖然該方法的魯棒性、外推性及精度仍需提高, 但這種硬件與軟件結合的配準方法可為在線配準研究拓寬思路.

圖2 在線機械校準 (a)激光干涉儀[4]; (b)激光干涉儀記錄旋轉目標偏移軌跡[4]; (c) 上海光源軟X光譜學顯微實驗站樣品臺[5]Fig.2.Online mechanical calibration: (a) Laser interferometer[4]; (b) laser interferometer records the deviation trajectory of the rotating target[4]; (c) SSRF soft X spectroscopy microscope experimental station sample stage[5].
圖像配準是將來自不同時間、角度、景深或探測器的不同圖片數據集轉換到同一坐標系下的方法, 廣泛應用在計算機視覺、醫學成像、遙感衛星、自動控制、材料科學等領域.圖像配準算法自20世紀60年代發展至今, 并沒有統一的分類標準.根據圖像數據獲取方式的不同, 可分為單模態圖像配準、多模態圖像配準; 根據提取圖像信息的不同,可分為基于區域的圖像配準、基于特征的圖像配準;根據空間變換性質, 可分為剛體變換配準(旋轉、縮放、平移等)、非剛體變換配準(徑向基函數、物理連續模型、大變換模型); 根據人機交互性, 可分為全自動配準、半自動配準、人工配準等.
隨著計算能力的提高, 作為圖像處理與計算機視覺等領域的共同熱門課題-圖像配準算法的研究進入高速發展階段.本文使用多個關鍵詞在多個數據庫調研了圖像配準相關研究的文章發表情況, 總結了圖像配準算法的發展趨勢.關鍵詞包括不限于圖像配準(image alignment, image registration)、深度學習(deep learning)、CT(computer tomography)、卷積神經網絡(convolutional neural network, CNN)、生成對抗網絡(generative adversarial network, GAN)、互相關(cross correlation)、互信息(mutual information)等, 搜索引擎使用谷歌學術、超星發現、Web of Science等, 數據庫包括Scopus文摘索引數據庫(荷)、SCI科學引文索引(美)、EI工程索引(美)、PubMed/Medline收錄、統計源期刊(中信所)、中文核心期刊(北大)、CSCD中國科學引文庫(中國科學院)等.如圖3(a)所示, 圖像配準研究從20世紀90年代開始發展,在20世紀迎來高速發展階段, 各種經典算法相繼被提出.如圖3(b)所示, 近年來, 圖像配準的相關研究雖然逐漸遞減, 但基于深度學習的圖像配準研究逐年增加.到2020年為止, 基于深度學習的圖像配準研究預計達到全年圖像配準相關文獻發表總量的1/4, 逐漸成為該領域的主流方法之一.

圖3 圖像配準領域文章發表情況 (a) 近30年圖像配準論文發表情況; (b) 近10年深度學習圖像配準論文增長趨勢Fig.3.Publication of papers in the field of image registration: (a) Publication of research papers on image registration in the past 30 years; (b) percentage of papers on deep learning image registration in the past 10 years.
本文針對同步輻射X射線納米尺度圖像配準的研究方向, 根據圖像配準算法的研究階段分別介紹: 經典圖像配準理論與算法、納米尺度圖像配準前沿應用研究及圖像配準算法前沿研究.依據工作原理、交互方式、數據類型等方面, 詳細闡述每類配準算法的原理、適用場景及優化方向, 并簡潔的對每種算法的貢獻及未來適用性進行總結, 本文概述導圖如圖4所示.

圖4 圖像配準算法分類概述導圖Fig.4.Classification overview map of image registration algorithms.
2 圖像配準理論與算法
常規圖像配準工作流程主要包括: 模型變換,特征檢測及描述, 尋優策略選擇并建立映射關系,圖像重采樣或變換等, 如圖5所示.其中, 核心步驟為特征的檢測描述與匹配, 圖像配準算法根據檢測特征信息算法的不同, 可分為基于區域的圖像配準與基于特征的圖像配準兩大類.
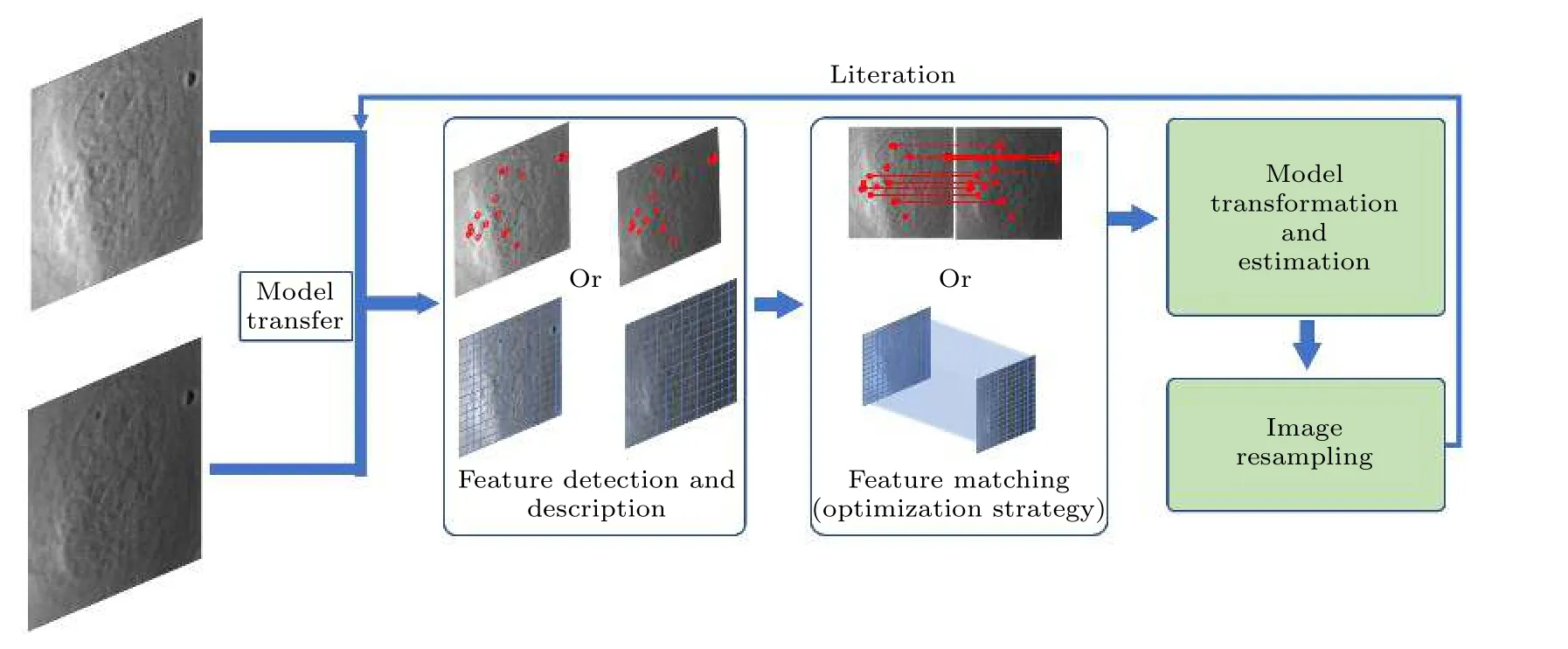
圖5 圖像配準的常規流程圖Fig.5.General flow chart of image registration.
2.1 基于區域的圖像配準算法
基于區域的圖像配準算法是利用圖片的強度信息等來構建特征空間的方法, 典型方法有: 互相關法、互信息法、傅里葉法等[6,7].
1971年, Leese等[8]在模式識別算法的基礎上提出一種基于圖像灰度的平均絕對差配準算法(mean absolute differences, MAD).隨后, 基于該MAD算法改進的絕對誤差和算法(sum of absolute differences, SAD)、誤差平方和算法(sum of squared differences, SSD)、平均誤差平方和算法(mean squared differences, MSD)、序貫相似性檢測算法 (sequential similarity detection algorithm, SSDA)[9]及絕對變換誤差和算法(sum of absolute transformed difference, SATD)等配準算法被相繼提出, 此類算法均采用圖像灰度值計算相似度進行圖像配準, 計算速度、魯棒性、精度均有所提高, 但各有側重.1974年, Pratt[10]在灰度值配準算法的基礎上提出互相關圖像配準法, 并通過計算機仿真結果證明.1982年, 在圖像點互相關法的基礎上, Guckenberger[11]證明了通過互相關函數在線性連續物體圖像配準中是有效的.隨后, 歸一 化 互 相 關(normalize cross-correlation, NCC)及快速歸一化互相關(fast normalize cross-correlation, FNCC)等算法被相繼提出, 進一步地提高了配準精度及速度[12,13].
1995年, Paul等[14]提出互信息配準法, 引用熱力學中熵的概念來表達兩幅圖像之間信息的不確定程度.互信息配準法適用于多模態配準, 如醫學影像配準、雙能CT投影配準[15]等.隨著尋優算法的發展, 從20世紀90年代開始, 遺傳算法[16]、粒子群算法[17]、蟻群算法[18]等尋優算法相繼被用于提高互相關、互信息等圖像配準算法的速度.
傅里葉變換圖像配準法通過傅里葉變換將圖像數據由空域變換到頻域, 采用相位相關技術進行計算匹配, 具有速度快、精度高等優勢[19].基于傅里葉變換的圖像配準常規流程如圖6所示.傅里葉變換針對平移、灰度變化、旋轉及縮放的圖像具有尺度不變性, 利用整幅圖像的灰度信息進行配準,精度較高.然而, 針對旋轉角度、縮放尺度及位移偏差較大或非線性畸變等圖像魯棒性不高, 對噪聲也較為敏感.
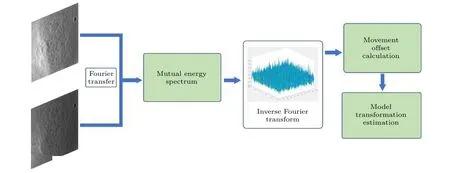
圖6 基于傅里葉變換的圖像配準流程圖Fig.6.Flow chart of image registration based on Fourier transform.
2.2 基于特征的圖像配準算法
基于特征的圖像配準算法根據圖像中的可識別特征進行圖像匹配.根據特征提取方式及人機交互性等, 可分為手動選取法和自動檢測法; 根據特征屬性, 可分為人工特征(又稱外部特征)法和自然特征(又稱內部特征)法.
特征手動選取法是具有配準功能的三維重構軟件的常用功能, 如斯坦福大學的納米CT重構軟件TXM wizard等[20].實際情況下, 由于光通量過低或不穩定等原因, 導致CT投影數據襯度低及信噪比低, 圖像自然特征不明顯, 手動選取特征變得尤為困難.20世紀90年代, 有研究人員在樣品中添加人工特征物-金顆粒, 人工特征在樣品投影中襯度高且易于檢測, 有效降低了配準計算的復雜度, 節省了大量時間.但人工特征法也因樣品制備困難、周期長及價格昂貴等缺點受到限制.
自動特征提取是指通過算法自動檢測圖像的自然特征并加以描述的方法, 如: 點特征、線特征、中心特征、區域重心等, 將其作為圖像配準算法的特征進行匹配.上述特征應是圖像中不受偏移、旋轉及縮放等變化影響的目標, 可稱之為不變描述符.因此, 基于特征的圖像配準算法的本質是不變描述符的利用, 該不變描述符應滿足條件有: 不變性、唯一性、穩定性及獨立性.但是, 實際使用過程中并不能同時滿足所有條件, 可按照使用需求適當權衡取舍, 實現最優特征選取.
特征檢測描述方法的優劣決定了圖像配準計算的效率和精度.隨著計算力提升及圖像處理學科的發展, 從20世紀80年代起, 經典的特征匹配算法, 如Moravec算子[21]、Harris角點檢測算子[22]、SIFT(scale-invariant feature transform)法及基于SIFT[23]改進的PCA-SIFT[24]、SURF[25]、CSIFT[26]等被相繼提出, 不斷優化圖像特征提取的效率、精度及穩定性.2006年, Rosten等[27]提出一種快速檢測特征點的算法 (features from accelerated segment detection, FAST), 原理是若某像素與其周圍鄰域內足夠多的像素點相差較大, 則該像素便可能為角點.2010年, Calonder等[28]提出一種二進制的特征點描述子 (binary robust independent elementary features, BRIEF), 該算法沒有采用灰度直方圖, 極大減少了特征匹配時間.然而, BRIEF僅是特征點描述子, 還需FAST, Harris, SIFT等算法檢測特征點.2011年, Rublee等[29]結合FAST特征點檢測法和BRIEF特征點描述法提出ORB(oriented brief)特征點檢測描述法, 不僅優化了BRIEF的噪聲敏感問題, 還兼具旋轉不變性.同年, Leutenegger等[30]提出一種二進制特征檢測描述算法BRISK, 利用FAST進行特征點檢測, 構造圖像金字塔多尺度表達使其具有尺度不變性, 特征點描述采用高斯濾波及局部梯度計算使其具有旋轉不變性.2012年, Alahi等[31]在BRISK算法的基礎上提出FREAK算法, 在兼具尺度不變性、旋轉不變性及噪聲不敏感性的基礎上, FREAK法采用與BRISK的均勻采樣法不同的視網膜拓撲采樣法(如圖7所示), 核心區域處理高精度圖像信息, 過度區域及稀疏區域處理低精度圖像信息, 使魯棒性大幅提高.另外, 常見的邊緣提取算子有LOG (laplace of Gaussian)算子[32]、Robert算子、Sobel算子、Prewitt算子等[33], 計算效率等詳見參考文獻[31, 32].

圖7 FREAK算法的類視網膜取樣模式[31]Fig.7.Retina-like sampling mode of FREAK algorithm[31].
在上述基于區域或特征的圖像配準算法中:
1)互相關與傅里葉變換等算法采用圖像全局信息, 雖然針對圖像噪聲、大尺度偏移及旋轉等影響的魯棒性不高, 但是兼顧了圖像配準的效率及精度, 很適用于圖像信息偏差不大, 高配準精度要求的圖像;
2)基于特征的配準算法則對旋轉、偏移等圖像具有高魯棒性, 通常采用點特征法進行匹配, 比較點特征檢測描述算子的效率可知, ORB算法最快, 其次為FREAK, BRISK, SURF 及SIFT等,但若進行模糊程度較高的圖像配準時, BRISK算法的性能表現最為出色;
3)互信息圖像配準算法和特征匹配配準算法均適用于多模態配準.
3 納米尺度圖像配準的應用研究
在過去幾十年里, 數種圖像配準算法被應用到X射線斷層成像技術中.每種算法都各有優缺點, 阻礙了它們在X射線納米成像高精度配準中的廣泛應用.例如, 基于互相關的圖像配準算法雖然計算速度快, 但是鄰角度投影的亞像素級誤差會不斷累加, 難以解決復雜的幾何變換問題; 基于特征的圖像配準算法, 自動檢測計算復雜, 人工標記制樣困難等.
近年來, 納米尺度圖像配準的發展主要以高精度、高速度、高魯棒性為目標.瑞士保羅謝勒研究所(Paul Scherrer Institute, PSI)的研究人員針對納米相干衍射成像的投影數據展開了一系列配準研究.2008年, Guizar-Sicairos等[34]提出了3種基于互相關及離散傅里葉變換的亞像素級精度配準算法, 與常規快速傅里葉變換方法相比, 有效減少了內存需求, 計算效率得到極大提高.2017年,Gürsoy等[35]針對納米尺度成像技術提出一種基于迭代重投影技術的快速高精度圖像配準技術.2019年, Odstrcil等[36]針對相干衍射相位成像, 利用的投影數據的吸收及相移信息提出一種聯合配準算法.該方法按照算法優勢將互相關配準法、共線垂直配準法、投影匹配法等配準算法分為預配準(即粗配準)和精配準兩部分進行全自動配準研究, 算法流程如圖8所示.該篇文章用模擬數據實驗對聯合配準算法進行測試, 如圖9所示的實驗結果證明該方法在保證亞像素級精度配準的前提下,有效避免了用戶交互過程, 實現了快速、高魯棒性的全自動投影數據配準與重建.

圖8 MR-PMA配準法流程圖[36]Fig.8.Flow chart of MR-PMA image alignment[36].

圖9 通過MR-PMA方法配準的FBP法重建質量[36] (Dataset 1為標準數據集, Dataset2為欠采樣并包含161個噪點的數據集、Dataset 3在Dataset 2基礎上添加了10%的高斯噪聲.分別對每個數據集進行32-1的降采樣法配準, 最后一列的插圖顯示了全分辨率數據集的重建質量)Fig.9.FBP reconstruction quality after alignment by our MR-PMA method[36] (Columns show reconstruction at different downsampling levels from 32 up to 1, and rows correspond to different synthetic datasets.Insets in the last column show detail of the reconstruction quality for the full resolution dataset).
2018年, 斯坦福大學同步輻射光源及東華大學的Yu等[37]通過評估不同配準算法的特性, 并提出一個聯合RP (reverse projection)、CM (center of mass), PC (phase correlation), SIFT, IAIR(intensity-based automatic image alignment)等多種配準算法的特定使用序列以克服單個配準算法的短板, 提供最佳的自動配準性能, 如圖10-圖12所示.首先, 利用RP法計算旋轉中心與投影中心的相對偏移量, 但是對于隨機振動誤差無效.因此, 采用精度較低、計算速度快的CM法作為粗配準步驟校正隨機振動誤差.其次, 采用兼顧精度與計算速度的相位相關法進一步提高配準精度.最后, 采用SIFT法和IAIR法(對低信噪比的投影魯棒性不高)進行最終偏移及旋轉誤差校正, 以達到最佳配準精度.根據電池電極顆粒納米CT數據的實驗結果證明, 該方法對納米尺度圖像有效配準, 實現高精度三維重建[37].

圖10 評估具有不同缺陷的不同圖像配準算法的精度和魯棒性[37]Fig.10.Evaluation of the precision and the robustness of different image registration algorithms with added imperfections[37].

圖12 配準后頁巖投影重建切片對比: (a) 原始數據, (b) 手動配準, (c) 自動配準; 重投影后頁巖投影數據對比: (d) 實驗數據,(e) 手動重投影, (f) 自動重投影[37]Fig.12.Reconstructed slices through the center of the shale sample without alignment (a) and with manual (b) or automatic (c)alignment.Panel (d) is the experimentally measured projection image.Panels (e) and (f) are the numerically reprojected images,calculated from the manual and auto-aligned 3D matrixes, respectively[37].

圖11 納米級投影圖像迭代配準重建流程圖[37]Fig.11.Schematics of the iterative projection image registration workflow for nanoscale X-ray tomographic reconstructions[37].
2020年, 中國臺灣光源的Wang等[38]針對納米成像投影數據提出一種無標記全自動配準算法.先后利用頻域共線配準法、空間共線配準法、單層迭代重建與重投影法來處理投影面內旋轉誤差、垂直誤差、水平誤差.如圖13和圖14所示, 實驗結果表明, 這種聯合配準算法有效降低了經典配準算法的計算復雜度, 提高了高精度配準的收斂速度,總處理時間最多可減少4個數量級.

圖13 Ji-Faproma算法不同噪聲水平下的配準精度對比[38] (a)投影內旋轉誤差的平均根方差; (b)投影垂直誤差和水平誤差的平均根方差; (c)配準后面對不同噪聲時的重建質量Fig.13.Performance of the JI-Faproma evaluated by comparing the alignment accuracy under different noise levels[38]: (a) Rootmean-square error of the in-plane rotational error correction; (b) root-mean-square errors of the vertical and horizontal error corrections; (c) reconstruction quality after JI-Faproma alignment for test phantoms containing different levels of noise.

圖14 Ji-Faproma算法在不同噪聲水平下的收斂情況[38]Fig.14.Ji-Faproma algorithm convergence under different noise level of raw projections[38].
此外, 中國科學院高能物理所的Wang等[39]針對納米分辨全場成像掃描過程中樣品抖動的問題, 提出了一種基于GMs(geometric moments)的校正樣品抖動的配準算法, 如圖15和圖16所示.實驗表明, 該方法通過測量和擬合的GMs差異來估算樣品抖動值以進行圖像校正, 有效保留了CT投影數據的精細結構, 與手動標記法相比具有更好的空間分辨率和襯度, 相比于添加金顆粒特征(手動標記法), 該方法極大節省了實驗成本.

圖15 GMs抖動校正法的流程圖[39]Fig.15.Workflow of the proposed jitter correction[39].

圖16 采用不同矯正方法的重構結果[39] (圖中: a列-d列分別是原始數據、手動對齊、重投影法、GMs法的切片; 第1-第3行是從x–z平面重建的切片, 在y方向上均勻間隔了50個像素; 第4行是x–z平面中的重構切片)Fig.16.Sinograms (top row) and reconstructed slices of a chlorella cell using different methods[39] (Row 2: reconstructed slices of row 1, displayed in the x–y plane.Row 3: reconstructed slices in the x–z plane.Columns from (a) to (d) are results of TXM without jitter correction, corrected by a re-projection-based method, by manual alignment and by the proposed GM method).
由上述研究可以看出, 由多種經典算法組合而成的粗配準-精配準-聯合配準算法模式是納米尺度圖像配準的有效處理方法之一, 達到了亞像素級精度、高魯棒性、高速度的研究目標.隨著各種新特征檢測描述方法的不斷提出, 通過以經典配準重構算法與新特征檢測描述算子結合使用的方式,聯合配準算法的性能仍有進一步提高的潛力.
4 基于深度學習的圖像配準算法
深度學習的概念由Hinton等于2006年提出,是基于機器學習多層神經網絡的應用研究, 目的是建立模擬人腦分析過程進行學習的方法[40].近年來, 隨著深度學習各項技術的快速發展, 陸續在多個領域的人工智能應用上取得成功, 例如: 在計算機視覺和模式識別中, CNN能夠有效實現圖像識別, GAN顯著提高了圖像翻譯, 圖像編輯, 圖像修復和圖像融合等任務的性能等.此外, 還有循環神經網絡(recurrent neural network, RNN)、自動編碼神經網絡(auto-encoder, AE)及強化學習(reinforcement learning, RL)等方法廣泛應用于各個領域.圖像配準作為圖像處理、機器學習、計算機視覺等領域的交叉熱門研究課題, 現有的圖像配準研究趨勢被深度學習的研究模式打破, 當前圖像配準的前沿研究大多涉及深度學習.
自 2014年起, 基于深度學習的圖像配準研究的會議論文和期刊論文發表數量迅速增加.如圖17所示, 基于CNN的圖像配準研究增量最多, 增速最快, 目前已占比約為深度學習圖像配準研究總數量的55%; 同時, 基于GAN圖像配準的研究趨勢也逐年增加, 增速迅速提升, 目前已經占比約13%;基于自動編碼神經網絡與強化學習的圖像配準研究增量較少, 分別占比約6%和7%.必須指出,上述方法并不是相互代替, 而是常常采用聯合使用的方式進行圖像配準.總體來看, 基于無監督的深度學習研究數量過半, 這是因為監督學習方法需要從大量特征中選擇最優的特征空間, 往往還需要用到人工特征進行訓練, 并且該方法還需要與預測估計值具有參照關系的目標數據(ground truth)進行訓練[41-43].但是, 由納米成像技術獲得的圖像數據通常沒有目標數據, 目標數據的計算過程不僅耗費人力, 并且易受到人為主觀因素的影響, 極大影響了圖像配準的準確性.因此, 本文將根據納米成像數據的特點及難點展開基于多種深度學習模式的前沿研究介紹.
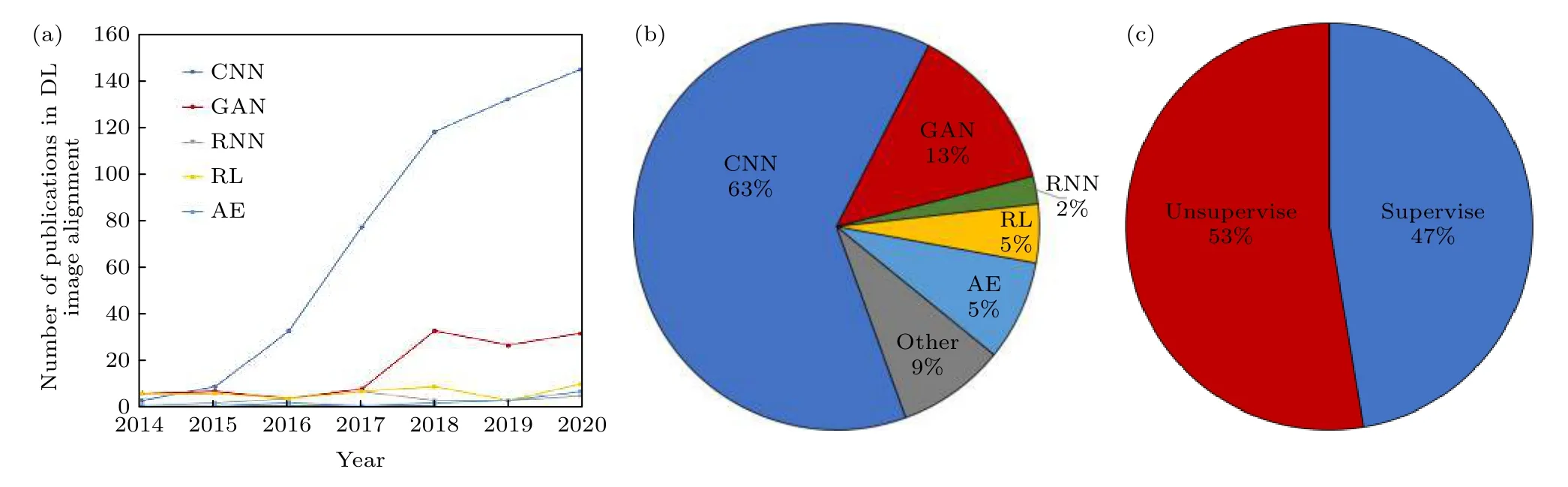
圖17 深度學習研究論文發表情況統計 (a) 2014年至2020年多種深度學習模式圖像配準論文發表數量統計; (b) 2014年至2020年多種深度學習模式的圖像配準文章百分比圖; (c) 2014年至2020年無監督與監督深度學習圖像配論文發表百分比圖Fig.17.A survey of the publication of deep learning research papers: (a) Number of published image registration papers based on multiple deep learning methods since 2014; (b) percentage of image registration papers based on multiple deep learning methods since 2014; (c) The percentage of published image registration papers based on unsupervised and supervised deep learning since 2014.
2012年, 由Krizhevsky等[44]采用的深層CNN由輸入層、卷積層、ReLu層、池化層和全連接層組成.深層CNN具有的正則化多層感知器、卷積濾波和算子使其具有卓越的圖像提取能力, 是當前深度學習圖像配準使用最廣泛的網絡結構模型.Cao等[45]基于深層CNN配準方法提出了線索感知深度回歸網絡, 建立從輸入圖像到輸出形變場的非線性映射模型, 實現準確有效的非線性形變配準.該研究通過基于關鍵點的均衡化采樣方法在訓練數據中采集足夠的訓練樣本來訓練CNN模型,方法流程如圖18所示.經實驗證明, 訓練結果可擴展至多樣數據集進行配準, 具有高魯棒性.

圖18 基于線索感知深度學習網絡的圖像配準[46]Fig.18.The framework of the proposed similarity-steered CNN regression for deformable image registration[46].
針對深度學習圖像配準的監督學習缺少目標數據的問題, 有研究者使用模擬數據進行基于監督學習的圖像配準訓練, 訓練結果對真實數據的固定噪聲極其敏感, 圖像配準的準確性同樣難以保證.
Krebs等[47]通過大量模擬圖像數據與少量真實圖像數據混合使用的方式解決無目標數據問題.Rohé等[48]使用全局信息和結構信息代替強度信息對部分區域進行與配準, 以增加計算速度并避免陷入局部最優化.隨后, 將配準后的偏移信息作為目標數據進行監督訓練, 測試數據的結果表明模型的精度、魯棒性、速度均有所提高.
Wu等[49]采用卷積結構的多層自動編碼網絡對腦部圖像數據進行無監督的深度學習圖像配準,卷積結構有效降低了多層自動編碼網絡(即貪婪算法)的復雜度, 訓練后的模型對測試數據具有一定的魯棒性, 為深度學習圖像配準應用的提供了思路.Fang等[50]提出了一種快速無監督學習的全連接卷積網絡, 直接進行輸入圖像數據的密度偏移矢量場(dense displacement vector field, DVF)的估計學習訓練, 并不需要目標數據進行標定.經使用公開CT數據集測試表明, 該方法可以在保持與常規CNN訓練模型同等精度下, 速度明顯提高.
2014年, GAN由Goodfellow等[51]提出, 迅速在各領域展開了大量研究, 相關研究文章發表數量如圖19所示.GAN由兩個競爭網絡組成, 分別為生成器和鑒別器.生成器從低維空間合成模擬真實數據的人工數據對鑒別器進行區分訓練, 通過對鑒別器的懲罰機制實現準確預測真實數據, 圖20為基于GAN的醫學圖像配準流程示例[52].

圖19 基于GAN研究的論文發表情況Fig.19.Number of papers published related to GAN research.

圖20 基于GAN的醫學圖像配準流程圖[52] (a) 生成器 (b)鑒別器Fig.20.Flow chart of medical image registration based on GAN[52]: (a) Generator network; (b) discriminator network.
Mahapatra等[53]通過訓練GAN生成配準圖像和相應的形變場提出一種無監督自適應的 GAN深度學習框架.通過實驗證明, 訓練模型可以適用于不同類型的圖像配準, 基于域自適應的配準方法比采用大量數據訓練配準法的性能更佳.Toriya等[54]針對低信噪比的衛星遙感圖像特征不明顯等問題, 采用基于GAN的pix2pix模型生成明顯特征點的光學圖像作為匹配之前的預處理步驟, 再用SIFT等算法進行匹配, 如圖21所示.該方法驗證了低信噪比圖像特征點強化后的特征匹配能力,所提出的深度學習特征預處理與基于特征配準算法的結合模式也契合了納米CT圖像數據的特點,如將pix2pix模型拓展為CycleGAN[55]模型以解決納米圖像數據無目標數據等問題, 為未來配準工作提供了新思路.

圖21 GAN配準前特征點預處理流程圖[54]Fig.21.Outline of using GAN as a preprocessing step before keypoint matching[54].
截止目前, 采用深度學習框架處理納米尺度圖像配準的研究還較少, 但必須指出:
1) 無監督的深度學習方法不受目標數據的限制, 完全依靠原始數據進行訓練, 無需人工特征標記;
2) 深度學習可用于特征匹配前預處理步驟,有效強化低信噪比圖像的自然特征.
因此, 上述方法均可外推至具有低信噪比、相鄰旋轉角度間連續偏移等特點的納米CT圖像數據集的配準研究中, 尤其是基于GAN模型作為特征強化的配準預方式.按照現有深度學習框架快速搭建, 無需人工交互即能完成納米尺度圖像配準,但要達到亞像素級精度、高速度及高魯棒性的目標還需進一步研究及驗證.
5 結論與展望
圖像配準技術是解決納米尺度圖像數據失準問題的有效方法.本文以圖像配準經典算法的發展過程為鋪墊, 詳細介紹了瑞士保羅謝勒研究所、美國阿貢實驗室、美國斯坦福大學、中國科學院高能物理研究所、中國科學技術大學、中國臺灣光源、中國上海光源等先進成像研究機構關于納米級別圖像的配準研究進展.總結了當前的研究目標為開發亞像素級精度、高速度及高魯棒性的配準方法,并根據前沿文獻的調研情況指出目前納米成像領域中最行之有效的圖像配準模式-聯合配準算法模式, 及預測未來研究趨勢為深度學習與圖像配準算法的結合模式.
本文通過從近年來發表的特征提取描述研究中篩選出適用于納米尺度圖像配準的特征提取描述算子, 為聯合算法的進一步優化提供了重要參考.可以預見, 隨著不斷有新特征檢測算子提出,與經典配準重構算法的組合應用也逐漸多樣化, 聯合配準算法的性能即具有巨大的提升空間.
基于深度學習的研究改變了圖像配準算法的發展趨勢.CNN和GAN等深度學習網絡具有的卓越的圖像提取能力在納米成像投影配準研究中有巨大的應用潛力.不僅可以直接用于圖像配準,還可以優化圖像配準的預處理步驟.同時, 本文也指出了深度學習在納米CT圖像配準研究中面臨的挑戰:
1)納米CT數據沒有真實目標值(Ground Truth)進行訓練;
2)深度學習訓練模型的配準精度尚未優于聯合配準等算法;
3)深度學習作為圖像配準算法的預處理步驟,強化自然特征;
4)保證及驗證配準圖像的真實性.
上述挑戰對基于深度學習的納米級別圖像配準的未來研究方向具有一定的指導意義.隨著深度學習框架的發展及GPU計算能力的提升, 深度學習具有極大潛力成為納米成像領域圖像配準的核心方法之一, 大大推動同步輻射納米成像技術的發展.
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
科技傳播(2019年22期)2020-01-14 03:06:54
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
